系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、CLIP
-
- 1、前言
- 2、图片-文本对数据集的使用逻辑
- 3、预训练伪代码
- [4、Contrastive pre-training对比预训练](#4、Contrastive pre-training对比预训练)
- [5、Create dataset classifier from label text根据标签文本创建数据集分类器](#5、Create dataset classifier from label text根据标签文本创建数据集分类器)
- [6、Use for zero-shot prediction用于零样本迁移预测](#6、Use for zero-shot prediction用于零样本迁移预测)
- 7、prompt工程
- 8、效果评测
- 二、ViLT
- 三、ALBEF
- 四、VLMo
- 五、BLIP
- 未完待续...
前言
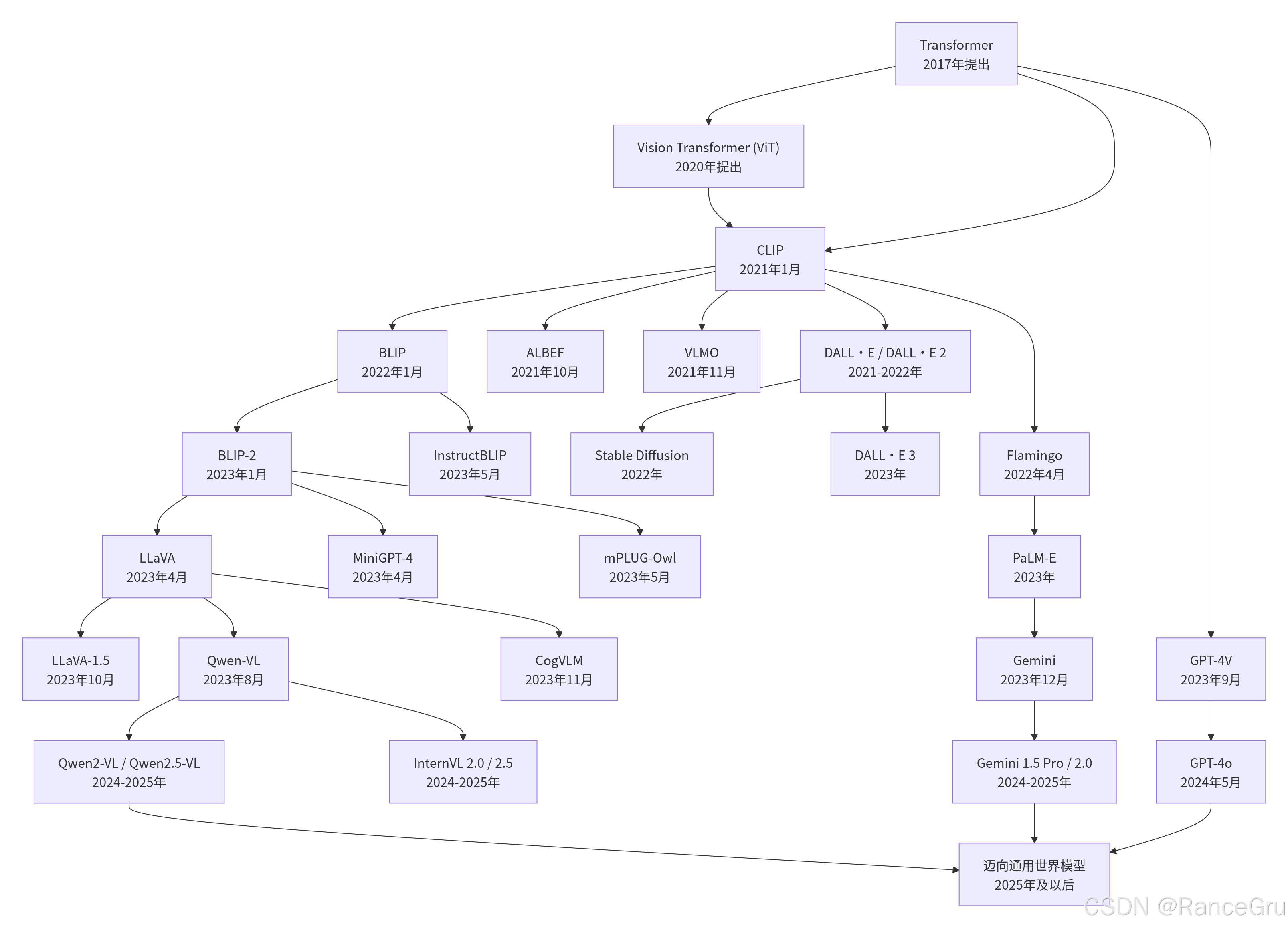
2017年提出的Transformer架构,凭借其强大的自注意力机制和并行计算能力,在自然语言处理领域引发革命,催生了BERT、GPT等大语言模型。然而,其真正迈向多模态的关键一步,是2020年ViT的诞生。ViT创新性地将图像分割为小块并序列化,使标准的Transformer能够直接处理图像,首次证明了纯Transformer架构在大规模数据下可以超越传统的卷积神经网络,打破了视觉任务对CNN的长期依赖。这一突破实现了视觉与语言在模型架构上的统一,为跨模态建模提供了共同的技术底座。
基于Transformer和ViT奠定的统一架构,多模态模型迎来了爆发期。2021年,CLIP通过对比学习联合训练文本和图像编码器,实现了强大的跨模态理解能力;DALL·E则展示了文本生成图像的惊人潜力。此后,模型朝着统一多模态架构、高效轻量化和全模态交互方向快速发展,标志着AI从单一模态感知进入了能够协同理解、生成文本、图像、音频等多模态信息的通用智能新阶段。
一、CLIP
1、前言
一个常规的视觉任务比如目标检测与分类工作,它都是有固定的提前定义好的类别标签集合,然后使用与类别相关的数据集训练得到一个模型,再根据这个模型去预测这些类别标签集合,但是却无法预测这个类别集合之外的类别标签。比如像ImageNet数据集提前定义了1000个固定类别,使用神经网络和数据集定义好的监督信号去训练的模型也只能去预测这1000个类别,但是对于这1000个类别之外的目标就无能为力了。这种有限制性的数据和训练虽然简化了训练工作,但是也限制了模型本身的泛化能力。
而CLIP工作则使用一个简单的预训练任务,给定一份配对的图片和句子,让模型学习图片与句子的联系,通过这种方式去学习图像的表征。这里的图片和句子一定是要进行配对的,所以CLIP制作了一个私有的400 million大小的图片-文本配对数据集,实现通过自然语言作为监督信号去训练视觉模型的工作。对比两种工作,CLIP的监督信号实现相对简单,且有利于zero-shot,相比使用有监督实现的视觉任务会更轻松。
有监督、无监督、自监督和弱监督是机器学习中基于训练数据标签情况的不同范式,其核心区别在于对标签的依赖程度和利用方式:
-
有监督学习
定义:使用大量带有人工标注标签的数据进行训练。模型学习输入数据(特征)与对应输出(标签)之间的映射关系。
-
无监督学习
定义:使用完全没有标签的数据进行训练。模型通过挖掘数据内在的结构、模式或分布来学习,不针对特定下游任务。
-
自监督学习
定义:属于无监督学习的一个分支。它使用无标签数据,但通过设计辅助任务,从数据自身构造出"伪标签"来进行训练。
-
弱监督学习
定义:使用带有噪声、不完整或不精确标签的数据(即"弱标签")来训练模型,以完成一个需要"强标签"(更精确、更丰富标签)的任务。
所以CLIP归属为一种弱监督模型。
2、图片-文本对数据集的使用逻辑
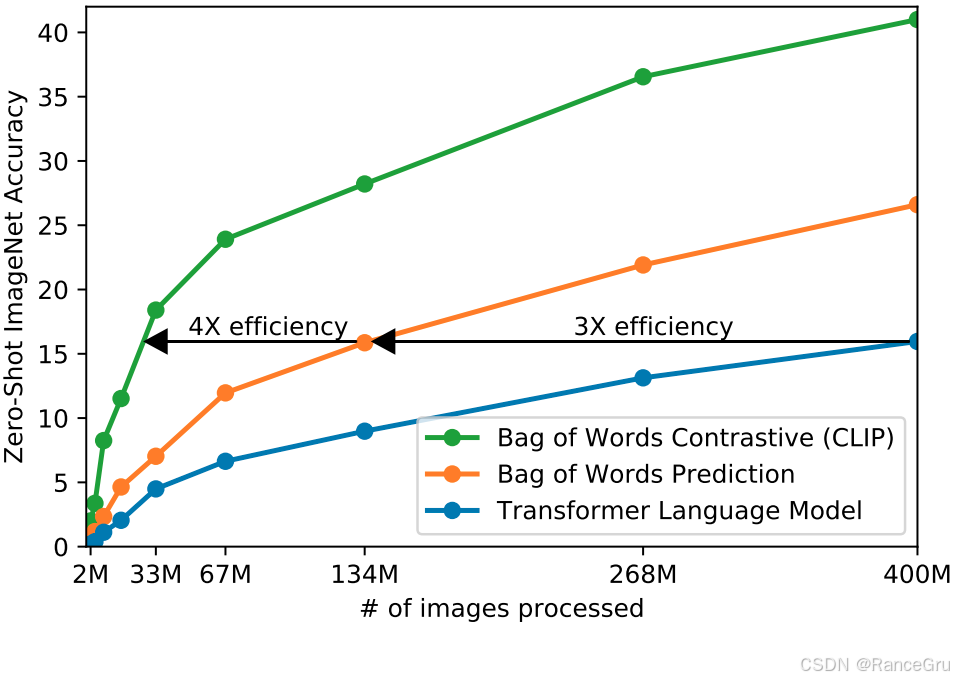
对于一个图片-文本对数据,如何利用它们之间的联系进行训练,openai构思了三种方法:
-
Transformer Language Model
一种自回归Transformer的预测模型。给定一张图片,通过自回归训练去预测所对应的文本。
但是对于一张图片而言,可以通过很多种角度去描述它,不同角度的描述文本之间的差距可能会很大,如果用自回归的方式去预测图片的对应文本,那么能够预测的输出太多了,导致训练会非常慢。
-
Bag of Words Prediction
一种基于"词袋"表示的预测模型。它试图预测与图像配对的文本描述中的词语。尝试放宽图片-文本的约束条件,使用自回归的方式去预测所有可能的相关词汇,这些词汇不需要按照严格的文本形式排列。约束放宽以后训练效率提高了三倍。
-
Bag of Words Contrastive (CLIP)
一种基于对比学习的对比模型,直接学习图像和其对应文本描述之间的匹配关系。继续放宽图片-文本的约束条件,不再使用自回归的方式去预测图片的对应文本,只要文本的描述和图片是对应的即可。约束放宽以后训练效率提高了四倍。
3、预训练伪代码
bash
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2- image_encoder:表示图像编码器,主要使用ResNet或者VIT将原始数据转换成特征向量。
- text_encoder:表示文本编码器,主要使用CBOW或者Transformer将原始数据转换成特征向量。
- In, h, w, c:表示一个批次的n个对齐的图像。n表示批次大小,hw表示图像高宽,c表示图像通道数。
- Tn, l:表示一个批次的n个对齐的文本。n表示批次大小,l表示文本序列的长度。
- I_f:表示图像原始数据经过编码器转换得到的特征向量。其形状为n, d_i,其中 d_i是图像特征的维度。
- T_f:表示文本原始数据经过编码器转换得到的特征向量。其形状为n, d_t,其中 d_t是文本特征的维度。
- W_id_i, d_e:表示可学习的图像线性投影矩阵,分别将d_i维度的图像特征向量映射到d_e维度的多模态共享嵌入空间中。
- W_td_t, d_e:表示可学习的文本线性投影矩阵,分别将d_t维度的文本特征向量映射到d_e维度的多模态共享嵌入空间中。
- t:表示可学习的温度参数。
- np.dot:用于计算两个矩阵的矩阵乘积。
- np.exp:用于计算自然指数函数。
- np.arange:用于创建等差数列,目的是返回一个有终点和起点的固定步长的排列。
- l2_normalize:表示L2归一化,即对投影后的向量进行L2归一化。
- I_e:表示将图像编码器提取的特征 I_f,通过可学习的投影矩阵 W_i线性变换到共享嵌入空间,然后进行 L2 归一化,最终转换为单位向量。即一个形状为 n, d_e的矩阵,其中每一行代表一张图像在 d_e维共享空间中的单位向量表示。
