String数据类型
String的基本命令:
1.set和get:

NX表示如果key不存在才设置,存在就不设置.
XX表示key存在才设置,不存在就不设置.
EX表示设置的过期时间,时间单位是秒;PX表示的是时间单位是毫秒.
2.mset和mget:
可以批量的设置和获取key.
3.setnx,setex,psetex:
分别是set nex,set ex,set px的缩写,功能一致.
4.incr,incrby:
分别表示整数value的自增和增值固定值,但只能针对整数,同时增加固定值也是只能增加整数.
5.decr,decrby,incrfloat:
分别是自减一和减去固定整数,增加小数.
6.append
在字符串的最后加上要拼接的字符串.
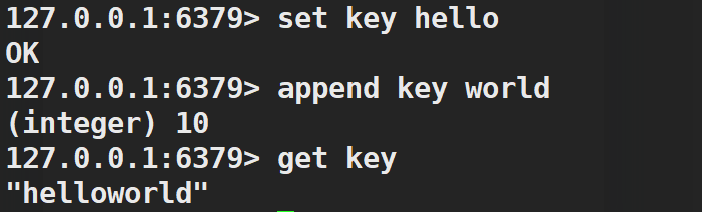
7.getrange和setrange
getrange是获取字符串的全部或部分,key后面的start和end表示就是范围(左闭右闭),可以使用负数,例如-1表示最后一个字符.
setrange表示改变字符串中的部分或全部字符.
8.setlen:
获取字符串的长度,统计的是字节(一个汉字三个字节).
String的一些应用场景
1)作为缓存,协助MySQL进行工作,由于redis具有良好的处理高并发的特性,可以很好降低MySQL面对大量请求宕机的缺点.
2)计数功能,当一个视频有一个点赞时就可以进行统计.
3)对session进行集中管理,面对负载均衡的情况,不同主机之间可以连接同一个redis服务器,使用一个redis服务器来进行管理session.
Hash数据类型
redis中存储数据的方式是通过"键值对"这样的哈希表的方式存储,而Hash数据类型表示的是value的值是hash,这就是在哈希表的里面套了一层哈希表,这样的结构外层使用的是key-value,里层表示的是field-value.
Hash的基本命令:
1)hget和hset:
hset可以设置一个value为哈希,hget则通过key和field来取到value.


2)hexists和hdel:
hexists可以根据key和查找field是否存在;hdel根据key删除field.
3)hkeys和hvals:
hkeys表示可以获得所有的field,hvals表示可以获得所有的value.但是这里的两个操作都不安全,如果哈希表中的数据过多,可能导致redis处理速度变慢.
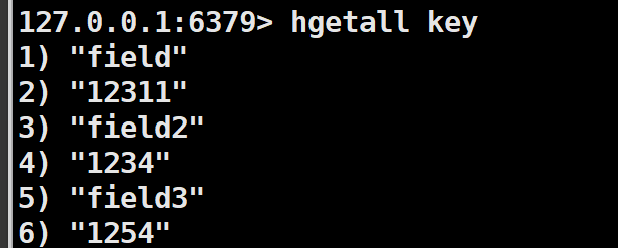
4)hgetall和hmget:
hgetall表示获取所有的field和value,hmget表示可以获取多个field的value.
5)hlen,hincr,hincrfloat:
分别是获取field的个数,针对整数和小数的加减.
6)hstrlen:
获取value值的字符串长度

List数据类型
list类型其实就类似于数组或顺序表,可以进行头插和头删,也可以进行尾插和尾删.
list的基本命令
1)lpush,rpush和lrange:
分别是头插和尾插,根据范围获取元数.
2)lpop和rpop:
头删和尾删.
3)lpushx,rpushx:
lpushx表示的是头插,但是key存在就插入,不存在就不会插入;rpushx表示尾插,存在就插.
4)lindex和llen:
lindex表示根据下标获取值;llen获取list中的元素个数.
