面向智能体与大语言模型的 AI 基础设施:选项、工具与优化
本文探讨了用于部署和优化 AI 智能体(AI Agents)与大型语言模型(LLMs)的各类基础设施选项及工具。
无论采用云、本地还是混合云部署,基础设施在 AI 架构落地过程中都起着关键作用。本文是 AI 基础设施系列文章的一部分,聚焦于部署和优化 AI 智能体与大语言模型的多样化基础设施选择,深入剖析了基础设施在 AI 架构(尤其是推理环节)实现中的核心价值。我们将详细介绍包括开源解决方案在内的各类工具,通过图表展示推理流程,并强调高效、可扩展 AI 部署的关键考量因素。
现代 AI 应用对基础设施提出了精密化要求------需承载大语言模型的计算强度、多智能体系统的复杂性,以及交互式应用的实时性需求。核心挑战不仅在于选择合适的工具,更在于理解这些工具如何在整个技术栈中协同集成,从而交付可靠、可扩展且经济高效的解决方案。
本指南涵盖 AI 基础设施的全维度内容,从硬件加速、模型服务到监控与安全,详细解析了经过生产环境验证的开源工具、架构模式及实施策略。
一、AI 基础设施在架构中的核心作用
AI 架构定义了 AI 系统构建与部署的蓝图,而基础设施则是支撑该架构落地的基石。对于 AI 智能体与大语言模型而言,基础设施直接影响系统性能、可扩展性、成本与可靠性。设计精良的基础设施能够实现:
- 更快的推理速度:低延迟对交互式 AI 智能体和实时应用至关重要
- 更强的可扩展性:在用户需求增长时保持性能稳定
- 更高的成本效益:优化资源利用率以降低运营支出
- 更优的可靠性:确保高可用性和容错能力
二、AI 基础设施栈:分层架构设计
现代 AI 基础设施栈由七个相互关联的层级构成,每个层级承担特定功能,同时与相邻层级实现无缝集成。理解这一分层架构,对于工具选型、资源分配及运维策略制定具有重要指导意义。
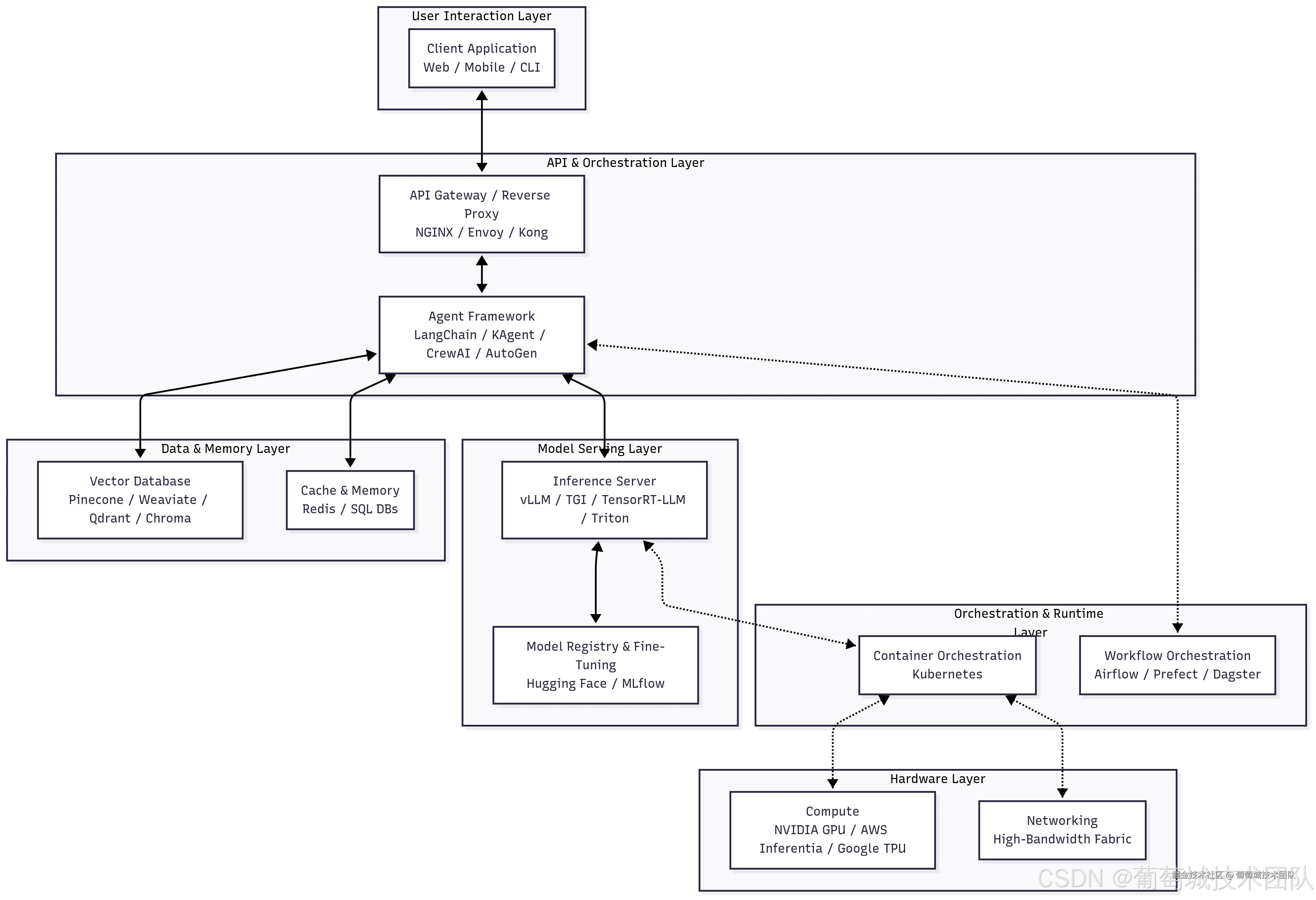
(一)层级解析与核心工具
- 用户交互层:用户请求的入口,客户端可包括 Web 界面、移动应用或命令行工具。核心需求是与后端 API 层建立稳定、低延迟的连接。
- API 与编排层 :负责管理用户请求并编排复杂工作流
- API 网关(NGINX、Envoy、Kong):作为统一入口,处理流量接入、身份认证、限流及路由
- 智能体框架(LangChain、KAgent、CrewAI、AutoGen):AI 业务逻辑核心,其中 KAgent 是专为高效编排设计的专用工具,支持 AI 任务的动态路由与工作流管理
- 数据与内存层 :提供上下文支持和持久化存储,将无状态模型转化为具备知识储备的助手
- 向量数据库(Pinecone、Weaviate、Qdrant、Chroma):用于存储和查询高维向量的专用数据库,是检索增强生成(RAG)的核心组件
- 缓存与内存(Redis、SQL 数据库):Redis 用于低延迟缓存和短期内存存储,SQL 数据库则存储对话历史、用户偏好等长期数据
- 模型服务层 :推理核心层级,负责模型加载与执行
- 推理服务器(vLLM、TGI、TensorRT-LLM、Triton):专为高吞吐量、低延迟推理优化的服务器,支持动态批处理和量化
- 模型注册与微调(Hugging Face、MLflow):集中式仓库,管理从训练到部署的全模型生命周期
- 编排与运行时层 :抽象底层硬件的基础层级
- 容器编排(Kubernetes):管理容器生命周期,提供可扩展性、弹性及高效资源利用率
- 工作流编排(Airflow、Prefect、Dagster):编排复杂的数据和机器学习流水线,支持训练任务、数据摄入等操作
- 硬件层 :计算的物理载体
- 计算资源(NVIDIA GPU、AWS Inferentia、Google TPU):大语言模型推理必需的专用加速器
- 网络设备(NVLink、InfiniBand):支持多 GPU 和多节点通信的高速互联设备
(二)层级依赖与数据流
基础设施栈的每个层级都有明确的职责范围,并通过标准化协议和 API 与其他层级交互:
- 用户交互层处理所有外部交互,将用户请求转换为下游服务可处理的标准化格式
- API 网关层提供安全、路由和流量管理核心功能,确保请求经过正确认证、授权后分发至可用资源
- 服务编排层管理容器化服务的生命周期,负责 AI 工作负载的部署、扩缩容和健康监控------这一层对 AI 应用尤为重要,因其需应对动态资源需求,且需通过精密调度算法考量 GPU 可用性、模型加载时间和内存约束
- AI 服务层包含 AI 应用的核心业务逻辑,涵盖模型推理引擎、智能体编排系统和工具集成框架,抽象不同 AI 框架的复杂性并为上游服务提供统一 API
- 计算与加速层提供 AI 工作负载所需的原始计算能力,通过专用硬件为不同类型操作提供加速支持
- 存储层管理冷热数据,包括模型权重、向量嵌入和应用状态
- 监控与可观测性层提供全层级的系统性能、用户行为和运维健康状态可视化工具有
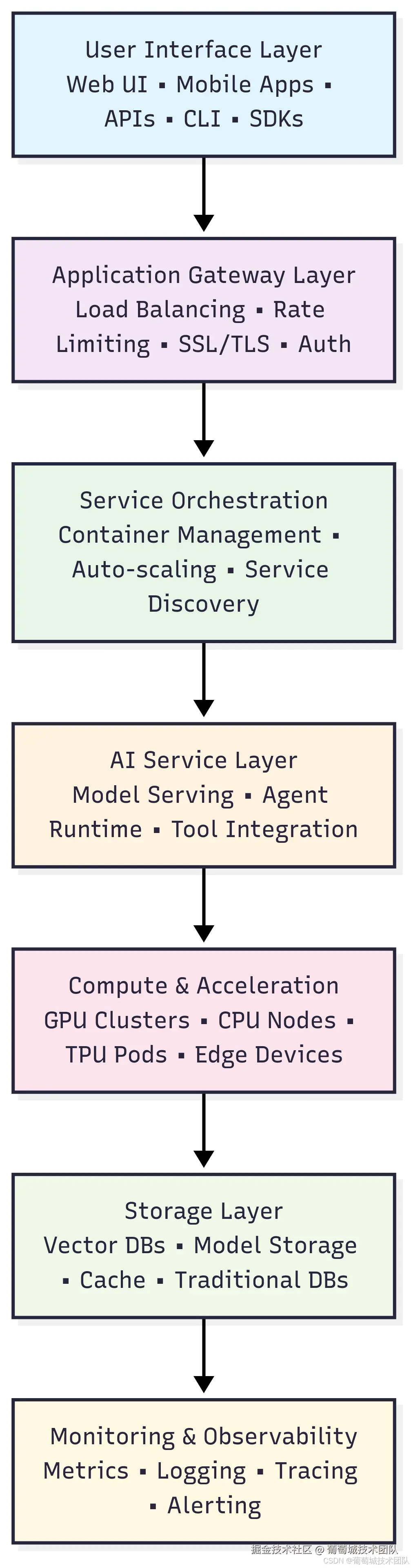
层级构成:用户交互层 → API 网关层 → 服务编排层 → AI 服务层 → 计算与加速层 → 存储层 → 监控与可观测性层 各层核心功能:
- 用户交互层:Web UI/移动应用、API/命令行工具/SDK
- API 网关层:负载均衡、限流、SSL/TLS 加密、身份认证
- 服务编排层:容器管理、自动扩缩容、服务发现
- AI 服务层:模型服务、智能体运行时、工具集成
- 计算与加速层:GPU 集群、CPU 节点、TPU Pod、边缘设备
- 存储层:向量数据库、模型存储、缓存、传统数据库
- 监控与可观测性层:指标采集、日志记录、链路追踪、告警通知
三、推理流程:从用户提示到 AI 响应
用户查询在 AI 基础设施中的流转涉及多个步骤和工具,以下流程图展示了完整流程及核心组件的交互关系。
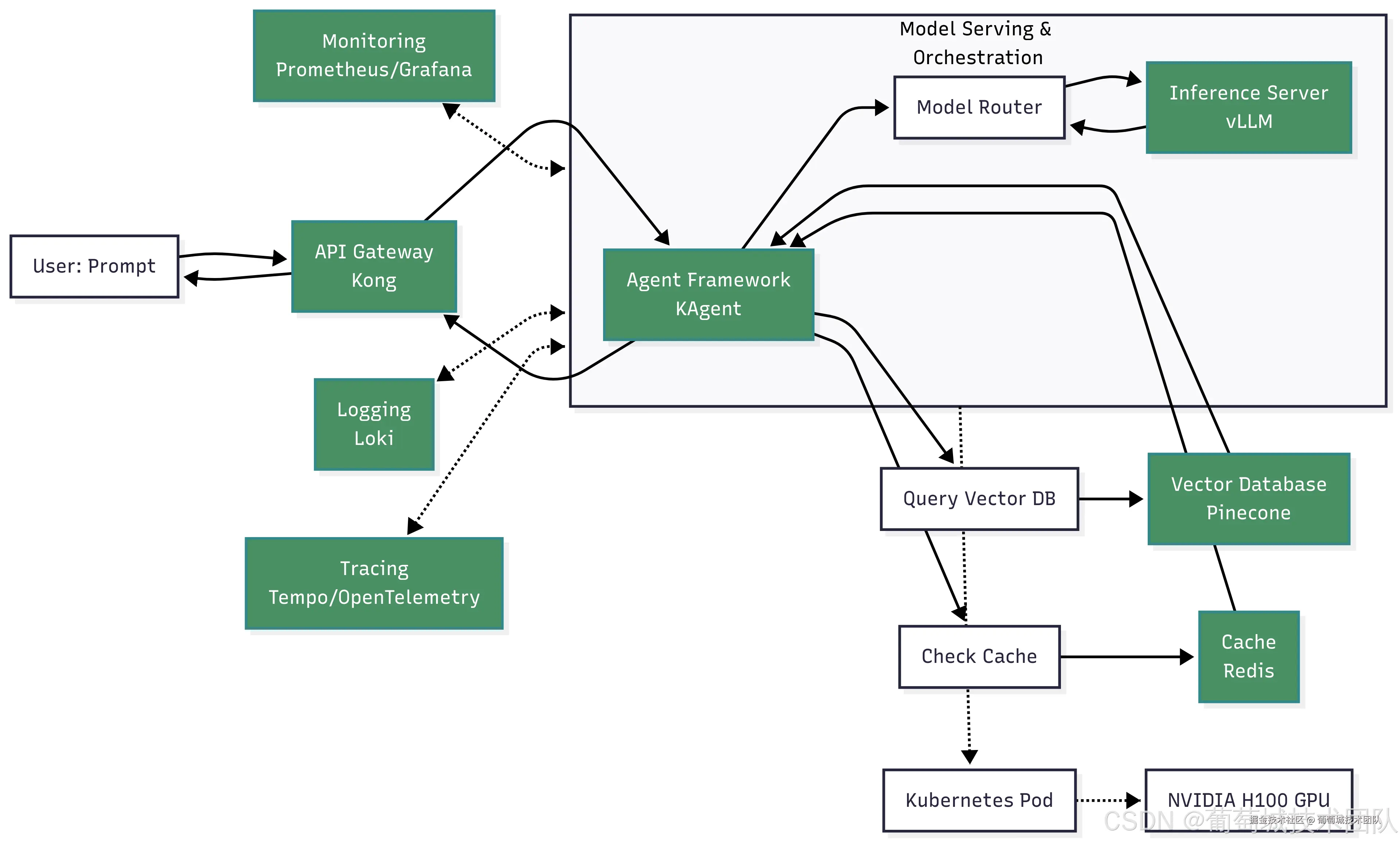
核心组件交互:用户提示 → API 网关(Kong)→ 智能体框架(KAgent)→ 模型路由器 → 推理服务器(vLLM)→ NVIDIA H100 GPU(Kubernetes Pod);配套组件:缓存(Redis)、向量数据库(Pinecone)、监控工具(Prometheus/Grafana)、日志工具(Loki)、链路追踪工具(Tempo/OpenTelemetry)
(一)步骤拆解
- 初始接入:用户通过 Web 界面发送提示词,请求经 API 网关(Kong)路由,网关完成身份认证和限流处理
- 智能体编排:网关将请求转发至 KAgent 等智能体框架,框架解析用户意图并启动多步骤推理流程
- 上下文检索(RAG):智能体将提示词转换为嵌入向量,查询向量数据库(Pinecone),获取内部文档中的相关上下文
- 内存与缓存处理:智能体检查缓存(Redis)中是否存在相似查询,并从 SQL 数据库中检索长期上下文
- 模型路由与推理 :智能体将增强后的提示词发送至模型路由器,路由器调用推理服务器(vLLM);服务器通过动态批处理和 KV 缓存高效生成响应
- KV 缓存的作用:在自回归解码过程中,KV 缓存存储之前所有令牌的键(Key)和值(Value)向量;生成新令牌时,仅需计算该令牌的向量,其余向量从缓存中读取,大幅减少重复计算,降低延迟并提升吞吐量
- 响应生成与执行:生成的响应返回至智能体,智能体可对响应进行后处理或通过 API 调用触发特定操作;最终响应经 API 网关返回给用户
- 可观测性监控:整个流程通过 Prometheus 采集指标、Loki 记录日志、OpenTelemetry 实现链路追踪,确保系统性能全可视
理解端到端推理流程对于优化系统性能和故障排查至关重要。
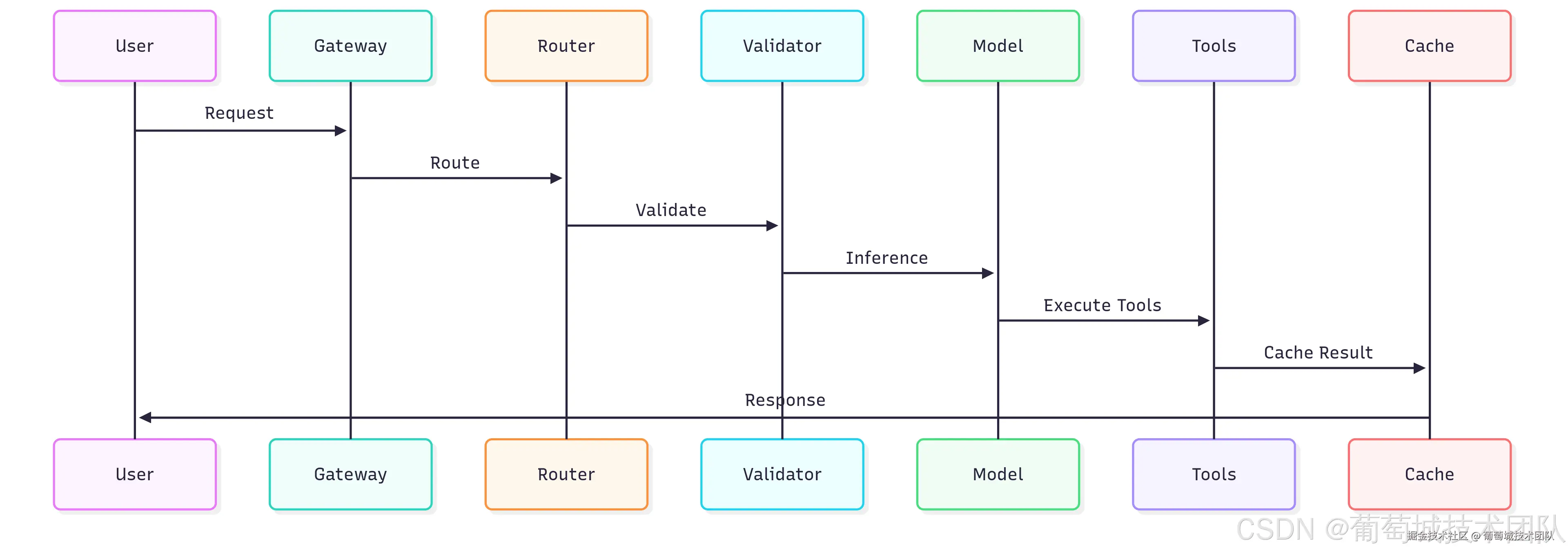
简化流程:用户 → 网关 → 路由器 → 验证器 → 模型 → 工具 → 缓存 → 响应 核心环节:请求路由、输入验证(基于 Pydantic 的 Schema 验证)、推理处理(GPU 加速)、工具执行(智能体专用)、响应缓存(Redis 提升性能)
四、核心开源工具清单
(一)模型服务引擎
- vLLM:生产级推理首选工具,基于分页注意力(PagedAttention)算法和连续批处理技术,吞吐量较传统框架提升 2-4 倍,支持大型模型的张量并行
- 文本生成推理(TGI):具备企业级特性,提供全面监控、流式响应和兼容 OpenAI 的 API,适合追求运维简化的生产部署场景
- Ollama:擅长开发环境和边缘部署,支持自动模型管理、量化处理和简易配置,是原型开发和本地部署的理想选择
(二)智能体框架
- LangChain:生态最全面的框架,支持与工具、数据源及模型提供商的广泛集成,模块化架构可灵活构建复杂工作流
- CrewAI:专注于多智能体场景,采用基于角色的设计,支持智能体协作和复杂团队动态管理
