在腾讯等大厂的面试中,MySQL数据库的知识点经常是必考项,尤其是在涉及性能优化、存储引擎选择、索引原理等方面。本文将结合常见的MySQL面试问题,详细解答关于MySQL优化和数据库引擎等核心知识,帮助你在面试中脱颖而出。 编辑
编辑
一、MySQL慢查询优化
1. MySQL慢查询如何优化?  编辑
编辑
MySQL的慢查询是指执行时间较长的查询,通常超过了指定的阈值。优化慢查询的方式包括:
- 增加索引 :通过分析
EXPLAIN输出,检查查询中是否缺少合适的索引。可以为查询的WHERE、JOIN条件等字段添加索引。 - 查询优化 :重写复杂的查询语句,避免使用
SELECT *,指定需要的字段;避免在WHERE子句中使用不必要的函数(如LIKE、SUBSTRING等)。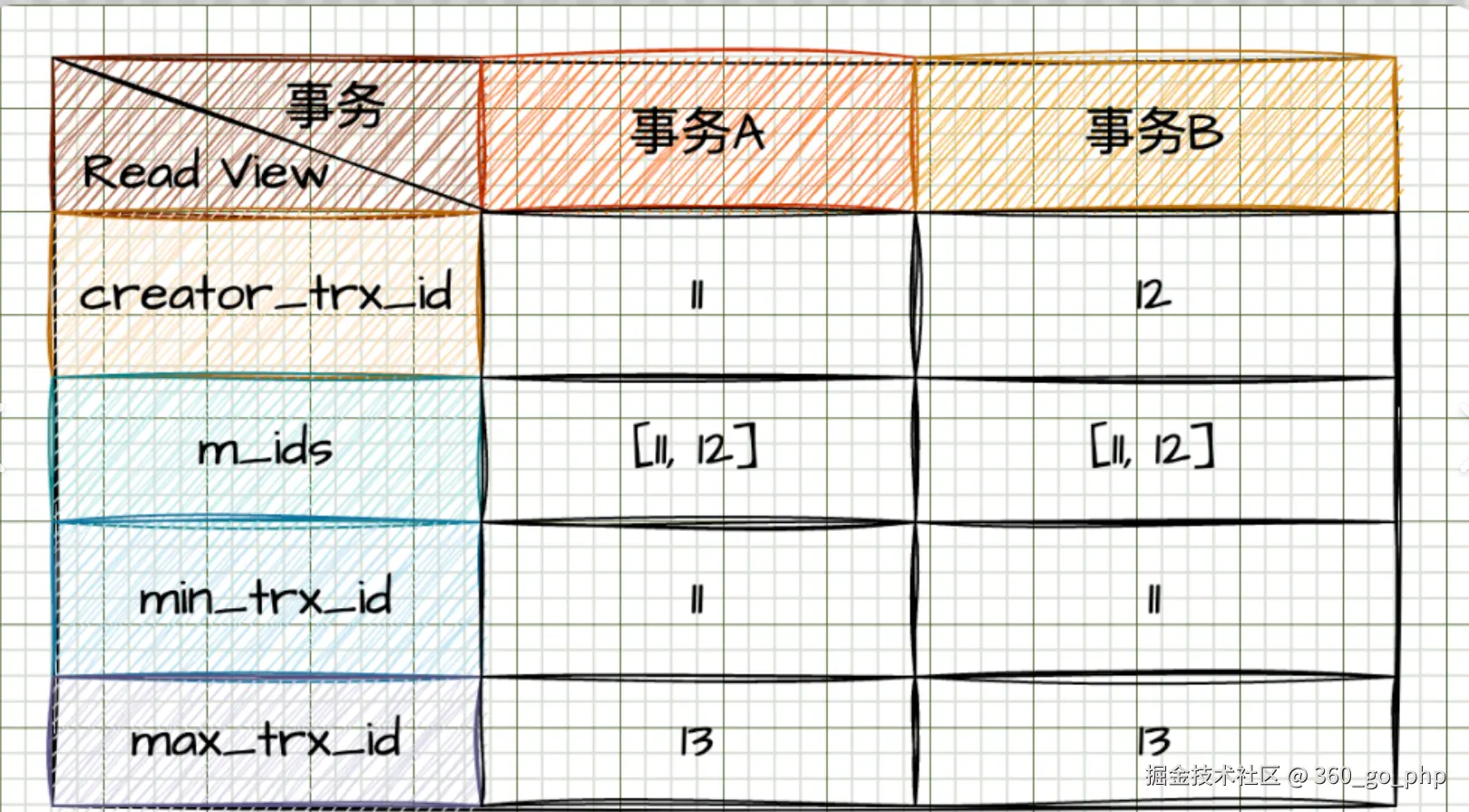 编辑
编辑 - 分区表:对于海量数据表,可以使用分区表将数据按范围分割,减少查询扫描的行数。
- 缓存:使用查询缓存或应用层缓存(如Redis)来缓存频繁查询的结果,减少数据库负担。
- 避免全表扫描:尤其是对于大表,避免没有索引的查询条件导致全表扫描,可以优化索引。
- 优化表设计 :合理设计表结构,使用合适的数据类型,避免冗余字段,提高查询效率。
 编辑
编辑
2. 优化器是什么时候起作用的?
