树莓派的YOLO智能AI识别系统,识别ESP32还是STM32
文档结尾有代码下载链接
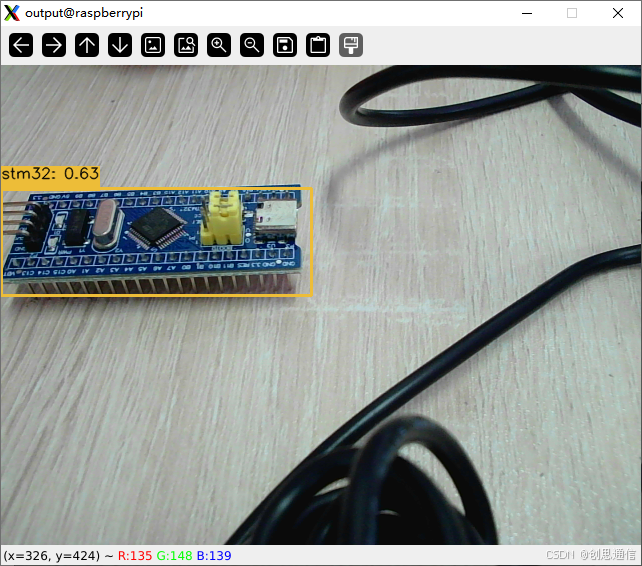
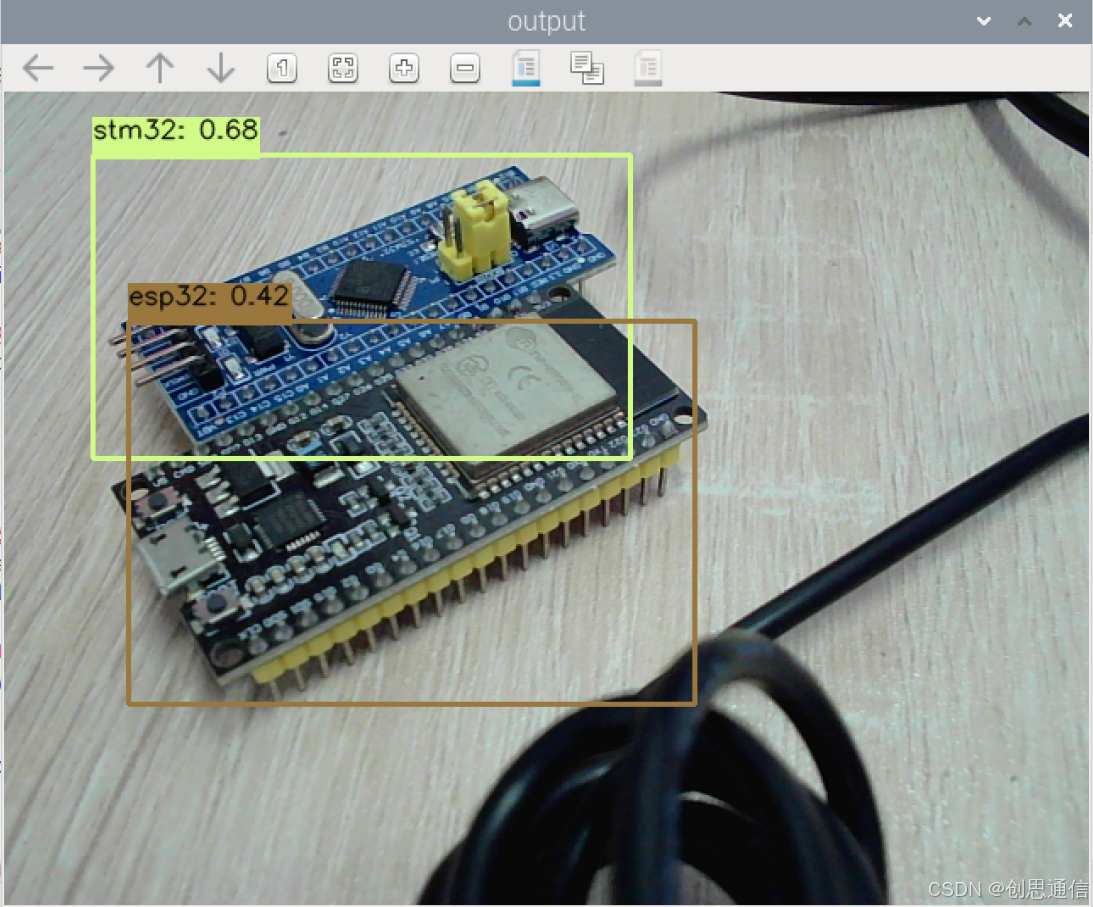
🎯 实现效果
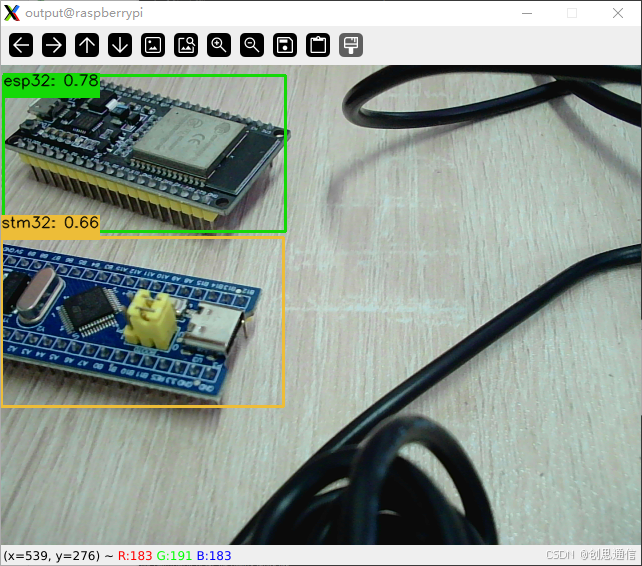
!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/7d344804617a4d64904b4f7171018d49.png
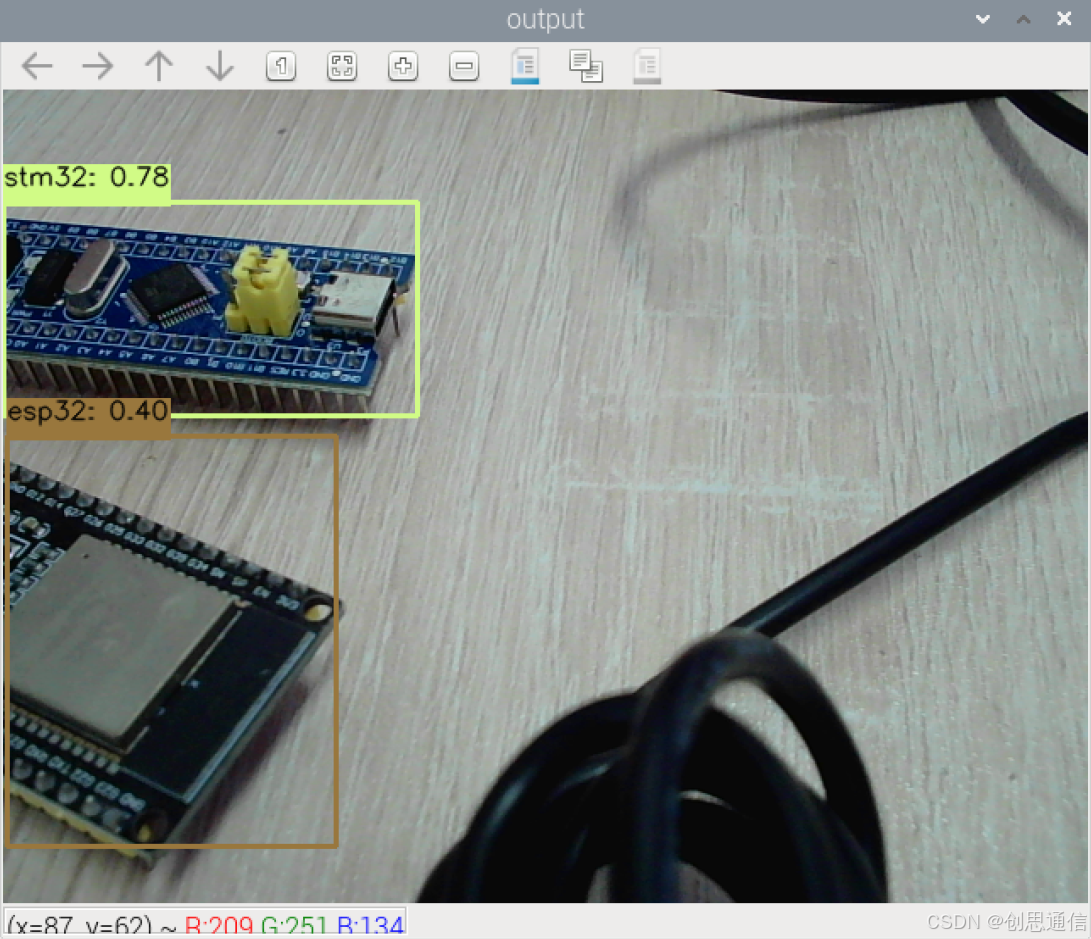
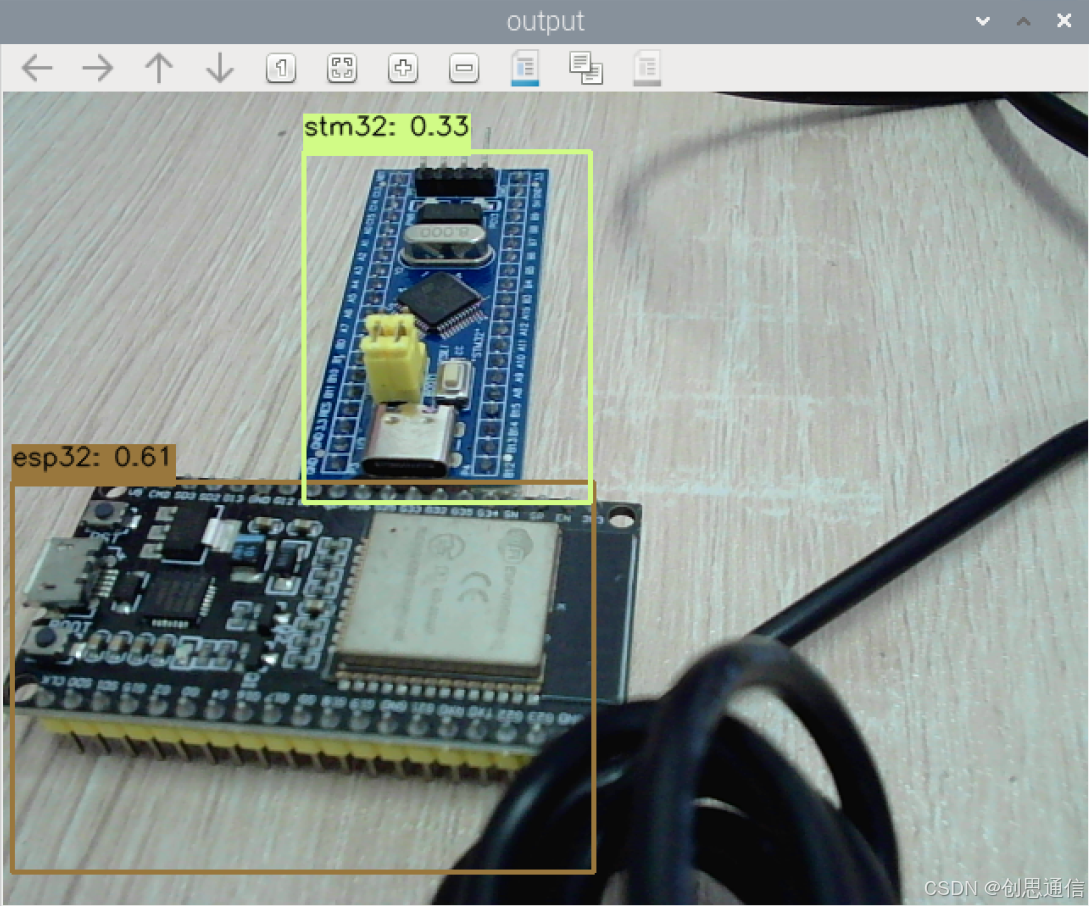
🌟 系统组成:
- 树莓派主板:推荐树莓派5,性能足以支撑图像识别和数据处理,兼容性也更优;
- 摄像头模块:选择USB摄像头;
- 显示屏:小尺寸HDMI显示屏可实时显示识别信息;
- 网络模块:树莓派5自带WiFi/以太网,确保设备能连接互联网,用于数据上传;
- 电源:5V/3Amicro-USB电源,保证树莓派稳定运行,避免因供电不足导致识别中断。
🌟 驱动思路
1.核心目标与整体架构
- 核心目标:通过摄像头实时捕获画面,使用预训练的 ONNX 模型检测出画面中的 stm32 和 esp32 设备,在画面中标记出目标位置、类别及置信度,并支持实时显示与退出控制。
- 整体架构:采用 "数据流管道" 设计,分为 5 个核心模块,按顺序协作:摄像头捕获 → 图像预处理 → 模型推理 → 结果后处理 → 可视化显示
2.分模块驱动思路
(1). 摄像头捕获模块(VideoCapture 类)
- 设计目的:解决摄像头读取与图像处理的速度不匹配问题,避免因处理耗时导致的画面延迟或卡顿。
- 实现思路:
- 采用多线程异步读取:单独启动一个线程(_reader)负责持续从摄像头读取帧,主线程专注于处理帧,两者通过队列(queue)通信。