- AutoGen:对话式 AI 框架,支持多智能体通过协作推理和协商解决问题
(三)向量数据库
- ChromaDB:适合开发环境和小规模部署,Python 集成性优异,部署简易,采用 SQLite 后端确保可靠性
- Qdrant:生产环境性能出色,基于 Rust 开发,具备高级过滤能力和分布式扩展特性,支持向量相似度与结构化数据结合的复杂查询
- Weaviate:提供企业级功能,包括混合搜索、多模态支持和 GraphQL API,支持灵活的查询模式
五、AI 智能体架构
AI 智能体超越了简单模型的范畴,是具备复杂推理和行动能力的系统。
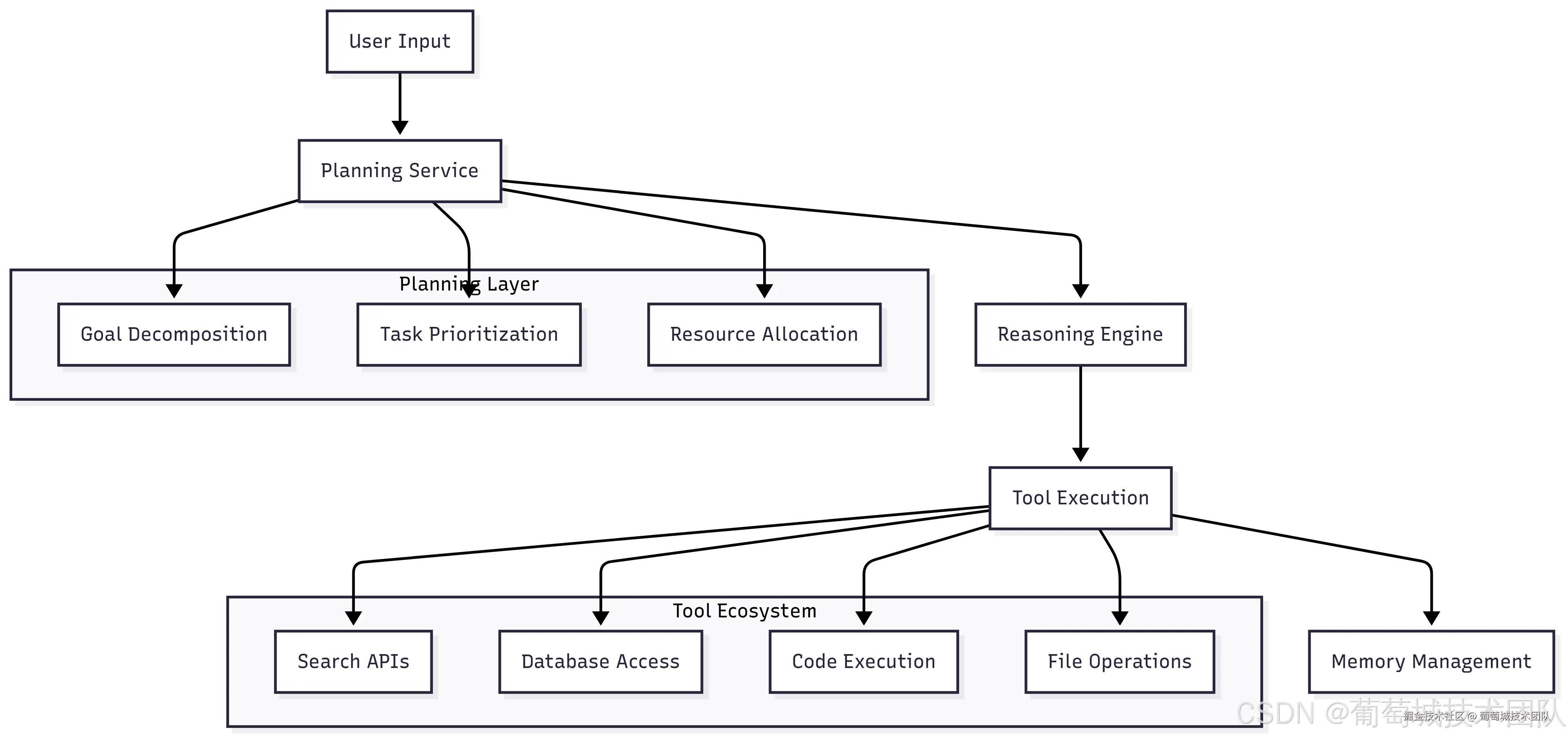
架构组成:用户输入 → 规划服务(规划层:目标分解、任务优先级排序、资源分配、推理引擎)→ 工具执行(工具生态:搜索 API、数据库访问、代码执行、文件操作)→ 内存管理(工作内存、情景记忆、语义记忆)
(一)核心组件
- 规划服务:将复杂请求分解为可执行的子任务,需考量任务依赖关系、资源约束和故障处理机制
- 工具集成:需实现动态工具发现、安全执行沙箱隔离和性能监控,所有工具需容器化部署,并配置合理的资源限制和网络隔离策略
- 内存系统:管理智能体的各类内存------工作内存(当前上下文)、情景记忆(对话历史)和语义记忆(习得知识)
六、优化策略
(一)模型量化
量化技术可降低内存占用并提升推理速度:
- INT8 量化:内存占用减少 2 倍,精度损失极小
- INT4 量化:内存占用减少 4 倍,精度损失约 2%-5%
(二)模型服务优化
包括 Transformer 模型的 KV 缓存管理、可变请求量的动态批处理,以及多 GPU 部署的张量并行技术。
1. KV 缓存(键值缓存)
KV 缓存是大语言模型高效推理的核心优化技术。若缺少该机制,每个令牌生成时都需重新计算所有历史令牌的向量,导致计算开销难以承受。
(1)工作原理
缓存存储序列中所有历史令牌的计算后键(Key)和值(Value)向量;生成新令牌时,模型仅计算该令牌的 KV 向量,其余向量从缓存中读取。这一机制将计算复杂度从二次降至线性,显著提升推理速度。