5)linsert:
linsert根据基准值(list中的值)的插入基准值的前和后;

6)lrem:
lrem后面要跟要删除元数的个数和value,从前面开始遍历,删除指定的个数,当个数为正数就从前开始;为负数就从后开始遍历;为0就删除所有等于的value值.
7)ltrim,lset:
ltrim表示除了删除除了指定的left,right外所有的元素;lset表示在指定下标插入值.
8)blpop,brpop:
这里指的是带有阻塞效果的头删和尾删,这里的阻塞只针对list为空时,当list中有元素时,此时blpop和lpop没有区别,但是当list为空时,此时将lpop会直接返回nil,而blpop则会等待一定时间再返回nil,在这等待时间的过程中如果有元素插入,此时blpop就会将元素直接返回.
当有多个key同时blpop时,此时如果list不为空,就会返回最左边list的值;如果都为空就会进行等待,等到哪个list中有值了就返回.

List的一些应用场景
1)可以作为消息队列,通过blpophebrpop就可以实现一个经典的生产者消费者模型.
2)分频道的消息队列,可以有多个消费者同时监视同一个list,也可以一个消费者同时监视多个list.
Set数据类型
Set通俗讲就是集合,集合中的元素是无序的,这里的无序表示的是顺序并不会影响集合的结果,集合中的元素是不能重复.
除了基本的对单个集合的操作,还有进行对多个集合的取交集(inter),并集(union),差集(diff).
set的基本命令
1)sadd,smembers,sismember:
sadd往集合中添加元素,当有重复元素是就会进行去重,最后只能有一个.
smembers是查询所有的元素.
sismember表示要查询member在不在集合中.
2)spop,srandmember:
spop表示随机删除一个元素.
srandmember表示随机取出一个元素.,但是不删除.
3)scard:
计算出集合中所有的元素个数.
4)sinter,sunion,sdiff:
分别是计算交集,补集,差集;加上store就是将求出的集合重新装到新的集合中.
Set的一些引用场景
set比较适合的是标签,例如体育,游戏等题材,可以将其抽象成标签,提供给用户选择,方便推荐相应题材.
Zset数据类型
Zset表示的是"有序"的集合,插入元素要以score member的形式进行,zset中的有序其实就是按照对比score进行排序.
1)zadd:
添加一个或多个集合元素,以分数 元素的形式来进行插入,返回的是添加的元素个数.
CH:不仅返回添加元素的个数,也返回了更新元素的个数.
incr:类似incrby的效果,将score增加指定值.
2)zcard,zcount:
zcard表示统计一共几个元素.
zcount表示在指定区间内(使用score)的所有元素个数,默认是两边都是闭区间,但是可以排除边界值.

3)zrange,zrevrange:
zrange获取指定区间中的所有元素.
zrevarge表示将指定区间内所有元素逆转(降序排序).
两者带上withscore都可以将元素和分数都返回.
4)zpopmax/zpopmin:
删除集合score中最大/最小的值.
5)bzpopmax:
zpopmax的阻塞版本.
6)zrank/zrevrank:
升序/降序返回元素的排名.
7)zscore:
返回指定member的分数.
8)zrem:
指定的member进行删除.
9)zremrangebyrank/zremrangebyscore:
按照排序/分数删除指定区间内的元素(左闭右闭).
10)zincyby:
将分数增加指定值.
11)zinterstore,zunionstore:
交集,并集.
Zset的一些应用场景
1)一般可以用于游戏的天梯系统,当这些排名有变化时,就根据相应的分数进行修改.
2)删除排行榜上的人就可以使用zset中的命令.
scan渐进式遍历
为了防止keys*这样的操作导致redis阻塞,我们可以使用渐进式遍历(这里的scan表示遍历string,其他类型也有其他命令).
