我们来彻底讲清楚 HTTP 和 HTTPS 的区别。我会用一个经典的比喻开始,然后深入技术细节,保证清晰易懂。
一、核心比喻:明信片 vs 挂号信
理解 HTTP 和 HTTPS 最直观的方式就是想象两种邮寄方式:
-
HTTP 就像寄明信片。
-
你写的内容(你的密码、银行信息、聊天记录)对任何一个经手它的邮递员、分拣员来说都一目了然。
-
别人可以轻易地偷看、甚至修改上面的内容,而你无从得知。
-
你只能相信邮政系统里的每个人都是好人。
-
-
HTTPS 就像寄封口的、带锁的挂号信。
-
加密(封口):信的内容被加密,只有指定的收件人有钥匙能打开阅读。
-
完整性(火漆封印):信件有一个特殊的封印(哈希校验)。如果中途被人拆开修改,收件人一看封印坏了就知道信被动过手脚。
-
身份认证(挂号回执):邮局会核实收件人的身份,确保这封信确实送到了你希望送达的那个人手里,而不是一个冒充者。
-
结论:HTTP 是明文传输,不安全;HTTPS 是加密传输,安全。
二、技术层面的区别
为了让这个"安全的挂号信"系统工作起来,HTTPS 在 HTTP 的基础上加入了三个核心的 security layer(安全层),它们统称为 SSL/TLS 协议。
| 特性 | HTTP | HTTPS |
|---|---|---|
| 协议 | 应用层协议 | HTTP + SSL/TLS 协议 |
| 默认端口 | 80 | 443 |
| 传输方式 | 明文传输 | 加密传输 |
| 安全性 | 无 | 极高。提供加密、身份验证和数据完整性 |
| SEO & 浏览器 | 现代浏览器标记为"不安全" | 搜索引擎(如Google)的排名因素,浏览器标记为"安全" |
| 性能 | 略快(无加密解密开销) | 略慢(有加密解密开销,但现代硬件下差异可忽略不计) |
| 需要证书 | 否 | 是。需要由受信任的证书颁发机构(CA)签发的数字证书 |
三、HTTPS 是如何工作的?------ SSL/TLS 握手详解
"挂号信"的寄送过程在技术上被称为 SSL/TLS 握手。这是一个在正式传输你的HTTP数据之前,客户端(浏览器)和服务器之间建立安全通道的过程。过程稍复杂,但理解后你会豁然开朗。
目标: 双方协商出一个只有他们俩知道的对称加密密钥(就像两人商量好同一把锁的钥匙),后续所有通信都用这把密钥来加密和解密。之所以用对称加密,是因为它比非对称加密快得多。
握手步骤简析:
-
Client Hello (客户端打招呼)
- 浏览器连接到服务器的 443 端口,说:"你好!我想建立一个安全连接。我支持这些加密套件(比如 AES, RSA),这是我的随机数A。"
-
Server Hello (服务器回应)
-
服务器回应:"你好!我选择我们都支持的
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384这个加密套件。这是我的数字证书(里面包含了我的公钥),还有我的随机数B。" -
数字证书的核心作用 :证明"我就是我所说的那个网站"。证书由全球信任的证书颁发机构签发,浏览器会验证证书的真伪和有效性。
-
-
验证证书与生成预主密钥
-
浏览器验证服务器的证书是否有效、是否过期、是否被信任。验证通过后,信任这台服务器的身份。
-
浏览器生成第三个随机数,叫 Pre-Master Secret。
-
浏览器用证书里提供的服务器公钥加密这个 Pre-Master Secret,然后发送给服务器。
-
-
生成会话密钥
-
只有服务器 有自己的私钥,所以只有它能解密得到 Pre-Master Secret。
-
现在,客户端和服务器都拥有了三个随机数:Client Random , Server Random , 和 Pre-Master Secret。
-
双方用相同的算法 ,根据这三个随机数,生成一模一样的会话密钥。这个密钥就是后续用来对称加密数据的"主钥匙"。
-
-
握手结束,安全通信开始
-
双方互相发送一条消息,说:"之后我们就用刚才商量好的密钥加密通信了,握手完毕!"