MySQL优化器(Query Optimizer)在执行查询之前起作用。具体来说,优化器在查询语句被解析和转换成执行计划后,通过对不同的执行策略进行评估,选择最优的执行计划来执行查询。优化器主要工作在查询解析阶段,它会根据表的结构、索引、查询条件等信息来选择合适的访问路径。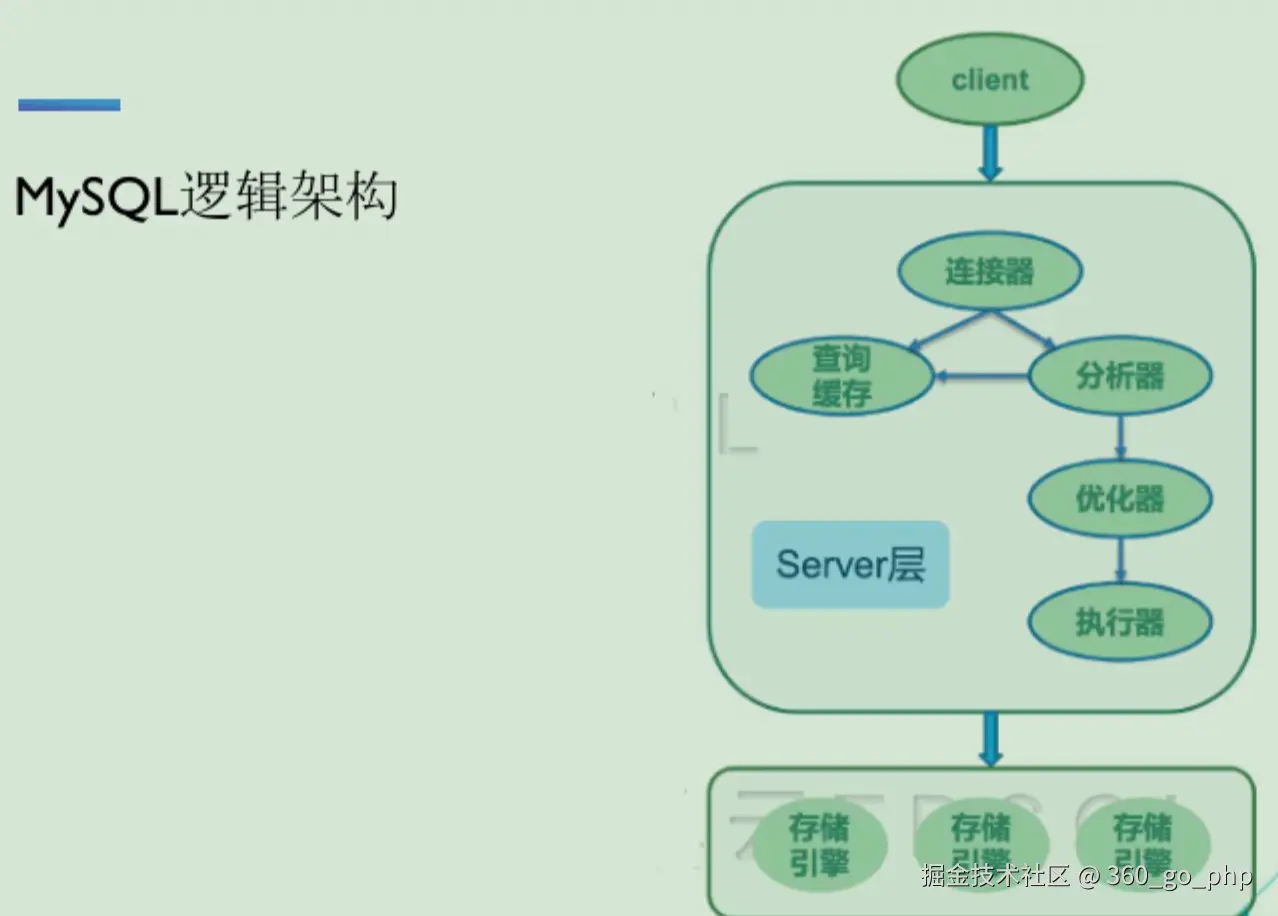 编辑
编辑
二、MySQL存储引擎及相关问题
3. MVCC的原理? 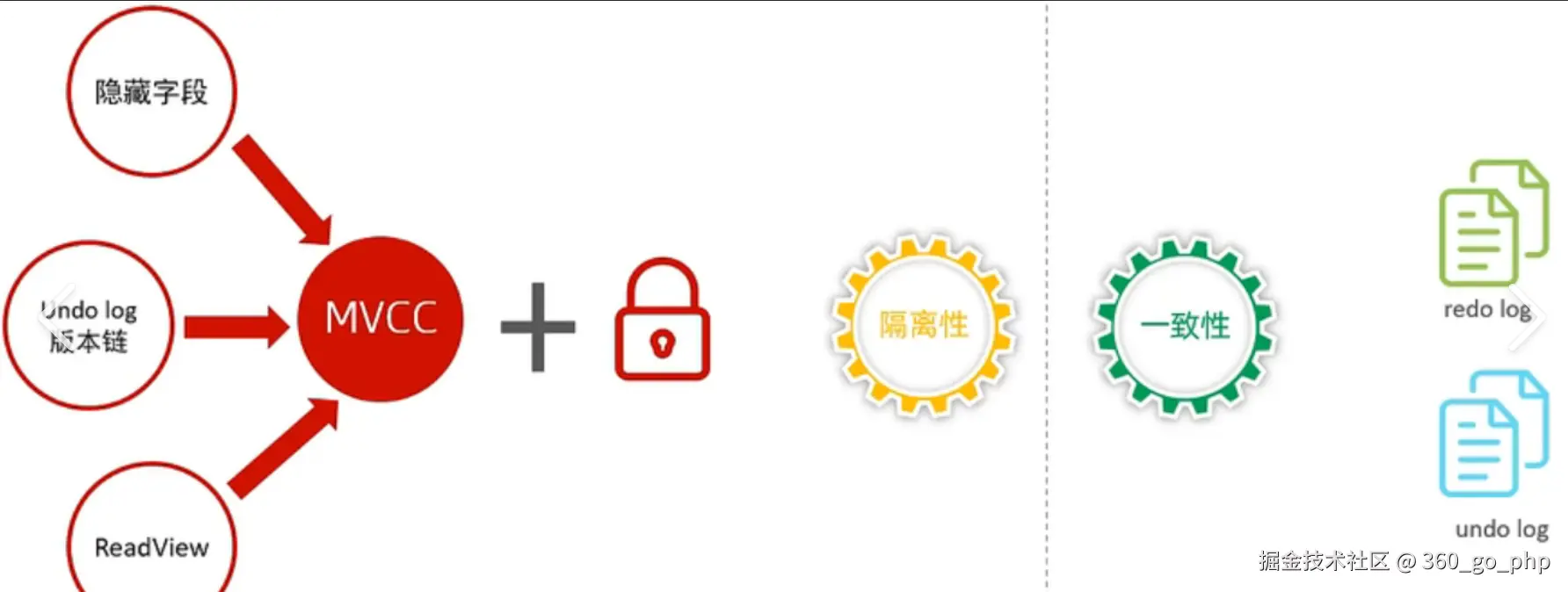 编辑
编辑
MVCC (Multi-Version Concurrency Control)是MySQL InnoDB存储引擎用来实现高并发控制和数据一致性的技术。它的原理主要通过对每一行数据的多个版本进行控制来实现并发读写。