1 前言
随着游戏行业全球化进程的深入推进,哔哩哔哩也在海外游戏市场积极布局。哔哩哔哩有丰富的游戏储备,运营众多自研和代理游戏,随着出海战略的推进,我们的目标用户已经覆盖全球多个地区。
游戏要想在海外市场取得成功,需要进行全面的本地化适配,其中语言本地化是关键一环。与普通文档翻译不同,游戏翻译需要处理系统界面、技能描述、剧情对白、活动公告等多种文本类型,每种内容都有不同的表达方式和风格要求。更重要的是,游戏翻译不仅要保证语言的准确性,更要传达游戏的文化内涵和情感体验,稍有疏忽就会影响玩家体验和沉浸感。
然而,游戏翻译的复杂性远超想象。我们在实践中面临着三大核心挑战:翻译内容复杂多样,质量管控难度大,成本与效率平衡。 国内友商手游出海时,曾出现过因翻译质量问题导致玩家在社区中客诉、游戏声誉受损的情况。成本压力也尤为突出,不仅因为游戏翻译文本量大、翻译难度高、单价贵,而且在游戏运营期间会有频繁的内容更新和活动上线,每次都需要重新翻译和审校,项目的总体年度维护成本往往超过初版本翻译成本。
如何在保证翻译质量的前提下降低本地化成本,成为我们亟需解决的问题。为此,哔哩哔哩游戏算法团队构建了一套基于大语言模型的游戏翻译体系,并在多个项目、多个语种中取得了显著成效。本文将详细介绍这套翻译平台的技术架构和核心价值。
2 传统翻译方法与痛点
在深入我们的技术方案之前,我们先了解一下传统游戏翻译是如何进行的,以及面临哪些问题。
2.1 传统翻译流程
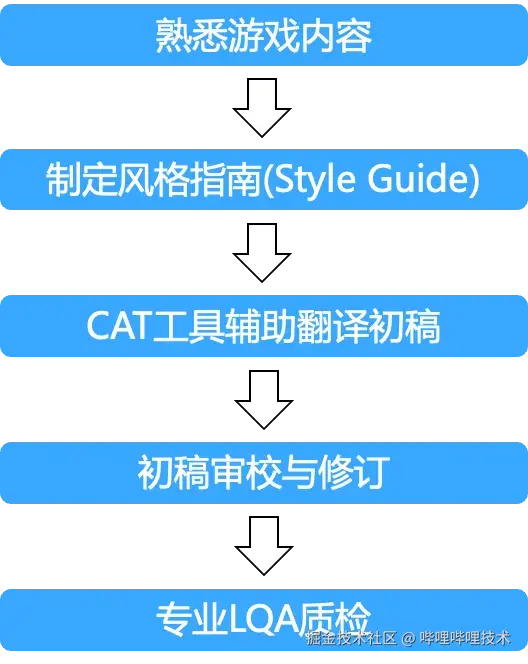
传统的游戏本地化翻译主要依赖人工配合CAT工具(Computer-Assisted Translation Tools,如MemoQ、Trados、Smartcat等)的方式,典型流程包括:
-
第一步-熟悉游戏内容: 译者通过实际游玩或相关材料了解游戏内容,全面理解游戏机制、角色设定、和世界观等细节。
-
第二步-制定风格指南 (Style Guide): 制定包括术语规范、格式要求、文本长度限制等在内的风格规范,确保团队统一翻译风格。
