OLMOCR1.0:
allenai开源多模态的文档智能解析大模型(OLMOCR)方法、效果浅析
往期相关:
- 端到端的多模态文档解析模型-DeepSeek-OCR架构、数据、训练方法
- 再看两阶段多模态文档解析大模型-PaddleOCR-VL架构、数据、训练方法
- 如何打造一个文档解析的多模态大模型?MinerU2.5架构、数据、训练方法
olmOCR 2相关对比:
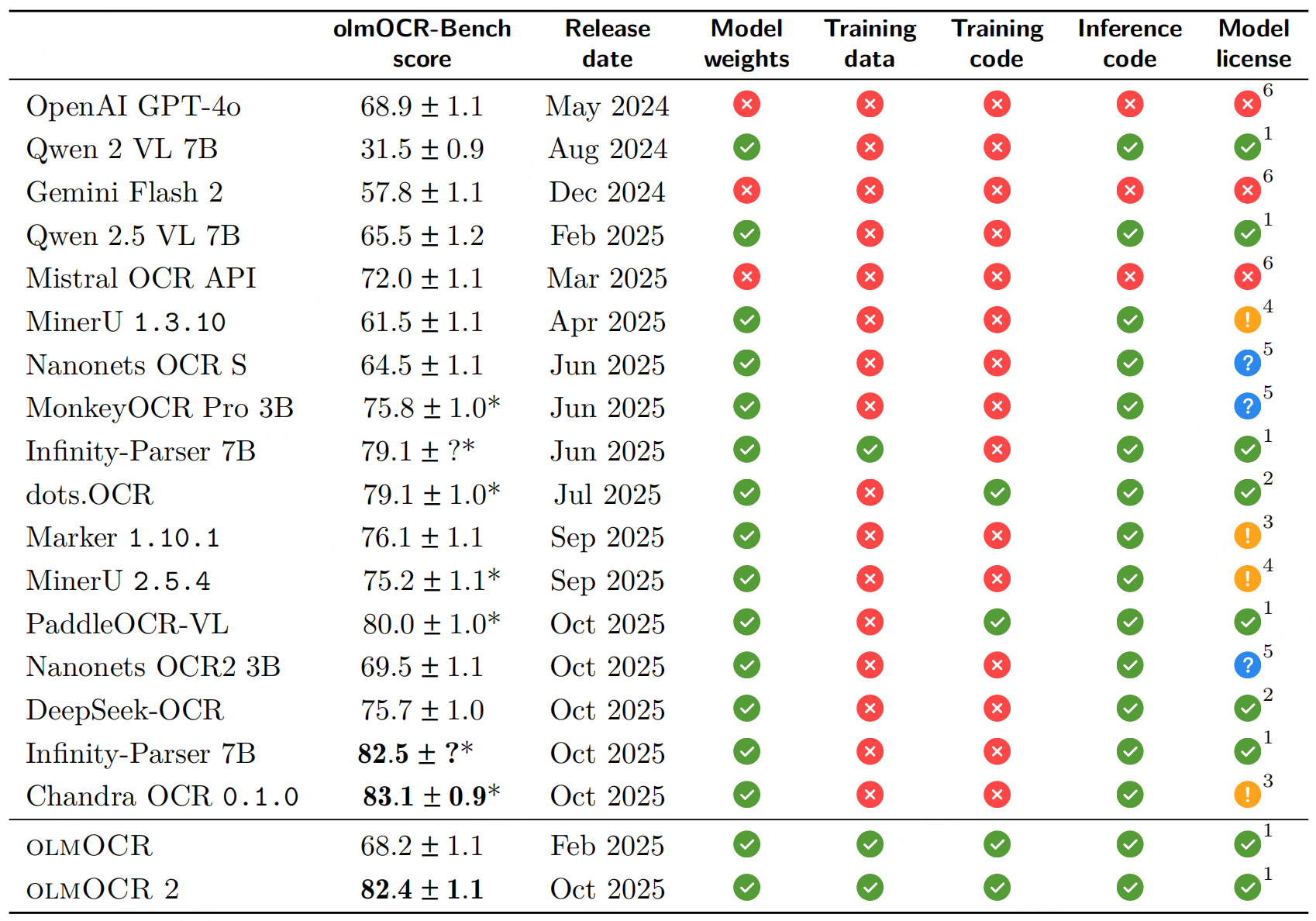
olmOCR 2 是一套面向文档 OCR 的端到端解决方案,其核心方法围绕RLVR,通过 "合成数据规模化 - 单元测试定奖励 - RL 训练提性能" 的闭环,解决传统 OCR 系统在复杂场景(数学公式、表格、多列布局)中的痛点。
现有问题
传统OCR系统的性能评估依赖编辑距离 ,计算模型输出与Ground Truth的字符级差异(插入、删除、替换次数)。
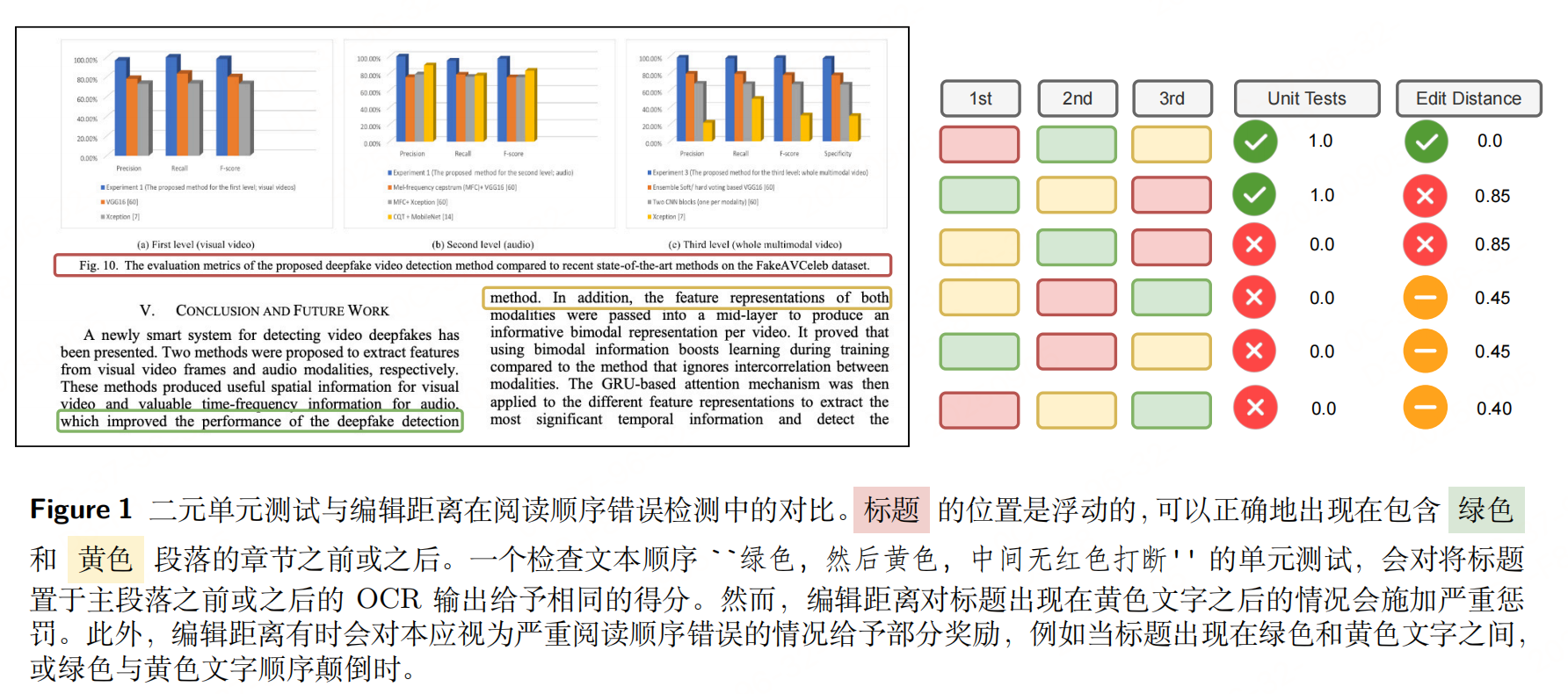

为解决上述问题,设计了下面6类可验证的二进制单元测试(结果仅"通过(PASS)"或"失败(FAIL)"),覆盖文档OCR的需求:
| 测试类型 | 核心功能 |
|---|---|
| 文本存在性 | 验证特定短语(如关键句子、公式)是否精确出现在输出中 |
| 文本不存在性 | 验证无关内容(如页眉、页脚、页码)是否未出现在输出中 |
| 自然阅读顺序 | 验证句子/段落的顺序是否符合人类阅读习惯(如图1中"绿色→黄色"不被红色打断) |
| 表格准确性 | 验证表格单元格的相对位置与数值是否正确(如"Model"在"GPT-4-turbo"上方) |
| 数学公式准确性 | 用KaTeX渲染模型输出与参考公式,验证视觉结构是否一致(如图2) |