- 队列 "去缓存" 机制:队列最大容量设为 3,若队列非空则先清空旧帧,只保留最新帧,确保主线程读取的始终是当前最新画面(解决 "画面滞后" 问题)。
- 资源可控释放:通过terminate()方法统一停止线程、释放摄像头资源,避免程序退出时的资源泄漏。
(2). 模型加载与推理模块
- 设计目的:高效加载 ONNX 模型并完成实时推理,确保模型可用性与推理速度。实现思路:
- 模型只加载一次:在程序初始化阶段(主逻辑开始时)通过cv2.dnn.readNetFromONNX()加载模型,避免在循环中重复加载(减少内存占用和启动耗时)。
- 异常处理:捕获模型加载失败的异常(如文件不存在、格式错误),及时终止程序并提示错误,提高健壮性。
- 推理流程:将预处理后的图像(blob 格式)输入模型,通过net.forward("output0")获取输出(指定输出节点名,需与模型定义一致),确保推理结果正确解析。
(3). 图像预处理模块(preprocess 函数)
- 设计目的:将原始摄像头帧转换为模型要求的输入格式,确保模型可正确推理。实现思路:
- 格式转换:使用cv2.dnn.blobFromImage()完成 4 项关键操作:
- 缩放:将图像尺寸缩放到模型输入要求的 640×640;
- 归一化:将像素值从 0,255 转换为 0,1(通过1/255.0);
- 通道转换:将 OpenCV 默认的 BGR 格式转为模型常用的 RGB 格式(swapRB=True);
- 批量处理:输出形状为 (1,3,640,640) 的 blob(满足模型的 batch 维度要求)。
(4). 结果后处理模块(postprocess 函数)
- 设计目的:解析模型输出的原始数据,过滤无效检测,将结果映射回原始图像,为可视化做准备(核心逻辑)。
- 实现思路:
- 输出解析:模型输出为 (25200,7) 的张量(25200 个候选框,每个框含 7 个参数:x,y,w,h,obj_conf,stm32_score,esp32_score),需提取关键信息:x,y,w,h:归一化的边界框中心坐标和宽高;obj_conf:目标置信度(判断是否为 "物体");stm32_score/esp32_score:两类目标的类别置信度。
