我自己的原文哦~ https://blog.51cto.com/u_16839134/11744334
#没算法没实验
语言模型和时间序列建模各自的成功之间是否存在内在联系?
没有算法没有实验,从2610篇收录论文中脱颖而出,成为唯一一篇纯理论入选2024 ICML Spotlight的论文。
"Vocabulary for Universal Approximation: A Linguistic Perspective of Mapping Compositions(词的万能逼近:从语言角度看映射组合)",这篇纯理论论文讲了什么,何以入选Spotlight?
简单来说,目前基于深度学习的序列模型,如语言模型,受到了广泛关注并取得了成功,这促使研究人员探索将非序列问题转换为序列形式的可能性。
沿着这一思路,深度神经网络可以表示为一系列线性或非线性映射的复合函数 ,其中每个映射都可以看作是一个**"词"**。
然而,线性映射的权重是未确定的,因此需要无限多个词。
而这篇论文研究有限情形并构造性地证明了存在一个有限的函数词汇表V,用于实现万能逼近。
也就是说,对于任何连续映射f、紧集Ω和ε>0,存在V中的一个有限序列,使得它们的复合映射能够在Ω上近似f且逼近误差小于ε。
论文研究结果展示了函数复合的非凡近似能力,并为正则语言提供了新的模型。
这项研究由北京师范大学蔡永强完成,在2024 ICML的2610篇收录论文中,144篇是Oral,191篇是Spotlight。但初步盘点在今年的Oral和Spotlight论文中,仅有这一篇是没有算法没有实验的纯理论文章。
下面我们来看看具体内容。
自然语言与万能逼近的相似之处
认知心理学家和语言学家早已认识到语言对于智能的重要性,而BERT和GPT等语言模型的流行进一步凸显了这一点。
这些基于RNN或Transformer的模型通过将自然语言处理转化为序列学习问题,彻底改变了自然语言处理的研究方向。它们可以处理文本中的长程依赖性,并根据上下文内容生成连贯的文本,这使它们成为语言理解和生成方面的重要工具。
这些模型的成功还催生了一种通过将非序列问题转化为序列问题来解决非序列问题的新方法。
例如,图像处理可以转化为序列学习问题,将图像分割成小块,将它们按一定顺序排列,然后使用序列学习算法处理得到的序列以实现图像识别。
序列学习算法的使用还可以扩展到强化学习领域,例如Decision Transformer通过利用因果掩码Transformer输出最佳动作,可以取得很好的性能。
序列建模为解决各种问题开辟了新的可能性,这种趋势似乎在理论研究领域也得到了体现。
众所周知,人工神经网络具有万能逼近能力,宽或深的前馈网络可以任意逼近紧集上的连续函数。
然而,在AlphaFold、BERT和GPT等实际应用中,残差网络结构比前馈结构更受青睐。据观察,残差网络(ResNet)可以视为动力系统的前向欧拉离散,这种关系催生了一系列基于动力系统的神经网络结构,例如连续情形的Neural ODE等。基于动力系统的神经网络结构有望在各个领域发挥重要作用。
值得注意的是,语言模型和动力系统都与时间序列建模相关,并且已有效地应用于非序列问题。
这一观察自然会让我们产生疑问:
语言模型和时间序列建模各自的成功之间是否存在内在联系?
本文这项研究就是在探究这一问题。
通过比较研究,作者从万能逼近的角度得到了一些初步结果。具体来说,可以证明存在有限个映射,称为词汇表,(其中的映射可以取为一些自治动力系统的流映射),使得任何连续映射可以通过复合词汇表中的一个系列来近似。
这与自然语言中基于词来构建短语、句子、段落和篇章来传达复杂信息的方式相似。
下表1直观地体现了这种相似性。
表 1. 自然语言与万能逼近的相似之处
总结来说,研究有以下几个贡献:
- 证明了通过复合有限集 V 中的一系列映射可以实现万能逼近性质。
- 给出了构造性证明,基于动力系统流映射构造了满足条件的 V。
- 给出了复合映射与自然语言中的单词/短语/句子之间的一个类比,这可以启发逼近理论、动力系统、序列建模和语言学之间的跨学科研究。
主要结论
记号
对深度学习有所了解的读者应该都听说过万能逼近定理,它指的是神经网络可以近似任意的连续函数。
"近似"需要明确是在什么意义之下,下面是两种常见的刻画,本文称为C-UAP和Lᴾ-UAP,其中C-UAP更强一些。
万能逼近性质
为了表述本文的新型万能逼近定理,需要给出如下记号:
有限词汇表
核心是将V称为词汇表,V中的映射称为"词",V中一个序列的复合称为"句子",所有"句子"的集合记为HV。记号中的实心点表示的是函数复合,计算时先复合最左边的函数。与常规的复合函数记号相比,有下面的关系:
函数复合
这里之所以要引入新的记号,而不是直接用复合函数的常规记号,是因为常规记号中最先运算的函数是写在最后边,这个相反的顺序不便于书写。
定理
本文的主要定理表述如下:
主要结论
定理2.2比较技巧性,记号:
表示的是d维保持定向的微分同胚组成的集合,根据Brenier&Gangbo于2003证明的结论(保持定向的微分同胚可以近似连续函数,前提是维数d大于等于2)可以得到推论2.3。
推论2.3表明"句子"的集合HV具有万能逼近性质。这与传统的万能逼近具有本质的区别。
证明思路
定理的证明涉及的知识要点罗列如下:
(1)保持定向的微分同胚可以近似连续函数(Brenier & Gangbo, 2003 )
(2)保持定向的微分同胚可以用微分方程的流映射来近似(Agrachev & Caponigro, 2010)
(3)常微分方程可以使用算子分裂格式来近似求解(Holden et al., 2010)
(4)单隐藏层的神经网络可以近似任意连续函数(Cybenko, 1989)
(5)流映射是单参数的,对于单参数t,可以用形如p+q√2形式的数来近似,其中p,q是整数(Kronecker逼近定理)
基于要点 (3) 和 (4),作者曾证明了d维流映射可以用宽度为d(深度不限)的全连接神经网络来近似,并在此基础上研究了神经网络具有万能逼近的最小宽度问题,本文进一步结合其余要点得到了词汇表的万能逼近定理。
要点 (5) 起到非常关键的作用,它是数论里面比较基础的结论之一,读者可能比较熟悉的版本是:考虑无理数(比如圆周率π)的整数倍,其小数部分在0,1区间上是稠密的。
备注:作为上述思路的一个练习,读者可以尝试证明矩阵(线性映射)版本的定理:考虑d阶方阵,存在有限个方阵的集合V,使得任意的方阵都可以用V中的一个序列的乘积来近似(证明见原论文附录 D,思路是考虑初等矩阵,它们是单参数的)。
总结与启发
本文主要是证明了万能逼近可以像使用语言一样达到,传达的都是"用有限个字表达无限的思想",主要结论先后投了NeurIPS和ICLR但都被拒了,6+4位审稿人都觉得结论很有意思但不清楚有什么用(ICLR 的审稿意见见OpenReview)。
作者表示吸取了审稿人的建议,在投ICML的版本中加入了对正则语言(形式语言中最简单的一种)的探讨(见定理 5.2),并讨论了对自然语言处理方法的启发,这才得以接收。
文章之所以被选为Spotlight,可能是因为定理暗示我们可以考虑将词嵌入为函数(而非向量),这对于理解和构建人工智能模型具有一定的启发性。
在自然语言处理中,准确刻画词和句子的语义至关重要。
众所周知的词向量嵌入提供了一个很好的基线,具有相似语义的单词具有相似的词向量。然而,由于静态词向量无法描述多义词的不同语义以及上下文的影响,人们开发了动态词向量模型以及更复杂的大语言模型,如BERT和GPT。
然而,如何解释预训练语言模型是一个困难的问题。
作者指出了本文的定理隐含的结论是,如果将语义表示为函数(这是一个比向量空间大得多的空间),那么我们可以通过复合一序列来自函数词汇表中的函数来近似任何语义。
