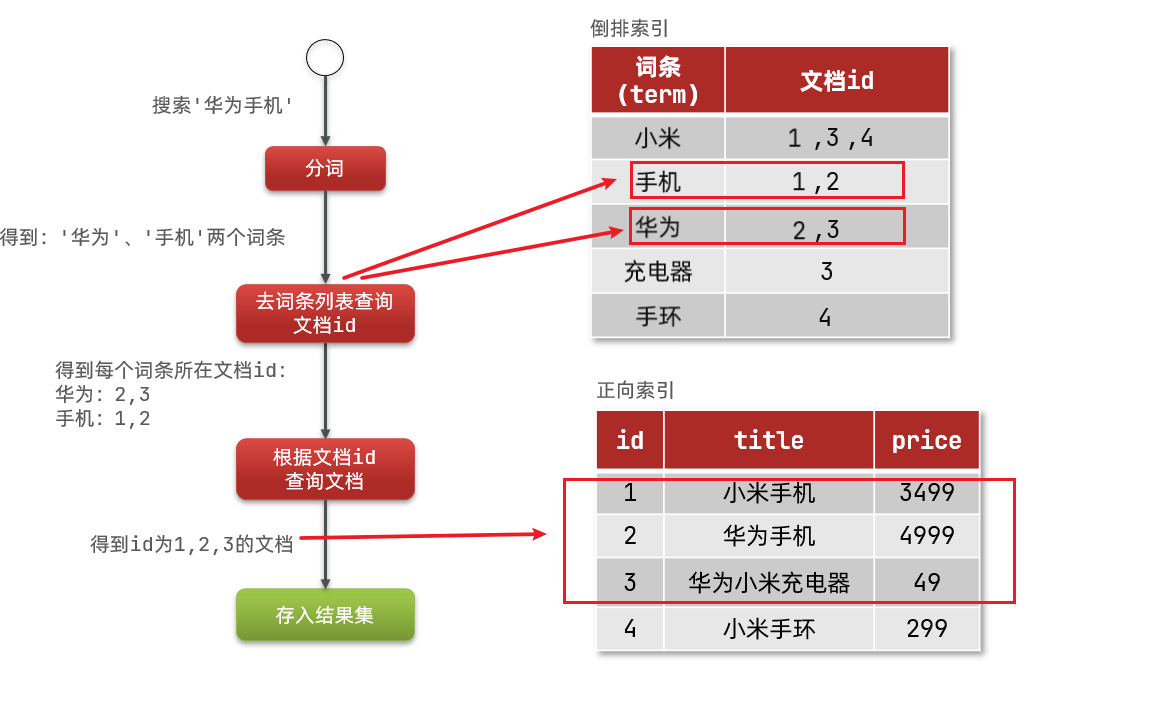
1.倒排索引 Ducument Term
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息。 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条。
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
- elasticsearch是面向文档(Document) 存储的,可以是数据库中的一条商品数据,一个订单信息。
2.索引和映射 Index Document Filed Mapping DSL
索引就像数据库里的表,映射就像数据库中定义的表结构。

3.分词器 ik_smart ik_max_word
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
