论文题目:Masked Point-Entity Contrast for Open-Vocabulary 3D Scene Understanding(开放词汇3D场景理解的掩蔽点-实体对比)
会议:CVPR2025
摘要:开放词汇的3D场景理解对于增强物理智能至关重要,因为它使具体代理能够在现实世界环境中动态解释和交互。本文介绍了一种新的用于开放词汇3D语义分割的掩蔽点-实体对比学习方法MPEC,该方法利用了不同点云视图之间的3D实体-语言对齐和点-实体一致性来培养实体特定的特征表示。MPEC改进了语义区分,增强了独特实例的区分,在ScanNet上实现了最先进的开放词汇3D语义分割结果,并展示了卓越的零样本学习场景理解能力。在8个数据集上进行了广泛的微调实验,从低级感知到高级推理任务,展示了学习3D特征的潜力,推动了不同3D场景理解任务的一致性能提升。
项目地址:https://mpec-3d.github.io
深度解读MPEC - 开放词汇3D场景理解的新突破
引言
在人工智能快速发展的今天,让机器像人类一样理解3D世界变得越来越重要。想象一下,一个家庭服务机器人需要理解"把桌子左边的那个红色杯子拿给我"这样的指令------它不仅要识别"杯子"这个类别,还要理解空间关系和视觉属性。这就是开放词汇3D场景理解要解决的问题。
