Kafka在企业级RAG系统中的最佳实践:从消息可靠性到异步流水线
本文深度解析如何用Kafka优雅地解耦大文件处理流程,涵盖事务保证、死信队列、流式处理等企业级实践。
📖 目录
- 一、业务场景:为什么需要异步解耦?
- 二、整体架构设计
- 三、Kafka事务保证数据一致性
- 四、Producer端可靠性配置详解
- 五、Consumer的错误处理与死信队列
- 六、完整的异步处理流水线
- 七、流式文档解析防止OOM
- 八、生产环境最佳实践
- 九、总结与思考
前言
在构建企业级RAG(检索增强生成)知识库系统时,我遇到了一个典型问题:
某天生产环境突然收到告警 :用户上传了100个文档,每个10MB,前端显示"上传成功",但用户在AI对话时查询不到任何内容。经过排查发现,文件已经上传到MinIO,但后续的文档解析和向量化流程从未执行。
这就是典型的同步处理导致的系统脆弱性问题。本文将分享我如何用Kafka构建一个健壮的异步文件处理流水线。
一、业务场景:为什么需要异步解耦?
1.1 文件处理的完整链路
在RAG系统中,一个文档从上传到可被检索,需要经历以下步骤:
scss
用户上传 → 分片上传 → 文件合并 → 文档解析 → 语义分块 → 向量化 → ES存储 → 可被检索
(5min) (2s) (30s) (10s) (60s) (5s)每一步都是耗时操作,如果采用同步处理:
- ❌ 用户体验差:上传一个10MB的PDF需要等待2分钟
- ❌ 资源浪费:HTTP连接长时间占用
- ❌ 扩展困难:单点处理能力有限
- ❌ 容错性差:任何一步失败都会导致整个流程失败
1.2 异步化的收益对比
| 对比维度 | 同步处理 | Kafka异步 | 提升 |
|---|---|---|---|
| 用户等待时间 | 120秒 | 2秒 | 98%↓ |