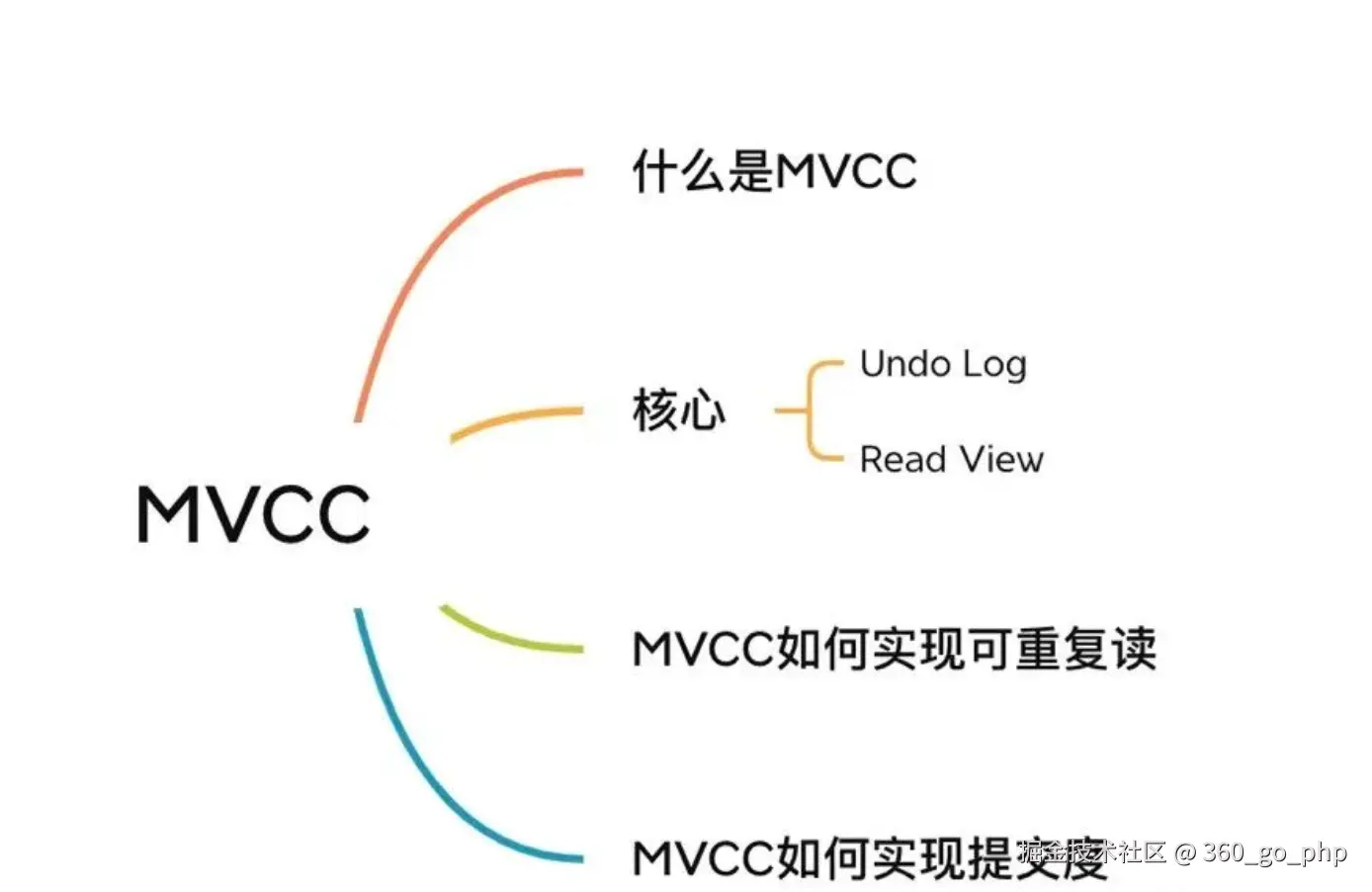 编辑
编辑
具体机制:
- 每个数据行都包含两个隐藏的列:
trx_id(事务ID)和**roll_pointer**(回滚指针)。 - 在事务操作数据时,InnoDB并不直接修改原始数据,而是将数据的一个新版本保存起来。每个版本都会记录一个事务ID。
 编辑
编辑 - 当查询数据时,InnoDB会根据当前事务的ID和数据版本的事务ID来决定是否能看到该数据。