大家好,我是大头,职高毕业,现在大厂资深开发,前上市公司架构师,管理过10人团队! 我将持续分享成体系的知识以及我自身的转码经验、面试经验、架构技术分享、AI技术分享等! 愿景是带领更多人完成破局、打破信息差!我自身知道走到现在是如何艰难,因此让以后的人少走弯路! 无论你是统本CS专业出身、专科出身、还是我和一样职高毕业等。都可以跟着我学习,一起成长!一起涨工资挣钱!
MySQL零基础教程
本教程为零基础教程,零基础小白也可以直接学习。 基础篇和应用篇已经更新完成。 接下来是原理篇,原理篇的内容大致如下图所示。
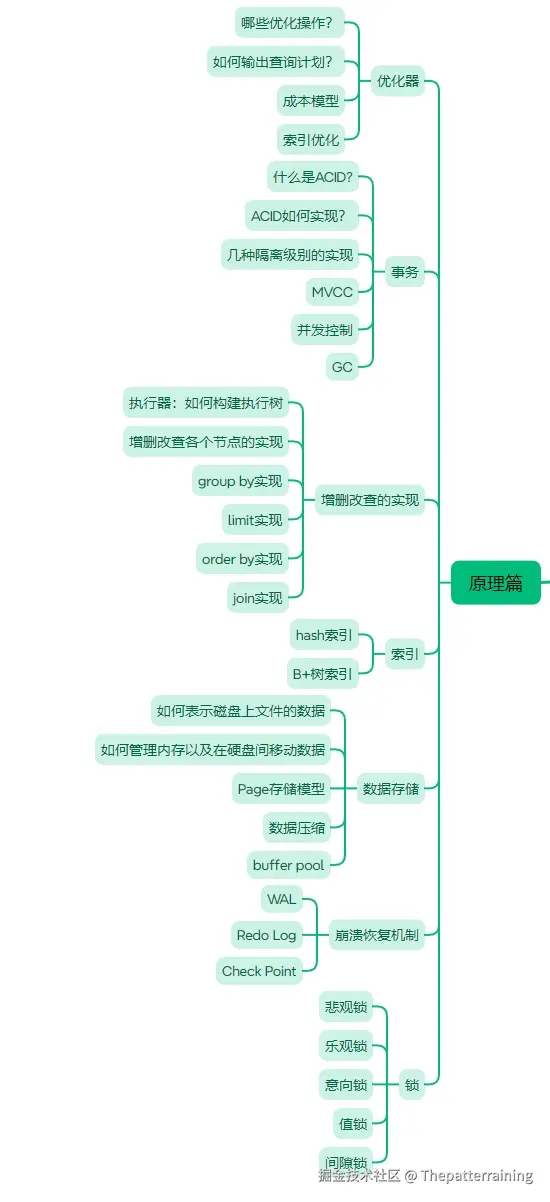
零基础MySQL教程原理篇之SQL数据存储
我们知道数据库只是管理数据的,数据最终存储在磁盘上还是一些文件,那么这些文件是如何存储的呢?文件内容是什么?加载到内存以后,内存布局是什么样的?老说page,page是什么?
page(页)
页的三个概念
- 硬件上的页面(通常是4KB)
- 操作系统上的页面(4KB,x64 2MB/1GB)
- 数据库页面(512B-32KB)
磁盘和内存通信是一页一页的,如果数据都在一页里,后续的访问请求就可以走内存了,要不然还的从磁盘获取。内存中可以获取bit数据。
这样做的好处就是加快获取速度,对于MySQL中的一张表来说,相邻的10行数据通常都在一页里,因此我们只产生一次IO,就可以获取到10行数据。
流程:
- 查询执行器:向内存中的
buffer pool请求查询内容。 - buffer pool: 如果数据所在的页已经在buffer pool中,就直接返回。如果数据所在的页不在buffer pool中,就向磁盘中的
database file请求。 - database file: 有页目录,还有具体的页,数据存在页中,查询页目录找到对应的页返回给
buffer pool。
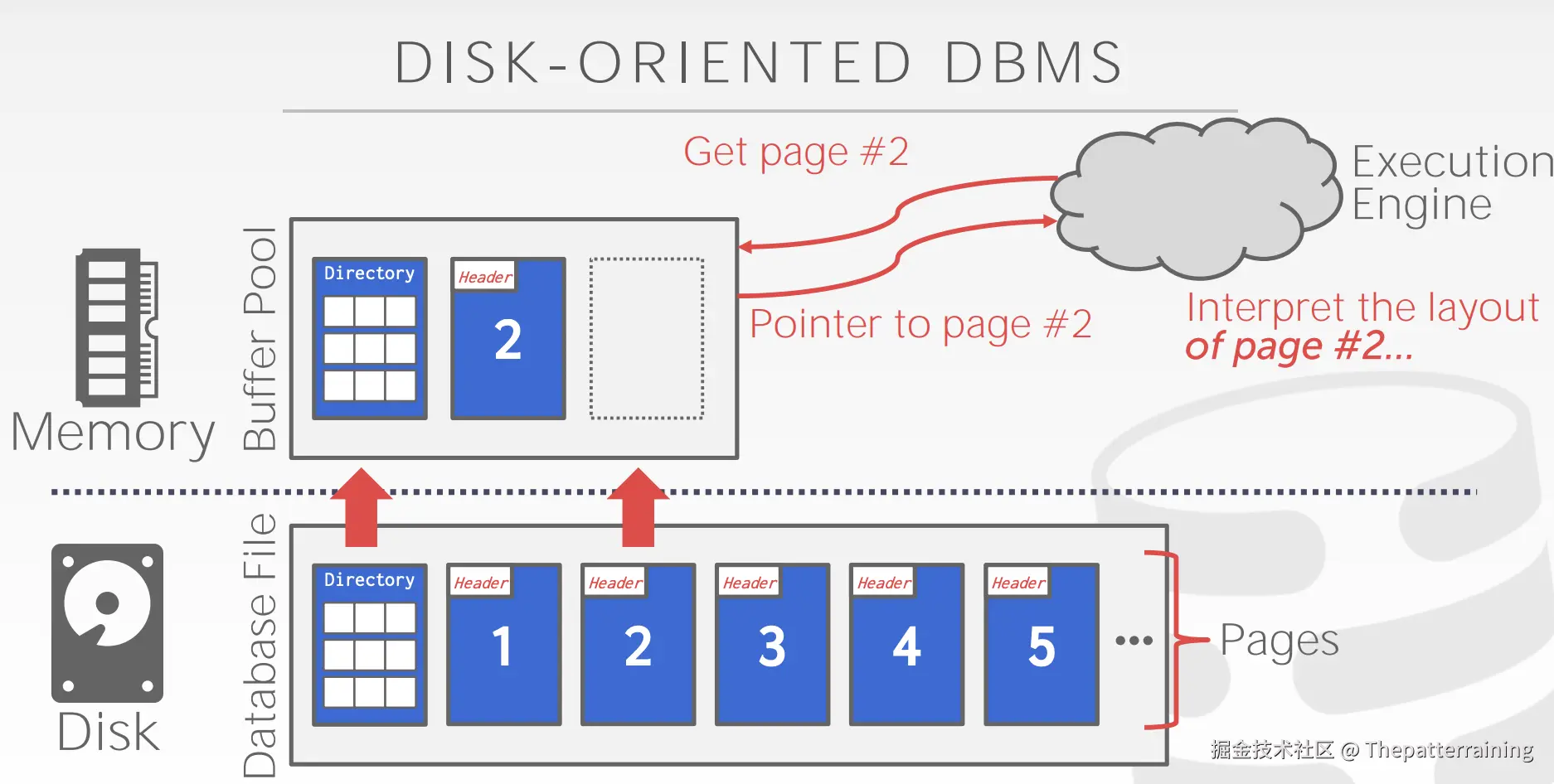
上面的步骤操作系统本身就可以实现,比如使用mmap,但是操作系统是统一的动作,遇到一些问题不知道该如何处理,而DBMS则可以根据不同的情况做不同的处理,进行优化。像主流的mysql,SqlServer,Oracle都没有用mmap。mongoDB早期使用的mmap,后面也是用WiredTiger替换掉了mmap。
