文章目录
数据采集的困难性
在全球互联网环境中进行数据采集时,常面临网络访问约束、隐私安全保护以及数据格式多样性等挑战。同时,系统还需兼顾高并发处理能力、运行稳定性和业务合规性要求。借助IPIDEA提供的全球优质网络服务,能够灵活应对各类网络环境,实现高效稳定的数据获取、隐私安全保护与智能解析,从而高效、稳定地获取全球公开数据,为AI模型训练、市场洞察分析及复杂业务流程提供可靠支撑。
数据采集的重要性
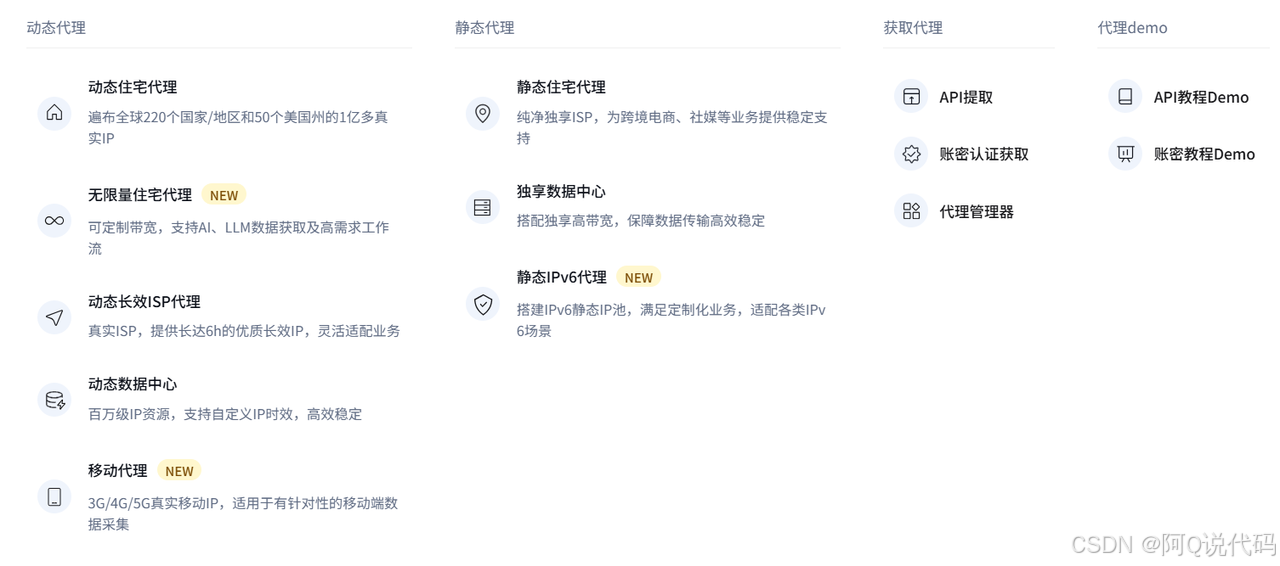
在实际数据采集工作中,代理服务是开发团队与企业有效应对网络约束与访问压力的重要技术方式。通过更新出口与智能调度,可显著提升数据采集的成功率,降低因高频访问被中断的风险。同时,借助多地网络资源,能够获取更全面、更具代表性的数据样本,支持多区域覆盖需求。
对开发者而言,稳定、高质量的代理服务直接决定了数据采集系统的效率、扩展性与数据完整性,是构建高可用数据基础设施的关键支撑。
IPIDEA产品选取
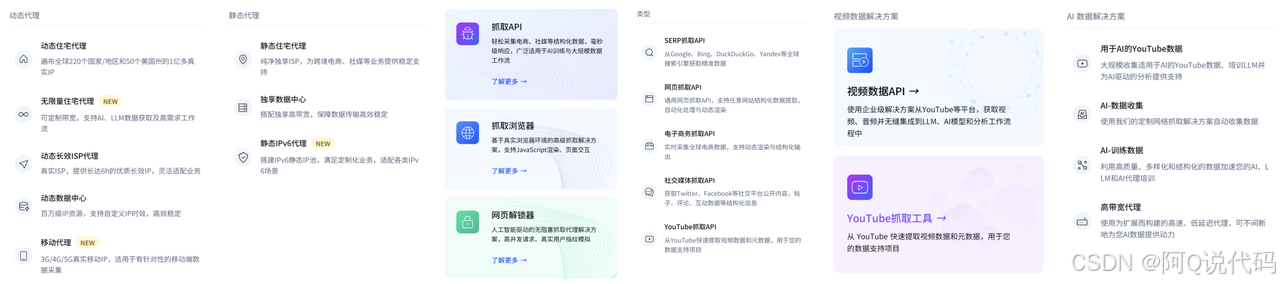
✅IPIDEA视频·AI双引擎:一端高效提取YouTube等平台音视频数据,另一端提供AI专属采集与训练支持,助力智能场景快速落地
✅IPIDEA全场景抓取体系:以抓取API、抓取浏览器与网页解锁器为核心,覆盖SERP、电商、社交等多领域数据源,全面适配全球主流平台
✅IPIDEA代理服务矩阵:集动态与静态代理于一体,支持API与账密多种接入方式,为全球化数据采集提供稳定、安全的IP支撑
前提准备
API获取
1、API提取
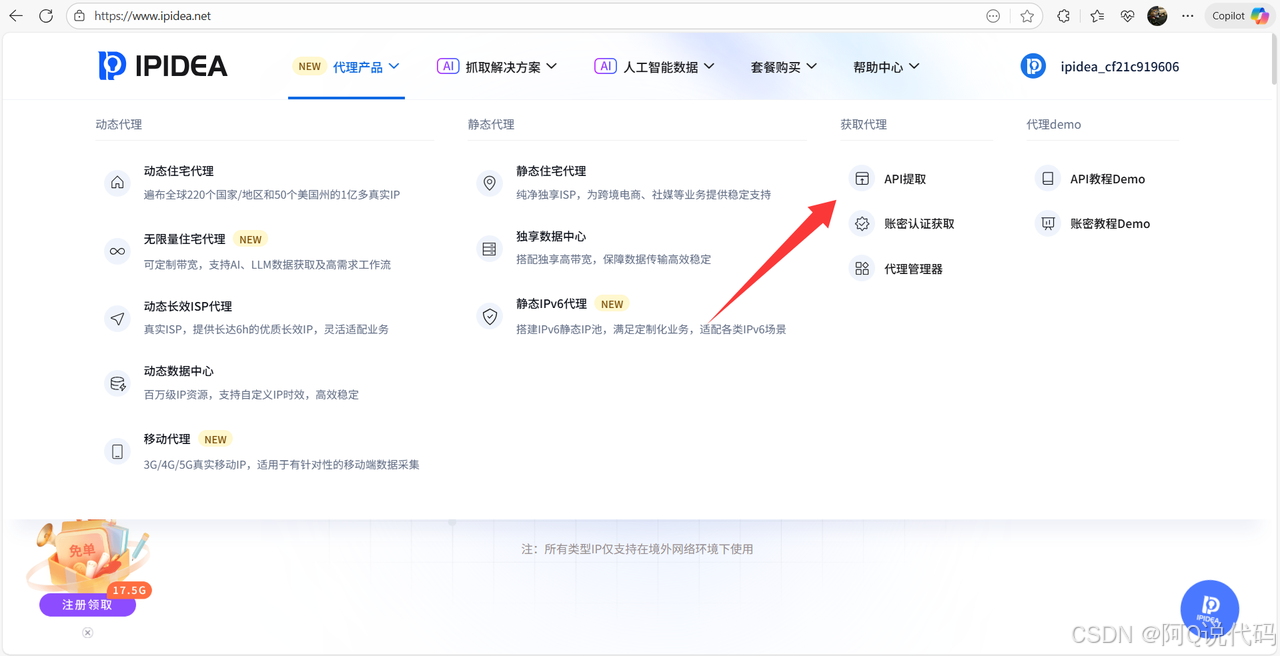
2、动态住宅IP提取
- 套餐选择:根据用量需求,灵活选用IP服务的计费方式
- 账户余额:平台内可用的充值金额
- 地区设置:指定IP资源的地理位置范围
- 提取数量:单次获取的IP数量
- 代理协议:设定代理连接所使用的通信协议类型
- 数据格式:选择IP数据的导出文件格式
- 分隔方式:设定多个IP地址之间的分隔符号
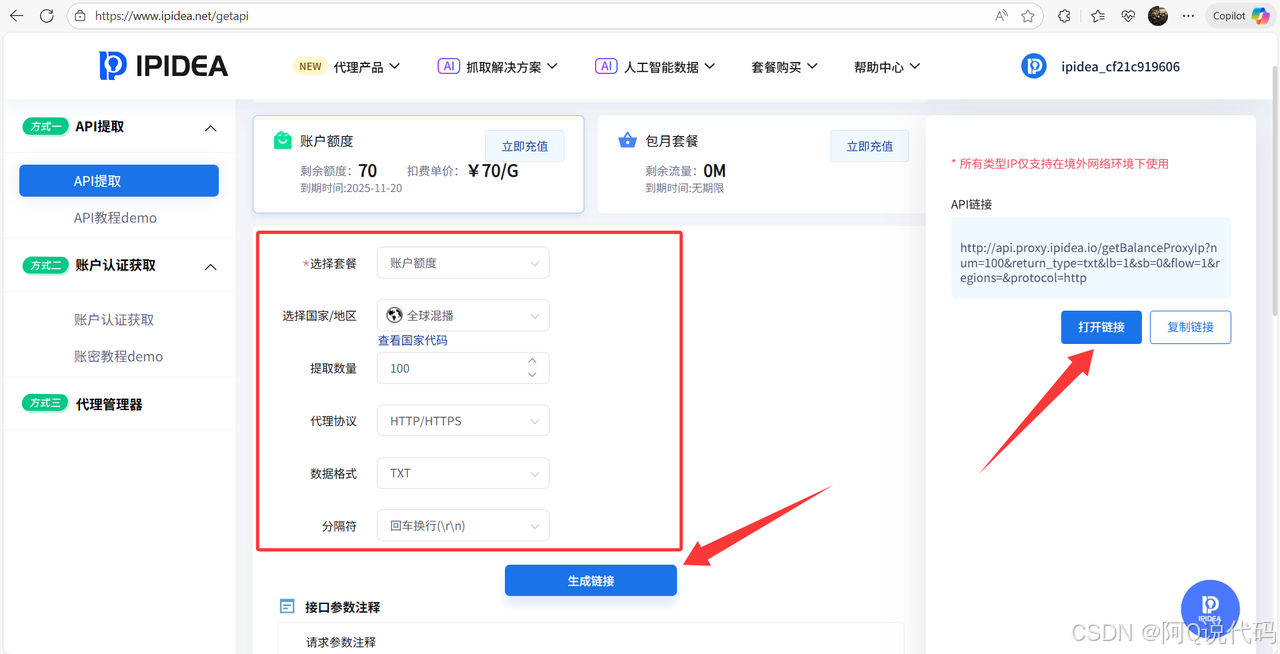
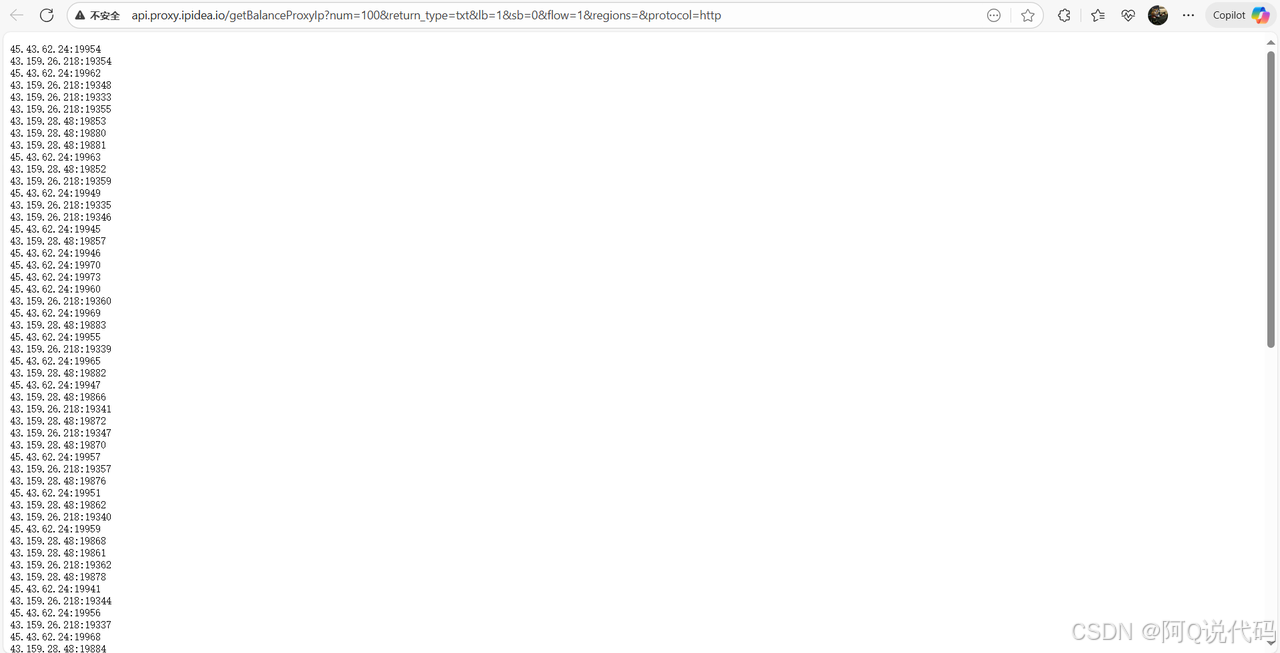
3、打开连接查看动态住宅IP数量
4、Python代码API提取IP
python
