《KingbaseES数据库》本篇文章所属专栏---持续更新中---欢迎订阅!

KingbaseES(简称KES)是面向全行业、全客户关键应用的企业级大型通用融合数据库产品,适用于事务处理类应用、数据分析类应用、海量时序数据采集检索类应用、要求苛刻的互联网应用等场景;可用作管理信息系统、业务及生产系统、决策支持系统、多维数据分析系统、运行日志管理系统、全文检索系统、地理信息系统、时序数据处理相关系统的承载数据库。 KES采用融合数据库架构,通过多语法体系一体化架构实现一套软件兼容Oracle、MySQL、SQL Server、PostgreSQL等多个异构数据库的语法; 采用多模数据一体化存储,支持对关系模型、文档模型、全文本、GIS数据、时序等数据的统一存储、混合访问、模型间转换; 采用集中分布一体化架构,满足不同级别的可用性,为客户提供不同级别的可用性、性能扩展、成本需求,确保业务连续,最大化投资价值。

下面我将围绕KingbaseES 数据库性能调优主题来展开今天的文章内容
文章目录
-
- 第一章:理解数据库性能的本质
-
- [1.1 什么是性能?](#1.1 什么是性能?)
- [1.2 性能指标模型](#1.2 性能指标模型)
- [1.3 数据库时间模型](#1.3 数据库时间模型)
- 第二章:明察秋毫:构建系统化的诊断思维
-
- [2.1 性能问题产生模型](#2.1 性能问题产生模型)
- [2.2 性能诊断整体流程](#2.2 性能诊断整体流程)
- 第三章:利器出鞘:操作系统级诊断实战
-
- [3.1 CPU诊断:mpstat实战](#3.1 CPU诊断:mpstat实战)
- [3.2 内存瓶颈分析](#3.2 内存瓶颈分析)
- [3.3 I/O瓶颈分析](#3.3 I/O瓶颈分析)
- 第四章:数据库内部资源深度分析
-
- [4.1 使用sys_stat_statement工具](#4.1 使用sys_stat_statement工具)
- [4.2 等待事件分析](#4.2 等待事件分析)
- [4.3 自动负载信息库SYS_KWR](#4.3 自动负载信息库SYS_KWR)
- [4.4 共享内存命中率分析](#4.4 共享内存命中率分析)
- 第五章:性能优化实战经验
-
- [5.1 数据库参数优化](#5.1 数据库参数优化)
- [5.2 SQL优化](#5.2 SQL优化)
- [5.3 性能诊断与优化经验](#5.3 性能诊断与优化经验)
- 第六章:总结与展望
正文开始------
第一章:理解数据库性能的本质
在深入技术细节之前,让我们先建立一个核心认知:什么是数据库性能?
1.1 什么是性能?