今天要介绍的MPEC(Masked Point-Entity Contrast)是来自BIGAI(通用人工智能研究院)团队在CVPR 2025上发表的一项突破性工作,它在这个领域取得了多项最佳性能。
什么是开放词汇3D场景理解?
传统的3D场景理解模型只能识别训练时见过的固定类别(比如"椅子"、"桌子")。而开放词汇意味着模型能够理解任意的文本描述,包括:
- 新的物体类别("植物"、"毛巾")
- 详细的空间描述("圆桌旁边的台灯")
- 复杂的属性组合("左边第一个毛巾")
这对于构建真正智能的具身AI系统至关重要。
现有方法的问题
问题1:过度依赖2D模型
目前主流方法的做法是:
- 使用强大的2D视觉-语言模型(如CLIP)
- 将多个2D图像的特征投影到3D空间
- 希望这样能学到好的3D表示
但这存在根本性缺陷:
- 📷 单个图像视野有限,看不到完整的3D空间关系
- 🔄 多个视图之间的语义一致性难以保证
- 🎯 缺乏真正的3D几何和空间理解
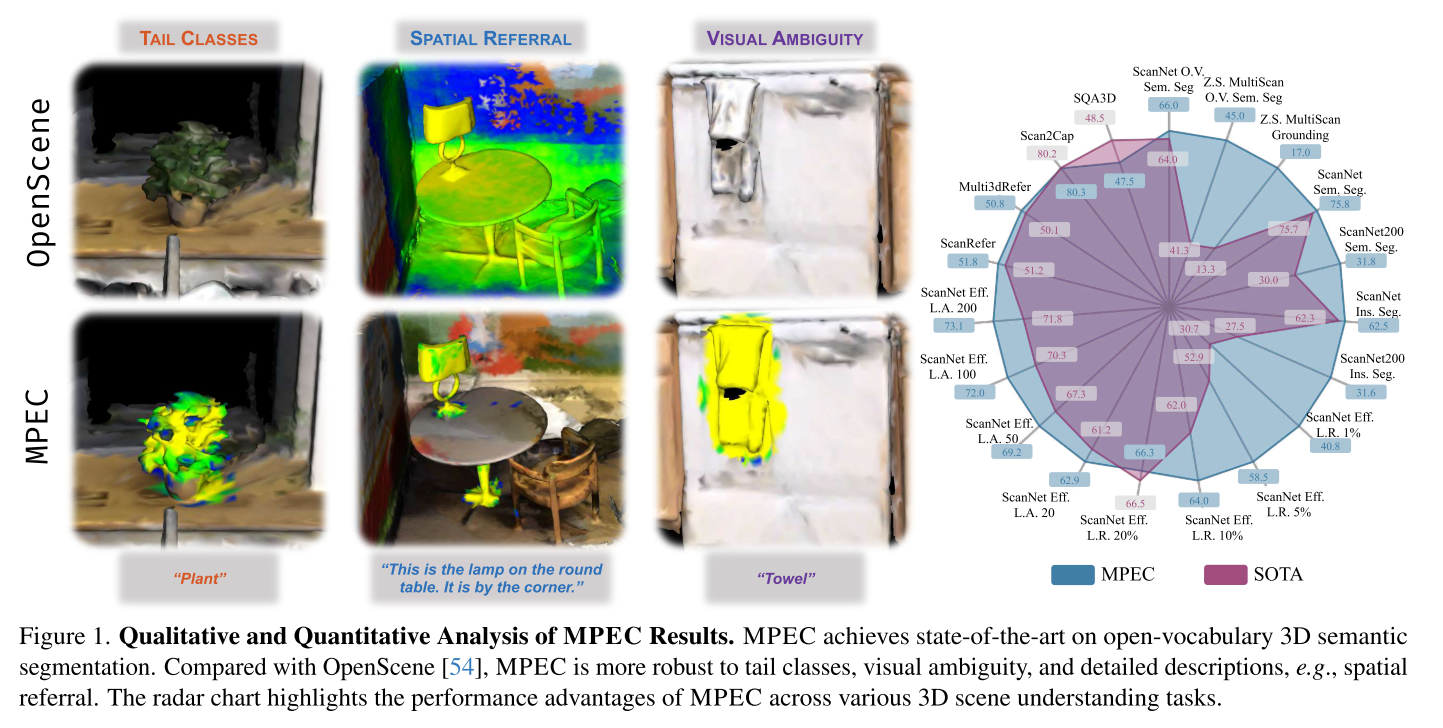
论文中举了一个很好的例子:OpenScene在识别颜色相似的物体时会出现混淆,因为它主要依赖2D视觉特征,缺乏3D空间上下文。
问题2:实例区分能力不足
人类在理解场景时,会自然地将其分解为一个个物体实例。但现有方法往往:
- 在处理尾部类别(罕见物体)时表现不佳
- 面对视觉歧义(相似外观)时容易混淆
- 无法处理空间引用("角落里的那个")