-
第三步-CAT工具辅助初稿翻译: 借助CAT工具(Computer-Assisted Translation Tools, MemoQ、Trados、Smartcat等)进行初稿翻译,利用术语库和记忆库来保证术语和相似句式翻译的一致性,提高翻译效率。
Tips:
术语库:存储专业术语的双语对照表,确保特定概念在整个项目中翻译的一致性
翻译记忆库:存储历史翻译过的句段对,通过模糊匹配复用相似表达
-
第四步-初稿审校与修订: 通过一校和二校修订,发现并纠正表达不当、风格不统一的问题,反馈译者沟通确认终稿。
-
第五步-专业LQA质检: 最终由专业本地化质量保证(Localization Quality Assurance,LQA)专家进行交付前检查,确保整体品质达标。
2.2 传统的翻译方法的局限性
尽管传统本地化流程在游戏行业应用已久,但在面对大体量、多语种、快迭代的出海项目时,仍存在以下三方面瓶颈:
- 成本高: 传统的本地化翻译过程中,专业游戏翻译人员稀缺,市场单价居高不下。对于追求全球发行的大型项目而言,单个语种的翻译成本往往达到百万级别 ,全球多语种发行每年的翻译总成本甚至达到千万级规模。
- 周期长: 为了保证翻译质量,通常需要经过多轮流程,单版本翻译内容迭代过程一般耗时2个月以上。
- 质量不稳定: 传统流程对供应商和人员依赖性强。供应商资源紧张或翻译人员流动会导致项目延期或质量波动。同一名称在不同版本中可能出现不同译法,影响游戏体验。
- 历史资产利用不足: 虽然CAT工具支持记忆库功能,但基于字符串相似度的模糊匹配对包含变量的游戏文本效果不佳。术语管理完全依赖人工,无法自动从历史翻译中发现新的术语对。
针对这些问题,B站游戏算法团队利用大模型的能力,构建了一套更高效、稳定、智能的翻译体系。
3 哔哩游戏大模型翻译体系
3.1 平台整体架构设计
我们构建的翻译体系并非简单地将Excel表格拖入ChatGPT,而是基于LLM的能力特点,量身定制了一套人机协作流程。整个体系采用四层架构:
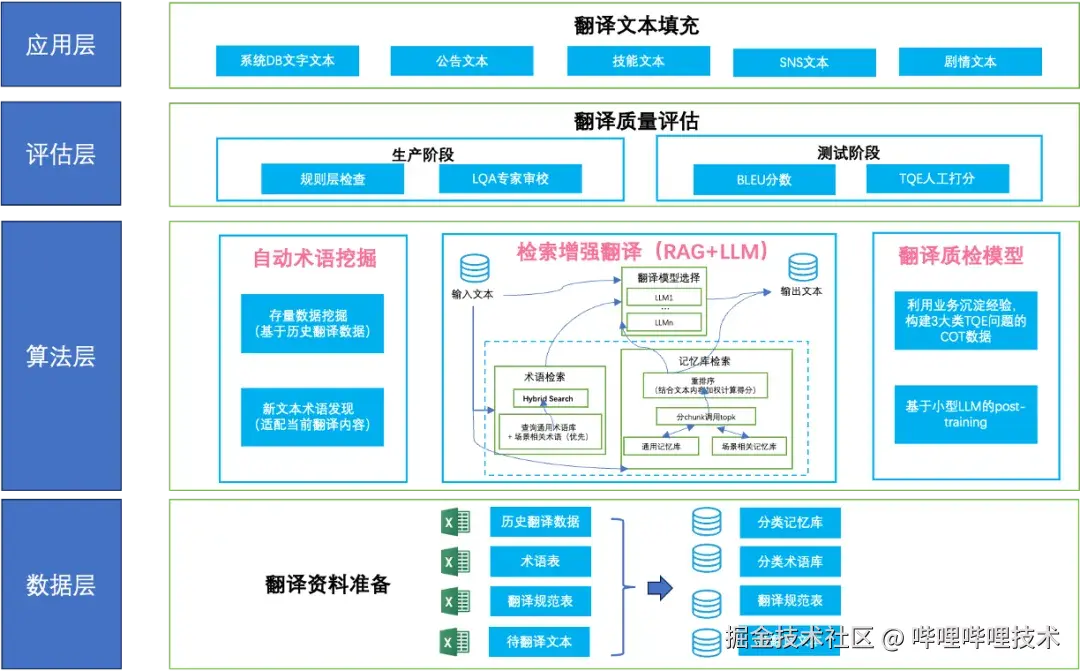
- 数据层:翻译资料准备,包括历史翻译数据、术语表、翻译规范表、待翻译文本等基础数据资产。
- 算法层:核心翻译能力,包含三大核心模块:
- 自动术语挖掘:从历史数据中自动发现和补全术语库
- 检索增强翻译(RAG+LLM):为LLM提供相关上下文,确保翻译一致性
- 翻译质检模型三大核心模块:自动检测和评估翻译质量
-
评估层:翻译质量保障,分为生产阶段(规则后检查+LQA专家审校)和测试阶段(BLEU分数+TQE(Translation Quality Estimation)人工打分)。
-
应用层:面向不同文本类型的翻译场景,支持系统文本、公告文本、技能文本、SNS文本、剧情文本等多种游戏内容。
3.2 核心运作流程
-
第一步-数据准备: 系统自动从翻译资料库中提取相关术语、历史翻译记忆等资源
-
第二步-智能翻译: 结合术语挖掘结果,通过RAG检索机制为LLM提供上下文,生成高质量译文
-
第三步-质量保障: 多层次质检确保输出质量,不合格内容触发反馈优化流程
3.3 系统核心价值
-
效率提升: 翻译周期相比传统方案缩短85%以上,整体成本节省70%~80%
-
规模价值: 支持简体中文、繁体中文、日语、韩语、泰语、英语、德语、法语、西班牙语、葡萄牙语等10种语言同时翻译,实现全球同步发布
-
质量稳定: 通过标准化流程减少对外部供应商的依赖,AI+人工混合模式确保交付稳定性,线上客诉控制在万分之一内
4 哔哩游戏大模型翻译体系的核心技术
在阐述了平台整体架构和价值后,本章将深入探讨支撑平台运行的三大核心技术:检索增强翻译、自动术语挖掘和翻译质量评估体系。
4.1 检索增强翻译(RAG)流程
在游戏本地化过程中,术语不统一、句式风格漂移、剧情断裂等问题极易破坏玩家的沉浸体验。为系统性解决这些问题,我们构建了基于大语言模型(LLM)的检索增强生成(RAG)翻译流程,并结合领域适应的翻译模型训练,形成了完整的游戏翻译解决方案。
4.1.1 核心价值
一、 保证术语一致性
游戏版权方通常对专属名词、技能、人物称呼等有严格限制,即使有缩写或语序变化也必须统一。RAG翻译可以很好的解决这个问题。
术语翻译一致性的例子如下,可看出通过RAG流程,翻译的一致性更好。

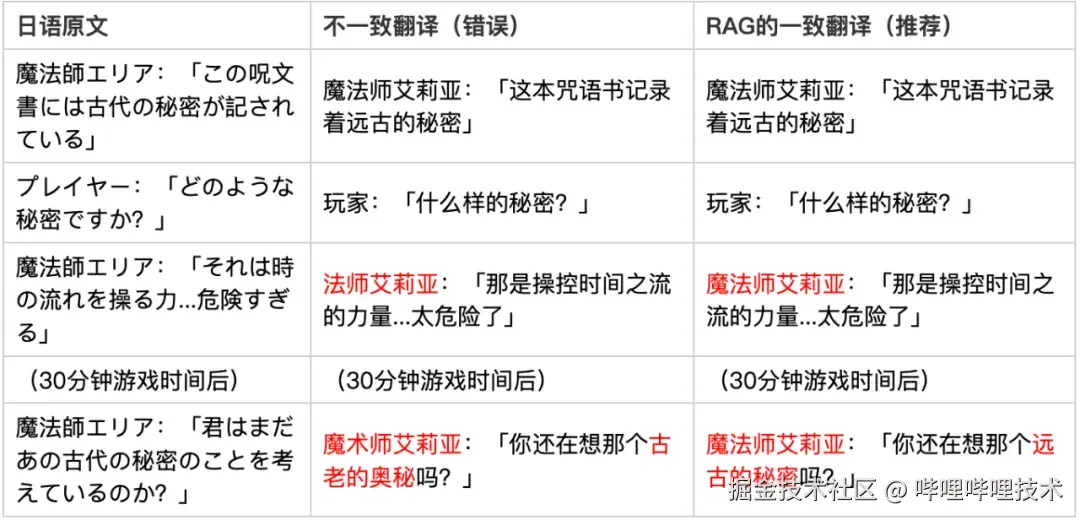
二、保证上下文一致性
剧情文本涉及大量角色风格、情感、语气等语言特征,传统方法无法通过逐句翻译实现自然衔接,且出现过的内容,需要保证翻译的一致性,RAG翻译的方式可有效处理。
一个上下文一致性的剧情翻译样例如下:
4.1.2 RAG核心流程与架构
我们构架的RAG翻译系统包含术语检索和记忆库检索两大核心模块,分别处理不同类型的翻译需求。整体系统架构如下图所示:
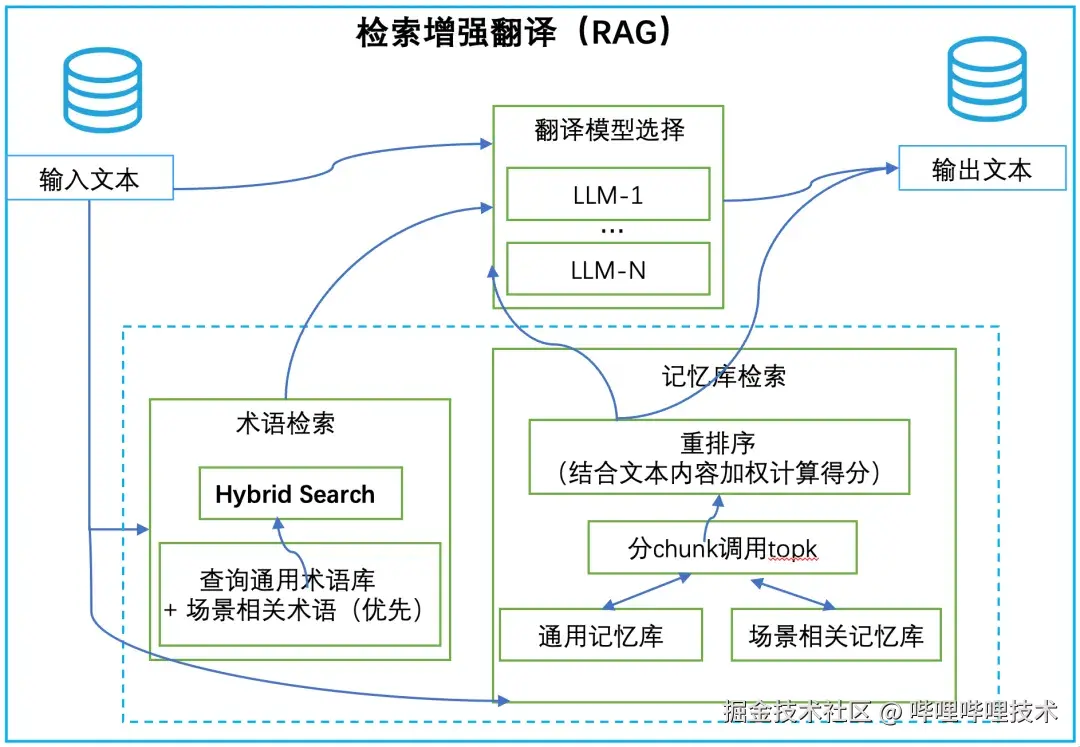
一、术语检索模块(Hybrid Search)
-
查询通用术语库: 覆盖游戏通用概念、UI元素等标准化表达
-
场景相关术语优先: 根据文本类型(如技能描述、剧情对白)动态调整术语权重
-
精确匹配: 确保IP相关词汇、角色名称等关键术语的翻译一致性
二、 记忆库检索模块
- 分chunk调用topk:将文本按语义单元切分,每个chunk独立检索相似表达
- 重排序机制:我们设计了多因子加权打分函数,结合文本内容重新计算得分,确保检索结果的相关性
Score = α * SemanticSim + β * RoleSim + γ * StyleSim + δ * MoodSim
- 其中:
- SemanticSim:当前片段与候选译文的语义相似度(如向量余弦相似度)
- RoleSim:说话人是否一致(完全一致为1,相似角色为0.5,其他为0)
- StyleSim:语体风格是否匹配(如敬语 vs 俚语)
- MoodSim:情绪/场景氛围是否一致(如"悲伤 vs 悲伤"为1,相似情绪为0.5)
- 双库支持:通用记忆库提供跨项目复用,场景相关记忆库保证项目特色