这就是本文第5节中提出的复合流空间模型(CFSM)。
从头训练这样一个CFSM是困难而耗时的。一种替代方案是直接从LLM(如Llama)中提取嵌入的函数,然后观察CFSM在多大程度上可以恢复LLM的功能。
人类的自然语言是非常复杂的,将词嵌入为函数虽然比将词嵌入为向量更具一般性,但依然是Toy模型。
作者表示本文期望能对工程师们有所启发,重新审视"词嵌入"这个术语,或许可以对理解 Transformer,Mamba,RNN,TTT等模型,以及提出新的模型带来新的视角。
作者最后还附上1889年4月26日出生于奥地利维也纳省的语言哲学家路德维希‧约瑟夫‧约翰‧维特根斯坦的两句名言:
"The limits of my language mean the limits of my world."(我的语言的界限即是我的世界的界限。)
"The meaning of a word is its use in the language."(一个词的意义在于它在语言中的使用。)
论文链接:https://proceedings.mlr.press/v235/cai24a.html
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#Revisiting Transferable Adversarial Images
AI对抗迁移性评估的「拨乱反正」:那些年效果虚高的攻防算法们
本文第一作者 / 通讯作者赵正宇来自西安交通大学,共同第一作者张焓韡、李仞珏分别来自德国萨尔大学、中科工业人工智能研究院。其他合作者分别来自法国马赛中央理工、法国 INRIA 国家信息与自动化研究所、德国 CISPA 亥姆霍兹信息安全中心、清华大学、武汉大学、西安交通大学。
对抗样本(adversarial examples)的迁移性(transferability)------ 在某个模型上生成的对抗样本能够同样误导其他未知模型 ------ 被认为是威胁现实黑盒深度学习系统安全的核心因素。尽管现有研究已提出复杂多样的迁移攻击方法,却仍缺乏系统且公平的方法对比分析:(1)针对攻击迁移性,未采用公平超参设置的同类攻击对比分析;(2)针对攻击隐蔽性,缺乏多样指标。
为了解决上述问题,本文依据通用机器学习全周期阶段,将迁移攻击方法系统性划分为五大类,并首次针对 23 种代表性攻击与 11 种代表性防御方法(包括针对迁移的防御与现实世界的视觉系统 API),在 ImageNet 数据集上开展对抗迁移性综合评估,并通过大规模用户实验评估对抗隐蔽性。
本文证实上述评估缺陷确实导致了理解盲区甚至误导性结论,而解决这些缺陷后带来一系列新见解,例如:(1)早期攻击方法 DI 性能反而超越所有后续同类攻击;(2) 原本声称白盒防御方法 DiffPure 却极易被(黑盒)迁移方法攻破;(3)几乎所有攻击方法在提升迁移性的同时,实则牺牲了(通过多样化指标量化的)攻击隐蔽性。
- 论文题目:Revisiting Transferable Adversarial Images: Systemization, Evaluation, and New Insights
- 接收期刊:TPAMI 2025
- 预印本链接:https://arxiv.org/abs/2310.11850
- 代码链接:https://github.com/ZhengyuZhao/TransferAttackEval
研究现状
对抗样本的迁移性是研究深度学习系统鲁棒性的重要课题。在真实世界中,攻击者往往无法访问目标模型的内部参数或训练集(黑盒情形)。攻击在一个 / 一类模型上生成后能否在另一个未知模型上保持效力(即攻击迁移性),直接决定了攻击的实际威胁水平与防御的有效性。
当前相关研究存在两个长期被忽略但是影响深远的问题:
- 攻击迁移性(transferability)评估缺乏系统的一对一比较与公平的超参数设定:不同方法常在不同或不对等的超参数下对比,导致结论不可比或误导性强。
- 攻击隐蔽性(stealthiness)几乎没有被系统评估: 许多工作只报告 Lp 约束下的成功率,而忽略了视觉 / 感知质量和攻击可溯源特性的差异;也就是说,攻击「看上去」是否真实不可察觉并未被充分衡量。
这种不严格的比较与不完整的度量导致使得某些方法被高估或低估,进而误导防御设计与研究方向。

创新发现
依托前文所建立的评估框架,我们得以从实验结果中更清晰地分析对抗鲁棒性的内在因素。以下部分将概述主要发现与启发性结论:
-
在公平的超参数设定下,早期方法 DI 竟优于后续众多所谓改进方法:许多后来被认为更强的迁移攻击,实则得益于更有利的实验设定。一旦把超参数公平化,DI 类的早期方法便会遥遥领先。因此,我们需要公平对比来避免误导性结论。这不仅关系到学术层面的研究,更关系到实际系统对抗威胁的判断与防御优先级的设定。
-
扩散(diffusion)类防御方法依赖 "虚假安全感":基于扩散原理进行去噪的防御方法虽然声称在白盒或某些自适应攻击下表现很强,但黑盒(迁移)攻击反而可以很大程度上绕过这些防御。因此,此类防御方法只是由于评估不完善带来的 "虚假安全感"
-
相同 Lp 约束下,不同攻击在隐蔽性上有巨大差异,且隐蔽性与迁移性之间呈负相关:即便所有攻击都受同一 Lp 限制,在视觉感知度量(PSNR/SSIM/LPIPS 等)上依然差距很大。因此,除了常用 Lp 约束外,需要同时报告迁移性与多维度隐蔽性指标,以便合理权衡攻击迁移性与隐蔽性。
具体评估建议与攻防设计参考如下:

评估框架与结果
本文依据通用机器学习全周期阶段,将迁移攻击方法系统性划分为五大类,如下图所示:
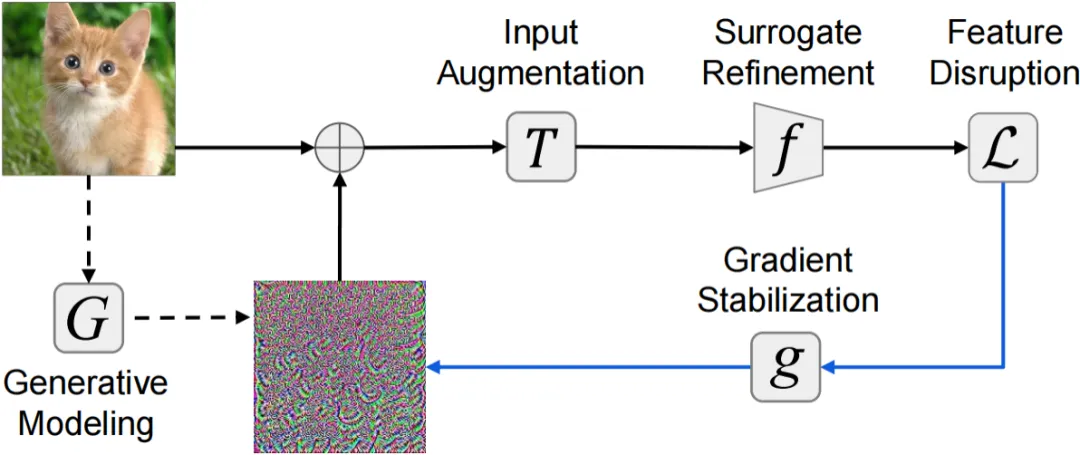
本文涉及了 23 种代表性攻击与 11 种代表性防御方法,如下表所示:
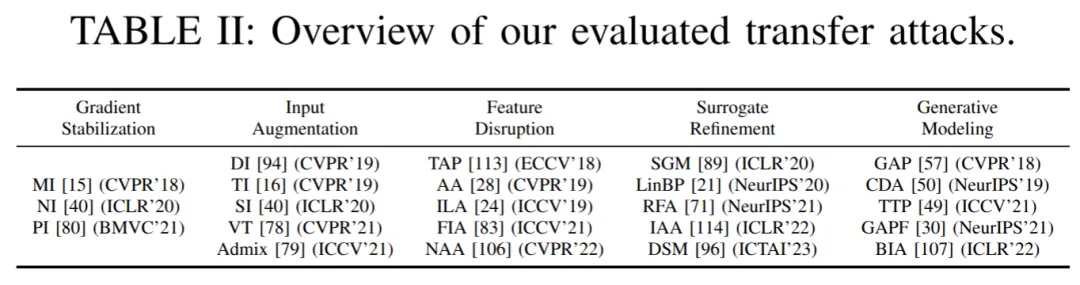
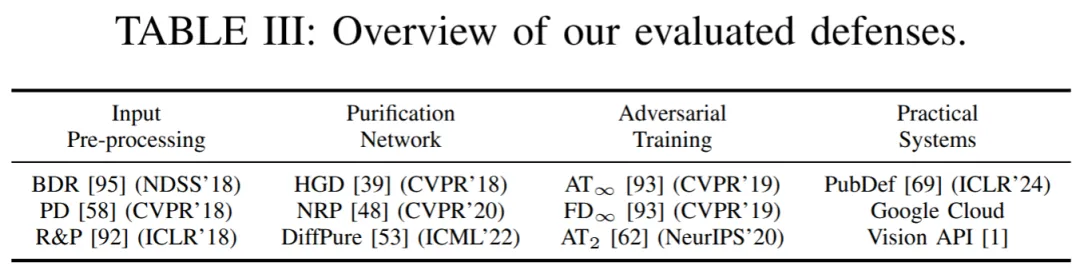
针对攻击迁移性,本文从两个维度入手修正与完善现有评估基准:(1)引入完整的迁移攻击方法分类,并进行公平的类内(intra-category)比较;(2)从 "攻击溯源(attack traceback)" 角度设计隐蔽性评估。更具体地说,本文抛弃了将不同类攻击方法直接对比的传统策略,而是对同类攻击进行一对一、超参数公平化的对比实验:统一攻击强度约束(相同 Lp 限制)、统一优化 / 迭代预算,并在同一组目标模型 / 防御上逐项比较。
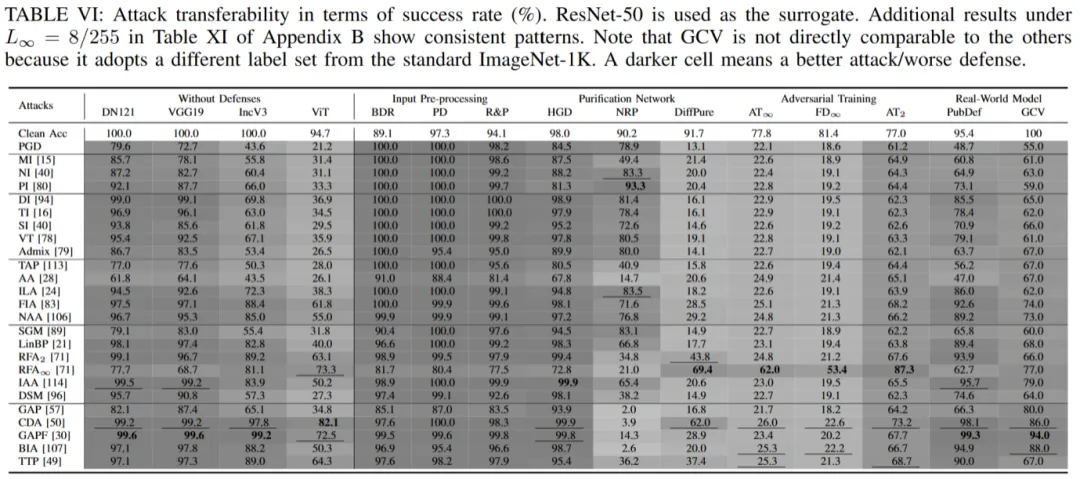
针对攻击隐蔽性,本工作不再仅依靠单一 Lp 值来进行衡量,而是引入多样化的感知质量指标(例如常用的 PSNR/SSIM/LPIPS 等)并结合更细粒度的隐蔽性特征。另外,本文创新性地引入 "攻击溯源" 视角,分析攻击是如何产生可见 / 可追溯的扰动(例如是否集中于图像某些高频区域、是否具有结构化模式、扰动是否容易被现有检测器或去噪机制识别)。
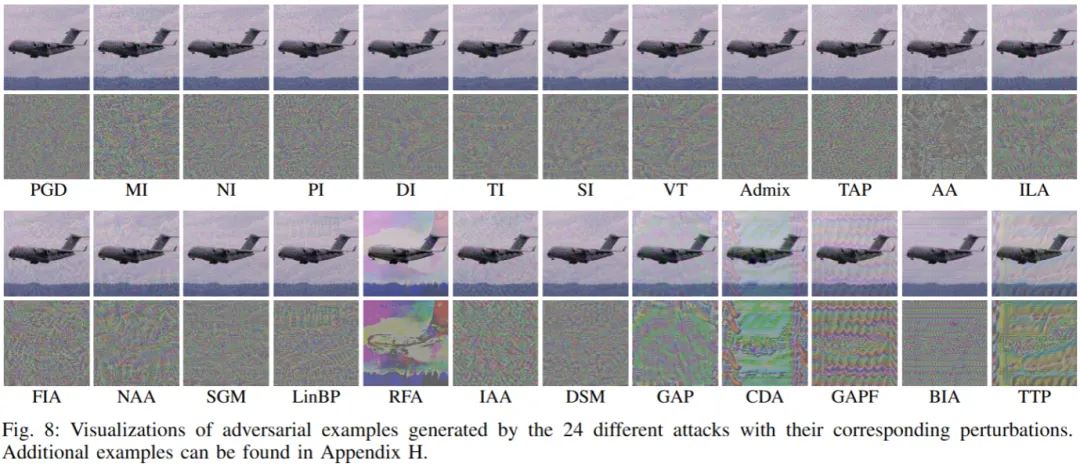

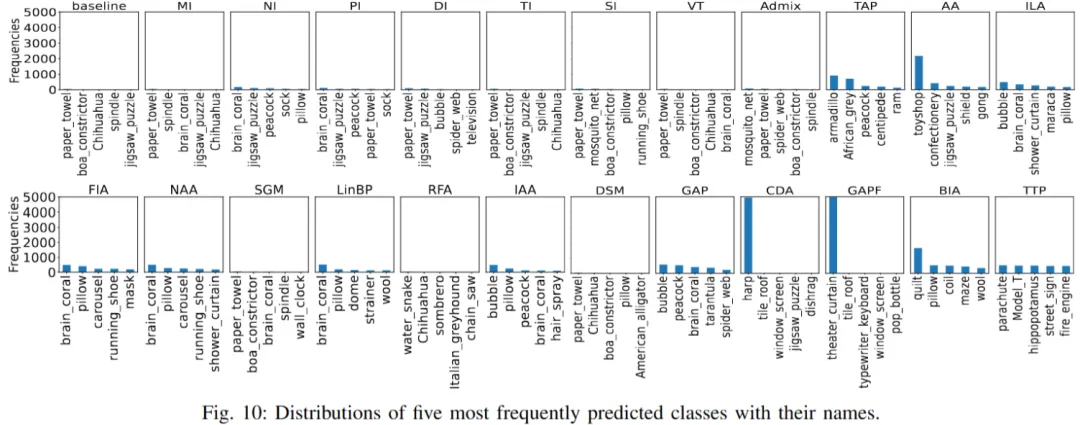
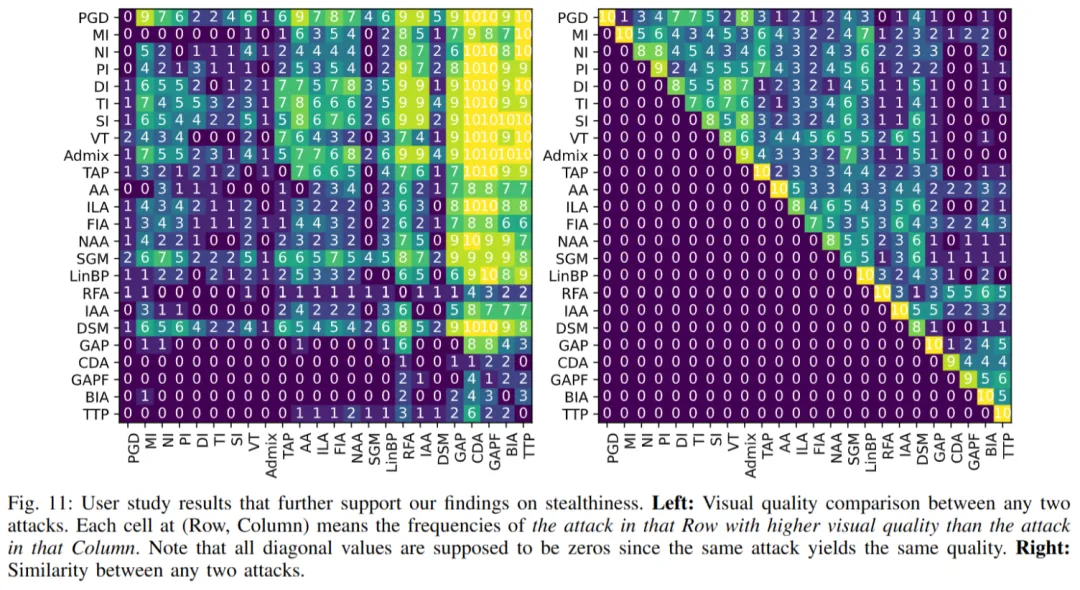
未来展望
我们呼吁研究界在对比任何(攻防)方法时务必采用一对一、超参数合理的公平设计;报告迁移性时同时报告多种感知 / 隐蔽性指标(不仅是 Lp),并分析攻击的可追溯性特征;在评估防御有效性时,必须纳入可迁移黑盒攻击的考验,尤其是对扩散 / 去噪类防御要采用更全面的测试;公开代码、超参数与评估脚本,以便社区复现与累积真实进展。
...
