文章目录
- 摘要
- Abstract
- 一、自然语言处理
-
- [1. 预训练-微调](#1. 预训练-微调)
-
- [1.1 BERT](#1.1 BERT)
- [1.2 GPT](#1.2 GPT)
- [1.3 微调优化](#1.3 微调优化)
- [2. prompt learning](#2. prompt learning)
-
- [2.1 Template(模板)](#2.1 Template(模板))
- [2.2 Verbalizer(表述器)](#2.2 Verbalizer(表述器))
- [2.3 Template与Verbalizer 核心关联](#2.3 Template与Verbalizer 核心关联)
- [2.4 Template和Verbalizer的构造](#2.4 Template和Verbalizer的构造)
- [2.5 优化预训练](#2.5 优化预训练)
- [3. delta tuning](#3. delta tuning)
-
- [3.1 Delta learning三种类别](#3.1 Delta learning三种类别)
- [3.2 delta tuning相关说明](#3.2 delta tuning相关说明)
- [4. OpenPrompt](#4. OpenPrompt)
-
- [4.1 API的设计及工作流程](#4.1 API的设计及工作流程)
- [4.2 常用template汇总:](#4.2 常用template汇总:)
- 总结
摘要
本周主要学习大模型微调的优化方法------prompt learning和delta tuning。Prompt learning学习了其核心组成template和verbalizer和它们的构造,还学习了将prompt learning融入预训练实现对预训练的优化。Delta tuning学习了含有的三种类别以及delta tuning的优势。
最后还学习了prompt learning的工具包OpenPrompt。了解OpenPrompt的api设计结构。工作流程以及常用template。
Abstract
This week, I mainly learned about the optimization methods for large model fine-tuning: prompt learning and delta tuning. In prompt learning, I studied its core components---templates and verbalizers, as well as their construction. I also learned how to integrate prompt learning into pre-training to optimize the pre-training process. In delta tuning, I learned about its three categories and the advantages of delta tuning.
Finally, I studied OpenPrompt, a toolkit for prompt learning, including understanding its API design structure, workflow, and commonly used templates.