4.索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。
4.1 Mapping映射属性 type(text keyword) index analyzer properties
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
keyword类型只能整体搜索,不支持搜索部分内容
-
数值:long、integer、short、byte、double、float、
-
布尔:boolean
-
日期:date
-
对象:object
-
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
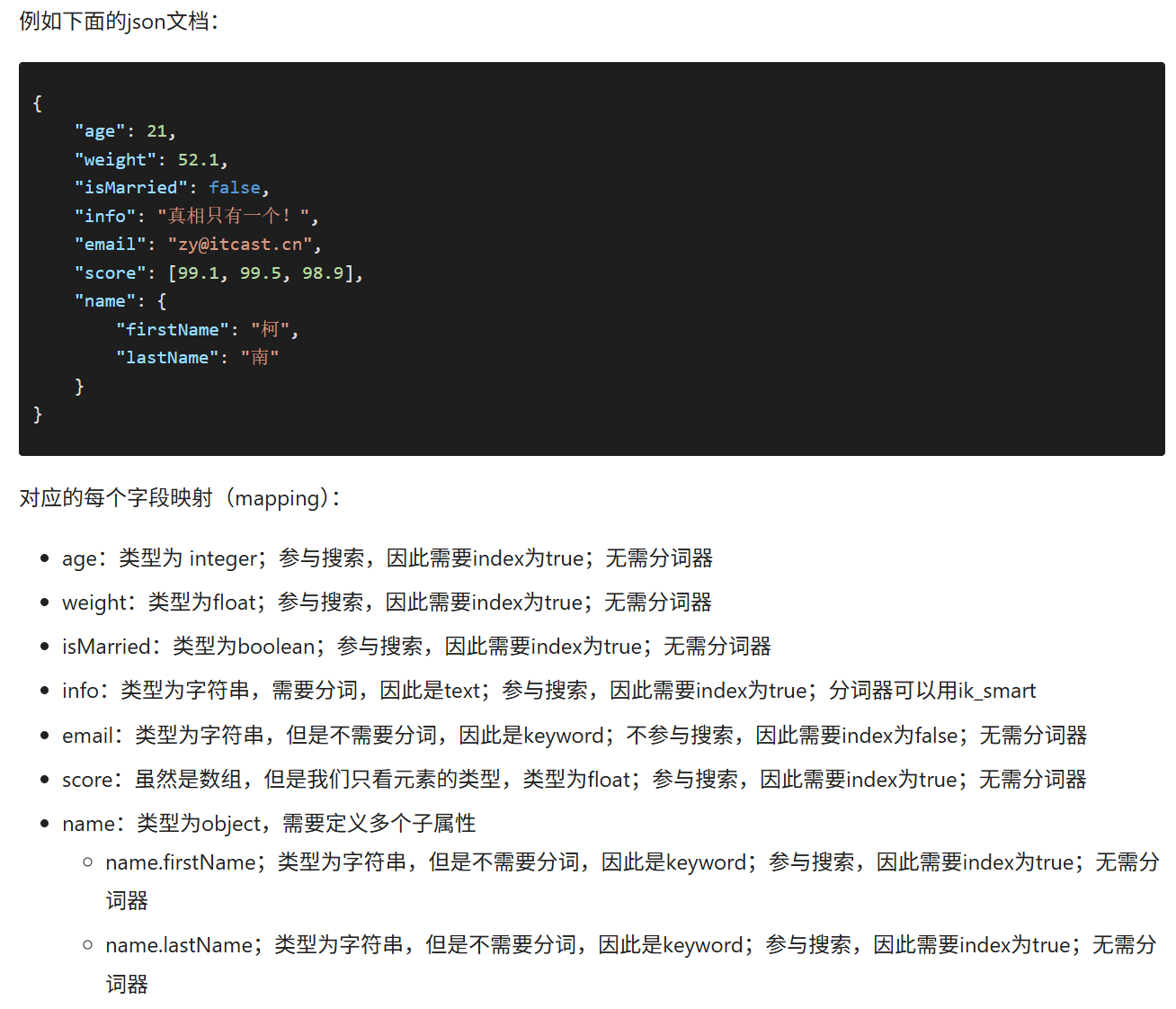
4.2索引库的CRUD