| 并发处理能力 | 10个/秒 | 100个/秒 | 10倍 |
| 系统资源利用率 | 峰值100% | 平均40% | 削峰填谷 |
| 容错性 | 失败即丢失 | 自动重试+死信队列 | 企业级 |
| 可扩展性 | 垂直扩展 | 水平扩展 | 无限 |
关键设计决策 :在"文件合并"和"文档解析"之间插入Kafka,实现上传流程 和处理流程的解耦。
二、整体架构设计
2.1 系统架构图
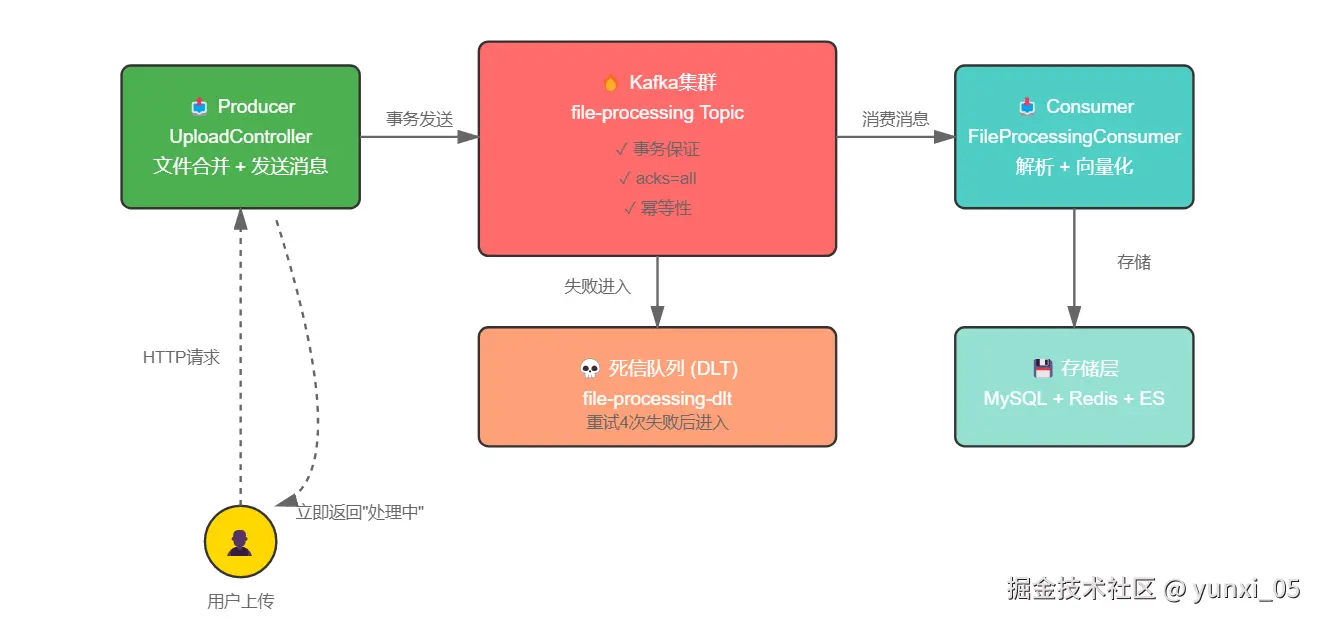 核心组件:
核心组件:
- Producer端:UploadController 负责文件合并后发送消息
- Kafka集群:消息中间件,提供可靠性保证
- Consumer端:FileProcessingConsumer 负责文档处理
- 死信队列:处理失败的消息隔离存储
2.2 完整的消息流转流程
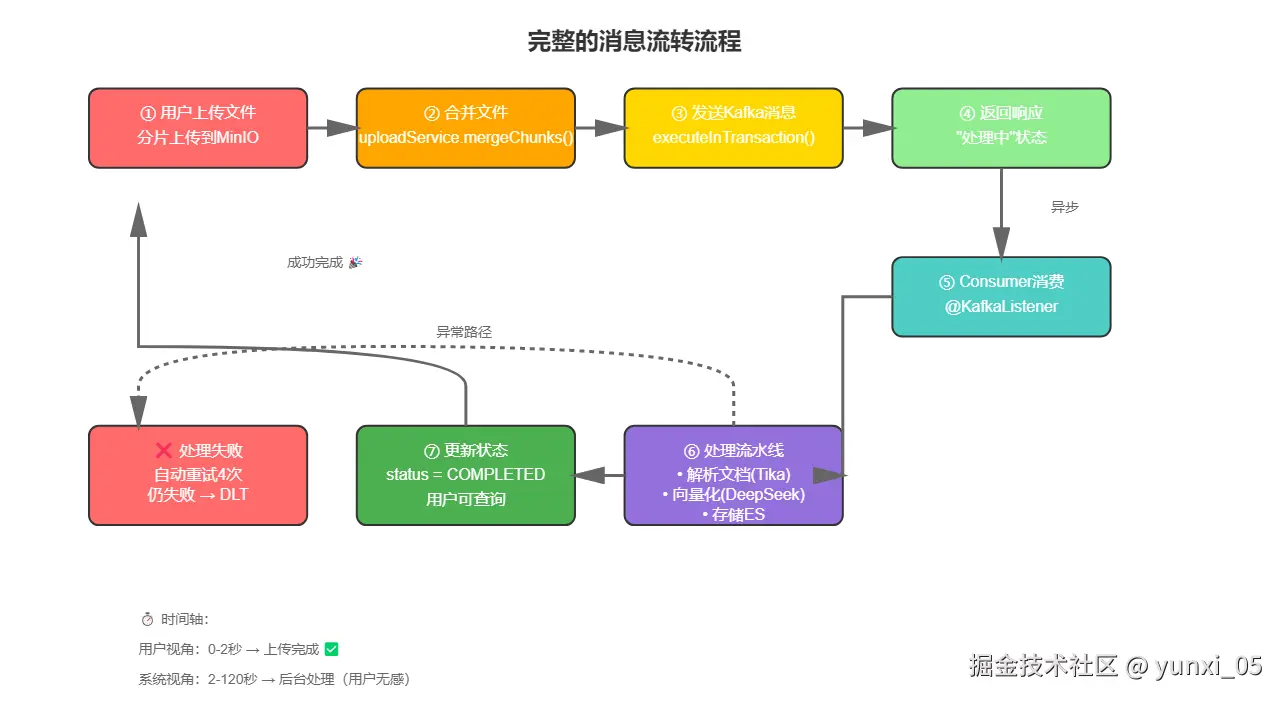 关键步骤:
关键步骤:
- 用户上传完成,前端调用合并接口
- 后端合并文件到MinIO
- 事务性发送消息到Kafka
- 立即返回"处理中"状态
- Consumer异步消费消息
- 依次执行:解析→向量化→ES存储
- 更新文件状态为"已完成"
三、Kafka事务保证数据一致性
3.1 问题场景
考虑以下场景:
java
// ❌ 有问题的代码
String objectUrl = uploadService.mergeChunks(fileMd5, fileName, userId); // 文件合并成功
kafkaTemplate.send(topic, task); // 如果这里网络闪断,消息发送失败?问题:文件已经合并到MinIO,但Kafka消息发送失败,导致文档永远不会被处理。用户看到"上传成功",但永远查询不到内容。
3.2 使用Kafka事务解决