MySQL自己实现的话,主要关心的两个问题:
- 如何表示磁盘上文件的数据
- 如何管理内存以及在硬盘间移动数据
如何表示磁盘上文件的数据
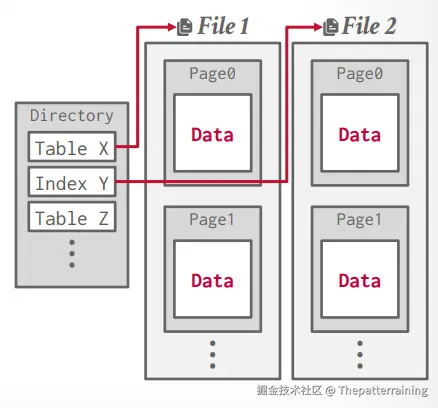
数据库的数据最终以文件的形式放在磁盘中。通过文件读写将数据读写到文件中。文件有特定的格式,具体的内容有数据库进行解析然后展示在数据库中。这就是storage manager or storage engine。或者换一个名字,大家就知道了,就是存储引擎。例如InnoDB或者Myisam。
storage manager负责文件的读写工作。所有的文件(不管是一个或者多个)以 page 的形式存储,管理多个 page 组成的集合。
一个page就是一个固定大小的数据块。page 可以保存任何东西,tupe(表中的一行数据), metadata(表的元数据), indexes(索引), log等等。每个page有唯一的ID,是page ID。
有些page要求是独立的,自包含的(self-contained)。比如mysql的InnoDB。因为这样的话一个表的元数据和本身的数据内容在一起,如果发生问题的话,可以找回元数据和数据。如果元数据和数据在不同的page中,如果发生问题导致元数据的page丢失,那么数据则恢复不了了。
indirection layer记录page ID的相对位置,方便找到对应的偏移量。这样page目录就能找到对应的page。
不同的DBMS对于文件在磁盘上的存储方式不一样,有下面几种
- 堆存储
- 树存储
- 有序文件存储(ISAM)
- hashing文件存储
我们这里主要介绍堆存储
堆存储
- 无序的,保存的顺序和存储的顺序无关。
- 需要读写page
- 遍历所有的page
- 需要元数据记录哪些是空闲的page,哪些是已经使用的page。
- 使用
page directory方式来记录文件位置。
page directory
- 存储page ID和所在位置的关系
- 存储page的空闲空间信息