- T_e:表示将文本编码器提取的特征T_f,通过可学习的投影矩阵 W_t线性变换到共享嵌入空间,然后进行 L2 归一化,最终转换为单位向量。即一个形状为 n, d_e的矩阵,其中每一行代表一句文本在 d_e维共享空间中的单位向量表示。
- logits:一个 n, n 的矩阵,其元素是经过温度参数缩放后的图像-文本对之间的余弦相似度。
- labels:表示一个从 0到 n-1的标签数组
- cross_entropy_loss:表示交叉熵损失。
- loss_i:表示图像到文本的对比损失。将 logits矩阵的每一列的对应文本视为一个分类器的输出,目标是将正确的图像分类出来。
- loss_t:表示文本到图像的对比损失。将 logits矩阵的每一行的对应图像视为一个分类器的输出,目标是将正确的文本分类出来。
- loss:表示对称对比损失。既要求每个图像找到其匹配的文本,也要求每个文本找到其匹配的图像
4、Contrastive pre-training对比预训练

- 将n个文本输入经过 Text Encoder文本编码器转换为一组数值向量,表示为 T1, T2, ..., TN。
- 将n张图片输入经过 Image Encoder图像编码器转换为一组数值向量,表示为 I1, I2, ..., IN。
- 将每个图像与文本向量映射到大小一致的共享矩阵中。
- 通过对比损失函数,让匹配的图文对向量彼此靠近,不匹配的彼此远离。
- 经过对比对称处理,矩阵中心对角线上的元素是正确的配对,称为正样本。矩阵非对角线上的元素则是错误的配对,称为负样本。
- 根据得到的正负样本进行对比训练,最终CLIP训练出来一个文本编码器和一个图像编码器。这两个编码器能够将图像和文本映射到同一个共享的语义向量空间中,从而实现零样本的图像分类、跨模态检索等任务。
5、Create dataset classifier from label text根据标签文本创建数据集分类器
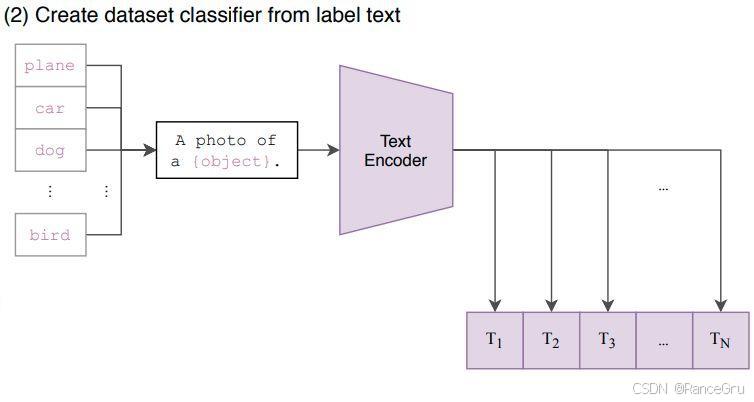
- 根据需求创建一个标签文本集,比如想对ImageNet数据集中的图片进行分类任务,那么就需要创建1000个词语的标签文本集。
- 根据标签文本集和提前构建好的prompt template提示模板,将每一个词语转换为一个句子,1000个词语就会有1000个句子。
- 根据得到的句子和CLIP训练得到的文本编码器,将每个句子转换为一个对应的特征向量,1000个句子就会有1000个特征向量。
6、Use for zero-shot prediction用于零样本迁移预测
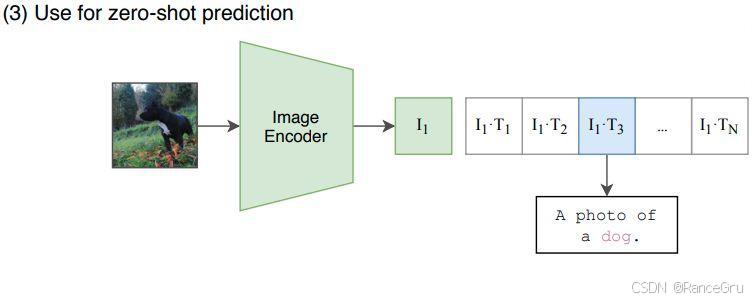
- 传入一张图片,根据CLIP训练出来的图像编码器将图片转换为一个特征向量。
- 根据转换得到的图像特征向量与以上文本编码器编码得到的n个文本特征向量进行一一比对,计算图像特征向量 I 1 I_1 I1与每一个文本特征向量 T 1 , T 2 , T 3 , . . . , T n T_1,T_2,T_3,...,T_n T1,T2,T3,...,Tn的相似度。
- 最后使用一个softmax计算概率分布,得到一个相似度最接近的一个图片-文本对。
7、prompt工程
之所以要把一个标签词语通过prompt扩展成一个句子,目的是通过句子的上下文去避免对词语的歧义理解,因为简单的词语往往可能带有多种解释,比如门户可能是指房门,也可能是指互联网入口。这样通过上下文来确定指向的是什么东西。
所以CLIP工作涉及到了一个prompt工程,可以根据一些已知信息去定制对应的prompt,使得句子更加明确,比如数据来源是一个黑白数据集,那么就可以扩展为'a black and white photo of the {}.',来源是玩具数据集,那么就可以扩展为'a toy {}.'等等。CLIP的具体prompt句子模板如下:
bash
"source": [
"imagenet_templates = [\n",
" 'a bad photo of a {}.',\n",
" 'a photo of many {}.',\n",
" 'a sculpture of a {}.',\n",
" 'a photo of the hard to see {}.',\n",
" 'a low resolution photo of the {}.',\n",
" 'a rendering of a {}.',\n",
" 'graffiti of a {}.',\n",
" 'a bad photo of the {}.',\n",
" 'a cropped photo of the {}.',\n",
" 'a tattoo of a {}.',\n",
" 'the embroidered {}.',\n",
" 'a photo of a hard to see {}.',\n",
" 'a bright photo of a {}.',\n",
" 'a photo of a clean {}.',\n",
" 'a photo of a dirty {}.',\n",
" 'a dark photo of the {}.',\n",
" 'a drawing of a {}.',\n",
" 'a photo of my {}.',\n",
" 'the plastic {}.',\n",
" 'a photo of the cool {}.',\n",
" 'a close-up photo of a {}.',\n",
" 'a black and white photo of the {}.',\n",
" 'a painting of the {}.',\n",
" 'a painting of a {}.',\n",
" 'a pixelated photo of the {}.',\n",
" 'a sculpture of the {}.',\n",
" 'a bright photo of the {}.',\n",
" 'a cropped photo of a {}.',\n",
" 'a plastic {}.',\n",
" 'a photo of the dirty {}.',\n",
" 'a jpeg corrupted photo of a {}.',\n",
" 'a blurry photo of the {}.',\n",
" 'a photo of the {}.',\n",
" 'a good photo of the {}.',\n",
" 'a rendering of the {}.',\n",
" 'a {} in a video game.',\n",
" 'a photo of one {}.',\n",