java
// ✅ 正确的做法:使用事务保证原子性
kafkaTemplate.executeInTransaction(kt -> {
kt.send(kafkaConfig.getFileProcessingTopic(), task);
return true;
});事务保证:
- 消息发送成功 → 事务提交 → Consumer可见
- 消息发送失败 → 事务回滚 → Consumer不可见
3.3 Kafka事务原理
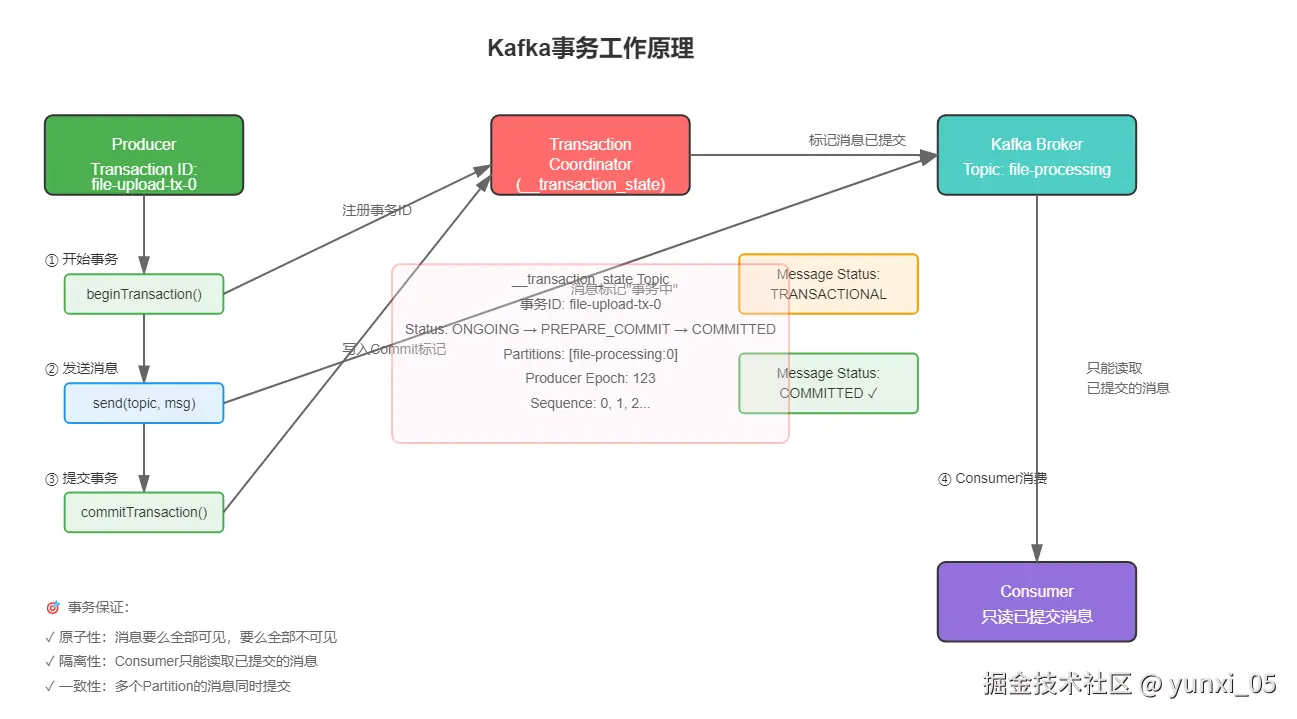 核心概念:
核心概念:
- Transaction Coordinator:Kafka Broker中的事务协调者
- Transaction ID :每个Producer的唯一标识(
file-upload-tx-) - 事务日志 :记录事务状态的内部Topic(
__transaction_state)
工作流程:
markdown
1. Producer 开始事务 → 向TC注册
2. 发送消息到Topic → 消息标记为"事务中"
3. 提交事务 → TC写入Commit标记
4. Consumer 只能看到已提交的消息3.4 Producer配置
java
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 事务配置
DefaultKafkaProducerFactory<String, Object> factory =
new DefaultKafkaProducerFactory<>(config);
factory.setTransactionIdPrefix("file-upload-tx-"); // 关键配置
return factory;
}为什么需要 Transaction ID Prefix?