4.1.3 自训练翻译模型模块
在RAG检索机制外,我们还构建了基于历史数据的自训练翻译模型,通过学习历史场景的常见表达模式,可以大幅提升翻译质量和一致性。具体方法包含:
一、指令微调(Instruction Tuning)
- 多输入指令设计: 设计支持术语库、记忆库、场景上下文等多种输入的指令模板,使模型能够灵活利用各类翻译资源
- 针对性数据增强: 基于游戏翻译场景的特点,构造包含术语约束、风格要求、上下文信息的训练样本,提升模型在复杂翻译任务中的表现
二、强化学习优化
-
基于人类反馈的微调: 针对游戏翻译中的常见规则和质量要求,采用GRPO(Group Relative Policy Optimization)等强化学习方法进行人类反馈优化
-
奖励模型设计: 基于翻译质量、术语一致性、风格匹配等多维度构建奖励函数
4.1.4 效果验证
-
RAG翻译流程使专家得分提升50%
-
全面覆盖系统文本、技能描述、剧情对白、公告文本等多类游戏翻译需求
-
有效保障术语统一、表达一致、角色语言风格连贯
4.2 自动术语挖掘
术语统一是保证翻译质量的核心环节之一。除了遵循版权方提供的IP术语表外,每个版本还需构建覆盖本地化特色与文本表达习惯的项目术语集。我们的自动术语挖掘技术分为两个互补的流程:存量术语挖掘和新文本术语发现。
4.2.1 存量翻译对中的术语挖掘

从历史翻译文本中自动识别未被术语库覆盖的术语对,用于补全术语体系,避免翻译不一致,确保历史经验的充分利用。完整流程包括三步:
-
候选术语对抽取: 结合词法分析与语义判断,采用Few-shot Prompting指导LLM生成匹配术语。例如从日文「風ノ剣士ユウト」和译文「风之剑士优人」中,识别出术语对「風ノ剣士」-「风之剑士」、「ユウト」-「优人」。
-
术语筛选过滤: 依据词频与上下文使用场景过滤冗余内容,剔除已存在的重复项。
-
专家审核确认: 将候选术语对提交语言专家审核,形成最终增量术语库。
4.2.2 待翻译文本的候选术语发现