(2)挑战与解决方案
- 内存占用问题:KV 缓存可能消耗大量 GPU 内存,尤其对于长序列和大批量请求
- 优化技术:通过缓存卸载、量化和淘汰策略等高级方法,平衡内存使用与性能表现
(三)硬件加速优化
- GPU 优化:聚焦内存带宽利用率提升、计算密集型与内存密集型操作识别,以及多 GPU 协同效率优化
- CPU 优化:充分利用高级指令集(AVX-512、AVX2)、线程库(OpenMP、Intel TBB)和优化数学库(Intel MKL、OpenBLAS)
(四)成本优化策略
- 智能缓存:基于语义相似度的 AI 响应缓存
- 抢占式实例:利用闲置资源处理批处理任务和开发工作
- 模型共享:单个模型实例为多个应用提供服务
- 动态扩缩容:基于队列深度和响应时间目标进行弹性伸缩

优化维度:资源合理配置、使用模式优化、架构优化 核心策略:动态扩缩容(基于需求自动伸缩)、抢占式实例(降低 50%-90%成本)、缓存策略(响应与模型缓存)、批处理(优化 GPU 利用率)、模型优化(量化与剪枝)、多租户(共享基础设施)
七、综合工具参考表
以下表格按基础设施层级整理了完整的开源工具清单,为 AI 系统构建提供全面参考。
| 层级 | 类别 | 工具 | 核心应用场景 |
|---|---|---|---|
| 硬件与云 | GPU 计算 | ROCm、CUDA Toolkit、OpenCL | 硬件加速、GPU 编程、计算优化 |
| 云管理 | OpenStack、CloudStack、Eucalyptus | 私有云基础设施、资源管理 | |
| 容器与编排 | 容器化 | Docker、Podman、containerd、LXC | 应用打包、隔离、可移植性 |
| 编排工具 | Kubernetes、Docker Swarm、Nomad | 容器调度、扩缩容、服务发现 | |
| 分布式计算 | Ray、Dask、Apache Spark、Horovod | 分布式训练、并行处理、多节点推理 | |
| 工作流管理 | Apache Airflow、Kubeflow、Prefect、Argo Workflows | 机器学习流水线自动化、任务调度、工作流编排 | |