| 基线鲁棒性 | 验证无长重复n-gram、无非目标语言字符(避免模型幻觉) |
这些测试的优势在于:
- 公平处理浮动元素:对图注、表格等位置灵活的元素,只要核心逻辑正确(如表格单元格关系、阅读顺序),均判定为通过,避免编辑距离的"过度惩罚";
- 精准反映实际正确性:聚焦"用户是否能用"(如公式能否正确渲染、表格能否正确读取),而非"字符是否完全匹配"。
数据
手动为每个文档设计单元测试耗时极长(原文提到"需数小时/文档"),无法支撑RL训练的大规模数据需求。因此,文章开发了全自动合成数据生成 pipeline,实现"文档→HTML→单元测试"的端到端规模化,核心流程分三步:
1. 步骤1:挑选"难处理场景"PDF数据源
为确保合成数据的挑战性(覆盖真实OCR痛点,避免"模板化数据",确保数据多样性,与真实世界OCR需求对齐。),文章选择高难度文档样本 :
数据来源arXiv数学论文(含复杂公式)、旧扫描件(低分辨率)、多列布局文档、含复杂表格的文档。
2. 步骤2:PDF→HTML的三阶段转换(生成"带Ground Truth的结构化文档")
HTML是生成单元测试的关键:其语义标签(如<header>、<footer>、<table>、KaTeX公式)可直接用于自动提取测试用例。转换过程依赖通用VLM(Claude-sonnet-4-20250514) ,分三阶段迭代优化:
| 阶段 | 核心任务 | 输入 | 输出 |
|---|---|---|---|
| 1. 布局分析 | 让VLM识别文档结构:列数、图像/表格位置、页眉/页脚区域、公式位置等 | 原始PDF页面图像 | 布局结构描述(如"2列,右上角有表格") |
