【强化学习】第六章:无模型控制:在轨MC控制、在轨时序差分学习(Sarsa)、离轨学习(Q-learning)
说明:从强化学习知识框架上看,本篇承接无模型评估篇:https://blog.csdn.net/friday1203/article/details/156023792?spm=1001.2014.3001.5501
但是,从知识点上看,本篇是承接前五章的所有重点和难点!所以你前面知识点必须非常熟悉,本篇才能顺水推舟的理解了。尽管本篇我已经尽力回溯之前的知识点,但你还是得没有逻辑断点,才能看懂本篇。
一、梳理本章在强化学习中的位置
1、从第四篇的策略迭代 算法流程中,我们知道强化学习的基本框架 是:要先进行评估,评估完后再进行策略改进 。所以第五篇我们讲了无模型评估 (也叫预测 ),本篇开讲无模型控制 (也就是策略改进 、优化)。
也所以,本篇的在轨MC控制、在轨算法:Sarsa、离轨算法:Sarsa(λ)和Q-learning,这些算法的最终目标都是求最优策略 的。那现实生活中哪些问题会用到本篇的算法呢?比如:
2、本篇是DeepMind流派,或者说是强化学习鼻祖Rich Sutton和Andew Barto出版的 强化学习那本书里的理论部分的最后一讲。所以本篇学完以后,你就可以把这些理论框架应用到实践过程中了。
3、本篇之后我们开讲OpenAI流派,也就是深度强化学习。比如,DQN(深度Q网络,Deep Q-Network),就是将卷积神经网络(CNN)与Q-Learning相结合,用CNN来逼近Q函数。DQN就是2013年玩Atari游戏的那个算法。后面很多算法也是基于DQN的扩展。
二、在轨学习、离轨学习
上面的在轨离轨概念是鲁鹏老师课件中的截图。鲁鹏老师的解释是:
在轨:就是自己边打边学,通过自己打游戏,积攒经验提升自己的策略。
离轨:就是看别人打游戏,然后通过别人的经验来提升自己的策略。
其实,我个人认为,在轨 就是在策略Π下 ,打出一些序列s1,a1,r1,s2,a2,r2...,然后通过这些序列计算价值->贪婪化提升策略。意思就是序列s1,a1,r1,s2,a2,r2...是策略Π下的序列。通过学习序列s1,a1,r1,s2,a2,r2...得到的经验提升,叫在轨学习。而离轨 学习指,从不同的策略Π下的、序列s1,a1,r1,s2,a2,r2...,序列s1',a1',r1',s2',a2',r2'...,中学习,得到的经验提升,叫离轨学习。
因为在不同策略Π下,计算得到的"价值"是不同的,而我们的"策略"又是以"价值"为依据 的。也所以传统的强化学习范式 是:
获得策略Π下的序列-->计算价值(状态价值或者动作价值或者状态动作价值)-->依据价值贪婪化(或者ε-greedy,也就是利用和探索)提升策略-->得到最优策略,done!