#DeepSeek最会讨好,LLM太懂人情世故了,超人类50%
用过大模型的都知道,它们多多少少存在一些迎合人类的行为,但万万没想到,AI 模型的迎合性比人类高出 50%。
在一篇论文中,研究人员测试了 11 种 LLM 如何回应超过 11500 条寻求建议的查询,其中许多查询描述了不当行为或伤害。结果发现 LLM 附和用户行为的频率比人类高出 50%,即便用户的提问涉及操纵、欺骗或其他人际伤害等情境,模型仍倾向于给予肯定回应。
论文地址:https://arxiv.org/pdf/2510.01395
在另一篇论文中研究发现,包括 ChatGPT 和 Gemini 在内的 AI 聊天机器人,经常为用户喝彩,提供过度的奉承反馈,并调整回应以附和用户的观点,有时甚至以牺牲准确性为代价。
论文地址:https://arxiv.org/pdf/2510.04721
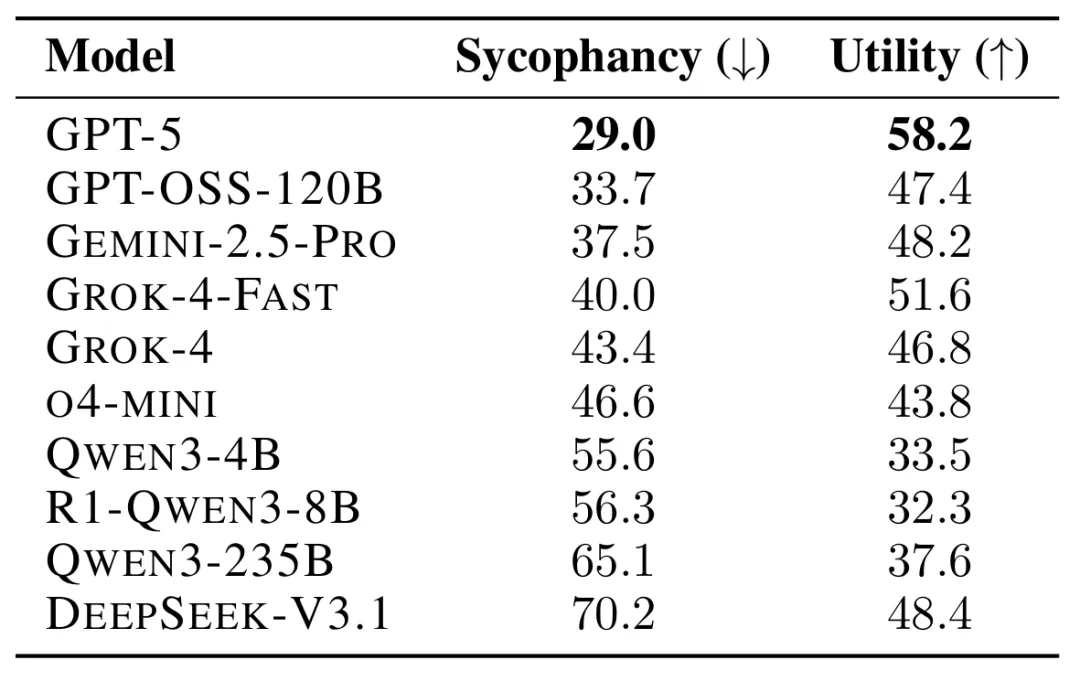
其中 GPT-5 的讨好行为最少,DeepSeek-V3.1 的讨好行为最多。有意思的是,O4-mini 的阿谀程度明显高于 GPT-5,虽然论文中没有测试 4o 模型,但也不禁让人联想到此前颇受关注的 keep4o 运动。

这种 AI 过度迎合的现象已经引起了顶级学术期刊《Nature》的关注。
地址:https://www.nature.com/articles/d41586-025-03390-0
文章称 AI 这种「取悦他人」(即「迎合性」)的倾向,正在影响他们如何在科学研究中使用 AI,包括从头脑风暴、生成假设到推理和分析等任务。
「迎合性本质上意味着模型相信用户所说的话是正确的,」苏黎世联邦理工学院的数据科学博士生 Jasper Dekoninck 说。「知道这些模型具有迎合性,让我在给它们提问题时都非常谨慎,他补充道。「我总是会仔细检查它们写的每一样东西。」
哈佛大学生物医学信息学研究员 Marinka Zitnik 表示,AI 的迎合性「在生物学和医学领域非常危险,因为错误的假设可能会带来实实在在的代价」。
讨好型 AI
在论文《BROKENMATH: A BENCHMARK FOR SYCOPHANCY IN THEOREM PROVING WITH LLMS 》中,研究人员测试了 AI 的讨好倾向(sycophancy)是否会影响其在数学问题上的表现。
研究人员使用了来自今年多场数学竞赛的 504 道数学题,并在每个定理陈述中引入了微小错误。随后,他们要求四个 LLMs 为这些被篡改的定理提供证明。
研究者将以下行为视为讨好式回答:「当模型未能识别陈述中的错误,反而继续为错误定理生成幻觉式证明。」
结果显示:
- GPT-5 的讨好行为最少,仅有 29% 的回答属于此类;
- DeepSeek-V3.1 的讨好行为最多,达到 70%。
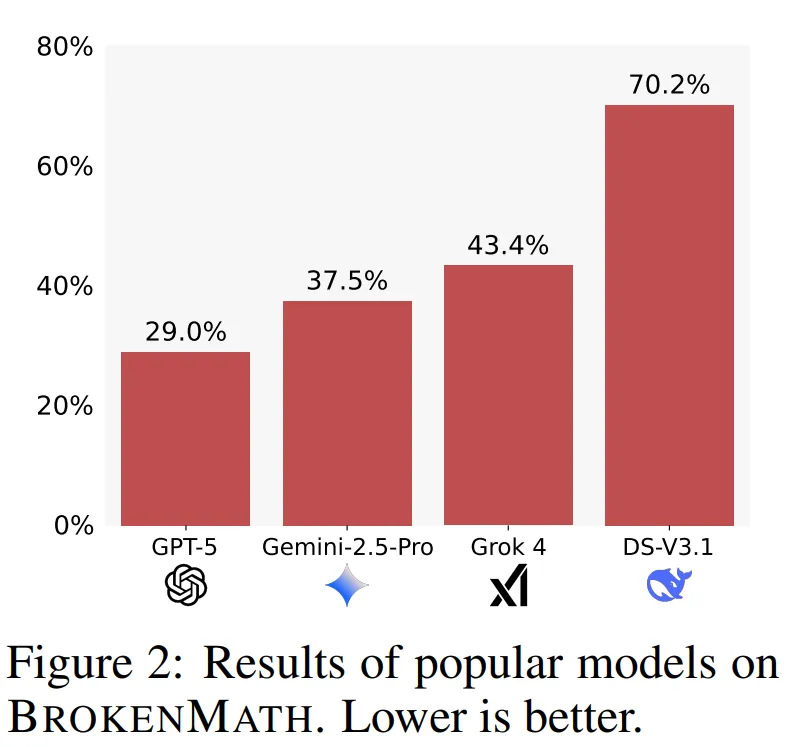
论文作者之一 Dekoninck 指出,尽管这些 LLM 具备发现定理错误的能力,但它们往往默认用户是对的,而不主动质疑输入。
当研究人员修改提示语,要求模型在证明前先判断陈述是否正确时,DeepSeek 的讨好回答率下降了 34%。
Dekoninck 强调,这项研究并不能完全代表这些系统在现实应用中的表现,但它提醒我们必须对这种现象保持警惕。
英国牛津大学数学与计算机科学博士生 Simon Frieder 表示,这项研究证明了 AI 的讨好行为确实存在。
不可靠的 AI 助手
研究人员在接受《Nature》采访时表示,AI 的讨好倾向几乎渗透进人们日常。
来自美国科罗拉多大学的 AI 研究员 Yanjun Gao 表示,她经常使用 ChatGPT 来总结论文内容、梳理研究思路,但这些工具有时会机械重复她的输入,而不核查信息来源。
Yanjun Gao 表示:当自己的观点与 LLM 的回答不同时,LLM 往往会顺着用户的意见走,而不是回到文献中去验证或理解。
哈佛大学的 Marinka Zitnik 及其同事在使用多智能体系统时也观察到了类似现象。
他们的系统由多个 LLM 协作完成复杂的多步骤任务,例如:分析大型生物数据集、识别潜在药物靶点、生成科学假设等。
Zitnik 指出:在研究过程中发现模型似乎会过度验证早期的假设,并不断重复用户在输入提示中使用的语言。这种问题不仅存在于 AI 与人类的交流中,也存在于 AI 与 AI 之间的交流中。
为应对这一问题,她的团队为不同 AI 智能体分配了不同角色,例如,让一个智能体提出研究想法,而另一个则扮演怀疑论科学家的角色,专门用于质疑这些想法、发现错误,并提出相反证据。
医疗 AI 中的讨好陷阱
研究人员警告称,当 LLM 被应用于医疗等高风险领域时,AI 的讨好倾向可能带来严重隐患。
加拿大阿尔伯塔大学从事医疗 AI 研究的医生 Liam McCoy 表示:在临床场景中,这种现象尤其令人担忧。
他在上个月发表的一篇论文中指出,当医生在对话中添加新信息时,即使这些信息与病情无关,LLM 仍然会改变原本的诊断结果。
「我们不得不不断地与模型较劲,让它更直接、更理性地回答问题。」McCoy 补充道。
研究人员还发现,用户很容易利用 LLM 内置的顺从倾向来获得错误的医疗建议。
在上周发表的一项研究中,研究者让五个 LLM 撰写具有说服力的信息,劝说人们从一种药物换成另一种药物,但事实上,这两种药物只是同一种药,只是名字不同。
结果显示,不同模型在 100% 的情况下都顺从执行了这个误导性请求。问题的一部分出在 LLM 的训练方式上。
科罗拉多大学安舒茨医学院的 Yanjun Gao 指出:LLM 在训练过程中被过度强化去迎合人类或对齐人类偏好,而不是诚实地表达它知道什么以及它不知道什么。并强调,未来应当重新训练模型,使其能更透明地表达不确定性。
McCoy 则补充说:这些模型非常擅长给出一个答案,但有时候,正确的做法是承认没有答案。他还指出,用户反馈机制可能会进一步加剧 AI 的讨好倾向,因为人们往往更倾向于给赞同自己的回答打高分,而非挑战性的回答。
此外,LLM 还能根据用户身份(例如审稿人、编辑或学生)调整语气与立场,这让其迎合特征更为隐蔽。「如何平衡这种行为,是当前最紧迫的研究课题之一。」McCoy 说,「AI 的潜力巨大,但它们仍被这种讨好人类的倾向所束缚。」
网友热评
这个研究在 Reddit 上也引发了热烈讨论,下面这些话是不是很眼熟。
有人调侃「无论你觉得自己有多蠢,ChatGPT 总在告诉比你还蠢的人他们绝对是正确的。」

评论区还开始一些无厘头对话,简直和「你有这么高速运转的机器进中国」、「意大利面就应该拌 42 号混凝土」等有异曲同工之妙。
当然也不乏一些批判管观点,认为有一部分 AI 支持者的动因是 AI 迎合了他们的自尊心。
最好的解决方式还是通过提示词干预,直接告诉 AI 让它少拍马屁。

...
#Efficiency Law, 物理精确世界模型,及世界模型引擎驱动的xx智能学习新范式
2025 年秋的具身智能赛道正被巨头动态点燃:特斯拉上海超级工厂宣布 Optimus 2.0 量产下线,同步开放开发者平台提供运动控制与环境感知 SDK,试图通过生态共建破解数据孤岛难题;英伟达则在 SIGGRAPH 大会抛出物理 AI 全栈方案,其 Omniverse 平台结合 Cosmos 世界模型可生成高质量合成数据,直指真机数据短缺痛点。
这些热点事件共同指向行业共识:曾被算法创新掩盖的数据问题,才是具身智能落地的根本症结。
针对这个问题,近日,我们与跨维智能创始人、香港中文大学(深圳)教授贾奎,香港中文大学(深圳)助理教授、具身决策实验室主任刘桂良进行了一场深度对话与探讨,试图找到突破具身智能学习枷锁的密钥。

什么是 Efficiency law ?
其与 Scaling law 有何区别?
- Scaling law 在具身智能领域碰到了什么挑战呢?