一、自然语言处理
1. 预训练-微调
预训练Pre-training搭建通用能力基础,微调 Fine-tuning适配具体任务需求。
1.1 BERT
微调
1,字符级别任务
无论输入句子数量的多少,会对每个字符token产生一个表示representation,并对representation进行分类。
例如,对token进行分类,判断一个token是上下文还是一个实体,因此会将token的representation送入一个额外分类层,实现对每一个token的分类。
2,句子级别任务
CLStoken送入(CLStoken代表句子级别的语义)接一个分类层再进行下一步的微调
注:
对实体和上下文的说明:
实体:实体是指文本中具有特定意义和指代的对象,通常为名词性短语,如人名、地名、组织机构名、时间、日期等。
上下文:上下文是指围绕某个词或短语的周围文本内容,BERT 能够利用双向的上下文信息来理解文本的语义。
具体任务:关系抽取(多种方法):
具体案例:判别清华大学与背景的关系
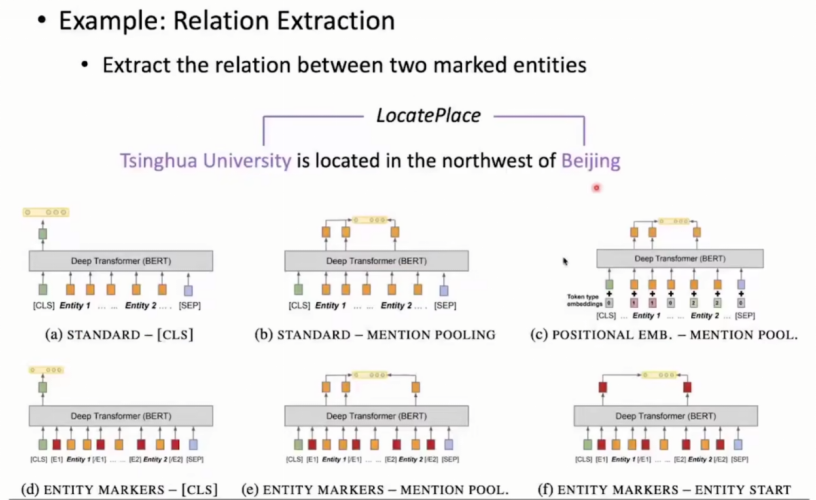
(a)将CLS直接输入,进行分类
(b)mention pooling。将CLS,SEP间的所有实体token聚合送入分类层
(c) mention pooling+对位置信息的考虑。对实体进行位置排序,上下文所有字符标记为0,实体加上token time embedding,即第一个实体标记1,第二个标记2。再和hidden representation相加进行分类
(d)entity markers。使用两个特殊字符包含实体,并且两个字符可能不存在于词表中,需要申请。此时模型可以注意到特殊字符,以便模型更好地理解文本结构和语义关系,再将CLS送入分类层
(e),(f)在(b),(c)基础上,添加特殊字符划分实体。
1.2 GPT
生成式模型:每一个生成的位置都取决于前n-1个token概率。因此直接使用最后一层token的representation接一个分类层,公式如下:

对于不同任务的处理方式:
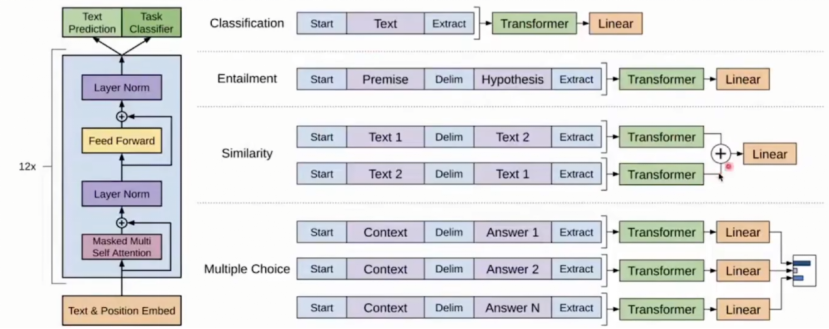
对于相似性任务,需要将两个结果求和后再进行线性层变换。
1.3 微调优化
如何高效微调大模型?
从task和data角度:使用prompt learning提高
优化角度:delta learning,使用小部分参数优化大模型。
2. prompt learning
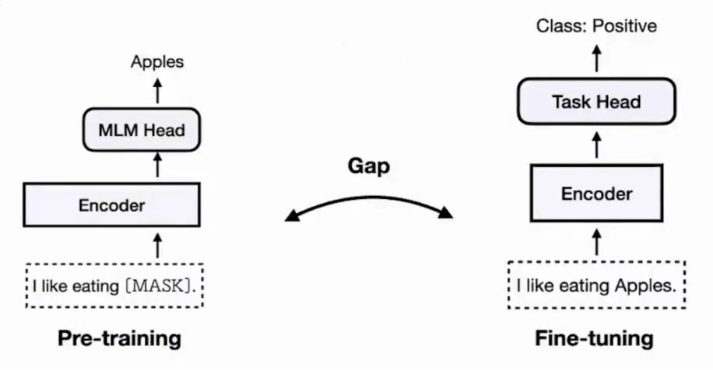
pre-training:训练通用模型,通常使用大规模无标注数据训练基础模型。不针对某类户型(任务),但能支撑各种后续改造,核心是学习数据的通用规律(如NLP中语言的语法、语义、常识关联)。
fine-tuning:适配具体任务,通常使用小规模有标注任务数据在预训练模型基础上继续训练。基于现成的框架,调整细节,核心是把通用能力适配到具体任务(如文本分类、情感分析、实体识别)。
图中主要为预训练模型预测mask的token,fine tuning根据pre training的结果对文本进行情感预测。
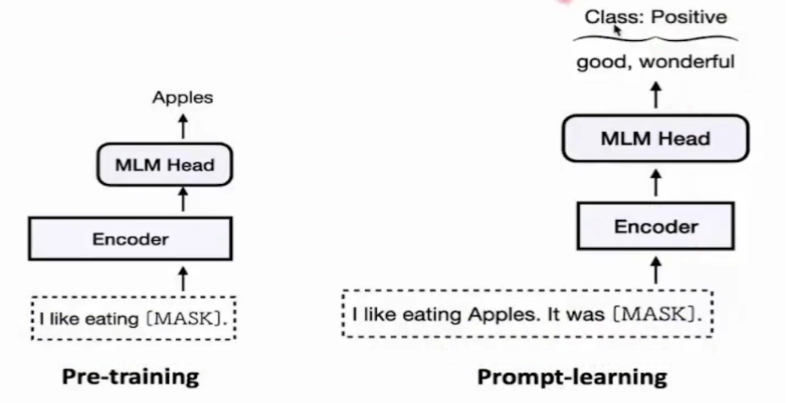
引入prompt learning(消除pre training与 fine tuning间任务的明显区分)。图中可以看出prompt learning也对文本进行mask,但是mask为任务部分。