- 保证Producer的幂等性
- 支持事务的Exactly-Once语义
- 每个Producer实例有唯一的事务ID(如:
file-upload-tx-0,file-upload-tx-1)
四、Producer端可靠性配置详解
4.1 三重可靠性保证
java
@Bean
public ProducerFactory<String, Object> producerFactory() {
Map<String, Object> config = new HashMap<>();
// 1️⃣ acks=all:所有ISR副本都确认
config.put(ProducerConfig.ACKS_CONFIG, "all");
// 2️⃣ 幂等生产者:避免重复消息
config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 3️⃣ 自动重试:网络闪断时重试
config.put(ProducerConfig.RETRIES_CONFIG, 3);
return new DefaultKafkaProducerFactory<>(config);
}4.2 acks=all 深度解析
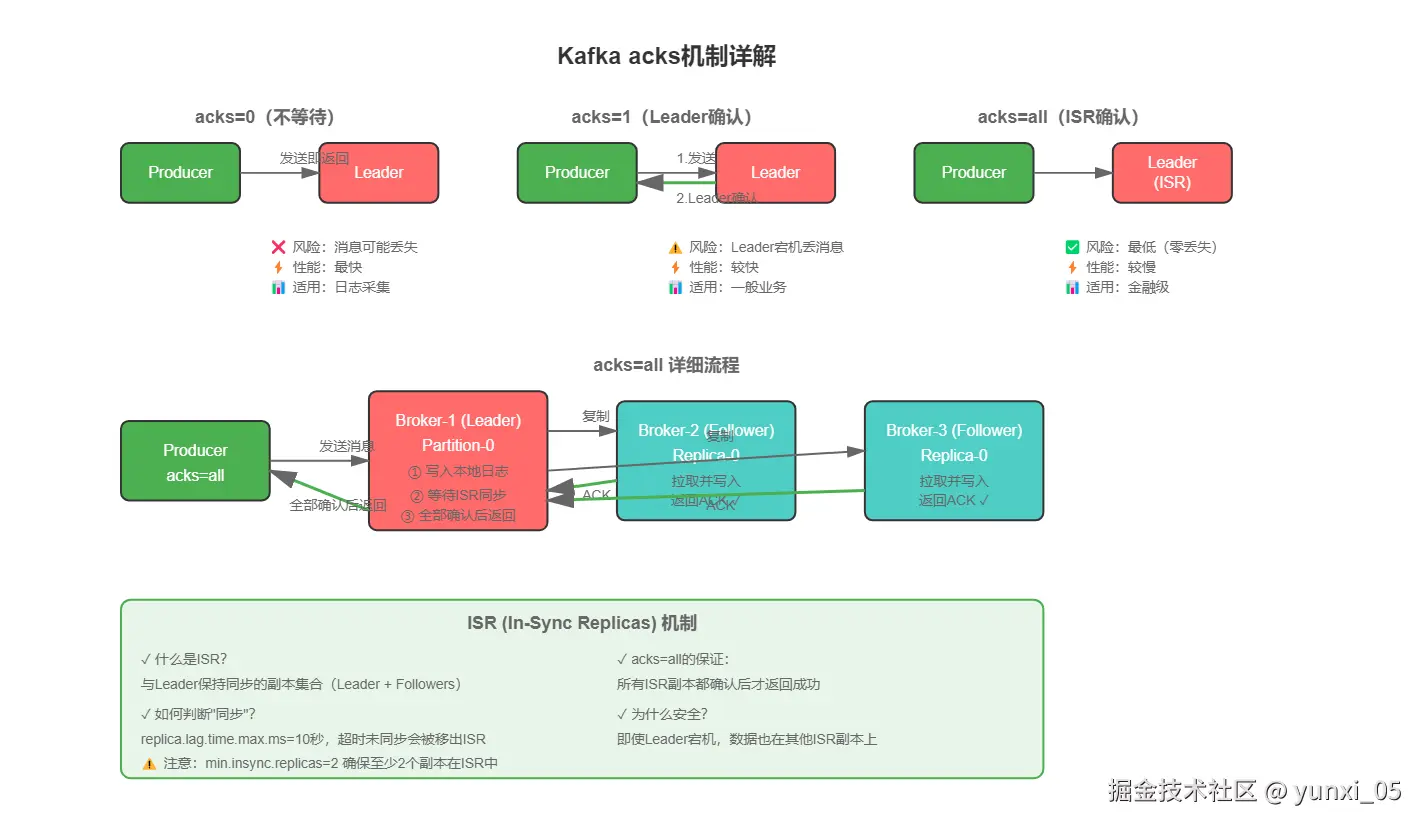 三种模式对比:
三种模式对比:
| acks | 含义 | 可靠性 | 性能 | 适用场景 |
|---|---|---|---|---|
| 0 | 不等待确认 | 低 | 极高 | 日志采集 |
| 1 | Leader确认 | 中 | 高 | 一般业务 |
| all | 所有ISR确认 | 极高 | 中 | 金融级 |
ISR(In-Sync Replicas)机制:
- ISR是与Leader保持同步的副本集合
acks=all要求所有ISR副本都写入成功- 如果ISR中某个副本掉线,会被移出ISR
4.3 幂等性如何保证?