MPEC的创新解决方案
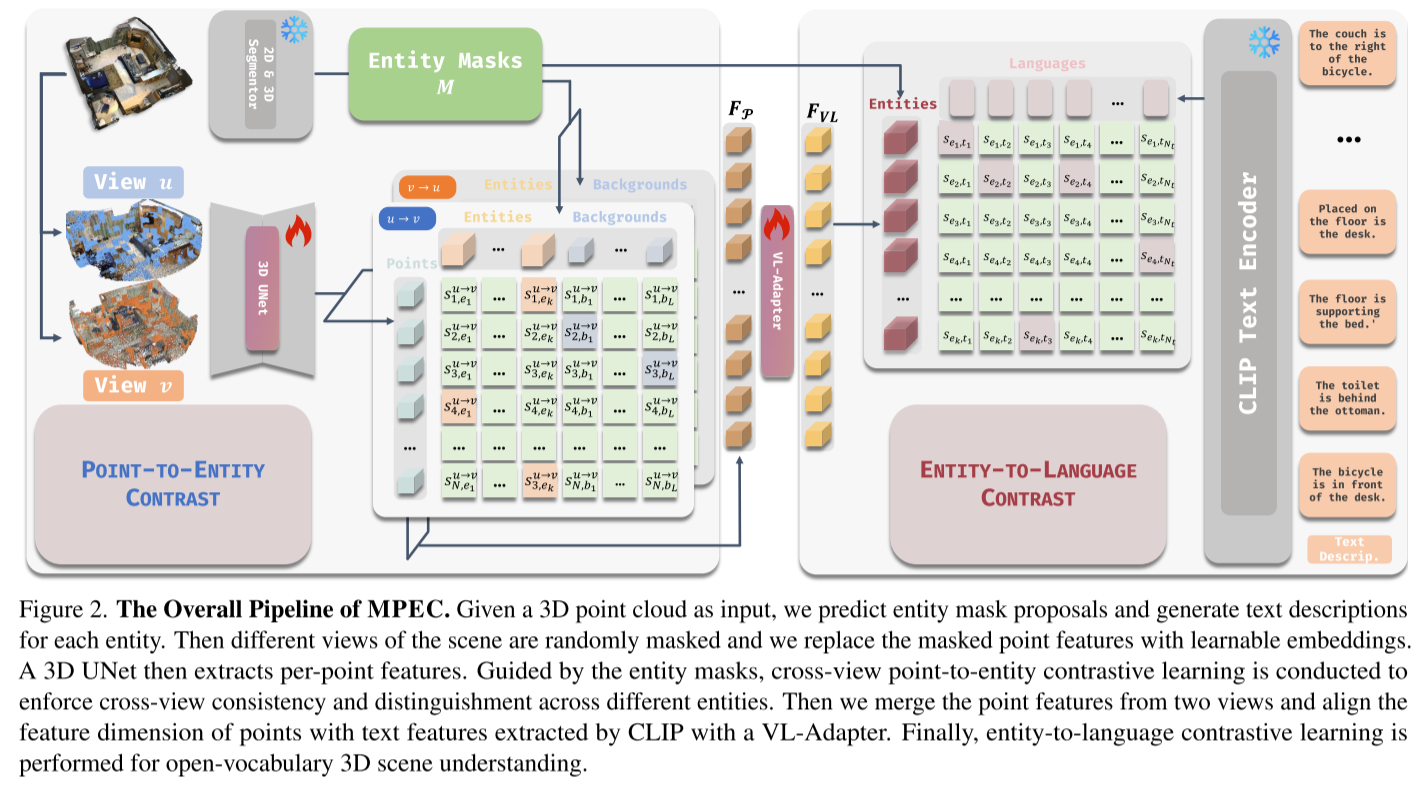
MPEC提出了一个优雅的双层对比学习框架,巧妙地将3D几何信息和语言理解结合起来。
核心创新1:点到实体对比学习
基本思路: 让模型学会在不同视角下一致地理解同一个物体。
具体做法:
-
生成多视图:对同一个3D场景生成两个不同的增强视图
-
实体级对比:
- ✅ 同一物体在不同视图中的点应该相似
- ❌ 不同物体的点应该有区别
- 🎭 背景点也参与对比
-
关键技巧 - 跨视图掩码:
- 随机遮挡一些区域
- 用可学习的掩码令牌替换
- 为什么重要? 避免模型过度强调物体的独特性,保留物体间的共同属性(如语义类别)
这就像教孩子认识物体:让他从不同角度观察同一个杯子,理解虽然角度不同,但它们都是"杯子"。
核心创新2:实体到语言对比学习
有了好的3D表示后,下一步是将它与语言对齐。
两种文本类型:
- 描述性文本:"这是一个棕色的木质衣柜"
- 引用性文本:"衣柜在床的左边"
双向对比:
- 文本→实体:给定文本,找到对应的3D实体
- 实体→文本:给定3D实体,找到所有相关描述
巧妙设计: 实体到文本使用二元交叉熵损失,因为一个物体可以有多个描述方式。
整体架构
3D点云 → [跨视图增强] → 3D编码器(SPUNet)
↓
[点到实体对比]
↓
[特征合并] → VL适配器