Prompt learning小样本 / 零样本学习的核心组件为Template,Verbalizer。
2.1 Template(模板)
核心定义:将原始任务(如分类、问答)的输入文本,套入固定的句式框架,转化为模型熟悉的"自然语言描述",本质是"任务格式化工具"。
作用:明确任务意图(如"判断情感""提取实体"),让模型无需额外指令就能识别任务类型。
具体举例:
情感分类任务(输入:"这部电影超好看"):
模板 → "句子'{text}'的情感是正面、负面还是中性?答案:{label}"
填充后 → "句子'这部电影超好看'的情感是正面、负面还是中性?答案:正面"
2.2 Verbalizer(表述器)
核心定义:将任务的"抽象标签"(如分类任务的"0/1"、问答任务的"正确/错误")映射为"自然语言词汇/短语",本质是"标签具象化工具"。
作用:让模型的输出与任务标签对齐(模型只能生成自然语言,无法直接输出"0/1"这类抽象标签)。
具体举例:
情感分类标签(0=负面,1=正面):Verbalizer → {0: "负面", 1: "正面"}
文本匹配标签(0=不匹配,1=匹配):Verbalizer → {0: "不相关", 1: "相关"}
2.3 Template与Verbalizer 核心关联
Template负责"包装输入",Verbalizer负责"解码输出",两者配合实现"任务→模型可处理格式"的完整转化。比如:
原始任务(文本分类)→ 模板包装输入 → 模型生成自然语言答案 → Verbalizer映射为标签 → 输出最终结果。
优势:不用考虑多任务间的区别。同样一套数据,根据不同的prompt设置或者不同verbalizer选择的不同可以把任务看成不同的分类,因为似乎可以用prompt将所有任务重新组成一个新的范式
2.4 Template和Verbalizer的构造
Template(模板):定义输入输出的结构
核心作用:规范输入与输出的映射关系,减少模型理解歧义。
构造原则:
1,明确任务指令:清晰说明模型需要完成的任务(如分类、翻译、推理等)。
2,预留输入占位符:用特殊符号(如 INPUT、{text})表示待填充的原始输入。
3,指定输出格式:如果需要特定格式(如 JSON、标签、短句),需明确约束。
4,加入示例(可选):少样本场景中,在模板中插入少量(1-5 个)输入输出对作为示范。
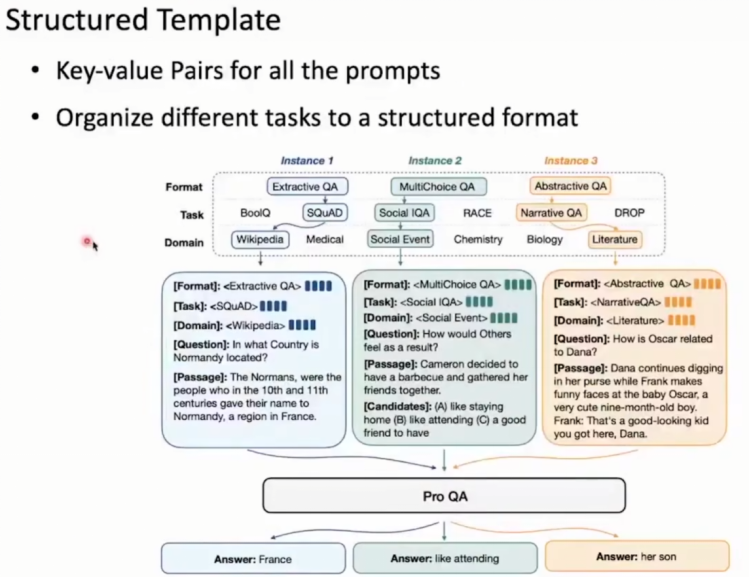
所有输入变为键值对,用于提醒模型要做什么。虽然许多任务使用统一规范范式,但给出不同提示,让模型作出区分。
补充:
键值对:基本的数据表示。分为以下三类表示:
第一种类型是scalar(标量),也就是一个单独的string(字符串)或数字(numbers),比如"北京"这个单独的词。
第二种类型是sequence(序列),也就是若干个相关的数据按照一定顺序并列在一起,又叫做array(数组)或List(列表),比如"北京,东京"。
第三种类型是mapping(映射),也就是一个名/值对(Name/value),即数据有一个名称,还有一个与之相对应的值,这又称作hash(散列)或dictionary(字典),比如"首都:北京"。
Json格式举例:

Verbalizer(表述器):定义输出与标签的关联
将模型的自然语言输出(如 "是的""好的")映射到任务的目标标签(如 "1""正例"),尤其在分类任务中常用.