page header(页的元数据)
- page 大小
- checksum 校验和
- DBMS版本信息
- 事务可见性
- 压缩信息
页布局
面向元组的存储
一般想法,直接存储,并在后面追加,比如存储张三的用户信息,然后紧跟着后面存储李四的用户信息,这就像我们平时写txt文件一样,不断追加。但是对于可变数据长度很难管理。
- 记录page数,也就是page内部可插入的偏移量
- 一个一个tupe按照顺序存储

所以,page内部,通常不使用上面那种,而使用的是slotted pages(插槽布局)
- slotted pages
- slot array 存储插槽信息的偏移量,通过他找到对应的tuple
- 支持可变长度的
tuple - 但是会产生一些碎片空间,因为太小,tuple放不下。
- 压缩可以去除碎片空间,但是压缩的时候这个page就不能读写了。
slotted pages的样式如下,通过这样的改造,我们就可以支持可变长度的管理了。
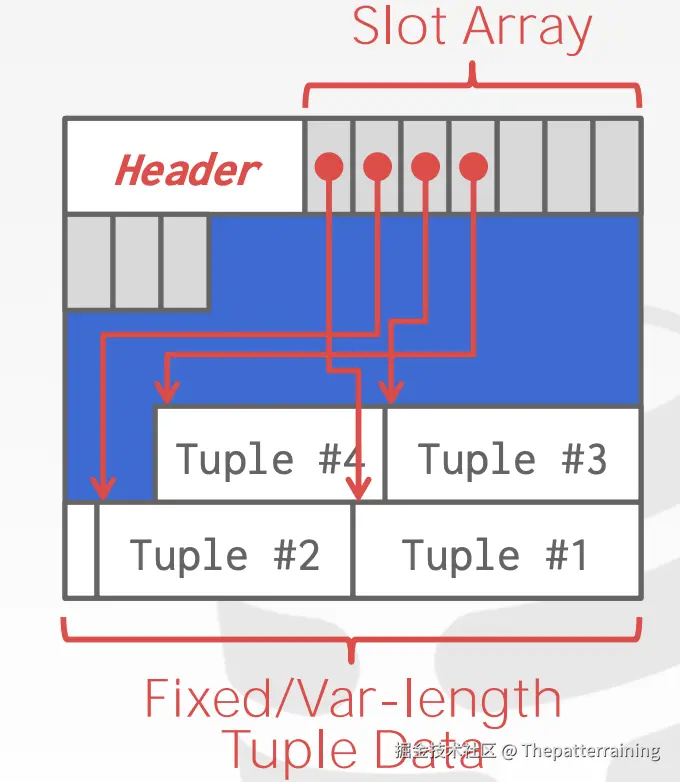
record ID表示一个tuple的物理位置,不同的DBMS有不同的名称,来表示数据的唯一位置,比如postgresql的ctid,oracle的rowid。ctid由page id和slot number组成。

这里要注意一点,record ID并不是我们表里的主键ID,主键ID代表一行数据的唯一标识,而record ID表示的是这一行数据存储的物理位置,这是两个东西。在MySQL中,record ID是不可见的。
接下来,看一下增删改查的操作。
插入新的tuple的时候,也就是执行insert语句的时候。
- 检查
page direactory,找到一个page里面有空的可用的slot(插槽位置) - 如果该page不在内存,就从磁盘上获取它,将它加载到内存,这需要一次读IO
- 在page里面检查slot array,找到一个空的空间,将tuple插入
更新tuple的时候
- 检查page direactory,找到tuple对应的page
- 如果该page不在内存,就从磁盘上获取它,将它加载到内存
- 在page里面通过
