作者:默语佬
CSDN技术博主
原创文章,转载请注明出处
前言
上周在做代码Review时,看到一段让我印象深刻的SQL查询:
sql
SELECT DISTINCT user_id FROM orders WHERE status = 'completed';我建议改成GROUP BY,理由是"性能更好"。结果小伙伴反问了一句:"这不都是去重吗?DISTINCT写起来更简单,为啥要用GROUP BY?"
这个问题让我意识到,很多开发者对DISTINCT和GROUP BY的理解还停留在表面。他们知道两者都能"去重",但不清楚背后的执行原理、性能差异、以及各自适用的场景。
作为一名在数据库优化领域深耕多年的架构师,我见过太多因为误用DISTINCT或GROUP BY导致的性能问题:慢查询、索引失效、额外的排序开销。今天,我将从SQL执行原理、性能分析、实战场景三个维度,深度剖析DISTINCT与GROUP BY的本质差异,帮助大家写出更高效的SQL。
目录
- 去重操作的本质:从执行计划看原理
- DISTINCT详解:简单高效的去重利器
- [GROUP BY剖析:强大的分组聚合引擎](#GROUP BY剖析:强大的分组聚合引擎)
- 性能对决:五个维度的深度分析
- 实战场景:如何选择正确的去重方案
- 性能优化:索引与执行计划调优
- 踩坑经验与最佳实践
去重操作的本质:从执行计划看原理
SQL去重的底层实现
很多人认为DISTINCT和GROUP BY是完全不同的两个特性,但实际上,在MySQL的执行层面,它们使用了相似的去重算法。让我们通过执行计划来理解这个本质:
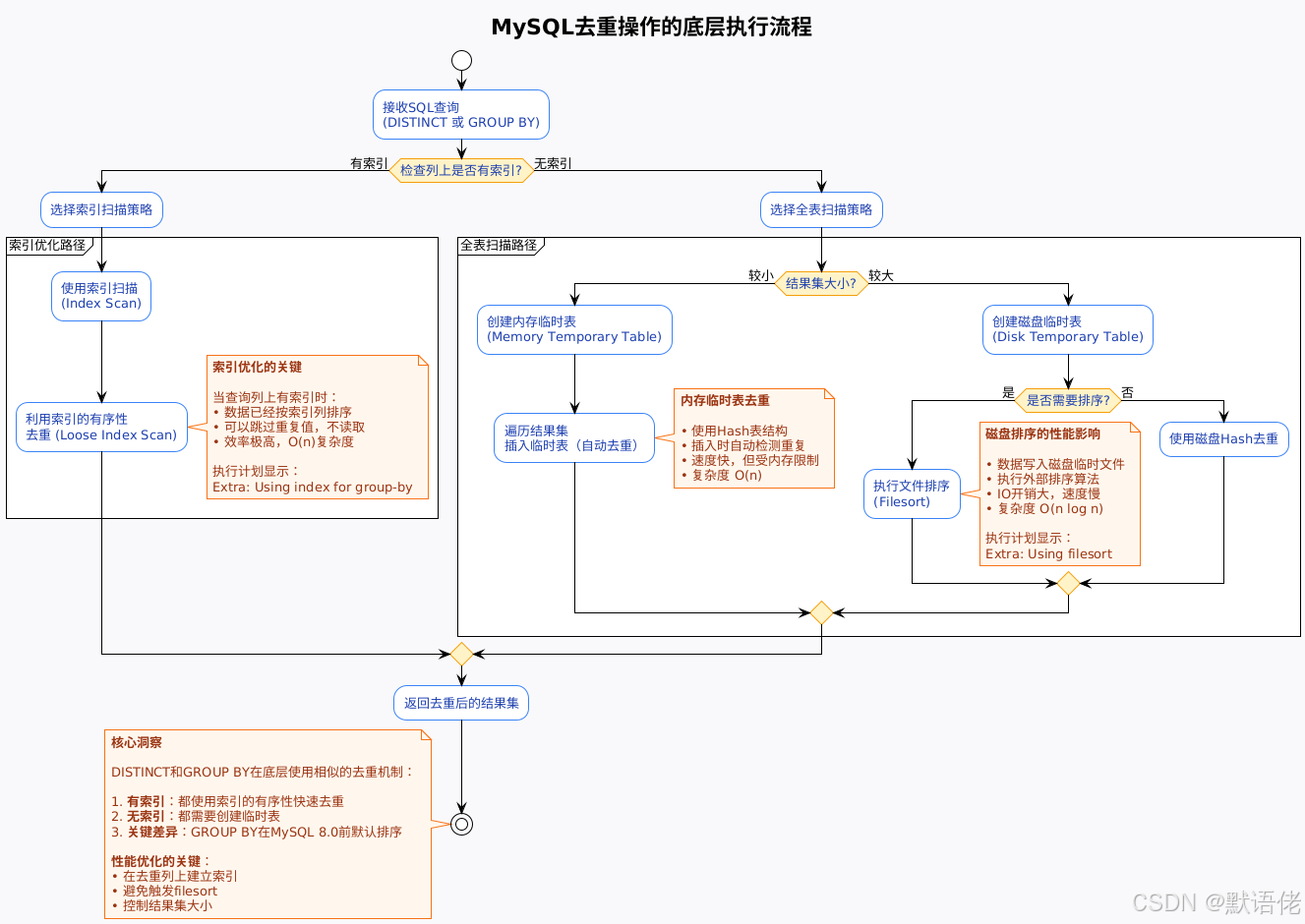
我的深度理解:很多开发者误以为DISTINCT是一个"神奇的关键字",能瞬间去重。实际上,去重是一个计算密集型操作,需要比较每一行数据。MySQL的优化器会根据是否有索引、结果集大小等因素,选择不同的执行策略。理解这个底层原理,是写出高性能SQL的前提。
DISTINCT与GROUP BY的执行计划对比
让我们通过一个实验来验证两者的相似性:
sql
-- 准备测试表
CREATE TABLE test_dedup (
id INT PRIMARY KEY AUTO_INCREMENT,
category VARCHAR(50),
city VARCHAR(50),
amount DECIMAL(10,2),
INDEX idx_category (category),
INDEX idx_city (city)
) ENGINE=InnoDB;
-- 插入10万条测试数据
INSERT INTO test_dedup (category, city, amount)
SELECT
CONCAT('Category', FLOOR(1 + RAND() * 100)),
CONCAT('City', FLOOR(1 + RAND() * 50)),
ROUND(RAND() * 1000, 2)