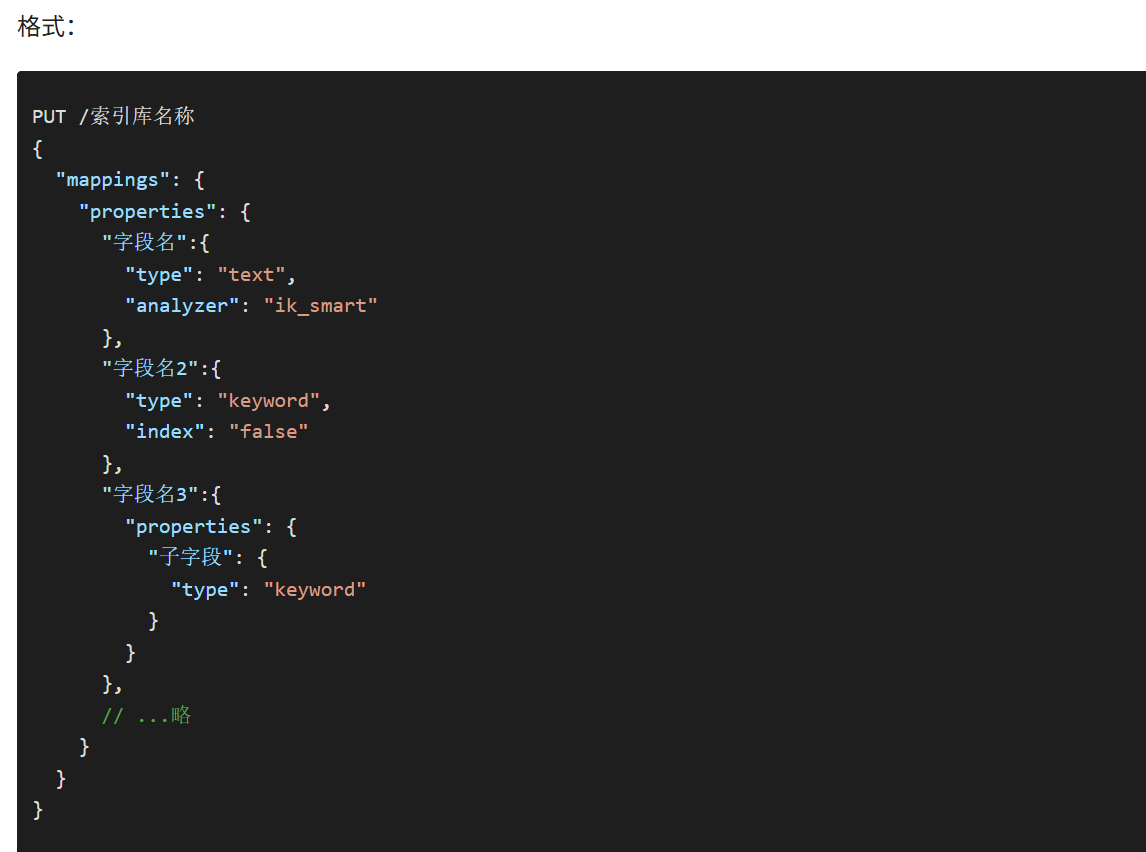
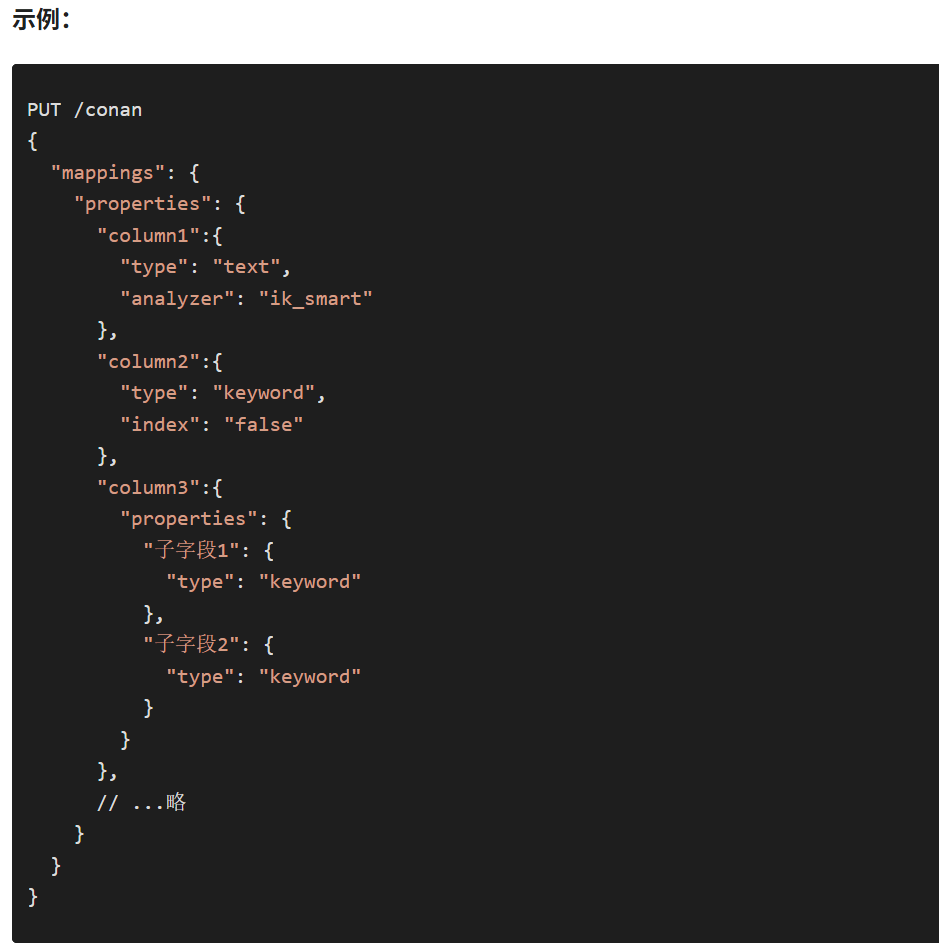
4.2.1创建索引库和映射 PUT /xxx {"mappings": {"properties":{"字段名":{"type": "text"} } } }
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
4.3文档的CRUD

4.4地理坐标和copy_to:字段拷贝

5.ES搜索引擎
5.1 DSL查询分类
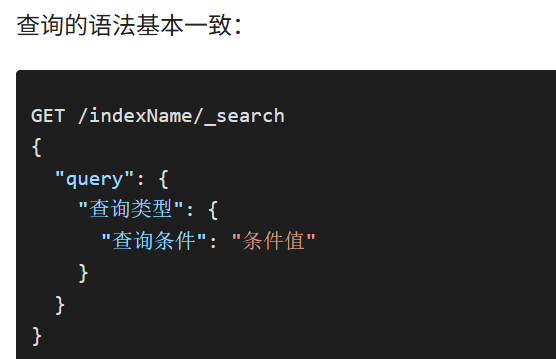
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
-
查询所有 :查询出所有数据,一般测试用。例如:match_all
-