| 2. 内容渲染 | 让VLM基于布局分析,生成与原始PDF尺寸一致的语义HTML | 原始图像+布局描述 | 初始HTML(含文本、KaTeX公式、HTML表格) |
| 3. 输出优化 | 渲染初始HTML为图像,与原始PDF对比,让VLM修正差异(如字体、间距、公式格式) | 原始图像+初始HTML+渲染图像 | 优化后的最终HTML |
3. 步骤3:基于HTML自动生成单元测试
利用HTML的结构化信息,程序化提取单元测试用例,无需人工干预:
- 文本不存在性测试:从
<header>/<footer>标签提取页眉/页脚,生成"这些内容不应出现"的测试; - 数学公式测试:从KaTeX标签提取公式,生成"渲染后与参考一致"的测试;
- 表格测试:从
<table>标签随机采样单元格,生成"单元格相对位置正确"的测试; - 阅读顺序测试:基于HTML中段落的先后顺序,生成"段落顺序符合HTML结构"的测试。
最终生成的合成数据集 olmOCR2-synthmix-1025 包含:2186个PDF页面 → 30381个单元测试用例,为RL训练提供充足数据。
训练流程:SFT→RLVR→模型融合,端到端优化
olmOCR 2的训练分为监督微调(SFT) 和强化学习(RLVR) 两阶段,结合模型融合(Souping)进一步提升性能:
1. 阶段1:sft
让模型掌握基础的文档解析能力(文本提取、公式识别、表格结构感知),为后续RL优化打基础。选择Qwen2.5-VL-7B-Instruct,使用改进后的监督数据集 olmOCR-mix-1025(267962页,来自10万+PDF),相比旧版(olmOCR-mix-0225)的改进:
- 用GPT-4.1替代GPT-4o处理数据,减少幻觉;
- 统一公式格式(块级公式用