FROM
(SELECT 1 UNION SELECT 2 UNION SELECT 3 /* ... 生成足够行数 */) t1,
(SELECT 1 UNION SELECT 2 UNION SELECT 3 /* ... */) t2;对比实验1:有索引的列
sql
-- DISTINCT查询
EXPLAIN SELECT DISTINCT category FROM test_dedup;
-- GROUP BY查询
EXPLAIN SELECT category FROM test_dedup GROUP BY category;执行计划结果(MySQL 8.0):
| 字段 | DISTINCT | GROUP BY | 说明 |
|---|---|---|---|
| type | index | index | 都使用索引扫描 |
| key | idx_category | idx_category | 都使用同一索引 |
| Extra | Using index for group-by (scanning) | Using index for group-by (scanning) | 完全相同! |
关键发现:在有索引的情况下,DISTINCT和GROUP BY使用完全相同的执行计划!MySQL优化器将DISTINCT内部转换为GROUP BY执行。
对比实验2:无索引的列
sql
-- DISTINCT查询(无索引列)
EXPLAIN SELECT DISTINCT amount FROM test_dedup;
-- GROUP BY查询(无索引列)
EXPLAIN SELECT amount FROM test_dedup GROUP BY amount;执行计划结果(MySQL 5.7):
| 字段 | DISTINCT | GROUP BY | 差异分析 |
|---|---|---|---|
| type | ALL | ALL | 都是全表扫描 |
| Extra | Using temporary | Using temporary; Using filesort | GROUP BY多了排序! |
关键发现:在MySQL 5.7及之前版本,GROUP BY会触发额外的排序操作,这是性能差异的根源。
DISTINCT详解:简单高效的去重利器
DISTINCT的核心特性
DISTINCT是SQL标准中的去重关键字,语义清晰,用法简单。让我们深入理解它的特性:
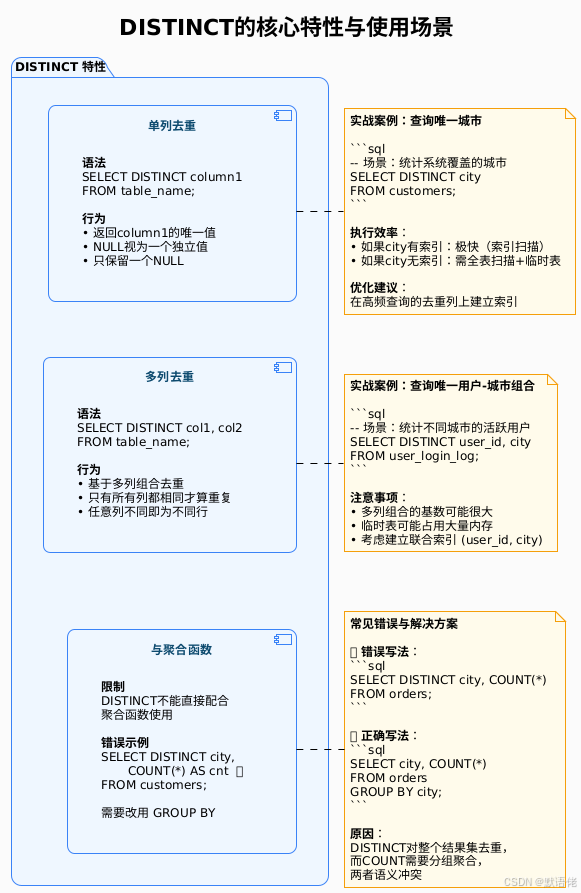
DISTINCT的NULL处理机制
这是一个容易被忽略但非常重要的特性:
sql
-- 创建测试数据
CREATE TABLE test_null (
id INT,
city VARCHAR(50)
);
INSERT INTO test_null VALUES
(1, 'Beijing'),
(2, 'Shanghai'),
(3, NULL),
