
Lumi SDK说明
Lumi SDK分为以下三个部分:
- 手臂控制
- 升降与头部控制
- AGV控制
手臂控制
采用标准JAKA SDK下载链接
版本要求>=v2.2.7
AGV控制
通过TCP发送字符串指令来控制或获取AGV的运动。具体文档参见AGV API手册.pdf
python示例可参考 04. JAKA Lumi Demo Case 示例/agv 目录下的资料
升降与头部电机控制
以下未做特殊说明时单位统一为度、毫米、千克、秒
采用http接口的方式控制与访问。总计有4个关节
- 关节1:升降,运动范围0,300mm
- 关节2:腰部旋转,运动范围-140,140度
- 关节3:头部旋转,运动范围-180,180度
- 关节4:头部俯仰,运动范围-5,35度
web ui
浏览器访问http://192.168.10.90:5000,即可访问。
注意:当前仅提供基本状态监控等功能,后续将逐步完善
接口说明
以下的URL地址端口是固定的,IP地址需根据实际网络连接情况修改。采用wifi连接的情况下默认为192.168.10.90
使能控制
POST: http://192.168.10.90:5000/api/extaxis/enable
Body段JSON参数:{"enable":0}
| 参数名称 | 含义 |
|---|---|
| enable | 0:关闭使能;1:开启使能 |
python调用例子:
python
import requests
import json
response = requests.post("http://192.168.10.90:5000/api/extaxis/enable", json={"enable": 1})
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("enable ok")curl调用
shell
curl -X POST http://192.168.10.90:5000/api/extaxis/enable \
-H "Content-Type: application/json" \
-d '{"enable": 1}'其他语言可调用标准http库进行处理
复位
POST: http://192.168.10.90:5000/api/extaxis/reset
Body段JSON参数:无
python调用例子:
python
import requests
import json
response = requests.post("http://192.168.10.90:5000/api/extaxis/reset", json={})
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("reset ok")运动到指定位置
POST: http://192.168.10.90:5000/api/extaxis/moveto
Body段JSON参数:{"pos":0,0,0,0,"vel":100,"acc":100}
| 参数名称 | 含义 |
|---|---|
| pos | 给定位置,分别为升降位置,腰部旋转,头部旋转,头部俯仰,单位为mm和度,超出运动范围的给定位置将报错 |
| vel | 速度比率,范围0.1,100,超出范围将自动约束 |
| acc | 加速度比率,范围1,100,超出范围将自动约束 |
注意:
- 调用将阻塞直到运动完成或错误
- 调用前需要保证处于使能状态
- 超出运动范围的给定位置将报错
python调用例子:
python
import requests
import json
response = requests.post(
"http://192.168.10.90:5000/api/extaxis/moveto",
json={"pos": [200, 10, 10, 10], "vel": 100, "acc": 100},
)
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("moveto success")获取状态
GET: http://192.168.10.90:5000/api/extaxis/status
Body段JSON参数:无
返回值:以数组的形式返回每个关节的状态,包含如下信息
| 参数名称 | 含义 |
|---|---|
| id | 关节编号 |
| pos | 关节当前位置 |
| vel | 关节当前速度 |
| toq | 关节当前转矩 |
| enable | 关节使能状态位 |
| error | 关节错误标志位 |
| ecode | 关节错误码 |
python调用例子:
python
response = requests.get("http://192.168.10.90:5000/api/extaxis/status",)
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
parsed_text_json = json.loads(response.text) # Parse the text as JSON
print(f"JAKA Lumi state: {parsed_text_json[0]['pos']},{parsed_text_json[1]['pos']},{parsed_text_json[2]['pos']}")综合例程
python
import requests
import json
import time
API_URL = "http://localhost:5000/api/extaxis"
LUMI_ENABLE_URL = API_URL + "/enable"
LUMI_RESET_URL = API_URL + "/reset"
LUMI_MOVETO_URL = API_URL + "/moveto"
LUMI_STATUS_URL = API_URL + "/status"
LUMI_SYSINFO_URL = API_URL + "/sysinfo"
LUMI_GETSTATE_URL = API_URL + "/status"
def test():
# get system infomation
response = requests.get(LUMI_SYSINFO_URL)
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
parsed_text_json = json.loads(response.text)
print(f"JAKA Lumi info: {parsed_text_json}")