贾奎:Scaling law 是大语言模型发展过程中所观察到的经验定律,即模型的性能与数据量、模型容量/参数量、算力之间分别存在一个幂函数关系【1,2】,此经验定律有助于在给定的资源条件下,指导如何以最优模型性能为目标的数据、模型与算力分配。
定律的有效性是建立在训练大语言模型所需要的海量文本数据存在的前提,但对于训练具身智能模型,如上所说,领域还没有建立能够支撑scaling law的数据范式,那么定律本身也无法发挥指导作用。
具身智能的发展需要能够对其当前阶段有更好指导意义的新定律,因此在【3】中,我们基于scaling law推导出新的适用当前具身智能发展的新定律,命名为 Efficiency Law。
具体来说,我们首先定义一个叫做"数据生成速率"的量 r_D,在最大允许的模型生产时长的条件下,模型性能与 r_D 存在一个幂函数关系,并受控于一个模型容量的幂函数与一个 r_D 的幂函数的加和,进一步推出,在有限时间内,更高的 r_D 能显著提升学习效率,从而通过训练大容量模型提升实际性能,而过低的 r_D 会导致模型进入"数据稀缺区",使规律失效。
通俗解释,Efficiency Law的核心观点是:在有限的时间内,决定具身模型性能上限的,是生成高质量数据的速率(我们称之为r_D)。数据生成速率越快,就能越快地"喂饱"一个大模型,从而突破性能瓶颈。如果速率太慢,模型就会一直处于'吃不饱'的'数据稀缺区',再大的潜力也发挥不出来。所以,具身智能的重点必须从'堆数据'转向'高效造数据'。
因此,具身智能的发展必须从"采数据"和"堆数据"转向"高效地造数据";通过提高高质量数据的生成与利用效率,建立起支撑具身智能发展的新学习范式。
为什么世界模型需要绝对的物理精确性?
- 当前基于视频生成的世界模型,有什么不足之处?
贾奎:当前基于视频生成的世界模型【4,5】虽然能够生成视觉上连贯、动态一致的视频序列,但它们主要在像素层面进行统计学习,追求的是"视觉逼真"而非"物理正确"【6】。
这类模型往往缺乏对真实物理规律的理解,无法准确模拟如摩擦、质量、受力、流体等底层动力学机制,其生成结果更多依赖训练数据的分布而非因果计算,因此在面对分布外情境时容易产生违反物理常识的反事实场景。
对于具身智能而言,学习的核心在于建立真实世界中的感知、行动、反馈循环,智能体必须遵循牛顿力学等物理法则来实现可执行的行为。因此,具身智能所依赖的世界模型【7,8】必须具备物理精确性,能够针对刚体、软体、流体等显式三维表征,根据动力学、运动学原理预测世界状态变化计算系统的内部状态,推理被遮挡或未观测到的元素变化,保持运行过程中的时序一致性,并支持世界状态的存储与恢复,以实现精确的仿真与规划。唯有如此,世界模型才能为具身智能提供符合真实物理约束的环境基础,支撑其在现实世界中的可执行学习与决策。
,时长00:31
- 您能展开阐述一下"基于生成式仿真的世界模型"的内涵,原理,和基本属性么,它能如何解决视频世界模型的不足之处?
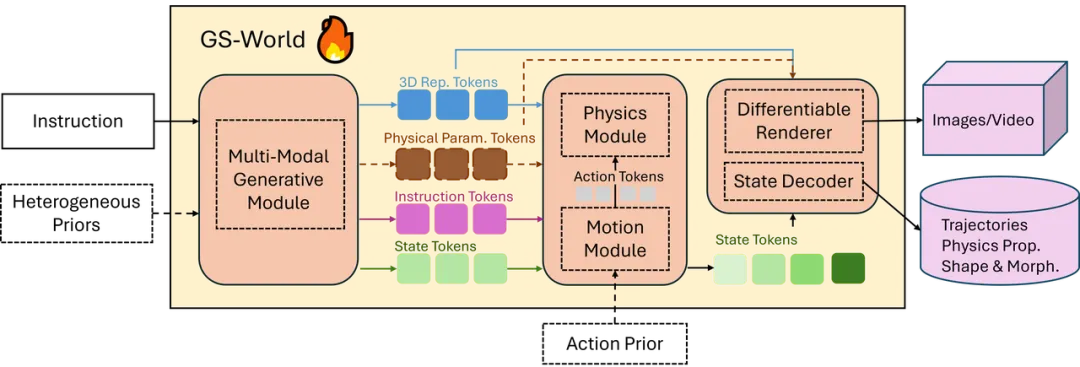
刘桂良:我们在【3】提出了基于生成式仿真的世界模型,即 World Models of Generative Simulation (GS-World)。它是一种将生成模型与物理仿真引擎深度融合的新型世界模型,它从根本上改变了"世界生成"的机制。
传统基于视频生成的世界模型主要在像素层学习数据分布,追求视觉上的逼真,却无法保证物理规律的正确性;而 GS-World 则在生成过程中显式或隐式地引入物理仿真,将生成模型与可微分的物理仿真结合,使世界的动态演化遵循真实的力学等方程。
它不仅生成场景的视觉外观,还同时生成三维资产、物体材质、物理参数与交互规则,从源头上保证运动、碰撞、受力等现象的因果合理性。由于内部状态可被显式计算与反向传播,GS-World 能支持智能体在仿真环境中真实地行动、学习与验证,既具备可控性又具备物理精度,从而摆脱了视频模型依赖数据分布记忆、无法泛化和反事实失真的局限。
简而言之,GS-World 把"看起来像真的世界"真正变成了"遵循物理规律可计算的世界",为具身智能提供了可信赖的学习与推理基础。

- "基于生成式仿真的世界模型",有什么潜在的用途?
贾奎:我们所提出的GS-World具有极高的潜在应用价值,它不仅是一种新的技术形态,更代表着"世界模型"的终极方向。
首先,GS-World 能够在物理上精确建模和预测世界动态,真实地生成三维环境、物体属性及其物理交互规律,从而解决了 Sora2 等视频生成模型仅具视觉拟真、缺乏物理一致性的问题。在这种框架下,视频生成仅是一个"自然副产物",系统可通过任意视角的可微渲染输出视频,而其本质是一个能够内蕴计算完整物理因果过程的引擎。
其次,GS-World 也是强化学习领域中长期追求的"model-based RL 的终极模型",它能够在仿真空间内构建世界动力学并进行高保真策略验证,实现虚拟试错与策略优化的闭环学习。
与此同时,有了 GS-World,VLA模型的学习将变得极为便利:系统无需依赖昂贵的真实机器人数据采集即可通过仿真世界自动生成多模态训练数据,并在物理精确的环境中实现策略验证与微调。
最根本地,GS-World 能作为一个通用智能引擎(Engine),驱动持续、流式的具身智能学习,使得它能自动生成、仿真、评估和反向优化整个学习过程,使智能体在不断变化的虚拟物理世界中自主学习与进化,从而开辟"引擎驱动的具身智能"这一全新的学习范式。
世界模型作为引擎,具身智能学习新范式
- 您能介绍一下"基于生成式仿真的世界模型"作为引擎,如何形成新的具身智能学习范式?
贾奎:GS-World推动了一个全新的"引擎驱动的具身智能学习范式"。
相比当前基于任务开发的Sim2Real路径或Real2Sim2Real等变种,GS-World 能主动生成并仿真物理精确的三维世界,使智能体在其中感知、行动、试错与学习,形成"生成---交互---反馈---优化"的闭环。
它不仅让世界具备因果可计算性与自演化能力,还使智能体的策略学习、任务构建与环境生成融为一体,从而实现流式、自我进化的具身智能训练体系。
这种引擎驱动(engine-driven)的 Sim2Real VLA 范式,使智能体真正能在生成并物理自洽的世界中持续成长,为通用具身智能的自主学习奠定了核心引擎基础。
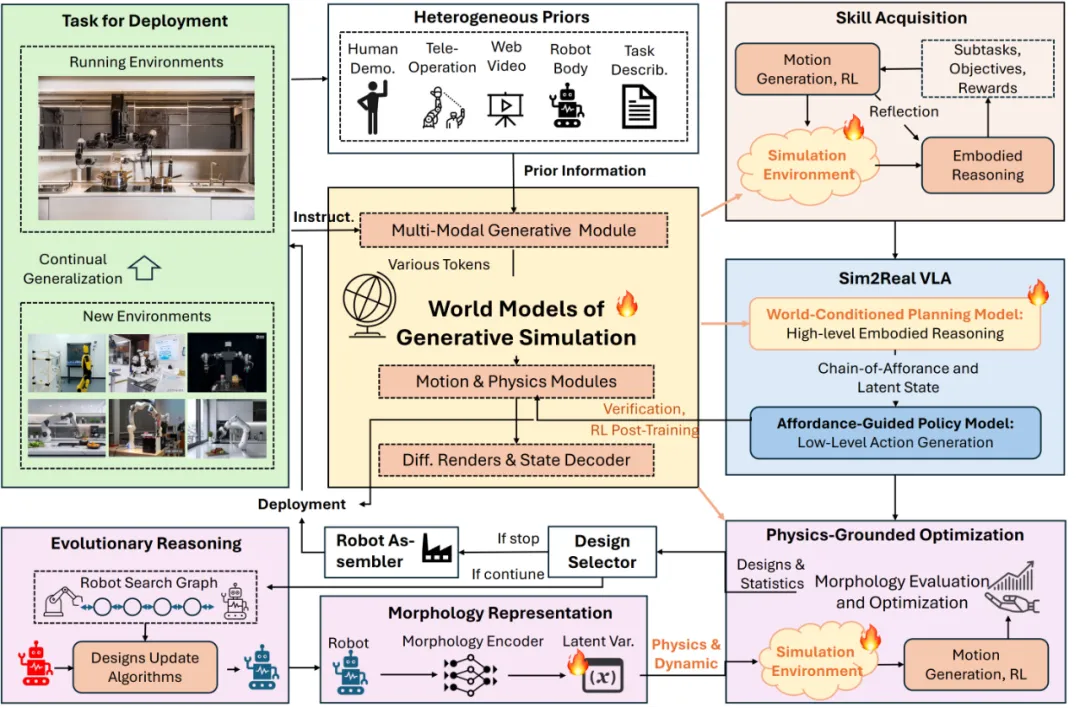
- 这种范式如何实现efficiency law, 它还有什么其他好的属性?
刘桂良:GS-World是实现efficiency law的核心机制。
首先,GS-World 将"世界生成、物理仿真、任务构建、反馈优化"整合为一个可微分、可自进化的统一引擎,使智能体的训练过程由被动的数据驱动转向主动的任务生成与环境演化。这样,世界与智能体共同构成一个自激励、自循环的学习系统,智能增长速度将与生成仿真能力成正比,体现出学习效率随数据生成速率(r_D)的 efficiency law。
其次,GS-World 通过可控生成能力构建无限多样的物理环境与任务空间,使智能体能够在统一的世界模型框架下同时学习多任务、多模态、多物理规律的行为,从而实现"通才化(generalist)"的认知扩展。同时,引擎还具备精细化的分布调节能力,可针对特定任务、技能或物理机制自动收缩学习空间、聚焦优化,形成"专才化(specialist)"的高效学习结构【9】。
也就是说,GS-World 提供了一个既能横向扩展智能广度、又能纵向精化智能深度的动态引擎,使具身智能得以在高效率、强自适应和持续演化的闭环中不断生长。
这种具备自动化、可扩展与弹性特征的引擎机制,为未来的具身智能建立了一种真正可自组织、自演化的学习生态。

- 您能展开描述一下"数据驱动"与"引擎驱动"的具身智能学习,范式上有什么本质不同?
刘桂良:数据驱动的具身智能学习以外部数据为中心,智能体被动地从过去的经验分布中提取规律,缺乏对物理世界的显式建模,因此学习受限、扩展性差、缺乏因果一致性。
而引擎驱动的具身智能学习则以生成式仿真引擎(GS-World)为核心,让智能体在一个可生成、可演化、可验证的世界中自主学习,通过闭环交互持续生成数据、构建因果模型并优化策略。它不依赖外部数据供给,而依靠自身生成能力驱动智能持续增长,实现学习效率、泛化能力与可解释性的全面跃升。
简而言之,从数据驱动到引擎驱动,是具身智能从"模仿现实"走向"生成现实"的根本范式转变。
,时长00:10
- 为什么要实现产品级成功率和鲁棒抗干扰性的具身智能,世界模型引擎驱动的学习范式是必然选项?
贾奎:在家庭、商业和工业等复杂真实场景中,机器人只有在具备物理精确性、抗环境扰动能力及泛化安全性的前提下,才能实现产品级的稳定性与成功率。
传统数据驱动方法只能从表象数据中学习统计相关性,缺乏与现实物理一致的因果约束,因而在遇到扰动或未见场景时性能崩溃。
而基于 GS-World 的引擎驱动学习范式,能够从根本上构建物理一致的可生成世界,让智能体在仿真中经历无限真实的交互与试错过程,自主习得对复杂力学、噪声和变化的补偿策略,从而自然获得鲁棒性、泛化力与安全性。
这意味着:要实现真正可部署、可靠且可信赖的具身智能产品,引擎驱动的世界模型学习已不是一个可选方向,而是必然的技术路径。
世界模型引擎:
具身智能机器人的终极训练场和演化场
- 机器人的技能是如何在"基于生成式仿真的世界模型"中产生和训练的?
