一. 系统分析与设计
1.1 系统分析概述
1.1.1 系统分析的定义与任务
- 系统分析是一种问题求解技术,通过分解系统为各个组成部分,研究各部分的工作方式与交互,以实现系统目标。
- 主要任务:对现行系统进行详细调查,整合调查文档资料,分析组织内部管理状况与信息处理过程,为系统开发提供资料,并提交系统方案说明书。
1.1.2 系统分析的主要步骤
- 认识、理解当前现实环境,获取当前系统的 "物理模型"。
- 从当前系统的 "物理模型" 抽象出当前系统的 "逻辑模型"。
- 对当前系统的 "逻辑模型" 进行分析和优化,建立目标系统的 "逻辑模型"。
- 将目标系统的逻辑模型具体化(物理化),建立目标系统的物理模型。
- 系统开发的目的:将现有系统的物理模型转换为目标系统的物理模型。
1.2 系统设计
1.2.1 系统设计的基本原理
系统设计需遵循以下核心原理,以保证系统的科学性与可维护性:
- 抽象:重点说明本质方面,忽略非本质方面,简化复杂系统的设计。
- 模块化:将系统拆分为可组合、分解和更换的单元(模块),降低耦合度。
- 信息隐蔽:将每个程序的成分隐蔽或封装在单一设计模块中,减少模块间的相互干扰。
- 模块独立:每个模块完成一个相对独立的特定子功能,且与其他模块的联系简单。
- 模块独立的核心要求:高内聚、低耦合------ 内聚指模块内部功能的相关性,耦合指多个模块间的联系紧密程度。
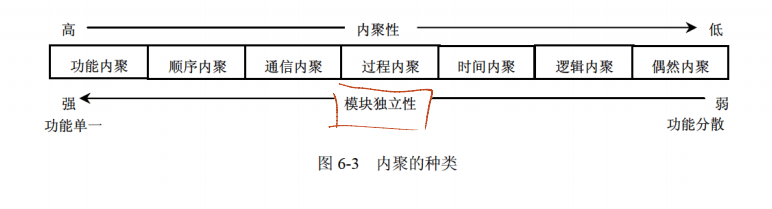
1.2.2 内聚(模块内部功能相关性)
内聚程度从低到高分类及定义如下表:
| 内聚分类 | 定义 | 记忆关键字 |
|---|---|---|
| 偶然内聚 | 一个模块内的各处理元素之间没有任何联系 | 无直接关系 |
| 逻辑内聚 | 模块内执行若干个逻辑上相似的功能,通过参数确定该模块完成哪一个功能 | 逻辑相似、参数决定 |
| 时间内聚 | 把需要同时执行的动作组合在一起形成的模块 | 同时执行 |
| 过程内聚 | 一个模块完成多个任务,这些任务必须按指定的过程执行 | 指定的过程顺序 |
| 通信内聚 | 模块内的所有处理元素都在同一个数据结构上操作,或者各处理使用相同的输入数据 / 产生相同的输出数据 | 相同数据结构、相同输入输出 |
| 顺序内聚 | 一个模块中的各个处理元素都密切相关于同一功能且必须顺序执行,前一个功能元素的输出就是下一个功能元素的输入 | 顺序执行、输入为输出 |
| 功能内聚 | 最强的内聚,模块内的所有元素共同作用完成一个功能,缺一不可 | 共同作用、缺一不可 |
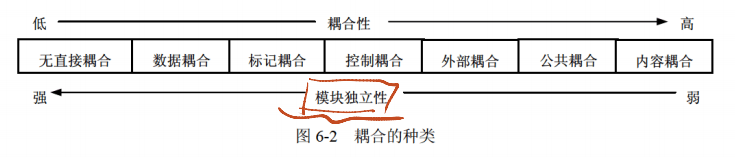
1.2.3 耦合(模块间联系紧密程度)
耦合程度从低到高分类及定义如下表:
| 耦合分类 | 定义 | 记忆关键字 |
|---|---|---|
| 无直接耦合 | 两个模块之间没有直接的关系,分别从属于不同模块的控制与调用,不传递任何信息 | 无直接关系 |
| 数据耦合 | 两个模块之间有调用关系,传递的是简单的数据值,相当于高级语言中的值传递 | 传递数据值、调用 |
| 标记耦合 | 两个模块之间传递的是数据结构 | 传递数据结构 |
| 控制耦合 | 一个模块调用另一个模块时,传递的是控制变量,被调用模块通过该控制变量的值有选择地执行模块内的某一功能 | 控制变量、选择执行某一功能 |
| 外部耦合 | 模块间通过软件之外的环境联合(如 I/O 将模块耦合到特定的设备、格式、通信协议上) | 软件外部环境 |
| 公共耦合 | 通过一个公共数据环境相互作用的那些模块间的耦合 | 公共数据结构 |
| 内容耦合 | 当一个模块直接使用另一个模块的内部数据,或通过非正常入口转入另一个模块内部时 | 模块内部关联 |
1.2.4 系统设计的核心流程
- 系统分析阶段:明确软件 "做什么",形成目标系统的逻辑模型(以规格说明书描述)。
- 系统设计阶段:将 "做什么" 的逻辑模型转换为 "怎么做" 的物理模型,制定系统蓝图,权衡技术与实施方法,确定详细设计方案。
- 设计步骤:
- 概要设计:基本任务包括设计软件系统总体结构、数据结构及数据库设计、编写概要设计文档、评审。
- 详细设计:基本任务包括模块内详细算法设计、模块内数据结构设计、数据库的物理设计、其他设计(代码、输入 / 输出格式、用户界面)、编写详细设计说明书、评审。
1.3 系统总体结构设计
1.3.1 系统结构设计原则
- 分解 ------ 协调原则:将系统分解为子系统,协调子系统间的交互。
- 自顶向下原则:从系统顶层开始设计,逐步细化到底层模块。
- 信息隐蔽和抽象原则:隐藏模块内部细节,通过抽象简化设计。
- 一致性原则:设计风格、命名规范等保持一致。
- 明确性原则:模块功能、接口等定义清晰,无歧义,消除多重功能和无用接口(避免病态连接和降低接口复杂度)。
- 模块间高内聚低耦合:保证模块独立,减少相互依赖(独立性高)。
- 模块的扇入系数和扇出系数合理:扇入指调用该模块的上级模块数,扇出指该模块调用的下级模块数,避免过大或过小。
- 模块规模适当:模块功能不宜过于复杂或简单,便于维护与理解。
- 模块的作用范围应该在控制范围之内。
1.3.2 子系统划分的原则
- 子系统要具有相对独立性,功能边界清晰。
- 子系统之间数据的依赖性尽量小,减少数据交互复杂度。
- 子系统划分的结果应使数据冗余较小,避免重复存储。
- 子系统的设置应考虑今后管理发展的需要,具备可扩展性。
- 子系统的划分应便于系统分阶段实现,降低开发难度。
- 子系统的划分应考虑到各类资源的充分利用,优化资源配置。
1.4 系统文档

二. WebApp 分析与设计(不常考)
2.1 WebApp 分析
2.1.1 WebApp 的定义与开发模式
- WebApp(基于 Web 的系统和应用):大多数采用**敏捷开发过程模型(软件工程里有提到)**进行开发,适应需求快速变化的特点。
2.1.2 WebApp 的特性
- 网络密集性:服务于不同客户群体的需求,依赖网络环境。
- 并发性:支持大量用户同时访问,需保证并发处理能力。
- 无法预知的负载量:用户数量波动大,需应对突发高负载。
- 性能:响应时间过长易导致用户流失,需优化性能。
- 可用性:需保证高可用性(如 7×24×365 可用),减少 downtime。
- 数据驱动:与用户的数据交互频繁,需高效管理数据。
2.1.3 WebApp 的五种需求模型
- 内容模型 :
- 定义:给出 WebApp 提供的全部内容(文字、图形、图像、音频、视频),包含结构元素(内容对象、分析类),为内容需求提供视图。
- 特点:内容开发可贯穿 WebApp 实现前、构建中、运行后;内容对象包括产品描述、新闻文章等;数据树是内容设计基础,定义层级关系,审核内容以发现遗漏和不一致。
- 交互模型 :
- 定义:描述用户与 WebApp 的交互方式,由用例、顺序图、状态图、用户界面原型等元素构成。
- 核心工具:
- 用例:方便客户理解系统功能,是交互分析的主要工具。
- 顺序图:描述用户与系统交互的顺序(如登录流程)。
- 状态图:对系统进行动态描述(如状态变化)。
- 用户界面原型:展现界面布局、内容、导航链接、交互机制及美观度。
- 功能模型 :
- 定义:定义用于 WebApp 内容的操作,及其他非内容但用户必需的处理功能,常以用户交互活动为目标。
- 特点:功能与内容直接相关(如生成统计报表),需满足用户操作需求。
- 导航模型 :
- 定义:为 WebApp 定义所有导航策略,考虑每类用户从一个元素(如内容对象)到另一个元素的导航路径。
- 配置模型 :
- 定义:描述 WebApp 所在的环境和基础设施,复杂配置体系可用 UML 部署图表示。
2.2 WebApp 设计
2.2.1 架构设计
- 核心结构:采用多层架构,包括用户界面 / 展示层、控制器层(基于业务规则指导与客户端浏览器的信息交互)、内容 / 模型层(包含 WebApp 业务规则)。
- 典型架构:MVC(模型 - 视图 - 控制器)结构------ 分离 WebApp 的功能与信息内容,模型负责数据与业务逻辑,视图负责用户界面展示,控制器负责协调模型与视图的交互。
2.2.2 构件设计
- WebApp 构件:定义良好的聚合功能单元,包含内容设计元素(内容对象及展示方式)和功能设计元素(处理逻辑),需与信息体系结构保持一致。
- 构件级内容设计:关注内容对象的表现形式,适配 WebApp 特性。
- 构件级功能设计:将 WebApp 拆分为多个构件并行开发,确保功能一致性。
2.2.3 内容设计
- 核心:着重于内容对象的表现和导航组织,常用结构包括线性结构、网格结构、层次结构、网络结构及它们的组合,需兼顾用户体验与内容访问效率。
2.2.4 导航设计
- 核心:定义导航路径,使用户能便捷访问 WebApp 的内容和功能,需结合用户类型与使用场景,设计清晰、直观的导航方式(如菜单、面包屑导航)。
三. 软件需求
3.1 需求的分类
3.1.1 按需求内容分类
- 业务需求:客户提出的宏观功能需求,反映组织的业务目标。
- 用户需求:设计人员调查的每个用户的具体需求,体现用户的操作诉求。
- 系统需求:整合业务需求与用户需求后形成的最终需求,包括功能需求、性能需求、设计约束三个方面。
3.1.2 从客户角度分类
- 基本需求:需求规格说明书中明确规定的功能,是系统必须实现的核心需求。
- 期望需求:客户认为理所应当包含的功能(未明确写出但隐含的需求)。
- 兴奋需求:客户未要求的额外功能,可能增加开发成本与时间,需权衡必要性。
3.1.3 软件需求的详细分类
- 功能需求:软件必须完成的基本动作(如数据查询、数据录入)。
- 性能需求:软件或人机交互的静态 / 动态数值需求(如系统响应时间、数据处理速度)。
- 设计约束:受硬件、软件、标准等外部因素的限制(如需兼容特定操作系统)。
- 属性需求:软件的质量属性(可用性、安全性、可维护性、可转移性)。
- 外部接口需求:用户接口(如界面风格)、硬件接口(如与打印机的连接)、软件接口(如与数据库的交互)、通信接口(如网络协议)。
3.2 需求工程
3.2.1 需求工程的六个阶段
- 需求获取:通过收集资料、联合讨论会(JRP)、用户访谈、书面调查、现场观摩、参加业务实践、阅读历史文档、抽样调查等方法获取需求。
- 需求分析与协商:分析不同来源需求的关系,判断需求的合理性与一致性,协调需求冲突。
- 系统建模:建立系统的抽象模型(如数据流图、E-R 图),可视化需求。
- 需求规约(需求定义):编写需求规约(需求规格说明书),在开发方与用户间达成共识。
- 需求验证 :通过评审验证需求的完整性、一致性、可行性,验证通过后由用户签字确认,形成需求基线(作为后续开发与验收的依据)。
- 需求管理:规划和控制需求工程的所有过程,确保需求的稳定性与可追溯性。
3.2.2 需求管理的核心内容
- 定义需求基线:通过评审的需求说明书即为需求基线,需求变更需按流程执行。
- 处理需求变更:重点关注需求变更中的风险管理,需避免的高风险做法包括:无足够用户参与、忽略用户分类、用户需求不断增加、模棱两可的需求、不必要的特性、过于精简的 SRS(需求规格说明书)、不准确的估算。
- 需求跟踪 :
- 双向跟踪:包括正向跟踪(确认用户原始需求是否全部实现)和反向跟踪(确认软件实现的功能均为用户要求,无多余功能)。
- 目的:确保需求与最终产品的一致性,便于追溯需求变更影响。
四. 结构化分析
4.1 结构化分析方法(SA)的核心特点
- 自顶向下、逐步分解,面向数据流,是一种数据驱动的分析方法。
- 需建立的核心模型:功能模型(数据流图)、行为模型(状态转换图)、数据模型(E-R 图)、数据字典(定义数据元素、结构、流、存储、加工逻辑、外部实体)。
4.2 数据流图(DFD)
4.2.1 数据流图的定义与作用
- 定义:数据流图(Data Flow Diagram)是描述系统数据流程的图形工具,摆脱物理内容,从逻辑上描述系统的功能、输入、输出和数据存储,是系统逻辑模型的核心组成部分。
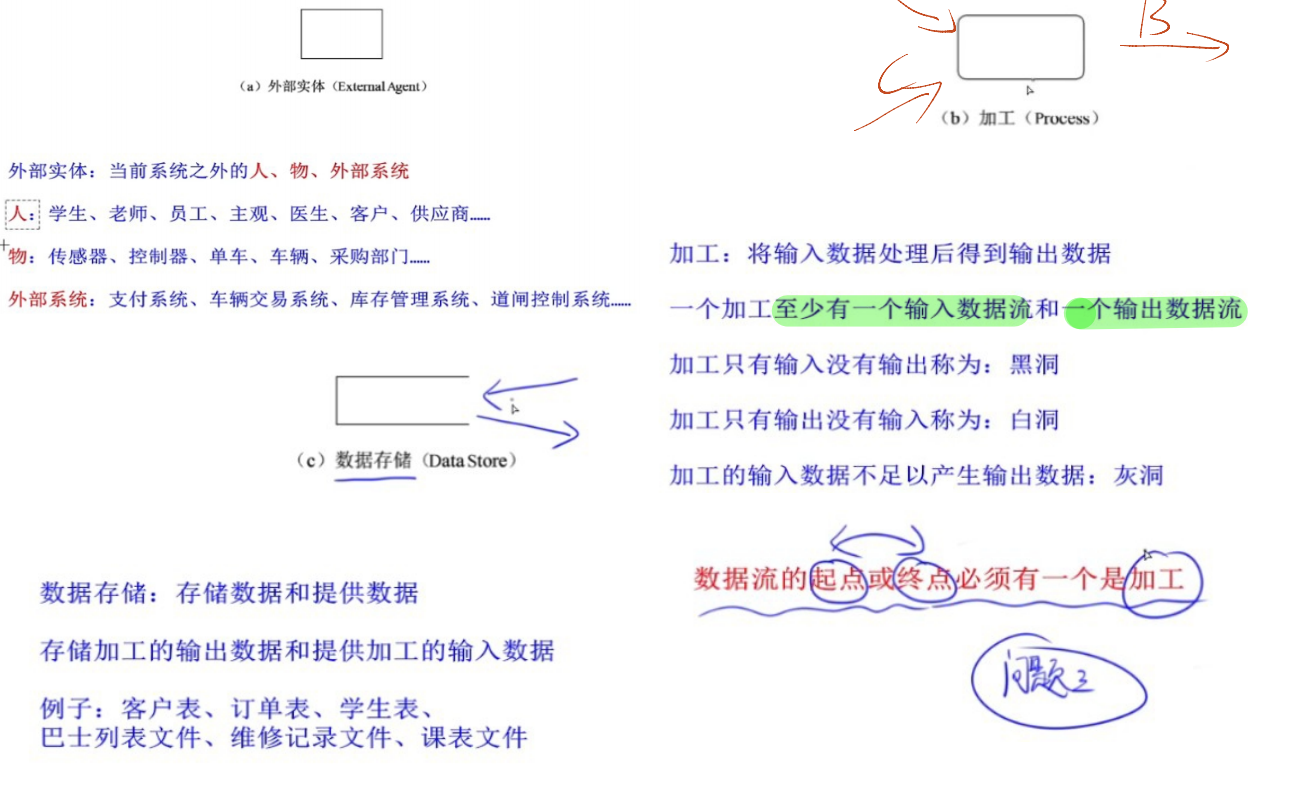
4.2.2 DFD 的基本成分及图形表示
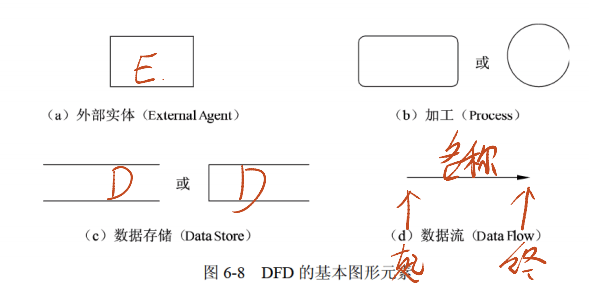
| 成分 | 说明 | 图形表示 |
|---|---|---|
| 外部实体 | 存在于软件系统之外的人员或组织,是系统数据的发源地或归宿地 | 矩形 |
| 加工 | 描述输入数据流到输出数据流的变换,有唯一名字和编号,编号反映其在分层 DFD 中的层次与位置 | 圆角矩形 / 矩形 |
| 数据存储 | 表示暂时存储的数据(如文件、数据库表),有唯一名字,流向数据存储为写操作,流出为读操作 | 开口矩形(或双杠矩形) |
| 数据流 | 由固定成分的数据组成,反映数据流向,除与数据存储直接交互的数据流外,均需命名以反映含义 | 带箭头的直线 |
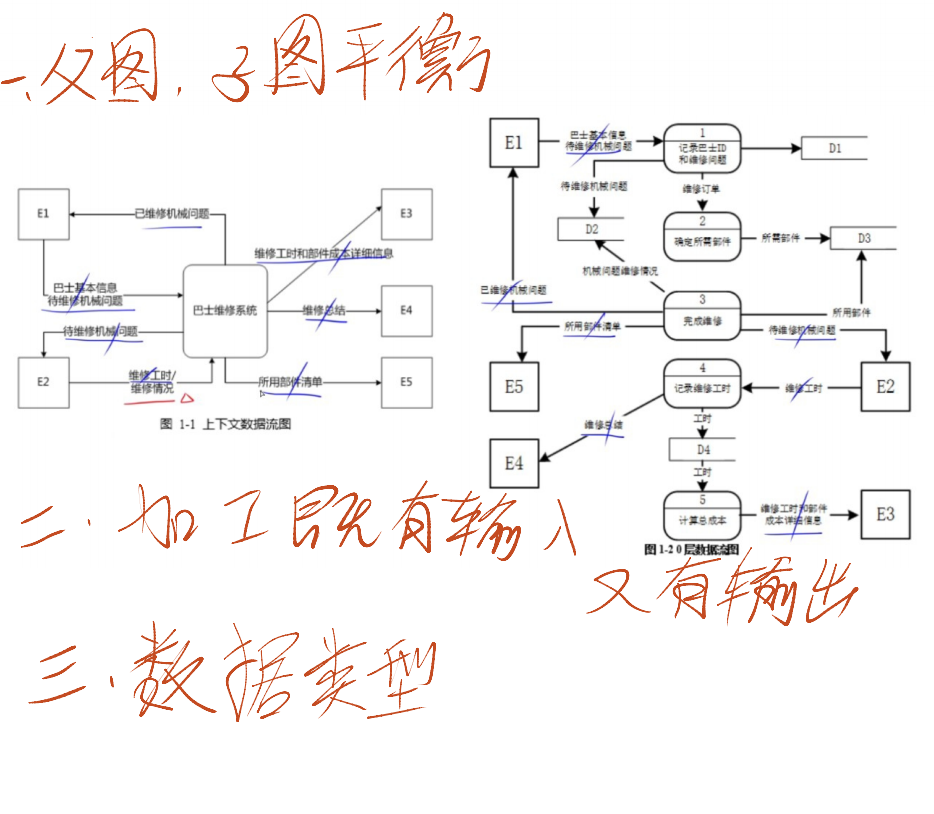
4.2.3 分层数据流图的画法
- 画顶层图:将整个软件系统视为一个大加工,画出系统与外部实体的输入 / 输出数据流,描述系统的边界。
- 画 0 层图 :将顶层图的加工分解为若干子加工,用数据流连接子加工,使顶层输入数据流经子加工处理后转换为顶层输出数据流,明确系统内部的核心流程。
- 确定加工的方法:在数据流组成或值发生变化的地方画加工;或根据系统功能划分加工。
- 确定数据流的方法:将用户视为一个单位处理的若干数据看作一个数据流。
- 画子图:将 0 层图中的每个加工视为小系统,按画 0 层图的方法画出每个加工的 DFD 子图,逐步细化流程。
4.2.4 图与加工的编号规则
- 顶层图:仅 1 个加工,无需编号。
- 0 层图:仅 1 张,加工号可设为 0.1、0.2... 或 1、2...。