# reset all joint
response = requests.post(LUMI_RESET_URL, json={})
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("reset ok")
# enable all joint
response = requests.post(LUMI_ENABLE_URL, json={"enable": 1})
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("enable ok")
# read position
response = requests.get(LUMI_GETSTATE_URL)
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
parsed_text_json = json.loads(response.text) # Parse the text as JSON
print(
f"JAKA Lumi state: {parsed_text_json[0]['pos']},{parsed_text_json[1]['pos']},{parsed_text_json[2]['pos']}"
)
parsed_text_json[0]["pos"]
# home
response = requests.post(
LUMI_MOVETO_URL,
json={"pos": [0.0, 0, 0, 0], "vel": 100, "acc": 100},
)
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
# move to position A blockly
for i in range(100):
response = requests.post(
LUMI_MOVETO_URL,
json={"pos": [0.0, -100.0, -90.0, -5.0], "vel": 100, "acc": 100},
)
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("move to A ok")
# move to position B blockly
response = requests.post(
LUMI_MOVETO_URL,
json={"pos": [200.0, 100.0, 90.0, 30.0], "vel": 100, "acc": 100},
)
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("move to B ok")
# disable all joint
time.sleep(2)
response = requests.post(LUMI_ENABLE_URL, json={"enable": 0})
if response.status_code != 200:
print(f"Error: {response.status_code}")
return
print("disable ok")
if __name__ == "__main__":
test()Docker下ACT学习与推理安装文档及配置说明v1.0
docker镜像包:
V1.0 仅带环境,需要挂载源码
V1.1 不需要挂载源码,需要提供数据。源码路径为/ACT
使用docker-compose.act.yml启动docker容器,参考5.2-5.3
1安装Docker环境
docker安装参考 https://blog.csdn.net/educth/article/details/144138879
1.卸载旧有版本(如有)
sudo apt-get remove docker docker-engine docker.io containerd runc
2.更新 apt 索引并安装依赖
sudo apt-get update
sudo apt-get install
ca-certificates
curl
gnupg
lsb-release
3.添加 Docker 官方的 GPG 密钥(国内容易遇到网络问题,可以使用手动下载的方式)
#联网添加密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg |
sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
#概率遇到报错:gpg: no valid OpenPGP data found.执行测试:
curl -I https://download.docker.com/linux/ubuntu/gpg
#若无法收到200 OK,说明网络有问题。
#手动下载并转换密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o docker.gpg
sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg docker.gpg
#检查 docker.gpg 文件内容是否非空:
ls -lh docker.gpg
rm docker.gpg
4.设置 Docker 仓库
echo
"deb [arch=$(dpkg --print-architecture)
signed-by=/etc/apt/keyrings/docker.gpg]
https://download.docker.com/linux/ubuntu
$(lsb_release -cs) stable" |
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
5.再次更新 apt 索引
sudo apt-get update
6.安装 Docker Engine
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
7.验证 Docker 是否安装成功
docker -v
8.将当前用户加入docker组:
sudo groupadd docker
sudo usermod -aG docker $USER
重新登录或重启宿主机后生效,或使用以下命令
sudo chmod a+rw /var/run/docker.sock
9.(可选)docker换源、修改docker存储路径
在 Docker 的配置文件 /etc/docker/daemon.json中加入以下内容,如果文件不存在或内容不正确,可以手动创建或修改。