在仅有源语言(如日文)的新版本文本中,自动识别潜在术语并生成目标语言候选表达,避免翻译不一致。完整流程包括两步:
-
文本分析与词组提取:结合词法分析与语义(词向量相似度)判断生成候选术语,使用LLM进行新术语的对应译文生成。
-
专家审核确认:将候选术语列表提交审核,纳入当前版本的术语表。
4.2.3 效果验证
-
显著节省人力成本:相比人工挖掘,本方案术语挖掘效率提升95%以上
-
覆盖率提升:额外挖掘出20%术语,候选准确率达到80%,显著节省人力成本
4.3 自动化翻译质量评估体系
在游戏本地化的翻译流程中,LLM虽具备通用语义理解与表达能力,但也暴露出不可控和质量不确定的问题。为了解决这些问题,我们构建了一套多层次的质量评估体系,从规则检测到智能评估,多维度保障翻译质量。
4.3.1 质量问题的系统性分析
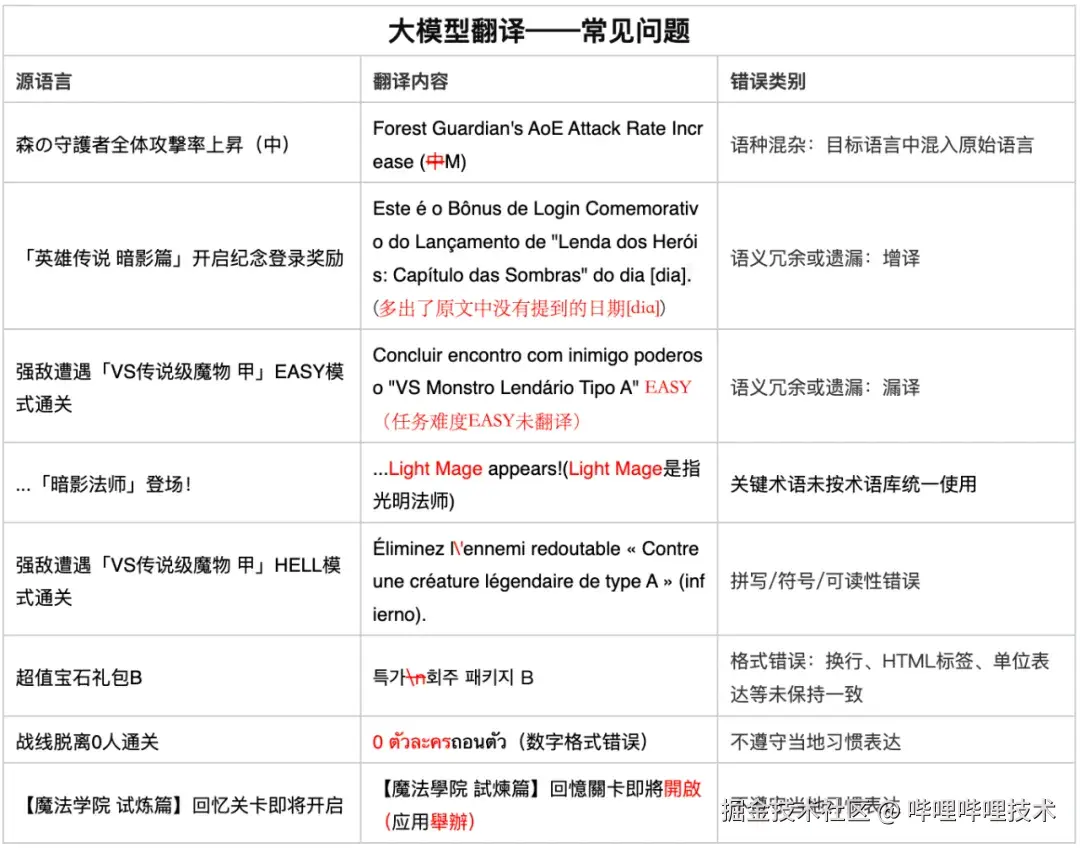
通过对大量翻译输出的分析,我们将LLM翻译中的质量问题归纳为三个维度:
一、准确性问题
- 增译现象: 模型添加原文中不存在的信息,如将简单的登录奖励描述扩展为包含具体日期的复杂表述
- 漏译问题: 关键信息遗漏,特别是游戏中的难度标识、数值参数等重要元素
- 术语违规: 未按照预设术语库进行翻译,导致角色名称、技能名称等关键词汇不一致
二、语言质量问题
- 语种混杂: 目标语言中混入源语言片段,如英文翻译中保留日文字符
- 格式不当: HTML标签、换行符、特殊符号的不当处理
- 可读性问题: 符号使用不规范、拼写错误等基础语言问题。
三、本地化适应性问题
-
文化表达不当: 不符合目标语言的表达习惯和文化背景
-
数字格式错误: 数字、日期、货币等的本地化格式处理不当
-
语域不匹配: 正式度、敬语等语言风格与游戏场景不符
我们从TQE反馈中收集了部分模型的错误翻译输出,样例如下:
4.3.2 分层翻译质量治理
在翻译质量评估的过程中,采用BLEU、COMET 等传统评分方法,在高分区间无法有效区分译文在业务场景的优劣;而效果好的人工评估(TQE)耗时长、成本高,通常需要较长时间评估一个版本,无法快速获得反馈。