# coding=utf-8
# !/usr/bin/env python
import json
import threading
import time
import requests as rq
# 设置请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:85.0) Gecko/20100101 Firefox/85.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br"
}
# 测试链接
testUrl = 'https://ipinfo.ipidea.io'
# 核心业务
def testPost(host, port):
# 配置获取到的ip,port
proxies = {
# host api获取到的代理服务器地址
# port api获取到的端口
'http': 'http://{}:{}'.format(host, port),
'https': 'http://{}:{}'.format(host, port),
}
while True:
try:
# 配置代理后测试
res = rq.get(testUrl, proxies=proxies, timeout=5)
# print(res.status_code)
# 打印请求结果
print(res.status_code, "***", res.text)
break
except Exception as e:
print(e)
break
return
class ThreadFactory(threading.Thread):
def __init__(self, host, port):
threading.Thread.__init__(self)
self.host = host
self.port = port
def run(self):
testPost(self.host, self.port)
# 提取代理的链接 json类型的返回值
tiqu = 'http://api.proxy.ipidea.io/getBalanceProxyIp?num=10&return_type=json&lb=1&sb=0&flow=1®ions=&protocol=http'
while 1 == 1:
# 每次提取10个,放入线程中
resp = rq.get(url=tiqu, timeout=5)
try:
if resp.status_code == 200:
dataBean = json.loads(resp.text)
else:
print("获取失败")
time.sleep(1)
continue
except ValueError:
print("获取失败")
time.sleep(1)
continue
else:
# 解析json数组,获取ip和port
print("code=", dataBean["code"])
code = dataBean["code"]
if code == 0:
threads = []
for proxy in dataBean["data"]:
threads.append(ThreadFactory(proxy["ip"], proxy["port"]))
for t in threads: # 开启线程
t.start()
time.sleep(0.01)
for t in threads: # 阻塞线程
t.join()
# break
time.sleep(1)
账密获取
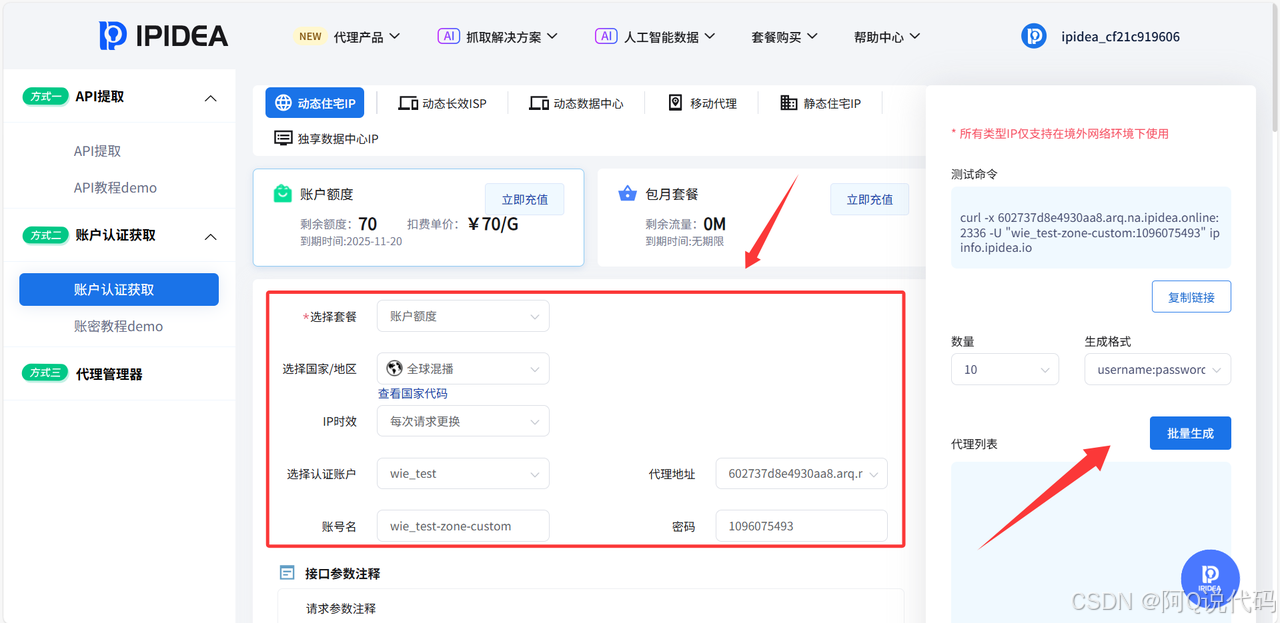
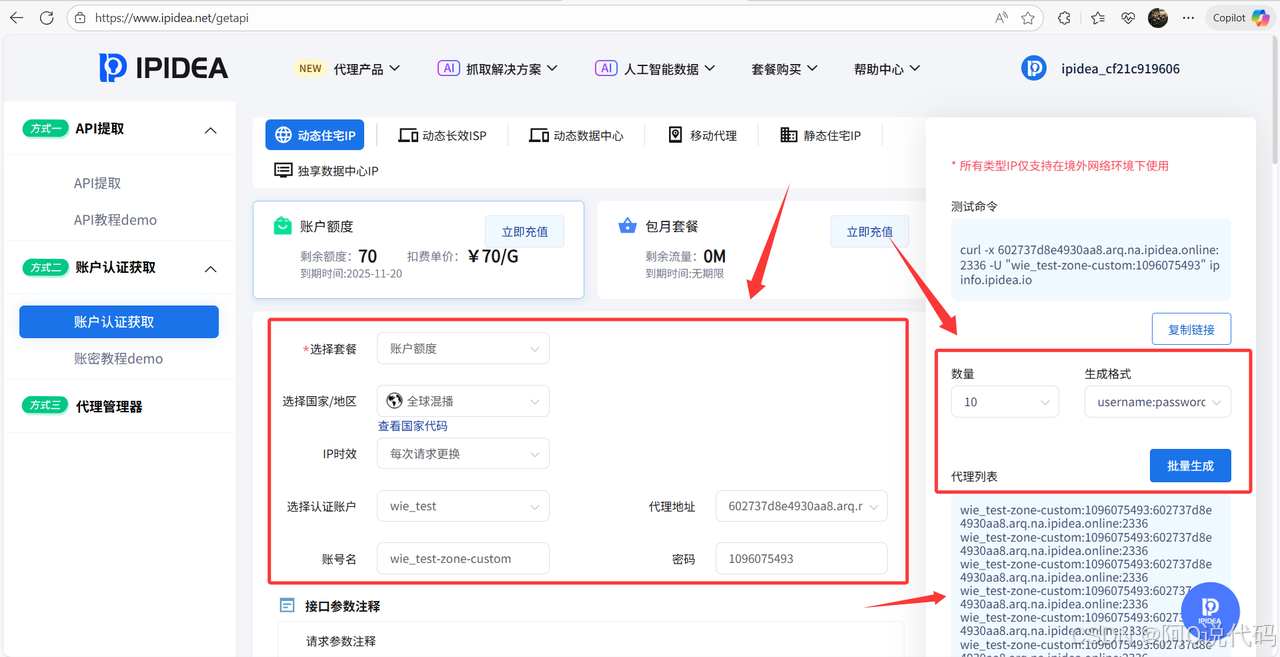
1、此处需要选择认证账户处需要自己创建认证账户,然后保存生成的账号名、密码、代理地址
2、Python代码获取IP
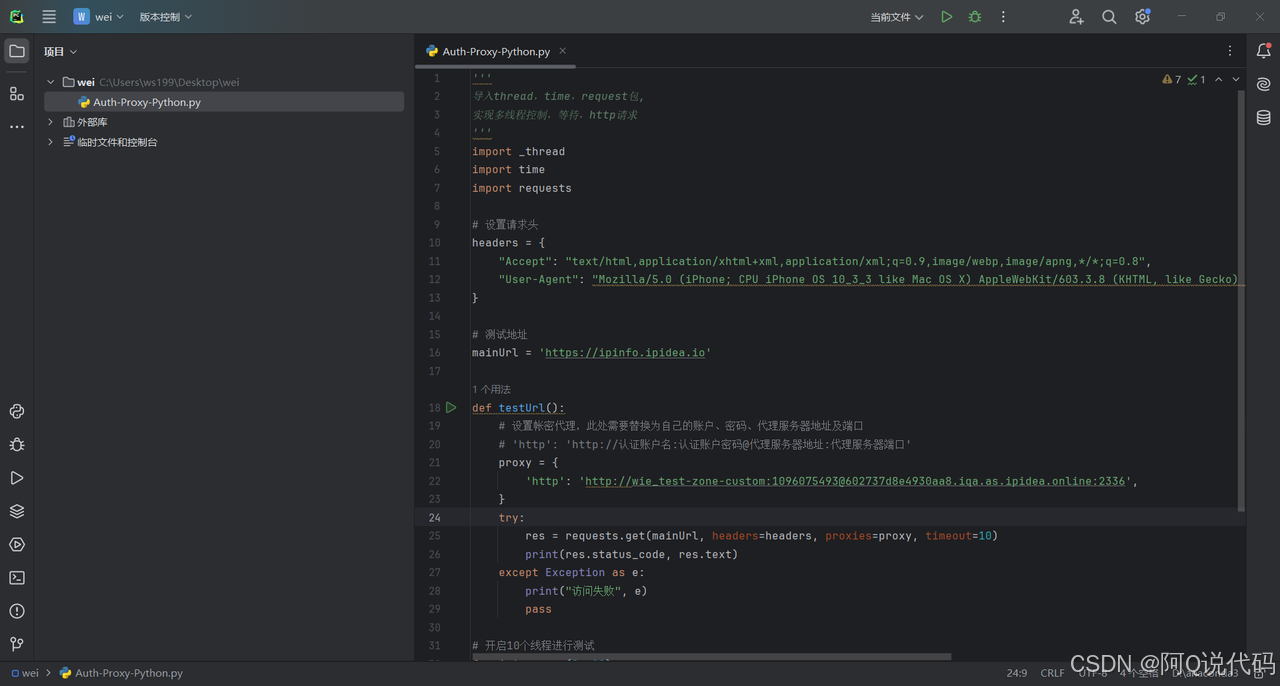
python
'''
导入thread,time,request包,
实现多线程控制,等待,http请求
'''
import _thread
import time
import requests
# 设置请求头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
# 测试地址
mainUrl = 'https://ipinfo.ipidea.io'
def testUrl():
# 设置帐密代理,此处需要替换为自己的账户、密码、代理服务器地址及端口
# 'http': 'http://认证账户名:认证账户密码@代理服务器地址:代理服务器端口'
proxy = {
'http': 'http://wie_test-zone-custom:1096075493@602737d8e4930aa8.iqa.as.ipidea.online:2336',