如果数据版本是被提交的,或者在当前事务之前已经提交,则该版本数据对当前事务可见。
 编辑
编辑 - 读取未提交数据:MVCC通过这种方式避免了"脏读"现象,并使得不同的事务能够并行执行。
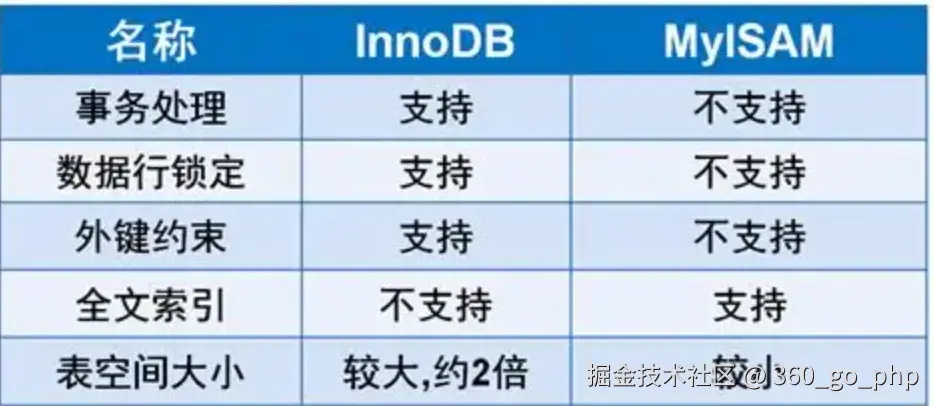
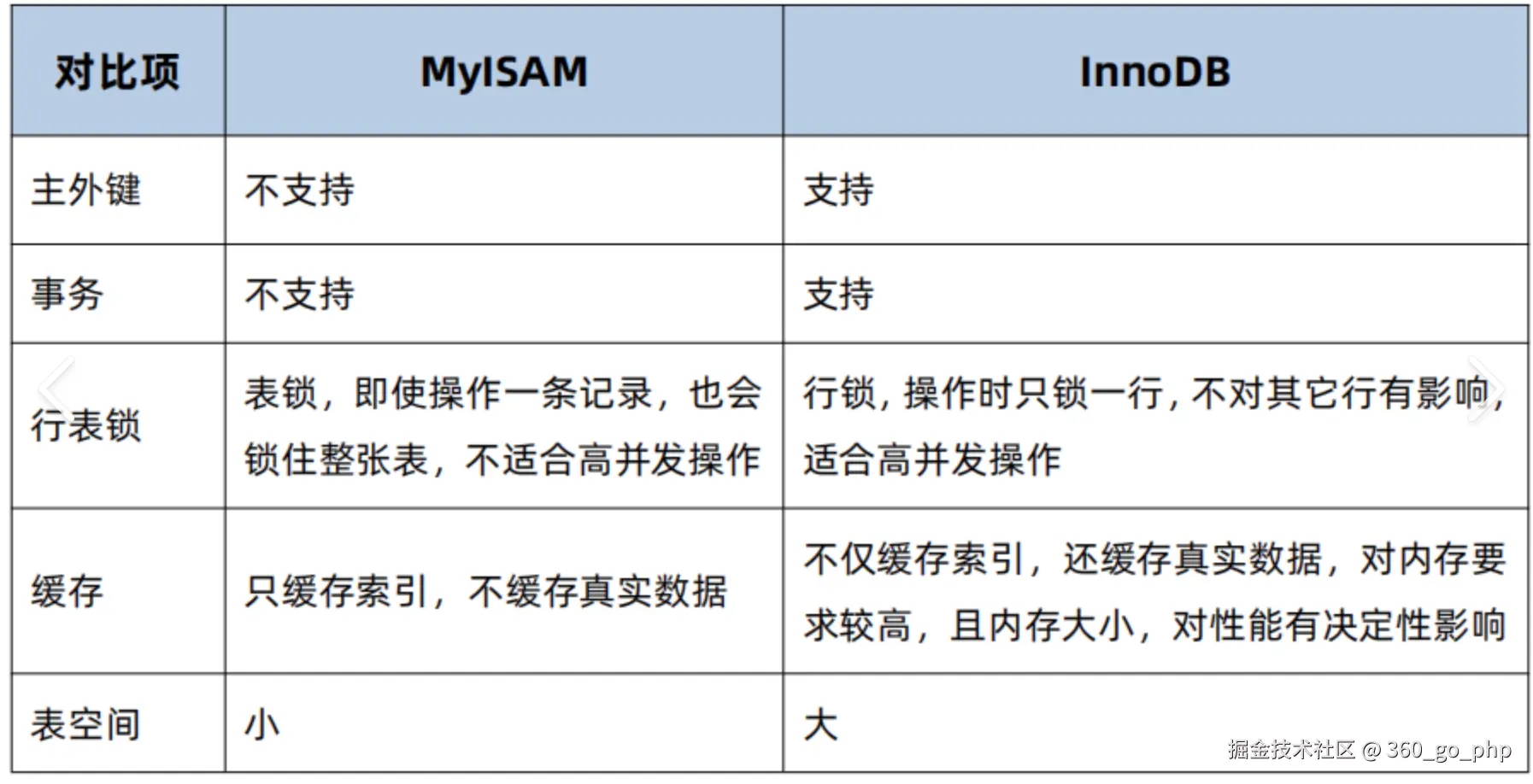
