在最近的项目中,我负责从零搭建一个基于 Spring Boot + Dubbo + Redis + RocketMQ 的分布式微服务系统。整个项目大约持续一个多月,代码量较大,是我第一次完整实践从后端架构设计到部署上线的全过程。
1. 自我介绍
略
2. 项目介绍
略
3. 为什么要做微服务?
做微服务的核心原因是为了解耦与扩展性 。单体项目后期难以维护,功能耦合严重、部署困难、影响面大。 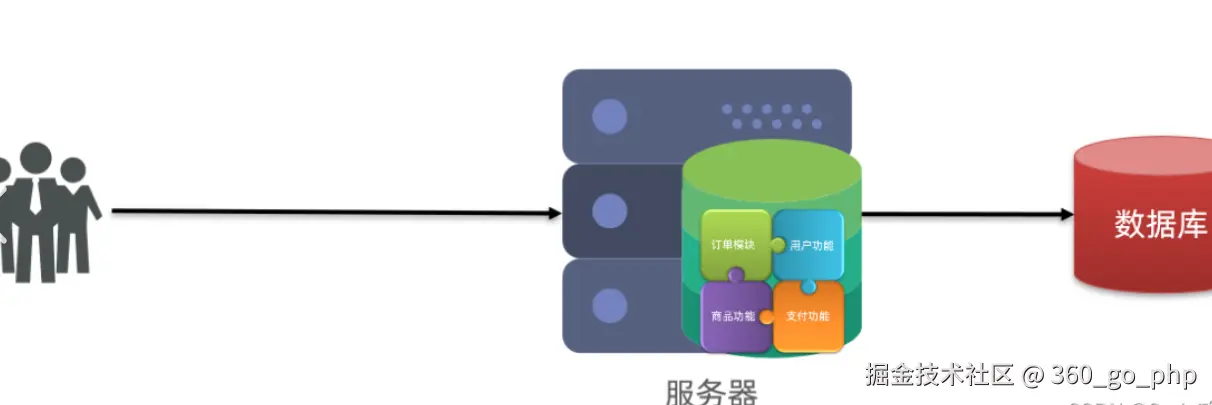 编辑
编辑
微服务将系统拆分成多个独立模块(如用户、订单、支付、库存等),每个服务可以独立开发、独立部署、独立扩展 ,提升了系统的灵活性和可靠性。 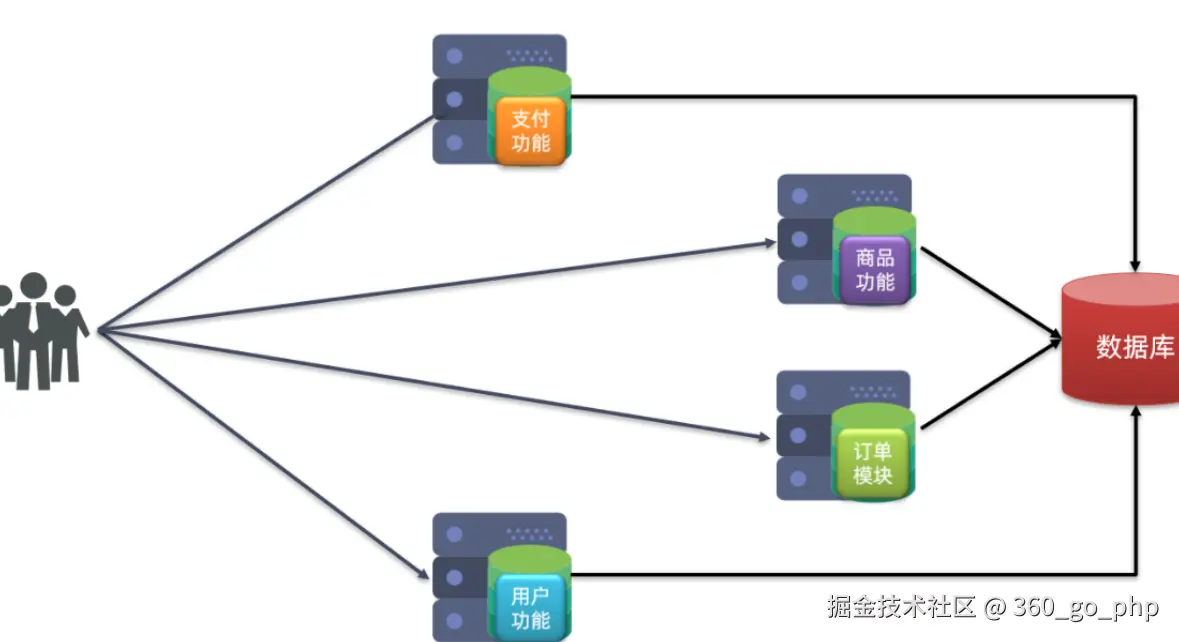 编辑
编辑
4. 为什么用 Dubbo?