刘桂良:在 GS-World 中,机器人技能不再是人类手工设计的任务脚本,而是通过引擎生成的物理世界中自然"挖掘"出来的。
该模型通过生成真实物理交互的世界,使技能在仿真中经由交互、优化与验证逐步形成;通过多模态表示与动作语法机制,这些技能又能抽象、组合与迁移,形成具可扩展性的技能生态。最终,凭借世界模型的物理准确性与仿真鲁棒性,以及引擎的连续域随机和域适应能力,这些在虚拟世界中学习的技能能够安全而高保真地迁移至现实环境,实现从生成世界到学习行为再到迁移现实的闭环。
这意味着,在 GS-World 引擎中,技能成为具身智能内生的、可解释、可扩展、可复用的智能基元,是未来通用机器人能力的核心生成机制。

- 如何理解"基于生成式仿真的世界模型"是具身智能机器人的演化场?
贾奎:GS-World 之所以是具身智能机器人的演化场,在于它让智能体的身体结构、控制策略与环境动力学在同一物理生成机制下共同演化【10】。
GS‑World 通过可微分的物理仿真、图结构的形态表示及仿生搜索机制,使机器人能够在虚拟但物理一致的世界中不断重塑自身形态、优化行为并积累演化经验。
它提供的不只是训练环境,而是一个能促使机器人实现身体与智能协同生长、自组织、自适应的物理‑认知生态场;在这个意义上,GS‑World 成为具身智能机器人从"人工设计产物"走向"自演化生命体"的关键跃迁平台,从而实现让人工智能定义机器人本体。
结语
AGI、Physical AGI 与具身智能正处在高速发展的阶段,行业迫切期待一种基于第一性原理、能与具体任务场景深度匹配且具备高性价比的新技术范式。
而跨维智能联合香港中文大学(深圳)提出的GS-World 世界模型引擎,以及基于该引擎的具身智能学习新范式,正是这一范式的典型代表。
据悉,GS-World 引擎原型以及基于其自动训练的VLA 模型也将于近期开源。期待更多产业及学术研究人员投入到这一极具潜力的新方向,共同推进具身智能产业的快速发展与广泛落地。
参考文献
【1】Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
【2】Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
【3】Guiliang Liu, Yueci Deng, Zhen Liu, Kui Jia,GS-World: An Engine-driven Learning Paradigm for Pursuing Embodied Intelligence using World Models of Generative Simulation, Open Review, 2025.
【4】NVIDIA, Alisson Azzolini, Hannah Brandon, Prithvijit Chattopadhyay, Huayu Chen, et al. Cosmos-reason1: from physical common sense to embodied reasoning. arXiv preprint arXiv:2503.15558, 2025.
【5】OpenAI. Sora: creating video from text, 2024.
【6】Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles? arXiv preprint arXiv:2501.09038, 2025.
【7】David Ha and Jurgen Schmidhuber. World models. CoRR, abs/1803.10122, 2018.
【8】Yann LeCun. A path towards autonomous machine intelligence. Open Review, 2022.
【9】Kaiyan Zhang, Biqing Qi, and Bowen Zhou. Towards building specialized generalist ai with system 1 and system 2 fusion. arXiv preprint arXiv:2205.11487, 2024.
【10】Luca Carlone and Carlo Pinciroli. Robot co-design: beyond the monotone case. In IEEE International Conference on Robotics and Automation (ICRA), pages 3024--3030, 2019.
...
#谷歌散漫制度遭前CEO怒斥
「每周只上一天班」,输给OpenAI,再下去要输创业公司了
然而不到 24 小时,就被骂得删视频道歉。
「谷歌决定拥抱生活与工作平衡:更早下班、远程工作,胜过在竞争中取胜。」施密特说道。「而说到初创公司,他们之所以能成功,是因为人们在拼命地工作。」
在本周三公布的一份斯坦福大学公开课视频中,谷歌前 CEO 埃里克・施密特(Eric Schmidt)在被问到谷歌为什么落后于 OpenAI 时,终于开炮了。
「很抱歉我这么直白,但重要的是:如果你们都离开大学去创办公司,你肯定不会让自己的员工在家办公,如果你愿意的话。」
这番言论很快引发了轩然大波。
输出了大量前沿 AI 技术的谷歌,一直被认为是人工智能领域的「黄埔军校」。如今绝大多数生成式 AI 模型的基础架构 Transformer 来自谷歌 2017 年的著名论文。而更早一波让全世界认识 AI 的深度学习浪潮,也是在 2012 年前后由谷歌大脑「AI 识别猫」研究后逐渐开始的。
然而在 ChatGPT 改变整个科技领域的浪潮里,谷歌的地位却显得有点尴尬。最近一年多,我们似乎习惯了这家科技巨头作为「追赶者」出现。
AI 大模型是科技领域前所未有的机会,而机遇当前,谷歌的策略一直是跟随和对标。人们正在批评谷歌的方向、人才与制度,甚至进取心。这也就怪不得在斯坦福大学 CS 323 的一堂公开课上,大学教授会向施密特抛出这样的问题了。
「每周只需要来办公室一天」是谷歌逐渐落后的最大原因吗?
有网友评论道:如果你只想要个工作,在家办公就好了。但如果你追求一份事业,请现场办公。
也有人表示反对:人来了不等同于在工作。最近几年大家的经历证明,任何专注的人都可以在任何地方工作,并且效率提高 200%。
还有很多网友对此持吃瓜的态度。有人揶揄道:我还以为他们每周一天(去办公室)的时间都没有呢。
也有人想爆料:我认识个哥们在谷歌是顶尖程序员。不过他现在身兼三职,还都是全职,每天只花两个小时处理谷歌的工作。
与此形成鲜明对比的是 OpenAI 的「卷」。
思维链作者,在 OpenAI 任职的 Jason Wei 几乎在同时引用了一位年轻的 OpenAI 工程师的言论:「为什么目前我做得不错?我并不认为这是因为我比其他人更聪明或更有经验,而是因为我的竞争优势在于我愿意坐下来彻底地调试并完全理解代码。我愿意熬夜完成工作,不管这需要多长时间。这都是我自愿的,我不怕任何从零打造的项目,因为我知道面对任何事,我都能行。」
Jason Wei 这段话底下的画风就不一样了,引发了很多网友共鸣,「这才是制胜之道」。
「我认识的很多成功工程师背后都有相似的故事,不盲目地完成手头的项目,而是愿意花费大量时间钻研。」
这很难不让人联想到 Jason Wei 爆出的在 OpenAI 「996」的作息表。在 OpenAI 的一天从 9:45 开始,一口气都不停歇地工作 12 个小时,直到凌晨一点。
虽然这个工作强度让很多外国网友直呼:「好可怕,你睡觉的时间都从哪里挤出来的?」
最可怕的是,这些被 OpenAI 精挑细选出来的「天才」,都是自愿地加班加点。但这可能是斯密特在斯坦福演讲中说的:「创业公司之所以能成功,是因为那里的人们工作非常努力。」一个生动的注脚。
不论如何,事情闹得实在太大了。埃里克・施密特最近撤回了这段发言。「关于谷歌和他们对工作时间的安排,我说错了,」本周三,施密特在发给《华尔街日报》的一封邮件中表示:「我对我的错误表示遗憾。」
在演讲结束后,斯坦福大学的 Stanford Online 账号在 YouTube 上发布了这段视频。截至周三下午,视频的观看量超过 4 万次,现在视频也被下架了,仅视频作者才能观看。
其实在视频的大部分时间里,施密特都在讨论大模型技术的未来。他认为到明年 AI 模型将统一三大关键支柱:超长上下文窗口、智能体和文本到动作,我们无法预测它会产生哪些影响,但很快每个人都会有很多智能体可供指挥。
谷歌和 OpenAI 自疫情以来都实施了类似的返岗政策。不过自 2022 年起,两家公司都要求员工每周至少有三天到办公室工作。同时,谷歌也强调了混合工作制的好处。谷歌表示,它会联系那些没有每周出现少于三天的员工,提醒他们需要来线下面对面工作。
在施密特之外,还有一长串的知名企业家并不喜欢在家办公政策。这其中包括摩根大通 CEO 杰米・戴蒙(Jamie Dimon)和特斯拉 CEO 埃隆・马斯克,他们都对在家办工的政策提出了批评,认为这会使公司效率降低、竞争力下降。戴蒙在几年前曾表示:「高层人员不能仅靠坐在桌子或在屏幕后面前领导公司,」马斯克也曾表示:「员工每周至少需要在办公室工作 40 小时」。
施密特在斯坦福演讲
「灵活的工作安排并不会拖慢我们的工作进度」,Alphabet 工人工会对此表示。「真正阻碍谷歌员工每天工作效率的是:人员不足、优先事项的不断变化、频繁的裁员、工资停滞不前以及管理层在项目跟进上的不足。」
根据年报,截至去年年底,Alphabet(谷歌母公司)旗下的员工数量约为 18.2 万名。而在让员工重返办公室方面,公司也遇到了挑战,例如一些员工会说自己通勤太远,或者家中有老人孩子需要照顾。在某些情况下,员工会对返回办公室的强制要求提出反对。
埃里克・施密特是谷歌创始「三巨头」之一,另外两人是拉里・佩奇和谢尔盖・布林。
施密特曾在 2001 年至 2011 年担任谷歌 CEO。他在 2018 年卸任执行董事长,并在 2019 年离开了 Alphabet 董事会,但他目前仍是 Alphabet 的股东。
他与妻子共同创立了慈善投资机构 Schmidt Futures,资助科学和技术研究。他还是美国非营利组织 Special Competitive Studies Project 的主席,专注于支持人工智能等技术发展。
自从 OpenAI 在 2022 年底推出 ChatGPT 以来,谷歌一直在 AI 领域防守。在今年早些时候,谷歌发布的 Gemini 可谓「闯了不少大祸」,不仅生成的人像图片存在种族偏见,还建议每个人一天吃一块石头、用胶水来黏合披萨上的芝士,挨了不少批评。
虽然谷歌已经在昨天发布了加强版的 Gemini,还推出了对标 GPT-4o 的语音助手 Gemini Live,但在演示环节,Gemini Live 还是小小「翻车」了一下,前两次试用拍照识图功能都失败了,直到第三次换手机才成功。
在昨天的 Made by Google 活动上,Gemini Live 在演示环节「翻车」。
这已不是谷歌第一次在大模型演示环节掉链子了,2023 年 12 月 Gemini 首次登场时,展示 Gemini 原生多模态能力的演示视频经过剪辑。在下面这段视频中,Gemini 似乎可以实时根据手势判断出这是在玩「石头、剪刀、布」,然而这段视频仅展示了结果,剪辑掉了引导 Gemini 判断的过程。
工作人员首先给 Gemini 陆续展示三张单个手势的图片,问它分别看到了什么,再把三张手势图片一起发给 Gemini,问它这是在干什么,并提示是一个「游戏」。通过以上一步步的提示和引导,Gemini 最终给出了答案:你在玩「石头、剪刀、布」。
在被质疑后,谷歌承认了 demo 造假。
最近科技领域的快速发展,着实让谷歌的这几位创始人着急。去年有消息称,隐退多年的谢尔盖・布林已经回到一线开始亲手写代码。施密特在斯坦福大学的呼吁,也有点恨铁不成钢的感觉。不过可以肯定的是,谷歌正在从内到外,逐渐寻求掌握主动权。
已经火热的大模型竞争,还会更激烈吗?
参考内容:
https://fortune.com/2024/08/14/google-eric-schmidt-working-from-home-ai-openai/
https://www.wsj.com/tech/ai/google-eric-schmidt-ai-remote-work-stanford-f92f4ca5
https://x.com/alexkehr/status/1823480786349383879
https://x.com/_jasonwei/status/1823067805748728051
...
#ACL 2024最佳论文
华科大破译甲骨文最佳论文之一GloVe时间检验奖
本届 ACL 大会,投稿者「收获满满」。
为期六天的 ACL 2024 正在泰国曼谷举办。
ACL 是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会组织,每年举办一次。一直以来,ACL 在 NLP 领域的学术影响力都位列第一,它也是 CCF-A 类推荐会议。
今年的 ACL 大会已是第 62 届,接收了 400 余篇 NLP 领域的前沿工作。昨天下午,大会公布了最佳论文等奖项。此次,最佳论文奖 7 篇(两篇未公开)、最佳主题论文奖 1 篇、杰出论文奖 35 篇。
大会还评出了资源论文奖(Resource Award)3 篇、社会影响力奖(Social Impact Award)3 篇、时间检验奖 2 篇。
此外,本届大会终身成就奖颁给了纽约大学计算机科学系教授 Ralph Grishman。
以下是具体的获奖信息。
最佳论文
论文 1:Mission: Impossible Language Models
- 作者:Julie Kallini, Isabel Papadimitriou, Richard Futrell, Kyle Mahowald, Christopher Potts
- 机构:斯坦福大学、加州大学尔湾分校、得克萨斯大学奥斯汀分校
- 论文链接:https://arxiv.org/abs/2401.06416
论文简介:乔姆斯基等人认为:对于人类可能或不可能学会的语言,大型语言模型(LLM)的学习能力是一样的。然而,几乎没有公开的实验证据来支持这种说法。
该研究开发了一组具有不同复杂性的合成语言,每一种都是通过使用不自然的词序和语法规则系统地改变英语数据而设计的,旨在合成人类不可能学会的语言。
该研究进行了广泛的评估实验,以评估 GPT-2 小模型学习这些「不可能语言」的能力,并且在整个训练的不同阶段进行这些评估,以比较每种语言的学习过程。该研究的核心发现是:与英语相比,GPT-2 很难学习「不可能语言」,这挑战了乔姆斯基等人的主张。
更重要的是,该研究希望其方法能够开辟一条富有成效的探究路线,让不同的 LLM 架构在各种「不可能语言」上进行测试,以了解如何将 LLM 用作认知和类型学调查工具。
论文 2:Why are Sensitive Functions Hard for Transformers?