Template 与 Verbalizer 的结合使用
在实际任务中,两者通常配合使用:
用 Template 将输入和任务指令结构化,引导模型生成自然语言输出;
用 Verbalizer 将模型输出映射到目标标签,完成任务闭环。
2.5 优化预训练

Prompt learning引入学习策略:
模型训练过程:
(1)中小型模型、few-shot setting:预训练------prompting组织数据,处理数据------微调所有参数
注:few-shot setting中,大语言模型通过少量示例即可完成新任务,无需频繁更新模型参数。
(2)Delta tuning角度:预训练------添加soft prompts(即一些token)------冻结模型并且只训练soft prompt embedding
注:Soft Prompts(软提示)是与Hard Prompts(硬提示)
硬提示:由人工设计的固定文本(如情感标签"积极"),需根据任务手动调整。
软提示:通过向量空间优化动态调整(如输入层参数优化),无需人工干预。
(3)Instruction tuning:和prompt data(提示数据)一起预训练------做zero-shot推理
如何通过改进预训练过程,让语言模型更好地适配下游任务(尤其是零样本或少样本场景)
核心思路:将 提示学习(Prompt Learning)的关键要素融入预训练,增强模型的泛化能力和任务适应性。
(1)Soft token可以加入预训练:优化提示学习的初始化
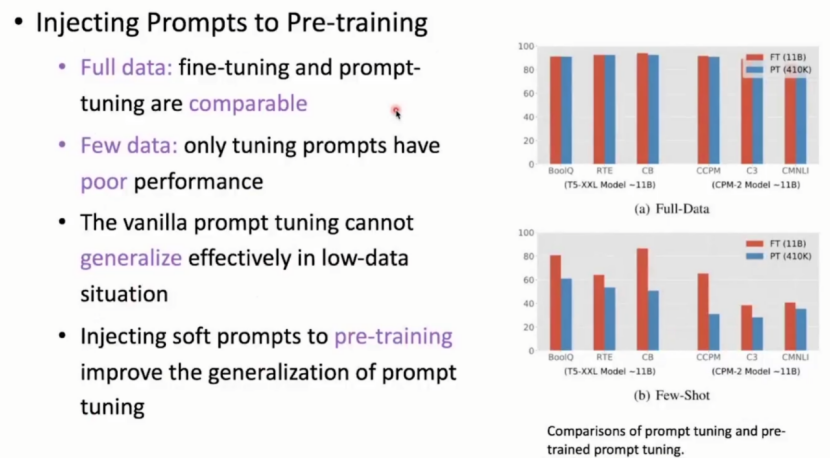
如果在下游任务中才随机初始化 Soft token,由于其参数是 从0开始学习,需要大量任务数据才能收敛,且容易陷入局部最优(优化空间小)。因此放入预训练中,使其在预训练中就开始训练,此时它有更好的初始化,会在下游任务拥有更好的表现。
(2)文本 prompted data 加入预训练:增强模型的任务泛化能力
文本 prompted data指的是用提示模板(Prompt Template)格式化后的训练数据。例如,将"情感分类"任务的数据改写成 "这句话的情感是 正面 / 负面",将 "翻译" 任务改写成 "中文:文本 英文:译文" 等,让数据呈现出 "任务描述 + 输入 + 输出" 的统一范式。
目标:让模型在预训练阶段就接触大量不同任务的提示化数据prompt data (当拥有1300亿数据训练60个任务),学习 "根据提示推测任务类型并输出结果" 的能力。这样,当遇到未见过的新任务时,模型能通过相似的提示范式(如 "任务描述:输入 → 输出")快速理解任务需求,实现零样本推理。