基本语法:scan a count b
a首次要从0开始,往后的遍历a填的是返回的'a'.
b表示要返回的key的个数
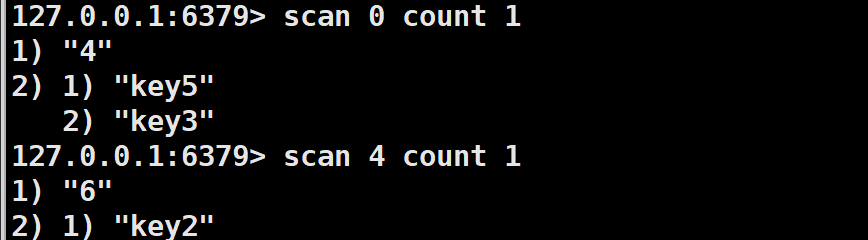
这里的返回的key的个数不一定会按照指定的个数返回(返回1不一定返回一个key).
在Java和Spring中使用redis客户端
在idea中使用redis客户端,首先要引入依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.5</version>
</dependency>使用jedispool这个类,初始化这个redis连接池.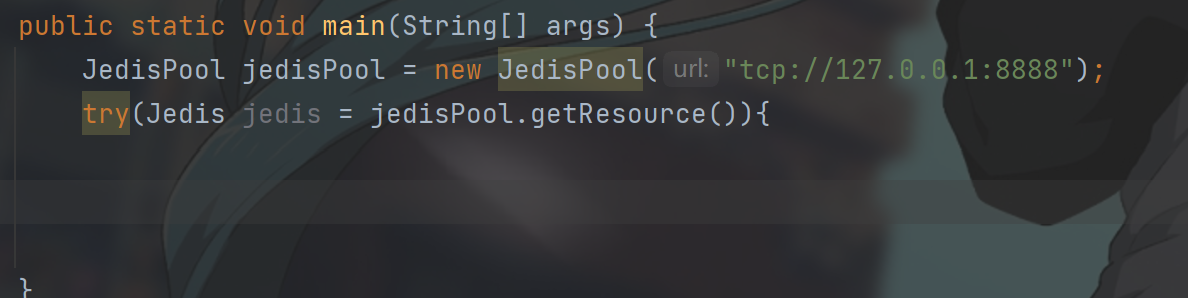
这里要注意的是redis服务器在云服务器上,需要开设redis的端口,我们远程的主机才能连接到redis的服务器,但是开放这个端口会导致redis服务器不安全,这会导致服务器被攻击,所以可以采取ssh远程端口映射,将redis在服务器上的端口映射到我们本地,这样使用本地的IP端口就可以进行访问了.