性能是一种指标,表明软件系统对于其及时性要求的符合程度。及时性用响应时间或者吞吐量来衡量。
-
响应时间:对请求做出响应所需要的时间。对于单个事务可以是事务完成所需要的时间;对于用户任务,则是端对端的时间。
-
系统吞吐量:特定时间内能够处理的请求数量。
软件性能的及时性包括两个重要方面:响应性和可扩展性。响应性是系统实现其响应时间或者吞吐量目标的能力;可扩展性则是系统在对其软件功能的要求增加的情况下,继续实现其响应时间或吞吐量目标的能力。
1.2 性能指标模型
数据库请求响应时间:即一个数据库请求从向数据库发起,到用户收到最后一条结果数据的时间间隔,其大小 = CPU计算时间 + 非空闲等待时间(如IO时间、数据库锁时间)。
并发吞吐量:即单位时间内,数据库能够处理的请求数量。该指标与前一指标的关系是:假设系统中只有一个会话,则只要该会话持续发起请求,即请求之间没有任何时间间隔,系统即可达到其最大并发吞吐量 = 1 / 数据库请求响应时间。
注意:这里的资源包括:CPU、内存、磁盘等存储设备、网络设备等硬件资源,数据库锁、应用锁等软件资源。
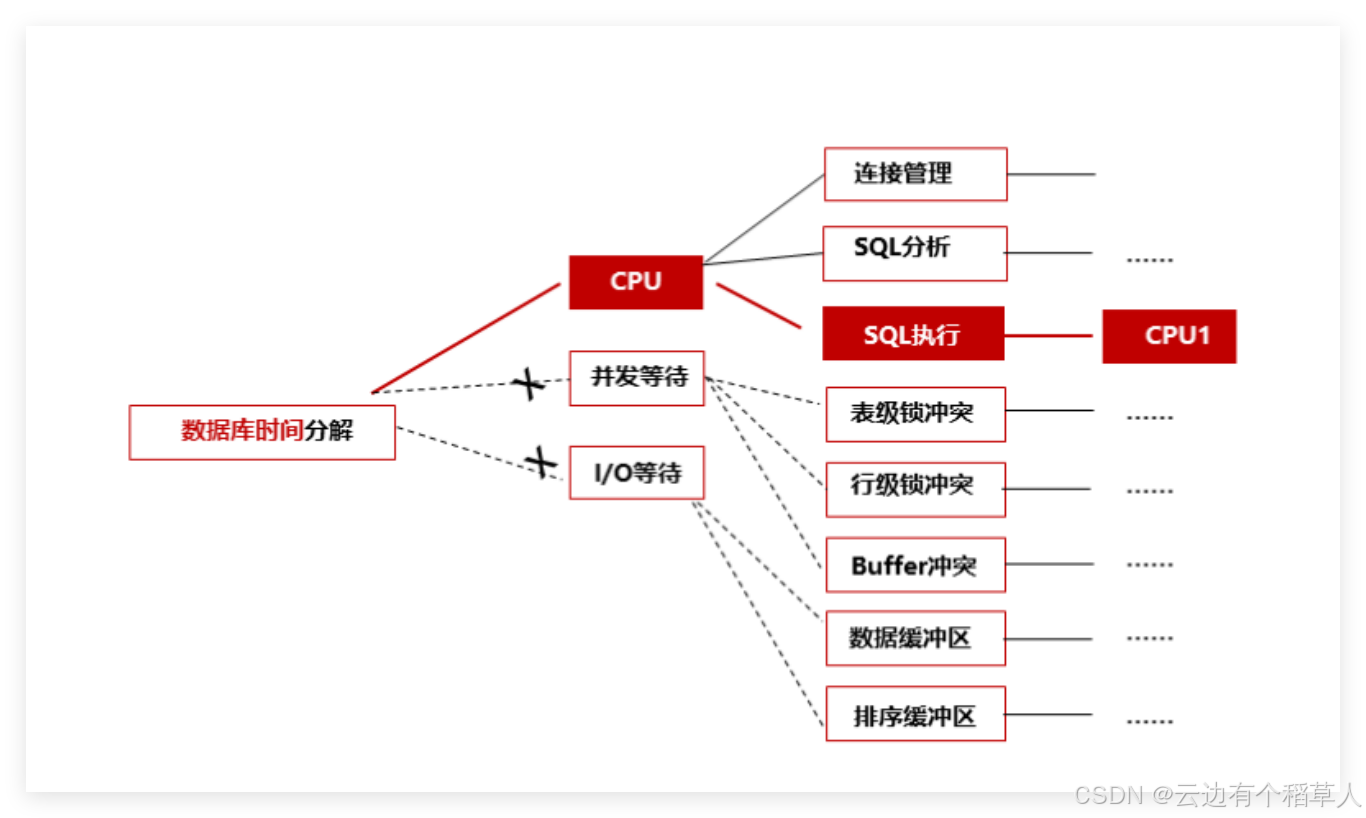
1.3 数据库时间模型
性能优化的第一步是确定性能问题的根本原因,然后才有可能给出有效的调优建议来解决或缓解该问题。
我们在数据库中引入时间模型来解决该问题。时间模型中最重要的就是数据库时间(DB TIME),DB TIME定义为在数据库中处理用户请求所花费的时间总和。这里我们给出数据库时间模型的量化公式:
数据库时间 = CPU时间 + 等待时间
数据库调优的根本目标则是缩短数据库时间:CPU或等待时间,随之吞吐量也自然提高。
注意:数据库时间不等于响应时间,它只是用户感知到的响应时间的一部分,因为它不包含中间层(网络、中间件等)花费的时间。
第二章:明察秋毫:构建系统化的诊断思维
性能问题不会凭空产生,它们总是有迹可循的。
2.1 性能问题产生模型
性能问题是由于某些系统资源争用或耗尽的结果。当系统资源耗尽时,系统无法扩展到更高的性能级别。而资源争用或不尽的根本原因,是对资源的使用不当,或资源的处理能力已经无法满足系统的负载需要。
数据库需要的软硬件资源包括:CPU、IO、内存、网络、锁等。这些资源在达到处理能力上限的时候,通常会产生性能问题。常见的资源瓶颈现象可能包括:
- CPU利用率接近100%
- IO利用率接近100%
- 内存不够,开始写swap
- 网络流量达到带宽上限,网络传输存在大量错误
- 数据库内部有大量的时间在等待
注意:在进行性能调优时,DBA主要的目标是找出并优化对资源的不当使用;如果没有不当使用,则说明资源的处理能力已经无法满足系统的负载需要,此时应给出资源需求估计。
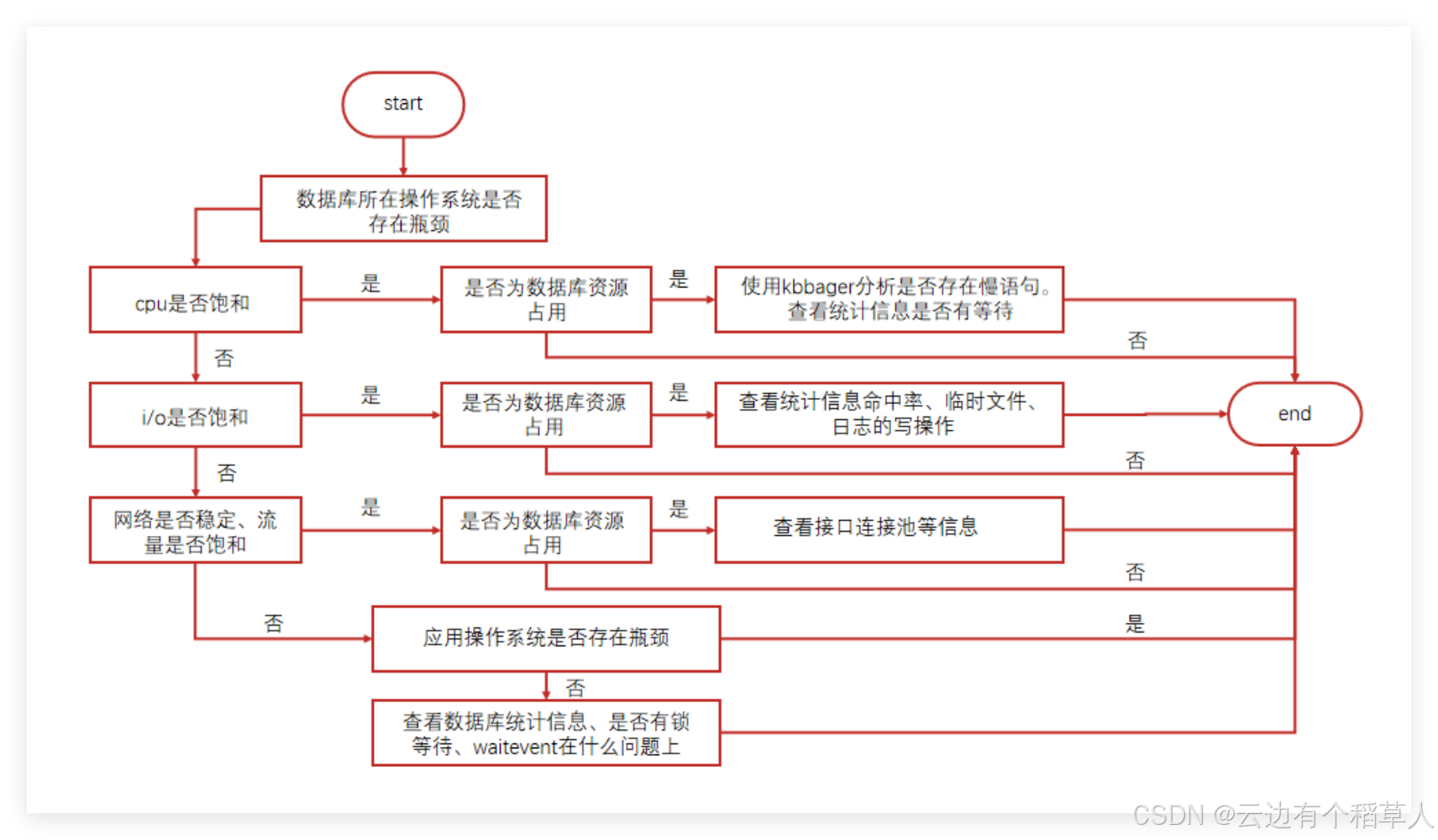
2.2 性能诊断整体流程
KingbaseES实例性能调优的整体过程如下:
- 定义性能目标
从用户那里获得关于性能问题范围的直接反馈,定义我们要达成的性能目标。准确确定应用场景,包括相关的测试用例。
需要收集的信息包括:
- 确定性能指标:可接受性能指标是什么?如响应时间、吞吐量的要求
- 确定问题涉及的范围:由于执行的缓慢影响到了什么?