-
从此,所有的 HTTP 请求和响应数据都使用这把会话密钥进行加密和解密,在网络上传送的就是一堆无法直接阅读的密文。
-
这个过程的核心妙处在于:
-
用于加密实际数据的对称密钥 从未在网络上明文传输过。
-
用于传输对称密钥的非对称加密(公钥加密,私钥解密)非常安全,但只用在握手阶段,避免了其性能低下的缺点。
-
通过数字证书保证了客户端是在和真正的服务器通信,而不是一个中间人假冒的服务器。
四、为什么 HTTPS 如此重要?
-
隐私保护:防止你的密码、信用卡号、聊天记录、搜索历史等敏感信息被窃听。
-
数据完整性:防止传输的数据被运营商、黑客等中间人篡改(例如,在网页里插入广告或恶意代码)。
-
身份认证 :确保你访问的是真正的
www.mybank.com,而不是一个长得一模一样的钓鱼网站。这是通过验证服务器的 SSL 证书来实现的。 -
信任与合规:现代浏览器(Chrome, Firefox等)会将所有 HTTP 网站标记为"不安全",这会极大影响用户信任。此外,许多新的 Web API(如地理位置、Service Workers)都要求网站部署在 HTTPS 下。
-
SEO 提升:Google 等搜索引擎明确表示,HTTPS 是搜索排名的正面因素。
总结
| 方面 | HTTP | HTTPS |
|---|---|---|
| 本质 | 明信片 | 挂号信 |
| 安全 | 无 | 加密、身份验证、完整性 |
| 协议 | HTTP | HTTP over SSL/TLS |
| 端口 | 80 | 443 |
| 证书 | 不需要 | 必须由CA签发 |
| 网址显示 | http://... |
https://... 并有锁形标志 |
简单来说,HTTPS 就是穿着防弹衣的 HTTP 。在当今这个隐私和安全至关重要的时代,HTTPS 不再是"可选项",而是任何网站和网络服务的"标配"。你的 Door State Service 如果需要通过公网访问,必须使用 HTTPS 来防止车门被恶意控制。
这个问题通常的问法是:
"从你在浏览器地址栏输入一个URL(比如www.google.com)并按下回车,到最终看到页面,这中间发生了什么?"
下面我将为你提供一个极其详细且清晰易懂的解答。这个过程可以被分解为十几个关键步骤,我们一步一步来看。
终极详解:从 URL 到网页的魔法之旅
第 1 步:URL 解析
-
你做了什么 :输入
https://www.google.com/search?q=hello并按下回车。 -
浏览器做什么 :浏览器首先会解析你输入的字符串。
-
它需要判断你输入的是一个URL 还是一个要搜索的关键词。
-
它提取出协议(
https)、主机名(www.google.com)、端口(默认为443)、路径(/search)和查询参数(q=hello)。
-
第 2 步:检查缓存
-
在真正发起网络请求之前,浏览器会检查所有可能缓存数据的地方,按顺序检查:
-
Service Worker 缓存:如果网站注册了Service Worker,它可以拦截请求并返回缓存内容,实现强大的离线功能。
-
HTTP 缓存 :浏览器 disk cache 中根据请求的URL存储着之前服务器返回的响应。浏览器会根据缓存策略(如
Cache-Control,Expires,ETag等头部)决定是直接使用缓存,还是需要去服务器验证缓存是否新鲜。
-
第 3 步:DNS 域名解析
-
目标 :找到
www.google.com这个域名对应的IP 地址。因为网络世界不认识域名,只认IP地址。 -
过程(这是一个递归查询的过程):
-
浏览器检查自身的DNS缓存。
-
如果没有,检查操作系统的DNS缓存。