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
-
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
- ids
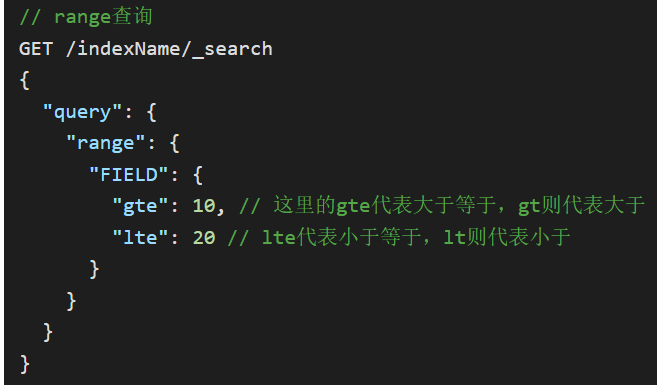
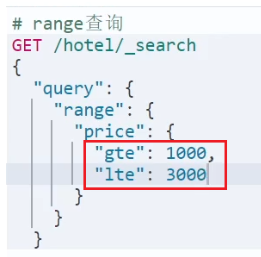
- range
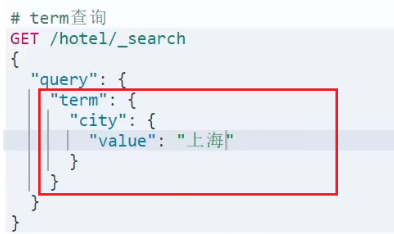
- term
-
地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
5.2全文检索查询
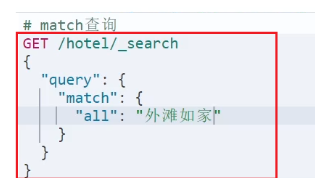
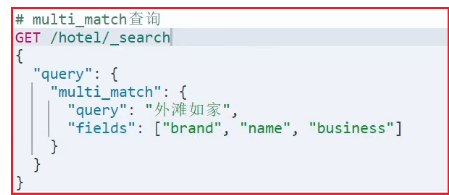
match和multi_match的区别是什么?