- 子图:子图号等于父图中被分解的加工号;子图内加工号格式为 "子图号。序号"(如父图加工为 2,子图加工号为 2.1、2.2...)。
- 父图与子图关系:若图 A 的加工被图 B 分解,则图 A 为父图,图 B 为子图;父图有 n 个加工时,可对应 0~n 张子图(同一层)。
4.2.5 数据流图设计的注意事项(重点)
- 为数据流、加工、数据存储、外部实体命名,名字需反映实际含义,避免空洞(如 "数据 1""加工 2")。
- 画数据流而非控制流,数据流需体现数据的传递,而非控制逻辑。
- 每条数据流必须与加工相关(输入来自加工或外部实体,输出指向加工或外部实体),外部实体间、外部实体与数据存储间、数据存储间无直接数据流。
- 一个加工的输出数据流与输入数据流不能同名,即使组成成分相同。
- 允许一个加工有多条数据流流向另一个加工,或有两个相同输出数据流流向不同加工。
- 保持父图与子图平衡:子图的输入 / 输出数据流需与父图对应加工的输入 / 输出数据流在数量和名字上一致;若父图一个数据流对应子图多个数据流,需保证子图数据流的 data 项全体与父图数据流一致。
- 数据存储的处理:首次出现仅与一个加工相关的 data 存储,可作为该加工的内部文件,在父图中省略;整套 DFD 中每个 data 存储需既有读又有写数据流,单张子图可例外。
- 保持数据守恒:加工的输出数据流数据需能从输入数据流直接获得或由加工产生,无无来源的输出。
- 每个加工必须既有输入数据流又有输出数据流,避免 "无输入" 或 "无输出" 的无效加工。
4.3 数据字典
4.3.1 数据字典的定义与作用
- 定义:用于定义数据流图中所有符号(数据流、加工、数据存储、外部实体)的含义,确保 DFD 的一致性与可理解性。
- 作用:作为 DFD 的补充说明,是结构化分析的核心文档之一,为后续设计与开发提供数据依据。
4.3.2 数据字典的常用符号及含义
| 符号 | 含义 | 举例说明 | ||
|---|---|---|---|---|
| = | 被定义为 | 学生信息 = 学号 + 姓名 + 性别 + 年龄 | ||
| + | 组成(表示数据由多个部分构成) | 学号 = 入学年份 + 学院代码 + 专业代码 + 序号 | ||
| A,B 或 [A | B] | 或(数据取其中一个部分) | 性别 =男,女 或 性别 =[男 | 女] |
| {...} | 重复(数据由 0 个或多个某部分构成) | 成绩列表 ={成绩}(成绩列表由 0 个或多个成绩组成) | ||
| (...) | 可选(数据中该部分可出现或不出现) | 学生信息 = 学号 + 姓名 +(联系方式)(联系方式可选) |
4.3.3 数字词典的管理

4.3.4 加工逻辑的描述


以下不常考
五. 测试基础知识(软件工程里的单元测试里提到过)
5.1 测试的定义与原则
5.1.1 测试的定义
- 系统测试是为了发现错误而执行程序的过程,成功的测试是发现至今尚未发现的错误的测试(而非无错误的测试)。
5.1.2 测试的核心原则
- 应尽早并不断地进行测试(从需求阶段开始,贯穿开发全过程)。
- 测试工作应避免由原开发软件的人或小组承担(避免主观偏见)。
- 设计测试方案时,需确定输入数据和基于系统功能的预期输出结果。
- 测试用例需包含有效 / 合理用例和无效 / 失效用例,全面覆盖场景。