-
如果还没有,操作系统将查询发送到配置的本地DNS服务器(通常是你路由器或ISP提供的)。
-
本地DNS服务器先检查自己的缓存,如果没有,则从DNS根服务器 开始查询,再到
.com顶级域名服务器 ,最后到google.com权威域名服务器,最终拿到IP地址,并逐级缓存返回给浏览器。
-
第 4 步:建立 TCP 连接
-
目标 :浏览器拿到IP地址后,需要和服务器建立一条可靠的传输通道。这是通过 TCP 三次握手完成的。
-
SYN:浏览器向服务器发送一个SYN包(同步序列编号),表示请求建立连接。
-
SYN-ACK:服务器收到后,回复一个SYN/ACK包,表示同意建立连接。
-
ACK:浏览器再回复一个ACK包,表示确认。至此,连接建立成功。
-
-
这个过程保证了客户端和服务器都具备数据发送和接收的能力。
第 5 步:如果是 HTTPS,进行 TLS 握手
-
由于我们使用的是
https,在发送HTTP请求之前,必须先建立安全连接。 -
TLS 握手(简化版):
-
浏览器向服务器发送支持的加密算法列表和一个随机数。
-
服务器选择加密套件,并发送自己的数字证书(包含公钥)和另一个随机数。
-
浏览器验证证书的合法性(是否由可信机构颁发、域名是否匹配、是否过期)。
-
验证通过后,浏览器生成一个预主密钥 ,用服务器的公钥加密后发送给服务器。
-
服务器用自己的私钥解密得到预主密钥。
-
双方根据两个随机数和预主密钥,各自生成相同的会话密钥。
-
-
此后,所有的数据传输都将使用这个会话密钥进行对称加密。
第 6 步:发送 HTTP 请求
-
安全通道建立后,浏览器终于可以沿着这条安全的TCP连接发送HTTP请求了。
-
请求报文包括:
-
请求行 :
GET /search?q=hello HTTP/1.1 -
请求头 :
Host: www.google.com,User-Agent,Accept,Cookie(如果有该域下的cookie,浏览器会自动附带)等。 -
请求体 :对于
GET请求,通常没有请求体。如果是POST请求,则包含提交的数据。
-
第 7 步:服务器处理请求并返回响应
-
请求到达服务器:请求可能先经过负载均衡器,被分发到某台后台服务器。
-
服务器处理:Web服务器(如Nginx, Apache)接收请求,可能会将其转发给应用服务器(如Tomcat, Node.js)。应用服务器根据路径和参数执行相应的业务逻辑(查询数据库、处理计算等)。
-
生成响应 :服务器生成一个 HTTP 响应。
-
状态行 :
HTTP/1.1 200 OK -
响应头 :
Content-Type: text/html; charset=UTF-8,Set-Cookie,Cache-Control等。 -
响应体:通常是请求的HTML文档内容。
-
第 8 步:浏览器接收响应并解析
-
浏览器开始逐步接收服务器返回的数据。
-
关键过程:解析与渲染
-
构建 DOM 树 :浏览器解析HTML字节流,将其转换为令牌,最终构建成一棵DOM树 (文档对象模型)。如果遇到
<script>标签,会停止HTML解析,先去下载和执行JavaScript (除非标记了async或defer)。 -
构建 CSSOM 树 :解析CSS(包括外部CSS文件和样式元素),构建 CSSOM 树(CSS对象模型)。
-
合并成渲染树 :将DOM树和CSSOM树合并,排除非视觉元素(如
<head>),形成一棵渲染树,它只包含可见内容及其样式信息。 -
布局:计算渲染树中每个节点在屏幕上的确切位置和大小(又称"重排")。
-
绘制:将布局后的节点像素点绘制到屏幕上(又称"重绘")。
-
-