" 'a doodle of a {}.',\n",
" 'a close-up photo of the {}.',\n",
" 'a photo of a {}.',\n",
" 'the origami {}.',\n",
" 'the {} in a video game.',\n",
" 'a sketch of a {}.',\n",
" 'a doodle of the {}.',\n",
" 'a origami {}.',\n",
" 'a low resolution photo of a {}.',\n",
" 'the toy {}.',\n",
" 'a rendition of the {}.',\n",
" 'a photo of the clean {}.',\n",
" 'a photo of a large {}.',\n",
" 'a rendition of a {}.',\n",
" 'a photo of a nice {}.',\n",
" 'a photo of a weird {}.',\n",
" 'a blurry photo of a {}.',\n",
" 'a cartoon {}.',\n",
" 'art of a {}.',\n",
" 'a sketch of the {}.',\n",
" 'a embroidered {}.',\n",
" 'a pixelated photo of a {}.',\n",
" 'itap of the {}.',\n",
" 'a jpeg corrupted photo of the {}.',\n",
" 'a good photo of a {}.',\n",
" 'a plushie {}.',\n",
" 'a photo of the nice {}.',\n",
" 'a photo of the small {}.',\n",
" 'a photo of the weird {}.',\n",
" 'the cartoon {}.',\n",
" 'art of the {}.',\n",
" 'a drawing of the {}.',\n",
" 'a photo of the large {}.',\n",
" 'a black and white photo of a {}.',\n",
" 'the plushie {}.',\n",
" 'a dark photo of a {}.',\n",
" 'itap of a {}.',\n",
" 'graffiti of the {}.',\n",
" 'a toy {}.',\n",
" 'itap of my {}.',\n",
" 'a photo of a cool {}.',\n",
" 'a photo of a small {}.',\n",
" 'a tattoo of the {}.',\n",
"]\n",8、效果评测
以下是根据CLIP的zero-shot和resnet50的linear probe在不同数据集中的表现对比:
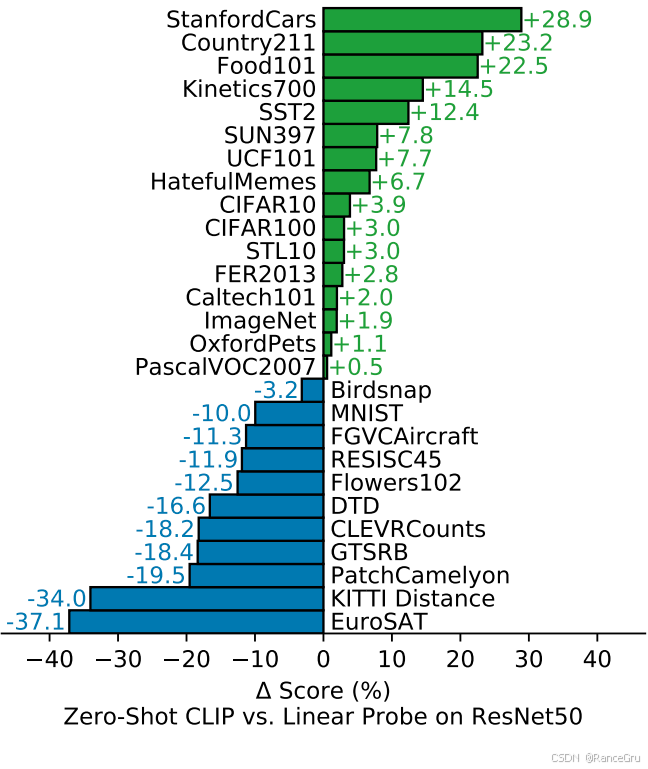
对于具有文本可描述性的数据集,CLIP在zero-shot上的效果能够保持较好的能力,但是对于更抽象更精细任务的特定领域的数据集而言,CLIP可能经过few-shot处理会更好。
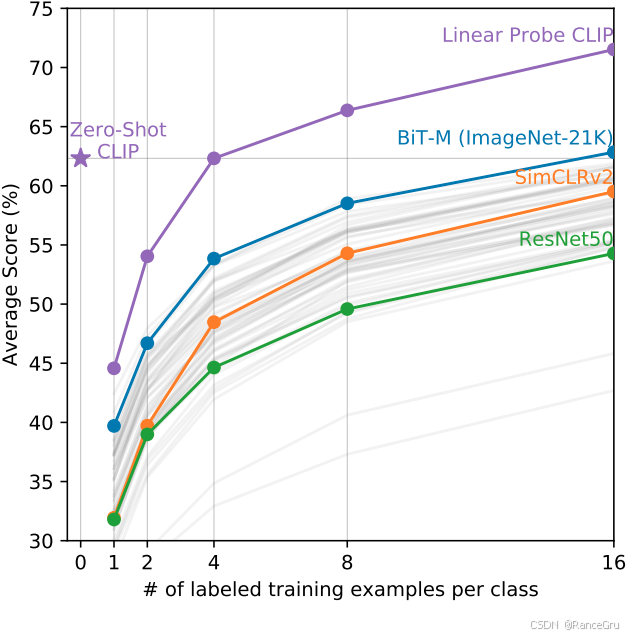
所以CLIP也进行了few-shot测试,对CLIP的图片编码器进行冻结主干微调分类头,在横坐标上从学习0个类的带标签数据到学习16个类的带标签数据,微调出来的模型在纵坐标上的准确率进行对比,可以发现随着微调训练样本类的增多,CLIP在某些时候few-shot的能力会比zero-shot的能力更强。所以在某些时候,如果zero-shot效果不佳,也可以尝试few-shot处理。
二、ViLT
1、前言
当前多模态领域主要采取先进行预训练,然后再进行少样本微调或者零样本迁移。在这种情况下,预训练的质量与效率就变得格外重要,如果能提供一个较好的预训练模型,甚至不需要微调就能够直接zero-shot实现不错的下游工作。
在多模态训练中主要包括不同模态的特征提取和模态共享空间中的交互融合两个过程,可是此前的视觉和语言预训练VLP图像特征提取方法非常臃肿,其中大部分工作中的图像特征提取都涉及区域检测和卷积架构。但是这种方式一方面导致效率低下,因为有些特征提取工作甚至比多模态交互工作占用更多的计算。另一方面导致特征表达能力不统一,因为模型的上限取决于视觉嵌入器及其预定义视觉词汇的表达能力
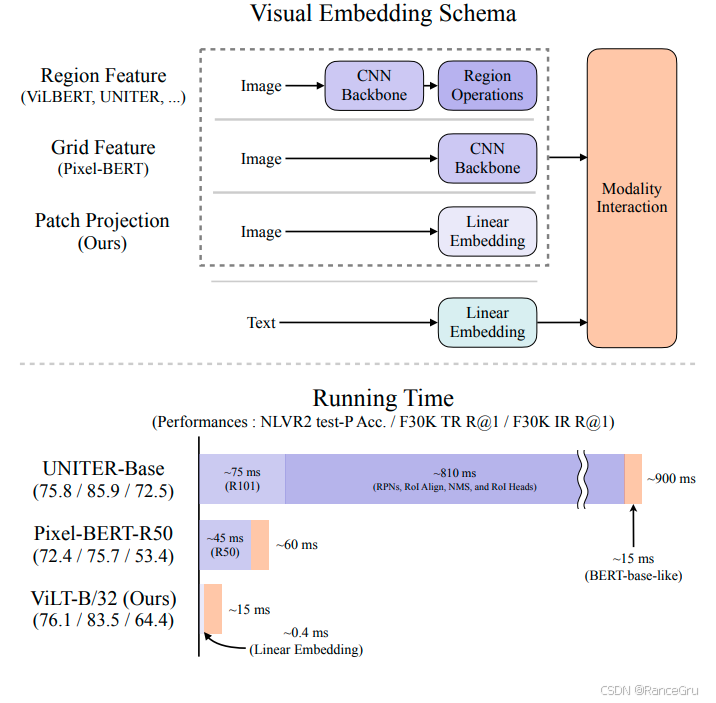
-
Region Feature区域特征
ViLBERT, UNITER 等模型主要将输入图像传入CNN骨干网络进行训练,然后根据物体边界提取区域特征,最终结合文本的线性嵌入特征在多模态共享空间进行模态交互。这种方法非常复杂,需要依赖预训练的目标检测器来提取目标区域的特征,导致流程冗长。
-
Grid Feature网格特征
Pixel-BERT等模型将输入图像传入CNN骨干网络进行训练,然后直接从卷积特征图获取网格特征,再结合文本的线性嵌入特征在多模态共享空间进行模态交互。这种方法简化了一步,跳过了耗时的区域检测操作,直接使用CNN的整个特征图。
-
Patch Projection图像分块线性投影
ViLT等模型将输入图像分割成小块,再经过展平、线性投影等操作实现线性嵌入,然后结合文本的线性嵌入特征在多模态共享空间进行模态交互。这种方法移除了CNN骨干网络,对图像使用了线性变换进行嵌入,使得视觉和文本的特征提取方式在底层实现了统一。
2、VLP不同架构设计思路
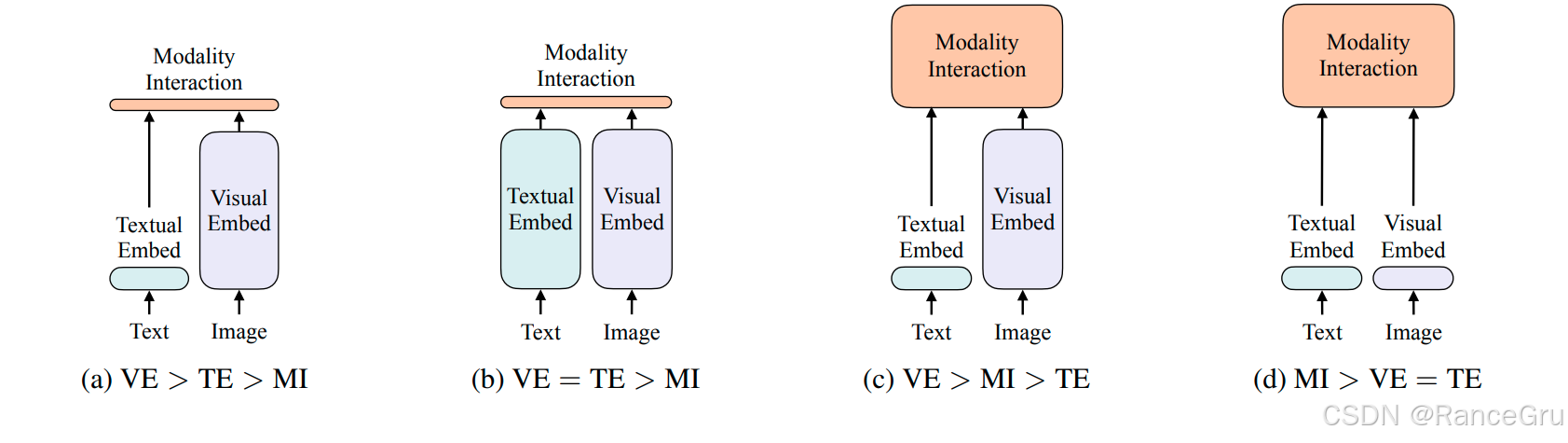
以上图片主要从视觉嵌入VE、文本嵌入TE和模态交互MI的角度出发,阐述在不同架构中这三者的权重变化。
-
a类型VE > TE > MI
这是一种以视觉为主导的架构。模型首先通过神经网络深入提取视觉图像的特征信息,然后再简单提取文本的线性嵌入特征,着重挖掘视觉图像内的细节信息。最后将两者简单地结合起来,在浅层的多模态共享空间中进行简单的模态交互融合。
-
b类型VE = TE > MI
这是一种以视觉与文本并重的架构。模型首先通过神经网络深入提取视觉图像的特征信息,然后再通过神经网络深入提取文本的线性嵌入特征,充分挖掘各自模态内的细节信息。最后将两者简单地结合起来,在浅层的多模态共享空间中进行简单的模态交互融合。
-
c类型VE > MI > TE
这是一种以视觉为主导的架构。模型首先通过神经网络深入提取视觉图像的特征信息,然后再简单提取文本的线性嵌入特征,着重挖掘视觉图像内的细节信息。最后将两者深度地结合起来,在深层的多模态共享空间中进行深入的模态交互融合。