- 检验程序是否 "做了该做的事"(功能正确性)和 "没做不该做的事"(无多余功能)。
- 严格按照测试计划执行,避免随意测试。
- 妥善保存测试计划和测试用例,便于追溯与复用。
- 测试用例可重复使用或追加测试,支持回归测试。
5.2 测试阶段
5.2.1 单元测试
- 测试对象:单个模块(如函数、类)。
- 测试执行:由程序员自行测试,验证模块内部的接口、信息传递、功能正确性。
- 测试依据:软件详细说明书。
- 辅助模块:
- 驱动模块(上层模块):调用被测模块,模拟上级模块的功能。
- 桩模块(底层模块):模拟被测模块调用的子模块,返回预设数据。
- 特点:自顶向下的单元测试中无需额外编写驱动模块。
5.2.2 集成测试
- 测试对象:多个模块组合后的整体(验证模块间的接口与交互)。
- 集成方式:
- 一次性组装:将所有模块一次性组合测试,简单、节省时间,但发现错误少,仅适用于小规模项目。
- 增量式组装:逐步添加模块测试,能发现更多错误,但耗时长,包括:
- 自顶向下集成:从顶层模块开始,逐步集成下层模块,需编写桩模块。
- 自底向上集成:从底层模块开始,逐步集成上层模块,需编写驱动模块。
- 混合式集成:结合自顶向下与自底向上,兼顾两者优势,但测试工作量大。
5.2.3 确认测试
- 测试对象:已完成集成的软件系统。
- 测试目标:验证软件功能是否符合需求规格说明书。
- 测试类型:
- 内部确认测试:无用户参与,由开发方内部执行。
- Alpha 测试:用户在开发环境下测试,发现问题直接反馈开发方。
- Beta 测试:用户在实际使用环境下测试,模拟真实场景。
- 验收测试:用户根据需求规格说明书(SRS)对项目进行验收,决定是否接收。
5.2.4 系统测试
- 测试对象:完整的软件系统(含硬件、软件、网络等)。
- 测试目标:验证系统的性能、可靠性、兼容性等非功能需求。
- 核心测试类型:
- 负载测试:测试系统在极限负载下的性能指标(如并发用户数、数据量)。
- 强度测试:测试系统在资源极度短缺(如内存不足、CPU 占用过高)时的表现。
- 容量测试:测试系统可处理的同时在线最大用户数量(并发测试)。
- 测试方法:采用黑盒测试方法,不关注内部实现逻辑。
5.2.5 回归测试
- 测试时机:软件修改错误或需求变更后。
- 测试目标:验证修改是否引入新错误,确保原有正确功能不受影响。
5.3 测试方法
5.3.1 动态测试(程序运行时测试)
- 黑盒测试法(功能性测试) :
- 特点:不了解软件代码结构,仅根据功能需求设计用例,验证软件功能是否符合预期。
- 适用场景:确认测试、系统测试。
- 白盒测试法(结构性测试) :
- 特点:明确代码逻辑,根据代码流程设计用例,覆盖代码分支与语句。
- 适用场景:单元测试、集成测试。
- 灰盒测试法:结合黑盒与白盒测试,既关注功能又关注部分内部逻辑。
5.3.2 静态测试(程序静止时测试)
- 定义:不运行程序,通过人工审查代码与文档发现问题。
- 测试类型:
- 桌前检查:程序员自行检查自己编写的程序,在编译后、单元测试前执行。
- 代码审查:由程序员与测试人员组成评审小组,通过会议审查代码。
- 代码走查:小组会议形式,测试人员提供测试用例,程序员模拟计算机手动运行用例,检查代码逻辑。
5.4 测试策略
| 策略 | 核心流程 | 优点 | 缺点 |
|---|---|---|---|
| 自底向上测试 | 从最底层模块开始测试,编写驱动模块,逐步合并模块至整个系统 | 较早验证底层模块的正确性 | 需编写大量驱动模块,较晚验证系统整体逻辑 |