从连接池中取出一个连接jedis,jedis就表示当前的一个redis连接,我们可以对这个对象进行操作.
这里的方法都是和在Linux上操作的命令相似,可以举一反三.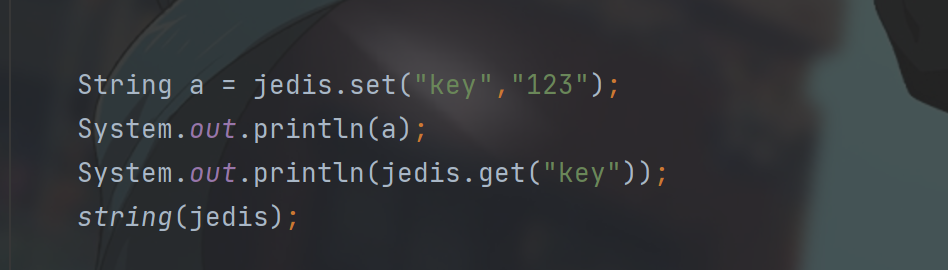
在Spring中使用redis客户端,同样要引入依赖,在创建spring的项目时需要勾选上操作redis的选项
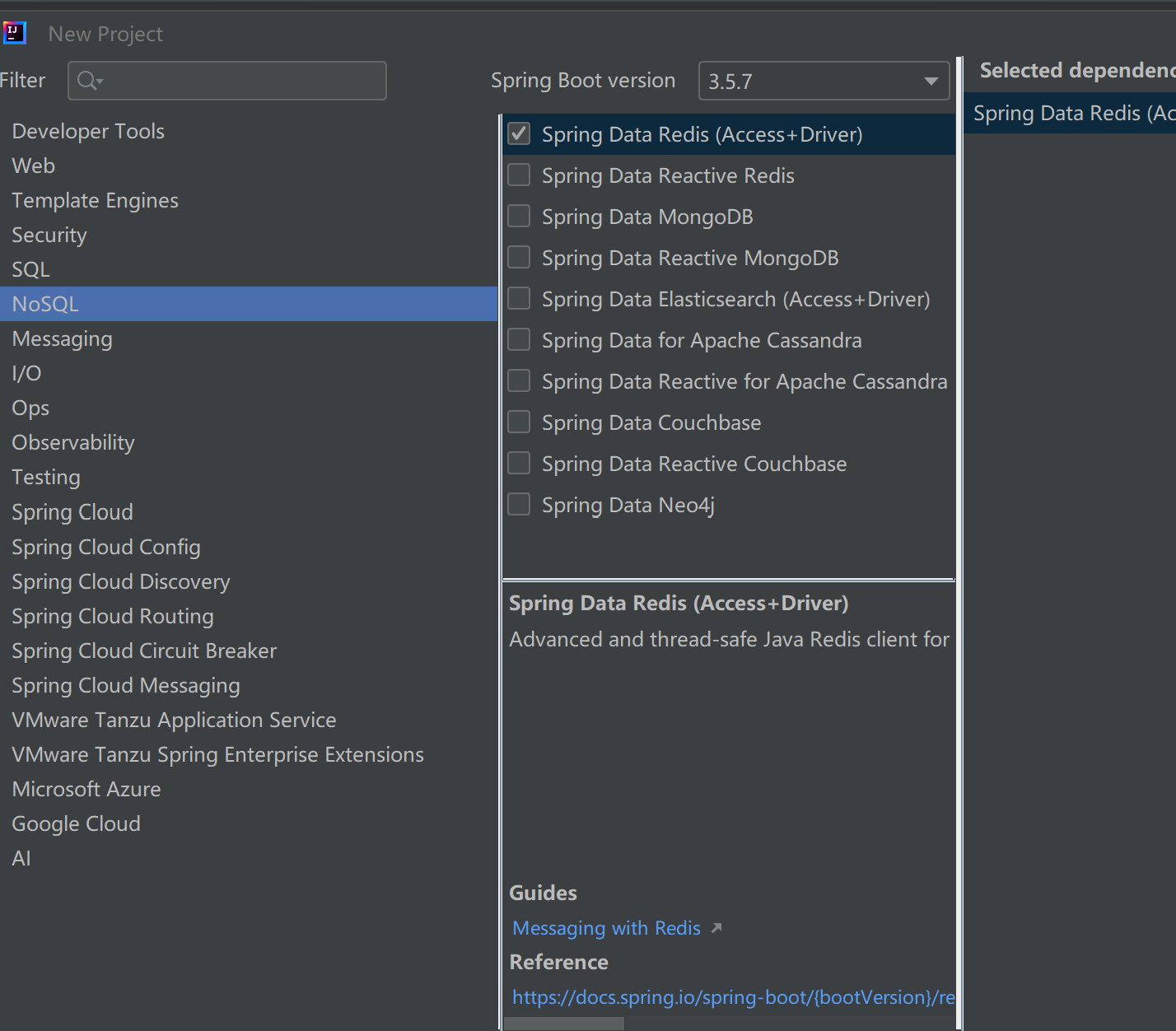
创建好项目后就需要设置配置文件:
spring:
data:
redis:
host: 127.0.0.1
port: 8888同时检查ssh端口映射是否开启:

准备工作就已完成,接下来就是进行编写代码:
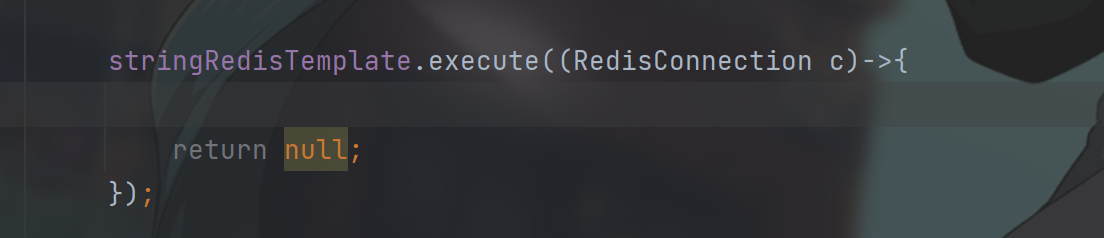
在spring中需要使用 StringRedisTemplate 这个类来进行操作redis,这个类对jedis中的操作又进行了一次封装.
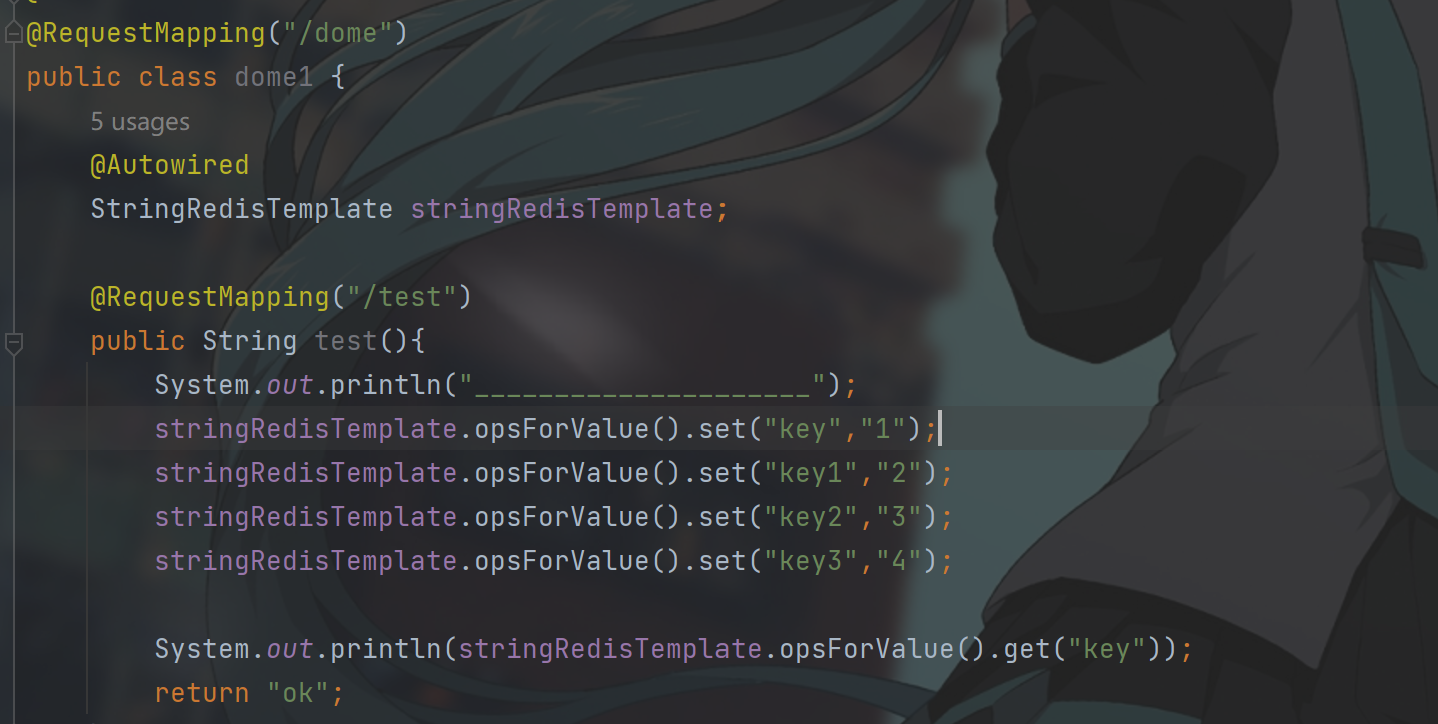 上面使用的就是插入字符串类型.
上面使用的就是插入字符串类型.
除了封装以外,redisTemplate还有可以通过回调函数调用封装前的方法