-
d类型MI > VE = TE
这是一种以视觉与文本并重的架构。模型首先简单将图像转换为线性嵌入,然后简单将文本转换为线性嵌入,不再着重前期的特征挖掘。最后将两者深度的结合起来,在深层的多模态共享空间中进行模态交互融合。
3、模型结构
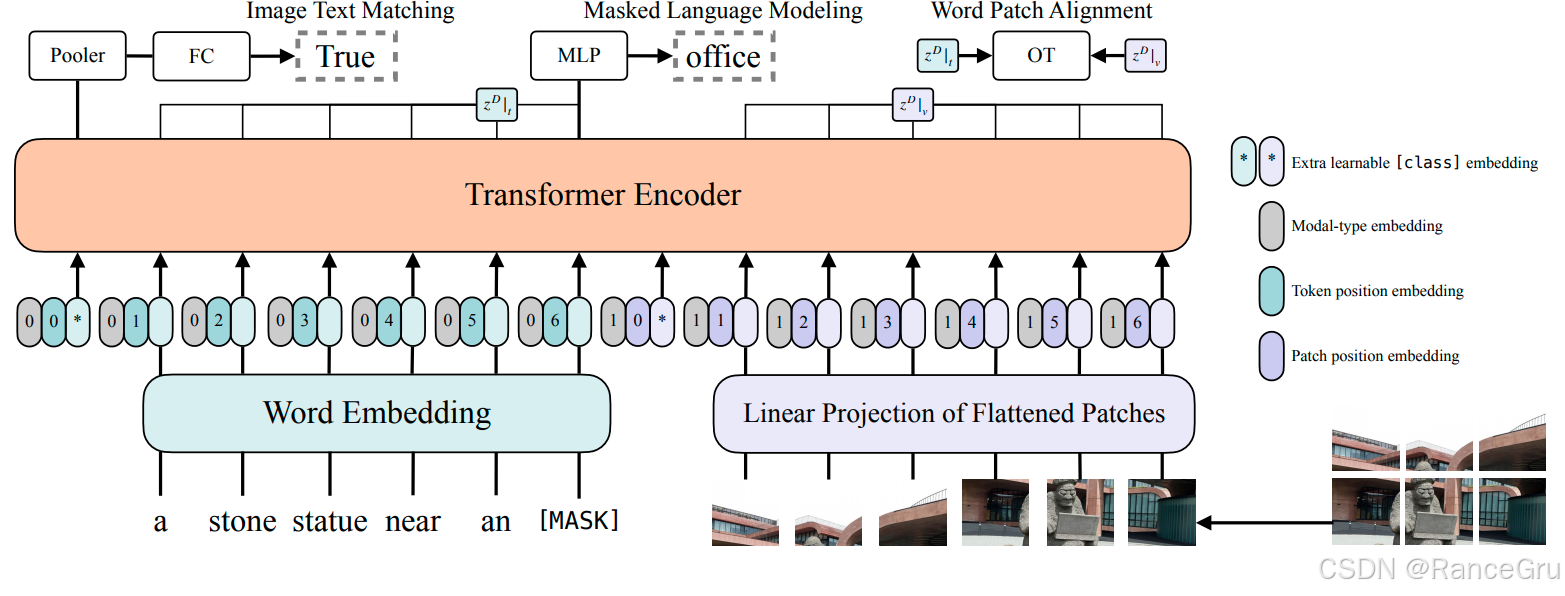
-
Word Embedding单词嵌入
将文本中的每个单词转换成一个固定维度的特征向量。最后通过一个线性投影层将这些特征向量映射多模态共享向量空间。
-
Linear Projection of Flattened Patches展平图像块的线性投影
将一张图片均匀切割成多个小方块,然后将每个方块展平为一维向量,最后通过一个线性投影层将这些特征向量映射多模态共享向量空间。这里使用的是ViT的处理方式
-
Extra learnable class embedding额外的可学习类别嵌入
一个特殊的、可训练的向量,通常预先添加在输入序列的CLS位置。在Transformer编码过程中,这个标记会聚合整个输入序列的全局语义。
-
Modal-type embedding
一个用于标识向量来源的嵌入。通常会为所有文本部分的向量加上同一个"0"嵌入,为所有图像部分的向量加上同一个"1"嵌入。告诉模型当前处理的向量是来自文本还是图像。
-
Token position embedding词元位置嵌入
为文本序列中的每一个单词添加一个表示其在原始句子中的位置向量。
-
Patch position embedding图像块位置嵌入
为图像序列中的每一个图像块添加一个表示其在原始图片中空间位置向量。
-
Transformer Encoder编码器
一个由多层自注意力机制和前馈神经网络堆叠而成的模型结构。
-
Image Text Matching图文匹配任务
一个二分类任务,判断输入的图片和文字描述是否相关。使用Pooler池化层+FC全连接层实现一个二分类判断。
-
Masked Language Modeling掩码语言建模任务
一个完形填空任务,使用MASK随机遮盖输入文本中的部分词语,让模型根据图片信息预测被遮盖的词。使用MLP多层感知机接收被遮盖位置对应的Transformer输出向量。
-
Word Patch Alignment词-块对齐任务
一个细粒度对齐任务,衡量文本中的每个词与图像中的每个块之间的相关性。使用OT最优传输方法计算两个向量分布之间的最小成本匹配。
4、损失函数
WPA、ITC、MLM和ITM是多模态视觉-视觉语言预训练模型中常见的几种Loss损失函数,它们各自服务于不同的训练目标和任务,共同促进模型学习图文对齐与理解。

-
Word-Patch Alignment Loss
词-块对齐损失,核目标是实现图像分割的图像块与文本描述中具体单词之间的细粒度对齐,它不满足于图像和文本的全局匹配,而是试图建立"图像的这一部分"对应"文本的这个词"的精确映射。如上图所示。
能促使模型学习到图像内容与文本描述之间更精细、更准确的对应关系,对于某些需要理解细节的下游任务有潜在好处。但是计算成本极高,需要对图像块和文本单词进行密集的匹配计算,训练速度非常慢。
-
Image-Text Contrastive Loss
图像-文本对比损失,是对比学习在多模态领域的典型应用,能够拉近匹配图像-文本对在共享嵌入空间中的距离,同时推远不匹配对的距离,实现不同模态在多模态共享空间中的快速对齐。
能够利用海量的弱监督网络数据,高效地将图像和文本的表征映射到统一的语义空间。直接有效的相似度度量在零样本迁移的图像-文本检索任务上表现卓越。但是只关注全局匹配,缺乏对模态内部及跨模态细粒度关系的建模能力,而且如果训练数据中存在大量图文不匹配的噪声,这种简单的对比学习会容易受到误导。
-
Masked Language Modeling Loss
掩码语言建模损失,是自然语言处理的经典预训练任务,主要是在文本中随机掩盖部分词语,让模型根据剩余的文本上下文和对应的图像信息来预测被掩盖的词语,常作用于多模态编码器,是促成深度融合的核心任务之一。
能够迫使模型整合视觉信息来理解并补全文本,从而学习到视觉概念与语言词汇之间的深层关联。与自回归生成不同,MLM允许模型利用被掩盖词左右两侧的上下文,获得更丰富的语义表示。并且通过预测不完整信息,能提高模型在信息缺失情况下的推理能力。虽然能在预训练时使用了特殊的MASK标记,但下游任务微调时通常没有,可能导致预训练-微调之间的差异。
-
Image-Text Matching Loss
图像-文本匹配损失,是一个二分类任务,模型需要根据图像和文本的融合特征,判断它们是否匹配或不匹配,主要作用于多模态编码器,是另一个促进多模态融合的关键任务。
可以直接优化匹配判断能力,使模型能够更精确地理解图文之间的一致性,这对视觉问答、推理等任务至关重要,还可以利用ITC分数挑选那些与正样本相似度高、容易混淆的"难负样本"来计算损失,从而大幅提升模型的判别力。这二分类任务很大程度上依赖于正负样本的构建质量,如果只是简单随机的替换图像-文本对会导致学习到的信息相对有限,不足以让模型学到复杂的不匹配关系。
5、创新与局限
创新:
-
架构极简,推理效率高
视觉处理轻量化:完全摒弃了传统多模态模型中复杂的CNN视觉编码器,仅通过一个ViT线性投影层将图像分割转换转换为向量。这使得模型在推理时能大大提高效率。其次统一使用了单流Transformer,图像和文本token在输入层就进行拼接,通过一个共享的Transformer编码器进行处理。这种设计简化了模型结构,实现了真正的端到端训练。
-
模态融合早且深
早期深度融合:图像和文本信息在模型的最底层就开始通过自注意力机制进行交互,允许两种模态在多个Transformer层中进行充分、深度的双向信息交换。这使得模型在需要深度理解图文关系的任务如视觉问答、自然语言视觉推理上具有理论优势。
-
高效的目标函数
结合ITM与MLM:除了基础的图像-文本匹配ITM损失外,还使用了掩码语言建模MLM,迫使模型利用视觉上下文来预测被掩码的文本,增强了跨模态的语义对齐能力。
局限:
-
视觉特征提取能力较弱
视觉图像的细节信息的丢失:只是简单的对图像进行线性投影,无法像CLIP的ViT或CNN目标检测器那样深入提取丰富的视觉特征。导致面对需要精细视觉感知的任务时表现不佳。因为一张图像蕴含的信息往往会比一句文本蕴含的信息丰富,所以图像编码器往往需要比文本编码器要大,提取的深度更深,这样才能提取出更有用的信息,如果只是简单的进行线性投影可能导致文本无法对齐到图片中的部分细节信息。
-
实际性能与效率的权衡
实际效率与推理效率的不平衡:虽然前期特征提取层的参数少,但由于是单流架构,每次都需要对图像文本的线性投影进行完整的跨模态计算,面对同一张图片不同文本时都需要重新计算。不像CLIP那样,可以计算并缓存同一张图像特征,面对不同文本只需要重新计算文本的线性投影,而且CLIP的模态融合计算也是相当简单。所以在实际下游任务中的工作效率和零样本泛化能力可能反而不如CLIP。
