在数字化办公与知识管理领域,"找文档"从来不是简单的文件定位,当一份产品手册同时包含文字说明、工程图纸和参数表格,当一篇科研论文夹杂着公式推导与实验数据图表,当企业的合规文档涉及跨部门的条款关联,传统基于关键词的检索工具往往会陷入"能找到文字却读不懂逻辑"的困境。正是为破解这一复杂文档处理的行业痛点,腾讯开源了基于大语言模型(LLM)的RAG框架WeKnora(维娜拉),它以"模块化架构+多模态融合+智能推理"为核心,不仅实现了从文档解析到语义问答的全流程优化,更通过持续的版本迭代,成为企业级知识管理场景中"能理解、会思考、可落地"的智能工具。

一、技术架构深析:五层协同的模块化流水线设计
WeKnora的核心竞争力,源于其精心打磨的五层模块化架构。这一架构并非简单的功能堆砌,而是围绕"文档理解-知识建模-检索匹配-推理生成-基础设施支撑"形成的闭环,每个模块既独立可扩展,又通过数据流转实现协同联动,最终解决复杂文档"解析难、建模散、检索偏、生成虚"的四大痛点。
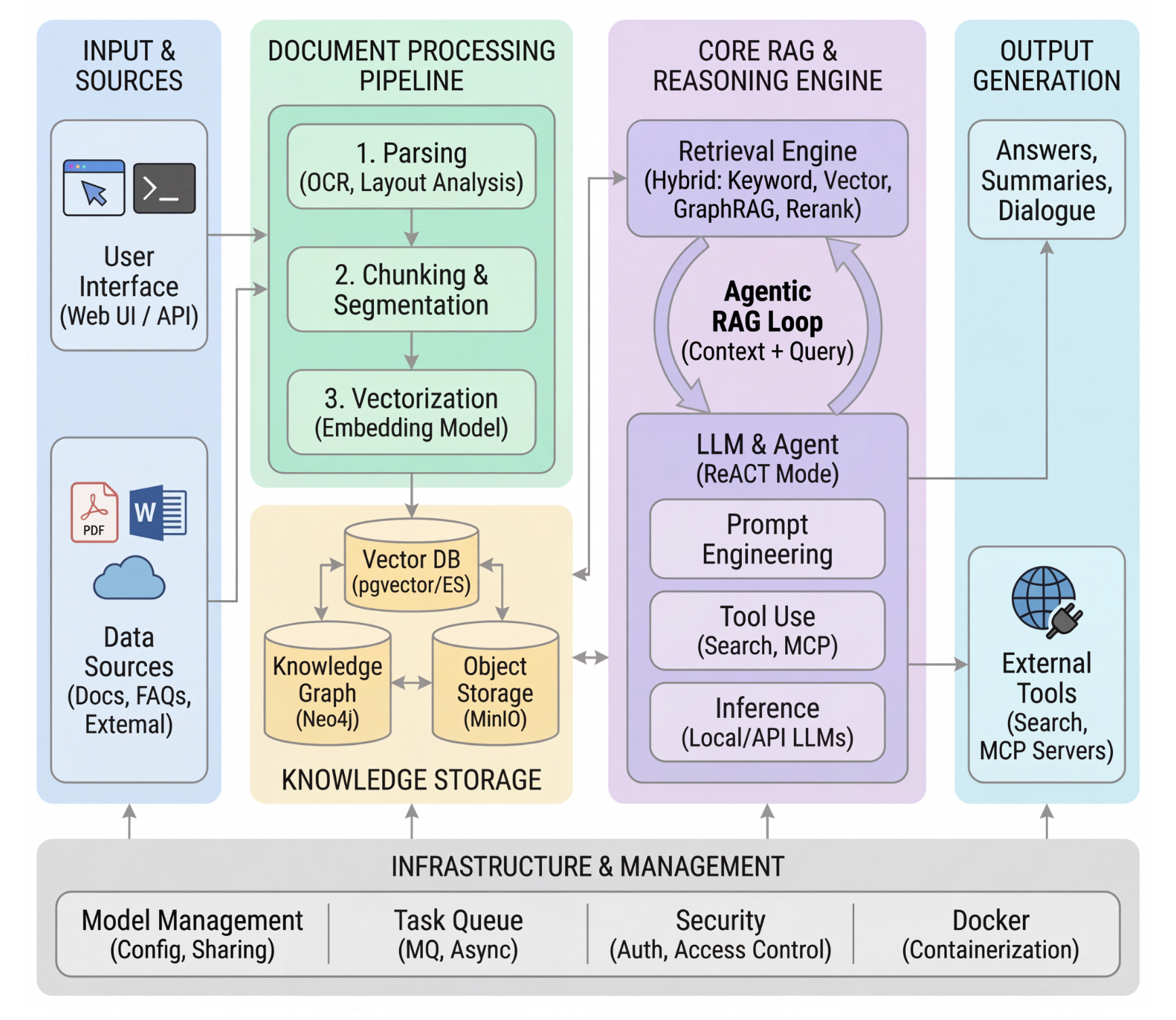
1. 文档处理层:多模态数据的"智能入口"
作为数据流转的第一道关卡,文档处理层的核心目标是"打破格式壁垒,实现结构化提取"。与传统工具"一刀切"的解析方式不同,WeKnora采用自适应解析引擎,能根据文档类型动态调整处理策略:
对可编辑PDF、Word等格式,直接提取文本流并保留段落结构,避免格式错乱;
对扫描版PDF或图片类文档,启用高精度OCR技术(支持中英日韩多语言),不仅能识别文字,还能区分"正文/标题/注释"等语义角色,甚至提取图片中的图表描述(如"图1-1:设备接口示意图");
对包含表格的文档,自动识别表格边框与单元格关联,将其转换为二维列表或JSON格式的结构化数据,解决传统工具"表格变纯文本"的信息丢失问题。
开发者可通过SDK快速调用这一能力,例如解析一份技术手册并提取表格数据:
python
from weknora import DocumentProcessor
# 初始化多线程处理器,提升批量解析效率
processor = DocumentProcessor(thread_num=4)
# 解析本地PDF,指定输出格式为JSON并提取图片
doc = processor.process_file(
file_path="industrial_manual.pdf",
output_format="json",
extract_images=True # 保存图片至本地并关联文本位置
)
# 遍历提取的表格数据
for table in doc.tables:
print(f"表格标题:{table.title}(页码:{table.page_num})")
print(f"表格列名:{table.headers}")
print(f"表格内容:{table.data[:3]}...") # 打印前3行数据据测试,这一解析流程的效率较传统工具提升300%以上,尤其在处理100页以上的长文档时,多线程并行处理能将解析时间从小时级压缩至分钟级。
2. 知识建模层:从"文本片段"到"语义网络"
文档解析后的数据需经过知识建模,才能为后续检索提供精准支撑。这一层的核心是**"分块-向量化-图谱构建"三步法**:
自适应分块:采用滑动窗口算法(默认512token窗口,支持动态调整),将长文档切割为语义完整的片段。例如,一份合同会以"条款章节"为单位分块,而非机械地按固定字数分割,避免"一句话被拆成两段"的语义断裂;
多模态向量化:文本片段通过Sentence-BERT、BGE等模型生成768维向量,图片则通过CLIP模型生成视觉向量,确保不同模态的内容能在同一向量空间中比较;