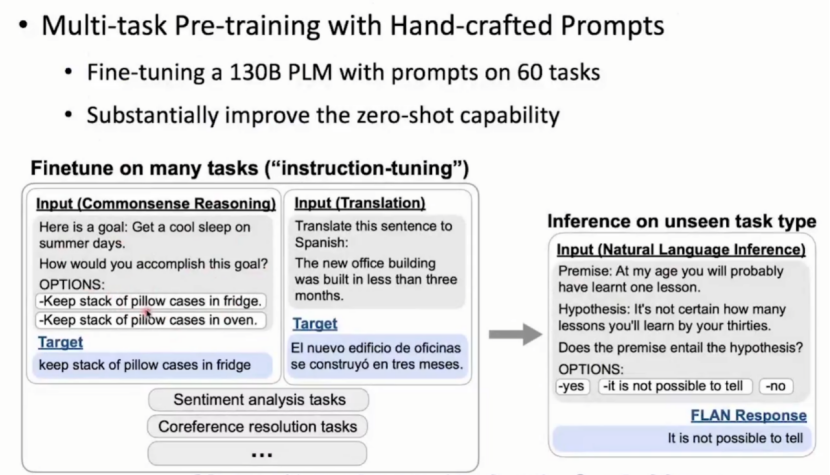
现象解释:随着推测数据规模的不断增大,可能一开始模型推测表现没有传统模型优秀,但是到达一定数量后训练效果有质的提升。考虑原因,预训练数据过大占满容量,没有大量多余空间在未见过的任务上inference。
总结
将提示学习的参数(Soft token)和任务的通用范式(prompted data)提前放入预训练,让模型在预训练阶段就具备 "理解提示、适配任务" 的基础能力。
目标是:减少下游任务对标注数据的依赖,让模型仅通过少量提示(甚至零样本)就能解决新任务。
3. delta tuning
模型不变只微调小部分参数实现对整个模型的优化。
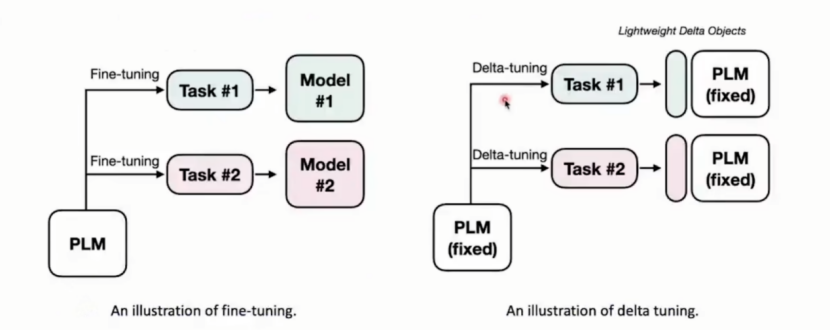
假设对于原来感知语言模型(PLMs)的fine tuning可能需要对每个任务进行优化,使用delta tuning可能就是对每个任务优化出来一些参数,因此大大减少内存使用
3.1 Delta learning三种类别
(1)Addition-based(增量式的):将不存在于模型的额外的参数插入,并只训练插入的参数,模型其余参数保持不变。
(2)Specification-based(指定式的):指定训练哪些参数,其余参数保持不变。
(3)Reparameterization-based(重参数式的):给微调一个基本假设,认为可以在低维或低秩矩阵中完成,这样可以使用少量的参数完成微调
Addition-based
方法一:Adapters
在transformer框架的每一层加入adapter,并且训练的时候只训练adapter,训练的数据大概是总体的0.5%-8%
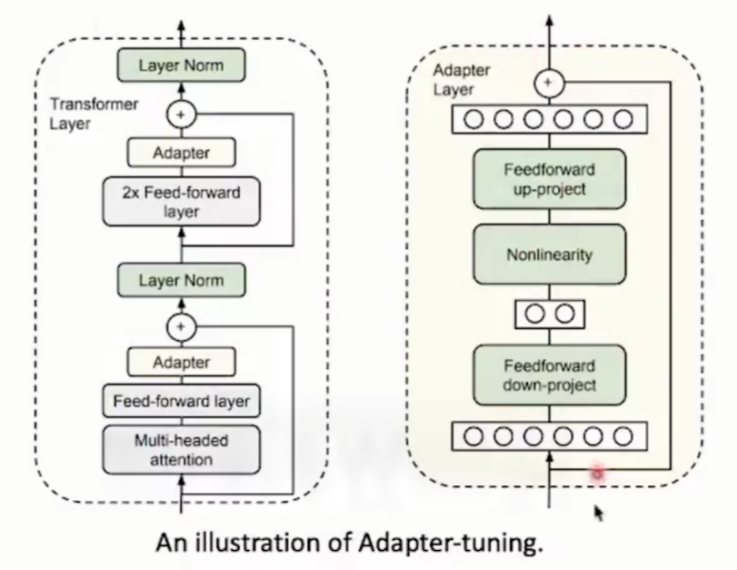
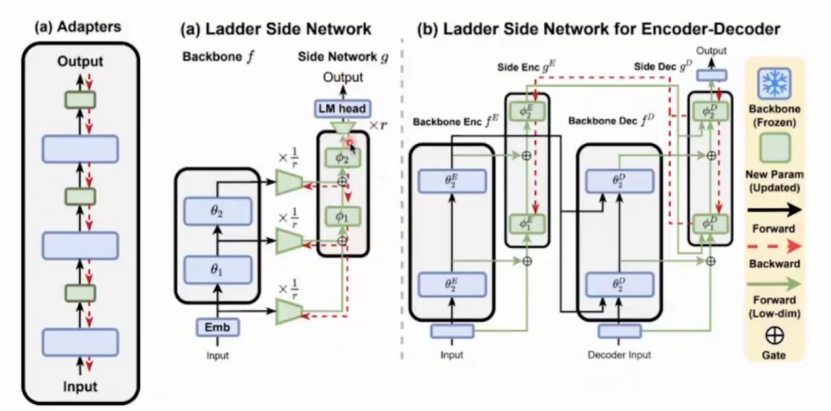
方法二:prefix-tuning
prefix-tuning:与prompt learning相关的增量式
在每个 Transformer 层的输入前添加可调的连续向量soft token(前缀),仅优化这些soft token前缀参数。
在transformer中每一层的隐藏状态hidden states
Specification-based
方法:BitFit
只去微调transformer中的b(偏置值)

Reparameterization-based
方法一:低维