三、ALBEF
1、前言
在多模态领域的视觉语言预训练工作中,大多数旧的VLP方法是使用目标检测器对视觉图像进行特征提取和编码,使用Transformer编码器对语言文本进行特征提取与编码,然后再统一输入到多模态共享空间中进行融合。但使用不同的编码器可能会使图像和文本的特征处于不同的语义空间,并且使用目标检测器提取的图像特征会更深更抽象,与简单提取的文本编码特征会相差很远,导致难以有效学习跨模态交互。就好比同样是语言,汉语和英语虽然能够相互对应,但是天然存在一种形态上隔阂。
其次目标检测器大多是基于CNN神经网络实现的,不仅需要进行人工标注边界框,而且需要高分辨率图像,计算代价大。所以很多新方法开始使用Transformer架构去作为统一编码器,也就是使用Transformer编码器同时对视觉图像和语言文本进行编码。然后没有进行对齐就直接传入多模态共享空间进行融合,可能导致图文匹配的精度受限。
另外预训练使用的网络图像-文本数据含有大量噪声,也就是文本并没有很好或者甚至没有去描述图片,导致传统的掩码语言建模等目标容易过拟合噪声文本,降低模型泛化能力。
最终尝试进行多任务联合训练,能同时提升表征对齐和深层理解的能力。
2、模型结构
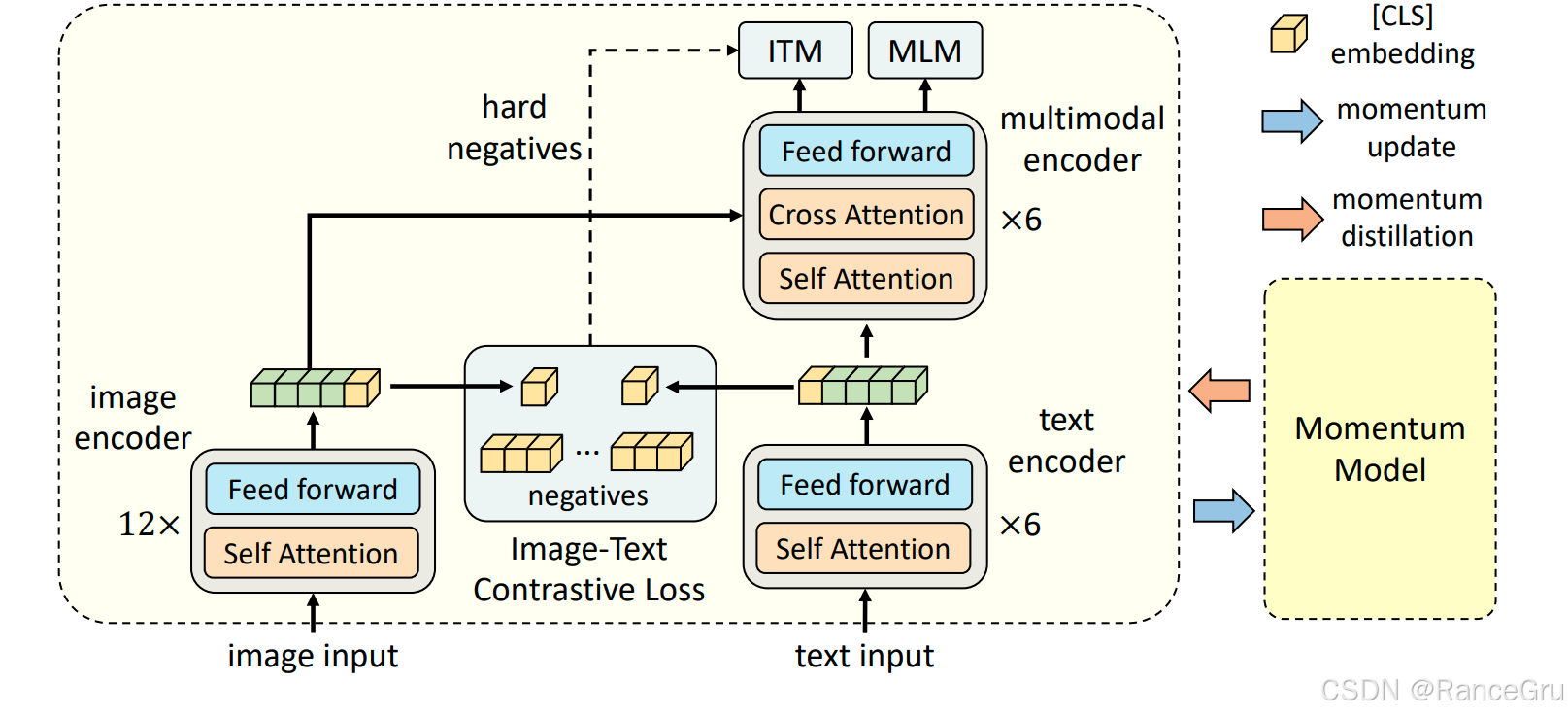
-
image input图片输入、text input文本输入
表示原始图像输入和原始文本输入。
-
image encoder图像编码器、text encoder文本编码器
表示一个tansformer模型结构。用于将原始图像数据和原始文本数据转换为一个形状一致的特征矩阵。
-
Feed forward前馈网络
表示前馈神经网络FFN,也叫作多层感知机MLP。是前向传播的前提。
-
Self Attention自注意力机制
表示自注意力机制。对于输入序列中的每个位置,其Query、Key、Value都由该序列自身通过线性变换得到。让序列中的每个词都能关注到序列中的所有其他词,从而捕捉长距离依赖和上下文信息。
-
Cross Attention交叉注意力机制
表示交叉注意力机制。对于输入序列中的每个位置,其Query来自一个序列,而Key和Value来自另一个序列。建立两个不同模态或序列之间的对齐关系,让目标序列的每个位置能够有选择地关注源序列的相关部分。
-
CLS embedding类嵌入
表示一个结合了位置信息和上下文信息的初始嵌入。将原始数据投入embedding后会转换得到一个初始序列,这个初始序列由开头的一个带有位置编码信息的token和后续的token组成。将初始序列输入到多层Transformer编码器后,在每一层的自注意力机制中,CLS token会与序列中的所有其他token进行交互,从而聚合整个序列的上下文信息。
-
negatives负样本
表示负样本。在对比学习中,模型需要学会将匹配的图像-文本对拉近,将不匹配的图像-文本对推远。这里通常指从当前训练批次中随机选取的其他不配对样本。
-
hard negatives难负样本
表示难负样本。特指那些与正样本在语义上相似,但实际上并不匹配的负样本。在对比学习中会将正样本拉近,负样本推远,但是在负样本中有的可以推的很远的,也有推的不是很远的,这些趋近于正样本的负样本被采集出来当做难负样本。通过让模型特别关注和区分这些难负样本,可以迫使模型学习更精细、更本质的语义特征,而不是依赖浅层或虚假的关联,从而极大提升模型的判别能力和鲁棒性。
-
multimodal encoder多模态编码器
表示多模态共享向量空间。不同模态的数据将会在这里融合学习。
-
ITC Image-Text Contrastive Loss
表示图像-文本对比损失。是对比学习在多模态领域的典型应用,能够拉近匹配图像-文本对在共享嵌入空间中的距离,同时推远不匹配对的距离,实现不同模态在多模态共享空间中的快速对齐。
-
ITM Image-Text Matching Loss
表示图像-文本匹配损失。是一个二分类任务,模型需要根据图像和文本的融合特征,判断它们是否匹配,主要作用于多模态编码器,是另一个促进多模态融合的关键任务。
-
MLM Masked Language Modeling Loss
表示掩码语言建模损失。是自然语言处理的经典预训练任务,主要是在文本中随机掩盖部分词语,让模型根据剩余的文本上下文和对应的图像信息来预测被掩盖的词语,常作用于多模态编码器,是促成深度融合的核心任务之一。
-
Momentum Model动量模型
表示一个动量模型。在训练开始时,动量模型的结构与主模型完全相同。它的参数是通过直接复制主模型的参数来初始化的。动量模型不通过梯度下降直接更新,而是作为一个稳定、缓慢变化的目标生成器。为主模型提供更一致、噪声更少的监督信号。
-
momentum update动量更新
表示动量模型参数的更新方式。动量模型的参数不会通过自身的损失函数反向传播来更新,而是通过一种特殊的EMA指数移动平均方式来缓慢地向主模型的参数靠拢。通过长期且少量的汲取主模型参数,使得动量模型获取到主模型的长期、平滑的平均状态。这种方法让动量模型比主模型更稳定,不容易受到单批训练数据噪声的干扰,从而能为主模型提供一个更可靠的、不会快速变化的学习目标。
-
momentum distillation动量蒸馏
表示知识从动量模型流向主模型的过程。当主模型计算某些任务时,不仅要匹配真实标签,还要匹配动量模型输出的特征或概率分布。将动量模型学到的更稳定、更丰富的表征知识蒸馏到主模型中。以帮助主模型学习到更鲁棒、更通用的特征,尤其在处理大量含有噪声的网络数据时,可以有效防止主模型学到错误或脆弱的关联。
首先将原始图像和原始文本数据分别输入到对应的编码器中,其中一张图片蕴含的信息通常会比一句文本蕴含的信息丰富,所以图片的编码需要比文本的编码更深,这要才有可能挖掘到同等分量的特征信息。
图像编码器是采用一个标准的12层ViT base模型,就是将原始图片分割为patch图像块,然后经过Embedding转换为一个由cls token和n个图形块token组成的序列,最后在ViT模型内部中训练学习。
文本编码器是采用一个对半切分的6层BERT模型,使用前面6层做文本编码,使用Tokenizer分词器将一句文本转换为一个由cls token和n个词语token组成的序列,最后在BERT模型内部中训练学习。
如果输入的是一对配对的图像-文本对,那么这些数据通过对应的编码器能得到一个图像序列一个文本序列。将两个序列中的cls token分别进行提取与处理,这些cls token中蕴含了对应数据的位置信息和全局特征。将两个cls token即为正样本对,与其他cls token的排列形成负样本对。则这些negatives负样本则来源于Momentum Model动量模型。最终根据正样本对与负样本对进行ITC loss相近度计算,学习图像数据与文本数据之间的距离。