(4, NULL),
(5, 'Beijing');
-- DISTINCT查询
SELECT DISTINCT city FROM test_null;
-- 结果:
-- Beijing
-- Shanghai
-- NULL <- 只保留一个NULL我的经验总结:在实际业务中,NULL值的处理常常是数据质量问题的来源。DISTINCT将多个NULL合并为一个,可能掩盖了数据问题。建议在去重前先清洗NULL值:
sql
-- 推荐做法:排除NULL后再去重
SELECT DISTINCT city
FROM test_null
WHERE city IS NOT NULL;DISTINCT的性能陷阱
陷阱1:大结果集的全表扫描
sql
-- 危险的查询(100万行数据)
SELECT DISTINCT user_id
FROM large_order_table; -- 可能触发磁盘临时表优化方案:
sql
-- 方案1:添加索引
ALTER TABLE large_order_table ADD INDEX idx_user_id(user_id);
-- 方案2:限制结果集
SELECT DISTINCT user_id
FROM large_order_table
WHERE order_date >= '2024-01-01'; -- 先过滤再去重陷阱2:多列组合的基数爆炸
sql
-- 危险的查询(组合基数可能很大)
SELECT DISTINCT user_id, ip_address, device_id
FROM access_log; -- 可能产生数百万唯一组合优化建议:评估组合列的基数,如果接近总行数,说明去重意义不大,考虑是否真的需要DISTINCT。
GROUP BY剖析:强大的分组聚合引擎
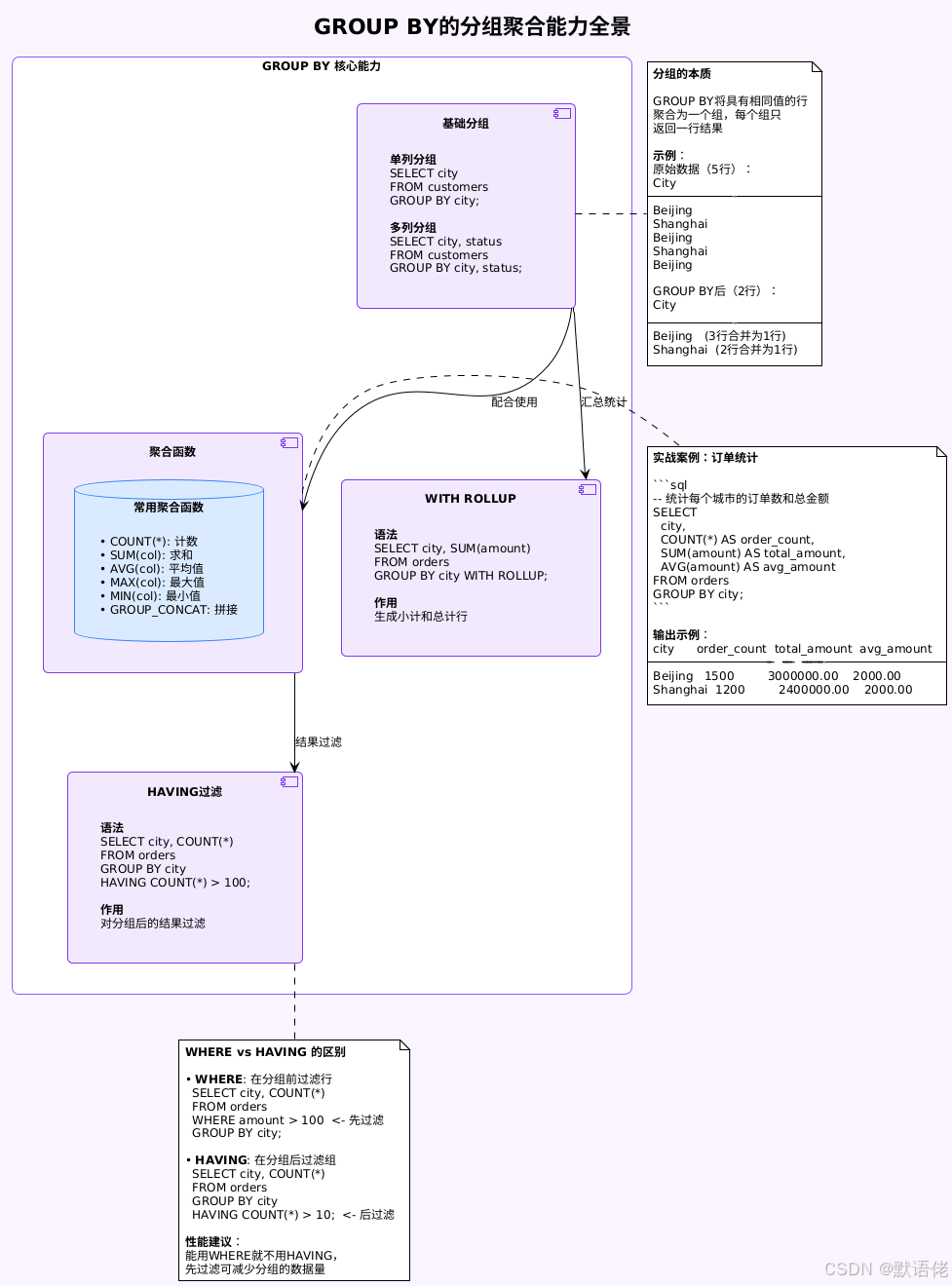
GROUP BY的核心能力
GROUP BY不仅能去重,更重要的是提供了强大的分组聚合能力:
GROUP BY的高级特性
特性1:多列分组的层次关系
sql
-- 按城市和类别两个维度统计
SELECT
city,
category,
COUNT(*) AS product_count,
SUM(sales) AS total_sales
FROM products
GROUP BY city, category
ORDER BY city, category;
-- 结果示例:
-- city category product_count total_sales
-- Beijing Electronics 150 500000
-- Beijing Clothing 200 300000
-- Shanghai Electronics 120 450000
-- Shanghai Clothing 180 280000特性2:WITH ROLLUP生成汇总行
sql
-- 生成多层级汇总
SELECT
city,
category,
