Interaction算法实现集合之间的向量积,例如,给定两个维度是n的向量集合,使用向量积计算输出一个维度是n*n的向量集合。
两个维度是3的向量集合,其中,id1是数据行的索引值,vec1以及vec2两个维度是3的向量集合:

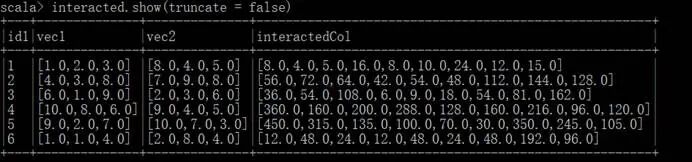
使用Interaction算法,计算输出interactedCol ,一个维度是9的向量集合:

Java代码示例
在Java本地开发环境中,创建Interaction算法测试类,初始化spark实例:

定义测试数据集合,设置数据集合的列名称以及数据类型,对数据集合执行初始化,生成spark数据类型的数据集合:
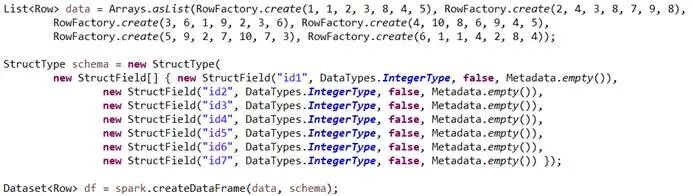
设置Interaction算法输入的数据列以及输出的数据列,执行特征转换,输出数据集合:

运行Java代码,特征转换输出的数据集合:

Scala代码示例
与Java代码示例的功能逻辑相同:

启动spark-shell的Scala本地运行环境:
运行Interaction算法代码:
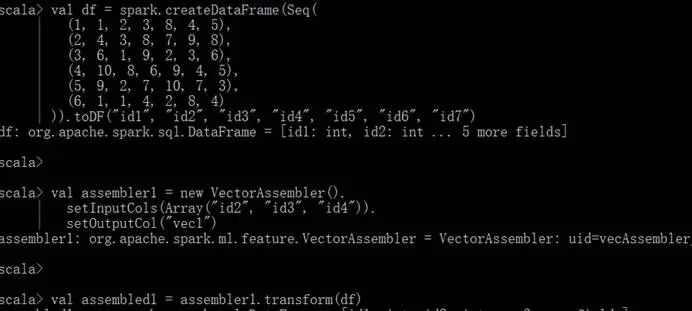
特征转换输出的数据集合: