以太网帧结构
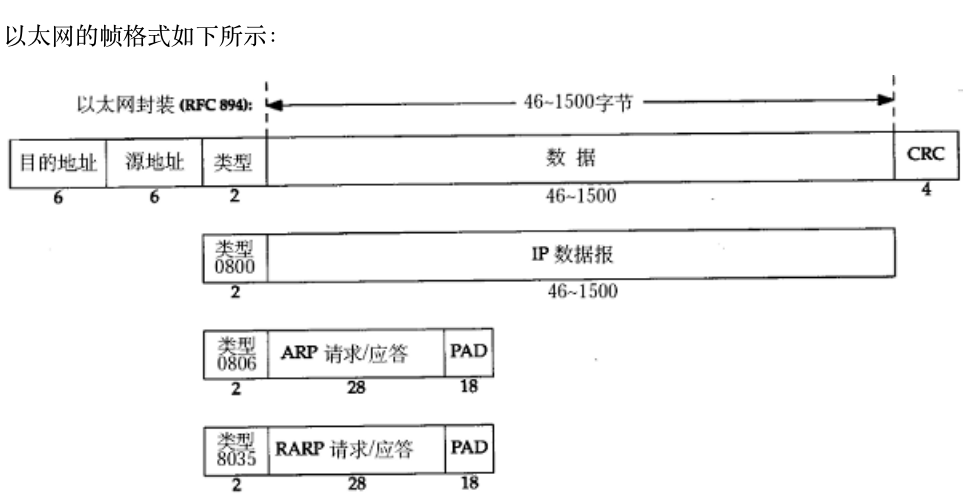
| 目标MAC地址(6字节) | 源MAC地址(6字节) | 帧类型(2字节) | 数据载荷(46 - 1500字节) | CRC校验码(4字节) |
1.源地址和目的地址(MAC地址)
定义:确为网卡的物理地址 / 硬件地址,长度48位(6字节),网卡出厂时固化。
MAC地址用来识别数据链路层中相连的节点;长度为48位, 及6个字节.一般用16进制数字加上冒号的形式来表示(例如: 08 : 00 : 27 : 03 : fb : 19)
在网卡出厂时就确定了, 不能修改mac地址通常是唯一的
作用:在局域网内标识数据帧的发送者和接收者(类似快递单上的收件 / 寄件人地址)。
- 帧协议类型字段(EtherType)
定义:2字节字段,指示数据载荷中封装的上层协议类型。
常见值:
0x0800:对应 IPv4 协议
0x0806:对应 ARP 协议(地址解析协议)
0x8035:对应 RARP 协议(反向地址解析协议,现已很少使用)
0x86DD:对应 IPv6 协议
作用:接收方网卡根据此字段判断应将帧数据交给哪个上层协议栈处理(如IP协议栈或ARP模块)。
- 帧末尾CRC校验码
定义:4字节(32位)的循环冗余校验码,也称FCS(帧校验序列)。
作用:接收方通过CRC校验检测帧在传输过程中是否出现比特错误(如信号干扰导致的位翻转)。若校验失败则丢弃该帧。
对比理解MAC地址和IP地址
IP地址描述的是路途总体的 起点 和 终点;
MAC地址描述的是路途上的每⼀个区间的起点和终点。
认识MTU
MTU相当于发快递时对包裹尺寸的限制.这个限制是不同的数据链路对应的物理层, 产⽣的限制.
以太网帧中的数据长度规定最小46字节, 最大1500字节, ARP数据包的长度不够46字节, 要在后⾯补填充位;
最⼤值1500称为以太网的最大传输单元(MTU), 不同的网络类型有不同的MTU;
如果⼀个数据包从以太网路由到拨号链路上, 数据包长度大于拨号链路的MTU了, 则需要对数据包进行分片(fragmentation);
不同的数据链路层标准的MTU是不同的;
MTU 对 TCP 协议的影响
MTU(Maximum Transmission Unit,最大传输单元)是数据链路层规定的单次传输数据的最大长度,而 TCP 的 MSS(Maximum Segment Size,最大报文段长度)受 MTU 限制。
MTU 与 MSS 的关系
-
MTU(数据链路层限制):
-
以太网默认 MTU = 1500 字节(含 IP 头 + TCP 头 + 数据)。
-
IP 头通常占 20 字节 ,TCP 头占 20 字节 ,因此 MSS =
1500 - 20 - 20 = 1460 字节。
-
-
MSS(TCP 层限制):
-
表示 TCP 单次可发送的最大数据长度(不含 TCP/IP 头)。
-
若数据超过 MSS,TCP 会分段(Segment),IP 层可能分片(Fragment)。
-
MSS 协商(三次握手阶段)
TCP 在建立连接时,双方通过 SYN 报文交换 MSS 值:
-
客户端发送 SYN :携带自己的 MSS(如
1460)。 -
服务端回复 SYN-ACK :携带自己的 MSS(如
1420)。 -
双方选择较小的 MSS :最终 MSS =
min(1460, 1420) = 1420。- MSS 值存储在 TCP 头部的 选项字段(Kind=2)。
为什么协商 MSS?
避免 IP 分片(降低传输效率),确保数据能被对端完整接收。
MTU 对 TCP 性能的影响
-
MTU 过小:
-
增加分段次数 → 降低吞吐量。
-
更多 TCP 头部开销(每个分段需加 20 字节 TCP 头 + 20 字节 IP 头)。
-
-
MTU 过大:
- 可能触发 IP 分片 → 丢失任意分片会导致整个数据报重传。
MTU对IP协议的影响
由于数据链路层MTU的限制,对于较大的IP数据包要进行分包处理。
IP分片机制:
-
分包过程
-
将较大的IP包分成多个小包,并给每个小包打上标签
-
每个小包IP协议头的16位标识(Identification) 都是相同的,用于标识属于同一个原始数据包
-
-
标志字段设置
-
每个小包的IP协议头的3位标志字段中:
-
第2位(DF位):置为0,表示允许分片
-
第3位(MF位):表示结束标记
-
如果是最后一个小包,置为1
-
如果不是最后一个小包,置为0
-
-
-
-
重组过程
-
到达对端时,将这些小包按顺序重组,拼装到一起返回给传输层
-
重组依据:IP头部的标识符、分片偏移量、MF标志位
-
-
分片丢失的影响
-
一旦这些小包中任意一个小包丢失,接收端的重组就会失败
-
但IP层不会负责重新传输数据,数据包将被丢弃
-
重传责任由上层协议(如TCP)或应用程序承担
-
存在的问题:
-
效率低下:分片增加处理开销,降低传输效率
-
可靠性差:任意分片丢失导致整个IP数据包作废
-
安全风险:可能被用于分片攻击
优化建议:
-
应用程序应尽量控制数据包大小,避免IP分片
-
TCP通过MSS协商自动避免分片
-
UDP应用需要手动控制数据包大小
ARP报文格式

ARP报文采用大端序(网络字节序),其格式如下:
| 字段 | 长度(字节) | 说明 |
|---|---|---|
| 硬件类型 | 2 | 链路层网络类型,1表示以太网 |
| 协议类型 | 2 | 要转换的地址类型,0x0800表示IP地址 |
| 硬件地址长度 | 1 | MAC地址长度,以太网为6字节 |
| 协议地址长度 | 1 | IP地址长度,IPv4为4字节 |
| op(操作码) | 2 | 1=ARP请求,2=ARP应答 |
| 发送端MAC地址 | 6 | 发送方的MAC地址 |
| 发送端IP地址 | 4 | 发送方的IP地址 |
| 目的端MAC地址 | 6 | 目标MAC地址(请求时为全F广播地址 FF:FF:FF:FF:FF:FF) |
| 目的端IP地址 | 4 | 目标IP地址 |
ARP请求的处理流程(广播)
当主机B收到一个 ARP请求 (广播包,目的MAC=FF:FF:FF:FF:FF:FF)时:
(1) MAC层处理
-
所有主机 都会接收广播包(因为目的MAC是
FF:FF:FF:FF:FF:FF)。 -
MAC层不会丢弃,因为广播包是发给所有主机的。
(2) ARP层处理
主机B的ARP模块解析ARP请求,检查以下字段:
-
op字段:-
如果是 ARP请求(op=1) ,继续检查
目的IP。 -
如果是其他值(如非法值),直接丢弃(ARP层)。
-
-
目的IP字段:-
匹配主机B的IP:
-
记录 主机A的MAC和IP 到ARP缓存。
-
构造 ARP应答(单播返回给主机A)。
-
-
不匹配:
- 在ARP层丢弃(不再处理)。
-
为什么不在MAC层丢弃?
因为ARP请求是广播包 ,MAC层无法判断是否该丢弃(所有主机都必须接收广播包)。只有到了ARP层才能检查
目的IP是否匹配自己。
ARP应答的处理流程(单播)
当主机A收到 ARP应答(单播包,目的MAC=主机A的MAC)时:
(1) MAC层处理
-
检查目的MAC:
-
匹配主机A的MAC → 继续传递给ARP层。
-
不匹配 → 直接在MAC层丢弃(因为单播包只发给特定主机)。
-
(2) ARP层处理
主机A的ARP模块解析ARP应答,检查以下字段:
-
op字段:-
如果是 ARP应答(op=2),继续处理。
-
如果是其他值(如非法值),直接丢弃(ARP层)。
-
-
目的IP字段:-
匹配主机A的IP → 更新ARP缓存(记录主机B的MAC和IP)。
-
不匹配 → 在ARP层丢弃(异常情况)。
-
关键结论
| 数据包类型 | 丢弃位置 | 原因 |
|---|---|---|
| ARP请求(广播) | ARP层丢弃 | 所有主机都会收到广播包,MAC层无法过滤,必须由ARP层检查 目的IP。 |
| ARP应答(单播) | MAC层丢弃 | 单播包的目标MAC明确,不匹配的主机应在MAC层直接丢弃。 |
只有需要 MAC 地址但缓存里没有时才会触发,而不是每次发送数据都发 ARP。
没有缓存时,每次子网路由都会触发ARP
完整数据发送流程(结合 ARP 协议)
cpp
应用层:生成数据(如 HTTP 请求)
↓
传输层:加 TCP/UDP 头(端口号)
↓
网络层:加 IP 头(源 IP、目标 IP)
↓
* * 检查 ARP 缓存 * *
│
├── 如果有目标 MAC → 直接封装帧,发送数据
│
└── 如果没有目标 MAC → 先发 ARP 请求,等应答后再封装帧
↓
数据链路层:加 MAC 头(源 MAC、目标 MAC)场景一:目标 IP 在同一个子网(局域网通信)
步骤详解:
-
应用层
- 生成数据(如 HTTP 请求报文)。
-
传输层
-
添加 TCP/UDP 头部(包含源端口、目的端口)。
-
例如:
TCP 头 + HTTP 数据。
-
-
网络层(IP 层)
-
添加 IP 头部(源 IP、目标 IP、TTL 等)。
-
关键判断:通过子网掩码计算,发现目标 IP 在同一子网。
-
检查 ARP 缓存:
-
如果缓存中有目标 IP 对应的 MAC → 直接跳到步骤 5。
-
如果缓存中没有 → 触发 ARP 请求。
-
-
-
ARP 解析过程
-
ARP 请求(广播):
-
发送广播包:
"Who has 192.168.1.100? Tell 192.168.1.50" -
目的 MAC =
FF:FF:FF:FF:FF:FF(广播地址)
-
-
ARP 应答(单播):
-
目标设备回应:
"192.168.1.100 is at aa:bb:cc:dd:ee:ff" -
更新 ARP 缓存。
-
-
-
数据链路层
-
用获得的 MAC 地址封装以太网帧:
-
目的 MAC = 目标设备的 MAC
-
源 MAC = 本机 MAC
-
-
通过网卡发送数据。
-
场景二:目标 IP 不在同一个子网(跨网络通信)
步骤详解:
-
应用层 → 传输层 → 网络层(同上)
-
网络层(IP 层)关键判断
-
通过子网掩码计算,发现目标 IP 不在本地网络。
-
例如:
192.168.1.50访问8.8.8.8。
-
-
ARP 解析默认网关
-
触发 ARP 请求查询默认网关的 MAC 地址:
"Who has 192.168.1.1? Tell 192.168.1.50"(网关 IP)
-
获得网关的 MAC 地址(如
gg:gg:gg:gg:gg:gg)。
-
-
数据链路层封装
-
目的 MAC = 网关的 MAC 地址(不是最终目标的 MAC)
-
源 MAC = 本机 MAC
-
IP 头中的目标 IP 仍然是最终目标 (如
8.8.8.8)
-
-
网关路由
-
网关收到帧后,根据 IP 头部的目标 IP 进行路由转发。
-
后续经过多个路由器,最终到达目标网络。
-
ARP 缓存机制
缓存作用
-
避免重复查询:每次通信前不必都发 ARP 请求。
-
提高效率:减少网络广播流量。
缓存特性
-
有效期:通常 2-5 分钟(系统可配置)。
-
自动更新:收到 ARP 应答时更新缓存。
可以用 arp - a(Windows / Linux)查看当前缓存。