SUM(sales) AS total_sales
FROM products
GROUP BY city, category WITH ROLLUP;
-- 结果示例:
-- city category total_sales
-- Beijing Electronics 500000
-- Beijing Clothing 300000
-- Beijing NULL 800000 <- 北京小计
-- Shanghai Electronics 450000
-- Shanghai Clothing 280000
-- Shanghai NULL 730000 <- 上海小计
-- NULL NULL 1530000 <- 总计我的实战经验:WITH ROLLUP在生成报表时非常有用,可以一次查询得到明细+小计+总计,避免多次查询或应用层计算。但要注意,ROLLUP生成的汇总行用NULL表示,前端展示时需要特殊处理。
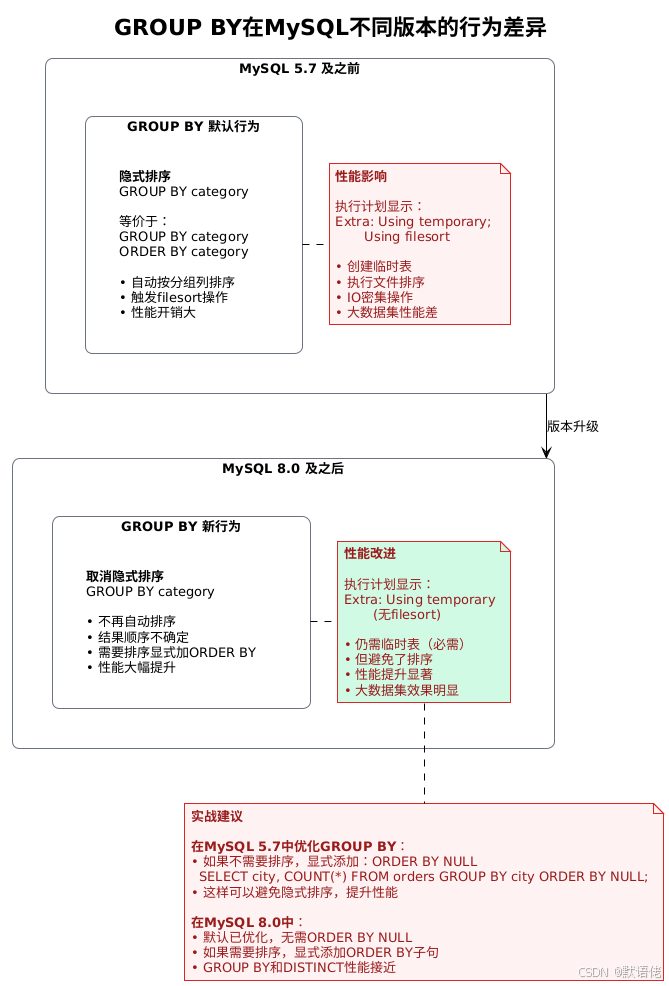
GROUP BY在MySQL 8.0的重要变化
这是一个影响性能的关键改进:
性能对比实验(100万行数据):
| 版本 | SQL | 执行时间 | Extra |
|---|---|---|---|
| MySQL 5.7 | SELECT city FROM orders GROUP BY city |
3.2秒 | Using filesort |
| MySQL 5.7 | SELECT city FROM orders GROUP BY city ORDER BY NULL |
1.1秒 | 无filesort |
| MySQL 8.0 | SELECT city FROM orders GROUP BY city |
1.0秒 | 无filesort |
| MySQL 8.0 | SELECT DISTINCT city FROM orders |
1.0秒 | 性能相当 |
我的经验总结 :如果你的生产环境还在用MySQL 5.7,记得在不需要排序的GROUP BY查询中添加ORDER BY NULL,这是一个简单但有效的优化技巧。升级到MySQL 8.0后,这个优化就不需要了。
性能对决:五个维度的深度分析
性能测试实战
测试环境:
- MySQL 8.0.32
- 表数据:100万行
- 服务器:8核16GB
- 存储:SSD
测试1:有索引的列去重
sql
-- 准备测试表
CREATE TABLE perf_test (
id INT PRIMARY KEY AUTO_INCREMENT,
category VARCHAR(50),
city VARCHAR(50),
amount DECIMAL(10,2),
INDEX idx_category (category),
INDEX idx_city (city)
) ENGINE=InnoDB;
-- 插入100万行测试数据(100个唯一类别)
-- ...