multimodal encoder多模态共享向量空间编码器是由BERT的后六层组成的,不同模态的样本序列对经过Cross Attention交叉注意力机制进行融合,然后使用ITM Loss和MLM Loss进行拟合。
ITM Loss是一个二分类任务,就是判断图像序列与文本序列是否匹配,负样本往往比正样本多得多,但是大多数负样本对都是很容易就可以判断出来的,导致loss拟合得太快学不到更深入的信息。所以需要寻找一些非常接近正样本的负样本,称为难负样本,这个难负样本主要是根据ITC loss计算的相近度相似度进行选取的,也就是除了正样本之外距离最近最高的那个文本为难负样本。ITM Loss在面对这种非常接近正样本的文本时就需要格外小心,不再像之前那些随机负样本那样能轻松判断了。
MLM是完形填空任务,是自然语言处理的经典预训练任务,主要是在文本中随机掩盖部分词语,让模型根据剩余的文本上下文和对应的图像信息来预测被掩盖的词语,借助融合后的特征进行填补缺失的文本。
在ITC、ITM和MLM三个任务在前向传播中使用的都是同样的完整的图像数据,但是在文本数据中ITC和ITM使用的是完整的文本数据,而MLM使用的是带掩码的文本数据。说明每次训练需要做两次forward。一次forward是用了这个完整的图像数据和文本数据,另一次forward是用了完整的图像数据和带掩码的文本数据。这种计算多种loss和多次前行传播的流程会导致实际训练时间长,但实际在很多的多模态工作中都会有这种情况。
3、噪声数据优化

视觉-语言预训练模型通常使用从互联网自动爬取收集的海量图像-文本对。这些数据并非人工精心标注,而是通过自动化流程获得,因此天然包含多种噪声,导致这些图像的文本描述可能不客观、不精细、不完整、不准确甚至完全无关联。
在训练过程中,先针对现有模型根据Exponential Moving Average指数移动平均方式构建和维护一个动量模型,这个动量模型对当前批次数据中的随机噪声和波动不敏感且更新缓慢,能够保持输出的结果有更稳定、更平滑的表示。相当于一个不断演变的"教师",它融合了训练过程中多个历史状态的知识,而非仅依赖当前可能带噪声的批次。因此,其预测往往比单次训练中基于噪声标签的判断更合理。
所以在实际训练中会有三种标签:
数据集的实际标签,是来自网络爬取的大规模图像-文本对,通常含有噪声文本、非最优匹配文本或者不匹配文本。
ALBEF学生模型的预测标签,是当前训练中学生模型对图片预测的文本结果。
ALBEF动量模型预测的伪标签,是当前训练中动量模型对图片预测的文本结果。
一方面计算预测标签与实际标签之间的损失,另一方面计算预测标签与伪标签之间的损失,再按照权重综合计算两种损失从而得到总损失,从而引导模型的拟合方向,避免模型因为实际标签的噪声导致训练的严重偏移。
这样能够允许模型不会因为产生与噪声实际标签不同,但与动量模型伪标签一致的合理预测输出而受到严重惩罚。动量模型作为"更智慧的教师",提供了更可靠的软目标,帮助学生模型抵抗噪声数据的过拟合,学习到更鲁棒的多模态表征。
所以在ITC、MLM和ITM损失中,ITC和MLM都需要计算两次,一次是预测标签与实际标签之间的损失,另一次是预测标签与伪标签之间的损失,然后在综合计算总的ITC和MLM损失。至于ITM是在ITC的基础上进行的,已经蕴含了伪标签信息和实际标签信息,就不需要重复计算了。
四、VLMo
1、前言
像CLIP、ALBEF这种模型,采取了一个双塔结构进行特征处理,也就是一个图像模型加上一个文本模型,然后模态之间的交互就是做了一个非常简单矩阵乘法。这种方法对于检索任务来说极其有效的,因为可以提前把数据特征抽好,然后直接算矩阵乘法就好了。但是缺点也非常明显,就是过于简单矩阵乘法并没有深入的融合多模态特征,不适用多模态中的复杂任务。
除了双塔结构模型外,还有一种单塔结构模型,也就是多模态适用同一个编码器进行特征提取。通常是使用同一个编码器先把图像数据和文本数据分开训练,然后在模态交互的时候再用编码器做模态之间的交互融合,以弥补双塔模式的缺陷。但是单塔结构模型在做检索任务的时候却没有双塔结构模型那么便利,每次都需要重新计算数据特征,计算效率较低,推理时间慢。
所以VLMo工作尝试设计一个统一的模型架构,综合两种工作的优点,既能作为双编码器实现高效的图像-文本检索,又能作为融合编码器进行深层的跨模态交互。
2、模型结构
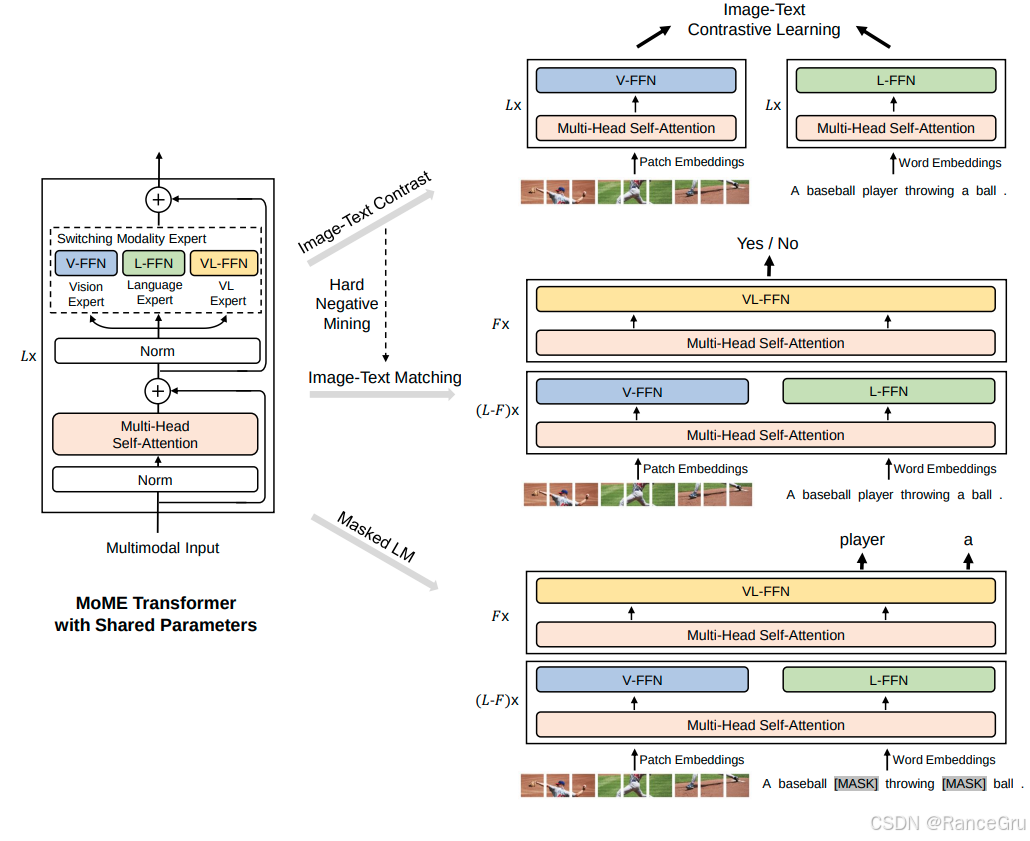
-
MoME Transformer with Shared Parameters
表示具有共享参数的模态专家混合Transformer,共享参数的意思是Multi-Head Self-Attention和Layer Normalization模块是所有模态共享的。专家是指不同模态任务是使用不同的前馈网络来灵活处理。
-
Multimodal Input多模态输入
表示支持不同模态的数据输入。
-
Norm归一化
表示LayerNorm。
-
Multi-Head Self-Attention多头自注意力机制
表示多头自注意力机制。
-
Switching Modality Expert切换模态专家
表示能够自主切换模态专家,分别是指V-FFN、L-FFN、VL-FFN这三个FFN专家网络,对于不同类型的数据会在嵌入编码后添加特定的type编码来指明数据类型,通过分析隐藏在数据中的类型信息,判断当前处理的是文本、图像还是图文对,也是根据模态类型调用不同的FFN专家。
-
Vision Expert V-FFN
表示使用纯图像数据训练的V-FFN
-
Language Expert L-FFN
表示使用纯文本数据训练的L-FFN
-
VL Expert VL-FFN
表示使用图像-文本对数据端到端训练的VL-FFN
-
Hard Negative Mining难负样本挖掘
表示难负样本挖掘,和ALBEF一样通过ITC任务挖掘更优质的负样本数据给ITM任务进行训练。
-
ITC Image-Text Contrastive Loss
表示图像-文本对比损失。是对比学习在多模态领域的典型应用,能够拉近匹配图像-文本对在共享嵌入空间中的距离,同时推远不匹配对的距离,实现不同模态在多模态共享空间中的快速对齐。
-
ITM Image-Text Matching Loss
表示图像-文本匹配损失。是一个二分类任务,模型需要根据图像和文本的融合特征,判断它们是否匹配,主要作用于多模态编码器,是另一个促进多模态融合的关键任务。
-
MLM Masked Language Modeling Loss
表示掩码语言建模损失。是自然语言处理的经典预训练任务,主要是在文本中随机掩盖部分词语,让模型根据剩余的文本上下文和对应的图像信息来预测被掩盖的词语,常作用于多模态编码器,是促成深度融合的核心任务之一。
-
Patch Embeddings
表示图像块嵌入,把图片分割为小块,然后编码转换为一个向量矩阵。