}
try:
res = requests.get(mainUrl, headers=headers, proxies=proxy, timeout=10)
print(res.status_code, res.text)
except Exception as e:
print("访问失败", e)
pass
# 开启10个线程进行测试
for i in range(0, 10):
_thread.start_new_thread(testUrl, ())
time.sleep(0.1)
time.sleep(10)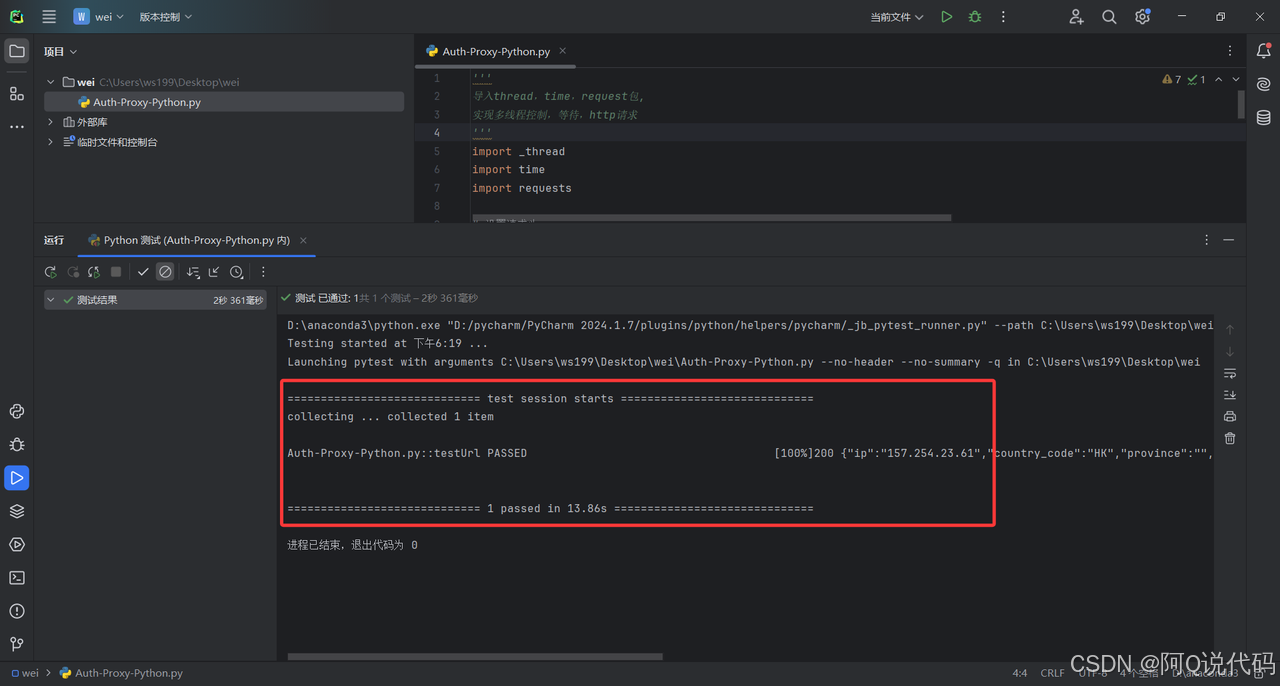
IPIDEA实现Amazon商品数据自动化采集方案
代理预处理
代理预处理:通过IPIDEA API提取IP,先检测有效性,筛选可用代理池
python
get_ipidea_proxy_from_api() # 提取代理
test_proxy(proxy) # 测试代理可用性
init_valid_proxy_pool() # 初始化有效代理池多页自动化获取
多页自动化获取:按页码自动生成Amazon搜索URL,批量采集商品数据
python
get_ipidea_proxy_from_api() # 提取代理
test_proxy(proxy) # 测试代理可用性
init_valid_proxy_pool() # 初始化有效代理池智能访问策略
模拟真实用户访问行为,合理控制请求频率,保障采集任务的连续性与稳定性。
python
time.sleep(randint(2, 4)) # 请求间隔
if len(response.text) < 8000: # 页面反爬检测
time.sleep(randint(8, 12))
continue数据标准化
数据标准化:提取商品名称、价格、评分、库存等关键信息,清洗后存入CSV
python
parse_amazon_product(html, page_num) # HTML解析
save_to_csv(product_list) # 写入CSV(带锁防并发冲突)
init_csv_header() # 初始化表头日志监控
日志监控:记录爬取状态、代理使用情况,方便问题排查
python
