《Flamingo: a Visual Language Model for Few-Shot Learning》
下载地址:https://arxiv.org/pdf/2204.14198.pdf

1. 一段话总结
Flamingo是DeepMind提出的视觉语言模型(VLM)家族 ,核心目标是实现少样本学习 (仅需少量标注示例快速适配新任务)。其通过三大架构创新:一是用Perceiver Resampler 连接预训练视觉编码器(冻结NFNet-F6)与语言模型(冻结Chinchilla系列),处理可变尺寸视觉特征并输出固定视觉 tokens;二是在冻结语言模型层间插入GATED XATTN-DENSE层 ,实现视觉信息对语言生成的条件约束且避免训练不稳定;三是通过单图像交叉注意力掩码 支持任意 interleaved(交织)的图文/视频文本输入。模型训练基于三类网页来源数据(M3W interleaved图文、LTIP图文对、VTP视频文本对),在16个图像/视频任务中,仅需32个任务示例的少样本设置就超越此前零/少样本SOTA,且在6个任务上超越需数千倍任务数据的微调SOTA;同时支持微调,在VQAv2等5个任务上刷新SOTA,但存在分类性能弱于对比学习模型、继承语言模型幻觉等局限。

2. 思维导图(mindmap)
mindmap
## 核心定位:Flamingo视觉语言模型(VLM)
- 目标:少样本学习(仅少量标注快速适配新任务)
- 所属机构:DeepMind
- 模型规模:3B、9B、80B(核心为80B,简称Flamingo)
## 架构创新
- 视觉处理模块
- 视觉编码器:冻结预训练NFNet-F6(对比学习预训练)
- Perceiver Resampler:将可变视觉特征→固定64个视觉tokens,降低跨注意力计算量