-
Word Embeddings
表示词语嵌入,把一句文本分割为词语,然后编码转换为一个向量矩阵。
-
𝐿x、𝐹x、(𝐿-𝐹)x
表示MoME Transformer with Shared Parameters的层数,𝐿x表示所有层,𝐹x表示后期融合编码器层数,(𝐿-𝐹)x表示前期特征对齐编码层数。
3、模型初始嵌入表示
H 0 v = v I C L S , V v i p , . . . , V v N p + V p o s + V t y p e H^v_0 = v_{I_{CLS}},Vv\^p_i,...,Vv\^p_N+V_{pos}+V_{type} H0v=vICLS,Vvip,...,VvNp+Vpos+Vtype
- H 0 v H^v_0 H0v:表示视觉输入初始嵌入。
- v I C L S v_{I_{CLS}} vICLS:表示视觉分类标记,一个独立的可学习的嵌入向量,用于聚合整张图像的全局信息。
- V v i p , . . . , V v N p Vv^p_i,...,Vv^p_N Vvip,...,VvNp:表示从第i个到第N个图像块的线性投影嵌入。原始图像被分割为N个不重叠的图像块,每个块通过一个线性层投影嵌入到模型所需要的维度。
- V p o s V_{pos} Vpos:表示视觉位置编码,为每个图像块和分类标记添加位置信息,使模型感知空间结构。
- V t y p e V_{type} Vtype:表示视觉类型嵌入,一个独立的可学习的嵌入,用于区分不同的模态类型。
H 0 w = w T C L S , w i , . . . , w M , w \[ T S E P ] + T p o s + T t y p e H^w_0 = w_{T_{CLS}},w_i,...,w_M,w_{\[T_{SEP}}]+T_{pos}+T_{type} H0w=wTCLS,wi,...,wM,w\[TSEP]+Tpos+Ttype
- H 0 w H^w_0 H0w:表示语言输入初始嵌入。
- w T C L S w_{T_{CLS}} wTCLS:表示文本分类标记,一个独立的可学习的嵌入向量,用于聚合整个文本序列的语义信息。
- w i , . . . , w M w_i,...,w_M wi,...,wM:表示从第i个到第M个词语的词嵌入。原始文本被划分为M个不重叠的词语,每个词语通过词表投影嵌入到模型所需要的维度。
- w T S E P w_{T_{SEP}} wTSEP:表示文本分隔标记,用于表示当前文本序列的结束。
- T p o s T_{pos} Tpos:表示文本位置编码,为每个文本标记添加顺序信息。
- T t y p e T_{type} Ttype:表示文本类型嵌入,一个独立的可学习的嵌入,用于区分不同的模态类型。
H 0 v l = H 0 w ; H 0 v H_0^{vl} = H_0\^w;H_0\^v H0vl=H0w;H0v
- H 0 v l H_0^{vl} H0vl:表示文本-图像输入初始嵌入,将文本初始嵌入序列和视觉初始嵌入序列在序列维度上进行拼接,形成一个长的多模态序列。
4、分阶段训练策略
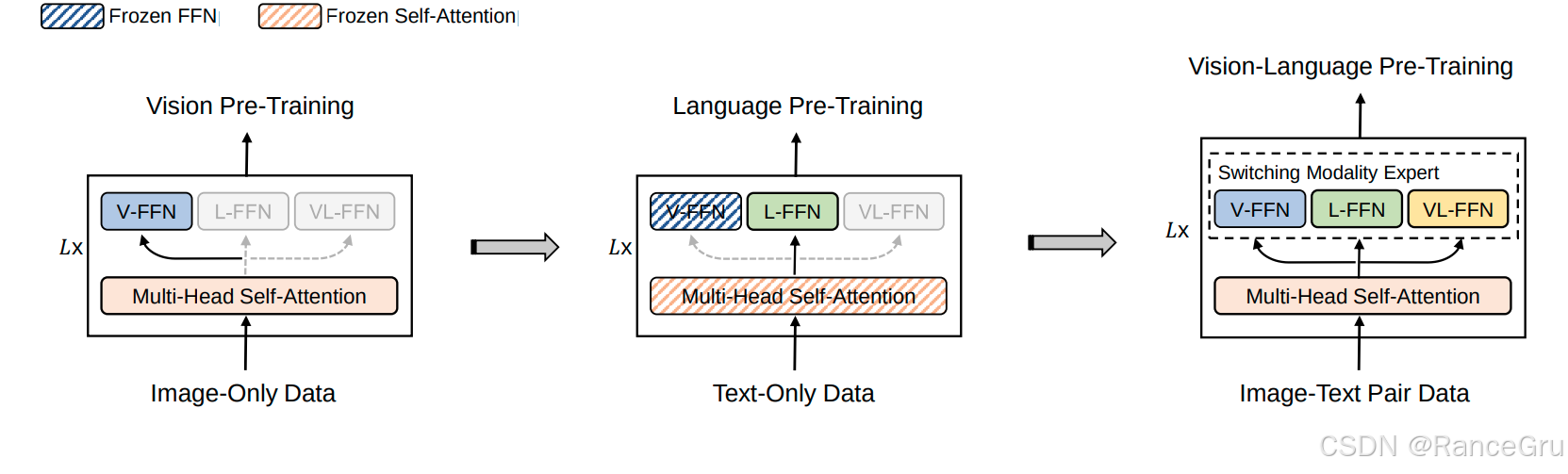
在当时多模态数据标注成本高且相对稀缺,而单模态数据则大量易得,所以在VLMo工作中尝试把单模态数据也应用到模型训练中,单模态和多模态数据集的训练主要是使用的一种分阶段、渐进式、且参数高效的视觉-语言预训练方法。
-
Vision Pre-Training仅图像数据预训练
使用纯图像数据进行训练,让模型学会理解视觉特征。模型中的 V-FFN 被激活并得到充分训练,成为处理视觉特征的专家,而 L-FFN 和 VL-FFN 在此阶段不会初始化,并使用Masked Image Modeling (MIM) 任务进行预训练。Vision Pre-Training阶段训练结束后,Multi-Head Self-Attention 和 V-FFN 的参数会被保留下来,作为后续训练的基础。
-
Language Pre-Training仅文本数据预训练
使用纯文本数据进行训练,让模型学会理解语言特征。冻结上个阶段得到的 V-FFN 参数且不进行使用,初始化并激活 L-FFN,将其训练成为处理语言特征的专家。冻结上个阶段得到的Multi-Head Self-Attention 参数,在保留已经学到的视觉特征的同时还直接用于纯文本数据的训练,并使用Masked Language Modeling (MLM) 任务进行预训练。Language Pre-Training阶段结束后,Multi-Head Self-Attention 、 V-FFN 和 L-FFN的参数会被保留下来,作为后续训练的基础。
-
Vision-Language Pre-Training图片-文本对数据预训练
目标:使用图文配对数据进行训练,让模型学会视觉与语言之间的对齐与深度融合。初始化并激活 VL-FFN,将其训练成为处理视觉-语言特征的专家。不再冻结任何模块,并使用ITC、ITM和MLM三个任务进行预训练,在图像-文本对数据上进一步微调,学习跨模态的注意力关系。在推理或训练时,对于图像块输入模型会路由到 V-FFN,对于文本输入模型会路由到 L-FFN,对于图像-文本对输入模型会路由到 VL-FFN。
这种分阶段训练,能够先打好单模态基础,再学习多模态交互,使得训练更稳定高效。而且在重复训练的过程中,通过冻结和复用大部分参数,极大地节省了训练成本。相比于从头训练一个多模态模型,这种方法只需逐步增加少量的FFN参数。
这里有一个注意点,就是需要先进行图像单模态训练,再进行文本单模态训练,最后再进行多模态训练。因为在视觉嵌入编码的特征数据上训练出来的一个多头自注意力模型,不需要微调就可以直接用于文本嵌入编码的特征数据上进行建模,构建的模型输出甚至在MLM任务上效果不错,但是反过来先文本再图像的训练效果却不行。
五、BLIP
1、前言
在常见的多模态图像-文本预训练模型工作中,以CLIP、ViLT、ALBEF、VLMo等代表工作不管是使用双塔结构还是单塔结构,其实都是属于纯 Encoder-Only 架构,也就是只使用了Transformer模型中的的Encoder部分。而基于 Encoder-Only 结构的模型虽然擅长图文对比学习和检索任务,但无法执行生成任务。
而传统的基于 Encoder-Decoder 结构的序列到序列模型,例如Seq2Seq、SimVLM模型虽然擅长生成任务,但其文本编码产生的语义表示不易与图像嵌入对齐,导致在图文检索任务中表现不佳。
另外想要构建一个强大的多模态模型,往往需要海量高质量的图文对数据,但此前的高质量的人工标注的图像-文本对数据极其有限,远不足以训练百亿参数级别的大模型。此前工作大多依赖于互联网爬取的大规模图像-文本对,但这些网络数据噪声很大,文本描述时常存在与图像内容不匹配、缺失关键语义或包含错误信息等问题,导致模型在对齐阶段时学到错误的关联。