↓
文本描述 → CLIP文本编码器 → [实体到语言对比]实验结果:全面领先
1. 开放词汇语义分割(主要任务)
在ScanNet基准测试上:

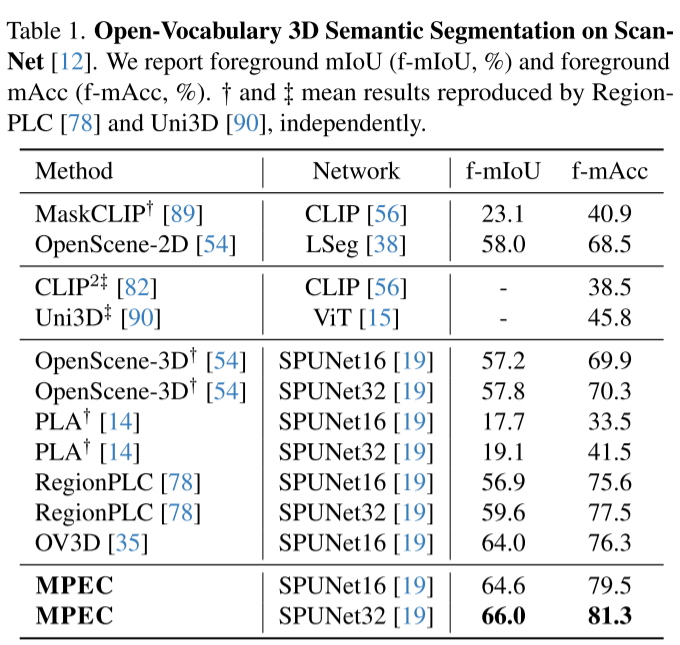
- 前景mIoU:66.0%(之前最好是64.0%)
- 前景mAcc:81.3%(之前最好是76.3%)
提升幅度显著:
- 相比OpenScene提升约10%
- 在长尾数据集ScanNet200上提升更明显(mAcc提升10%)
2. 零样本迁移:强大的泛化能力
在训练时从未见过的数据集上测试:
MultiScan场景:
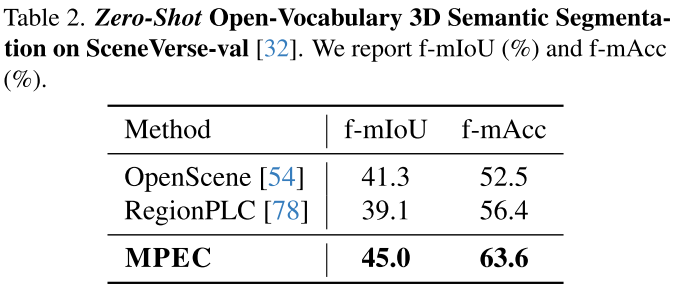
- mIoU:45.0%(OpenScene:41.3%)
- mAcc:63.6%(RegionPLC:56.4%)
Matterport3D:
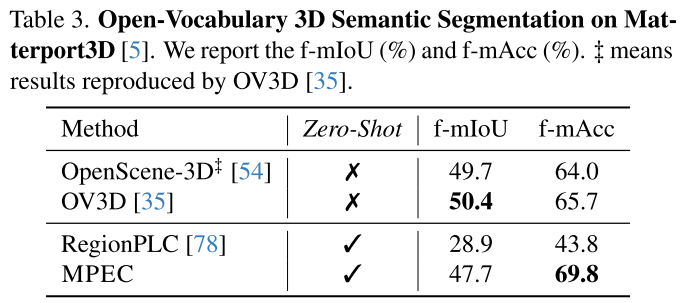
- 尽管训练时完全没用这个数据集
- 性能仍能媲美专门用该数据集训练的方法
- mAcc甚至超过4.1%!
3. 数据效率:少量数据就能学得好
这是最令人印象深刻的结果之一:
ScanNet Data Efficient Benchmark:
- 仅用1%的训练数据
- mIoU从30.7%提升到40.8%
- 提升幅度达33%!