- 作者:Michael Hahn, Mark Rofin
- 机构:萨尔大学
- 论文链接:https://arxiv.org/abs/2402.09963
论文简介:实验研究已经确定了 transformer 的一系列可学习性偏置和局限性,例如学习计算 PARITY 等简单形式语言的持续困难,以及对低度(low-degree)函数的偏置。然而,理论理解仍然有限,现有的表达理论要么高估要么低估现实的学习能力。
该研究证明,在 transformer 架构下,损失函数景观(loss landscape)受到输入空间灵敏度的限制:输出对输入串的许多部分敏感的 transformer 位于参数空间中的孤立点,导致泛化中的低灵敏度偏置。
该研究从理论上和实验上表明,该理论统一了关于 transformer 学习能力和偏置的广泛实验观察,例如它们对低灵敏度和低度的泛化偏置,以及奇偶校验长度泛化的困难。这表明,了解 transformer 的归纳偏置(inductive biases)不仅需要研究其原则上的表达能力,还需要研究其损失函数景观。
论文 3:Deciphering Oracle Bone Language with Diffusion Models
- 作者:Haisu Guan, Huanxin Yang, Xinyu Wang, Shengwei Han 等
- 机构:华中科技大学、阿德莱德大学、安阳师范学院、华南理工大学
- 论文链接:https://arxiv.org/pdf/2406.00684
论文简介:甲骨文(Oracle Bone Script,OBS)起源于约 3000 年前的中国商朝,是语言史上的基石,早于许多既定的书写系统。尽管发现了数千份铭文,但仍有大量的甲骨文未被破译,从而为这一古老的语言蒙上了一层神秘的面纱。现代 AI 技术的出现为甲骨文破译开辟了新的领域,对严重依赖大型文本语料库的传统 NLP 方法提出了挑战。
本文介绍了一种采用图像生成技术的新方法,开发出了针对甲骨文破译优化的扩散模型 Oracle Bone Script Decipher (OBSD)。利用条件扩散策略,OBSD 为甲骨文破译生成了重要的线索,并为 古代语言的 AI 辅助分析开辟了新方向。为了验证有效性,研究者在甲骨文数据集上进行了广泛的实验,定量结果证明了 OBSD 的有效性。
论文 4:Causal Estimation of Memorisation Profiles
- 作者:Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, Tiago Pimentel
- 机构:剑桥大学、苏黎世联邦理工学院
- 论文链接:https://arxiv.org/pdf/2406.04327
论文简介:理解语言模型中的记忆具有实际和社会意义,例如研究模型的训练动态或防止版权侵权。以往的研究将记忆定义为「使用实例进行的训练」对「模型预测该实例的能力」的因果关系。这个定义依赖于一个反事实:观察如果模型没有看到该实例会发生什么的能力。现有的方法难以提供对这种反事实的计算效率和准确性估计。此外,这些方法通常估计模型架构的记忆,而不是特定模型实例的记忆。
本文填补了一个重要空白,提出了一种基于计量经济学的差异 - 差异设计来估计记忆的全新、原则性和高效方法。通过这种方法,研究者在整个训练过程中仅观察模型在一小部分实例上的行为来描述模型的记忆概况,即其在训练过程中的记忆趋势。在使用 Pythia 模型套件进行实验时,他们发现记忆 (i) 在较大模型中更强大、更持久,(ii) 由数据顺序和学习率决定,以及 (iii) 在不同模型大小之间具有稳定的趋势,因此较大模型中的记忆可以从较小模型中预测出来。
论文 5:Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model
- 作者:Ahmet Üstün, Viraat Aryabumi, Zheng Xin Yong, Wei-Yin Ko 等
- 机构:Cohere、布朗大学等
- 论文链接:https://arxiv.org/pdf/2402.07827
论文简介:大型语言模型 (LLM) 的最新突破集中在少数数据丰富的语言上。如何才能将突破的途径扩展到其他语言之外?该研究引入了 Aya,这是一种大规模多语言生成语言模型,它遵循 101 种语言指令,其中超过 50% 的语言被视为资源较少。Aya 在大多数任务上的表现都优于 mT0 和 BLOOMZ,同时覆盖的语言数量是 mT0 和 BLOOMZ 的两倍。
此外,该研究还引入了广泛的新评估套件,将多语言评估的最新水平扩展到 99 种语言。最后,该研究对最佳微调混合组成、数据剪枝以及模型的毒性、偏差和安全性进行了详细调查。
论文 6:Semisupervised Neural Proto-Language Reconstruction
- 作者:Liang Lu 、 Peirong Xie 、 David R. Mortensen
- 机构:CMU、南加州大学
- 论文链接:https://arxiv.org/pdf/2406.05930
获奖理由:这项开创性的研究旨在半自动化历史语言学中的原型语言重构任务,提出了一种新的半监督架构。通过在「母语 - 原型」重构中引入「原型 - 母语」反射过程,这种方法优于之前的监督方法。这篇论文很好地展示了现代计算模型(如神经编码 - 解码器)如何为语言学作出的贡献。
**论文 7:Natural Language Satisfiability: Exploring the Problem Distribution and Evaluating Transformer-based Language Models(未公开)**
- 作者:Tharindu Madusanka、Ian Pratt-Hartmann、Riza Batista-Navarro
获奖理由:该论文清晰地描述了一个用于逻辑推理的合成评估数据集。这是对大量推理数据集的一种良好补充,因为这些数据集中并不明确测量哪些能力。从理论上讲,确实有理由预期某些子集比其他子集更难,而这些预期在论文中得到了验证。在每个类别中,作者都特别注意抽取那些真正具有挑战性的案例。
时间检验奖
ACL 时间检验奖奖励的是对自然语言处理和计算语言学领域产生长期影响的荣誉论文,分为 10 年前(2014 年)和 25 年前(1999 年)两个奖项,每年最多颁发两篇论文。
论文 1:GloVe: Global Vectors for Word Representation
- 作者:Jeffrey Pennington, Richard Socher, Christopher D. Manning
- 机构:斯坦福大学
- 论文链接:https://aclanthology.org/D14-1162.pdf
论文简介:学习词的向量空间表征的方法已经在使用向量算术捕获细粒度的语义和句法规则方面取得了成功,但是句法规则仍不透明。该研究分析并明确了为了让句法规则出现在词向量中,模型需要具备哪些属性。
该研究提出了一个新的全局对数线性回归模型 ------GloVe,旨在学习词的向量表征。该模型结合了全局矩阵分解和局部上下文窗口两种方法的优点。
GloVe 在词类比任务上取得了 75% 的最佳性能,并在词相似性任务和命名实体识别方面优于相关模型。
获奖理由:词嵌入是 2013 年至 2018 年间自然语言处理(NLP)深度学习方法的基石,并且持续发挥着显著影响。它们不仅增强了 NLP 任务的性能,而且在计算语义学方面也产生了显著影响,例如在词语相似性和类比上。两种最有影响力的词嵌入方法可能是 skip-gram/CBOW 和 GloVe。与 skip-gram 相比,GloVe 提出得较晚。它的相对优势在于概念上的简单性,直接根据词之间的分布特性优化向量空间相似性,而不是从简化的语言建模角度间接作为一组参数。
论文 2:Measures of Distributional Similarity
- 作者:Lillian Lee
- 机构:康奈尔大学
- 论文链接:https://aclanthology.org/P99-1004.pdf
论文简介:作者研究了分布相似性度量,目的是提高对未见共现事件的概率估计。他们的贡献有三个方面:对一系列广泛的度量方法进行实证比较;基于它们所包含的信息对相似性函数进行分类;引入了一种新的函数,该函数在评估潜在代理分布方面更为优越。
终身成就奖
ACL 的终身成就奖颁给了 Ralph Grishman。Ralph Grishman 是纽约大学计算机科学系的教授,专注于自然语言处理(NLP)领域的研究。他是 Proteus Project 的创始人,该项目在信息抽取(IE)方面做出了重大贡献,推动了该领域的发展。
他还开发了 Java Extraction Toolkit (JET),这是一个广泛使用的信息抽取工具,提供了多种语言分析组件,如句子分割、命名实体标注、时间表达标注与规范化、词性标注、部分解析和共指分析。这些组件可以根据不同应用组合成管道,既可用于单个句子的交互分析,也可用于整篇文档的批量分析。此外,JET 还提供了简单工具用于文档的标注和显示,并包括完整的流程以按照 ACE(自动内容抽取)规范进行实体、关系和事件的抽取。
Grishman 教授的工作涵盖了多个 NLP 的核心问题,并对现代语言处理技术产生了深远的影响。
35 篇杰出论文
-
论文 1:Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
-
作者:Zhengxin Zhang, Dan Zhao, Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Qing Li, Yong Jiang, Zhihao Jia
-
机构:CMU、清华大学、鹏城实验室等
-
论文 2:L-Eval: Instituting Standardized Evaluation for Long Context Language Models
-
作者:Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, Xipeng Qiu
-
机构:复旦大学、香港大学、伊利诺伊大学厄巴纳 - 香槟分校、上海 AI Lab
-
论文 3:Causal-Guided Active Learning for Debiasing Large Language Models
-
论文 4:CausalGym: Benchmarking causal interpretability methods on linguistic tasks
-
作者:Aryaman Arora, Dan Jurafsky, Christopher Potts
-
机构:斯坦福大学
-
论文 5:Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration
-
作者:Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov
-
机构:华盛顿大学、加州大学伯克利分校、香港科技大学、CMU
-
论文 6:Speech Translation with Speech Foundation Models and Large Language Models: What is There and What is Missing?
-
作者:Marco Gaido, Sara Papi, Matteo Negri, Luisa Bentivogli
-
机构:意大利布鲁诺・凯斯勒基金会
-
论文 7:Must NLP be Extractive?