- 确定问题发生的时间:这个问题只在高峰时段出现吗?
- 量化性能差距:这有助于确定问题的严重程度
- 确定自性能达标以来发生了哪些变化
- 测试并检查资源使用情况,定位性能瓶颈,找出性能问题的直接原因
收集从测试程序到数据库之间完整的操作系统资源负载信息、数据库内部统计信息、性能指标信息后,检查数据是否有任何性能问题的迹象。
- 检查资源使用的分布情况,找出性能问题的根本原因
在定位到性能瓶颈后,还需要进一步分析各种软硬件资源使用的分布情况(尤其是瓶颈资源),找出资源使用的不当情况(或者没有不当使用但是无法满足当前性能指标要求),才能找出性能问题的根本原因,使得性能收益最大化。
- 对于不合理的资源使用,合理化运用调优手段
在定位到性能问题的根本原因后,合理运用数据库的现有手段来解决性能问题。
-
提出需要进行的变更和实施变更的预期结果。然后,实现这些更改并监测应用程序的性能表现
-
确定步骤1提出的问题是否解决,如果没有解决,重复2,3,4,5步骤
第三章:利器出鞘:操作系统级诊断实战

3.1 CPU诊断:mpstat实战
cpu信息收集工具主要有:mpstat、iostat、nmon、oprofile、perf、sar、vmstat、uptime、/proc/stat、/proc/loadavg等。
mpstat使用示例:
[jwang@hai -]$ mpstat -P 0,1 2 4
Linux 3.10.0-693.21.1.e17.x86_64 (hai) 2020 年 03 月 21 日 _x86_64_(32 CPU)
11 时 52 分 38 秒
CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11 时 52 分 40 秒
0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00CPU资源分析要点:
- %usr:用户态消耗时间。如果比较大,说明用户程序本身有cpu瓶颈,需要优化程序本身。
- %sys:系统内核消耗时间。如果比较大,说明系统调用函数花费时间很多。
- %iowait:等待io的cpu时间,如果比较大,说明IO等待越严重,可能由于磁盘大量随机访问造成,也有可能磁盘出现瓶颈。
- %idle:空间cpu,如果比较大,说明不是瓶颈。
3.2 内存瓶颈分析
内存常用分析工具:top、free、nmon、/proc/zoneinfo、/proc/buddyinfo、/proc/meminfo、/proc/slabinfo、/proc/vmstat、/proc//maps等。
top命令示例:
top - 14:32:45 up 43 days, 8:28, 21 users, load average: 0.19, 0.30, 0.30
Tasks: 630 total, 1 running, 628 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.1 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 26372547+total, 20976670+free, 4104164 used, 49854604 buff/cache