所以在轨离轨指的就是我们学习的数据序列,是同一个Π,还是不同的Π,下的序列数据。所以学习不同Π下的序列数据,叫离轨学习。学习同一个Π下的序列数据,叫在轨学习。后面会不断出现这对儿概念,这里理解不了,后面再继续理解。
三、在轨蒙特卡罗控制(On-Policy Monte-Carlo Learning)
1、基于动作价值函数的无模型策略迭代:蒙特卡洛控制
这是一个通用的无模型策略控制方法,下面我先把相关内容整理出来,再逐一解释:
(1)有模型的场景,我们根据上图A来提升策略的,也就是DP算法。在DP算法中v和q直接是有概率连接的,我们通过v就可以求出q,有了q就可以更新策略了。但是现在是无模型场景,我们得不到状态转移矩阵了,所以我们得用B来提升策略。B是直接用动作价值函数,贪婪化的提升策略。
(2)那B处的动作价值函数怎么取得 ?假如我们用第五篇章学的MC学习方法,那就是上图C处,我们直接算的是(s,a)对儿的价值,也就是动作价值函数 的价值值。也所以上图的控制过程我们也叫蒙特卡罗控制。
(3)那B处的贪婪化提升策略,又是如何做的 ?此时B处就不能 再用单纯的贪婪提升策略了,得用ε-greedy策略 来提升。为什么?因为单纯的贪婪化是不行的,你不能就试了几次,就把这几次的经验当成永久不变的定律,环境变了,经验也得跟着变,所以在贪婪化利用的同时还得探索,也就是:ε-greedy算法。就是除了贪婪利用还得探索,ε-greedy算法就是利用与探索。其实特别好理解,不理解的同学参考老虎机问题: https://blog.csdn.net/friday1203/article/details/155787017?spm=1001.2014.3001.5501
(4)上图4处是数学证明,证明用ε-greedy算法获得的策略,比单纯用贪婪算法获得的策略更优。
(5)因为上图的策略迭代过程中的价值评估是用MC来做的,所以上图用的数据是一条条完整的幕,也就是数据是需要一条条完整的序列,而不是序列片段。也就是说如果你的数据不完整,那是没法用上述方法来做的。
同时从数据的另外一个角度说,上面的策略迭代是 在轨学习,不是 离轨学习。也就是数据来自同一个Π的,数据来自不同的Π,是离轨蒙特卡洛控制,而离轨MC控制是另外一种算法,离轨MC目前只是理论上有意义,实际中我们一般不用它,而且还涉及到重要性采样等操作。
2、GLIE的蒙特卡罗控制
上面小标题1的策略迭代流程也叫蒙特卡洛控制。虽然蒙特卡洛控制在迭代过程中,策略能收敛,但是这个收敛的策略是否是最优的策略呢?当系统的随机性非常大时,这个收敛的策略就不一定 是最优策略了。就是这个策略虽然是收敛的,但不一定是最优的 。那什么情况下才是收敛到最优策略 呢?如下左图所示,要满足GLIE条件 的MC控制,收敛后的策略才是最优策略 :