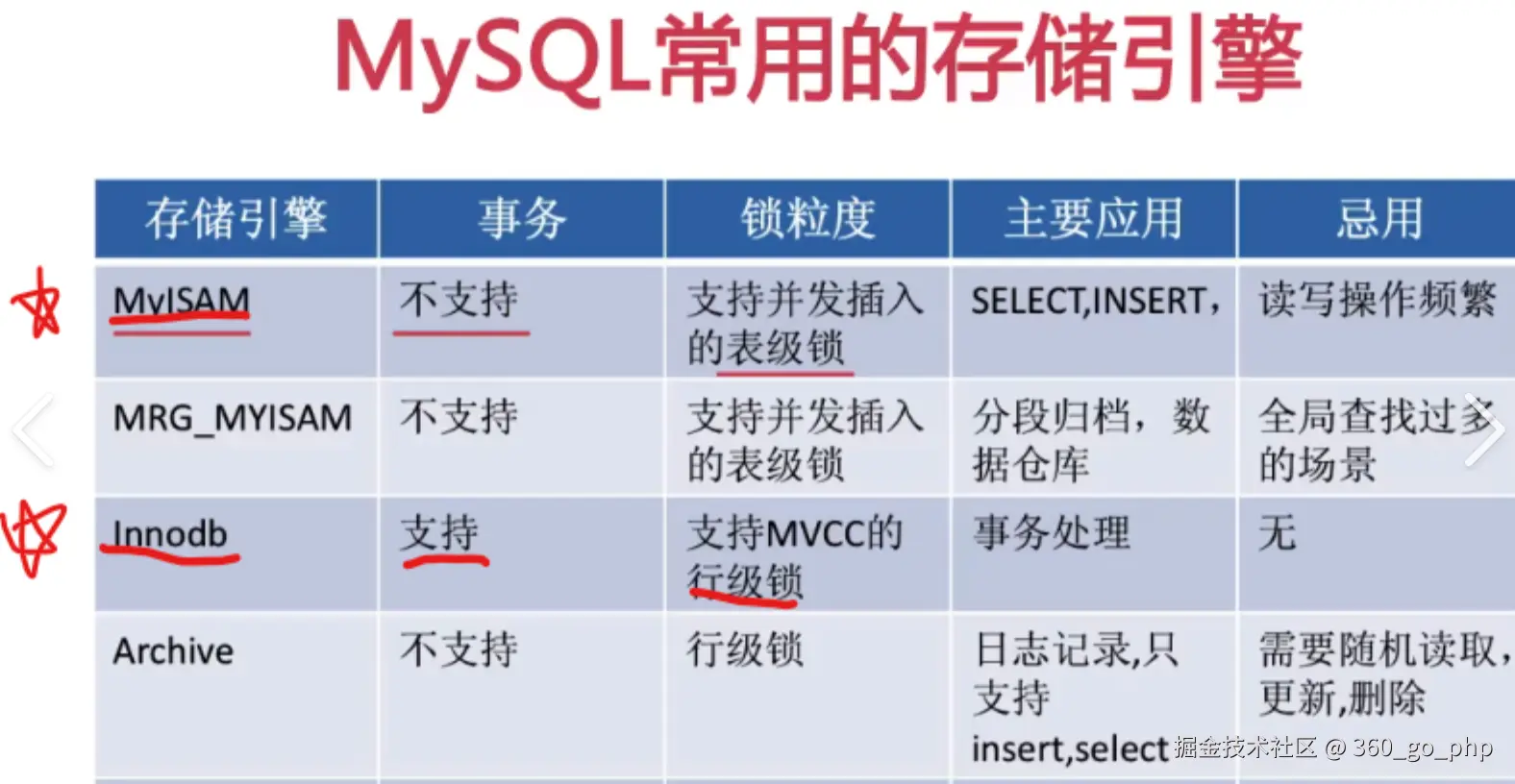
4. InnoDB和MyISAM的区别?
 编辑
编辑
- 事务支持 :
- InnoDB :支持事务(ACID),可以保证数据的一致性、隔离性、持久性和原子性。
- MyISAM :不支持事务,数据的一致性依赖应用层管理。
- 锁机制 :
- InnoDB :支持行级锁,锁粒度小,能够提高并发性。
- MyISAM :只支持表级锁,锁粒度大,适合读多写少的场景。
 编辑
编辑
- 数据存储 :
- InnoDB :数据存储方式是聚集索引存储,数据按主键顺序存储。
- MyISAM :数据存储方式是非聚集索引存储,数据存储在不同的文件中,索引和数据分离。
- 外键支持 :
- InnoDB :支持外键约束。
- MyISAM :不支持外键。
 编辑
编辑
- 性能 :