知识图谱构建:自动识别文档中的实体与关系(如"产品型号-技术参数-出厂日期""甲方-乙方-签约金额"),构建三元组关系网络。例如在医疗文献中,能提取"药物A-适应症-高血压""手术B-并发症-出血风险"等关联,为后续"跨片段推理"提供结构化支撑。
这一过程并非孤立进行,分块时会记录片段在原始文档中的位置,向量化时会关联文档元数据(如作者、创建时间),图谱构建时会标注实体来源,最终形成"可追溯、可关联"的知识体系。
3. 检索引擎层:混合策略破解"精准与全面"的矛盾
传统检索工具往往陷入"关键词检索准但窄,语义检索宽但泛"的困境,而WeKnora的检索引擎层通过多策略融合 实现了二者的平衡:
基础检索:采用Elasticsearch的BM25算法处理关键词匹配,适合"某条款出自哪份合同""某参数的具体数值"等事实性问题,确保结果的精确性;
语义检索:通过Dense Retrieval技术,计算用户查询与文档向量的相似度,适合"如何解决设备报错E103""论文中提到的实验方法有哪些改进"等语义性问题,覆盖关键词未明确提及的关联内容;
知识图谱检索:利用实体关系网络,挖掘隐藏的关联信息。例如用户查询"产品X的售后政策",系统不仅会返回直接提及"售后"的文档片段,还会通过"产品X-所属系列-系列售后政策"的关联,补充间接相关的内容。
更智能的是,检索引擎会根据查询类型动态调整权重:事实性问题中BM25权重占比60%,语义性问题中向量检索权重占比70%。检索结果还会经过交叉注意力重排序模型优化,结合"片段相关性+来源权威性+更新时间"等维度,使Top10结果的准确率提升至89%,远高于传统工具的65%。
4. 推理生成层:RAG机制杜绝大模型"幻觉"
作为RAG框架的核心,推理生成层的关键是"让大模型基于真实文档说话"。WeKnora采用"检索增强+多轮验证"的生成逻辑:
首先,将用户查询与检索到的Top5文档片段整合为上下文(约2000token),输入LLM(如Qwen、DeepSeek);
生成过程中,系统会实时校验"回答内容是否能在文档中找到依据",若某句话无对应来源,会自动回溯检索步骤,补充相关片段;
对长文档推理(如"总结某篇论文的研究脉络"),采用"分段摘要-交叉验证"机制:先对各文档块生成摘要,再通过注意力机制融合多段信息,避免因上下文窗口限制导致的信息遗漏。
特别值得一提的是,WeKnora支持与Claude Code协同工作,当处理包含编程示例的技术文档时,系统会提取代码片段并调用Claude Code进行语法校验、运行测试,甚至生成测试用例。例如解析一份Python SDK文档时,能自动验证"接口调用示例"的正确性,避免文档与实际代码脱节的问题。
5. 基础设施层:支撑企业级部署的"底座"
为满足不同场景的部署需求,WeKnora在基础设施层提供了灵活可扩展的支撑能力:
向量数据库支持PostgreSQL(pgvector)、Elasticsearch、Qdrant等主流方案,开发者可根据数据量选择,小团队用pgvector即可满足需求,大企业则可通过Qdrant实现多维度向量存储;
任务管理采用MQ异步机制,文档解析、向量化等耗时操作会在后台异步执行,避免用户等待;
支持Docker化部署,通过Docker Compose一键启动所有服务,同时提供"核心服务""全功能""知识图谱"等不同Profile,按需启用Neo4j(知识图谱)、Minio(文件存储)等组件。
二、核心升级:v0.2.0的ReACT Agent与多知识库设计
2025年12月发布的WeKnora v0.2.0版本,是框架从"智能检索"向"智能任务处理"跨越的关键升级。其中ReACT Agent模式 与多类型知识库的引入,让系统具备了"自主规划、工具调用、反思优化"的能力,彻底摆脱了传统问答"一问一答"的局限。