(1)什么是GLIE条件?
A处表示所有的(s,a)对儿要被探索无数次;B处表示在被探索了无数次后得到的策略趋同于贪婪策略。
条件A+条件B,叫GLIE条件。满足GLIE条件的MC控制是一定可以收敛到最优策略的。
(2)从前面的知识点我们可以知道:ε-greedy的利用和探索,得到的策略,比单纯用贪婪算法获得的策略更优。但是你如果想找到最优的策略,一是,你得满足GLIE条件。二是,你用ε-greedy算法迭代策略时,ε的设置就不能 再是一个一成不变的超参数了 ,ε得随着探索次数逐步递减,如上图E处的例子,ε=1/k,表示ε随着探索次数k的增加而减小。这样的策略迭代过程叫GLIE的蒙特卡洛控制,具体迭代过程就是上图的C处。策略收敛到最优策略的过程就是上图D处。
其实,GLIE的蒙特卡洛控制也不难理解。你想,ε-greedy算法中的ε是等于一个固定值的超参数,也就是每次打游戏时,agent都以固定的ε概率来探索和利用。当游戏中的(s,a)对儿都已经被探索了无数次了,此时就已经非常清楚(s,a)对儿中什么动作是最优的,那我们干嘛还要继续以概率ε来探索呢,探索就意味着可能好也可能坏,当我们已经知道如何action就是好的,那就往好的action上做才能获取最多的奖励,为什么还要以牺牲奖励为代价去冒险探索呢?!所以随着k趋向无穷大,最优的策略就是逐渐减少探索 。所以ε要随着k增加而逐渐减少,才能获取最多的奖励,此时对应的策略就是最优策略。
(3)小结:GLIE的蒙特卡罗控制就是:
一是,动作价值函数的计算使用MC学习 方法。也就是计算(s,a)对儿的价值时,用MC方法来计算。
二是,在用ε-greedy算法进行策略迭代时,把ε设置成一个自适应的动态参数 。类似梯度下降优化算法中的学习率的设置是一个道理。说着说如果ε设置的是一个固定值,策略也是可以收敛的,但是一般是不会 收敛到最优策略。如果ε被设置的是一个逐渐变小的更新值,策略是可以收敛到最优策略的。
下面我们要学Sarsa,Sarsa中的ε是不进行更新的。这里的ε是要更新的。这是最大的区别。
三是,蒙特卡洛学习分在轨和离轨两种,这里讲的是在轨蒙特卡洛 。离轨蒙特卡洛是另外一种版本,只有理论意义实际中基本不用。
四、在轨策略时序差分学习(On-Policy Temporal-Difference Learning):Sarsa
1、Sarsa简介
(1)要理解Sarsa,你先要理解贝尔曼期望方程、贝尔曼最优方程-->然后理解DP(DP是解决完备的MDP问题的)-->从DP去理解TD(TD就是DP的思想来解决非完备MDP问题的,也就是解决无模型强化学习问题的,其底层和DP一样都是贝尔曼期望方程)-->然后从TD的逻辑再来理解Sarsa,你就会发现DP-TD-Sarsa,它们是一脉相承的一族算法,其最底层都是贝尔曼方程。