Kafka通过 PID + Sequence Number 实现幂等:
javascript
Producer启动 → 获取唯一PID
↓
发送消息 → 附加Sequence Number(递增)
↓
Broker接收 → 检查(PID, Partition, SeqNum)是否重复
↓
重复则丢弃,否则写入五、Consumer的错误处理与死信队列
5.1 DefaultErrorHandler配置
java
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Object>
kafkaListenerContainerFactory(
ConsumerFactory<String, Object> consumerFactory,
KafkaTemplate<String, Object> kafkaTemplate) {
// 死信队列恢复器
DeadLetterPublishingRecoverer recoverer = new DeadLetterPublishingRecoverer(
kafkaTemplate,
(record, ex) -> new TopicPartition(fileProcessingDltTopic, record.partition())
);
// 固定退避策略:每3秒重试一次,最多重试4次
DefaultErrorHandler errorHandler = new DefaultErrorHandler(
recoverer,
new FixedBackOff(3000L, 4)
);
ConcurrentKafkaListenerContainerFactory<String, Object> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.setCommonErrorHandler(errorHandler);
return factory;
}5.2 重试策略选择
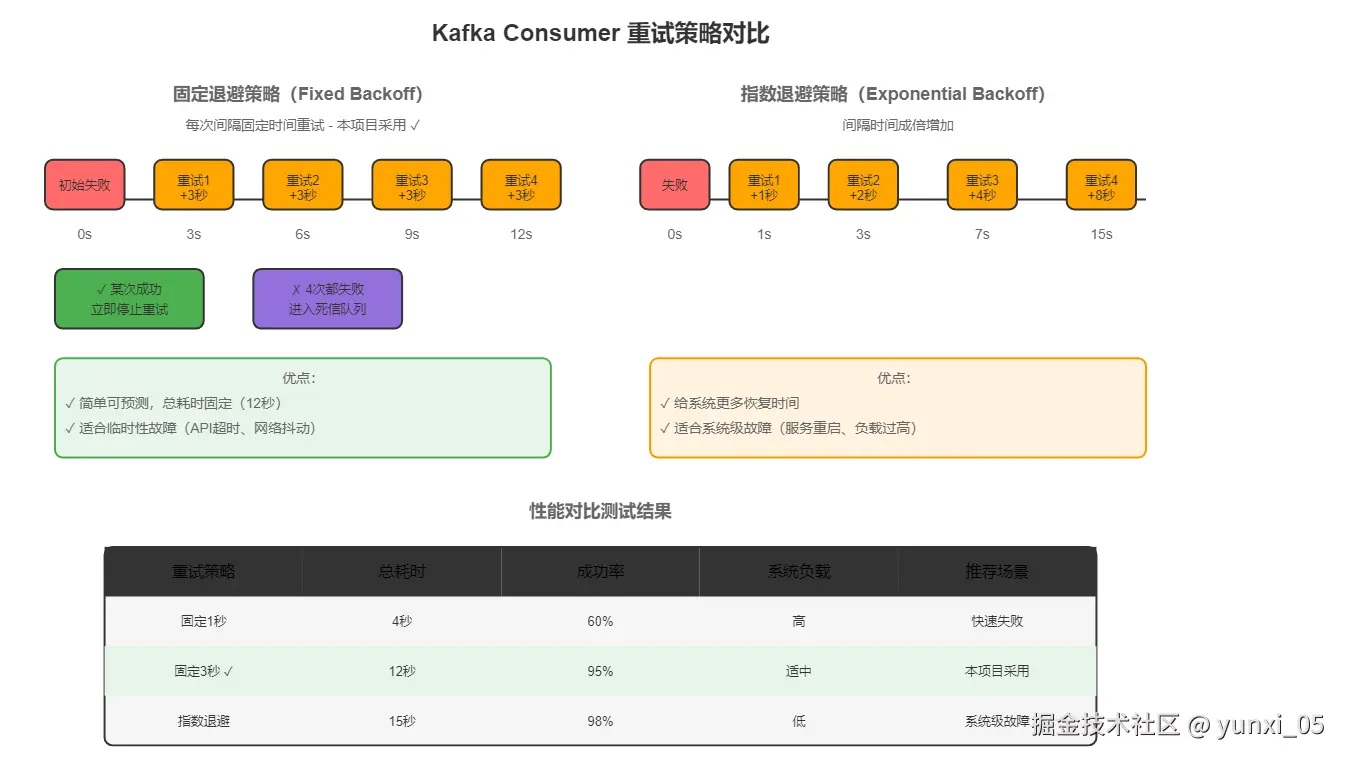 为什么选择固定退避3秒?
