论文地址:Aligning Language Models to Explicitly Handle Ambiguity
一句话讲:作者提出了一种名为"感知歧义性对齐"(APA)的新型对齐流程,旨在通过利用模型自身的内在知识,增强 LLM 处理 query 中歧义性问题的能力。该方法采用隐式信息增益指标来量化模型自身感知到的模糊性,使模型能够基于该指标通过对齐操作有效管理歧义/非歧义查询。
论文精读
不管是人跟人之间还是人跟 LLM 之间,沟通的时候其实经常会使用省略表达(省略词语或短语)或不精确表达(缺乏确切性),这可能导致基于不同假设或背景知识的人/LLM,对同样的输入产生不同的解读。因此,LLM 必须熟练处理查询中固有的模糊性以确保可靠性。
然而,即便是最先进的 LLM,在处理此类场景时仍面临挑战,主要源于以下障碍:
- LLM未被明确训练处理模糊性话语;
- LLM感知的模糊程度可能因知识储备不同而存在差异。
为解决这些问题,作者提出感知模糊性对齐(Alignment with Perceived Ambiguity, APA)方案------通过利用模型自身对模糊性的评估能力,建立 LLM 处理模糊查询的新型流程。
引言
歧义指的是某个表达可能具有多重含义的情况,用户可能带着明确的意图提出请求,但是由于领域知识不足或表达时疏漏,导致请求本身存在歧义。如果模型对这类歧义做出武断回应,就可能误读用户的真实意图,进而影响模型的可靠性。这种情况在需要高度可靠性的领域尤为明显,比如法律和医疗领域,误判可能导致严重后果。尽管歧义管理至关重要,但目前针对歧义进行稳健处理的解决方案仍存在显著研究空白。
正确处理模糊输入面临两大主要挑战:
- 模型并未被训练去显式表达模糊性。即便模型具备识别模糊性的能力,也需要通过其自身发出的明确线索(如表达不确定性或提供多种解释)来确认这种识别。
- 模型感知到的模糊程度会因其知识储备而异。以下图所示场景为例:初始查询"全国锦标赛"具有多重含义,可能指"全国网球锦标赛"或"全国高尔夫锦标赛"。若模型掌握所有可能含义的全面知识,就能识别出查询的模糊性(图1左)。但若知识储备有限,模型就会误判为明确查询(图1右)。因此,模型如何解读模糊性取决于其知识范围,我们将其定义为感知模糊性。
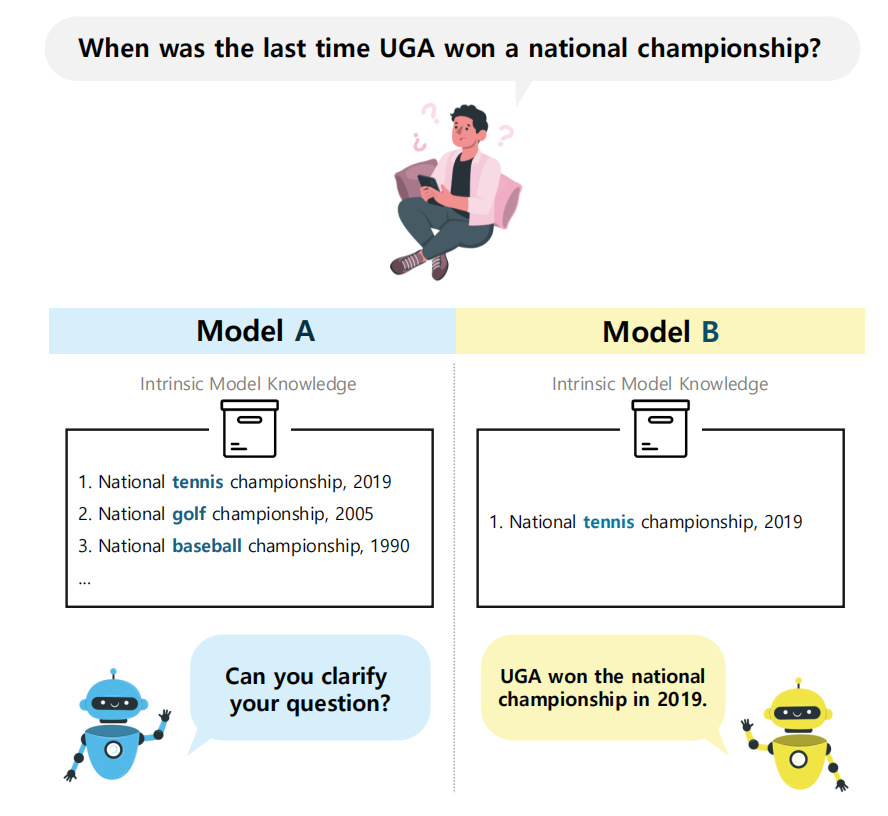
为解决这些问题,作者提出感知模糊性对齐(APA)方法,通过利用查询的感知模糊性,使模型能够显式处理模糊查询。具体而言,作者设计了一个代理任务,引导模型利用其内在知识对给定查询进行自消歧。随后,将消歧过程中获得的信息量化为模型感知输入模糊程度的隐性指标。对于选定的模糊查询及其消歧结果,模型会生成针对模糊性的澄清请求。最终,模型通过训练能够对模糊查询作出显式澄清请求。
此外,作者提出了三个数据集,为评估歧义问题构建了完整框架:歧义问答数据集(AmbigTriviaQA)、歧义网络问答数据集(AmbigWebQuestions)和歧义自由数据库问答数据集(AmbigFreebaseQA)。
作者的贡献可归纳为以下三点:
- 提出感知歧义对齐(APA)方法,使 LLM 能够通过感知歧义来显式处理模糊输入。
- 引入三个全新数据集------歧义问答数据集、歧义网络问答数据集和歧义自由数据库问答数据集,专门用于评估模型处理歧义的能力。
- 通过在多个问答数据集上的实证验证,证明 APA 方法能使模型有效处理歧义查询。
方法
作者提出的感知模糊性对齐(APA)是一个四阶段的对齐管道,如下图所示:
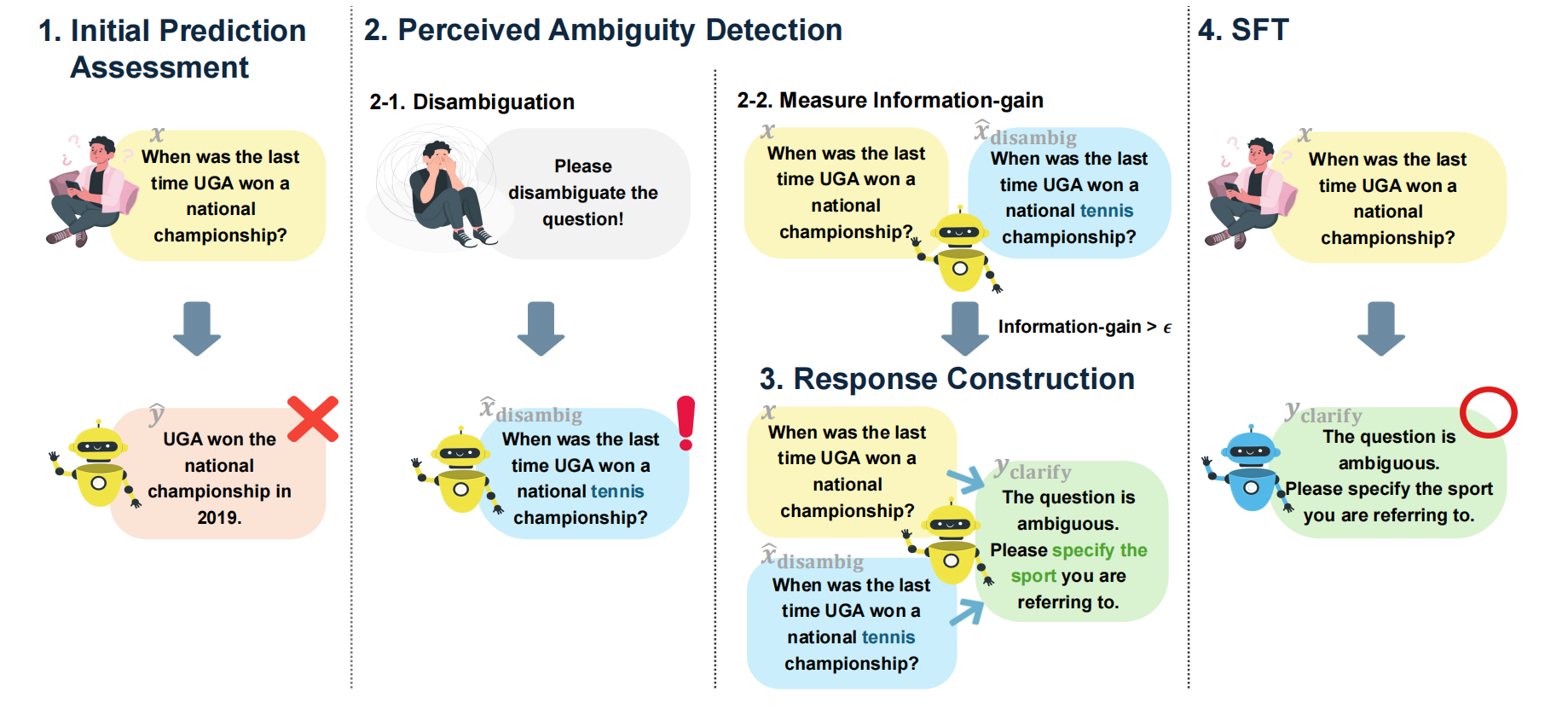
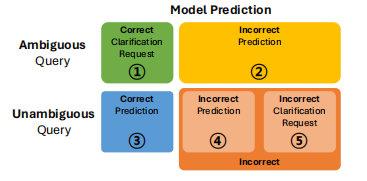
在此研究中,作者关注的是开放领域问答任务,模型 M M M 需要根据预定义的推理模板 t ( ⋅ ) t(·) t(⋅) 生成一个对无歧义查询 x u n a m b i g x_{unambig} xunambig 的预测 y ^ u n a m b i g \hat{y}{unambig} y^unambig, y ^ u n a m b i g \hat{y}{unambig} y^unambig 与真实标签 y y y 进行比较,然后被分类为 3️⃣-正确预测、4️⃣-错误预测和5️⃣-错误澄清请求。针对含歧义的输入查询,模型的预测 y ^ a m b i g \hat{y}{ambig} y^ambig 应该作为澄清请求 y c l a r i f y y{clarify} yclarify 以解决歧义。这种方法基于一个核心假设:用户最适合阐明自身意图。若 y ^ a m b i g \hat{y}_{ambig} y^ambig构成有效的澄清请求,则被视为1️⃣-正确,反之如果未能解决歧义的回应将被判定为2️⃣-错误。对齐的最终目标是在保持或提升3️⃣的同时,增加1️⃣的数量。
初始预测评估
初始阶段侧重于识别模型当前无法处理的样本。通过将明确查询的预测结果 y ^ unambig \hat{y}{\text{unambig}} y^unambig 与真实标签 y y y 进行匹配,并将模糊查询的预测结果 y ^ ambig \hat{y}{\text{ambig}} y^ambig 与澄清请求 y clarify y_{\text{clarify}} yclarify 进行匹配,从而评估其正确性。共收集n个正确样本(属1️⃣和3️⃣类别),构建为正确数据集 D correct = { ( x correct i , y correct i ) } i = 1 n D_{\text{correct}} = \{(x_{\text{correct}}^i, y_{\text{correct}}^i)\}{i=1}^n Dcorrect={(xcorrecti,ycorrecti)}i=1n 。而被归类2️⃣、4️⃣、5️⃣的错误样本则统一归入独立数据集 D incorrect D{\text{incorrect}} Dincorrect。
感知模糊检测