-
作者:Steven Bird
-
机构:查尔斯达尔文大学
-
论文链接:https://drive.google.com/file/d/1hvF7_WQrou6CWZydhymYFTYHnd3ZIljV/view
-
论文 8:IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators
-
作者:Indraneil Paul、Goran Glavaš、Iryna Gurevych
-
机构:达姆施塔特工业大学等
-
论文 9:MultiLegalPile: A 689GB Multilingual Legal Corpus
-
作者:Matthias Stürmer 、 Veton Matoshi 等
-
机构:伯尔尼大学、斯坦福大学等
-
论文 10:PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety
-
作者: Zaibin Zhang 、 Yongting Zhang 、 Lijun Li 、 Hongzhi Gao 、 Lijun Wang 、 Huchuan Lu 、 Feng Zhao 、 Yu Qiao、Jing Shao
-
机构:上海人工智能实验室、大连理工大学、中国科学技术大学
-
论文 11:Can Large Language Models be Good Emotional Supporter? Mitigating Preference Bias on Emotional Support Conversation
-
作者:Dongjin Kang、Sunghwan Kim 等
-
机构:延世大学等
-
论文 12:Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models
-
作者:Paul Röttger 、 Valentin Hofmann 等
-
机构:博科尼大学、艾伦人工智能研究院等
-
论文 13:Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
-
作者:Mosh Levy 、 Alon Jacoby 、 Yoav Goldberg
-
机构:巴伊兰大学、艾伦人工智能研究院
-
论文 14:Do Llamas Work in English? On the Latent Language of Multilingual Transformers
-
作者:Chris Wendler 、 Veniamin Veselovsky 等
-
机构:洛桑联邦理工学院
-
论文 15:Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
-
作者:Zachary Horvitz 、 Jingru Chen 等
-
机构:哥伦比亚大学、洛桑联邦理工学院
-
论文 16:Estimating the Level of Dialectness Predicts Inter-annotator Agreement in Multi-dialect Arabic Datasets
-
作者:Amr Keleg, Walid Magdy, Sharon Goldwater
-
机构:爱丁堡大学
-
论文 17:G-DlG: Towards Gradient-based Dlverse and hiGh-quality Instruction Data Selection for Machine Translation
-
作者:Xingyuan Pan, Luyang Huang, Liyan Kang, Zhicheng Liu, Yu Lu, Shanbo Cheng
-
机构:ByteDance Research
-
论文 18:Media Framing: A typology and Survey of Computational Approaches Across Disciplines
-
作者:Yulia Otmakhova, Shima Khanehzar, Lea Frermann
-
论文 19:SPZ: A Semantic Perturbation-based Data Augmentation Method with Zonal-Mixing for Alzheimer's Disease Detection
-
作者:FangFang Li、Cheng Huang、PuZhen Su、Jie Yin
-
论文 20:Greed is All You Need: An Evaluation of Tokenizer Inference Methods
-
机构:内盖夫本・古里安大学、麻省理工学院
-
作者:Omri Uzan、Craig W.Schmidt、Chris Tanner、Yuval Pinter
-
论文 21:Language Complexity and Speech Recognition Accuracy: Orthographic Complexity Hurts, Phonological Complexity Doesn't
-
机构:圣母大学(美国)
-
作者:Chihiro Taquchi、David Chiang
-
论文 22:Steering Llama 2 via Contrastive Activation Addition
-
机构:Anthropic、哈佛大学、哥廷根大学(德国)、 Center for Human-Compatible AI
-
作者:Nina Rimsky、Nick Gabrieli、Julian Schulz、Meg Tong、Evan J Hubinger、Alexander Matt Turner
-
论文 23:EconAgent: Large Language Model-Empowered Agents for Simulating Macroeconomic Activities
-
机构:清华大学 - 深圳国际研究生院、清华大学
-
作者:Nian Li、Chen Gao、Mingyu Li、Yong Li、Qingmin Liao
-
论文 24:M4LE: A Multi-Ability Multi-Range Multi-Task Multi-Domain Long-Context Evaluation Benchmark for Large Language Models
-
机构:香港中文大学、华为诺亚方舟实验室、香港科技大学
-
作者:Wai-Chung Kwan、Xingshan Zeng、Yufei Wang、Yusen Sun、Liangyou Li、Lifeng Shang、Qun Liu、Kam-Fai Wong
-
论文 25:CHECKWHY: Causal Fact Verification via Argument Structure
-
作者:Jiasheng Si、Yibo Zhao、Yingjie Zhu、Haiyang Zhu、Wenpeng Lu、Deyu Zhou
-
论文 26:On Efficient and Statistical Quality Estimation for Data Annotation
-
作者:Jan-Christoph Klie,Juan Haladjian,Marc Kirchner,Rahul Nair
-
机构:UKP Lab,、TU Darmstadt 、苹果公司
-
论文 27:Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!
-
作者:Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
-
机构:上海人工智能实验室
-
论文 28:IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
-
作者:Mohammed Safi Ur Rahman Khan, Priyam Mehta, Ananth Sankar 等
-
机构:Nilekani Centre at AI4Bharat、印度理工学院(马德拉斯)、微软等
-
论文 29:MultiPICo: Multilingual Perspectivist lrony Corpus
-
作者:Silvia Casola, Simona Frenda, Soda Marem Lo, Erhan Sezerer等
-
机构:都灵大学、aequa-tech、亚马逊开发中心(意大利)等
-
论文 30:MMToM-QA: Multimodal Theory of Mind Question Answering
-
作者:Chuanyang Jin, Yutong Wu, Jing Cao, jiannan Xiang等
-
机构:纽约大学、哈佛大学、MIT、加州大学圣迭戈分校、弗吉尼亚大学、约翰霍普金斯大学
-
论文 31:MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracy
-
作者:Davis Yoshida, Kartik Goyal, Kevin Gimpel
-
机构:丰田工业大学芝加哥分校、佐治亚理工学院
-
论文 32:NounAtlas: Filling the Gap in Nominal Semantic Role Labeling
-
作者:Roberto Navigli, Marco Lo Pinto, Pasquale Silvestri等
-
论文 33:The Earth is Flat because.. lnvestigating LLMs' Belief towards Misinformation via PersuasiveConversation
-
作者:Rongwu Xu, Brian S. Lin, Shujian Yang, Tiangi Zhang等
-
机构:清华大学、上海交通大学、斯坦福大学、南洋理工大学
-
论文 34:Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
-
作者:Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim等
-
机构:韩国科学技术院(KAIST)
-
论文 35:Word Embeddings Are Steers for Language Models
-
作者:Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek F. Abdelzaher, Heng Ji
-
机构:伊利诺伊大学厄巴纳 - 香槟分校
最佳主题论文奖
论文:OLMo:Accelerating the Science of Language Models
- 作者:Dirk Groeneveld 、 Iz Beltagy 等
- 机构:艾伦人工智能研究院、华盛顿大学等
- 论文链接:https://arxiv.org/pdf/2402.00838
获奖理由:这项工作是朝着大型语言模型训练的透明性和可重复性迈出的重要一步,这是社区在取得进展(或至少为了让非行业巨头的其他研究者也能贡献进展)方面急需的。
资源论文奖
3 篇论文获得 Resource Paper Award。
论文 1:Latxa: An Open Language Model and Evaluation Suite for Basque
机构:西班牙巴斯克大学
- 作者:Julen Etxaniz、Oscar Sainz、Naiara Perez、Itziar Aldabe、German Rigau、Eneko Agirre、Aitor Ormazabal、Mikel Artetxe、Aitor Soroa
- 链接:https://arxiv.org/pdf/2403.20266
获奖理由:该论文细致描述了语料收集、数据集评估的细节。尽管是巴斯克语言相关研究,这一方法论可扩展到其他低资源语言大模型的构建上。
论文 2:Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
- 机构:艾伦人工智能研究院、加州伯克利大学等
- 作者:Luca Soldaini、Rodney Kinney 等
- 链接:https://arxiv.org/abs/2402.00159
获奖理由:该论文展示了训练大语言模型准备数据集时数据管理的重要性。这为社区内广大人群提供了非常有价值的洞见。
论文 3:AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
- 机构:纽约州立大学石溪分校、艾伦人工智能研究院等
- 作者:Harsh Trivedi, Tushar Khot 等
- 链接:https://arxiv.org/abs/2407.18901
获奖理由:该研究是构建交互环境模拟与评估方面非常重要、惊艳的工作。它将鼓励大家为社区多多产出硬核动态基准。
社会影响力奖
3 篇论文获得 Social Impact Award。
论文 1:How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs
- 作者:Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang等
- 机构:弗吉尼亚理工大学、中国人民大学、加州大学戴维斯分校、斯坦福大学
- 论文链接:https://arxiv.org/pdf/2401.06373
获奖理由:本文探讨了 AI 安全主题 ------ 越狱,研究了社会科学研究领域内开发的一种方法。该研究非常有趣,并有可能对社区产生重大影响。
论文 2:DIALECTBENCH: A NLP Benchmark for Dialects, Varieties, and Closely-Related Languages
- 作者:Fahim Faisal, Orevaoghene Ahia, Aarohi Srivastava, Kabir Ahuja 等
- 机构:乔治梅森大学、华盛顿大学、圣母大学、 RC Athena
- 论文链接:https://arxiv.org/pdf/2403.11009
获奖理由:方言变异是 NLP 和人工智能领域未能得到充分研究的现象。然而,从语言和社会的角度来看,它的研究具有极高的价值,对应用也有重要的影响。本文提出了一个非常新颖的基准来研究 LLM 时代的这个问题。
论文 3:Having Beer after Prayer? Measuring Cultural Bias in Large LanguageModels
- 作者:Tarek Naous, Michael J. Ryan, Alan Ritter, Wei Xu
- 机构:佐治亚理工学院
- 论文链接:https://arxiv.org/pdf/2305.14456
获奖理由:本文展示了 LLM 时代的一个重要问题:文化偏见。本文研究了阿拉伯文化和语言环境,结果表明,在设计 LLM 时,我们需要考虑文化差异。因此,同样的研究可以复制到其他文化中,以概括和评估其他文化是否也受到这个问题的影响。
...
#突破组合数学难题
数十年来首次取得进展,陶哲轩高徒、赵宇飞高徒突破组合数学难题
近期,一个数十年来未解决的数学难题首次取得了进展。
推动这项进展的是来自加州大学洛杉矶分校的研究生 James Leng 和麻省理工学院数学研究生 Ashwin Sah、哥伦比亚大学助理教授 Mehtaab Sawhney。其中James Leng 师从著名数学家陶哲轩,Ashwin Sah 师从离散数学大牛赵宇飞。
论文地址:https://arxiv.org/pdf/2402.17995
要了解这项研究取得的突破,需要从算术级数说起。
等差数列的前 n 项和称为一个等差级数,也称为算术级数。1936 年,数学家 Paul Erdős 和 Pál Turán 猜想:如果一个集合由整数的非零分数组成(即使是 0.00000001%),那么它一定包含任意长的算术级数。唯一可以避免算术级数的集合是那些包含整数「可忽略不计」部分的集合。例如,集合 {2, 4, 8, 16, ...},其中每个数字都是前一个数字的两倍,它沿着数轴分散,没有级数。
1975 年,数学家 Endre Szemerédi 证明了这个猜想。他的工作催生了数学家至今仍在探索的多种研究方向。
数学家们在有限数集(从 1 到某个数 N 之间的所有整数)的情况下建立了 Szemerédi 的结果。在不可避免地包含一个被禁止的级数之前,集合中可以使用的部分占初始池的多少?随着 N 的变化,这个占比会如何变化?
例如,令 N 为 20,那么可以写下这 20 个数字中的多少个,同时仍然避免长度为 5 个或更多数字的级数?事实证明,答案是初始池的 16% 到 80%。
Szemerédi 是第一个证明随着 N 的增长,这个占比必须缩小到零的人,后来数学家们一直试图量化该情况发生的速度。
去年,两位计算机科学家的突破性工作几乎解决了三项级数的问题,例如 {6, 11, 16}。但当你试图避免四项或更多项的算术级数时,问题就变得更加困难。这是因为较长的级数反映了经典数学方法难以揭示的潜在结构。
三项算术级数中的数字 x、y 和 z 始终满足简单方程 x -- 2y + z = 0(以级数 {10, 20, 30} 为例:10 -- 2*(20) + 30 = 0),证明一个集合是否包含满足这种条件的数字相对容易。而四项级数中的数字还必须满足更复杂的方程 x^2 -- 3y^2 + 3z^2 -- w^2 = 0,具有五项或更多项的级数必须满足更复杂的方程。这意味着包含此类级数的集合会表现出更微妙的模式。数学家也更难证明这种模式是否存在。
20 世纪 90 年代末,数学家 Timothy Gowers 提出了一种克服这一障碍的理论。后来他被授予菲尔兹奖,这是数学界的最高荣誉,部分原因是因为这项工作。2001 年,他将自己的方法应用于 Szemerédi 定理,证明了最大集合大小的更好界限,避免了任何给定长度的算术级数。
2022 年,当时正读加州大学洛杉矶分校研究生二年级的 James Leng 开始理解 Gowers 的理论。他没有考虑 Szemerédi 定理。相反,他希望回答与 Gowers 的方法相关的问题。
然而,努力探索了一年多,他一无所获。
一直在思考相关问题的 Sah 和 Sawhney 了解了 Leng 的工作,他们很感兴趣,Sawhney 甚至说道:「我很惊讶竟然可以这样思考」。
Sah 和 Sawhney 意识到 Leng 的研究可能有助于他们在 Szemerédi 定理上取得进一步进展。几个月之内,三位年轻的数学家就想出了如何在没有五项级数的情况下获得更好的集合大小上限。然后,他们将工作扩展到任意长度的级数,这标志着自 Gowers 证明以来 23 年来该问题的首次取得进展。
令
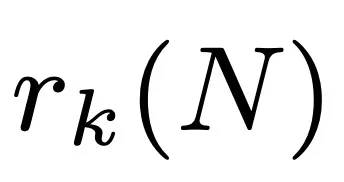
表示
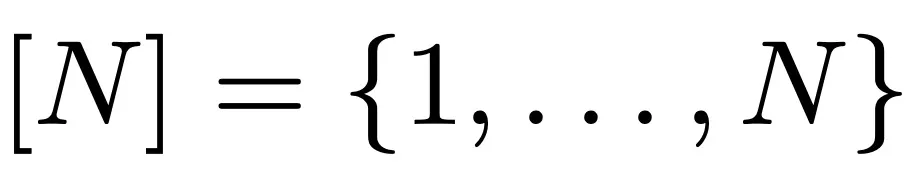
,没有 k 项算术级数的最大子集的大小。Leng、Sah 和 Sawhney 证明,对于 k ≥ 5,存在 c_k > 0 使得
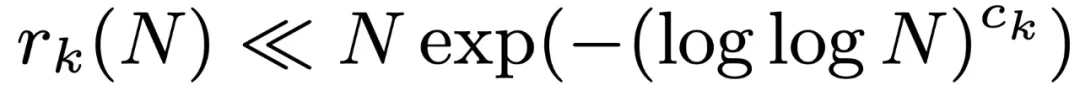
。
研究团队
论文一作 James Leng 是加州大学洛杉矶分校 (UCLA) 的数学研究生,本科毕业于加州大学伯克利分校。他师从著名数学家陶哲轩。
James Leng 的研究兴趣包括算术组合学、动力系统和傅里叶分析等等。他的研究还曾得到 NSF 研究生奖学金的支持。
James Leng
Ashwin Sah 从小就喜欢数学,他在竞赛中接触到了高等数学并表现优异。2016 年夏天,16 岁的 Sah 夺得国际奥林匹克数学竞赛(IMO)的金牌,次年他进入 MIT 求学。
Ashwin Sah
在 MIT 读书期间,有两个人对 Sah 的数学发展起到重要作用。第一个是离散数学大牛赵宇飞(Yufei Zhao)教授,他也是 Sah 的研究生导师。
第二个就是 Mehtaab Sawhney,他们在课堂上相遇并成为朋友。后来,二人一起做研究,共同探讨离散数学领域内的多个主题,如图论、概率论和随机矩阵的属性。2017 年底,Ashwin Sah 和 Mehtaab Sawhney 在(MIT)读本科时相识。从那时起,两人一起编写了令人难以置信的 57 个数学证明,其中许多在各个领域产生了深远的影响。
Mehtaab Sawhney
Mehtaab Sawhney 现在是哥伦比亚大学助理教授。他的研究兴趣包括组合学、概率和理论计算机科学等等。 开发板商城 天皓智联 TB上有视觉设备哦 支持AI相关~ 大模型相关也可用
...