- 语言条件约束模块
- 基础:冻结Chinchilla预训练语言模型(1.4B/7B/70B)
- GATED XATTN-DENSE层:插入LM层间,0初始化tanh门控避免训练不稳定,实现视觉-语言交互
- 多视觉输入支持:单图像交叉注意力掩码,仅关注当前文本前最近视觉输入,适配任意数量视觉样本
## 训练体系
- 训练数据(均来自网页,无人工标注)
- M3W:4300万网页的interleaved图文数据
- 图文对:ALIGN(18亿)+ LTIP(3.12亿,长描述高质量)
- 视频文本对:VTP(2700万,平均22秒/视频)
- 训练策略:多数据集梯度累积优化(非round-robin),最小化文本负对数似然加权和
## 性能表现
- 少样本学习(32-shot)
- 16个任务超零/少样本SOTA
- 6个任务(如VQAv2、HatefulMemes)超越需数千倍数据的微调SOTA
- 微调表现:在VQAv2、VATEX等5个任务上刷新SOTA
- 消融实验结论:M3W数据关键(移除性能降17%)、冻结LM避免灾难性遗忘、Perceiver Resampler优于MLP/Transformer
## 局限与影响
- 局限:分类性能弱于对比模型、继承LM幻觉/长序列泛化差、少样本提示敏感
- 社会影响:降低低资源任务应用门槛(如VizWiz助视障),但存在偏见/毒性风险,需 mitigation 策略
## 结论:验证预训练视觉-语言模型融合对通用视觉理解的价值3. 详细总结
一、摘要与核心背景
- 研究挑战:现有多模态模型要么需大量任务数据微调,要么(如对比学习模型)仅能处理分类等有限任务,无法支持开放式生成(如captioning、VQA)。