| 自顶向下测试 | 从顶层模块开始测试,编写桩模块,逐步集成至底层模块 | 较早验证系统主要控制与判断点 | 需编写大量桩模块,较晚验证底层模块正确性 |
| 三明治测试(混合测试) | 同时进行自顶向下与自底向上测试,中间层模块最后集成 | 兼顾两者优势,减少驱动 / 桩模块编写量 | 测试工作量大,协调复杂 |
5.5 测试用例设计
5.5.1 黑盒测试用例设计方法
- 等价类划分 :
- 核心思想:将输入数据按特性分类(有效等价类、无效等价类),每类选取一个用例覆盖,减少用例数量。
- 设计原则:
- 有效等价类:每个用例尽可能覆盖多个未覆盖的有效等价类。
- 无效等价类:每个用例仅覆盖一个未覆盖的无效等价类。
- 边界值划分 :
- 核心思想:选取数据范围的边界值(如范围 0~150 的边界值为 - 1、0、150、151)作为测试用例,边界处易出现错误。
- 错误推测 :
- 核心思想:凭经验推测可能出错的场景(如输入为空、输入特殊字符)设计用例,无固定方法。
- 因果图 :
- 核心思想:根据输入条件(因)与输出结果(果)的逻辑关系设计用例,覆盖所有因果组合,适用于条件复杂的场景。
5.5.2 白盒测试用例设计方法(覆盖级别从低到高)
- 语句覆盖:设计用例使代码中所有语句都被执行一次,覆盖层级最低(仅保证语句执行,不保证条件判断覆盖)。
- 判定覆盖(分支覆盖):设计用例使所有判断语句的真假分支都被覆盖一次。
- 条件覆盖 :设计用例使每个判断中的独立条件(如
a>0 && b<0中的a>0和b<0)的真假分支都被覆盖一次,覆盖层级高于判定覆盖。 - 判定 / 条件覆盖:设计用例使判断中每个条件的所有取值(真 / 假)至少出现一次,且每个判断的结果(真 / 假)也至少出现一次,综合判定覆盖与条件覆盖。
- 条件组合覆盖:设计用例使每个判断中条件的所有可能取值组合都至少出现一次,覆盖层级高于判定 / 条件覆盖。
- 路径覆盖:设计用例覆盖代码中所有可行路径,覆盖层级最高,确保所有逻辑流程都被验证。
5.6 调试
5.6.1 调试与测试的区别
- 测试:发现错误;调试:找出错误的代码位置与原因,并修复错误。
5.6.2 调试的核心步骤
- 确定错误的准确位置。
- 分析错误原因并设法改正。
- 改正后执行回归测试,验证错误已修复且无新错误引入。
5.6.3 常用调试方法
- 蛮力法:通过输出日志、断点调试等方式逐步排查错误,适用于简单错误。
- 回溯法:从错误出现的位置反向追溯代码流程,定位错误根源,适用于小型程序。
- 原因排除法 :列出所有可能的错误原因,逐一验证排除,包括:
- 演绎法:从一般原因推导具体错误。
- 归纳法:从具体错误现象归纳通用原因。
- 二分法:将代码或数据范围二分,逐步缩小错误范围。
六. 系统转换
6.1 系统转换的定义与转换计划
6.1.1 系统转换的定义
- 系统转换是新系统开发完毕后,投入运行并取代现有系统的过程,需实现与老系统的平稳交接。
6.1.2 三种系统转换计划
| 转换方式 | 核心流程 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 直接转换 | 新系统直接取代老系统,老系统停止使用 | 节省成本,转换速度快 | 风险大,一旦新系统故障会影响业务 | 新系统不复杂,或老系统已无法使用 |