这个解析过程是渐进式的。服务器无需等待整个HTML文档生成完毕再发送,可以边生成边发送,浏览器也会逐步解析和渲染,以提高用户体验。
第 9 步:加载其他资源
-
HTML文档中通常包含大量其他资源,如图片、图标、CSS文件、JavaScript文件等。
-
浏览器会解析文档,发现这些资源(如
<img src="...">,<link rel="stylesheet" href="...">),并对每一个资源 重复步骤 3 到 8(当然,DNS、TCP、TLS过程通常会有缓存和连接复用,不会每次都这么慢)。 -
现代浏览器通常允许同时与同一个域名建立多个TCP连接(通常是6个左右),以并行下载资源,加快速度。
第 10 步:最终页面展示
- 当所有资源都加载完毕,并且JavaScript也执行完成后(触发了
DOMContentLoaded和load事件),一个完整的、交互式的页面就呈现在你面前了。
总结流程图
图表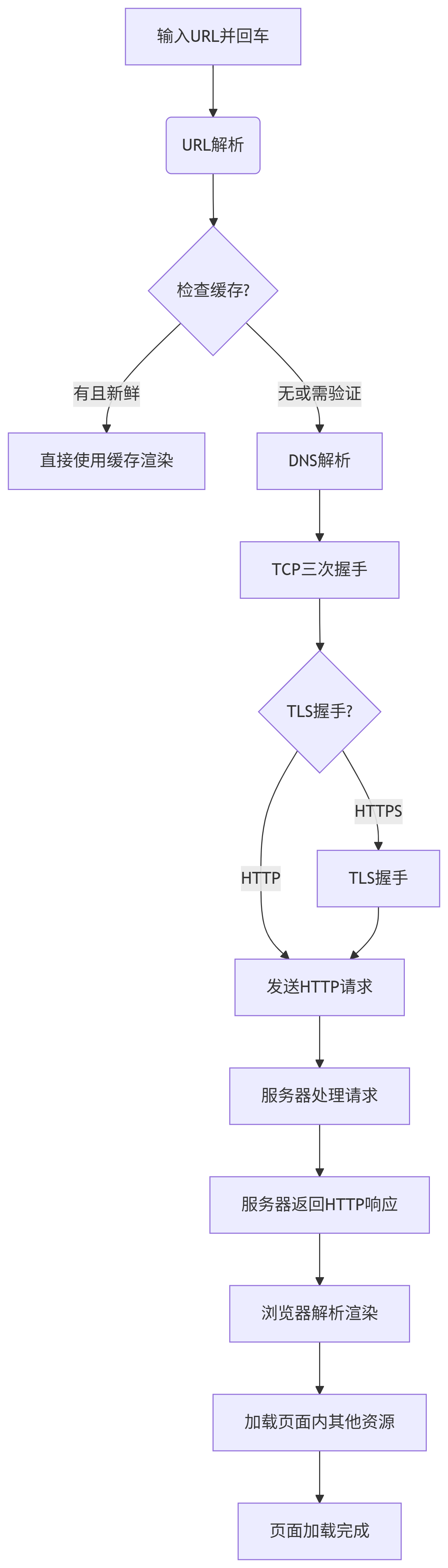
代码
这个过程涉及到了无数复杂的底层技术,但浏览器和现代Web标准让我们几乎无感知地完成了这一切,每秒都在全球上演数十亿次,这本身就是互联网工程的一个奇迹。希望这个详细的解答能帮助你彻底理解它!
URL 不是路由,但两者在Web开发中紧密相关。
我会用一个非常清晰的比喻和详细的解释来帮你彻底理解它们。
一、核心答案:URL ≠ 路由
-
URL :是一个地址 。它告诉你资源在哪里 ,以及如何访问它。它是浏览器(客户端)用来向服务器请求东西的标准格式。
-
路由 :是一套规则 或映射关系 。它是服务器端或前端框架内部的一个机制,用来决定当收到一个特定URL的请求时,应该执行哪段代码来处理它。
简单比喻:
想象一下你去一个巨大的图书馆(代表整个互联网或一台服务器)找一本书。
-
URL 就像是这本书的 索书号 ,比如
I247.5/A123。- 这个索书号有固定的格式,图书管理员能看懂。它明确指出了书在哪个区、哪个书架。
-
路由 就像是图书管理员 大脑里的记忆 或者他手边的 索引目录。
-
他看到索书号
I247.5/A123,他的"路由规则"告诉他:"哦,I247.5是中国现代小说区,第三个书架,我需要去那里找。" -
他看到索书号
K892/ B456,他的"路由规则"告诉他:"这是民俗文化区,第五个书架。"
-
所以,URL是对外 的、统一的地址格式,而路由是内部的、用于查找和分发的规则。
二、详解 URL - 资源的"身份证"和"地址"
URL 的全称是 U niform R esource L ocator(统一资源定位符)。它的唯一目的就是准确地定位互联网上的一个资源。这个资源可以是HTML页面、一张图片、一段视频、一个API接口数据等。
一个标准的URL由以下几个部分组成:
https://www.example.com:8080/articles/index.html?page=1&sort=date#comments
让我们把它拆解一下:
-
协议 :
https://- 规定了使用哪种协议来获取资源。最常见的是
http和https,也可以是ftp,mailto等。
- 规定了使用哪种协议来获取资源。最常见的是
-
主机名 :
www.example.com- 资源所在服务器的域名或IP地址。DNS系统会将它解析成服务器的IP地址。
-
端口 :
:8080- 服务器上正在"监听"请求的特定门牌号。HTTP默认端口是80,HTTPS是443,所以通常省略。如果服务器软件运行在其他端口(如8080),就必须明确指定。
-
路径 :
/articles/index.html-
这是与"路由"概念最容易混淆的部分!