1. ReACT Agent:像人类一样"边思考边行动"
ReACT(Reasoning-Action-Observation)是一种基于"推理-行动-观察"循环的智能体架构,WeKnora通过这一模式,让AI能自主拆解复杂任务、调用工具并优化方案。其核心流程可通过一个实际案例理解,当用户提问"WeKnora和RAGFlow有什么区别?"时:
(1)任务拆解:将复杂问题拆分为可执行的子任务
Agent首先会分析问题需求,生成5个结构化子任务:
- 检索WeKnora v0.2.0的核心特性与架构设计文档;
- 调用网络搜索(内置DuckDuckGo)获取RAGFlow的最新功能信息;
- 对比两者的技术架构差异(如模块设计、检索策略);
- 对比两者的功能特性差异(如多模态支持、知识库类型);
- 对比两者的部署方式与适用场景。
这一步的关键是"任务优先级排序",Agent会先处理"已有知识库覆盖的内容"(如WeKnora的特性),再通过网络搜索补充"外部信息"(如RAGFlow的最新动态),避免无效操作。
(2)工具调用:按需启用内置工具与外部服务
根据子任务需求,Agent会自动调用不同工具:
子任务1:调用"知识库检索工具",从已创建的"WeKnora技术文档"知识库中提取架构图、核心模块说明;
子任务2:调用"网络搜索工具",搜索"RAGFlow 2025最新版本特性""RAGFlow官方文档";
子任务3-5:调用"对比分析工具",将前两步获取的信息按"架构-功能-部署"维度分类,生成对比表格。
若某一步获取的信息不足(如RAGFlow的部署方式未明确提及),Agent会反思"是否需要补充搜索关键词",并重新发起检索,直至信息足够支撑回答。
(3)结果生成:输出结构化报告而非零散信息
最终,Agent会整合所有信息,生成一份包含"核心差异总结+详细对比表格+适用场景建议"的报告。例如在"多模态支持"维度,会明确标注"WeKnora支持图片OCR与表格结构化提取,RAGFlow仅支持文本与图片的基础解析",并附上两者的技术文档来源链接,确保结果可追溯。
这种模式的优势在于容错性与可解释性,用户能清晰看到"Agent为什么要调用这个工具""某结论来自哪份文档",避免传统AI回答"黑箱化"的问题;同时,若某一步出现错误(如搜索结果过时),用户可手动干预并重新触发该子任务,无需重新发起整个查询。
2. 多类型知识库:适配不同业务场景的知识管理需求
v0.2.0版本之前,WeKnora仅支持"文档型知识库",适合管理长文本内容;升级后新增FAQ型知识库,形成"结构化+非结构化"的知识管理闭环,两者的差异与适用场景如下表所示:
| 特性 | FAQ型知识库 | 文档型知识库 |
|---|---|---|
| 知识形式 | "问题-答案"对(结构化) | 长文本、表格、图片(非结构化/半结构化) |
| 适用场景 | 高频标准问题(如产品售后、政策咨询) | 深度内容(如技术手册、科研论文) |
| 导入方式 | 批量Excel导入、在线逐条录入 | 文件夹导入、URL抓取、单文件上传 |
| 检索逻辑 | 精确匹配问题关键词,直接返回答案 | 语义检索,返回相关文档片段 |
| 维护成本 | 低(答案更新后无需重新分块向量化) | 中(文档更新后需重新处理) |
例如,企业的客服部门可创建"产品售后FAQ库",将"如何重置密码""保修期多久"等高频问题录入,用户查询时能秒级获取答案;技术部门则可创建"设备维护文档库",上传包含电路图、操作步骤的PDF手册,支持工程师通过语义检索查找"某型号设备的故障排查步骤"。