为了解决以上问题,我们设计了三层递进的质量治理策略,从基础规则检测到智能化评估,形成完整的质量保障体系。
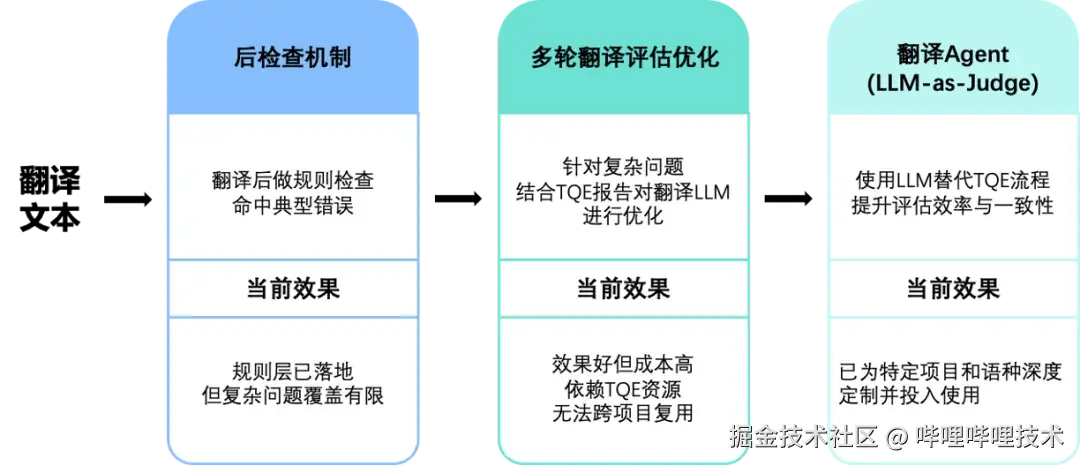
一、后检查机制
针对可明确定义的问题,目前已在生产阶段部署以下自动化检测策略:
- 语种一致性检测: 结合正则表达式与语言识别模型判断混和语种现象
- 格式完整性验证: HTML 标签闭合、Unicode 编码、换行与特殊符号规范等
- 术语一致性校验: 与术语库比对专有名词是否增漏译或误译
当前效果:规则层方案已在生产环境稳定运行,可覆盖70%以上格式和术语问题;但是复杂问题覆盖有限,优化空间趋于饱和,需要引入其他方案。
二、多轮评估与翻译优化迭代
针对规则无法判断的复杂问题,建立人机协作的多轮评估与优化流程:
- 分层评估策略: 先通过BLEU/COMET等指标初筛,再由TQE专家做详细评估
- 迭代优化机制: 结合TQE反馈,对翻译LLM进行进行多轮优化,直至质量评分达标
使用该方案效果显著但成本较高,在可扩展性上表现不佳。每次迭代都需要额外协调TQE专家资源,且评估结果都高度绑定特定项目版本,难以实现跨项目的经验复用,限制了方案的规模化应用。
三、翻译Agent(LLM-as-Judge)
为解决评估效率和标准一致性问题,构建本地化质量评估模型,部分替代人工TQE流程。使用历史TQE评估数据,构建了基于LLM的评估系统。
训练数据构建方法如下:
- 多维度标注体系: 建立覆盖准确性、语言质量、本地化适应性的三维评估框架
- 细粒度错误分类: 将每个维度进一步细分为具体的错误类型(如错译、漏译、增译等)
- 上下文信息整合: 每条训练样本包含原文、机器译文、专家评价、修正译文等完整信息
模型采用思维链(Chain-of-Thought)推理模式,让模型逐步分析每个质量维度,提升翻译质量评估的可靠性:
bash
‹quality_analysis>1.