(2)在轨策略时序差分学习 和MC控制 一样,第一步都是求动作价值函数 ,时序差分控制也是第一步求动作价值函数,只不过求动作价值函数用的是TD学习方法,而MC控制用的是MC学习方法。
(3)MC控制 适用于完整的回合制数据场景。如果数据不完整,比如游戏没有终止状态的场景,那就得用时序差分学习了。所以DP-TD-Sarsa都适用于没有终止情况的博弈。
2、使用Sarsa更新动作价值函数 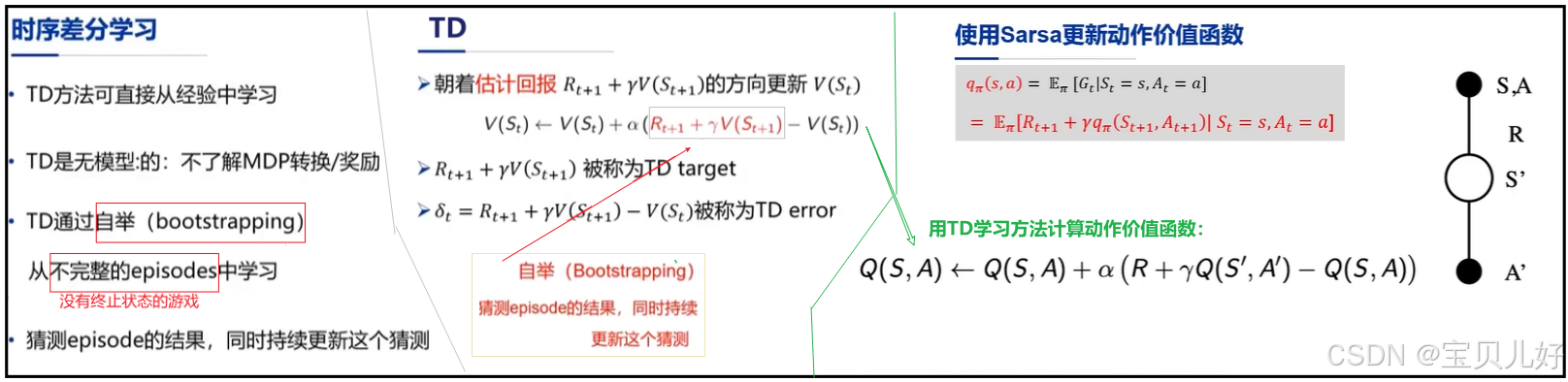
(1)Sarsa方法其实就是TD方法,上图绿线左边是第五章讲的TD,绿线右边是本部分要讲的Sarsa。之所以叫Sarsa是因为和TD一样,都是利用s,a,r,s,a,r....序列片段就可以计算了。所以sarsa就是序列片段的意思。
(2)右边只不过是把计算价值函数(TD)变成计算动作价值函数(Sarsa)而已,二者计算方法一模一样!具体过程是:
a. 先初始化一组价值,比如初始化Q(s,a)=0。
b. 当一个序列片段s1,a1,r1,s2,a2,r2,,,打完后,通过这个序列片段写出新Q(s,a)的更新式。
c. 利用Q(s,a)=0,更新Q(s,a),Q(s,a)->Q(s',a')
d. 用Q(s',a')和Q(s,a)之间的差分,更新动作价值值,直到Q收敛。
e. Q收敛后,就开始策略提升。策略提升用ε-greedy算法即可。
这个过程中最典型的特点就是自举。DP-TD-Sarsa的迭代过程都是自举的过程。
3、Sarsa算法的伪代码 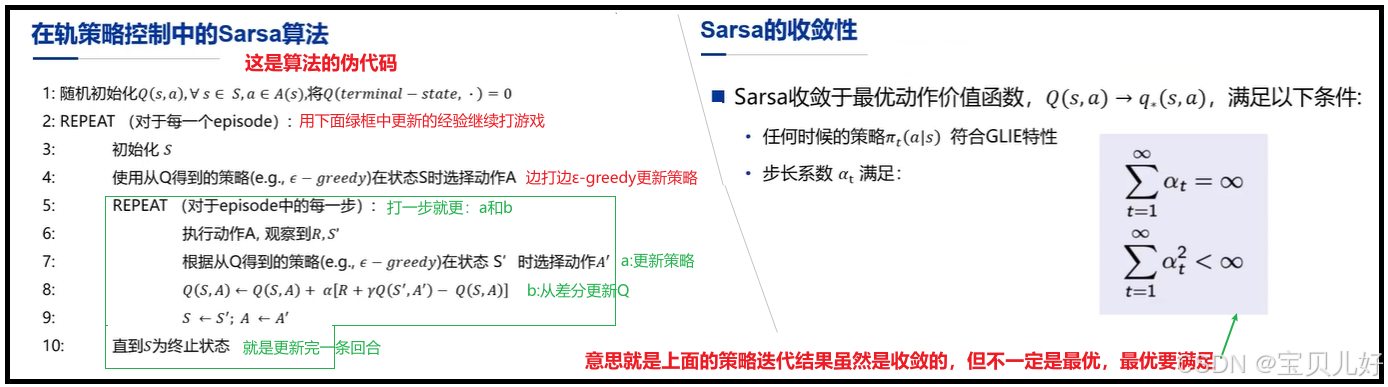
(1)上面迭代过程中用的是ε-greedy,这里的ε是一个固定超参,是不变的。这是有别于MC控制的。
(2)Sarsa是边打边算Q(s,a)、边ε-greedy地提升策略的。假如初始化Q(s0,a0)=0,agent打了一步游戏-->产生一个(s1,a1),s',r序列片段-->此时就用这个片段中的r更新了Q(s1,a1),同时策略Π也更新成:P(a=a1|s1)=1-ε、P(a=其他动作|s1)=1-ε。然后根据新策略,继续打下一步游戏,打完下一步,同理更新Q\Π-->在更新了的Q\Π下,继续打下下步,如此循环直到策略收敛。
(3)Sarsa最后得到的收敛的策略,一般不是最优策略 。因为Sarsa一般都是用于没有终止的游戏,或者说用于比较复杂的游戏,所以Sarsa除了利用 ,得用一个固定的ε来探索 。正是因为这个ε概率的探索,导致Sarsa最后得到的收敛的策略一般不会是最优策略,一般是一个局部的最优 策略,全局上看不一定是最优的。