-
它表示资源在服务器上的具体位置,通常对应着服务器上的文件路径或逻辑端点。
-
在上面的例子中,它可能对应服务器上
articles文件夹下的index.html文件。
-
-
查询字符串 :
?page=1&sort=date-
以
?开头,包含一组以&分隔的键值对。 -
用于向服务器传递额外的参数 。这些参数通常用于过滤、搜索、分页等(比如
?q=keyword表示搜索关键词)。
-
-
片段标识符 :
#comments-
以
#开头,也称为"锚点"。 -
它不会发送给服务器 ,而是由浏览器自己使用,用于定位到HTML文档中的某个特定位置(比如一个有着
id="comments"的章节)。
-
三、详解路由 - 服务器的"交通指挥员"
路由 是Web服务器或Web框架(如Express.js for Node, Django for Python, Spring MVC for Java)的一个核心功能。
它的工作流程如下:
-
服务器接收到一个HTTP请求(例如
GET /products/electronics)。 -
服务器的路由器 会检查这个请求的方法 (如GET, POST)和路径 (
/products/electronics)。 -
路由器根据一套预先定义好的规则表 (路由表),找到与这个 方法+路径 组合匹配的规则。
-
一旦匹配成功,路由器就会调用与该规则关联的函数 (通常称为控制器 或处理程序)来处理这个请求。
-
这个函数负责执行业务逻辑(比如从数据库查询所有电子产品),并生成返回给浏览器的响应(HTML页面或JSON数据)。
示例:一个简单的后端路由(以Node.js Express框架为例)
javascript
const express = require('express');
const app = express();
// 定义一条路由规则:
// - HTTP 方法: GET
// - 路径: '/products/electronics'
// - 处理函数: 后面的箭头函数
app.get('/products/electronics', (req, res) => {
// 1. 从数据库查询电子产品数据
const electronicProducts = ...;
// 2. 将数据渲染到HTML模板中
res.render('products', { products: electronicProducts });
});
// 另一条路由规则:处理登录请求
// - 方法: POST
// - 路径: '/login'
app.post('/login', (req, res) => {
// 1. 获取请求体中的用户名和密码
const { username, password } = req.body;
// 2. 验证用户信息
// ...
// 3. 返回验证结果
res.json({ success: true });
});前端路由
现代前端框架(如React, Vue, Angular)也有自己的"路由"概念。它的原理是:
-
监听URL中路径的变化(但不会向服务器发起新的页面请求)。
-
根据路径映射 到不同的前端组件并渲染它。
-
这创造了"单页面应用"的流畅体验。
-
例如:
https://myapp.com/#/dashboard和https://myapp.com/#/profile实际上访问的是同一个HTML文件,但前端路由会根据#后面的路径(/dashboard或/profile)来决定显示哪个组件。
四、总结与对比
为了让你看得更清楚,我把它们的区别和联系整理成了一个表格:
| 特性 | URL | 路由 |
|---|---|---|
| 本质 | 地址 、定位符 | 规则 、映射表 |
| 角色 | 客户端 发出的请求目标 | 服务器端 或框架内部 的分配机制 |
| 内容 | 包含协议、主机、端口、路径、查询参数等 | 包含HTTP方法 、路径模式 、处理函数 |
| 目的 | 唯一地标识和定位互联网上的资源 | 决定由哪段代码来处理接收到的请求 |
| 关系 | 路由的输入 :路由系统解析URL中的路径部分来做匹配 | URL的消费者:根据URL来执行相应的逻辑 |
它们是如何协同工作的?
-
你在浏览器输入一个 URL 并回车。
-
浏览器向该URL对应的服务器发送一个HTTP请求 ,请求中包含方法 和路径。
-
服务器上的路由系统接收到这个请求。
-
路由 根据请求的方法 和路径,查找匹配的规则。
-
找到后,调用对应的处理函数。
-
处理函数执行完毕,生成响应内容(如HTML),通过服务器返回给浏览器。
-
浏览器渲染响应内容,你就看到了网页。