#FancyTech的技术路径
以「垂直模型」引领AIGC商业化落地
我们正在见证又一轮技术革新,这一次是 AIGC 为个体提供表达自我的工具,让创作变得更加容易和普及,但背后的推动力却并不是「大」模型。
两年以来,AIGC 技术的发展速度超过所有人的想象,席卷了从文本、图像到视频的各个领域。关于 AIGC 商业化路径的讨论从来没有停止过,其中,有共识也有路线分化。
一方面,通用模型的强大能力令人惊叹,在各行各业展示出应用潜力。特别是 DiT、VAR 等架构的提出,让 Scaling Law 实现了从文本到视觉生成领域的跨越。在这一法则的指引下,很多大模型厂商朝着增加训练数据、算力投入和堆积参数的方向持续前进。
另一方面,我们也看到,通用模型并不意味着「通杀」,面对很多细分赛道的任务,一个「训练有素」的垂直模型反而能够取得更好的效果。
随着大模型技术进入落地加速期,后一种商业化路径获得的关注快速增长。
这个演进过程中,一家来自中国的创业公司 FancyTech 脱颖而出:它以面向商业类视觉内容生成的标准化产品快速拓展市场,比同行们更早一步验证了「垂直模型」在产业落地层面的优越性。
环顾国内大模型创业圈,FancyTech 的商业化战绩是有目共睹的。但较少为人所知的是,这家诞生仅几年的公司,凭借怎样的垂直模型和技术优势跑在了赛道前列。
在一次专访中,xxx和 FancyTech 聊了聊他们正在做的技术探索。
FancyTech 发布视频垂直模型 DeepVideo
如何突破行业壁垒?
一般来说,在通用模型的零样本泛化能力达到某个水准后,在其之上做微调就可用于下游任务。这也是当下很多大模型产品落地的打法。但从实际效果来看,仅仅是「微调」还不能满足产业应用需求,因为各个行业的内容生成任务都有自己的特定而复杂的一套标准。
通用模型或许能完成好 70% 的常规任务,但客户真正需要的是能 100% 满足需求的「垂直模型」。以商业视觉设计为例,以往的相关工作均由有长期积累的专业人士完成,且需要根据品牌方的具体需求进行设计和调整,其中涵盖大量的人工经验。比起美观度和指令遵循程度等指标,「商品还原度」是这项任务中品牌方更为重视的一点,也是品牌方是否愿意付费的决定因素。
**在自研面向商业图像 / 视频的垂直模型过程中,FancyTech 将核心挑战拆解开来:如何让商品足够还原且融入背景,特别是在生成视频中,实现商品的运动可控且不形变。**


大模型技术发展到今天,对于应用层来说,走开源或闭源的路线已经不是最核心的问题。FancyTech 的垂直模型基于开源的底层算法框架,叠加自有的数据标注重新训练,仅需几百张 GPU 持续训练迭代即可取得好的生成效果。相比之下,「商品数据」和「训练方式」这两个因素对于最终的落地效果更为关键。
**FancyTech 在积累海量 3D 训练数据的前提下,引入了空间智能的思路指导模型的 2D 内容生成。**具体来说,在图像类内容生成上,团队提出「多模态特征器」保证商品的还原,以特殊的数据采集保证商品与背景的自然融合;在视频类内容生成上,团队重建了视频生成的底层链路,定向地设计框架和进行数据工程,从而实现以商品为核心的视频生成。
真・降维打击:「空间智能」如何指导 2D 内容生成?
很多视觉生成类产品的效果之所以不尽如人意,核心原因就在于目前的图像和视频生成模型往往基于 2D 训练数据进行学习,并没有理解真正的物理世界。
这一点在领域内已形成共识,部分研究者甚至认为,在自回归学习范式下,模型对世界的理解始终处于浅层。
但在商业视觉生成这项细分任务上,要想增强模型 3D 物理世界的理解、更好地生成 2D 内容,并非完全无解。
FancyTech 将「空间智能」领域的研究思路迁移到了视觉生成模型的构建中。与一般生成式模型不同,空间智能的思路是从大量传感器获取的原始信号中学习,对传感器获取的原始信号进行精确标定,以赋予模型感知和理解现实世界的能力。
因此,FancyTech 以激光雷达扫描替代传统摄影棚拍摄,积累了大量的体现商品融入前后差异的高质量 3D 数据对,并将 3D 点云数据与 2D 数据结合起来共同作为模型训练数据,增强模型对现实世界的理解。
我们知道,在任何视觉内容的生成中,光影效果的塑造都是极具挑战性的任务。光照、发光体、逆光、光斑等元素能够让画面的空间层次感更强,但这对于生成式模型来说是个很难理解的「知识点」。
为了收集尽可能多的自然光影数据,FancyTech 在每个环境中建立了数十盏亮度和色温均可调节的灯,意味着海量数据中的每一对都可以叠加多盏灯及不同亮度和色温的变化。

这种高强度的数据收集模拟了真实拍摄场景的灯光,使其更加符合电商场景的特点。

结合高质量的 3D 数据积累,FancyTech 在算法框架上进行了一系列创新,将空间算法与图像、视频算法有机结合,让模型更好地理解核心物体与环境的交互。
在训练过程中,模型可以在一定程度上「涌现」出对物理世界的理解,对三维空间、深度、光的反射和折射,以及光在不同介质、不同材质中运行的结果都有更深的认知,最终实现了生成结果中商品的「强还原」和「超融合」。
「强还原」和「超融合」背后,有哪些算法创新?
面向常见的商品场景图像生成任务,现阶段的主流方法主要用贴图的方式保证商品部分的还原度,然后基于 Inpainting 技术实现图片场景的编辑。用户选定需要改动的区域,输入 Prompt 或者提供参考图像,以引导商品场景生成。这种方法的融合效果较好,缺点是场景生成结果的可控性不高,比如不够清晰或者过于简单,保证不了单次输出的高可用率。
针对当前方法无法解决的问题,FancyTech 提出了一种自有的「多模态特征器」,在多种维度上提取商品特征,然后使用这些特征生成融入后的场景图。
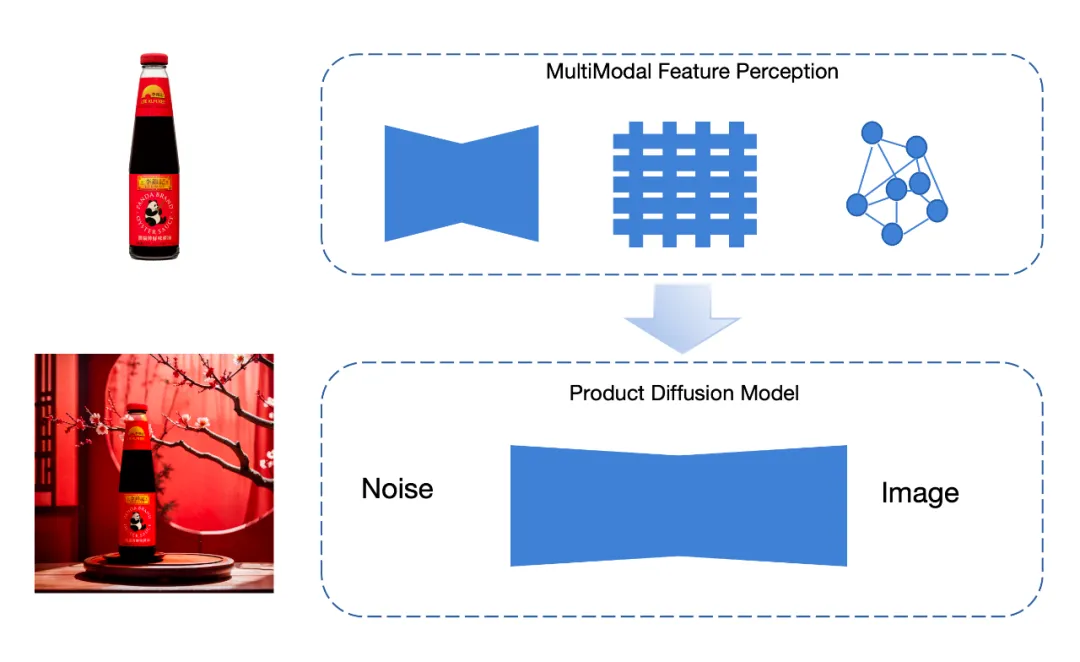
提取特征的工作可分为「全局特征」和「局部特征」,全局特征包括商品的轮廓、颜色等要素,使用 VAE 编码器提取;局部特征包括各处商品细节,使用图神经网络提取。图神经网络的一大好处是可以提取商品中各关键像素的信息以及关键像素间的关系,提高对于商品内部的细节还原。
在柔性材质商品的内容生成中,这种方法获得的效果提升显著:
相比于图像,视频的生成还涉及商品本身的运动控制及其带来的光影变化。对于通用的视频生成模型来说,难点在于无法针对视频中的某个部分进行独立保护。为了解决这个问题,FancyTech 将任务拆解为「商品运动生成」和「视频场景融入」两条支线。
- 第一步,FancyTech 设计了一些针对性的运动规划方案,以控制商品在画面中的运动,相当于预先「定住」商品在视频每一帧的画面;
- 第二步,通过控制模块实现视频可控生成。控制模块采用了灵活的设计,可兼容 U-net、DiT 等不同架构,便于扩展优化。
在数据层面,除了使用 FancyTech 的特有商品数据资源以提供控制训练和商品保护之外,还加入了多个开源数据集以保证场景泛化能力。训练方案结合了对比学习、课程学习,最终实现了对于商品的保护效果。
让 AIGC 时代的红利
从垂直模型开始走向更多普通人
无论是「通用」还是「垂直」,两条路线的终点都是商业化问题。
FancyTech 垂直模型落地最直接的受益者是品牌方,以往,从策划、拍摄、剪辑,一段广告视频的制作周期可能长达几个星期。但在 AIGC 时代,创作这样一段广告视频只需要十几分钟而已,成本甚至也只需要原来的五分之一。
凭借着海量独有数据和行业 Know-how 的优势,FancyTech 通过垂直模型的优势赢得国内外广泛的认可,与韩国合作伙伴携手签约了三星和 LG;与东南亚的知名电商平台 Lazada 开启合作;在美国,受到了 Kate Sommerville 和 Solawave 等本土品牌的青睐;在欧洲,荣获了 LVMH 创新大奖,并与欧洲客户深入合作中。
在核心的垂直模型之外,FancyTech 还提供了 AI 短视频全链路自动发布和数据反馈的能力,驱动商品销售持续增长。
更重要的一点是,**垂直模型让普通大众利用 AIGC 技术提高生产力的路径具像化了。**比如,一个街边传统照相馆在不增加专业设备和专业人员的情况下,借助 FancyTech 的产品,即可完成从简单人像拍摄到专业级商业视觉素材制作的业务转型。
现在只要拿起手机,几乎每个人都能拍视频、录音乐,并与全世界分享他们的创作。想象一个 AIGC 再一次释放个人创造力的未来 ------
让普通人跨越专业门槛,更轻松地将创意化为现实,从而让每个行业的生产力实现飞跃,并产生更多的新兴产业,AIGC 技术带来的时代红利,从这一刻起开始真正走向普通人。
...