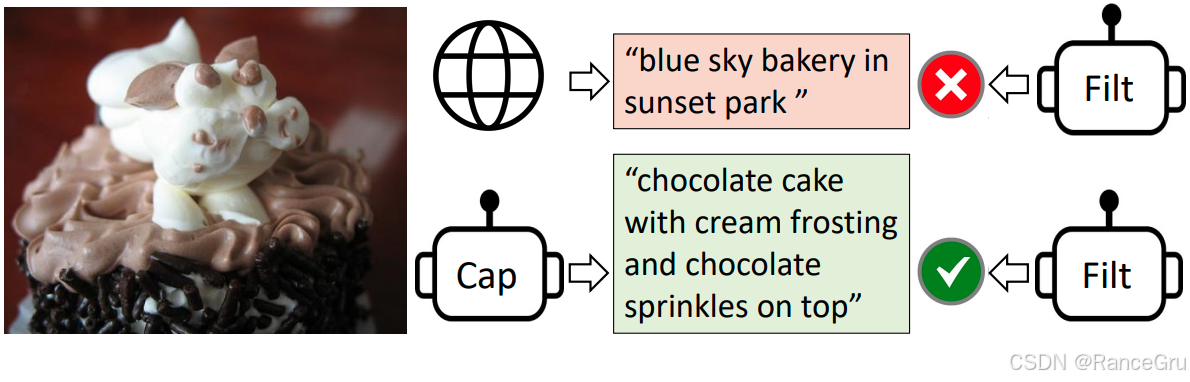
2、模型结构
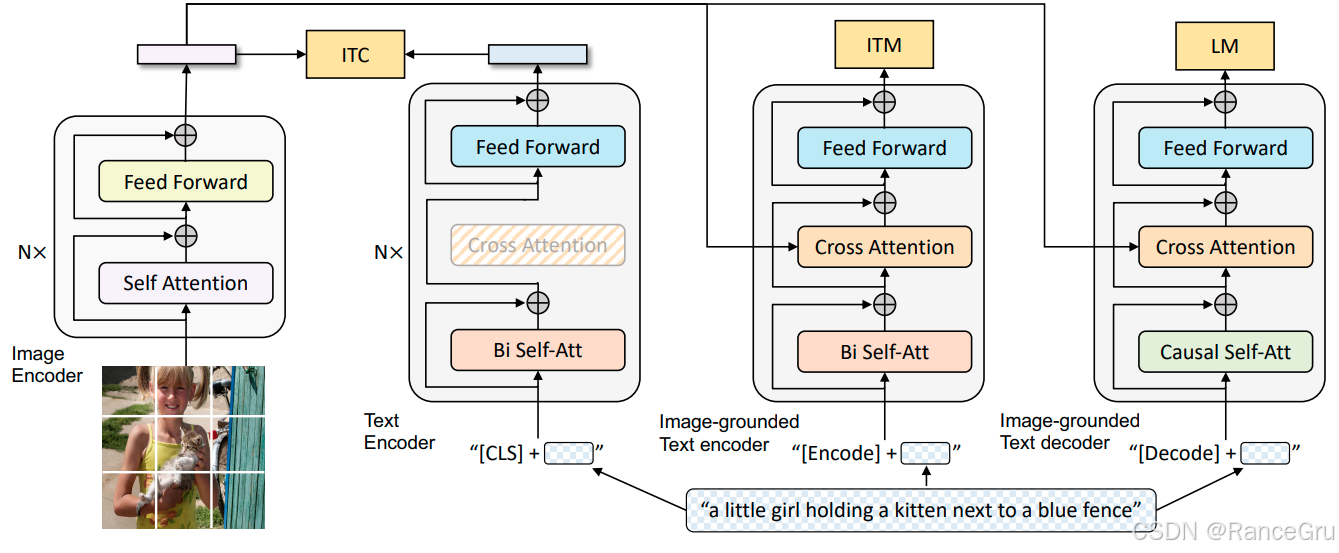
-
Image Encode
表示图像编码器,通常使用的是一个ViT模型。
-
Text Encoder
表示文本编码器,通常使用的是一个BERT模型。
-
Image-grounded Text encoder
表示基于图像的文本编码器,是一个多模态编码器,融合了图像和文本特征。
-
Image-grounded Text decoder
表示基于图像的文本解码器,是一个多模态解码器,融合了图像和文本特征。
-
Self Attention
表示自注意力机制。文本序列中的每个词元只能关注其左侧的词元信息,无法看到右侧的词元信息。
-
Feed Forward
表示前馈神经网络。
-
Bi Self-Att
表示双向自注意力。文本序列中每个词元可以同时关注其左侧和右侧的所有其他词元信息,旨在为输入序列的每个位置生成一个融合了全局信息的表示。
-
Cross Attention
表示交叉注意力机制。对于文本序列中的每个词元,其Query来自一个序列,而Key和Value来自另一个序列。建立两个不同模态或序列之间的对齐关系,让目标序列的每个位置能够有选择地关注源序列的相关部分。
-
Causal Self-Att
表示因果自注意力机制。对于文本序列中的每个词元,处理第t个元素时,只能访问第1到第t个元素的信息,第t+1及以后的未来信息被掩码完全屏蔽。主要用于确保模型在处理序列数据时遵循因果性,即模型在生成或处理当前时刻的信息时,只能访问当前及过去的信息,而不能得到未来的信息。
-
ITC Image-Text Contrastive Loss
表示图像-文本对比损失。是对比学习在多模态领域的典型应用,能够拉近匹配图像-文本对在共享嵌入空间中的距离,同时推远不匹配对的距离,实现不同模态在多模态共享空间中的快速对齐。
-
ITM Image-Text Matching Loss
表示图像-文本匹配损失。是一个二分类任务,模型需要根据图像和文本的融合特征,判断它们是否匹配,主要作用于多模态编码器,是另一个促进多模态融合的关键任务。
-
LM Language Modeling Loss
表示语言建模损失。是一个图像描述生成任务,模型需要根据给定的图片,以自回归的方式生成一句准确的通顺的描述。
Text Encoder、Image-grounded Text encoder和Image-grounded Text decoder其实是同一个基础模型的三种不同功能模式或变体,颜色一致的模块就是便是属于参数共享,比如Feed Forward、Cross Attention和Bi Self-Att。
在Text Encoder中会冻结Cross Attention层进行ITC任务,在Image-grounded Text encoder和Image-grounded Text decoder中就没有冻结Cross Attention层,但是却分别使用不同的自注意力层进行计算。
Bi Self-Att和Causal Self-Att在BLIP模型中对应的是两套独立的、不共享的参数,它们分别存储在模型的不同位置,因此在训练和推理时不会相互影响。但是在实际中Bi Self-Att和Causal Self-Att层其实使用的是同一套自注意力计算模块,只不过传入的注意力掩码的不同导致计算的方向和参数不同。Bi Self-Att通常不应用掩码,或应用一个全1的掩码,允许序列中所有位置的token相互关注。Causal Self-Att应用的是一个严格的下三角掩码,会将注意力分数矩阵中行索引大于列索引的位置的值设置为一个极大的负数-inf,这样在经过Softmax后,这些位置的注意力权重就变为0。这确保了每个token只能关注自身及之前的token,用于自回归文本生成任务。
3、噪声数据优化
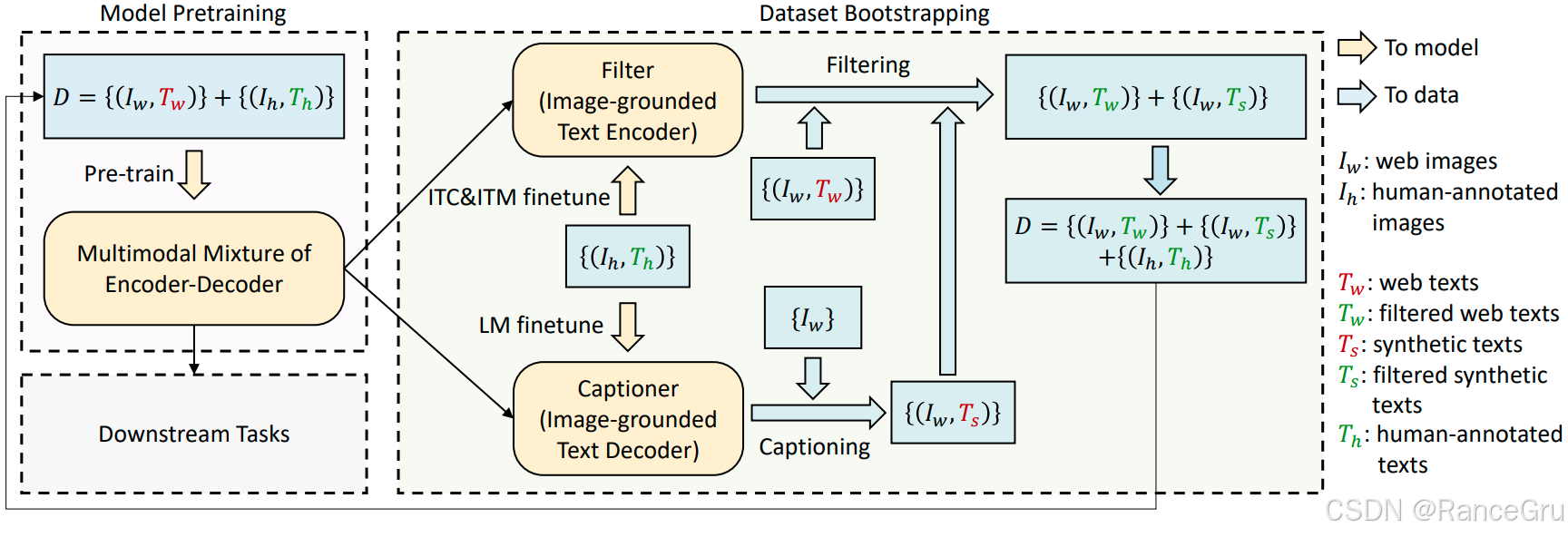
-
Model Pretraining
表示模型预训练工作。
-
Dataset Bootstrapping
表示数据集引导优化与构建工作
-
D
表示训练数据集
-
To model
表示传给模型
-
To data
表示传给数据
-
I w I_w Iw:web images
表示原始网络图像数据
-
I h I_h Ih:human-annotated images
表示经过人类标注的图像
-
T w T_w Tw:web texts
表示原始网络文本数据
-
T w T_w Tw:filtered web texts
表示经过ITC和ITM过滤的网络文本数据
-
T s T_s Ts:synthetic texts
表示经过LM生成的文本数据
-
T s T_s Ts:filtered synthetic texts
表示经过ITC和ITM过滤的生成文本数据
-
T h T_h Th:human-annotated texts
表示经过人类标注的文本数据
-
Multimodal Mixture of Encoder-Decoder
表示多模态混合编解码器,也就是预训练模型
-
Downstream Tasks Pre-train
表示进行下游任务的预训练模型
-
Filter (Image-grounded Text Encoder)
表示基于Image-grounded Text Encoder的数据过滤器
-
ITC&ITM finetune
表示使用人工标注数据集进行ITC和ITM微调
-
LM finetune
表示使用人工标注数据集进行LM微调
-
Captioner (Image-grounded Text Decoder)
表示基于Image-grounded Text Decoder的文本生成器
-
Filtering
表示数据过滤
-
Captioning
表示数据生成
先使用网络爬取的未优化数据集和人工标注数据集训练一个预训练模型。
然后使用人工标注数据集对预训练模型进行ITC、ITM和LM任务分别微调基于图像的文本编码器和基于图像的文本解码器。
再使用微调后的模型一边使用编码器对网络爬取的未优化数据集进行图像-文本对数据优化和重构,一边使用解码器根据图像数据生成对应文本数据,然后组成新的图像-文本对数据,同样传给编码器进行优化和重构。
最后得到一份经过优化的网络图像-文本对数据集,一份经过优化的生成图像-文本对数据集,把这两份数据集以及经过人类标注的图像-文本数据集组成新的训练数据集重新进行预训练和正常的下游任务预训练。

如图,红色表示丢弃,绿色表示采纳,通过ITC+ITM判断生成文本和原有文本哪个更好进行采纳,使得图像 -文本对数据能够更加的匹配,这样的训练数据才更有利于模型的预训练。