| 并行转换 | 新系统与老系统并行运行一段时间,新系统试运行通过后再取代老系统 | 风险极小,可对比新老系统性能,故障不影响业务 | 耗费人力与时间,需协调两系统数据转换 | 大型系统、关键业务系统 |
| 分段转换(逐步转换) | 将大型系统分为多个子系统,分期分批转换,成熟一个子系统替换一个 | 风险可控,兼顾直接与并行转换优势 | 耗时久,需协调新老系统接口 | 大型复杂系统 |
6.2 数据转换与迁移
6.2.1 数据迁移的核心目标
- 将数据从旧数据库迁移到新数据库,尽可能保留旧系统合理的数据结构,降低迁移难度。
6.2.2 数据迁移的三种方法
- 系统切换前通过工具迁移(如 ETL 工具)。
- 系统切换前采用手工录入(适用于数据量小的场景)。
- 系统切换后通过新系统生成(适用于可重新计算或采集的数据)。
6.2.3 数据迁移的 ETL 流程
- 抽取(Extract):从旧数据库中提取需要迁移的数据。
- 转换(Transform):对抽取的数据进行清洗、转换(如格式统一、数据映射),确保符合新系统要求。
- 装载(Load):将转换后的数据装入新数据库,并校验数据的完整性与准确性。
七. 系统维护
7.1 系统维护的定义与可维护性评价
7.1.1 系统维护的定义
- 软件维护是软件生命周期的最后一个阶段,不属于系统开发过程,指软件交付使用后,为改正错误、满足新需求而修改软件的过程。
7.1.2 系统可维护性的评价指标
- 可维护性:维护人员理解、改正、改动和改进软件的难易程度,核心指标包括:
- 易测试性:确认修改后软件所需的努力程度。
- 易分析性:诊断缺陷 / 失效原因、判定需修改部分的努力程度。
- 易改变性:修改、排错或适应环境变化的努力程度。
- 稳定性:修改导致未预料效果的风险程度。
7.2 系统维护的分类
系统维护包括硬件维护、软件维护和数据维护,其中软件维护分为以下四类:
| 维护类型 | 定义 | 示例 |
|---|---|---|
| 正确性维护 | 发现软件 bug 后进行的修改,修复错误 | 修复登录功能无法正常验证的问题 |
| 适应性维护 | 因外部环境变化(如操作系统升级、硬件更换)被动进行的修改与升级 | 软件适配新版本 Windows 系统 |
| 完善性维护 | 基于用户主动提出的新需求,修改软件以增加功能、提升性能 | 为文档软件增加 "云端备份" 功能 |
| 预防性维护 | 对未来可能出现的 bug 进行预防性修改,降低故障风险 | 优化代码逻辑以避免潜在的内存泄漏 |
八. 系统评价
8.1 系统评价的分类
| 评价类型 | 评价时机与目标 |
|---|---|
| 立项评价(预评价) | 系统开发前,分析项目是否具备开发可行性(如技术、经济、管理可行性),决定是否立项 |
| 中期评价(阶段评审) | 项目开发中期(如需求阶段、设计阶段结束后),或项目中途遇重大变故时,评价阶段成果是否合格、项目是否继续 |
| 结项评价(最终评价) | 系统投入正式运行后,评价系统是否达到预期目标与需求,综合评估系统的性能、效益、适用性 |
8.2 系统评价的核心指标
系统评价指标可从三个维度构建:
- 人机协同维度:运行效果与用户需求(人的维度)、系统质量与技术条件(机的维度)。
- 评价对象维度:开发方关注的系统质量与技术水平、用户方关注的用户需求与运行质量、外部环境关注的社会效益。
- 经济学维度:系统成本(开发成本、维护成本)、系统效益(直接经济效益、间接经济效益)、财务指标(投资回报率、回收期)。