KiB Swap: 16777212 total, 16777212 free, 0 used. 25713113+avail Mem内存资源分析要点:
- swap是否被使用,如果存在swap空间被使用的情况,说明发生了磁盘IO操作,数据库消耗CPU和IO时间,导致性能下降。
- 空闲内存是否比较少,一般来说如果空闲内存/物理内存 >70%,内存性能优,如果小于20%,则性能差,需要添加内存。
- 如果内存用的很少,查询比较慢,而且数据量很大,并且很多io,那可以考虑调大shared_buffers,提高命中率。
3.3 I/O瓶颈分析
测量I/O的工具包括:iostat, nmon, sar, vmstat, lsof, /proc/diskstat, /proc/partitions
iostat使用示例:
[root@localhost -]$ iostat -xkt 1
Linux 3.10.0-1160.e17.x86_64 (localhost.localdomain) 2024 年 08 月 20 日
avg-cpu: %user %nice %system %iowait %steal %idle
8.15 0.00 0.59 0.70 0.00 90.55
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 1.27 5.09 2.33 18.75 55.47 1519.95 149.47 0.11 5.07 22.80 2.86 4.32 9.10IO资源分析关键参数:
- %util:io的使用率,主要看是否已经接近或者超过100%,如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
- svctm:时间,主要说明磁盘本身的读写性能快慢。
- await:主要说明平均每次IO响应时间,一般小于5ms。
- 如果svctm比较接近await,说明I/O几乎没有等待时间。
- 如果await远大于svctm,说明I/O队列太长,应用得到的响应时间变慢。
第四章:数据库内部资源深度分析
4.1 使用sys_stat_statement工具
sys_stat_statement是KingbaseES系统的一个扩展组件,它提供了所有执行语句的统计信息,可以帮助找出哪种类型的查询很慢以及多久调用一次查询。
使用步骤:
-
在kingbase.conf里添加预加载项:
shared_preload_libraries = 'liboracle_parser, sys_stat_statements'
sys_stat_statements.track = 'top' -
重启数据库服务器
-
在执行的数据库里创建扩展:
sql
CREATE EXTENSION sys_stat_statements;关键视图字段说明:
- query:语句的文本形式
- calls:被执行的次数
- total_exec_time:在该语句中花费的总时间,以毫秒计
- rows:该语句检索或影响的行总数
- shared_blks_hit:该语句造成的共享块缓冲命中总数