准确性问题:存在错译,"暗影法师"误译为"Light Mage"。
2.语言质量问题:符号使用规范,无可读性错误。
3.语种特有问题:表达符合目标语言表达习惯。
</quality_analysis>
评分:[错误=1, 正确=0, 正确=0] → 综合评分:需要修正- 模型训练方式: SFT/RLHF训练方式相结合。
方案效果:
-
已为特定项目和语种深度定制并投入使用
-
显著提升了该项目的质量评估效率和准确性
5 翻译体系收益
经过持续的技术开发和业务实践,我们的翻译系统已在多个项目中完成落地验证,在成本效益、技术指标等方面都取得了显著成效。
5.1 业务效果
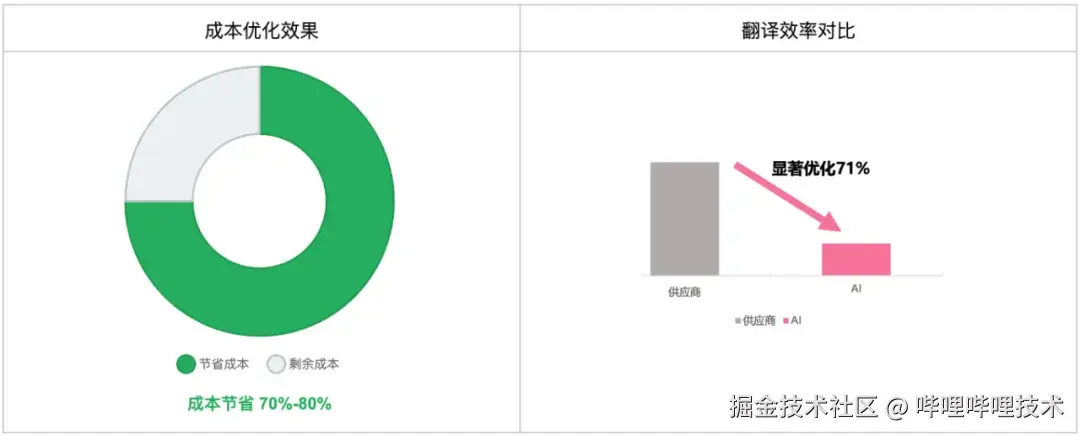
-
翻译成本节省70%~80%
-
翻译效率提升7倍以上
-
质量稳定性佳,线上客诉控制在万分之一内
5.2 技术指标
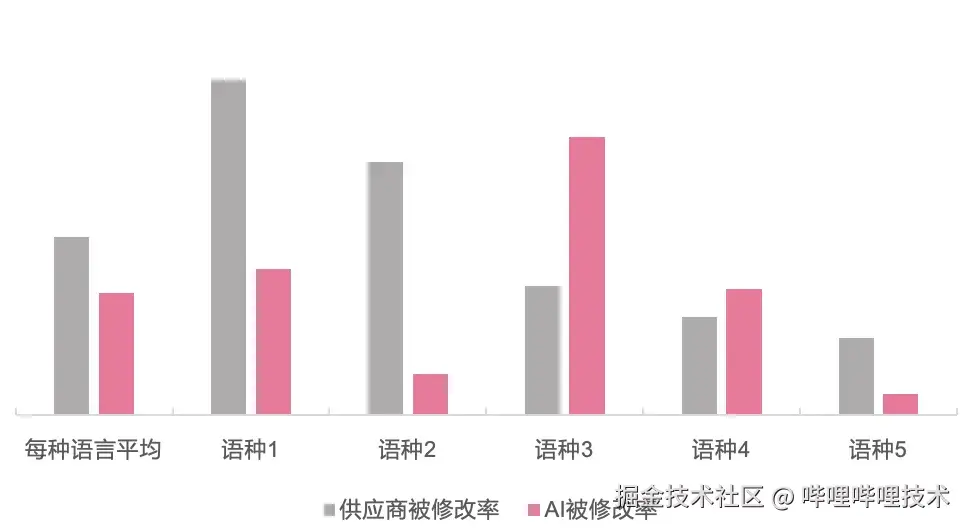
-
覆盖范围: 支持10个语种,处理文本量10万+字/版本
-
翻译准确率: 大模型翻译后的LQA专家修改率,显著低于传统(供应商)翻译方案
6 总结与展望
通过系统性的技术创新和工程实践,我们成功构建了有效的游戏翻译系统。不仅解决了传统翻译方法在成本、效率、质量和稳定性方面的痛点,更为哔哩哔哩游戏全球化发行提供了强有力的技术支撑。
基于当前技术积累和业务需求,我们未来的优化方向如下:
- 技术方面:多模态集成、对比学习、统一翻译、质检、术语发现的端到端训练框架
- 业务方面:LLM-as-Refiner自动化文本修正机制、翻译文本润色、风格一致性优化
随着技术的不断成熟和应用场景的拓展,我们将继续深化技术创新,为更多游戏的全球化进程提供高质量的翻译服务支持。
7 致谢
我们要特别感谢基建、运营及LQA同事在本翻译体系构建过程中的大力支持。基建团队为我们提供了稳定可靠的LLM训练推理资源和完善的API 支持;运营及LQA团队在业务需求梳理、项目协调和效果验证等方面发挥了关键作用,使得技术方案能够真正落地并产生实际价值。
-End-
作者丨Travix