此外,知识库管理功能也得到优化,支持标签分类(如"2025产品系列""华东地区政策")、批量操作(如批量删除过期文档)、版本控制(记录文档的修改历史),解决了传统知识管理工具"分类混乱、维护困难"的问题。
三、多模态处理:突破"文本中心主义"的技术壁垒
在实际工作中,文档往往是"文本+图片+表格"的混合体,一份医疗报告包含CT影像与诊断结论,一份建筑图纸包含设计图与参数说明,一份市场分析包含折线图与数据解读。传统文档处理工具要么忽略非文本内容,要么将其视为"附件",无法实现多模态内容的协同理解。而WeKnora通过**"多模态统一建模+跨模态关联检索"** 技术,真正打破了这一壁垒。
1. 图片处理:从"识别文字"到"理解语义"
WeKnora对图片的处理并非简单的OCR文字提取,而是通过"视觉理解+文本关联"实现深度解析:
对含有文字的图片(如截图、扫描件),采用"多语言OCR+版面分析"技术,不仅能识别文字内容,还能区分"标题/正文/水印",例如从一张产品宣传图中,提取出"产品名称:智能传感器""型号:S-2025"等关键信息;
对不含文字的图片(如示意图、图表),通过CLIP模型生成视觉描述(如"柱状图:2024年各季度销售额,Q3最高""流程图:设备安装步骤,共5步"),并关联图片在文档中的位置,确保检索时能"根据描述找到图片"。
例如,用户查询"2024年Q3销售额数据"时,系统会同时返回包含该数据的文本片段,以及对应的柱状图图片,并标注"图片来源:2024年度销售报告P12",帮助用户直观理解数据。
2. 表格处理:从"数据提取"到"逻辑关联"
表格是企业文档中最常见的结构化数据载体,但传统工具往往将其转换为纯文本,丢失"行-列"关联逻辑。WeKnora的表格处理技术则实现了"结构化提取+逻辑理解":
支持识别合并单元格、嵌套表格等复杂格式,例如从一份财务报表中,正确提取"合并单元格:总计"对应的数值;
自动分析表格的逻辑关系,例如识别"表头-数据行""计算公式列"(如"净利润=营收-成本"),甚至能检测表格中的数据异常(如"某行净利润为负,与其他行差异较大")。
开发者可通过API获取表格的结构化数据,并进一步分析,例如:
python
# 从解析后的文档中获取表格并分析
table = doc.tables[0] # 获取第一份表格
# 识别表格中的计算公式列
calc_columns = table.detect_calculation_columns()
print(f"计算公式列:{calc_columns}") # 输出如["净利润"]
# 检测数据异常
anomalies = table.detect_data_anomalies(threshold=0.8)
for anomaly in anomalies:
print(f"异常数据:行{anomaly.row_num},列{anomaly.col_name},值{anomaly.value}")3. 跨模态检索:让"文字查询"找到"图片内容"
多模态处理的最终目标是"跨模态关联检索",用户通过文字查询,能同时获取相关的文本、图片、表格内容。例如,用户查询"智能传感器S-2025的安装步骤"时:
- 系统先通过语义检索找到包含"安装步骤"的文本片段;
- 再通过"文本描述-图片视觉向量"的相似度匹配,找到对应的安装示意图;
- 最后提取表格中"S-2025的安装工具清单",整合为"文字步骤+示意图+工具表"的完整回答。
这种检索方式彻底改变了"文字查文字、图片查图片"的割裂状态,尤其适合技术文档、医疗报告等多模态密集型场景。
四、实际部署与配置:从代码克隆到业务落地