-- 测试DISTINCT
SELECT DISTINCT category FROM perf_test;
-- 执行时间:0.05秒
-- 执行计划:Using index for group-by
-- 测试GROUP BY
SELECT category FROM perf_test GROUP BY category;
-- 执行时间:0.05秒
-- 执行计划:Using index for group-by
-- 结论:性能完全相同!测试2:无索引的列去重
sql
-- 测试DISTINCT(无索引的amount列)
SELECT DISTINCT amount FROM perf_test;
-- 执行时间:1.2秒
-- 执行计划:Using temporary
-- 测试GROUP BY
SELECT amount FROM perf_test GROUP BY amount;
-- 执行时间:1.3秒
-- 执行计划:Using temporary
-- 结论:MySQL 8.0中性能相当(都约1.2秒)测试3:配合聚合函数
sql
-- DISTINCT无法实现
-- SELECT DISTINCT city, COUNT(*) FROM perf_test; -- 语法错误
-- GROUP BY轻松实现
SELECT city, COUNT(*) AS cnt, SUM(amount) AS total
FROM perf_test
GROUP BY city;
-- 执行时间:0.8秒(有索引)
-- 执行计划:Using index
-- 结论:聚合场景GROUP BY是唯一选择实战场景:如何选择正确的去重方案
基于我多年的实战经验,总结了以下场景的最佳实践:
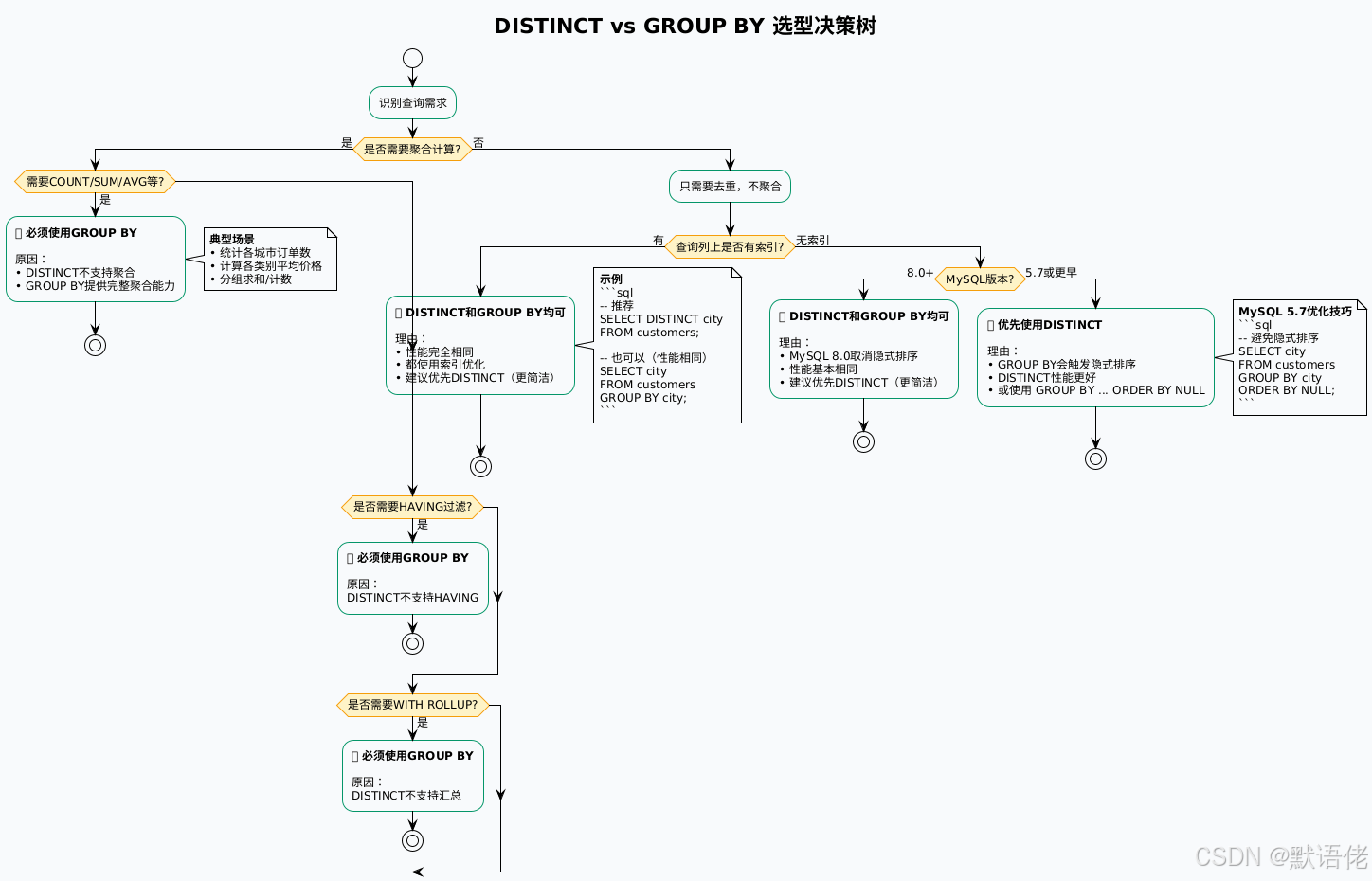
场景实战案例
场景1:用户城市统计(只去重)
sql
-- 需求:查询系统覆盖的所有城市
-- 特点:只需去重,不需聚合
-- ✅ 推荐方案:DISTINCT
SELECT DISTINCT city
FROM users
WHERE status = 'active';
-- 理由:
-- 1. 语义清晰(就是要去重)
-- 2. 代码简洁
-- 3. 性能足够好(如果city有索引)场景2:各城市用户数统计(去重+聚合)
sql
-- 需求:统计每个城市的活跃用户数
-- 特点:需要分组统计
-- ✅ 必须使用:GROUP BY
SELECT
city,
COUNT(*) AS user_count,
COUNT(DISTINCT user_id) AS unique_user_count
FROM user_activity
WHERE activity_date >= '2024-01-01'
GROUP BY city
HAVING user_count > 100 -- 筛选用户数>100的城市
ORDER BY user_count DESC;
-- 理由:
-- 1. DISTINCT无法配合聚合函数
-- 2. 需要HAVING过滤分组结果
-- 3. GROUP BY是唯一选择场景3:订单状态分布(多列去重)
sql
-- 需求:查询订单状态和支付方式的所有组合
-- 特点:多列去重
-- ✅ 方案1:DISTINCT(推荐)
SELECT DISTINCT order_status, payment_method
FROM orders;
-- ✅ 方案2:GROUP BY(功能等价)
SELECT order_status, payment_method
FROM orders
GROUP BY order_status, payment_method;
-- 选择建议:
-- • 如果只是去重:用DISTINCT(更直观)
-- • 如果后续可能需要统计:用GROUP BY(便于扩展)场景4:用户行为漏斗分析(复杂统计)
sql
-- 需求:分析用户从注册到购买的转化率
-- 特点:多层级统计,复杂聚合
-- ✅ 必须使用:GROUP BY + 子查询
SELECT
DATE(created_at) AS date,
COUNT(DISTINCT user_id) AS registered_users,
COUNT(DISTINCT CASE WHEN first_login_at IS NOT NULL THEN user_id END) AS activated_users,
COUNT(DISTINCT CASE WHEN first_order_at IS NOT NULL THEN user_id END) AS purchased_users,