选择 Dubbo 是因为它在高性能 RPC 通信 和服务治理能力 上表现优秀。
它相比 HTTP REST 接口更高效,支持负载均衡、服务注册与发现、容错机制等。
另外,在公司或校园内网环境中,Dubbo 的**注册中心(Zookeeper 或 Nacos)**让服务发现更加方便稳定。
5. 为什么分为四个服务?
我将项目拆分为四个服务(例如:用户服务、商品服务、订单服务、支付服务),主要基于**领域驱动设计(DDD)**的思想。
拆分的原则是:高内聚、低耦合。每个服务都聚焦于自己的一部分业务逻辑,这样可以方便后期扩展与维护。
6. 谈谈 Spring Cloud
Spring Cloud 是另一套微服务解决方案,相比 Dubbo 更偏向 HTTP + Spring Boot 全家桶的生态,比如使用 Eureka、Ribbon、Feign、Gateway、Hystrix 等组件。
我了解 Spring Cloud 的核心思想:它通过标准化组件来实现服务注册、配置中心、负载均衡和链路追踪等功能。
如果是互联网项目,Spring Cloud 更适合;而 Dubbo 更适合高性能 RPC 的企业内部系统。
7. 为什么项目里面自己没有用多线程?
项目初期主要是 I/O 密集型操作(数据库、网络通信),Spring 框架内部已经做了线程池和异步优化,因此我没有手动创建线程,避免资源竞争和管理复杂性。
8. 哪些地方用了多线程?
在异步消息处理和缓存预热部分用到了多线程:
- RocketMQ 消费者中使用线程池并发处理消息。
- Redis 缓存预热 时用多线程异步加载数据,加快启动速度。
 编辑
编辑
9. 在遇到什么困难的情况下用了 Redis?
项目初期数据库访问压力大,响应速度慢。我引入 Redis 缓存 来解决性能瓶颈。
具体使用场景包括:
- 热点数据缓存(如热门商品、用户登录信息)
- 分布式锁(防止超卖)
- 延迟队列与排行榜功能
Redis 的高并发读写能力显著提升了系统性能。
10. 为什么用 RocketMQ?
RocketMQ 主要用于异步解耦与削峰填谷 。
例如,订单创建后异步发送库存扣减消息,避免主线程阻塞,提高系统吞吐量。
它支持事务消息和高可靠性投递机制,比 RabbitMQ 更适合大规模分布式场景。  编辑
编辑
11. 为什么不用 2PC、3PC、TCC?
这些属于强一致性事务方案 ,实现复杂、性能开销大。
我使用了 RocketMQ 的最终一致性事务消息机制,在业务层通过状态回查保证可靠性,既满足一致性要求又兼顾性能。
12. 你1个多月做这个项目,怎么做完的?
坦白说,我几乎是靠高强度学习和熬夜赶出来的 。
我每天学习新技术(Dubbo、MQ、Redis 等),白天设计架构、晚上编码调试。
虽然辛苦,但过程极大提升了我对分布式系统的理解。
13. 项目上线了吗?用什么方案部署的?了解热部署吗?
项目已上线测试环境,使用 Docker + Nginx + Jenkins 实现 CI/CD 自动化部署。
我了解**热部署(Hot Deployment)**的概念------在不重启服务的情况下更新代码或配置。
开发阶段用 Spring DevTools ,生产环境通过 容器滚动更新 实现热部署效果。 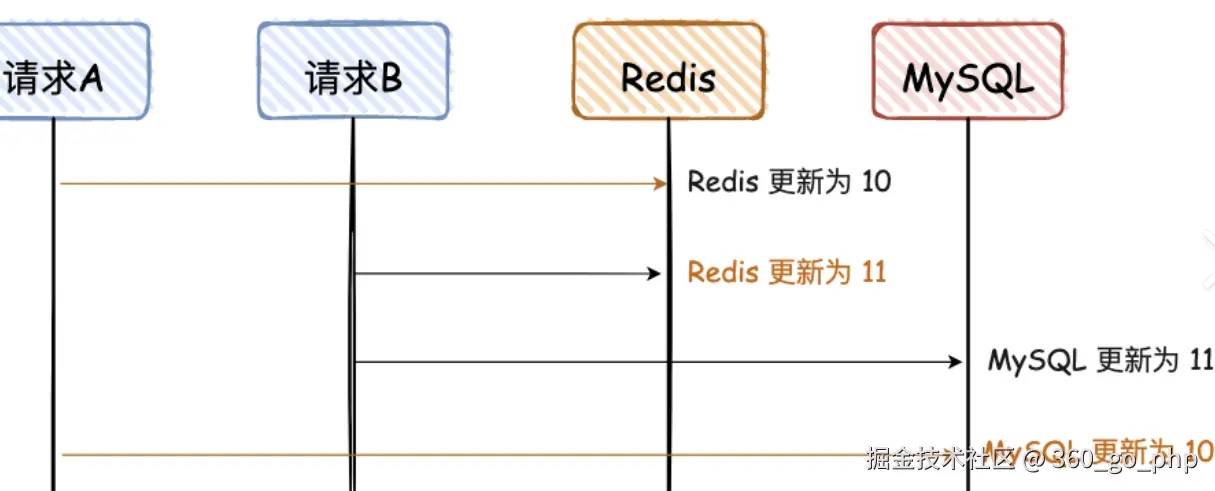 编辑
编辑
14. 为什么没有实习?