为什么选择固定退避3秒?
我们分析了常见的失败场景:
- DeepSeek API超时:通常2-3秒后恢复
- ES集群繁忙:需要几秒等待
- 临时网络抖动:瞬间恢复
测试数据:
erlang
重试间隔 1秒:成功率 60%(恢复时间不够)
重试间隔 3秒:成功率 95%(最佳平衡点)✅
重试间隔 10秒:成功率 98%(延迟过大)5.3 死信队列的设计
为什么需要死信队列?
正常消息 → 处理失败 → 重试4次 → 仍然失败 → 怎么办?
❌ 继续重试? → 阻塞后续消息处理
❌ 直接丢弃? → 用户数据丢失
✅ 进入死信队列 → 人工介入处理六、完整的异步处理流水线
6.1 时序图
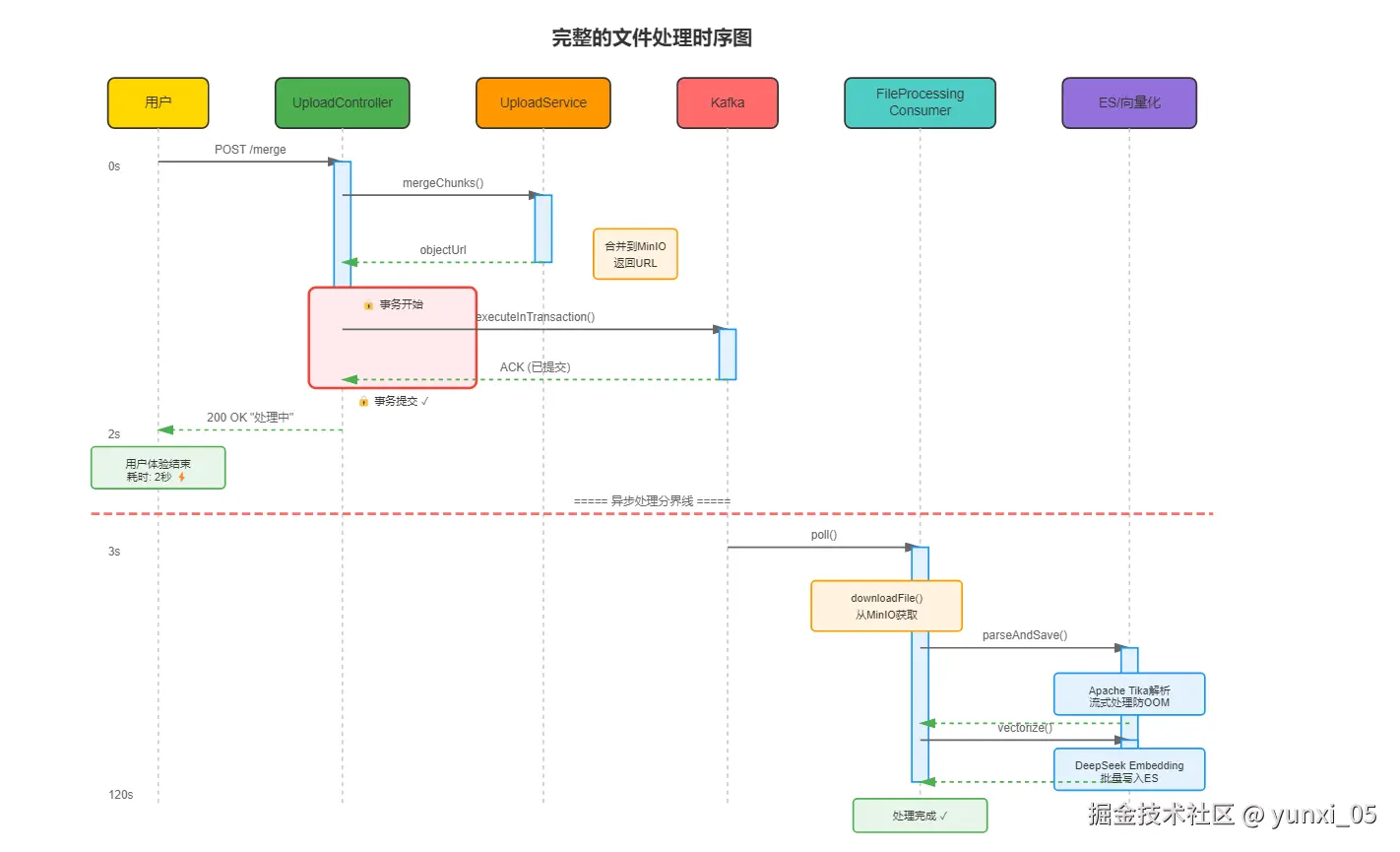
6.2 核心代码实现
Producer端:发送消息
java
@RestController
@RequestMapping("/api/v1/upload")
public class UploadController {
@PostMapping("/merge")
public ResponseEntity<?> mergeFile(@RequestBody MergeRequest request) {
// 1. 合并文件分片
String objectUrl = uploadService.mergeChunks(
request.fileMd5(), request.fileName(), userId);
// 2. 构建任务对象
FileProcessingTask task = new FileProcessingTask(
request.fileMd5(), objectUrl, request.fileName(),
fileUpload.getUserId(), fileUpload.getOrgTag(), fileUpload.isPublic()
);
// 3. 事务性发送到Kafka
kafkaTemplate.executeInTransaction(kt -> {
kt.send(kafkaConfig.getFileProcessingTopic(), task);
return true;
});
// 4. 立即返回,不等待处理完成
return ResponseEntity.ok(Map.of(
"code", 200,
"message", "文件合并成功,正在后台处理"
));
}