五、离轨学习(Off-Policy Learning)之 :Sarsa(λ)
前面的MC控制和Sarsa都是在轨学习。这里开讲离轨学习,也是本篇的重点。本部分如果你看不懂,先请深入理解一下老虎机问题中的利用和探索:https://blog.csdn.net/friday1203/article/details/155787017?spm=1001.2014.3001.5501
1、离轨学习 
其实本篇一开始就讲过在轨学习和离轨学习,这对儿概念乍一看,很多人都会很懵。现在我们已经有了更多的基础,再来理解一遍这对儿概念。
(1)在轨学习 是在同一个策略Π下,实际打出一系列s,a,r,序列,然后从这些序列中学习和提升策略,逐渐从小白变高手。
(2)离轨学习 是从别人 打的序列s,a,r中学习和提升自己的策略。就是别人打的s,a,r序列是人家自己的策略下打的序列,我们要从别人的经验中学习和提升自己,从而变成高手,这就是离轨学习。Q-learning是离轨学习的典型算法之一。
(3)目标策略、行为策略
离轨学习中的策略分:目标策略和行为策略
你可以把目标策略理解为agent 贪婪化利用 得到的策略。行为策略看成是探索得到的策略。
既然目标策略是"agent贪婪化利用得到的策略",那目标策略肯定是agent根据自己的策略、打出来的游戏序列、从中找到的最优策略,也叫agent自己学习的经验。
既然行为策略是"探索得到的策略",那行为策略就可以是 agent自己经验,也可以是别人的经验。
这么一转弯,事情就升华了。那岂不是agent可以不用 自己打游戏、总结经验,从小白变高手;而是 可以从别人打的游戏序列 中,学习经验,从小白变高手!对!这就是离轨学习的强大之处!比如我们要训练一个打游戏机器人,不一定非得要亲自打很多次游戏,得到游戏数据,然后总结经验,从小白变高手。而是我们可以直接拿来别人打的游戏数据,把这个数据当作是我们自己的"探索"的数据,从中学习策略,从而也达到高手的效果。
2、Sarsa(λ)原理
Sarsa(λ)可以类比TD(λ):https://blog.csdn.net/friday1203/article/details/156023792?spm=1001.2014.3001.5501
Sarsa(λ)也叫Sarsa算法的λ版本。
Sarsa(λ)和Sarsa算法的流程是一样的,只是计算Gt时用的时TD(λ)方法,其他都一样。
所以这里就不展开讲了,大家可以拼接拼接前面的相关知识点自己探索。这里只是为了知识框架的完整性,点到为止。