\[,行内公式用\(); - 表格用HTML格式存储(而非纯文本);
- 为图像添加基础alt文本;
2. 阶段2:强化学习(RLVR)
核心是用合成数据的单元测试作为奖励信号,通过GRPO算法优化模型,解决SFT阶段未覆盖的复杂场景(如多列、公式、表格)。
- 训练数据:olmOCR2-synthmix-1025的合成文档(带单元测试);
- 采样策略:每个文档生成28个不同的模型输出(completions),确保覆盖足够多的候选结果;
奖励函数设计

奖励总分为三部分,取值均为0~1,确保模型同时优化"内容正确性"和"输出格式合规性":
| 奖励类型 | 计算方式 | 作用 |
|---|---|---|
| 主奖励:单元测试通过率 | (通过的单元测试数量)/(总单元测试数量) | 核心:优化内容正确性(公式、表格等) |
| 辅助奖励1:EOS token | 若输出以EOS(结束符)结尾则为1,否则为0 | 避免模型无限重复(解决"重复循环") |
| 辅助奖励2:元数据位置 | 若文档元数据(语言、旋转校正系数)在输出顶部则为1,否则按位置递减 | 确保输出结构规范,便于下游处理 |
3. 阶段3:模型融合(Souping)
为避免单一模型的随机性,文章采用模型权重平均(Souping) 策略:训练6个不同随机种子的RL模型(3个用token级重要性采样,3个用序列级重要性采样);对6个模型的权重进行平均,得到最终的olmOCR-2-7B-1025模型;
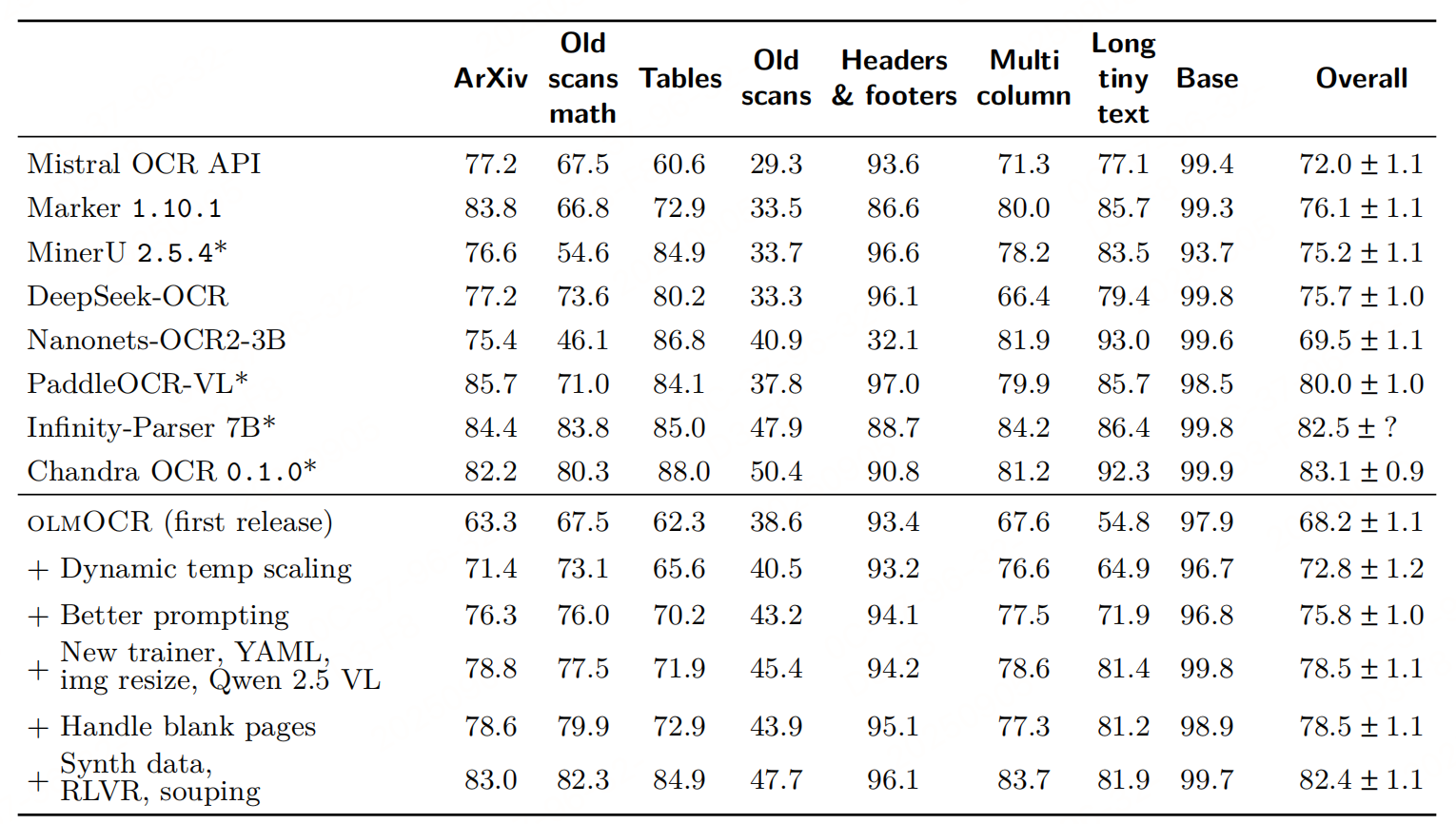
实验性能
参考文献:
olmOCR 2 Unit Test Rewards for Document OCR,https://arxiv.org/pdf/2510.19817v1