ROUND(COUNT(DISTINCT CASE WHEN first_order_at IS NOT NULL THEN user_id END) * 100.0 / COUNT(DISTINCT user_id), 2) AS conversion_rate
FROM users
WHERE created_at >= '2024-01-01'
GROUP BY DATE(created_at)
ORDER BY date DESC;
-- 理由:
-- 1. 涉及多个聚合指标
-- 2. 需要计算转化率
-- 3. 按日期分组
-- 4. DISTINCT无法满足需求我的经验总结 :实际业务中,80%的"去重"需求最终都会演变为"去重+统计"。所以我的建议是:如果是核心业务表的查询,即使当前只需要去重,也优先考虑GROUP BY,为将来的需求变更留有余地。
性能优化:索引与执行计划调优
索引优化策略
去重操作的性能优化,核心在于索引设计:
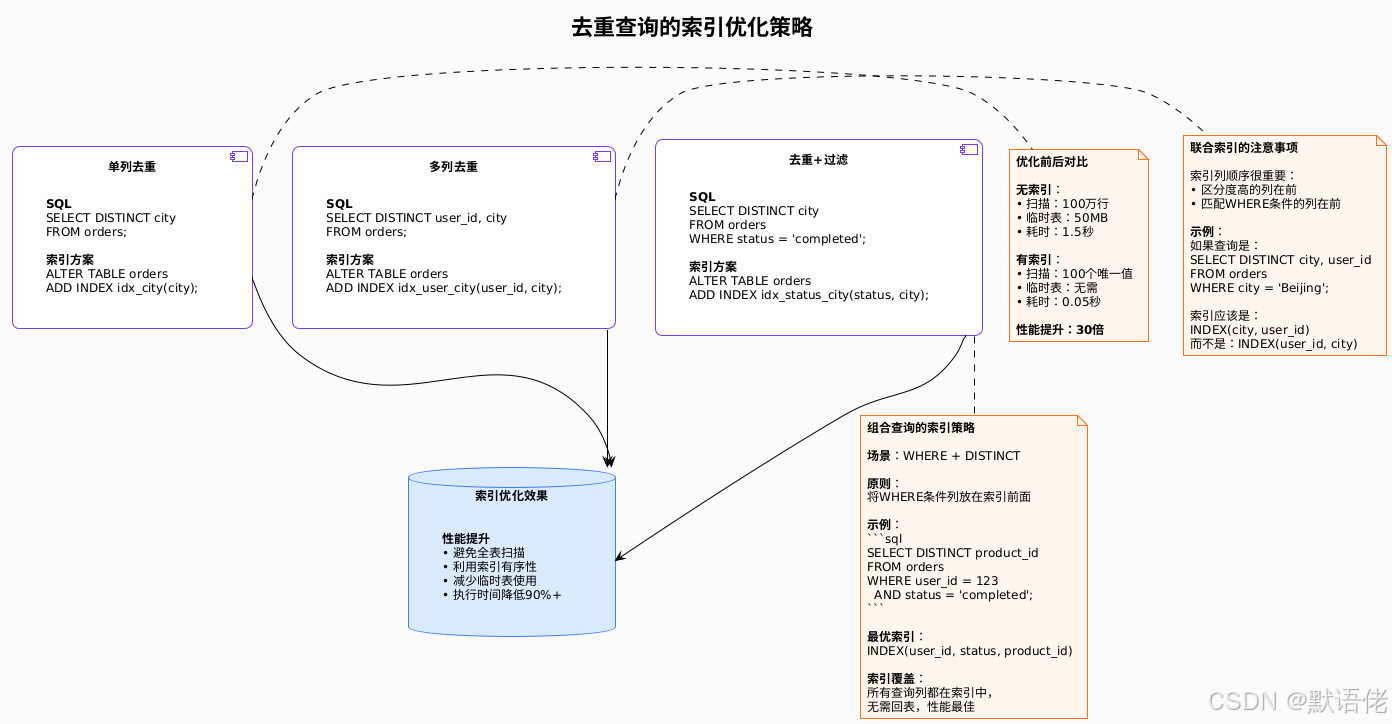
执行计划分析与调优
工具1:EXPLAIN分析
sql
-- 查看执行计划
EXPLAIN SELECT DISTINCT city FROM orders WHERE status = 'completed';
-- 关键字段解读:
-- type: 访问类型(ALL/index/range/ref等)
-- • ALL: 全表扫描(最慢)
-- • index: 索引扫描
-- • range: 索引范围扫描
-- • ref: 索引等值查询(最快)
--
-- key: 实际使用的索引
-- rows: 预估扫描的行数(越少越好)
-- Extra: 额外信息
-- • Using index: 索引覆盖(最优)
-- • Using index for group-by: 索引用于分组
-- • Using temporary: 使用临时表
-- • Using filesort: 文件排序(需优化)工具2:EXPLAIN FORMAT=JSON(更详细)
sql
-- JSON格式执行计划(MySQL 5.7+)
EXPLAIN FORMAT=JSON
SELECT DISTINCT city
FROM orders
WHERE status = 'completed';
-- 输出示例:
{
"query_block": {
"duplicates_removal": {
"using_temporary_table": false, -- 是否使用临时表
"using_filesort": false, -- 是否文件排序
"table": {
"access_type": "ref", -- 访问类型
"key": "idx_status_city", -- 使用的索引
"used_key_parts": ["status"], -- 索引使用部分
"rows_examined_per_scan": 500 -- 每次扫描行数
}
}
}
}实战调优案例:
问题SQL(慢查询日志发现):
sql
SELECT DISTINCT product_category
FROM orders
WHERE order_date >= '2024-01-01';
-- 执行时间:5.2秒
-- 扫描行数:200万行执行计划分析:
sql
EXPLAIN SELECT DISTINCT product_category
FROM orders
WHERE order_date >= '2024-01-01';
-- type: ALL <- 全表扫描!
-- key: NULL <- 没有使用索引!
-- rows: 2000000 <- 扫描200万行
-- Extra: Using where; Using temporary <- 使用临时表优化方案1:添加单列索引
sql
ALTER TABLE orders ADD INDEX idx_date(order_date);
-- 优化后执行计划:
-- type: range <- 改为范围扫描
-- key: idx_date <- 使用了索引
-- rows: 500000 <- 只扫描50万行(2024年的订单)
-- Extra: Using where; Using temporary
-- 执行时间:1.8秒
-- 性能提升:3倍优化方案2:添加覆盖索引(更优)
sql
ALTER TABLE orders ADD INDEX idx_date_category(order_date, product_category);