六、离轨学习(Off-Policy Learning)之 :Q学习(Q-learning)
1、Q-learning算法原理
Q-learning是离轨学习的典型算法之一。当年谷歌的DQN算法的渊源就是Q-learning算法。DQN是Deep Q-Network,是将Q-Learning和卷积神经网络(CNN)相结合的算法。DQN是当年玩Atari游戏超越人类而火出圈的那个算法,也是离轨学习算法。
下面我们详细看看Q-learning算法:
(1)A处:Q学习指的是算法是如何计算价值的。
一是,Q-learning算法计算的是动作价值函数 ,不是状态价值。就是说Q-learning算法也是用于无模型场景的,不知道状态转移矩阵的场景,所以Q-learning计算的也是(s,a)对儿。
二是,Q学习计算动作价值函数时,也是通过迭代完成的,上图A处是迭代过程。从A处可见,Q学习是用差分 迭代的。从这个角度看,Q学习和TD、Sarsa的迭代方式是一样的。
三是,A处的红色部分,也就是Gt的计算方法。从这部分看,Q学习计算Gt和DP、TD、Sarsa的方式也是一样的。
(2)B处、C处、D处、E处:这是Q学习的离轨控制 方法。
离轨控制就是策略控制,也叫策略迭代,也叫策略提升,也是小白变高手的过程。
DP的策略控制仅仅需要贪婪化提升即可。
TD控制其实就是Sarsa算法。 Sarsa算法是以1-ε的概率进行贪婪化利用,以ε的概率进行探索。其中ε从始自终都是一个固定不变的、0-1之间的、一个超参数。 最重要的是Sarsa算法中的利用和探索都是在轨的,就是都是自己打游戏,从自己打的游戏序列中提取策略的。
Sarsa是在轨控制 ,Q-learning和Sarsa最大的区别就是,Q-learning是离轨控制 。
上图B处是Q-learning的利用,就是在策略Π下贪婪化的寻找最大的(s,a)对儿。上图的C处是Q-learning从别人打的序列中,偷窥别人这么玩获得多少系统奖励。上图D处是Q-learning对比自己B处的奖励和别人C处的奖励:
如果自己最大的(s,a)对儿获得的奖励大于别人的(s,a')对儿获得的奖励,那么就用自己的(s,a)对儿作为最优策略。
如果自己最大的(s,a)对儿获得的奖励小于别人的(s,a')对儿获得的奖励,那么就用别人的(s,a')对儿作为最优策略。
所以如果说Sarsa是自己在不断的利用和探索,从而变成高手的。那Q-learning就是把"自己的利用"和"别人的探索"通过贝尔曼最优方程 整合到一起,从而变成高手的。也所以上图D处其实就是贝尔曼最优方程的形式。也所以上图E处就是Q-learning的贝尔曼最优方程的迭代过程。
(3)上图4处:Sarsa是无法收敛到最优策略的,但是Q-learning是可以收敛到最优策略的。这个结论后面还会继续展开说明。