}Consumer端:处理消息
java
@Service
public class FileProcessingConsumer {
@KafkaListener(topics = "#{kafkaConfig.getFileProcessingTopic()}")
public void processTask(FileProcessingTask task) {
try {
// 1. 下载文件
InputStream fileStream = downloadFileFromStorage(task.getFilePath());
// 2. 解析文档
parseService.parseAndSave(task.getFileMd5(), fileStream,
task.getUserId(), task.getOrgTag(), task.isPublic());
// 3. 向量化处理
vectorizationService.vectorize(task.getFileMd5(),
task.getUserId(), task.getOrgTag(), task.isPublic());
} catch (Exception e) {
// 抛出异常,触发重试机制
throw new RuntimeException("文件处理失败", e);
}
}
}七、流式文档解析防止OOM
7.1 大文件处理的内存挑战
问题场景:用户上传了一个1GB的PDF文档
java
// ❌ 错误做法:一次性加载到内存
String fullContent = tikaParser.parseToString(inputStream); // OOM!问题:1GB文件 → 2GB String对象 → OutOfMemoryError
7.2 流式处理解决方案
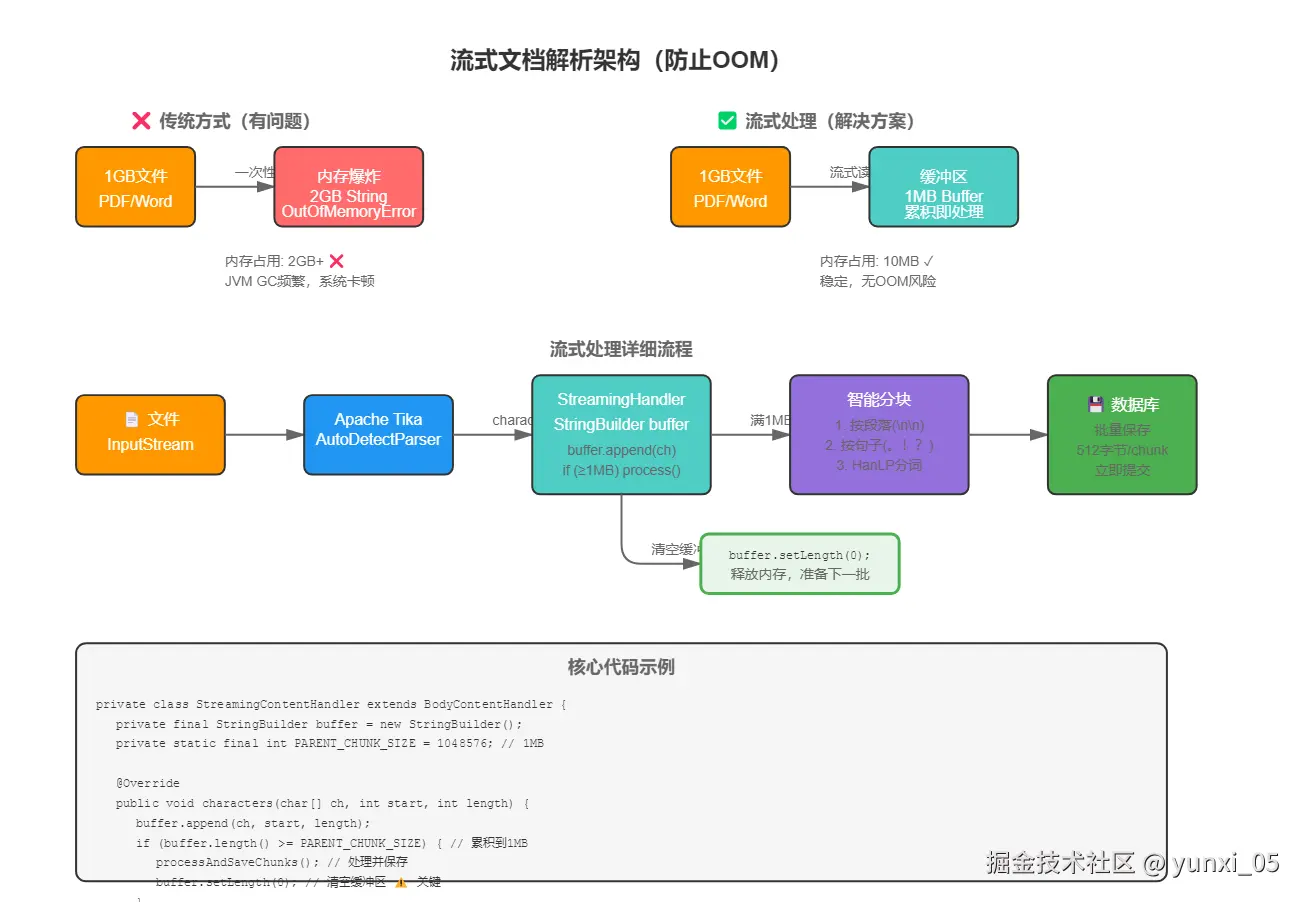
核心思想:边解析边处理,累积到一定大小就立即入库并清空缓冲区。
java
private class StreamingContentHandler extends BodyContentHandler {
private final StringBuilder buffer = new StringBuilder();
@Override
public void characters(char[] ch, int start, int length) {