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler(LOG_FILE, encoding="utf-8"),
logging.StreamHandler()
]
)完整代码与效果展示
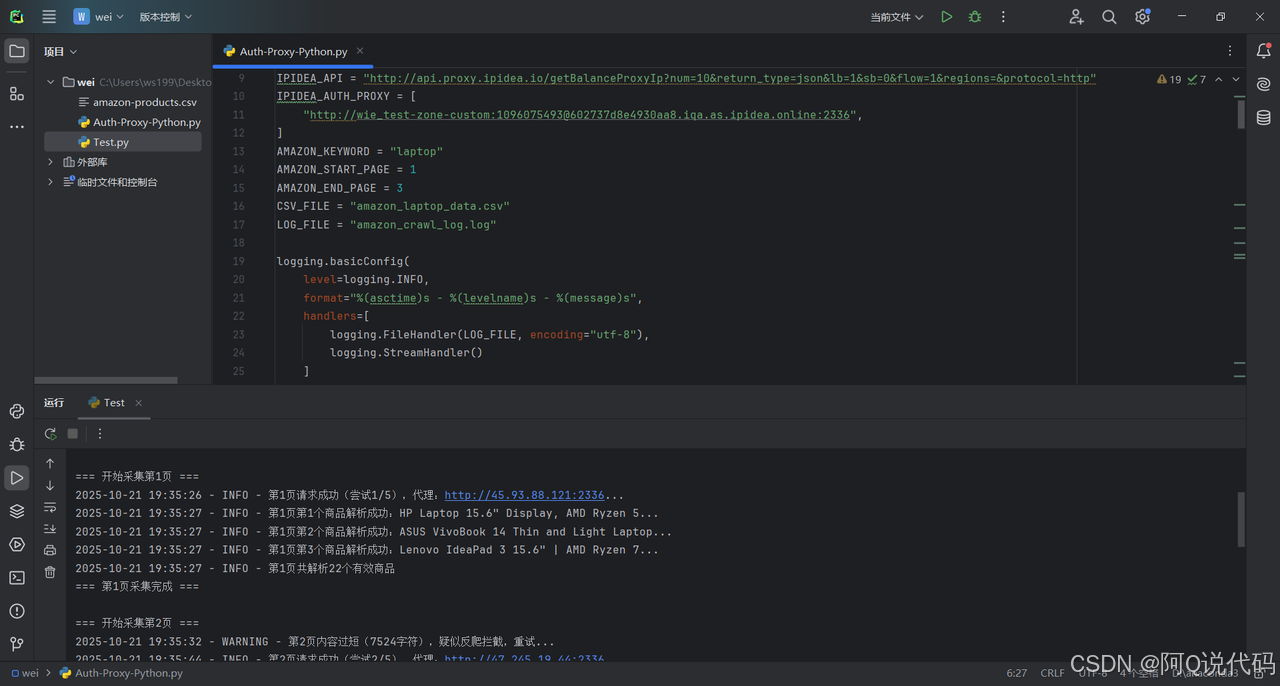
python
import requests
from bs4 import BeautifulSoup
import csv
import time
import logging
from random import randint
import threading
IPIDEA_API = "http://api.proxy.ipidea.io/getBalanceProxyIp?num=10&return_type=json&lb=1&sb=0&flow=1®ions=&protocol=http"
IPIDEA_AUTH_PROXY = [
"http://wie_test-zone-custom:1096075493@602737d8e4930aa8.iqa.as.ipidea.online:2336",
]
AMAZON_KEYWORD = "laptop"
AMAZON_START_PAGE = 1
AMAZON_END_PAGE = 3
CSV_FILE = "amazon_laptop_data.csv"
LOG_FILE = "amazon_crawl_log.log"
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler(LOG_FILE, encoding="utf-8"),
logging.StreamHandler()
]
)
valid_proxy_pool = []
csv_lock = threading.Lock()
success_count = 0
def get_ipidea_proxy_from_api():
try:
response = requests.get(IPIDEA_API, timeout=10)
response.raise_for_status()
data = response.json()
if data.get("code") != 0 or not data.get("success"):
error_msg = data.get("msg", "API返回未知错误")