- 核心贡献 :
- 提出Flamingo VLM家族,支持任意交织图文/视频文本输入,通过少样本提示快速适配多任务;
- 量化评估16个任务,在11个未参与设计验证的基准上实现无偏少样本性能;
- 16个任务中6个超微调SOTA(仅32个示例,任务数据量少1000倍),微调后再刷新5个任务SOTA。
二、模型架构与方法
(1)核心架构组件(图3、4)
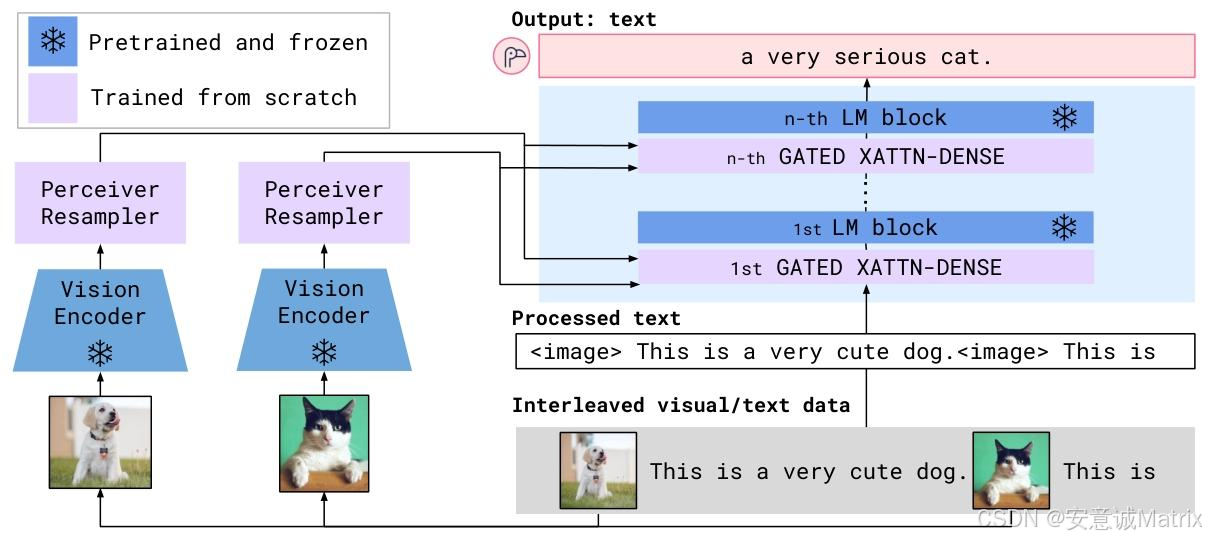
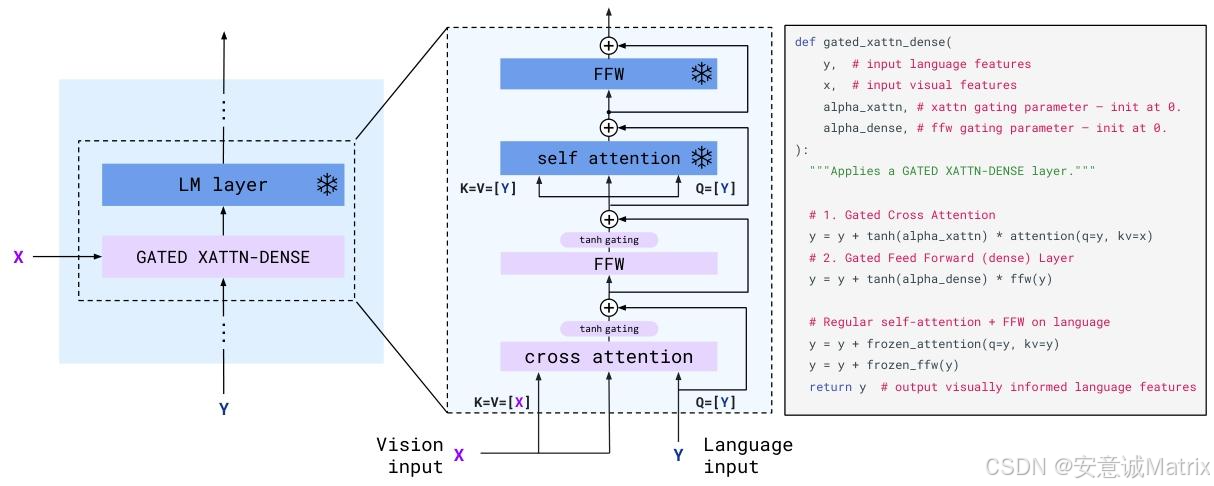
| 组件 | 功能描述 | 关键细节 |
|---|---|---|
| 视觉编码器 | 处理像素→视觉特征,冻结预训练 | 采用NFNet-F6,对比学习预训练(ALIGN+LTIP数据),输出2D/3D(视频)特征网格 |
| Perceiver Resampler | 连接视觉编码器与LM,处理可变视觉输入 | 学习固定数量 latent queries,交叉注意力作用于视觉特征,输出64个视觉tokens,支持图像/视频 |
| 冻结语言模型 | 提供文本生成与推理能力,避免灾难性遗忘 | 基于Chinchilla系列(1.4B→3B模型、7B→9B模型、70B→80B模型),全冻结 |
| GATED XATTN-DENSE层 | 插入LM层间,实现视觉对语言的条件约束 | 0初始化tanh门控(α=0,初始输出与原LM一致),交叉注意力(视觉为KV,语言为Q)+ 前馈层 |
- 模型参数分布(表5):
| 模型 | 冻结LM参数 | 冻结视觉编码器参数 | 可训练GATED XATTN-DENSE参数 | 可训练Resampler参数 | 总参数 |
|---|---|---|---|---|---|