3、Q-learning算法伪代码
如果上面的原理部分你还没看懂,那继续参考下面的代码,我再讲解一遍: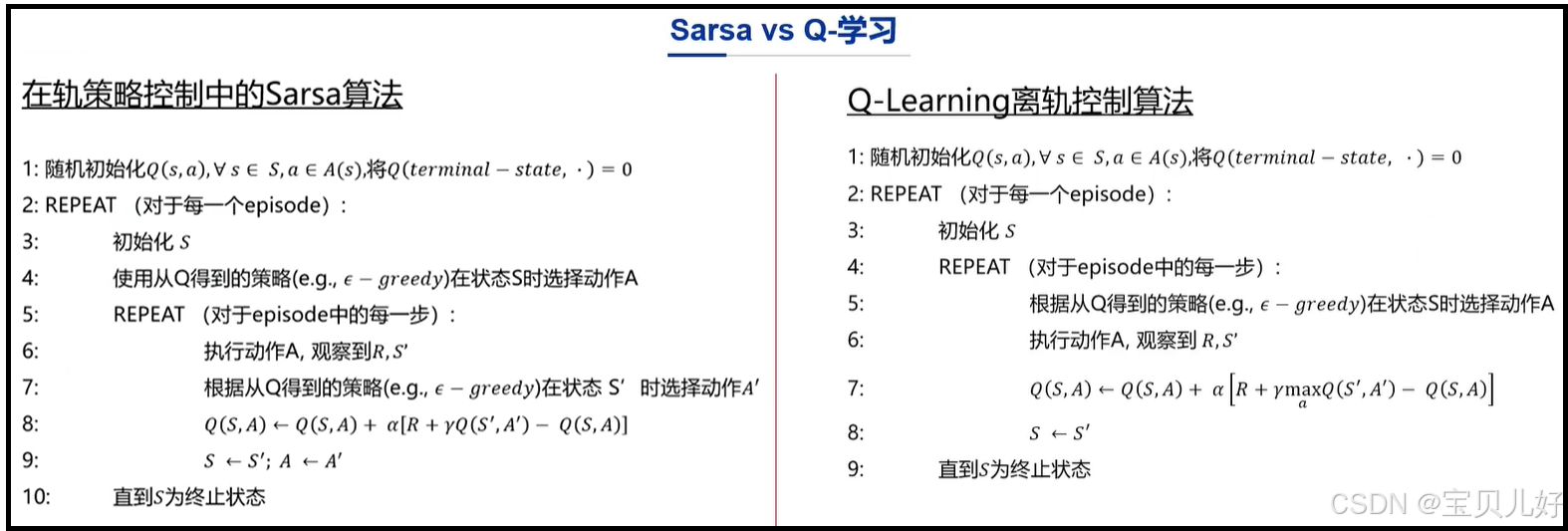
(1)左边是Sarsa算法的代码。右边是Q-learning算法的代码。
(2)Sarsa是每打一步游戏,在开打的这一步前,就开始分"利用"和"探索",它是以1-ε的概率进行利用,以ε的概率进行探索:
如果它实际上是利用,那它就是对其以往的策略进行贪婪化提升,然后计算提升后的策略下的动作状态价值,然后以新的动作状态价值指导下一步动作。
如果它实际上是探索,那它就不按以往的策略,而是主打选择相反的动作,并且实际做出这个动作,状态转移、获得系统奖励->然后计算前面动作的价值,更新策略->新策略指导下一步动作。
(3)Q-learning是每打一步游戏,它就直接开始利用自己的以往经验,也就是从以往策略中贪婪化的选出最优策略,按照这个最优策略来执行动作a,状态转移、获得系统奖励->然后再回看别人做了a'动作后,人家的新状态和系统奖励->然后对比自己的奖励和别人的奖励:
如果自己的奖励大于别人的奖励,按照自己策略,重新计算价值,指导下一步动作。
如果自己的奖励小于别人的奖励,修改自己的策略,重新计算价值,指导下一步动作。
4、Sarsa和Q-learning的效果对比
如果上面的原理和伪代码你也还是不理解,下面再通过一个实际例子继续理解: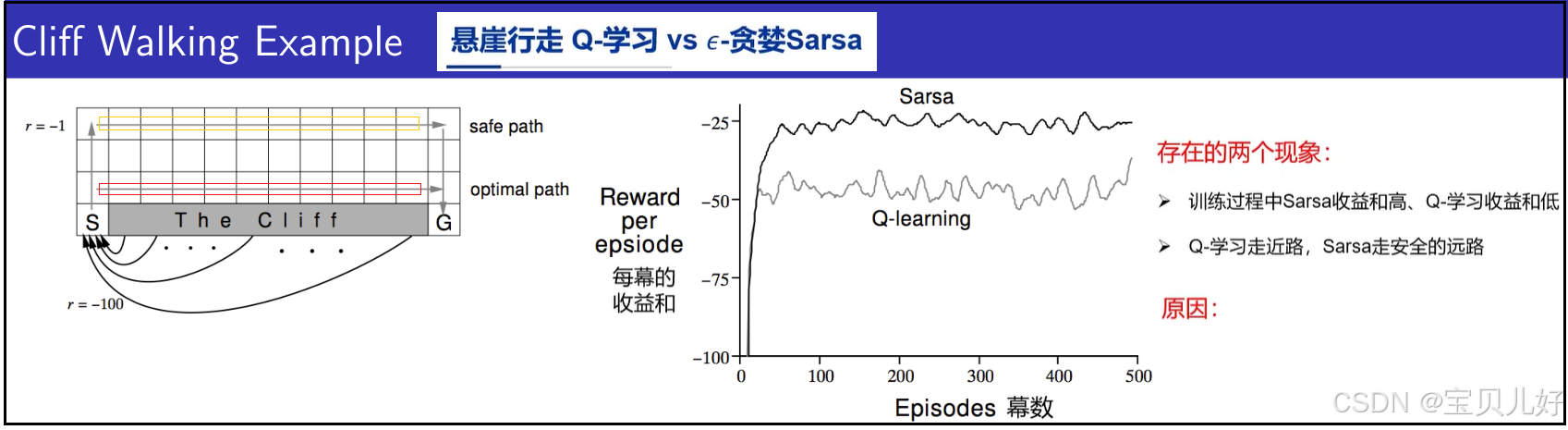
(1)上左图是一个小游戏。假如agent从S格开始上下左右4个方向随机走,走到G格子就赢了游戏。每次只能走1格。每走1步系统奖励-1分。如果碰到左、右、上面的墙壁,就还在原格子并且系统给予-1分的惩罚。如果碰到下面的cliff(悬崖),系统给与-100分惩罚,结束游戏。其实对于Sarsa和Q-learning算法来说,结束不结束无所谓,你可以看作是重新从S格子出发就行。
(2)上图中的红色线路是Q-learning算法最后收敛到的最优策略对应的线路,我们叫optimal path,也叫走近路。
上图中的黄色线路是Sarsa算法最后收敛到的策略对应的线路,我们叫safe path,也叫走安全的远路。因为越接近悬崖,只要一次走错,就摔入悬崖,game over了。
(3)上中图是Sarsa和Q-learning两个算法对应的收益,也就是系统奖励。可见,使用Sarsa算法玩这个游戏获得的奖励要稳定得高于Q-learning。
(4)为什么Sarsa走远路,Q-learning走近路?Sarsa奖励多,Q-learning奖励少?