认为优化过程可以在低维空间上完成,可以将120个任务优化压缩到一个低维子空间,子空间可能只有5维,然后在这5维空间训练,最后放缩到原本维度上。可以发现在5维空间表现得好的数据在原本120维度上也表现得很好。
方法二:LoRA(Low-Rank Adaption):低秩
可能实际并不低秩,但会强制拆分为低秩矩阵。例如:
R0(1000×1000 )= R1(1000×2)×R2(2×1000)
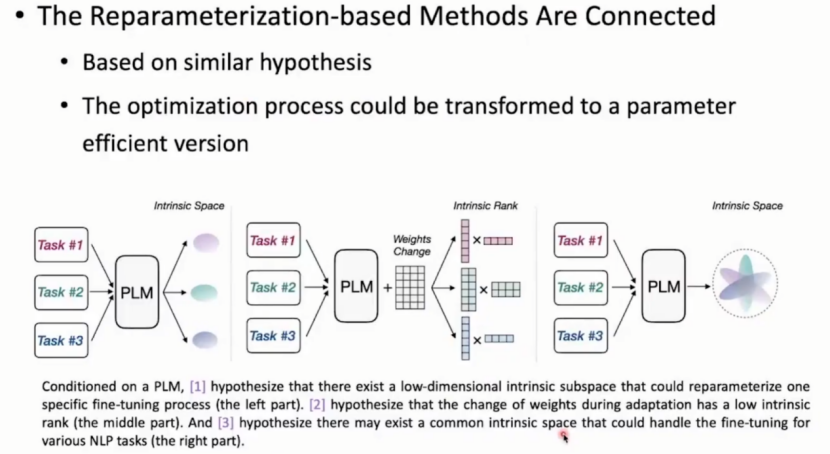
总结重参数方法的相似点:模型优化可以用很小的代价完成。
3.2 delta tuning相关说明
Delta tuning各类型间也有联系,引入统一tuning框架。将三种Delta tuning(Adapt,LoRA,Prefix Tuning)使用统一框架联系起来
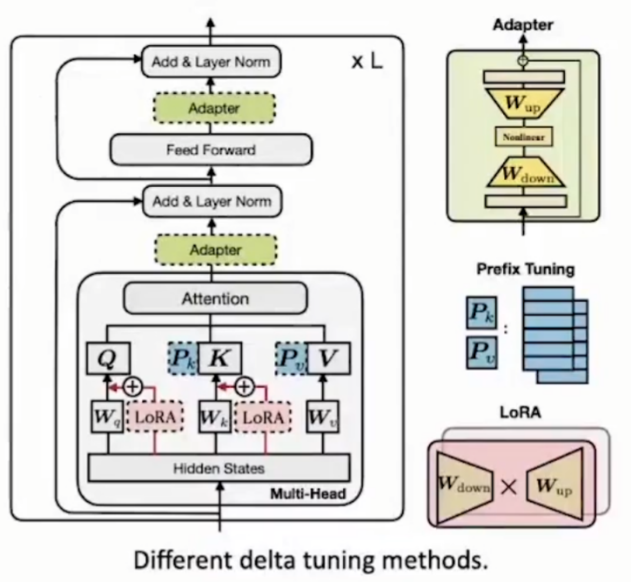

本质上各种delta tuning是做同一件事情:大模型不动,微调少部分的delta objects。只是因为函数不同,修改的位置不同导致拥有不同名字。
对delta tuning理论分析:
在低维子空间中寻找一个低维表示,或者是低维函数空间寻找低维表示。当满足一定下界后,去找该类表示,绝大多数参数不变。

从最优控制角度看,神经网络的反向传播等价于在最优控制中去寻找最优控制器的过程,delta tuning 可以看作是为特定下游任务寻求预训练语言模型的最佳控制器的过程。
最优结构探索
不同任务适用于不同的结构,将delta tuning插入不同位置并进行组合,通常比单一方法更有效,但并不存在一种在所有设置下都最优的组合策略。
使用自动机器学习的方法去搜索结构,使模型达到最优解,模型的训练效果和全参数微调差不多。这种情况下参数量减到很小完成delta tuning,使用更少的参数探索极限。
可迁移性
具有良好的可迁移性:各个方法的表现情况都差不多
节省计算空间,储存空间:与传统的全参数微调不同,delta tuning 中需要调整的参数数量远远小于模型的总参数数量,这使得在训练和存储过程中,所需的计算空间和储存空间都大大减少。
4. OpenPrompt
OpenPrompt
核心目的:通过统一的一套范式去定义不同的模板template、表述器verbalizer去实现不同的任务
4.1 API的设计及工作流程

PromptDataset(数据处理模块)
主要功能:输出一个template包裹上一个输入后被tokenize并对tokenizer封装。此时数据可以直接输入prompt模型
各个部分完成任务:
Template:定义提示词的模板结构,将原始示例转化为带提示的输入。会拥有一些soft token。
Tokenizer:将文本序列化,调用预训练语言模型PLMs的分词器,将原始文本拆分为 Token。
PromptTokenizer:对Tokenizer的封装,结合提示模板Template对数据进行进一步处理,并且对于不同的pre-trained模型会有不同的变换方式。
PromptModel (模型与提示模块)
主要功能:是对TemplateEmbeddings、PLMs、Verbalizer的封装,形成完整的提示学习模型,可直接调用它进行训练和推理。
各个部位的任务:
TemplateEmbeddings:将Template生成的提示文本PromptTokenizer转化为嵌入向量,作为预训练模型的输入部分。
PLMs:预训练语言模型(如:BERT、GPT、T5),负责理解带提示的输入并输出语义表示。
Verbalizer:将 PLMs 输出的词的概率分布映射到任务的标签空间。
例如,情感分析中把 "正面""负面" 等词的概率转化为最终的情感类别。
PromptTrainer(训练模块)
PromptTrainer:封装了训练逻辑,对接 PyTorch 的训练 pipeline,负责模型的训练、验证和测试流程,让用户无需关注底层训练细节,只需传入PromptModel和PromptDataset即可启动训练。
工作流程:
数据侧:Dataset提供原始数据------Tokenizer和PromptTokenizer对数据分词、结合Template生成带提示的输入------最终形成PromptDataset供模型使用。
模型侧:TemplateEmbeddings将提示模板转化为向量------输入PLMs进行语义理解------Verbalizer将模型输出映射到任务标签------整合为PromptModel。
训练侧:PromptTrainer调用PromptModel和PromptDataset,完成模型的训练和评估。
标签词label words的生成方式:
自定义:对于每个类设计几个标签词。例如:"情感分析"中,"棒极了","好"属于"正面"这个类别。
生成式:指通过模型自动生成与目标类别语义相关的标签词,而非完全依赖人工手动定义。本质是利用预训练语言模型(PLM)的语义理解能力,根据类别描述自动生成一批与该类别高度相关的词语,再通过筛选或打分得到最终的标签词。核心流程可概括为 "类别描述→模型生成→筛选优化"。例如:写出表示"惊喜"的成语,则会生成"惊喜万分", "喜出望外", ...