| 模型运行时与优化 | 机器学习框架 | PyTorch、TensorFlow、JAX、Hugging Face Transformers | 模型训练、推理、神经网络开发 |
| 推理优化 | ONNX Runtime、TensorRT、OpenVINO、TVM | 模型优化、跨平台推理、性能调优 | |
| 模型压缩 | GPTQ、AutoGPTQ、BitsAndBytes、Optimum | 量化、剪枝、模型体积缩减 | |
| 大语言模型服务 | vLLM、Text Generation Inference、Ray Serve、Triton | 高性能大语言模型推理、请求批处理、扩缩容 | |
| API 与服务 | 模型部署 | BentoML、MLflow、Seldon Core、KServe | 模型打包、版本管理、部署自动化 |
| Web 框架 | FastAPI、Flask、Django、Tornado | REST API 开发、Web 服务、微服务 | |
| 负载均衡 | Nginx、HAProxy、Traefik、Envoy Proxy | 流量分发、反向代理、服务网格 | |
| API 网关 | Kong、Zuul、Ambassador、Istio Gateway | API 管理、身份认证、限流 | |
| 数据与存储 | 向量数据库 | Weaviate、Qdrant、Milvus、Chroma | 嵌入向量存储、语义搜索、RAG 应用 |
| 传统数据库 | PostgreSQL、MongoDB、Redis、Cassandra | 结构化数据存储、缓存、会话存储、元数据管理 | |
| 数据处理 | Apache Kafka、Apache Beam、Pandas、Polars | 流处理、ETL、数据转换 | |
| 特征存储 | Feast、Tecton、Hopsworks、Feathr | 特征工程、特征服务、版本管理、共享 | |
| 监控与可观测性 | 基础设施监控 | Prometheus、Grafana、Jaeger、OpenTelemetry | 指标采集、可视化、分布式链路追踪 |