slot array获取tuple的偏移量 - 如果数据空间合适,那么直接覆盖该tuple,否则,将原来的tuple标记为
已删除,并将新tuple插入其他page。
因此更新的时候有一些问题
- page会产生碎片空间,如果有一个空闲空间是1KB的,但是每次插入的数据都放不下,那么这1KB空间就一直都没办法使用了。
- 更新的时候需要从磁盘获取整个page,也就是说,哪怕你就更新一行数据,他也会读取一页数据出来。
- 更新多条数据的时候,可能多个tuple在多个page中,产生随机IO,如果你更新的数据不在一起,就会产生多次IO加载多个page。
所以有些DBMS不能更新数据,只能增加数据,比如HDFS等
MySQL使用的就是面向元组的存储,除了这个,其实还有日志结构化存储和面向索引的存储。
行布局
tuple就是一行数据,也就是一堆bit,DBMS解释他们的作用。里面包含
- header
- data
首先看看行数据是怎么表示的
数据布局
假设我们有一个数据表foo,有id和value字段如下:
- id int类型 primary key
- value bigint类型
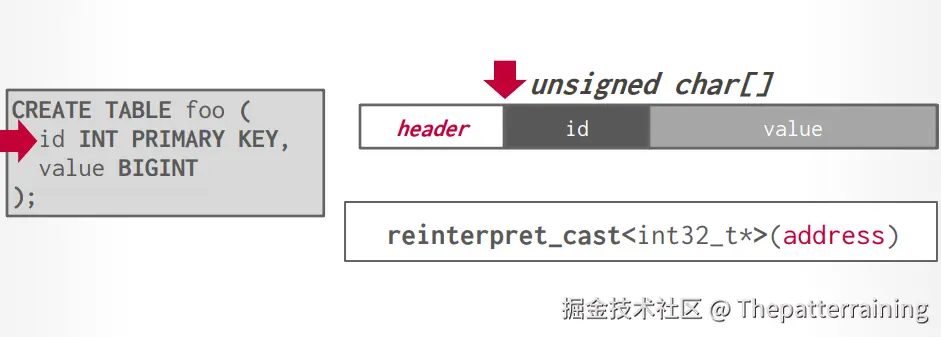
我们每一行的数据和上面的图一样,最前面是这一行的header,然后就是一些字段了,比如id、value,然后后面在跟着下一行数据的header,以此类推。
数据对齐
现代CPU是64位对齐,创建表以后,DBMS会自动的将数据进行对齐存储,不过,如果在创建表的时候考虑对齐,可以优化速度和存储空间。
数据对齐是可以直接对MySQL起到优化作用的,尤其是数据量大的时候,但是很多人都忽视了这一点,比如同样一行数据,如果有4个字段,分别是32位的id,64位的cdate,16位的color和32位的zipcode
那么占用空间如下:
- id: 32位,但是会占用64位,因为下一个是64位,所以会插入一个32位的空白进行64位对齐
- cdate: 64位
- zipcode:32位,但是会占用64位因为要64位对齐
上面的实际占用空间达到了 64 + 64 + 64 = 192位空间
而如果我们稍微改变一下顺序呢?