-- 优化后执行计划:
-- type: range <- 范围扫描
-- key: idx_date_category <- 使用覆盖索引
-- rows: 500000
-- Extra: Using where; Using index for group-by <- 索引覆盖!
-- 执行时间:0.3秒
-- 性能提升:17倍!我的调优经验:
- 先看type:如果是ALL(全表扫描),必须优化
- 再看key:如果是NULL(无索引),考虑添加索引
- 关注Extra :
- 看到
Using filesort:考虑添加排序索引 - 看到
Using temporary:检查是否可以用索引避免 - 看到
Using index:最优状态,无需优化
- 看到
踩坑经验与最佳实践
常见的坑与避坑指南
坑1:误用DISTINCT导致性能问题
sql
-- ❌ 错误示例:对大表的多列使用DISTINCT
SELECT DISTINCT user_id, ip_address, user_agent, timestamp
FROM access_log
WHERE log_date = '2024-01-01';
-- 问题:
-- • 组合列的基数极大(几乎每行都不重复)
-- • DISTINCT失去意义,但仍产生去重开销
-- • 可能创建巨大的临时表
-- ✅ 正确做法:评估是否真的需要DISTINCT
-- 如果基数接近总行数,去掉DISTINCT反而更快
SELECT user_id, ip_address, user_agent, timestamp
FROM access_log
WHERE log_date = '2024-01-01'
LIMIT 10000; -- 如果只是取样,直接LIMIT坑2:GROUP BY后忘记显式排序
sql
-- ❌ 错误示例:期望结果有序,但没有ORDER BY
SELECT city, COUNT(*) AS cnt
FROM orders
GROUP BY city;
-- 问题(MySQL 8.0):
-- • 结果顺序不确定(不再隐式排序)
-- • 每次执行顺序可能不同
-- • 分页查询可能出现重复或遗漏
-- ✅ 正确做法:显式添加ORDER BY
SELECT city, COUNT(*) AS cnt
FROM orders
GROUP BY city
ORDER BY cnt DESC; -- 明确排序规则坑3:在SELECT列表中使用非分组列
sql
-- ❌ 错误示例(MySQL 5.7 ONLY_FULL_GROUP_BY模式下报错)
SELECT city, user_name, COUNT(*) AS cnt
FROM orders
GROUP BY city;
-- 错误信息:
-- Expression #2 of SELECT list is not in GROUP BY clause
-- and contains nonaggregated column 'user_name'
-- 问题:
-- • user_name不在GROUP BY中
-- • 也不是聚合函数
-- • MySQL 8.0默认启用ONLY_FULL_GROUP_BY,会报错
-- ✅ 方案1:将列加入GROUP BY
SELECT city, user_name, COUNT(*) AS cnt
FROM orders
GROUP BY city, user_name;
-- ✅ 方案2:使用聚合函数
SELECT city, MAX(user_name) AS sample_user, COUNT(*) AS cnt
FROM orders
GROUP BY city;
-- ✅ 方案3:使用ANY_VALUE(MySQL 5.7+)
SELECT city, ANY_VALUE(user_name) AS sample_user, COUNT(*) AS cnt
FROM orders
GROUP BY city;坑4:HAVING中使用WHERE条件
sql
-- ❌ 错误示例:在HAVING中过滤行
SELECT city, COUNT(*) AS cnt
FROM orders
GROUP BY city
HAVING status = 'completed'; -- 错误!status不是聚合结果
-- 问题:
-- • HAVING用于过滤分组后的结果
-- • 不能用于过滤原始行
-- • 而且性能差(先分组再过滤)
-- ✅ 正确做法:WHERE过滤行,HAVING过滤组