4.2 常用template汇总:

A:主题分类的硬提示
" a {"mask"} news: {"meta": "title"} {"meta": "description"} "
任务是 "新闻主题分类",模板结构为 "a {mask} news: 新闻标题 新闻描述"。
具体举例:输入标题:"苹果发布新款 iPhone";描述:"搭载 A17 芯片,支持 5G",模板会生成 "a {mask} news: 苹果发布新款 iPhone 搭载 A17 芯片,支持 5G",模型需预测{mask}处的主题(如 "科技")。
B:实体类型识别的硬提示
" {"meta": "sentence"}. In this sentence, {"meta": "entity"} is a {"mask"} "
任务:识别句子中实体的类型(如 "人名""地名""机构名")。
具体举例:句子 "马云在杭州创办了阿里巴巴"、实体 "马云",模板生成 "马云在杭州创办了阿里巴巴. In this sentence, 马云 is a {mask}",模型需预测{mask}为 "人名"。
C:基于文本令牌初始化的软提示
" {"meta": "premise"} {"meta": "hypothesis"} {"soft": "Does the first sentence entails the second ?"} {"mask"} {"soft"}. "
任务:自然语言推理(判断前提是否蕴含假设)。
说明:{"meta": "premise"}和{"meta": "hypothesis"}填入 "前提句" 和 "假设句";{"soft": "..."}是初始化的软提示向量(由文本 "Does the first sentence entails the second ?" 转化而来)。模型需在{mask}处预测推理结果(如 "entails""contradicts""neutral"),软提示向量会在训练中被优化,以更精准地引导推理任务。
具体举例:前提:"A man is playing a guitar."(一个男人在弹吉他);假设:"A person is making music."(一个人在制作音乐),模型的目标是预测mask向量处的输出,即 "Entails"(因为弹吉他属于制作音乐,前提蕴含假设)。
D:规模的力量
" {"soft": None, "duplicate": 100} {"meta": "text"} {"mask"} "
说明:任务可理解为 "文本分类或生成",将输入文本{"meta": "text"}重复 100 次后输入模型,借助大模型对长上下文的建模能力提升任务性能(如分类准确性)。
E:后处理脚本支持
" {"meta": "context", "post_processing": lambda s: s.rstrip(string.punctuation)}. {"soft": "It was"} {"mask"} "
后处理:对模型输出进行格式优化,此处是 "去除结尾标点"。
说明:{"meta": "context"}填入上下文文本;post_processing指定一个 lambda 函数,对输出结果去除结尾标点(如将 "great!" 处理为 "great")。软提示{"soft": "It was"}引导模型生成后续内容(如 "a good day"),后处理确保输出格式整洁。
补充:post-processing(后处理)
作用:优化模型输出的 "最后一公里"
Post-processing 是指在模型生成结果后,对输出进行修正、优化或格式调整,以提升结果的准确性、可读性和实用性。它是弥补模型缺陷(如重复生成、格式混乱、逻辑矛盾)的关键步骤。
主要功能:
1,重复惩罚(Repetition Penalty)
大模型在生成文本时容易陷入 "循环生成"(如连续输出 "很好很好很好...")。后处理通过降低已生成词的概率来避免重复。
2,格式标准化与结构化提取
模型生成的文本可能格式混乱(如日期、列表无规范结构),后处理通过规则或工具将其转换为统一格式。
3,逻辑一致性校验(RAG 系统常见)
在检索增强生成(RAG)中,模型可能生成与检索知识矛盾的 "幻觉" 内容。后处理通过自然语言推理(NLI)模型判断生成答案与知识的一致性。
4,敏感内容过滤
对生成文本中的政治、暴力等违规内容进行拦截,保障应用安全性。
F:共享软令牌的混合提示
混合提示:结合硬文本和软令牌,且多个软令牌共享参数(soft_id相同表示共享)。
" {"meta": "premise"} {"meta": "hypothesis"} {"soft": "Does"} {"soft": "the", "soft_id": 1} first sentence entails {"soft_id": 1} second? "
说明:任务仍是自然语言推理,模板中 "Does" 是硬文本,"the" 是软令牌且soft_id=1(表示该软令牌在 "first sentence entails {soft_id:1} second?" 中共享,即两处 "the" 的向量参数相同)。这种设计减少了待训练的软令牌数量,提升训练效率。
补充:soft token
Soft token:可训练的连续向量(而非人工设计的离散文本)。例如,为情感分析任务设计一组可学习的向量作为提示,模型通过训练优化这些向量,使其能精准引导输出 "正面" 或 "负面" 类别。
实现方式:用 PyTorch 的nn.Embedding层初始化一组向量,与输入文本的词嵌入拼接后输入大模型,训练时仅更新这组向量。
Soft token的选择:
"Soft"的选择(包括初始化方式、长度、优化策略等)直接影响模型性能。
1.初始化:优先用文本令牌初始化,小数据必选,大数据可尝试随机初始化。
补充:
文本令牌初始化:用自然语言文本(如任务描述、指令)的词向量作为初始软提示。例如,情感分析任务用文本"判断这句话的情感是:"的词向量初始化。
2.长度:从8-20 个向量起步,根据过拟合 / 欠拟合调整。
3.优化:资源有限时仅优化软提示,数据充足时联合优化顶层参数,学习率设为 1e-4 ~ 5e-3。
4.位置:优先前缀位置,生成式任务可尝试后缀。
5.混合策略:复杂任务建议结合硬提示文本,提升引导效果。
G:指定标题不被截断
" a {"mask"} news: {"meta": "title", "shortenable": False} {"meta": "description"} "
注意:指定 "标题" 字段在输入时不被截断(保持完整)。
说明:与示例 A 类似,但{"meta": "title", "shortenable": False}确保新闻标题在填入模板时不会因长度限制被截断,保证输入信息的完整性,从而提升分类准确性。
总结
本周对于prompt learning的学习还未加入代码部分,因此下周将加入代码学习。