- match:根据一个字段查询【推荐:使用copy_to构造all字段】
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
注:搜索字段越多,对查询性能影响越大,因此建议采用copy_to,然后单字段查询的方式。
全文检索查询的基本流程如下:
- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户
比较常用的场景包括:
- 商城的输入框搜索
- 百度输入框搜索


5.3精准查询
精准查询类型:
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围

5.4地理坐标查询
5.5复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
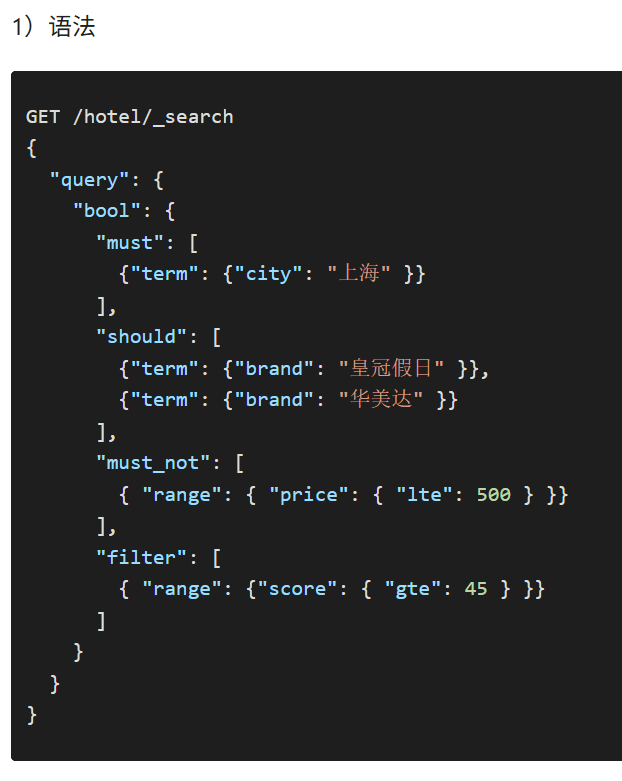
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似"与"
- should:选择性匹配子查询,类似"或"
- must_not:必须不匹配,不参与算分,类似"非"
- filter:必须匹配,不参与算分
注意:尽量在筛选的时候多使用不参与算分的must_not和filter,以保证性能良好
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
- 其它过滤条件,采用filter查询。不参与算分
6.设置搜索结果
查询的DSL是一个大的JSON对象,包含下列属性:
- query:查询条件
- from和size:分页条件
- sort:排序条件
- highlight:高亮条件
- aggs:定义聚合
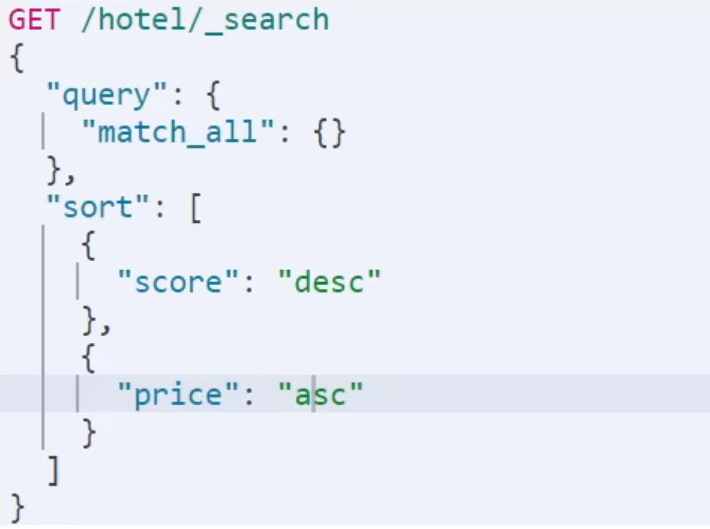
6.1排序
在使用排序后就不会进行算分了,根据排序设置的规则排列
普通字段是根据字典序排序地理坐标是根据举例远近排序
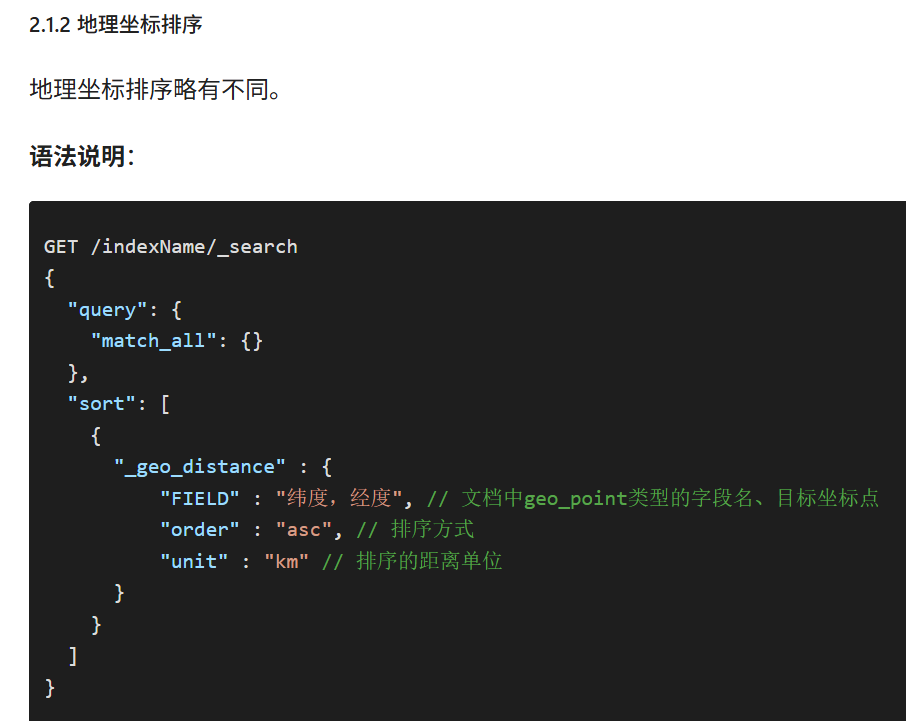