- id: 32位
- zipcode:32位
- cdate:64位
这样以来,我们就只占用了 64 + 64 = 128位空间,节省了64位空间,在数据量大的情况下,就意味着一页可以放更多的行数据,因此查询的IO次数就会减少。
数据表示
可变长度的数据varchar,varbinary,text,blob,他们的长度存在header里面。
日期时间类型存储的是时间戳。
float/real/double: 是浮点数,cpu支持浮点数运算,优点是速度快,但是会精度缺失 decimal: 是定点数,运算速度慢,但是精度高。
对于一些很大的数据,比如text,blob,应该避免使用这种类型,有可能一行就占用了一半的page空间,因此,不会在page里直接存储这些数据,而是采用了overflow page的方式。
- tuple中存储另外一个page页的指针,将具体数据存放到另外一个page页中。
- postgresql中叫
toast,如果数据大于2KB,就会放到toast中,tuple中只存储指针。 - mysql中叫
overflow page,如果数据大于1/2的page大小,就会放进去,tuple中只存储指针。
我们应该避免使用这些类型,因为维护overflow page很麻烦。
外部存储
- tuple中存储指向外部文件的指针或者文件地址。
NULL存储
- 行数据库通常是在Header里面增加bit map来判断是否是null
- 列数据库通常使用占位符来标识NULL
- 在每个属性前面增加bit来标识是否是NULL,这么做会破坏对齐,或增加存储空间,MySQL曾使用这个方法,后来抛弃了这个方法。
- NULL == NULL 是 NULL, NULL is NULL 是 true
所以大家知道为什么 NULL != NULL 了吗?
catalogs 用来存储数据库元信息,大多数数据库将这些信息存到一张表里面,下面的都是元数据。
- 表,字段,索引,视图等
- 用户,权限,安全等
- 内部数据统计等
infomation schemal api通过这个来获取catalogs信息- mysql
- show tables 获取所有的表
- describe table_name 获取表的信息
- postgresql
- \d or \d+ 获取所有的表
- \d table_name 获取表信息
- mysql
数据库压缩
目标1:必须产生固定长度的值 目标2:在查询期间尽可能推迟解压缩,你不希望先解压缩在查询,这样很占空间且影响速度 目标3:必须是无损方案
压缩粒度
- Block-level: 压缩同一张表的tuple