- shared_blks_read:该语句读取的共享块的总数
查询TOP SQL示例:
sql
SELECT query, calls, total_exec_time, mean_exec_time, rows
FROM sys_stat_statements
ORDER BY total_exec_time DESC
LIMIT 10;4.2 等待事件分析
为了了解数据库当前的运行时状态,管理员可以查看系统视图sys_stat_activity来进行查看。该视图能够知道数据库目前正在发生写什么:比如有多少个连接,客户端的情况,每个连接的状态,每个连接上的等待事件等。
sys_stat_activity关键字段:
- datname:数据库名称
- usename:用户名
- application_name:应用名称
- state:当前的状态
- wait_event_type:当前等待事件的类型
- wait_event:当前等待事件
- query:当前查询语句
等待事件类型包括:
- LightLock:轻量级锁
- Lock:重量级锁
- BufferPin:数据缓冲区等待
- IO:IO等待
- Client:客户端等待
- Activity:后台辅助进程活动等待
查询等待事件示例:
sql
SELECT wait_event_type, wait_event, state, count(*)
FROM sys_stat_activity
GROUP BY wait_event_type, wait_event, state;4.3 自动负载信息库SYS_KWR
SYS_KWR是KingbaseES自动负载信息库(Kingbase Auto Workload Repertories)的简称,它通过周期性自动记录性能统计相关的快照,分析出KingbaseES的操作系统运行环境、数据库时间组成、等待事件和TOP SQL等性能指标,为数据库性能调优提供指导。
快速生成报告步骤:
-
配置kingbase.conf,开启统计开关:
shared_preload_libraries = 'liboracle_parser, sys_kwr, sys_stat_statements'
track_sql = on
track_instance = on
track_wait_timing = on
track_counts = on
track_io_timing = on
track_functions = 'all'
sys_stat_statements.track = 'top' -
重启数据库服务器
-
通过KSQL连接,创建KWR插件和快照:
sql
CREATE EXTENSION sys_kwr;
SELECT * FROM perf.create_snapshot(); -- 获得快照1
-- 执行一些SQL操作
CREATE TABLE IF NOT EXISTS t1(id int);
SELECT count(*) FROM t1;
SELECT * FROM perf.create_snapshot(); -- 获得快照2
SELECT * FROM perf.kwr_report(1,2,'html'); -- 生成HTML版报告KWR报告核心价值:
- 自动采集操作系统统计信息,不需要额外的性能监控工具
- 感知数据库运行环境,排查数据库实例外部原因造成的性能问题
- 通过统一的DB Time模型,度量数据库关键活动耗时
- 通过query ID将SQL执行时间、等待时间和资源消耗关联起来,进行语句级分析
- 从多个维度(时间、IO、内存、锁、实例、库对象等)分析数据库实例的性能问题
4.4 共享内存命中率分析
系统表sys_statio_user_tables和sys_statio_user_indexes从I/O的角度记录用户表和用户索引的信息。如果命中率过低,则可以考虑加大shared_buffers。
关键视图查询:
sql
-- 查看表级别的IO统计
SELECT schemaname, relname,
heap_blks_read, heap_blks_hit,
round(heap_blks_hit * 100.0 / (heap_blks_hit + heap_blks_read), 2) as hit_rate
FROM sys_statio_user_tables
WHERE heap_blks_hit + heap_blks_read > 0
ORDER BY hit_rate ASC;
-- 查看索引级别的IO统计
SELECT schemaname, indexrelname,
idx_blks_read, idx_blks_hit,
round(idx_blks_hit * 100.0 / (idx_blks_hit + idx_blks_read), 2) as hit_rate
FROM sys_statio_user_indexes
WHERE idx_blks_hit + idx_blks_read > 0
ORDER BY hit_rate ASC;第五章:性能优化实战经验
5.1 数据库参数优化
主要是根据不同应用调节不同内核参数进行优化,比如经常有大量数据频繁访问可以调大shared_buffers,有写临时文件的情况调大work_mem。
关键优化参数:
共享内存参数:
- shared_buffers:数据库服务器使用的共享内存缓冲区量,建议设置为系统内存的15-25%
- wal_buffers:用于还未写入磁盘的WAL数据的共享内存量
私有内存区参数:
- work_mem:在写入临时磁盘文件之前用于内部排序操作和哈希表的内存量
- maintenance_work_mem:用于维护操作(如VACUUM、CREATE INDEX和ALTER TABLE ADD FOREIGN KEY)的最大内存量
I/O相关参数:
- checkpoint_timeout:自动WAL检查点之间的最长时间
- checkpoint_completion_target:在检查点期间用于扩散刷出脏缓冲区的时间分数
- bgwriter_delay:后台写入器活动轮次之间的延迟
- bgwriter_lru_maxpages:每个轮次中后台写入器最多刷出的缓冲区数
5.2 SQL优化
可以考虑创建合适的索引、使用分区、通过HINT控制优化器使用最优的执行计划、使用并行等方式。
索引设计原则:
-