本阶段旨在从错误数据集 D incorrect D_{\text{incorrect}} Dincorrect 中识别模型认为存在歧义的样本。鉴于模型难以直接显式表达歧义认知,作者构建了一个代理任务来估算模型视角下的歧义程度。具体而言,作者要求模型对给定查询 x x x 进行自消歧处理,并生成消歧后的查询 x ^ disambig \hat{x}{\text{disambig}} x^disambig。在此过程中,模型会利用其与 x x x 相关的内部知识来补充生成更详尽的细节。若原始查询 x x x 存在定义不完整的情况,且模型恰好具备弥补所需的相关知识,则从模型视角来看, x ^ disambig \hat{x}{\text{disambig}} x^disambig 将产生更高的确定性。反之,若 x x x 本身无需具体化说明,或模型缺乏必要知识,则 x ^ disambig \hat{x}{\text{disambig}} x^disambig 会表现出与 x x x 相似的不确定性水平。为量化 x x x 与 x ^ disambig \hat{x}{\text{disambig}} x^disambig 的不确定性,作者采用模型的平均熵进行计算。
形式上,输出分布的熵定义为: H x , i = − ∑ v ∈ V p x , i ( v ) log p x , i ( v ) \mathcal{H}{x, i}=-\sum{v \in \mathcal{V}} p_{x, i}(v) \log p_{x, i}(v) Hx,i=−∑v∈Vpx,i(v)logpx,i(v),其中 p x , i ( v ) p_{x, i}(v) px,i(v) 定义为句子 x x x 中第 i i i 个 token v v v 在完整的词表 V V V 中出现的概率。句子 x x x 的平均熵可定义为: H x = 1 N ∑ i H x , i \mathcal{H}{x}=\frac{1}{N} \sum{i} \mathcal{H}_{x, i} Hx=N1∑iHx,i, N N N表示句子的 token 数。
作者通过平均熵的差异量化 x ^ disambig \hat{x}{\text{disambig}} x^disambig 获得的额外信息,我们将其定义为信息增益(infogain): INFOGAIN x , x ^ disambig = H x − H x ^ disambig \text { INFOGAIN }{x, \hat{x}{\text {disambig }}}=\mathcal{H}{x}-\mathcal{H}{\hat{x}{\text {disambig }}} INFOGAIN x,x^disambig =Hx−Hx^disambig 。
若 x ^ disambig \hat{x}{\text {disambig }} x^disambig 能产生具有实际意义的细化表述,将带来显著的信息增益(InfoGAIN),这表明模型认为原始查询 x x x 存在歧义。无论真实歧义程度如何,当信息增益量超过阈值 ϵ \epsilon ϵ 时,该样本即被归类为歧义样本,记为 x ambig x{\text {ambig}} xambig。