| Flamingo-3B | 1.4B | 435M | 1.2B(每LM层插入) | 194M | 3.2B |
| Flamingo-9B | 7.1B | 435M | 1.6B(每4层LM插入) | 194M | 9.3B |
| Flamingo-80B | 70B | 435M | 10B(每7层LM插入) | 194M | 80B |
(2)训练数据与策略
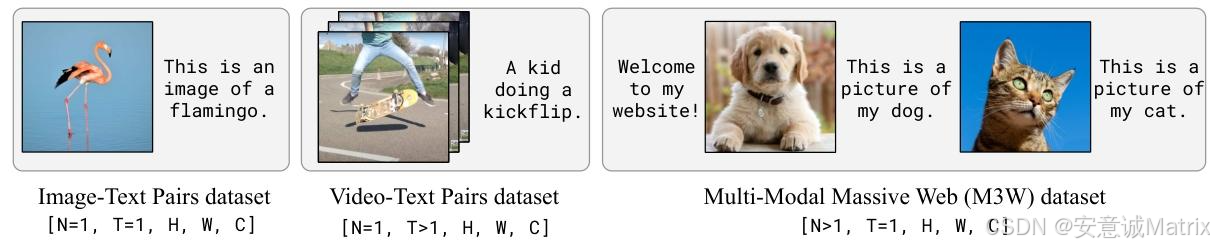
- 训练数据构成 (图9):
- M3W :4300万网页,提取interleaved图文,插入
<image>和<EOC>token,单序列最多5张图; - 图文对:ALIGN(18亿,alt-text标注)+ LTIP(3.12亿,长描述,平均20.5 tokens/图,高于ALIGN的12.4);
- 视频文本对:VTP(2700万视频,平均22秒/视频,配句子描述)。
- M3W :4300万网页,提取interleaved图文,插入
- 训练优化 :
- 目标:最小化多数据集文本负对数似然加权和(M3W权重1.0、ALIGN/LTIP 0.2、VTP 0.03);
- 策略:梯度累积(优于round-robin),AdamW优化,全局梯度裁剪(norm=1),视觉输入分辨率320×320(训练)/480×480(微调)。
(3)少样本任务适配
- 方式:构建interleaved多模态提示(支持示例对:(图像/视频, 文本)),示例后接查询视觉输入;
- 解码:开放式任务用beam search(beam=3),封闭式任务用对数似然评分候选答案;
- 零样本:用2个无图像的文本示例构建提示,避免 prompt engineering 偏差。
