英伟达的技术报告一般细节都比较多,本次开源的12B的参数模型-Nemotron Nano V2 VL专为文档理解、长视频理解及推理任务而设计。下面来快速过一下。
模型架构
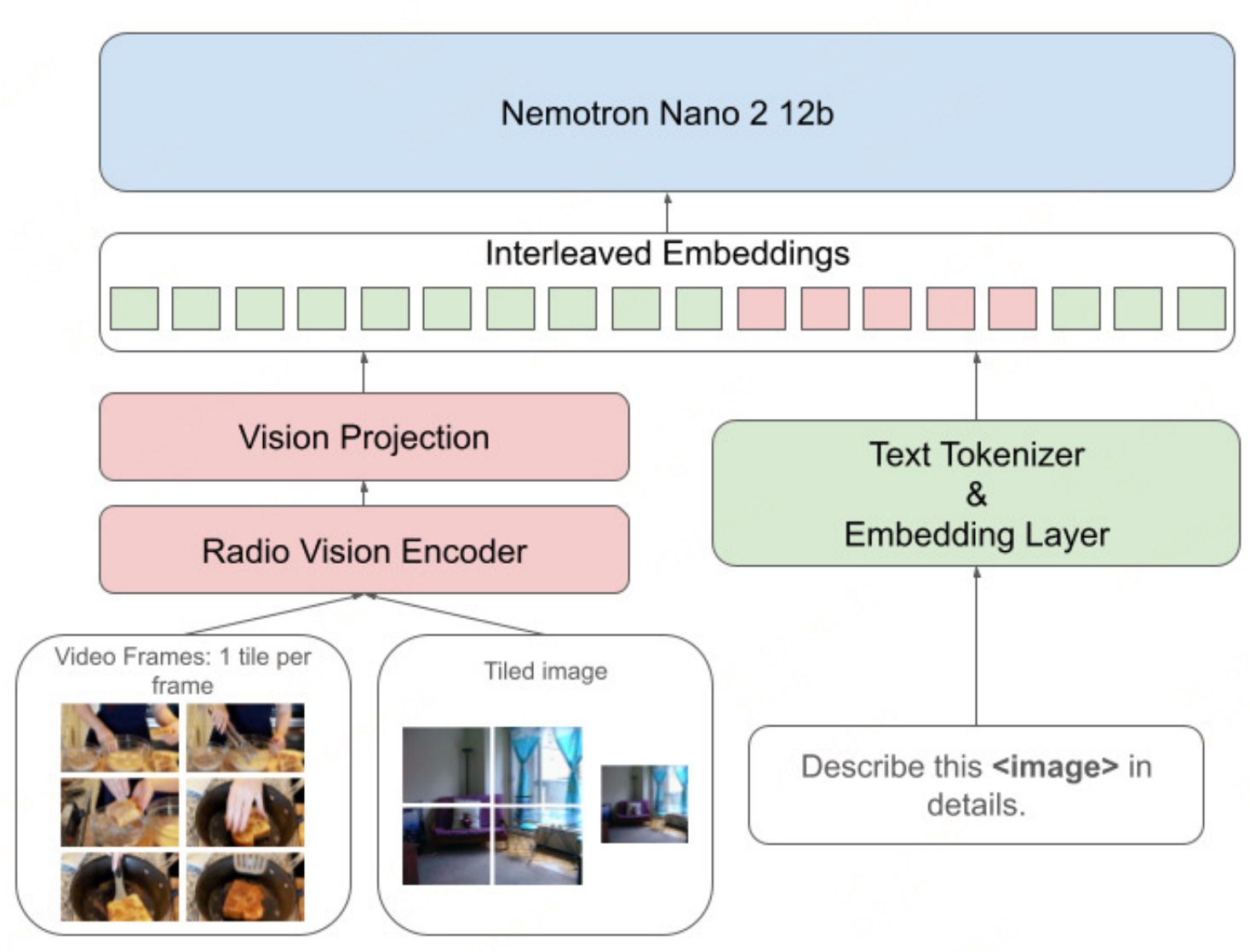
遵循"视觉编码器+MLP投射器+语言模型"架构。
- 视觉编码器:基于RADIOv2.5的c-RADIOv2VLM-H版本初始化,负责提取图像/视频的视觉特征。
- MLP投射器:作为跨模态桥梁,实现视觉特征与文本特征的对齐。
- 语言模型:基于Nemotron-Nano-12B-V2(混合Mamba-Transformer架构),提供强文本推理能力,支持最长311296 tokens的上下文长度。
图像视频输入处理策略上:

与英伟达之前的一个模型(《【多模态&LLM】英伟达NVLM多模态大模型细节和数据集》)相似,采用动态分辨率分块(tiling)策略,按长宽比 resize 后分割为512×512非重叠块,通过像素洗牌下采样将每个块的视觉token从1024缩减至256,最多支持12个块,同时保留单块缩略图捕捉全局信息。
- 视频处理:每秒提取2帧,最长视频限制128帧(超过64秒则均匀采样),每帧按单块处理,结合高效视频采样优化推理效率。
数据集


很有开源精神,Nemotron VLM Dataset V2(涵盖图像描述、VQA、OCR、文档提取等多任务)大部分已公开。
数据增强手段
- 对无明确标注的数据集,用Qwen2.5/Qwen3系列模型从OCR结果或描述中生成问答对。
- 补充推理轨迹:融合人类标注和模型生成(Qwen2.5-VL-32B、GLM-4.5V等)的推理轨迹,强化复杂任务推理能力。
- 多语言扩展:包含 Wikimedia 多语言语料和翻译后的文档数据,支持跨语言 multimodal 任务。
训练方法
采用"多阶段递进优化"策略,在保留文本推理能力的同时,逐步提升视觉理解和长上下文处理能力。训练一览表如下:
| 阶段 | 目标 | 上下文长度 | 训练数据量 | 操作 |
|---|---|---|---|---|
| Stage 0 | 跨模态对齐预热 | 16K | 220万样本(360亿token) | 冻结视觉编码器和语言模型,仅训练MLP投射器 |
| Stage 1 | 基础多模态能力构建 | 16K | 3250万样本(1125亿token) | 解冻全量参数,融合文本推理数据和多模态数据 |
| Stage 2 | 视频/长上下文扩展 | 49K | 1100万样本(550亿token) | 加入视频和多页文档数据,扩展上下文长度 |
| Stage 3 | 代码推理能力恢复 | 49K | 100万样本(150亿token) | 仅用代码推理数据训练,修复前阶段文本能力退化 |
| Stage 4 | 超长上下文优化 | 311K | 7.4万样本(120亿token) | 融入长上下文数据,适配超长文本/视频任务 |
参考文献:NVIDIA Nemotron Nano V2 VL,https://arxiv.org/pdf/2511.03929v2