因为我在这段时间专注于完成自己的技术项目,希望通过实战掌握后端架构核心能力。
相比短期实习,我认为做出一个完整项目更能展示真实能力。 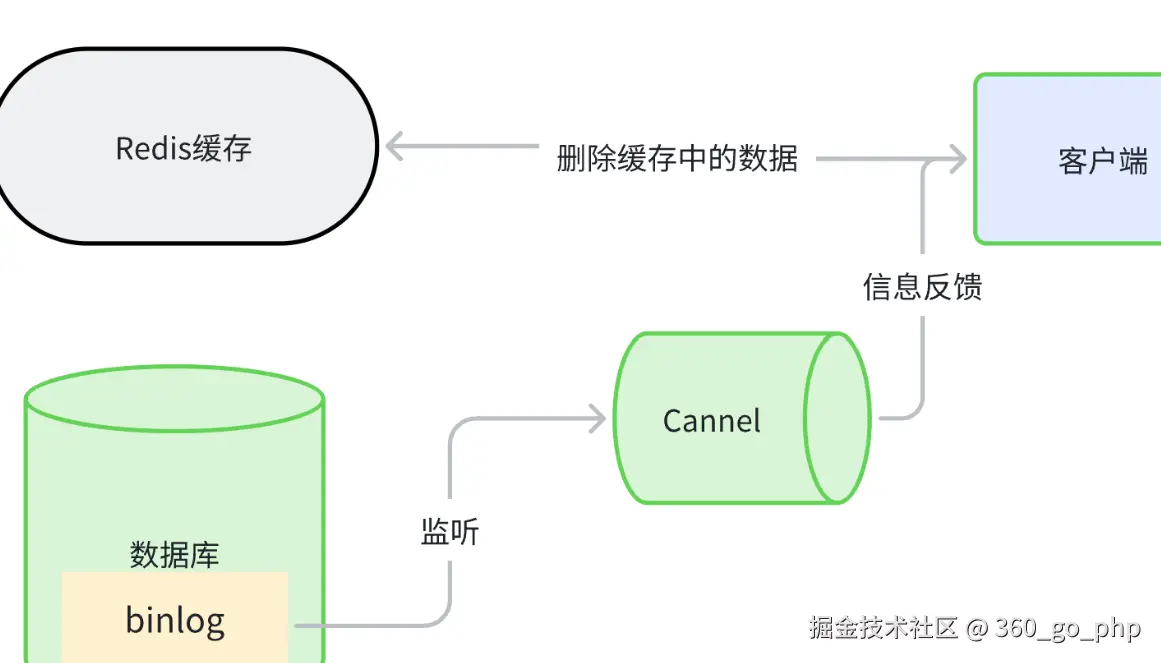 编辑
编辑
15. 给我讲一下 GC 的所有垃圾回收器
JVM 的 GC 分为两类:
- 年轻代回收器:Serial、ParNew、Parallel Scavenge
- 老年代回收器:Serial Old、Parallel Old、CMS、G1
不同回收器侧重点不同:
- Serial 单线程简单高效,适合小内存。
- Parallel GC 注重吞吐量。
- CMS 注重低延迟。
- G1 综合性能最佳,支持分区化内存管理。
16. G1 是什么版本出来的?
G1(Garbage First) 垃圾回收器是在 JDK 7u4 正式引入,在 JDK 9 中成为默认 GC。
17. 给我讲讲 Redis 的五大结构底层结构(尤其是跳跃表) 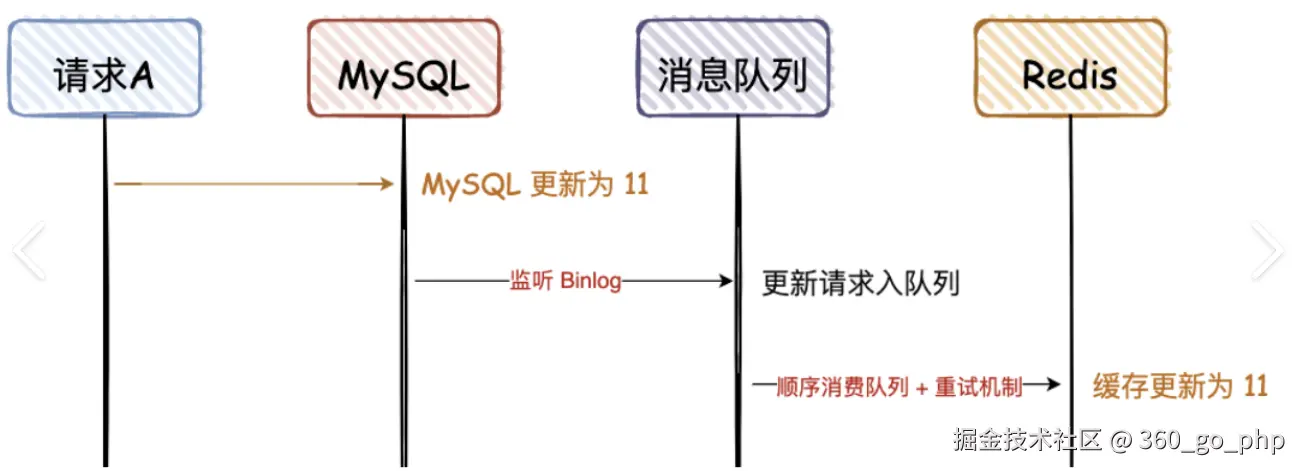 编辑
编辑
Redis 的五大数据结构与底层实现:
- String:SDS(简单动态字符串)
- List:双向链表或压缩列表(QuickList)
- Hash:哈希表 + 压缩列表
- Set:整数集合或哈希表
- ZSet(有序集合) :跳跃表(SkipList)+ 哈希表
其中跳跃表是一种平衡数据结构,通过多层索引实现 O(log n) 查找效率,既简洁又高效。 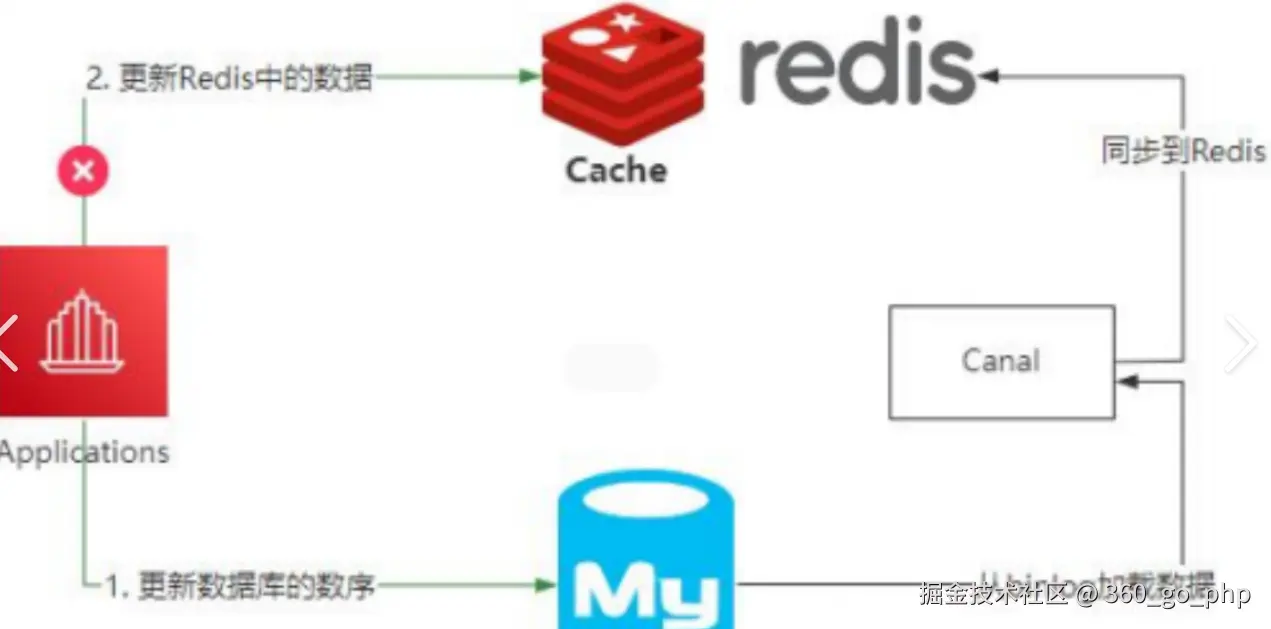 编辑
编辑
✅ 总结
这个项目让我真正理解了微服务架构、分布式通信、缓存优化、消息解耦等核心技术,也锻炼了独立解决复杂问题的能力。从零搭建到部署上线,是一次真正意义上的成长过程。