三、实验结果
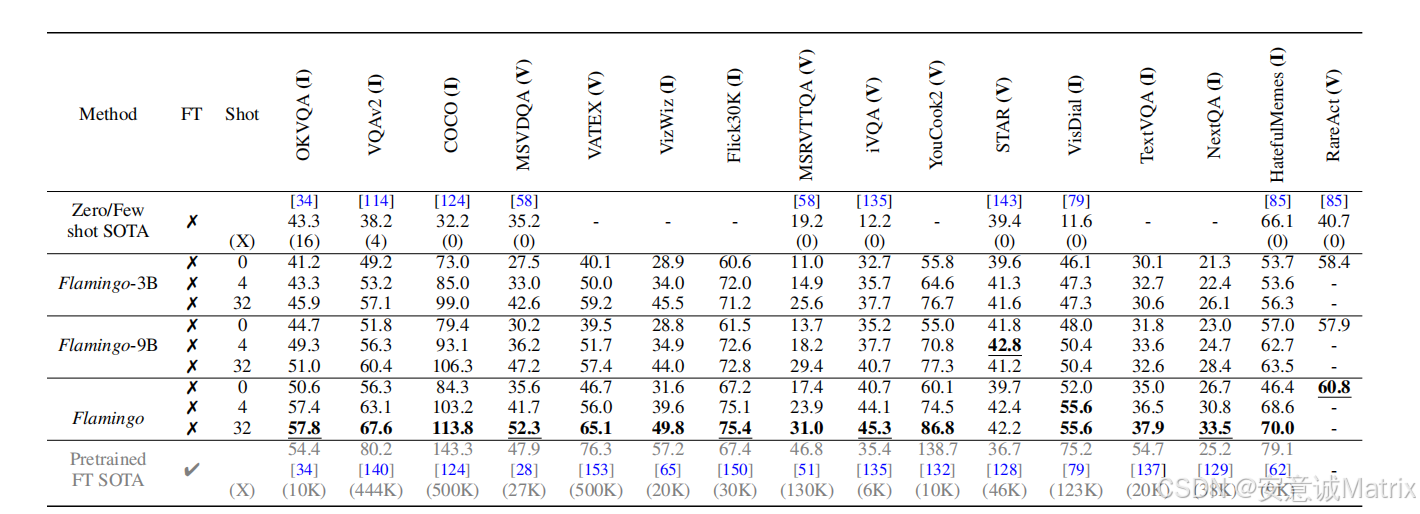
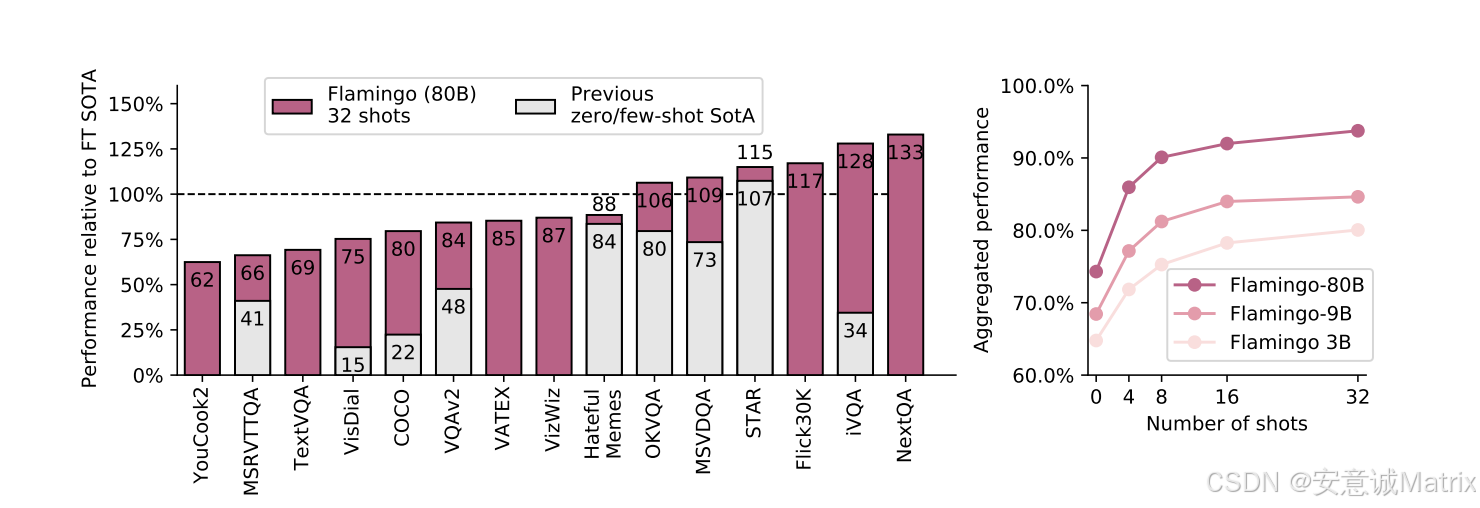
(1)少样本学习性能(表1、图2)
-
核心结论:
- 模型规模与shots数量正相关:Flamingo-80B(80B)性能最优,32-shot优于4-shot/0-shot;
- 少样本碾压零/少样本SOTA:在16个任务(如VQAv2、HatefulMemes)中,仅4个示例就大幅超越此前SOTA;
- 超越微调SOTA:32-shot设置下,在OKVQA、VQAv2等6个任务上,超越需10K~500K任务数据的微调模型(如VQAv2微调SOTA用44.4K数据,Flamingo仅32个示例)。
-
部分任务32-shot性能对比(示例):
| 任务 | 此前微调SOTA(数据量) | Flamingo-80B(32-shot) | 提升幅度 |
|---|---|---|---|
| VQAv2 | 80.2(44.4K) | 67.6(少样本)→82.0(微调) | 微调后超1.8 |
| HatefulMemes | 79.1(9K) | 70.0(少样本)→86.6(微调) | 微调后超7.5 |
(2)微调性能(表2)

- 微调策略:解冻视觉编码器(适配高分辨率),冻结LM,小学习率(3e-8~1e-5);
- 结果:在VQAv2(test-dev 82.0)、VATEX(test-std 84.2)、VizWiz(test 65.7)、MSRVTTQA(test-std 47.4)、HatefulMemes(test seen 86.6)5个任务上刷新SOTA,部分超越模型集成方法。
(3)消融实验(表3、表10)