- InnoDB :适合需要高并发、事务性操作的场景。
- MyISAM:适合读多写少的场景,性能较优,但不支持事务。
5. InnoDB的聚集索引和MyISAM的非聚集索引的区别?
-
InnoDB的聚集索引 :
-
在InnoDB中,数据行本身就按主键顺序存储,主键索引就是聚集索引。聚集索引将数据存储在叶子节点中,每条数据都是索引的一部分。
-
聚集索引效率高,因为数据存储和索引顺序一致,可以直接在索引上找到数据。
-
-
MyISAM的非聚集索引 :
-
在MyISAM中,数据和索引分开存储。非聚集索引的叶子节点存储的是数据的地址(或指向数据的指针)。
-
由于数据和索引是分开的,所以需要额外的查找步骤来获取数据,通常效率较低。
-
三、数据结构与算法
6. B+树、B树、红黑树的区别:
-
B树(Balanced Tree) :
-
是一种自平衡的树数据结构,所有的叶子节点在同一层级上。
-
每个节点可以存储多个关键字,适用于存储大量数据。
-
B树的查找效率较高,但插入和删除操作的复杂度较大。
 编辑
编辑
-
-
B+树(B Plus Tree) :
-
B+树是B树的变种,所有数据都存储在叶子节点中,非叶子节点仅作为索引存在。
-
叶子节点通过链表连接,适合范围查询(如数据库中的范围检索)。
-
比B树更适合数据库和文件系统的实现,尤其在磁盘存储中,能更有效地减少I/O操作。
 编辑
编辑
-
-
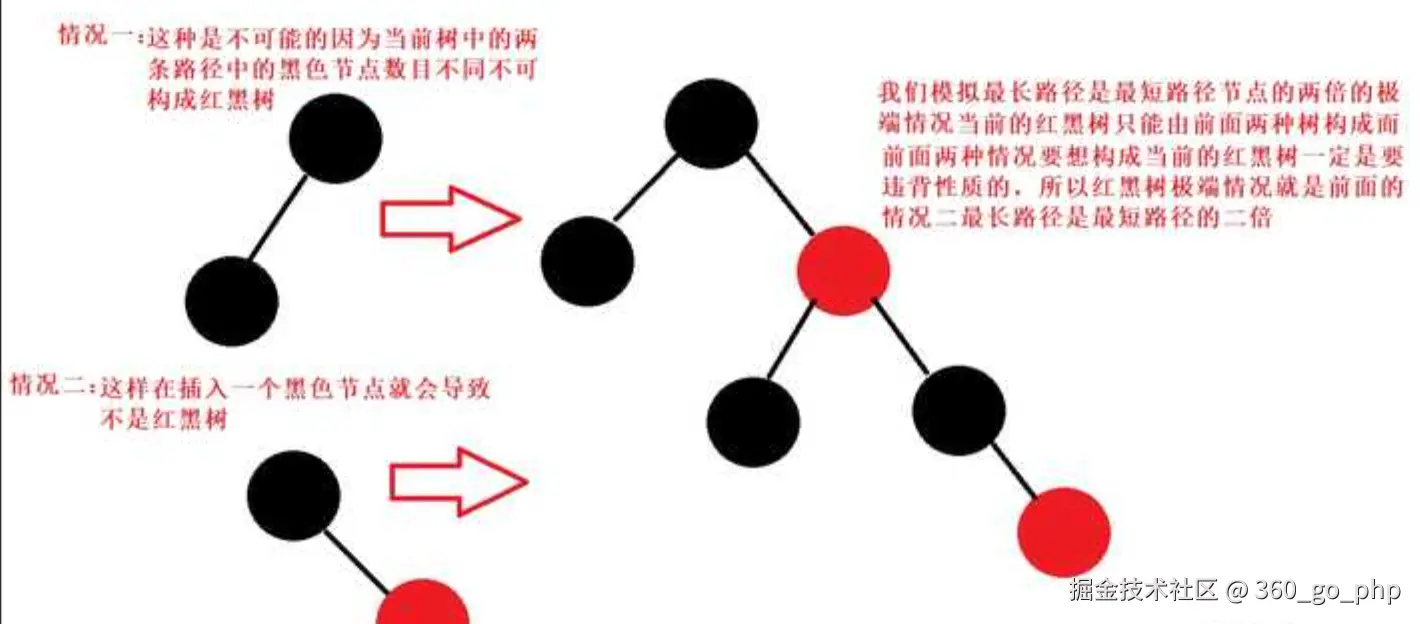
红黑树(Red-Black Tree) :
-
是一种自平衡的二叉查找树,每个节点都被标记为红色或黑色,并且满足一系列约束条件。
-
红黑树确保从根节点到所有叶子节点的路径上,黑色节点的数量是相同的,确保了树的平衡。
-
它常用于实现映射(如
TreeMap)和集合(如TreeSet)等数据结构,适用于需要频繁插入、删除的场景。
-
总结
在腾讯等大厂的MySQL面试中,考官往往不仅关注你的基础知识,还希望你能理解并应用MySQL的存储引擎、优化技巧和数据库设计原理。熟悉MySQL的各个方面,包括慢查询优化、事务控制、不同存储引擎的特点以及B树和红黑树等数据结构的差异,将使你在面试中更加得心应手。希望本文的解答能够帮助你深入理解并准备好面试中的相关问题!