文章目录
-
- [一、为什么现代 LLM 使用 Decoder-only](#一、为什么现代 LLM 使用 Decoder-only)
-
- [1.1 核心思想](#1.1 核心思想)
- [1.2 关键原因](#1.2 关键原因)
- 二、梯度下降(核心公式与要点)
-
- [2.1 核心公式](#2.1 核心公式)
- [2.2 关键要素](#2.2 关键要素)
- [2.3 为什么不是越快越好?](#2.3 为什么不是越快越好?)
- 三、神经网络架构基础
- 四、其他重要网络架构
- [五、Transformer 层传递详解(含 PyTorch 代码)](#五、Transformer 层传递详解(含 PyTorch 代码))
- [六、文字到 Token 的转换](#六、文字到 Token 的转换)
- 七、大模型权重文件内容与格式
- 八、权重加载后的逐层推理流程
- 九、残差连接的作用与实现
-
- [9.1 核心思想](#9.1 核心思想)
- [9.2 为什么有效?](#9.2 为什么有效?)
- 十、层归一化(LayerNorm)解析
- 十一、激活函数概览
- [十二、Transformer 层的本质与规模估算](#十二、Transformer 层的本质与规模估算)
-
- [12.1 正确认知](#12.1 正确认知)
- [12.2 典型层数](#12.2 典型层数)
- 十三、总结与哲学思考
一、为什么现代 LLM 使用 Decoder-only
1.1 核心思想
现代大语言模型(如 GPT、DeepSeek)多采用 Decoder-only 架构,因为预训练阶段将"编码"与"解码"能力统一到同一架构中。
1.2 关键原因
- 任务匹配:核心任务是自回归生成(预测下一个 token),这正是解码器擅长的。
- 能力内化:通过"预测下一个词"的预训练,decoder 的自注意力已能为输入前缀生成深层语义表示。
- 规模效应:足够的参数与数据让单一架构同时掌握理解与生成。
- 架构简化:统一架构更易于大规模扩展与训练。
对比:原始 Transformer(Encoder--Decoder,常用于翻译) vs Decoder-only(边读边写,即时编码)。
二、梯度下降(核心公式与要点)
2.1 核心公式
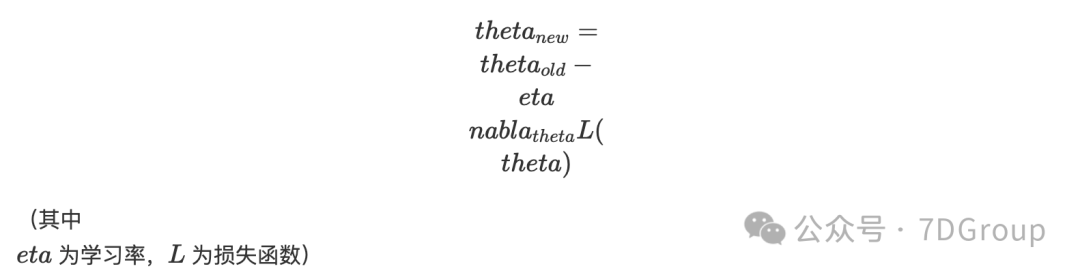
t h e t a n e w = t h e t a o l d − e t a n a b l a t h e t a L ( t h e t a ) thetanew=thetaold−etanablathetaL(theta) thetanew=thetaold−etanablathetaL(theta)
2.2 关键要素
- 梯度:指向损失上升最快方向,反向为下降方向。
- 学习率:步长大小,过大会发散,过小收敛缓慢。
- 损失函数:衡量模型错误程度。
2.3 为什么不是越快越好?
- 步长太大会发散或跳过最优点;
- 动态调整更好:初期可以用较大学习率,后期减小;
- 现代优化器(如 Adam)能为不同参数自适应学习率。
三、神经网络架构基础
- 前馈神经网络(FNN):信息单向流动,无循环连接,常用于分类与回归。
- 循环神经网络(RNN):专为序列设计,具备记忆,但容易出现梯度消失。LSTM/GRU 为常见改进
- 卷积神经网络(CNN):适用于网格数据(如图像),特点为局部连接与参数共享。
传播过程
- 前向传播:输入到输出的计算;
- 反向传播:基于链式法则计算梯度并更新参数。
四、其他重要网络架构
- Transformer:自注意力为核心,支持并行和长程依赖。
- 图神经网络(GNN):处理图结构数据,应用于社交网络、分子预测等。
- 生成对抗网络(GAN):生成器与判别器对抗训练,应用于图像生成。
- Diffusion 模型:前向加噪、反向去噪,当前图像生成 SOTA 方法之一。
五、Transformer 层传递详解(含 PyTorch 代码)
传递数据形状
- 张量本身:batch_size, seq_len, hidden_dim
- 注意力权重:batch_size, num_heads, seq_len, seq_len
PyTorch 示例(简化)
python
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model=512, n_heads=8, d_ff=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
x_norm = self.norm1(x)
attn_output = self.self_attn(x_norm, x_norm, x_norm, mask=mask)
x = x + self.dropout1(attn_output)
x_norm = self.norm2(x)
ff_output = self.feed_forward(x_norm)
x = x + self.dropout2(ff_output)
return x六、文字到 Token 的转换
分词策略
- 单词分词:按空格分割,词汇表大;
- 字符分词:每字符为 token,序列长;
- 子词分词(主流):BPE / WordPiece,兼顾效率与词汇覆盖。
转换流程
原始文本 → 分词 → T o k e n I D → 嵌入向量 → 位置编码 → 输入矩阵 原始文本 → 分词 → Token ID → 嵌入向量 → 位置编码 → 输入矩阵 原始文本→分词→TokenID→嵌入向量→位置编码→输入矩阵
代码示例
python
from transformers import AutoTokenizer
import torch.nn as nn
tokenizer = AutoTokenizer.from_pretrained("gpt2")
text = "Hello, world!"