logging.error(f"IPIdea API请求失败:{error_msg}(请检查API参数/添加白名单,IP:{data.get('request_ip')})")
return []
proxies = [f"http://{ip_port}" for ip_port in data.get("data", [])]
logging.info(f"从API成功提取{len(proxies)}个IPIdea代理")
return proxies
except Exception as e:
logging.error(f"IPIdea API调用异常:{str(e)},将使用备用账密代理")
return []
def test_proxy(proxy):
test_url = "https://www.amazon.com"
test_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
}
try:
proxy_dict = {"http": proxy, "https": proxy}
response = requests.get(
test_url,
headers=test_headers,
proxies=proxy_dict,
timeout=15,
allow_redirects=True
)
if response.status_code == 200 and "Amazon" in response.text[:1000]:
logging.info(f"代理测试通过:{proxy[:50]}...")
return True
else:
logging.warning(f"代理无效(状态码:{response.status_code}):{proxy[:50]}...")
return False
except Exception as e:
logging.error(f"代理测试失败:{str(e)} | 代理:{proxy[:50]}...")
return False
def init_valid_proxy_pool():
global valid_proxy_pool
api_proxies = get_ipidea_proxy_from_api()
if not api_proxies:
api_proxies = IPIDEA_AUTH_PROXY
logging.info(f"使用备用账密代理,共{len(api_proxies)}个")
valid_proxy_pool = [p for p in api_proxies if test_proxy(p)]
if len(valid_proxy_pool) < 2:
logging.warning(f"可用代理仅{len(valid_proxy_pool)}个,可能影响爬取稳定性,建议增加代理数量")
else:
logging.info(f"代理池初始化完成,可用代理数:{len(valid_proxy_pool)}")
def get_random_proxy():
if not valid_proxy_pool:
logging.error("可用代理池为空,无法发起请求")
return None
return valid_proxy_pool[randint(0, len(valid_proxy_pool) - 1)]
def fetch_amazon_page(page_num):
url = f"https://www.amazon.com/s?k={AMAZON_KEYWORD}&page={page_num}&gl=US"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.google.com/",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
for attempt in range(5):
proxy = get_random_proxy()
if not proxy:
time.sleep(5)
continue
try:
time.sleep(randint(2, 4))
proxy_dict = {"http": proxy, "https": proxy}
response = requests.get(
url,
headers=headers,
proxies=proxy_dict,
timeout=20,
allow_redirects=True
)
response.raise_for_status()
if len(response.text) < 8000:
logging.warning(f"第{page_num}页内容过短({len(response.text)}字符),疑似反爬拦截,重试...")