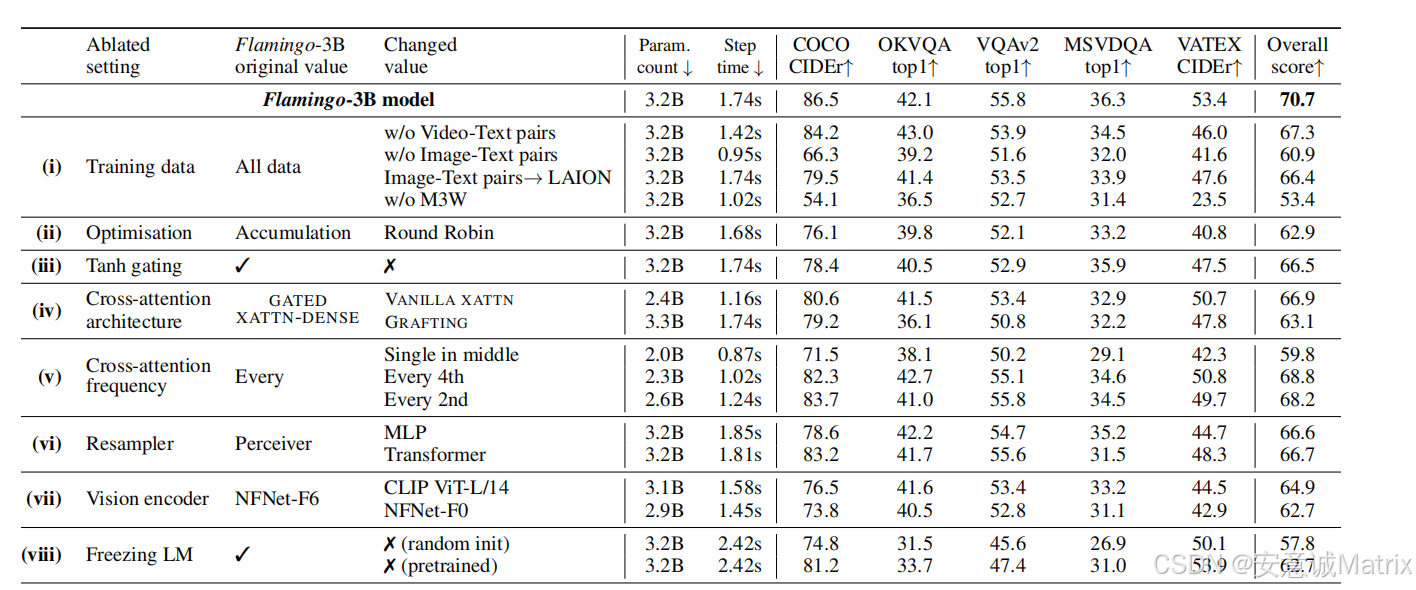
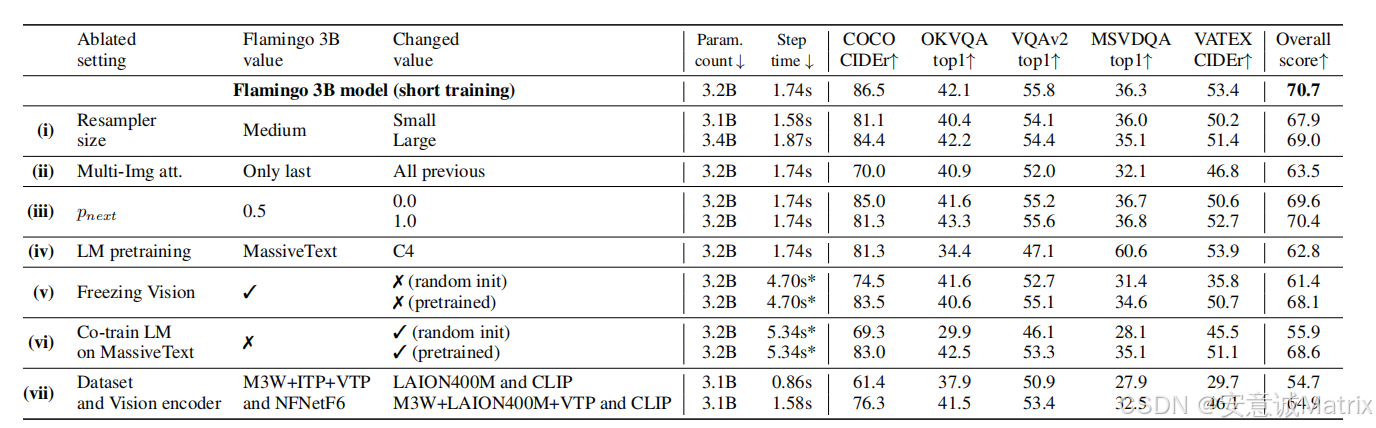
- 训练数据关键:移除M3W(interleaved数据)性能降17%,移除LTIP(图文对)降9.8%,移除VTP(视频文本对)损害视频任务性能;
- 架构组件必要:无tanh门控性能降4.2%且训练不稳定;Perceiver Resampler优于MLP(性能高4.1%)、Transformer(高4.0%);
- 冻结LM重要:LM随机初始化性能降12.9%,微调预训练LM降8.0%,验证冻结可避免"灾难性遗忘"。
四、讨论与局限
(1)局限性
- 分类性能弱:ImageNet零-shot性能(77.3,RICES+ensembling)低于对比模型(如CLIP 85.7);
- 继承LM缺陷:存在幻觉、长序列泛化差(训练最多5张图,推理32张图但性能 plateau)、少样本提示敏感(示例顺序/格式影响大);
- 少样本局限:32-shot后性能饱和,无法像梯度方法利用更多数据。
(2)社会影响
- 益处:降低低资源任务应用门槛(如VizWiz助视障)、"模型回收"减少重训练能耗;
- 风险:继承LM偏见(性别/种族)、毒性输出,需通过提示优化、过滤训练数据缓解;
- 建议:仅用于研究,实际应用前需针对性风险评估。
五、结论
Flamingo验证了"连接预训练视觉与语言模型"是实现通用视觉理解的关键方向,其少样本能力为低资源多模态任务提供新范式,同时为VLM的架构设计(冻结预训练模型、interleaved数据训练)提供参考。
4. 关键问题
问题1:Flamingo实现"少样本快速适配任务"的核心架构创新有哪些?分别解决了什么痛点?