| 机器学习实验追踪 | MLflow、Weights & Biases、Neptune.ai、ClearML | 实验日志、模型版本管理、超参数追踪 | |
| 大语言模型可观测性 | LangKit、Arize Phoenix、LangSmith、Helicone | 大语言模型性能监控、提示词评估、使用分析 | |
| 日志与分析 | ELK Stack、Fluentd、Loki、Vector | 日志聚合、搜索、分析、告警 | |
| 应用与智能体 | 智能体框架 | LangChain、AutoGen、CrewAI、LlamaIndex | 智能体开发、多智能体系统、工具集成 |
| 工作流自动化 | n8n、Apache Airflow、Temporal、Zapier Alternative | 业务流程自动化、工作流编排 | |
| 安全与访问控制 | Keycloak、HashiCorp Vault、Open Policy Agent | 身份认证、密钥管理、策略执行 | |
| 测试与质量保障 | DeepEval、Evidently、Great Expectations、Pytest | 模型测试、数据验证、质量保障 |
八、结语:基础设施作为战略优势
构建成功的 AI 基础设施需要在即时需求与长期可扩展性之间取得平衡------应从成熟、简洁的解决方案起步,逐步增加系统复杂度。
AI 基础设施架构设计是一项核心工程任务,直接影响 AI 产品的性能、成本和可靠性。基于分层架构构建的精良系统,结合 Kubernetes、vLLM、KAgent 和 Pinecone 等工具,能够支撑大规模部署并提供流畅的用户体验。
AI 基础设施领域发展迅速,但聚焦于开源工具构建坚实基础、实现全面可观测性并追求运维卓越,将帮助企业在把握 AI 技术进步的同时,保持系统的可靠性和可扩展性。尽管不同企业的实施路径因需求差异而有所不同,但本指南提供的框架将为构建具备实际业务价值的 AI 基础设施提供清晰 roadmap。
理解并实施 KV 缓存等高级优化技术,是 AI 系统从原型阶段迈向生产级部署的关键。随着 AI 技术的不断演进,高效的基础设施将持续成为核心差异化优势,助力企业部署功能强大、可扩展且成本效益优异的 AI 应用。