- 过滤低质量检测:先通过obj_conf > CONF_THRESH过滤 "非物体" 候选框;再通过类别置信度的最大值过滤 "类别不明确" 的候选框;计算最终分数(obj_conf × 类别分数),综合评估检测可靠性。
- 坐标映射:将模型输出的归一化坐标(基于 640×640)转换为原始图像坐标(基于 480×640),通过缩放因子(x_factor = 原始宽/640,y_factor = 原始高/640)实现,确保边界框位置准确。
- 非极大抑制(NMS):通过cv2.dnn.NMSBoxes()去除重叠度高的冗余框,保留最可靠的检测结果(避免同一目标被多次标记)。
(5). 可视化与控制模块(主循环)
- 设计目的:将检测结果直观显示,并支持用户交互控制。实现思路:
- 绘制检测框:根据后处理得到的边界框坐标,在原始图像上绘制矩形框,确保坐标不超出图像范围(通过max/min限制)。
- 绘制标签:在框上方 / 下方添加类别名称和置信度标签,通过背景矩形增强文字可读性。
- 实时显示与退出:通过cv2.imshow()实时显示处理后的画面,监听键盘输入(按 "q" 退出),退出时释放所有资源(摄像头、窗口)。
🌟 5.树莓派上部署运行
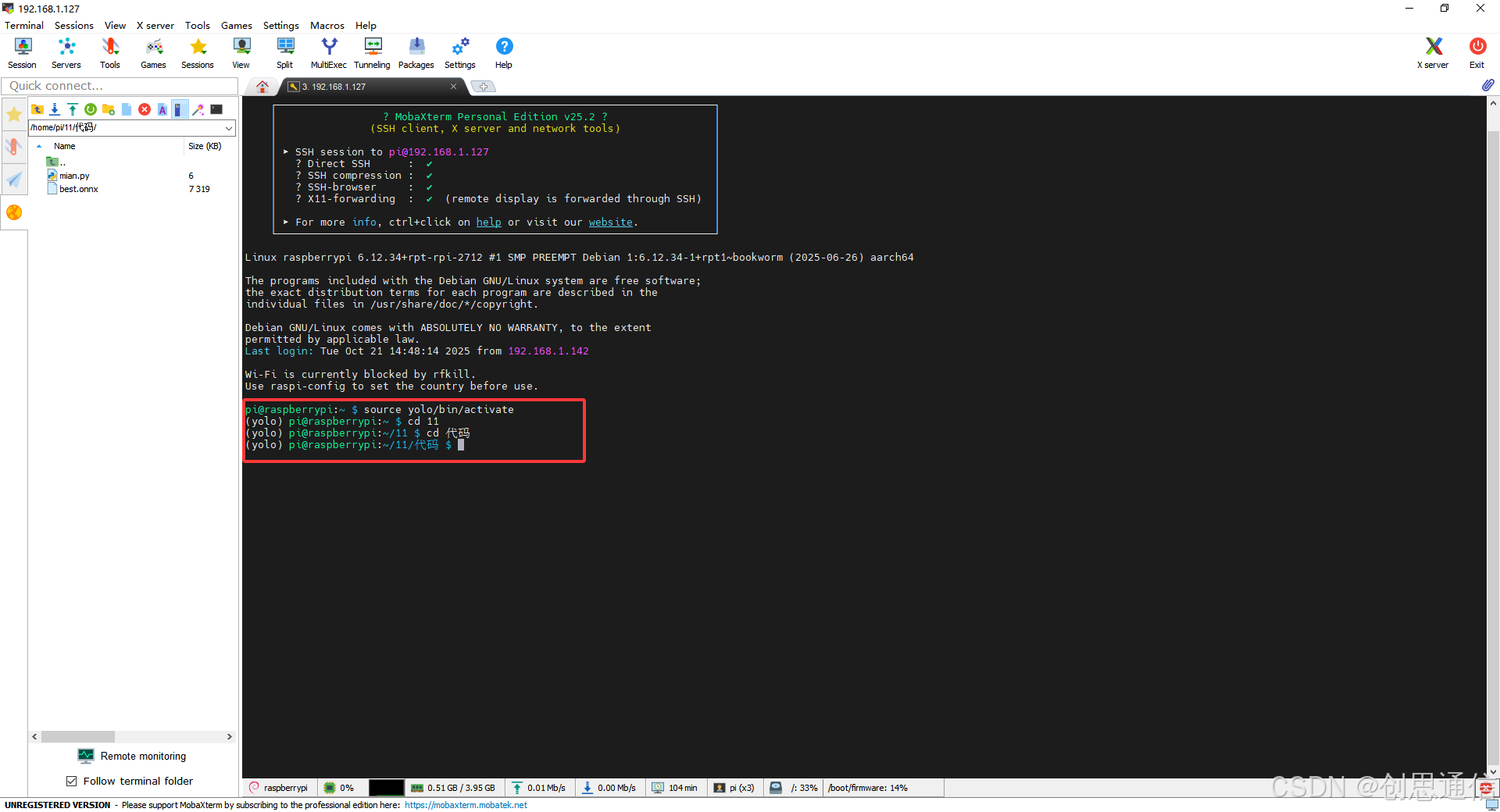
a. 搭建环境(树莓派端)
- 先安装所有依赖库,打开终端输命令安装。
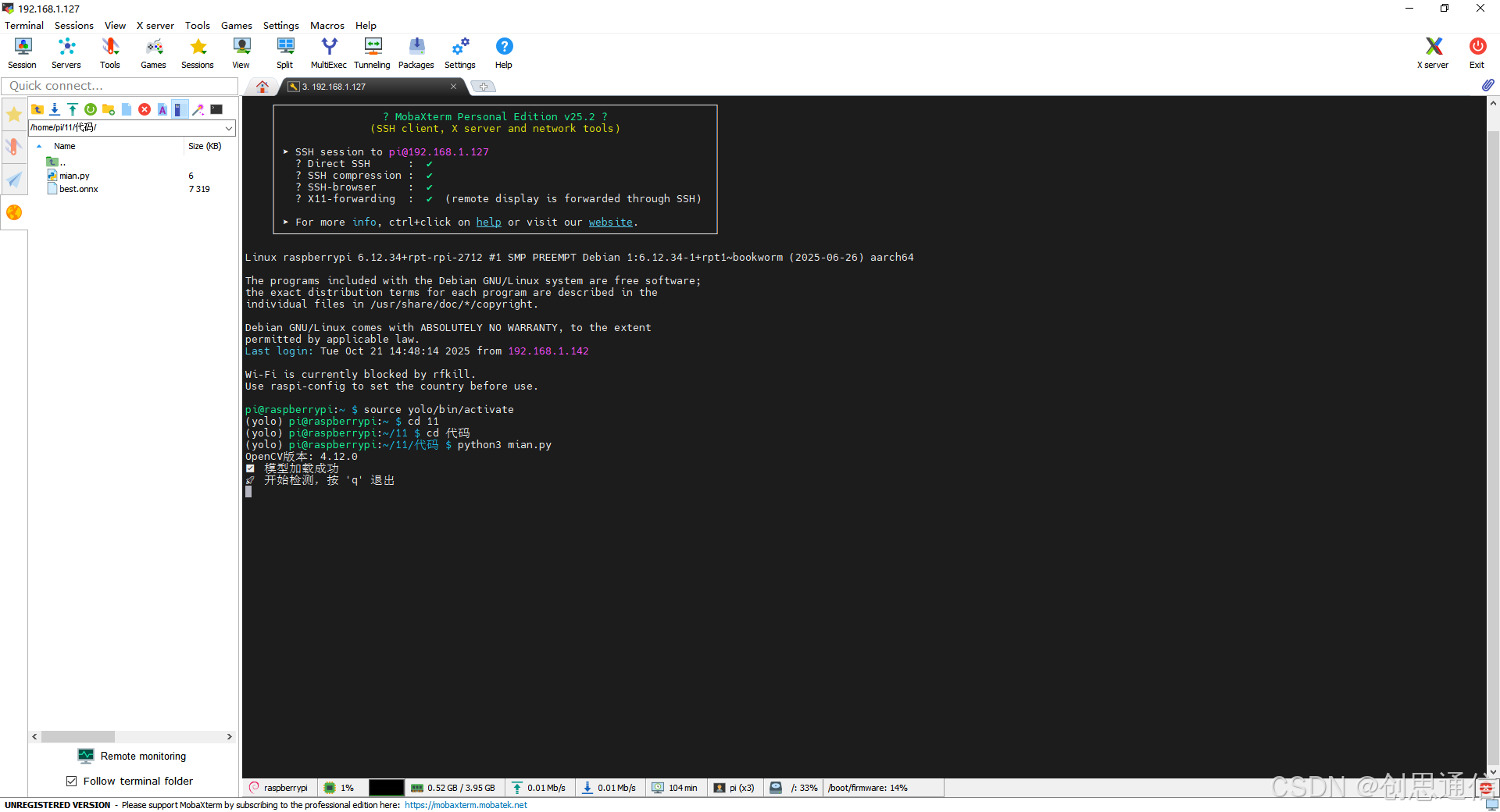
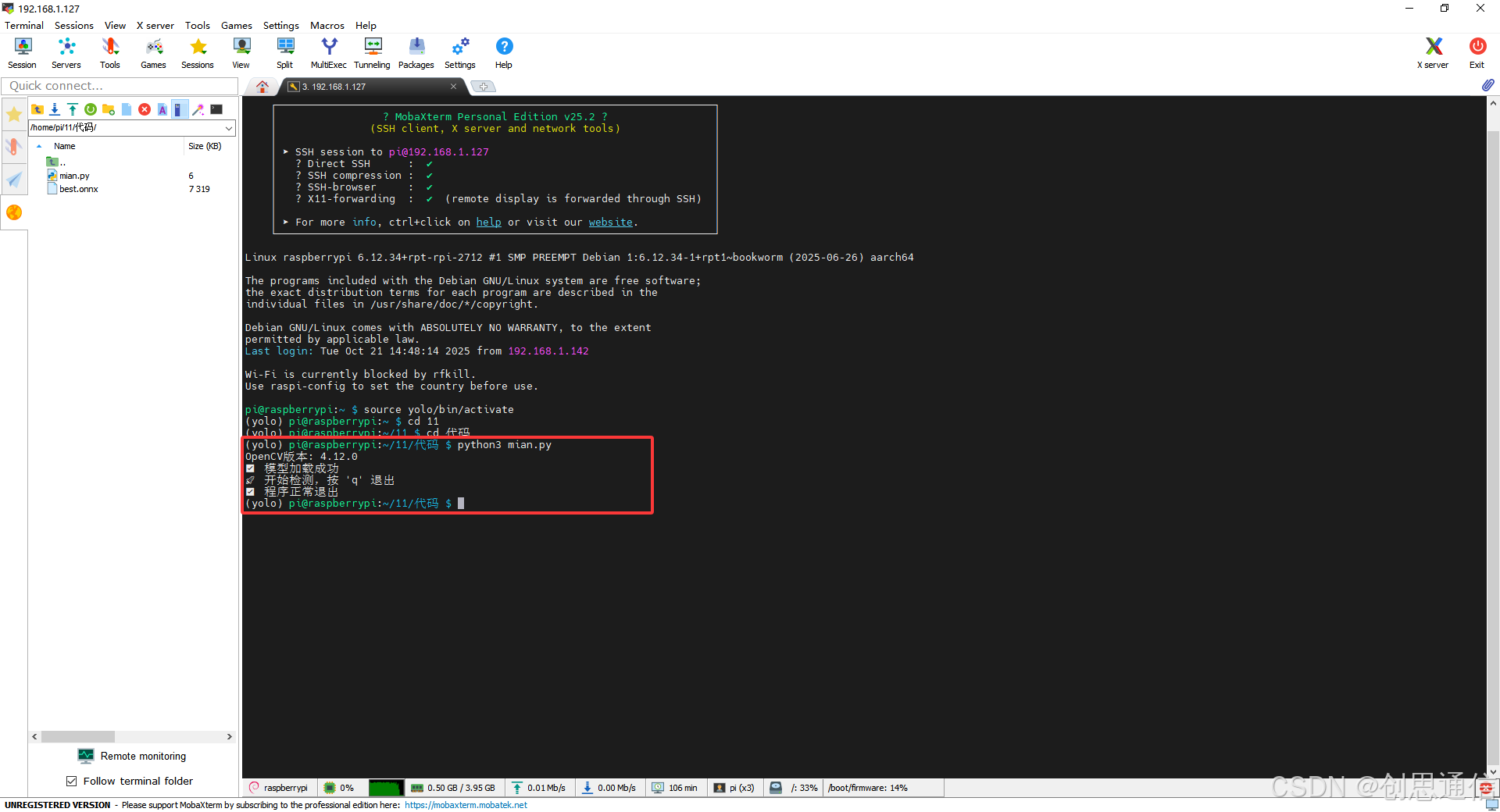
b. 运行程序
- 在终端进入代码文件夹,输命令:python3 mian.py。若是使用虚拟python,则需先进入虚拟环境再运行。此处使用SSH远程软件。
🎯 程序代码
python
import cv2
import numpy as np
import queue