因为Sarsa在每走一步之前,都要以ε的概率进行探索的。假如它目前在紧挨着悬崖的那一排格子中,一旦它真的开始探索,也就有极大的概率摔下悬崖而获取-100的奖励。假如它真的摔下悬崖得-100,那此时它计算出的悬崖边上的格子的价值就会非常低。我们策略提升的时候,都是贪婪化的寻找价值最高的格子走,因为价值高的格子意味着系统奖励多嘛,所以Sarsa的策略就提升为往高处走。所以Sarsa的策略收敛后,它走的就是最高的线路,也就是上图的safe path,也所以Sarsa获得系统奖励要多一些。
反观Q-learning,Q-learning只根据自己的经验走,假如Q-learning也是走到紧挨着悬崖的那一排格子中,对于Q-learning来说,上下左右都是一样的,
假如它上或左或右,就是没有下,这样上、左、右格子的奖励都是-1分,此时Q-learning还得看看别人的动作,假如它看到有人做了"下"的动作,获得了-100分,那Q-learning一对比,自己的动作是-1分,别人是-100分,那就以后还是相信自己的动作好了。假如Q-learning自己向下了,它获得了-100分,那看到别人左右上都是-1分,那它会直接用别人的策略,用-1分来重新计算所有格子的价值,来提升自己的策略。所以Q-learning策略收敛后,远离悬崖的格子的价值其实和靠近悬崖的格子的价值相差无几,所以它就收敛到最短的路径上。
5、用代码实现一下上面的小游戏
待续。。。
七、总结¶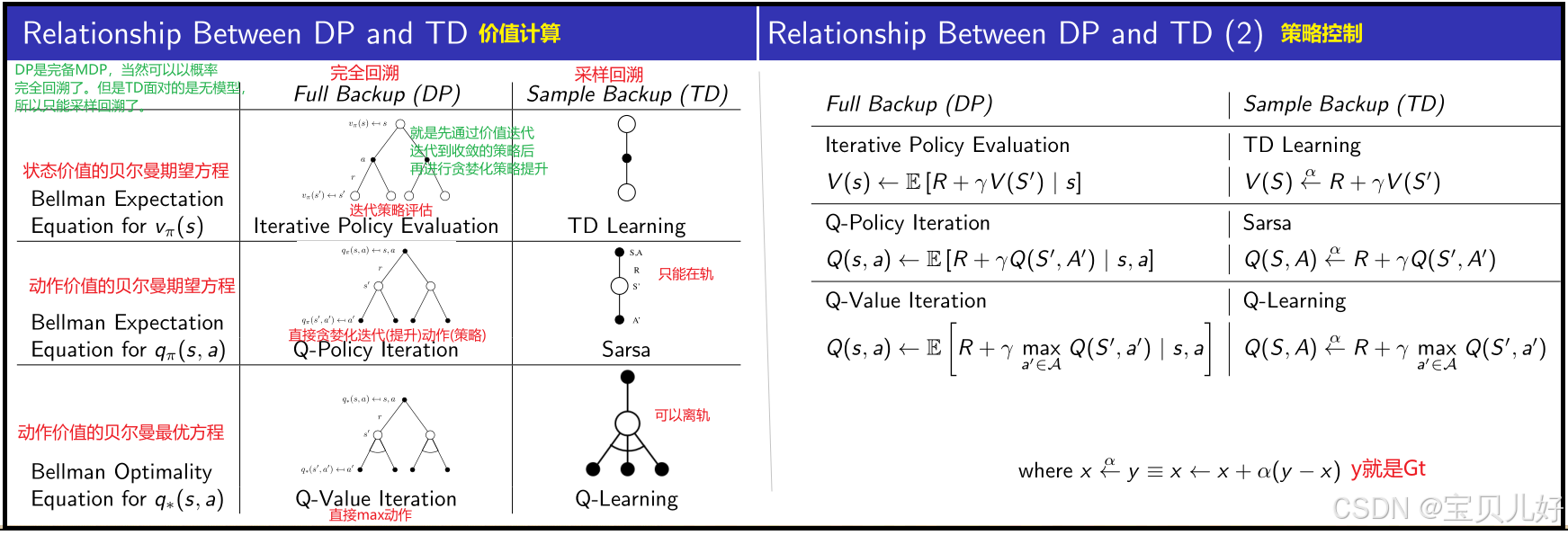
本篇完。传统强化学习到此结束。后面开启深度强化学习。