这说明MPEC学到的表示更加本质和可迁移。
4. 下游任务:全面开花
MPEC不仅在语义分割上表现出色,在多个3D理解任务上都取得了提升:
低层感知任务:

- 实例分割(ScanNet200):mAP@0.5提升至31.6%
- 语义分割(ScanNet):mIoU达75.8%
高层推理任务:
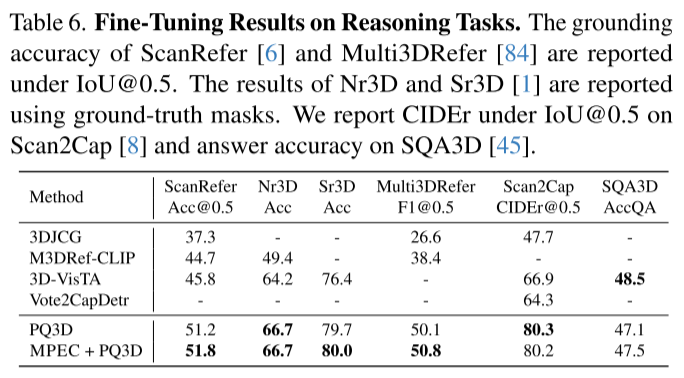
- 视觉定位(ScanRefer):准确率51.8%
- 3D问答(SQA3D):准确率47.5%
- 场景描述(Scan2Cap):CIDEr@0.5达80.2%
消融研究:每个设计都有用
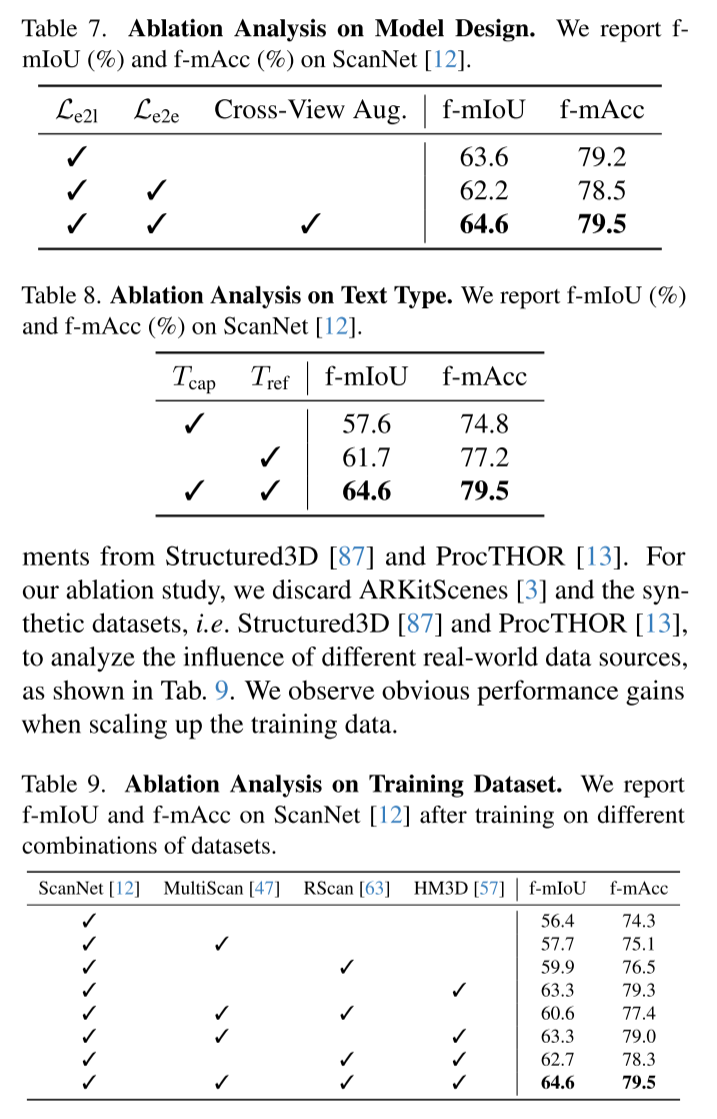
论文进行了详细的消融实验,验证了设计的有效性:
1. 跨视图增强的必要性
| 配置 | f-mIoU | f-mAcc |
|---|---|---|
| 仅实体到语言对比 | 63.6 | 79.2 |
| + 点到实体对比(无跨视图) | 62.2 ⬇️ | 78.5 ⬇️ |
| + 跨视图增强 | 64.6 ✅ | 79.5 ✅ |
关键发现: 如果没有跨视图增强,直接加入点到实体对比反而会降低性能!这验证了前面提到的设计动机。
2. 文本类型的重要性
| 文本类型 | f-mIoU | f-mAcc |
|---|---|---|
| 仅描述性 | 57.6 | 74.8 |
| 仅引用性 | 61.7 | 77.2 |
| 两者结合 | 64.6 | 79.5 |
启示: 物体的固有属性和空间关系都很重要,缺一不可。
3. 数据规模的影响
随着训练数据从单一数据集扩展到多个数据集,性能持续提升:
- 仅ScanNet:56.4% mIoU
-
- MultiScan:57.7%
-
- RScan:59.9%
-
- HM3D:64.6% ✅
技术亮点与启示
1. 实体中心的设计哲学
MPEC的核心洞察是:在3D场景中,物体实体是理解的基本单元。
传统方法要么:
- 在点级别操作(太细粒度)
- 在场景级别操作(太粗粒度)
而MPEC选择了实体级别,这恰好是人类理解场景的方式。
2. 巧妙的对比学习设计
跨视图掩码增强是一个精妙的设计:
- ✅ 鼓励跨视图一致性
- ✅ 避免过度强调实体唯一性
- ✅ 保留语义共性
这体现了对问题本质的深刻理解。