import threading
import time
INPUT_SIZE_WIDTH = 640
INPUT_SIZE_HIGHT = 640
CONF_THRESH = 0.3 # 适当降低阈值,避免漏检(可根据实际效果调整)
NMS_THRESH = 0.4 # NMS阈值
# 自定义无缓存读视频类(保留你原有的逻辑,确保摄像头正常)
class VideoCapture:
"""Customized VideoCapture, always read latest frame """
def __init__(self, camera_id):
self.cap = cv2.VideoCapture(camera_id)
self.cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
self.cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
self.q = queue.Queue(maxsize=3)
self.stop_threads = False
th = threading.Thread(target=self._reader)
th.daemon = True
th.start()
def _reader(self):
while not self.stop_threads:
ret, frame = self.cap.read()
if not ret:
break
if not self.q.empty():
try:
self.q.get_nowait()
except queue.Empty:
pass
self.q.put(frame)
def read(self):
return self.q.get()
def terminate(self):
self.stop_threads = True
self.cap.release()
def draw_detections(img, box, score, class_id):
"""绘制检测框(保留你原有的逻辑)"""
x1, y1, w, h = box
color = color_palette[class_id]
# 绘制边界框(确保不超出图像范围)
x1 = max(0, min(int(x1), img.shape[1]-1))
y1 = max(0, min(int(y1), img.shape[0]-1))
x2 = max(x1, min(int(x1 + w), img.shape[1]-1))
y2 = max(y1, min(int(y1 + h), img.shape[0]-1))
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
# 绘制标签
label = f"{classes[class_id]}: {score:.2f}"
(label_width, label_height), _ = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
label_x = x1
label_y = y1 - 10 if y1 - 10 > label_height else y1 + 10
# 标签背景
cv2.rectangle(
img, (label_x, label_y - label_height),
(label_x + label_width, label_y + label_height),
color, cv2.FILLED
)
# 标签文本
cv2.putText(img, label, (label_x, label_y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA)
def postprocess(input_image, output):
"""
核心修复:适配模型输出 (25200, 7)
每一行格式:[x, y, w, h, obj_conf, stm32_score, esp32_score]
"""