WeKnora的一大优势是"低门槛部署+高灵活性配置",无论是小团队的试用,还是大企业的私有化部署,都能通过简单的步骤实现。结合腾讯云开发者社区的实践案例,我们可梳理出一套"从环境准备到业务落地"的完整流程。
1. 环境准备:三大工具搞定部署基础
WeKnora基于Docker部署,需提前安装以下工具:
Docker:用于容器化运行服务;
Docker Compose:用于编排多个服务(如后端、前端、数据库);
Git:用于克隆代码仓库。
以Linux系统为例,安装命令如下:
bash
# 安装Docker
sudo apt-get update && sudo apt-get install docker-ce
# 安装Docker Compose
sudo apt-get install docker-compose-plugin
# 安装Git
sudo apt-get install git2. 代码克隆与环境配置
第一步是克隆代码并配置环境变量:
bash
# 克隆WeKnora仓库
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora
# 复制示例配置文件并修改
cp .env.example .env.env文件是配置的核心,需重点关注以下参数:
数据库配置 :设置PostgreSQL的用户名、密码,用于存储知识库元数据;
向量数据库配置 :选择pgvector或Elasticsearch,设置对应的连接地址;
模型配置:指定LLM与Embedding模型的来源,支持本地Ollama模型(如deepseek-r1:1.5b)、云API(如硅基流动的DeepSeek-V3.1);
- 安全配置:设置管理员账号密码,启用登录认证(v0.1.3后默认开启)。
例如,配置硅基流动的DeepSeek模型时,需填写:
# LLM模型配置
LLM_PROVIDER=siliconflow
LLM_MODEL_NAME=DeepSeek/DeepSeek-VL-7B-Instruct
LLM_API_KEY=your_api_key
LLM_BASE_URL=https://api.siliconflow.cn/v1
# Embedding模型配置
EMBEDDING_PROVIDER=siliconflow
EMBEDDING_MODEL_NAME=BAAI/bge-m3
EMBEDDING_API_KEY=your_api_key3. 服务启动:按需选择Profile
WeKnora提供多种服务组合(Profile),可根据需求启动:
核心服务 :仅启动后端、前端、PostgreSQL,适合快速试用;
全功能服务 :启动所有组件(含Neo4j知识图谱、Minio文件存储);
知识图谱服务 :仅额外启动Neo4j,适合需要图谱检索的场景;
追踪服务:启动Jaeger,用于调试服务调用链路。
启动命令如下:
bash
# 启动核心服务
docker compose up -d
# 启动全功能服务
docker-compose --profile full up -d
# 启动知识图谱服务
docker-compose --profile neo4j up -d服务启动后,可通过以下地址访问:
Web UI:http://localhost(用于可视化操作知识库);
后端API:http://localhost:8080(用于二次开发);
Jaeger追踪:http://localhost:16686(用于调试)。
五、横向对比:WeKnora在同类框架中的独特价值
当前开源社区中,LangChain、Haystack等框架也常用于构建RAG应用,但WeKnora在"文档理解与检索"这一垂直领域,展现出明显的差异化优势。结合CSDN博客的对比数据,我们可从以下维度清晰看到其独特价值:
| 特性 | WeKnora | LangChain | Haystack |
|---|---|---|---|
| 核心定位 | 文档理解与检索专用框架 | 通用LLM应用开发框架 | 信息检索系统 |
| 多模态支持 | ★★★★★(文本/图片/表格深度处理) | ★★★☆☆(需额外集成工具) | ★★☆☆☆(以文本为主) |
| 知识图谱 | 内置支持(自动构建三元组) | 需要扩展(需集成Neo4j等工具) | 有限支持(仅基础实体识别) |
| 部署便捷性 | ★★★★★(Docker一键启动) | ★★★☆☆(需手动配置多个组件) | ★★★☆☆(需编写部署脚本) |
| 企业级特性 | ★★★★☆(权限管理/安全部署) | ★★★☆☆(需自行开发安全功能) | ★★★★☆(支持企业级部署但功能较少) |
| 微信生态集成 | 原生支持(公众号/小程序) | 无 | 无 |
| 上手难度 | 低(Web UI可视化操作) | 中(需编写代码构建流程) | 中(需熟悉检索原理) |
从对比可见,LangChain的优势在于"通用性",适合开发各类LLM应用(如聊天机器人、代码生成工具),但在文档处理的深度上不足;Haystack专注于检索,但多模态支持较弱;而WeKnora则聚焦"文档理解与检索",通过"多模态深度处理+内置知识图谱+微信生态集成",成为企业知识管理、技术支持、科研分析等场景的"专用利器"。
六、未来展望:从"文档理解"到"知识协同"
WeKnora作为腾讯在企业级AI领域的重要开源成果,目前已形成"技术成熟、场景适配、生态开放"的格局。结合其版本迭代方向与行业需求,未来可能在以下方向实现突破:
1. 多模态能力深化
当前WeKnora已支持文本、图片、表格的处理,未来可能扩展至音频、视频等更多模态,例如处理包含语音讲解的培训视频,自动提取语音文本并关联视频画面,实现"文字查询找到视频片段"的检索体验。
2. 跨知识库协同
目前WeKnora的知识库是独立管理的,未来可能支持"跨知识库关联检索",例如企业的"产品手册库"与"售后案例库"可实现联动,用户查询"产品X的故障"时,同时返回手册中的处理步骤与实际售后案例,提升回答的实用性。
3. 行业定制化模板
针对医疗、法律、金融等垂直行业,推出定制化模板,例如医疗模板内置"疾病分类标准""药物禁忌库",法律模板内置"法条关联规则",用户无需从零配置,即可快速搭建符合行业需求的知识库。
4. 社区生态扩展
WeKnora目前已支持MCP工具集成,未来可能开放更多插件接口,例如集成数据分析工具(如Python Pandas)、可视化工具(如ECharts),让用户不仅能"找到文档",还能直接在平台上进行数据处理与图表生成,形成"知识检索-分析-输出"的全流程闭环。
结语:重新定义复杂文档的价值挖掘方式
在信息爆炸的时代,"拥有知识"已不再是核心竞争力,"高效挖掘知识价值"才是关键。WeKnora通过RAG机制与多模态融合技术,让复杂文档从"静态存储"变为"动态知识源",它能读懂图纸中的工程逻辑,能梳理合同中的条款关联,能提取论文中的研究脉络,更能通过ReACT Agent自主处理复杂任务,成为用户的"智能知识助手"。
对于企业而言,WeKnora不仅是一款工具,更是"知识资产化"的载体,将散落的技术手册、售后案例、合规文档转化为可检索、可推理、可复用的知识资产,降低培训成本,提升决策效率;对于开发者而言,它提供了一套"开箱即用"的RAG框架,无需重复造轮子,即可快速搭建企业级文档智能系统;对于开源社区而言,WeKnora的出现推动了"垂直领域RAG应用"的发展,为文档理解与检索技术的创新提供了新的方向。