构造回复
在这个阶段,作者定义了 y c l a r i f y y_{clarify} yclarify,它代表模型应针对模糊查询生成的澄清请求。作者探索了两种响应生成方法:
- 固定响应:使用预定义的澄清请求作为 x ambig x_{\text {ambig}} xambig 的 y c l a r i f y y_{clarify} yclarify。具体来说,预先定义了一组澄清请求列表,然后随机选择一个作为每个实例的 y c l a r i f y y_{clarify} yclarify。
- 生成响应:模型被提示生成一个澄清请求,指明模糊性的来源。为此,作者向模型提供 x ambig x_{\text {ambig}} xambig 和 x ^ disambig \hat{x}{\text{disambig}} x^disambig ,以识别导致模糊性的因素,从而生成针对该因素的特定 y c l a r i f y y{clarify} yclarify。
SFT 数据集
本阶段旨在构建用于模型对齐的数据集。作者对识别出的 m m m 个歧义样本进行标注,构建歧义数据集 D ambig = { ( x ambig j , y clarify j ) } j = 1 m D_{\text{ambig}} = \{(x_{\text{ambig}}^j, y_{\text{clarify}}^j)\}{j=1}^m Dambig={(xambigj,yclarifyj)}j=1m,其中 y clarify y{\text{clarify}} yclarify 作为真实标签。为避免模型丢失已有知识,同时引入 D correct D_{\text{correct}} Dcorrect 参与训练。通过平衡两个数据集的样本量使得 n = m n=m n=m,最终建立训练数据集 D = D correct + D ambig D = D_{\text{correct}} + D_{\text{ambig}} D=Dcorrect+Dambig。利用数据集 D = { ( x k , y k ) } k = 1 n + m D = \{(x^k, y^k)\}{k=1}^{n+m} D={(xk,yk)}k=1n+m,模型通过相同的推理模板 t ( ⋅ ) t(\cdot) t(⋅) 进行训练,学习对 x unambig x{\text{unambig}} xunambig 生成 y y y,对 x ambig x_{\text{ambig}} xambig 生成 y clarify y_{\text{clarify}} yclarify。参数为 θ \theta θ 的模型 M M M 通过以下目标函数进行训练:
min θ ∑ ( x , y ) ∈ D ∑ i = 1 ∣ y ∣ − log M θ ( y i ∣ y < i , t ( x ) ) \min {\theta} \sum{(x, y) \in D} \sum_{i=1}^{|y|} -\log M_{\theta}\left(y_{i} \mid y_{<i}, t(x)\right) θmin(x,y)∈D∑i=1∑∣y∣−logMθ(yi∣y<i,t(x))
根据 y clarify y_{\text{clarify}} yclarify 类型的不同,作者训练了两个版本的APA: A P A FIXED \mathrm{APA}{\text{FIXED}} APAFIXED 使用固定回复模板,而 A P A GEN \mathrm{APA}{\text{GEN}} APAGEN 使用生成式回复。
实验
数据集
模型在训练域内的表现能力至关重要。然而,为了实际应用,模型必须能够泛化到分布外(OOD)查询,因为实践中经常遇到与训练数据不同的查询。因此,作者使用 AmbigQA 作为训练和验证的域内数据集。该数据集包含模糊和明确的查询,其中明确查询带有真实答案标签。SituatedQA 被用作 OOD 测试数据集,分为两个不同的部分,分别称为 SituatedQA-Geo 和 SituatedQA-Temp,分别关注地理和时间上的模糊性。为了进一步评估不同问答领域的模糊性,作者构建了三个额外的数据集:AmbigTriviaQA、AmbigWebQuestions和AmbigFreebaseQA,分别源自TriviaQA、WebQuestions 和 FreebaseQA。作者采用 gpt-4o 对原始数据集中的初始查询进行模糊化处理,并验证生成结果。为了减轻验证过程中可能存在的偏差,作者进一步由人工标注者评估验证样本,并选择样本用于最终数据集。
Baselines
为评估本方法的有效性,作者引入两组 baselines:纯推理方法与训练方法。
- 仅推理方法:通过采用不同的提示策略来解决歧义问题。以直接提示(direct)作为基础基准,使用简单的问答提示进行测试。此外,作者还探索了歧义感知提示(ambig-aware),该方法通过添加处理歧义输入的额外指令来增强效果。同时,作者通过测量采样生成结果的一致性,对样本重复(sample REP)方法进行了验证。最后,作者对比了SELF-ASK方法,该方法在模型生成答案后,会根据生成结果自动判定歧义程度。
- 训练方法:由于缺乏可直接比较的前期研究,作者将APA与经过微调的基线模型进行对比,这些基线模型均使用领域内训练集进行训练。作者比较了应用完整训练集的 FULL-SET 方法。此外,作者还比较了两种利用与 APA 相同数量训练样本的变体:subset_rand 采用随机选取的子集进行训练,该子集中包含等量的模糊样本和明确样本;subset_ent 则以模型对模糊查询预测的熵值作为不确定性度量。前者选择具有最高熵值的模糊样本,后者则随机选取明确样本。
评估指标
成功的对齐应 保持模型处理明确输入的能力 ,同时有效管理模糊查询。
作者定义了两个不同的指标来量化此能力:
- 无歧义预测( F 1 u F1_{u} F1u):该模型需对无歧义查询 生成准确答案,同时尽量减少对歧义查询的任意响应。为衡量此指标,作者采用无歧义预测F1值,其计算方式为:对歧义查询的精确率 ③ ② + ③ + ④ \frac{③}{②+③+④} ②+③+④③ 与召回率 ③ ③ + ④ + ⑤ \frac{③}{③+④+⑤} ③+④+⑤③ 取调和平均值。
- 歧义性检测 ( F 1 a F1_a F1a):当输入信息存在歧义 时,模型应能识别并生成相应的澄清请求。然而,模型可能对澄清请求存在预测偏差。基于这些考量,作者采用F1分数评估模型的模糊性检测能力,该指标同时反映精确率 ① ① + ⑤ \frac{①}{①+⑤} ①+⑤① 和召回率 ① ① + ② \frac{①}{①+②} ①+②① 。
实现细节
本实验采用LLAMA2 7B和13B以及mistral 7B模型,并使用QLoRA进行高效训练,结果取三个不同随机种子的平均值。
实验结果
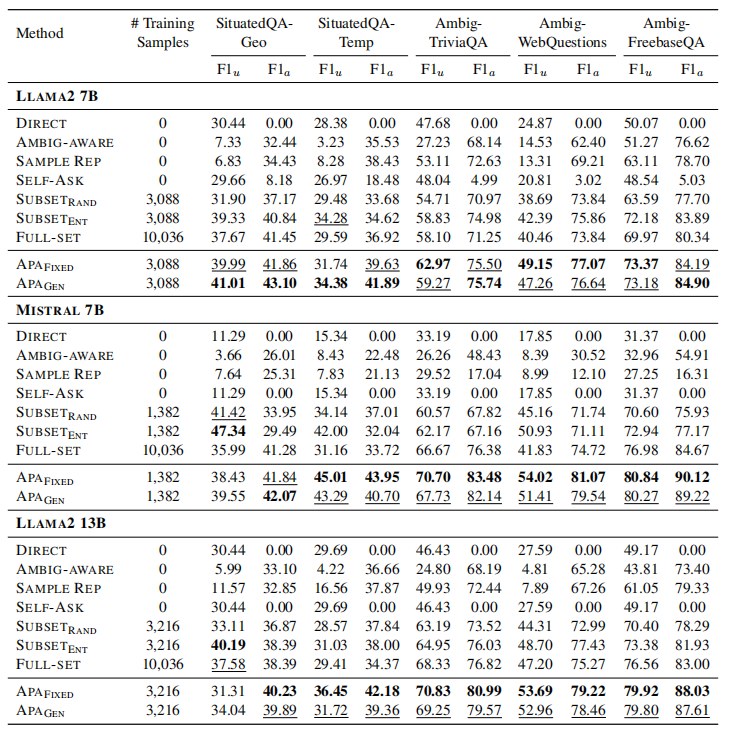
仅推理方法在处理歧义查询时存在显著局限性。 direct方法无法有效处理歧义查询,其持续为零的 F 1 a F1_a F1a 分数即为明证。 ambiga-ware 和 sample REP 方法对澄清请求表现出明显偏好,导致 F 1 u F1_u F1u 指标不足。SELF-ASK方法的 F 1 a F1_a F1a 分数偏低,表明仅通过"提问"模型而不进行任务特定训练时,其解决歧义的能力存在局限。
与仅推理方法相比,训练方法展现出更优的性能表现。 具体而言,与仅使用参考数据的方法相比,subsetrand 在两项指标上均展现出更优的性能。FULL-SET方法通过利用完整训练集,在所有基准方法中表现最为突出。值得注意的是,subsetent不仅大幅超越subsetrand,甚至在某些数据集上超越了FULL-SET。subsetent的实验结果表明,熵值能够有效捕捉数据的模糊性特征,这种特性使其在比对过程中具有显著优势。
APA在所有数据集上都表现出色。 尽管采用了相同的推理模板,APA 在 F 1 u F1_u F1u 上相比 direct 方法有了显著提升。考虑到 APA 是在 D correct D_{\text{correct}} Dcorrect 数据集上训练的,而该数据集包含模型已经能够处理的样本,这一改进尤其令人惊讶。此外,APA 在所有数据集的 F 1 a F1_a F1a 上都持续表现优异,最高提升了6分。这些结果突显了利用感知模糊性进行对齐的有效性,增强了泛化能力和鲁棒性。与subsetent相比,APA 的改进表明信息增益比熵提供了更好的模糊性量化。仅利用感知模糊的数据(在LLAMA2家族中约占32%,在mistral中约占13%)的效能再次强调了数据质量而非数量的重要性。此外,APA-FIXED 通常比 APAGEN 表现更优。这是因为 APAGEN 承担了生成特定澄清请求这一更具挑战性的任务。
消融实验
样本级别的未对齐分析
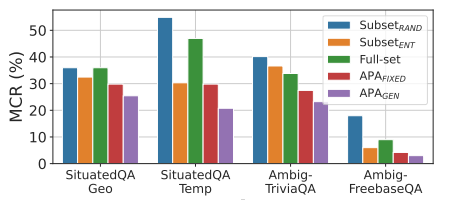
