一场关于AI算力的竞赛再次刷新纪录,这一次,英伟达将推理性能推向了新的高度。
在刚刚召开的GTC 2025大会上,英伟达CEO黄仁勋首次向世界展示了下一代Vera Rubin超级芯片。这款芯片以著名天文学家命名,正定义下一代计算模式。

官方数据显示,Vera Rubin NVL144平台可实现3.6 Exaflops的FP4推理算力与1.2 Exaflops的FP8训练算力,相较GB300 NVL72提升约3.3倍。

架构突破
Vera Rubin超级芯片采用全新的架构设计,主板整合了一颗Vera CPU与两颗Rubin GPU,配备最多32个LPDDR内存插槽。
而芯片内部构造方面, Rubin GPU拥有8个HBM4接口及两颗光罩尺寸相同的GPU核心芯片,由台积电代工生产,目前已进入实验室测试阶段。
Vera CPU则搭载88个定制Arm架构核心,最高支持176线程,为整个系统提供强大的通用处理能力。
在互联技术上,NVLINK-C2C互联带宽达到1.8 TB/s,系统总显存带宽为13 TB/s,快速存储容量为75 TB,分别较上一代提升60%。
这种架构设计使得Vera Rubin在保持高性能的同时,能够高效处理大规模AI工作负载。
产品路线图:从NVL144到Ultra NVL576
英伟达已经规划了清晰的产品蓝图。根据计划,Rubin GPU预计将在2026年第三或第四季度进入量产,时间点与现有的Blackwell Ultra"GB300"Superchip全面量产相当,甚至可能更早。
针对不同市场需求,英伟达准备了两大平台。首先是2026年下半年推出的Vera Rubin NVL144平台,配备两颗Rubin GPU,提供50 PFLOPS的FP4精度算力,搭载288 GB HBM4显存。
更为强大的Rubin Ultra NVL576平台则计划于2027年下半年亮相,将NVL规模从144扩展至576。
这一平台的GPU升级为四颗Reticle尺寸核心,性能最高达100 PFLOPS,搭载1 TB HBM4e显存。
Rubin Ultra NVL576平台的FP4推理算力达到15 Exaflops,FP8训练算力为5 Exaflops,相较GB300 NVL72提升高达14倍。

显存带宽和快速存储容量更是分别达到上一代的8倍。
推理专用:Rubin CPX的成本革新
除了主打产品,英伟达还专门针对推理场景推出了Rubin CPX,这一设计显著降低了长上下文推理和视频生成应用的成本。
Rubin CPX采用与传统Rubin芯片不同的技术路径,配备128GB GDDR7显存,NVFP4优化算力达30PFLOPS,专为百万级token的推理场景优化。

而在成本方面,Rubin CPX的BOM成本可能低至标准Rubin平台的四分之一。
这种成本降低主要来自四个方面,包括用GDDR取代HBM使每GB成本降低约50%,采用成熟的FCBGA单die封装规避CoWoS带来的成本上升和良率损失,以及无须NVLink Scale-up而节约约8000美元/GPU的扩展成本。
黄仁勋特别强调,Rubin平台并非单纯为AI设计,而是兼顾科研与AI的双重任务。
它未为低精度AI性能牺牲传统高效能运算能力,依旧支持高精度FP64科学计算,确保物理模拟、气候模型、量子化学等科研任务能获得充分性能。
惠普协助构建的系统将部署于美国洛斯阿拉莫斯国家实验室,分别命名为"Mission"和"Vision",前者专注国安任务,计划在2027年上线,后者服务开放科研与AI模型开发。
性能预计将较实验室前代系统Venado提升一倍以上。
在AI推理层面,Rubin平台的技术突破将直接降低大规模模型部署的门槛。尤其是其3.6 Exaflops的FP4推理算力,为未来多模态大模型的实时应用扫清了算力障碍。
从Blackwell到Vera Rubin,英伟达在一年内完成了两次架构迭代,这种创新速度令竞争对手难以企及。
黄仁勋在舞台上展示那颗承载着88个Arm核心的Vera CPU时,业界看到的是一个正在重新定义计算界限的公司。
随着2026年Rubin芯片的量产,AI推理的成本曲线将继续下探,这意味着智能体时代的应用场景将迎来新一轮爆发。
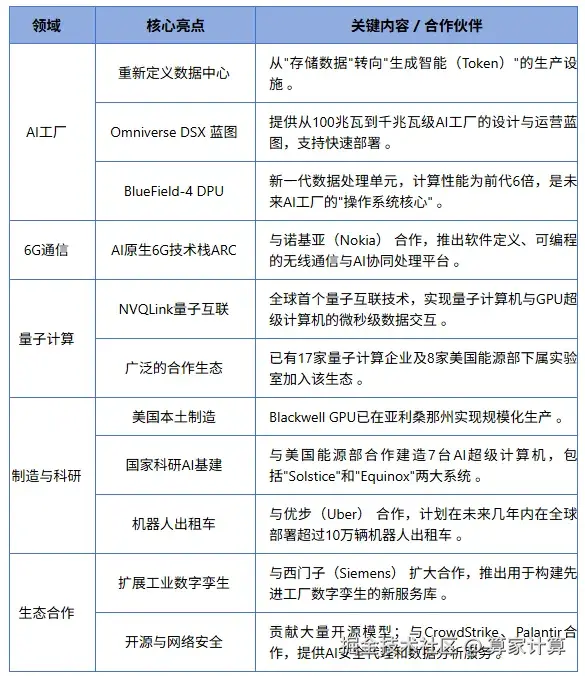
除了备受瞩目的Vera Rubin超级芯片,黄仁勋在GTC 2025大会上还勾勒了一幅更为宏大的技术蓝图,核心围绕AI工厂、6G通信、量子计算以及美国本土制造与科研基建展开 。
算家云将所有关键亮点整理成了表格,帮大家快速了解本次大会的全貌:
总的来说,在所有这些具体发布的背后,贯穿着两个核心的技术理念:
极端协同设计:英伟达强调从芯片、系统、软件栈到AI模型和应用的全链路同步设计与优化,以最大化整体系统的性能和效率。
软件生态是核心壁垒:黄仁勋将庞大的CUDA-X全栈加速库称为"公司最珍贵的宝藏"。这个包含超过350个专用库的软件生态,构成了其技术护城河,支撑着从计算光刻到量子计算等众多关键领域 。