B-树索引:这种索引是标准的索引类型,对于主键和频繁选择索引都是非常适用的。作为连接索引使用,数据库可以使用B-树索引检索索引列排序的数据。
-
位图索引:这种索引类型将相同的数据以元组ID位图的形式保存在磁盘上。具有占用空间小、查找迅速的特点。适合没有Update操作且基数值较低(1-10000)的数据列。
-
基于函数的索引:这种索引允许通过B-树访问从原始数据中通过函数派生的值。基于函数的索引在使用空值方面有一些限制,并且该索引的使用要求占用查询优化器。
索引设计注意事项:
- 构建和维护索引结构可能会很昂贵,而且会消耗磁盘空间、CPU和I/O容量等资源
- 通过插入、删除或更新索引所维护的键所需的资源大约是在表上实际进行DML操作所需资源的三倍
- 设计者应该灵活地定义索引构建的规则,根据不同情况对索引中的键进行排序
5.3 性能诊断与优化经验
除了上述从瓶颈分析、根因分析到实施调优手段这种自顶向下追溯原因的方法,KingbaseES也有一些常见的优化经验供用户参考:
- 如果遇见查询计划不准的情况,首先需要考虑是否做了analyze
- 数据量大性能慢的情况,首先需要考虑shared_buffers是否开小了
- 一般有排序和join的查询慢的情况,只要数据量稍微大点就需要考虑work_mem是否设置了比较大,确保不写临时文件,不过如果并发特别多设置太大可能导致内存不够
- 全表扫描慢的情况,可以考虑采用索引,尤其是表达式索引和条件索引,调整SQL的执行计划,选择合适的索引
- 多表join的慢的情况,可以考虑join顺序问题,调整执行计划得到最优的join的顺序
- 表的join慢的情况,比如原来采用了nestloop,数据无序可以考虑采用hashjoin,有序可以考虑mergejoin
- 对于慢语句,在cpu资源比较充裕的情况下,可以考虑并行技术
- 数据库层优化完还不行,可以考虑操作系统调优,比如IO问题考虑磁盘的调度策略,数据库一般采用deadline,还有操作系统预读和IO请求队列的调整
- 对于同类请求比较多的情况,可以尝试通过PBE进行SQL的变量绑定,缓解SQL的硬解析,当遇到成千上万的查询操作时,能够不经处理过程直接使用缓存的执行计划,那效率可以提高n倍
- 数据量大还可以考虑分区
- 数据库能够高效的运行,最关键的因素需要内存足更大了,能缓存住数据,更新也可以在内存先完成。但不同的业务对内存需要强度不一样,一推荐内存要占到数据的15-25%的比例,特别的热的数据,内存基本要达到数据库的80%大小
- 单机操作的时候可以考虑读写分离
- 连接数过多造成资源争用严重的,考虑使用连接池来减缓竞争压力
第六章:总结与展望
性能调优从来都不是一次性的任务,而是一个持续优化、不断精进的过程。KingbaseES为我们提供了强大的工具和方法论,但真正的价值在于将这些能力转化为业务发展的动力。
当我们下次面对性能挑战时,相信KingbaseES提供的这套完整解决方案------从精准的诊断工具到深度的优化建议,从稳定的基础架构到智能的调优能力。选择KingbaseES,不仅是选择了一个高性能的数据库产品,更是选择了一个值得信赖的技术伙伴。
让我们携手金仓数据库,共同打造更快、更稳、更强的数据底座,为企业的数字化转型注入源源不断的动力!