生成澄清请求以应对模糊查询的对齐过程可能会导致一种潜在的权衡,即模型错误地为之前处理得当的明确输入生成澄清请求。为了评估这种情况,作者定义了错误对齐澄清请求率(MCR),该指标衡量了在训练前正确回答(即3️⃣)但对齐后错误地生成澄清请求(5️⃣)的明确样本的比例。较低的 MCR 是理想的,这表示模型在对齐后仍能保持其现有能力。从下图中可以看出,总体而言,APA始终表现出最低的 MCR ,表明该模型成功学会了处理模糊性,同时有效地保留了现有能力。
阈值的影响
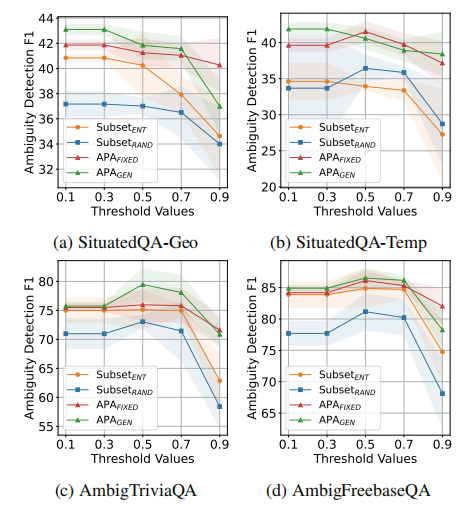
用于对齐的训练样本数量取决于阈值 ϵ 。为了理解 ϵ 对性能的影响,作者通过应用不同的 ϵ 进行模糊数据选择分析。作者比较了子集ent和子集rand,每种方法都有相同数量的训练样本。下图展示了不同 ϵ 下的F1a分数。总体而言,较大的 ϵ 减少了可用于训练的数据量,导致性能下降。子集rand在所有场景中表现持续不佳,而子集ent则在所有场景中表现强劲。尽管如此,APA在不同 ϵ 值下都优于所有基线方法。
数据选择中信息增益的影响
为深入分析 APA 框架下数据选择的信息增益效应,作者通过调整模糊数据筛选标准开展了消融实验。在保持正确数据集 D correct D_{\text{correct}} Dcorrect 不变的前提下,作者对 m 个模糊样本的筛选策略进行如下调整:
- 随机选择(RAND):从真实模糊样本中随机选取m个样本。
- 基于信息增益选择:采用两种基于信息增益的筛选方法:
- MAX:从真实模糊样本中选取信息增益值最高的前m个样本;
- MIN:从真实模糊样本中选取信息增益值最低的后m个样本。
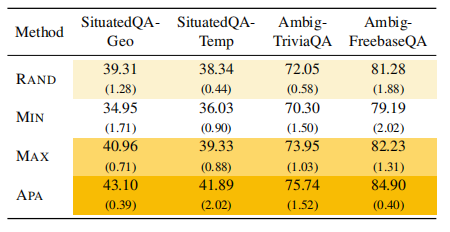
与基准方法相比,APA 通过利用感知模糊样本,允许潜在包含真实明确样本。下表展示了整体实验结果。RAND方法的表现始终落后于MAX方法1-4个百分点,这一差距凸显了基于信息增益的数据选择方法的有效性,即使在真实模糊样本中也是如此。值得注意的是,APA在所有数据集上均优于所有基准方法。尽管感知模糊性并不总是与真实模糊性一致,但实验结果表明,利用模型感知的模糊性显著提升了数据对齐效果。MIN方法在评估的所有方法中表现最差,作者推测其原因在于:训练样本中信息增益值较低的样本被感知为明确样本,但实际被训练为模糊样本。这种错位可能是导致性能下降的原因。
案例分析
下表展示了从查询 x x x 生成的消歧 x ^ disambig \hat{x}{\text {disambig }} x^disambig 和澄清请求 y c l e a r i f y y{clearify} yclearify 的示例。我们可以观察到,模型利用其内在知识(例如,1932年版的书籍)生成了关于查询的事实规范。此外,给定 x x x 和 x ^ disambig \hat{x}_{\text {disambig }} x^disambig ,模型成功生成了一个澄清请求,特别提到了导致歧义的因素(例如,哪个版本)。