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
- 根据距离排序

6.2分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
6.3高亮
6.4数据聚合
**聚合(aggregations)**可以让我们极其方便的实现对数据的统计、分析、运算。
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
聚合种类
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型
Elasticsearch 常用聚合方法(aggs)分类:
-
桶聚合(分组)
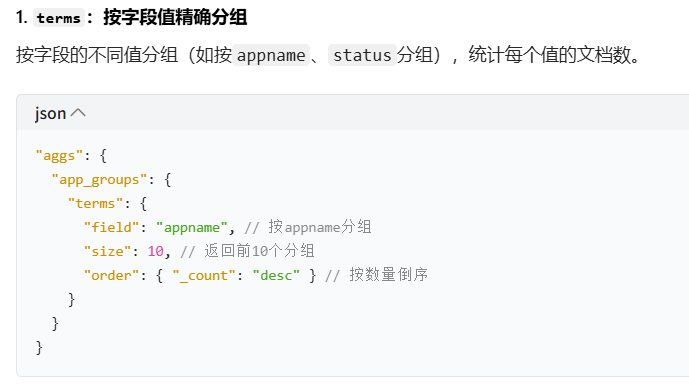
terms:按字段值精确分组(如按 appname)
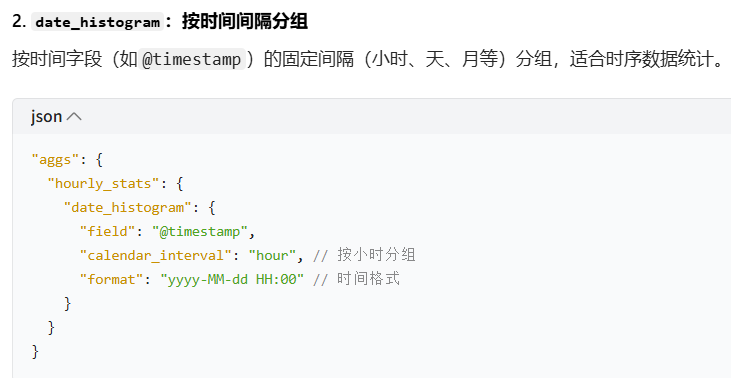
date_histogram:按时间间隔分组(如按小时 / 天)
range:按数值范围分组(如年龄分段)

filter/filters:按条件筛选单桶 / 多桶

-
指标聚合(计算)
count:统计文档数(默认doc_count)
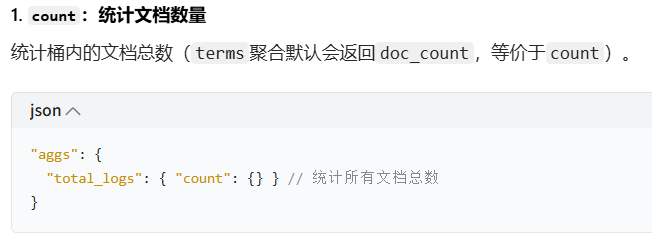
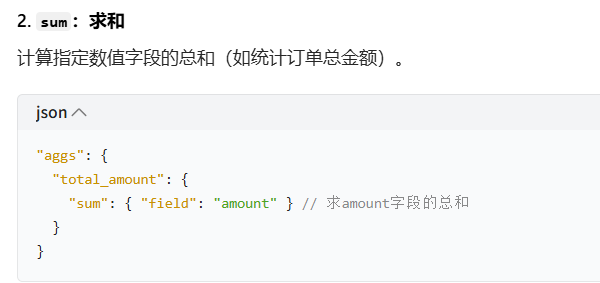
sum/avg:求和 / 平均值

max/min:最大 / 最小值

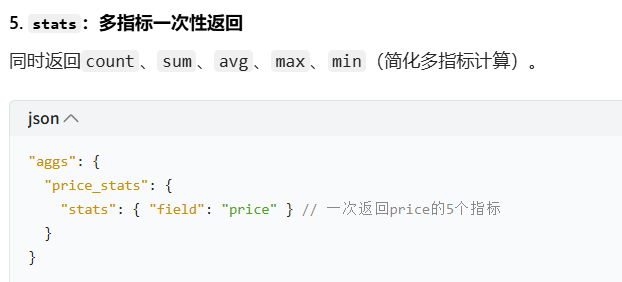
stats:一次性返回 count/sum/avg/max/min
-
管道聚合(二次计算)
avg_bucket:求多桶指标的平均值

max_bucket:找指标最大的桶

常用组合:桶聚合(分组)+ 指标聚合(算统计值),如按 appname 分组后算总日志量和平均响应时间。
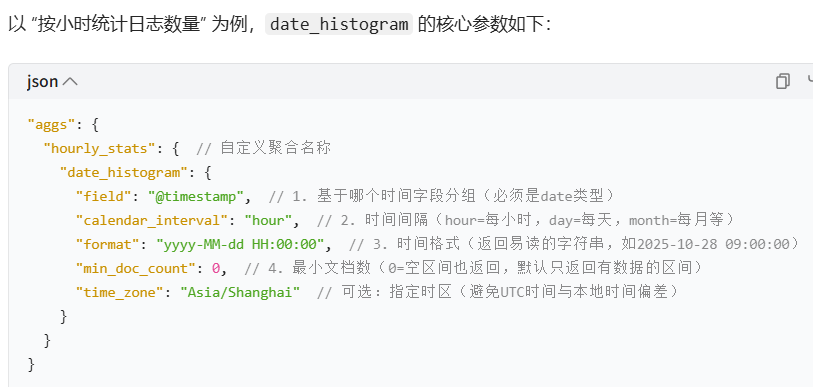
7.date_histogram 聚合