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://cr.console.aliyun.com",
"https://ccr.ccs.tencentyun.com",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://registry.docker-cn.com"
],
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": \[\]
}
},
"default-runtime": "nvidia"
"data-root":"/data/docker"
}
2Docker 容器配置NVIDIA环境
Docker 容器配置NVIDIA环境参考 https://blog.csdn.net/ydscc/article/details/146185450
1.检查 NVIDIA 驱动是否安装
#确保宿主机上已经安装了 NVIDIA 驱动,并且驱动版本与 CUDA 版本兼容
nvidia-smi
#如果输出显示了 GPU 信息和驱动版本,则说明驱动安装正常
#如果 nvidia-smi 命令找不到,可能需要安装 NVIDIA 驱动
sudo apt update
sudo apt install -y nvidia-driver
#安装后需要然后重启宿主机。
2.安装 NVIDIA Container Toolkit (Ubuntu / Debian 系统)
Docker 使用 NVIDIA Container Toolkit 来管理 GPU 设备。如果未安装或版本不兼容,可能会导致此问题。安装步骤如下:
添加 NVIDIA 容器工具包的仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
更新包列表并安装
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
3.更改Docker配置文件
检查 Docker 的配置文件 /etc/docker/daemon.json,确保其中包含以下内容,如果文件不存在或内容不正确,可以手动创建或修改:
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker-0.unsee.tech",
"https://docker.hlmirror.com",
],
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": \[\]
}
},
"default-runtime": "nvidia"
}
4.重启 Docker 服务
sudo systemctl restart docker
- 验证 Docker 是否识别 GPU
#方法一 如果输出为空,说明 Docker 未正确识别 NVIDIA 驱动
docker info | grep -i nvidia
#方法二
直接查找nvidia-container-cli,如果输出/usr/bin/nvidia-container-cli,则已安装
which nvidia-container-cli
运行下面命令测试,如果能看到设备信息,说明 nvidia-docker 支持正常。
nvidia-container-cli info
#方法三 拉取官方镜像
sudo docker run --rm --gpus all nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi
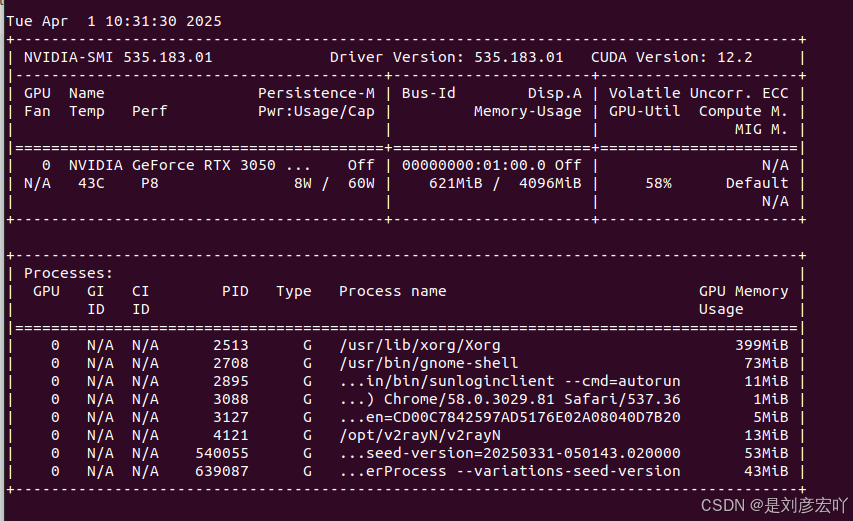
3启用训练环境
1.创建docker-compose.act.yml并准备好提供的docker image
version: "3.8"
services:
act:
image: actimages:V1.0
container_name: act
tty: false
stdin_open: false
volumes:
-
.../ACT:/ACT
-
/dev/shm:/dev/shm
network_mode: host
command: /bin/bash -c "sleep infinity"
restart: unless-stopped
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
2.运行容器,并进入容器
docker compose -f docker-compose.act.yml up -d
docker exec -it ros2_humble bash
3.修改数据路径:打开/ACT/constans.py文件
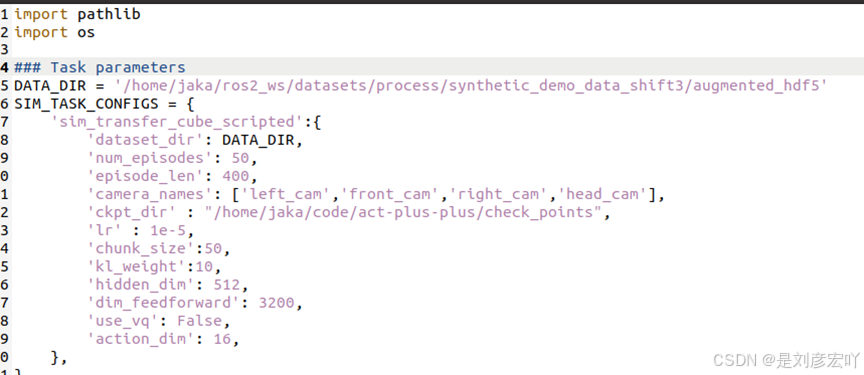
首先定义DATA_DIR的路径也就是数据集的路径,声明相机名称和数量(根据数据采集的结果来定义,名称与数据集里的相机名称要一致)。
4.修改/ACT/train.py创建一个check_points路径用于存储训练结果,并注释wandb相关内容
5.运行train.py即可训练模型

"ACT学习与推理"可能有多种含义,以下是几种常见的解释:
ACT算法中的学习与推理
- ACT算法:ACT(Action Chunking with Transformers)是一种基于Transformer的动作分块算法,用于机器人模仿学习。
- 学习过程:ACT算法通过将一系列动作划分为块,整体进行预测,减轻单步策略预测错误带来的严重影响。它使用生成式模型VAE(变分自动编码器)的方式训练模型,由Encoder部分和Decoder部分构成。
- 推理过程:在推理阶段,将隐变量设为0,使解码器输出一个最符合训练数据的平均策略,确保机器人执行稳定、可预测的动作。此外,ACT算法还采用了"时间集成"的策略,更频繁地查询策略并在重叠的动作块之间取平均值,保证整体动作的连贯性。
ACT-R认知架构中的学习与推理
- ACT-R认知架构:ACT-R(Adaptive Control of Thought - Rational)是一个人类认知理论,由美国人工智能专家和心理学家安德森(John R.Anderson)等人建立。
- 学习机制:ACT-R通过感知模块接收和处理环境信息,中央执行系统根据当前目标,决定访问声明性记忆还是程序性记忆。如果需要逻辑推理或解决问题,中央执行系统会利用symbolic系统中的规则和知识。
- 推理机制:在需要快速反应或模式识别时,中央执行系统则借助sub-symbolic系统,通过并行处理和统计学习完成任务。