# 压缩输出:去除batch维度,得到 (25200, 7)
outputs = np.squeeze(output[0])
rows = outputs.shape[0]
boxes = []
scores = []
class_ids = []
# 修复1:计算缩放因子(将模型640×640的坐标映射回原图像480×640)
img_h, img_w = input_image.shape[:2] # 原图像高、宽(480, 640)
x_factor = img_w / INPUT_SIZE_WIDTH # 640 / 640 = 1.0(宽方向无缩放)
y_factor = img_h / INPUT_SIZE_HIGHT # 480 / 640 = 0.75(高方向缩放)
# 遍历所有检测框
for i in range(rows):
# 修复2:提取目标置信度(是否是物体,非类别分数)
obj_conf = outputs[i][4]
if obj_conf < CONF_THRESH:
continue # 过滤"不是物体"的低置信度结果
# 修复3:提取2个类别的分数(outputs[i][5] = stm32,outputs[i][6] = esp32)
class_scores = outputs[i][5:7] # 取第5、6列,得到 [cls1, cls2]
max_class_score = np.amax(class_scores) # 最高类别分数
if max_class_score < CONF_THRESH:
continue # 过滤"类别不明确"的结果
# 修复4:计算最终分数(目标置信度 × 类别分数,更严谨)
final_score = obj_conf * max_class_score
# 获取得分最高的类别ID(0=stm32,1=esp32)
class_id = np.argmax(class_scores)
# 修复5:提取边界框并映射到原图像尺寸
x = outputs[i][0] # 模型输出的中心x(归一化)