date_histogram 是 Elasticsearch 中专门用于时间字段的聚合分析功能,作用是按 "时间间隔"(如每小时、每天、每月)对数据进行分组,统计每个时间区间内的文档数量(或其他指标),生成 "时间分布直方图"。
简单说,它能帮你回答类似这样的问题:
- "今天每小时有多少条日志?"
- "过去 7 天每天的订单量是多少?"
- "每个月的用户注册数有多少?"
核心特点
- 只针对时间字段 :必须作用于
date类型的字段(如@timestamp日志时间戳、create_time创建时间等)。 - 按时间间隔分组:支持灵活的时间间隔(如小时、天、周、月,甚至分钟、季度等)。
- 自动填充空区间:可配置 "即使某段时间没有数据,也返回该区间并计数为 0",确保时间序列的连续性。
8.term和terms区别
term和terms均用于 Elasticsearch 的精确匹配,但核心区别在匹配值数量 和使用场景,具体可从 3 个维度区分:
1. 核心用途
term:针对单个值 的精确匹配,仅用于 "筛选符合某一个特定值" 的文档(如筛选appname=tg-portalweb)。terms:有两个场景,一是针对多个值 的精确匹配(如筛选appname为tg-portalweb或tg-userweb),二是用于聚合分组 (如按appname的不同值统计数据量)。
2. 输入值与作用阶段
term:输入单个值(如字符串"tg-portalweb"、数字1),仅在查询阶段生效,目的是过滤文档。terms:输入数组形式的多个值(如["a","b"]),可在查询阶段 (多值筛选)或聚合阶段(分组统计)生效。
3. 结果差异
term:返回 "字段值完全等于指定值" 的所有原始文档。terms:查询时返回 "字段值属于指定多值集合" 的原始文档;聚合时返回 "按字段值分组" 的统计结果(如每个分组的文档数量)。
9.总结
wildcard:通配符模糊查询
track_total_hits: true 精确统计(适用于超过 10000 条)
_source:配置需要保留的字段(数组形式)
date_histogram:按照小时/天/月统计每个时间范围内数据量