3. 模块化和可扩展性
MPEC的设计非常模块化:
- 可以替换不同的3D编码器(SPUNet16/32)
- 可以使用不同的文本编码器
- 易于扩展到新的下游任务
局限性与未来方向
论文也诚实地讨论了一些局限:
当前挑战
- 复杂空间推理:在处理非常复杂的空间描述时仍有困难
- 文本编码器限制:CLIP对长文本和详细描述的理解有限
- 计算效率:跨视图对比需要额外的计算开销
未来方向
- 更强的文本编码器:集成专门处理3D空间关系的语言模型
- 端到端训练:探索联合优化文本编码器和3D编码器
- 更大规模的数据:论文强调3D视觉-语言数据的规模仍然是瓶颈
对领域的影响
MPEC的工作具有重要的理论和实践意义:
理论贡献
- 提出了实体级3D场景表示学习的新范式
- 揭示了跨视图一致性和实体区分性的平衡
- 为开放词汇3D理解提供了新的解决思路
实践价值
- 在多个基准测试上刷新SOTA
- 展现出色的零样本泛化能力
- 可作为多种下游任务的通用骨干网络
对具身AI的启示
- 为机器人提供更好的场景理解能力
- 支持更复杂的人机交互指令
- 推动真实世界应用的落地
实现细节
对于想要复现或使用这项工作的研究者:
训练配置
- 3D编码器:SPUNet(支持16和32层版本)
- 文本编码器:CLIP(冻结参数)
- VL适配器:两层MLP
- 优化策略:仅更新3D编码器和VL适配器
数据准备
- 使用SceneVerse数据管道
- 包含多个真实场景数据集(ScanNet、3RScan、HM3D、MultiScan)
- 自动生成描述性和引用性文本
推理流程
- 输入3D点云
- 通过3D编码器提取特征(无需跨视图增强)
- VL适配器映射到语言空间
- 与CLIP文本特征计算相似度
- 输出语义标签或定位结果
结语
MPEC代表了开放词汇3D场景理解领域的重要进展。它通过巧妙的双层对比学习框架,成功地将3D几何理解和语言对齐结合起来,在多个任务上取得了显著的性能提升。
核心takeaways:
- 🎯 实体是3D场景理解的关键抽象层次
- 🔄 跨视图对比帮助学习一致的3D表示
- 📝 结合描述性和引用性文本至关重要
- 🚀 良好的预训练带来强大的迁移能力
对于从事具身AI、机器人视觉或3D理解的研究者,MPEC提供了一个强大而优雅的解决方案。其模块化设计和优异性能使其成为未来研究的重要基线和起点。