y = outputs[i][1] # 模型输出的中心y(归一化)
w = outputs[i][2] # 模型输出的宽(归一化)
h = outputs[i][3] # 模型输出的高(归一化)
# 转换为原图像的像素坐标(左上角x1, y1 + 宽高w, h)
left = (x - w / 2) * x_factor
top = (y - h / 2) * y_factor
width = w * x_factor
height = h * y_factor
# 添加到结果列表
class_ids.append(class_id)
scores.append(final_score)
boxes.append([left, top, width, height])
# 应用非极大抑制(过滤重叠框)
indices = cv2.dnn.NMSBoxes(boxes, scores, CONF_THRESH, NMS_THRESH)
# 修复6:处理多维索引(避免遍历报错)
for i in indices.flatten() if len(indices) > 0 else []:
box = boxes[i]
score = scores[i]
class_id = class_ids[i]
draw_detections(input_image, box, score, class_id)
return input_image
def preprocess(img):
"""图像预处理(保留你原有的逻辑)"""
blob = cv2.dnn.blobFromImage(img, 1/255.0, (INPUT_SIZE_WIDTH, INPUT_SIZE_HIGHT), swapRB=True, crop=False)
return blob
# -------------------------- 主逻辑 --------------------------
if __name__ == "__main__":
print(f"OpenCV版本: {cv2.__version__}")
# 初始化摄像头
cap = VideoCapture(0)
if not cap.cap.isOpened():
print("❌ 无法打开摄像头")
cap.terminate()
exit()
# 类别配置(与模型输出的cls1、cls2顺序一致)
classes = ["stm32", "esp32"] # 确保:outputs[i][5]→stm32,outputs[i][6]→esp32
color_palette = np.random.uniform(0, 255, size=(len(classes), 3))
# 修复7:模型只加载一次(避免循环中重复加载导致卡顿)
try:
net = cv2.dnn.readNetFromONNX("best.onnx") # 你的模型路径
print("✅ 模型加载成功")
except Exception as e:
print(f"❌ 模型加载失败: {e}")
cap.terminate()
exit()
# 实时推理循环
print("🚀 开始检测,按 'q' 退出")
while True:
frame = cap.read()
if frame is None:
print("⚠️ 未获取到摄像头帧")
time.sleep(0.1)
continue
# 预处理 → 推理 → 后处理
img_blob = preprocess(frame)
net.setInput(img_blob)
outputs = net.forward(["output0"]) # 确保输出节点名与模型一致
outimg = postprocess(frame.copy(), outputs)
# 显示结果
cv2.imshow("output", outimg)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.terminate()
cv2.destroyAllWindows()
print("✅ 程序正常退出")