答案:核心架构创新有三点,分别解决多模态融合、训练稳定性、输入灵活性痛点:
- Perceiver Resampler:解决"视觉输入尺寸可变,无法直接对接固定输入的语言模型"痛点。它接收视觉编码器输出的2D(图像)/3D(视频)特征网格(尺寸可变),通过学习固定数量的latent queries与视觉特征交叉注意力,输出固定64个视觉tokens,降低视觉-语言交叉注意力的计算复杂度,同时支持图像/视频统一处理;
- GATED XATTN-DENSE层:解决"视觉信息注入预训练语言模型时,易破坏原有语言能力(灾难性遗忘)且训练不稳定"痛点。该层插入冻结语言模型层间,采用0初始化的tanh门控(α=0),初始时输出为0,确保模型初始行为与原预训练LM一致,训练中逐步融入视觉信息,既保留语言模型能力,又实现视觉对语言生成的条件约束;
- 单图像交叉注意力掩码:解决"无法处理任意数量交织图文/视频文本输入"痛点。通过掩码限制文本token仅交叉注意力于其前最近的视觉输入(而非所有历史视觉输入),虽仅直接关注单图像,但通过LM自注意力传递历史视觉信息,使模型训练时仅需处理5张图/序列,推理时可支持32张图/视频的少样本提示,适配任意数量视觉输入。
问题2:Flamingo在少样本学习场景下的性能优势具体体现在哪些方面?与传统微调方法相比有何核心差异?
答案:
(1)少样本性能优势
- 数据效率极高:仅需32个任务示例,就在16个图像/视频任务中超越此前零/少样本SOTA,且在6个任务(如OKVQA、HatefulMemes)上超越需数千倍任务数据的微调SOTA(例如OKVQA微调SOTA用10K数据,Flamingo仅32个示例,数据量少312倍);
- 任务通用性强:单一模型支持开放式(VQA、captioning)、封闭式(多 choice VQA)、视觉对话等全光谱任务,无需针对任务修改架构;
- 泛化能力好:仅在5个DEV基准(COCO、VQAv2等)上验证设计,在11个未参与设计的基准(如TextVQA、VisDial)上仍保持高性能,证明泛化性。
(2)与传统微调的核心差异
| 对比维度 | Flamingo少样本学习 | 传统微调方法 |
|---|---|---|
| 数据需求 | 32个任务示例 | 10K~500K任务数据(数千倍更多) |
| 模型修改 | 无需修改权重,仅通过提示适配 | 需修改模型权重,易过拟合/遗忘 |
| 部署成本 | 仅需推理,无超参 tuning | 需针对任务调学习率/批次等,部署复杂 |
| 任务适配速度 | 即时适配(提示构建后直接推理) | 需数小时至数天训练 |
| 跨任务兼容性 | 单一模型支持多任务,无冲突 | 单任务微调模型难以复用至其他任务 |
问题3:训练数据对Flamingo的少样本能力至关重要,其训练数据的构成有何特点?不同类型数据的作用分别是什么?
答案:
(1)训练数据构成特点
Flamingo训练数据均来自网页自动抓取,无人工标注,分为三类,覆盖"interleaved(交织)图文""单图图文对""单视频文本对"三种形态,确保数据多样性与多模态交互的真实性:
- M3W(MultiModal MassiveWeb) :4300万网页,提取interleaved图文(文本中插入
<image>标签标记图像位置,<EOC>标记片段结束),单序列最多采样5张图; - 图文对数据:ALIGN(18亿,图像+alt-text,噪声高、描述短)+ LTIP(3.12亿,图像+长描述,质量高,平均20.5 tokens/图);
- 视频文本对数据(VTP):2700万短视频(平均22秒/视频)+ 句子描述。
(2)不同数据的作用
- M3W(interleaved图文):核心作用是赋予模型"理解图文交织关系"与"少样本学习"能力。移除M3W会导致整体性能下降17%,因为其模拟真实网页中图文的自然交织场景,使模型学会从序列中捕捉视觉与文本的对应关系,这是少样本提示(interleaved示例+查询)的基础;
- 图文对(ALIGN+LTIP):作用是补充高质量视觉-语义对齐信息,提升视觉理解精度。移除图文对性能下降9.8%,其中LTIP(长描述)比ALIGN(短alt-text)质量更高,单独训练LTIP的对比模型性能优于单独训练ALIGN,二者结合可进一步提升视觉特征质量;
- VTP(视频文本对):作用是赋予模型视频理解能力,确保视频任务(如MSRVTTQA、YouCook2)性能。移除VTP会显著降低视频任务的少样本性能,其提供的视频-文本时序对齐信息,使模型能处理动态视觉输入(如预测视频中"击球后人的动作")。