time.sleep(randint(8, 12))
continue
logging.info(f"第{page_num}页请求成功(尝试{attempt+1}/5),代理:{proxy[:30]}...")
return response.text
except requests.exceptions.HTTPError as e:
if "503" in str(e):
logging.warning(f"第{page_num}页被拒绝(503),代理可能被封:{proxy[:30]}...")
else:
logging.error(f"第{page_num}页HTTP错误:{str(e)},尝试{attempt+1}/5")
time.sleep(randint(6, 10))
except Exception as e:
logging.error(f"第{page_num}页请求异常:{str(e)},尝试{attempt+1}/5,代理:{proxy[:30]}...")
time.sleep(randint(5, 8))
logging.error(f"第{page_num}页所有尝试失败,跳过该页")
return None
def parse_amazon_product(html, page_num):
global success_count
if not html:
return []
soup = BeautifulSoup(html, "html.parser")
products = soup.find_all(
lambda tag: tag.name == "div"
and tag.get("data-asin")
and "s-result-item" in tag.get("class", [])
)
product_list = []
for idx, product in enumerate(products, 1):
try:
name_tag = (
product.find("span", class_="a-size-medium a-color-base a-text-normal")
or product.find("span", class_="a-size-base-plus a-color-base a-text-normal")
)
name = name_tag.text.strip() if name_tag else ""
price_whole = product.find("span", class_="a-price-whole")
price_fraction = product.find("span", class_="a-price-fraction")
price = f"{price_whole.text.strip()}.{price_fraction.text.strip()}" if (price_whole and price_fraction) else ""
price = price.replace(",", "")
rating_tag = product.find("span", class_="a-icon-alt")
rating = rating_tag.text.strip().split()[0] if rating_tag else ""
stock_tag = product.find("span", class_="a-color-orange")
stock = stock_tag.text.strip() if stock_tag else "In Stock"
if name and price and rating:
product_info = [page_num, idx, name, price, rating, stock]
product_list.append(product_info)
success_count += 1
logging.info(f"第{page_num}页第{idx}个商品解析成功:{name[:30]}... | ${price} | {rating}分")
except Exception as e:
logging.error(f"第{page_num}页第{idx}个商品解析失败:{str(e)}")
logging.info(f"第{page_num}页共解析{len(product_list)}个有效商品")
return product_list
def save_to_csv(product_list):
with csv_lock:
with open(CSV_FILE, mode="a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerows(product_list)
def crawl_single_page(page_num):
logging.info(f"\n=== 开始采集第{page_num}页 ===")
html = fetch_amazon_page(page_num)
if not html:
return
product_list = parse_amazon_product(html, page_num)
if product_list:
save_to_csv(product_list)
logging.info(f"=== 第{page_num}页采集完成 ===")
def init_csv_header():
with open(CSV_FILE, mode="w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["页码", "商品序号", "商品名称", "价格(美元)", "评分", "库存状态"])
logging.info(f"CSV文件初始化完成,保存路径:{CSV_FILE}")
def start_automated_crawl():
init_valid_proxy_pool()
init_csv_header()
if not valid_proxy_pool:
logging.error("可用代理池为空,无法启动采集")
return
max_threads = min(len(valid_proxy_pool), 3)
threads = []
logging.info(f"启动多线程采集,并发数:{max_threads},页码范围:{AMAZON_START_PAGE}-{AMAZON_END_PAGE}")
for page_num in range(AMAZON_START_PAGE, AMAZON_END_PAGE + 1):
while len(threads) >= max_threads:
threads = [t for t in threads if t.is_alive()]
time.sleep(2)
thread = threading.Thread(target=crawl_single_page, args=(page_num,))
threads.append(thread)
thread.start()
logging.info(f"第{page_num}页线程启动,当前活跃线程:{len(threads)}")
time.sleep(randint(3, 5))
for thread in threads:
thread.join()
total_pages = AMAZON_END_PAGE - AMAZON_START_PAGE + 1
logging.info(f"\n=== 自动化采集完成 ===")
logging.info(f"总采集页码:{total_pages} 页")
logging.info(f"成功采集商品数:{success_count} 个")
logging.info(f"数据保存路径:{CSV_FILE}")
logging.info(f"日志保存路径:{LOG_FILE}")
if __name__ == "__main__":
time.sleep(randint(2, 4))
start_automated_crawl()总结
本文展示了IPIDEA如何通过自动化数据采集方案助力企业高效获取全球公开数据。方案核心包括智能资源调度、自动化多页采集、合规访问策略及数据标准化,确保采集过程的高效稳定与业务扩展性。欢迎访问IPIDEA官网,即刻体验服务能力。