SELECT city, COUNT(*) AS cnt
FROM orders
WHERE status = 'completed' -- 先过滤行
GROUP BY city
HAVING cnt > 100; -- 再过滤组最佳实践总结

性能优化Checklist
SQL编写阶段:
- 评估是否真的需要去重(基数检查)
- 选择DISTINCT还是GROUP BY(根据是否需要聚合)
- 先WHERE过滤再GROUP BY(减少分组数据量)
- 显式添加ORDER BY(如果需要排序)
索引设计阶段:
- 在去重列上建立索引
- 对于多列去重,考虑联合索引
- 对于WHERE + DISTINCT,索引包含WHERE条件列
- 检查索引覆盖(避免回表)
执行优化阶段:
- 使用EXPLAIN分析执行计划
- 检查type是否为ALL(全表扫描)
- 检查Extra是否有Using filesort
- 监控临时表大小(tmp_table_size)
MySQL版本相关:
- MySQL 5.7:GROUP BY添加ORDER BY NULL(避免隐式排序)
- MySQL 8.0:GROUP BY需显式ORDER BY(已取消隐式排序)
- 启用ONLY_FULL_GROUP_BY模式(避免SQL歧义)
实战总结
经过深度分析和实战验证,我总结了以下核心要点:
核心观点
-
DISTINCT和GROUP BY不是对立的,而是功能互补的
- DISTINCT:专注于去重,语义清晰
- GROUP BY:提供分组聚合能力,功能强大
- 选择的关键在于是否需要聚合计算
-
性能差异主要来自MySQL版本和索引
- MySQL 8.0后,两者性能接近
- 索引是性能的关键,有索引都快,无索引都慢
- 不要盲目追求"哪个更快",而要针对性优化
-
代码可维护性同样重要
- 简单场景优先DISTINCT(更直观)
- 复杂场景使用GROUP BY(更灵活)
- 考虑未来需求变更,留有扩展余地
选型速查表
| 需求描述 | 推荐方案 | 示例SQL |
|---|---|---|
| 查询唯一值列表 | SELECT DISTINCT | SELECT DISTINCT city FROM users |
| 统计每组数量 | GROUP BY + COUNT | SELECT city, COUNT(*) FROM users GROUP BY city |
| 计算每组总和/平均值 | GROUP BY + SUM/AVG | SELECT city, AVG(amount) FROM orders GROUP BY city |
| 过滤满足条件的组 | GROUP BY + HAVING | SELECT city, COUNT(*) FROM users GROUP BY city HAVING COUNT(*) > 100 |
| 多层级汇总统计 | GROUP BY + WITH ROLLUP | SELECT city, SUM(amount) FROM orders GROUP BY city WITH ROLLUP |
写在最后
作为一名数据库优化工程师,我最深的体会是:SQL优化没有银弹,只有针对具体场景的最优解。DISTINCT和GROUP BY各有优势,关键是理解它们的本质差异,根据业务需求做出正确选择。
我的建议是:
- 如果你是初学者,先掌握DISTINCT(简单直观),再学习GROUP BY(功能强大)
- 如果你在优化慢查询,先用EXPLAIN分析执行计划,再针对性添加索引
- 如果你在设计新系统,考虑在常用的去重/分组列上提前建立索引
- 如果你的生产环境还是MySQL 5.7,尽快规划升级到8.0(性能提升显著)
最后,记住一句话:好的SQL不是写出来的,是优化出来的。持续监控慢查询日志,不断优化索引设计,才能保证系统的长期稳定运行。
📝 关于作者
默语佬,CSDN技术博主,专注于数据库性能优化、MySQL架构设计、SQL调优等领域。十年数据库实战经验,服务过多个千万级数据量的系统。
技术专长:
- MySQL性能调优
- SQL优化与索引设计
- 数据库架构设计
- 慢查询分析与优化
联系方式:
- CSDN:默语佬
- 欢迎技术交流与合作
原创不易,如果这篇文章对你有帮助,请给个三连支持:点赞👍、收藏⭐、关注🔔!
有任何疑问欢迎评论区讨论,看到必回!如果你在SQL优化中遇到问题,也可以贴出执行计划,我会帮助分析~ 😊
版权声明:本文为默语佬原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。