- Tuple-level: 压缩整个tuple的内容(仅限行存储)
- Attribute-level:压缩同一个tuple的多个属性或单个属性
- Column-level:压缩存储于多个tuple中的一个或多个属性的多个值(仅限列存储)
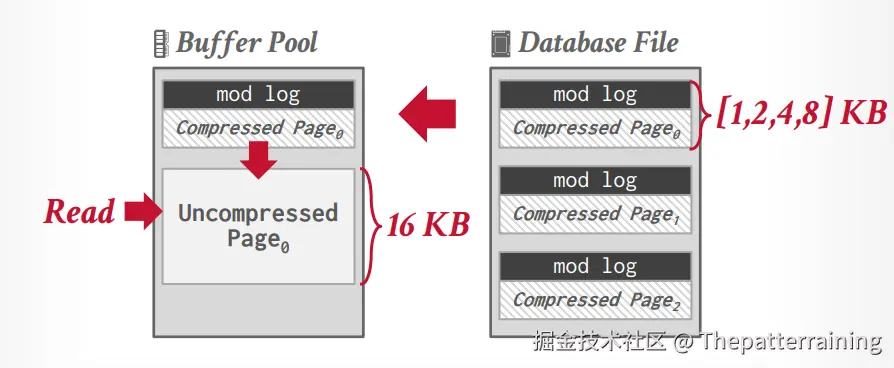
mysql innodb 压缩
innodb 在写入的时候可以不解压,但是读取的时候会先在buffer pool中解压在读取。因此Mysql innodb的压缩的好处是提升空间利用率,减少了磁盘IO,缺点是读取的时候需要解压,因此增加了这部分的时间和CPU功耗以及解压以后会占用更多的内存空间。 innodb 默认page 是 16KB,可以压缩到1/2/4/8KB。
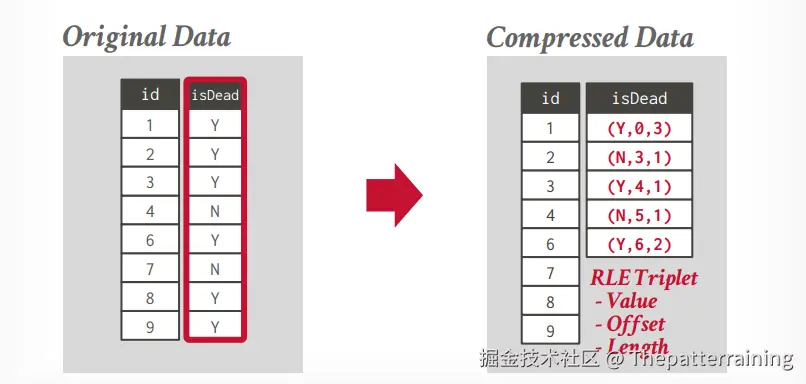
Column-level 压缩算法
run length encoding
将单个column中的相同值压缩成三元组,需要对列进行智能排序,以最大限度地提高压缩机会。
- 属性的值
- column segment的起始位置
- 值的数量
比如下面的数据,将压缩成右边的数据,(Y,0,3),代表值是Y,起始位置0,值的数量有3个。后面的压缩数据是一样的。这种压缩方法可以快速计算count的数量等。
如果你的值类型很少,且有序,那么将大大减少空间占用。
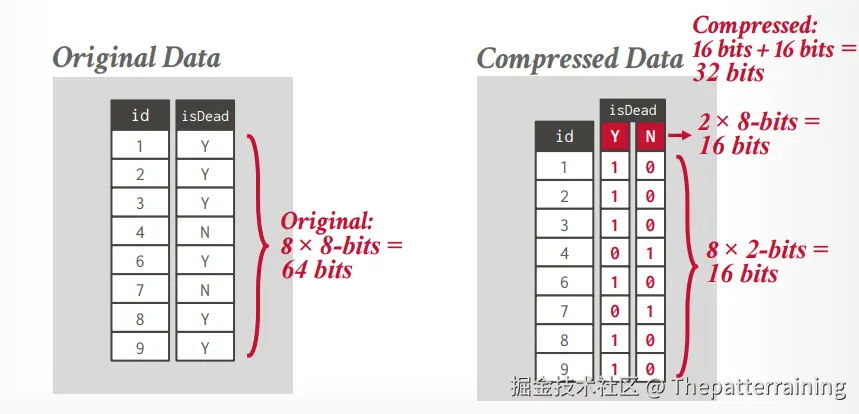
bit packing
如果字段里面的值都比较小,但是column type很大,可以忽略掉不需要的bit,比如int是32 bit,但是里面的值都很小,用不了这么多,就可以忽略他们。

bit map encoding
使用bit map来标识数据值,仅仅适用于值的类型比较少的。
delta encoding
找到一个基本的数据,以它为基础,进行压缩,+1,-1这种。再将其按照run length encoding的方式压缩,可以再次节省空间。
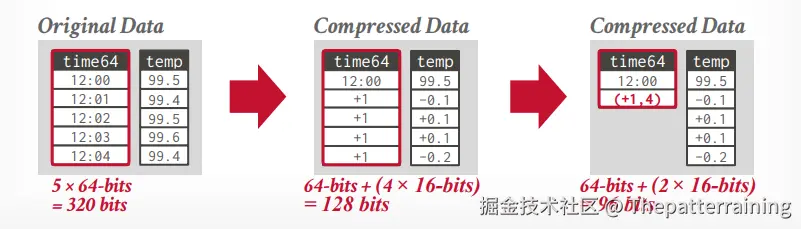
DICTIONARY COMPRESSION
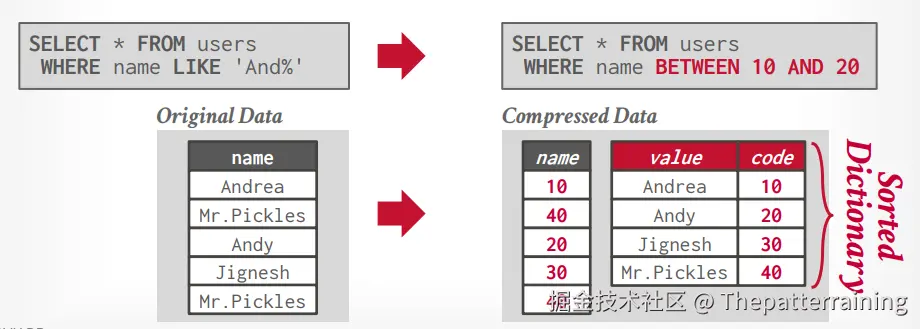
按照字典将数据进行映射,并存储,这样可以节省空间,如果在字典映射的时候还能先排序,那么还可以完成将where like 'and%'转成where between 10 and 20。
结论
本次讲解了数据库是如何存储数据的,数据布局是什么样子的,更是讲解了一些优化方法,比如数据压缩、数据对齐。如果你不理解原理的话,面试的时候你就只能背八股答出来网上千篇一律的回答了。