tokens = tokenizer.tokenize(text)
token_ids = tokenizer.encode(text)
embedding = nn.Embedding(vocab_size, embedding_dim)
embeddings = embedding(torch.tensor(token_ids))七、大模型权重文件内容与格式
存储的关键参数
- 词嵌入层:vocab_size, hidden_size
- 每层 Transformer:Q/K/V/输出投影矩阵、前馈网络权重、归一化参数
- 输出层:hidden_size, vocab_size
常见文件格式
- PyTorch:.pt、.pth、.bin
- Hugging Face:.safetensors(更安全、更快)
- 量化格式:GGUF/GGML(体积更小,便于部署)
八、权重加载后的逐层推理流程
python
def forward(self, input_ids):
x = self.embedding(input_ids) + self.position_embedding(position_ids)
for layer in self.layers:
residual = x
x_norm = self.norm1(x)
attn_output = self.attention(x_norm)
x = residual + attn_output
residual = x
x_norm = self.norm2(x)
ff_output = self.ffn(x_norm)
x = residual + ff_output
logits = self.lm_head(self.final_norm(x))
return logitsKV 缓存优化(推理)
python
# 如果存在 past_key_values,则拼接以避免重复计算
if past_key_values is not None:
key = torch.cat([past_key, key], dim=2)
value = torch.cat([past_value, value], dim=2)九、残差连接的作用与实现
9.1 核心思想

输出 = 输入 + 变换 ( 输入 ) 输出 = 输入 + 变换(输入) 输出=输入+变换(输入)
9.2 为什么有效?
- 提供直接梯度通路,缓解梯度消失;
- 保持信息完整,在最坏情况下输出=输入;
- 网络只需学习"变化量",学习更高效。
Transformer 中的实现示例
python
x = x + self.dropout(self.self_attn(self.norm1(x)))
x = x + self.dropout(self.ffn(self.norm2(x)))十、层归一化(LayerNorm)解析
操作
对每个样本的每个特征维度,进行标准化。
作用
- 稳定层输入分布,帮助加速收敛;
- 允许使用较大学习率;
- 缓解训练中的梯度问题。
十一、激活函数概览
- ReLU:max(0,x),简单且减少梯度消失;
- GELU:平滑近似,Transformer 常用;
- Sigmoid / Tanh:用于概率或归一化输出;
- Swish/SiLU:x * sigmoid(x),部分模型(如 LLaMA)使用门控变体。
在实际模型中:BERT/GPT 多用 GELU,LLaMA 使用 SwiGLU 等门控激活。
十二、Transformer 层的本质与规模估算
12.1 正确认知
一个 Transformer 层不是单个神经元,而是一个复杂模块,包含:多头自注意力、前馈网络(两个全连接层+激活)、层归一化与残差连接。
示例:d_model=768 的层大约含有 ~7M 参数,等价于大量传统神经元的复杂度。
12.2 典型层数
- GPT-3(大规模):96 层;
- LLaMA-2 7B:约 32 层;
- BERT-base:12 层。
十三、总结与哲学思考
完整处理链条:
文本分词 → 向量化(嵌入) → 添加位置编码 → 多层 T r a n s f o r m e r 加工 → 概率输出 → 自回归生成。 文本分词 → 向量化(嵌入)→ 添加位置编码 → 多层 Transformer 加工 → 概率输出 → 自回归生成。 文本分词→向量化(嵌入)→添加位置编码→多层Transformer加工→概率输出→自回归生成。
核心设计理念:
- 注意力机制实现全局信息交互;
- 残差与层归一化保证深层网络稳定训练;
- 自回归机制负责语言生成。
哲学思考:
大语言模型将人类知识编码为高维参数,前向传播是将这些知识应用于新输入。每层相当于处理不同抽象层次的"微型大脑",层层堆叠形成复杂能力。