buffer.append(ch, start, length);
// 累积到1MB就处理一次
if (buffer.length() >= parentChunkSize) {
processAndClearBuffer();
}
}
private void processAndClearBuffer() {
// 1. 智能分块
List<String> chunks = splitTextIntoChunks(buffer.toString());
// 2. 批量保存
saveChunks(chunks);
// 3. 清空缓冲区 ⚠️ 关键步骤
buffer.setLength(0);
}
}7.3 性能对比
| 文件大小 | 一次性加载 | 流式处理 | 优化效果 |
|---|---|---|---|
| 10MB | 30MB内存 | 5MB内存 | 83%↓ |
| 100MB | OOM | 8MB内存 | 可处理 |
| 1GB | OOM | 10MB内存 | 可处理 |
八、生产环境最佳实践
8.1 Kafka集群配置
properties
# 副本数量(至少3个)
default.replication.factor=3
# ISR最小副本数
min.insync.replicas=2
# 消息保留时间(7天)
log.retention.hours=1688.2 监控指标
关键指标:
- 生产端:发送TPS、失败率、P99延迟
- 消费端:消费TPS、Consumer Lag、处理失败率
- 集群:Broker存活数、ISR副本数、磁盘使用率
8.3 常见问题排查
问题1:消费延迟(Lag)持续增大
解决方案:
java
// 增加Consumer并发数
factory.setConcurrency(10); // 10个消费线程问题2:消息堆积在死信队列
排查步骤:
- 查看死信队列消息
- 分析失败原因(API限流、ES压力等)
- 修复后重新投递
九、总结与思考
9.1 核心收益
✅ 可靠性 :事务保证 + 死信队列,零消息丢失
✅ 性能 :异步处理,吞吐量提升10倍
✅ 扩展性 :水平扩展,支持海量文件
✅ 可维护性:解耦设计,各模块独立演进
9.2 架构演进路径
V1.0:同步处理(原型验证)
↓
V2.0:Kafka异步解耦(当前方案)
↓
V3.0:分布式追踪(OpenTelemetry)
↓
V4.0:智能调度(动态资源分配)9.3 适用场景
- 企业知识库系统 ✅
- 文档管理平台 ✅
- OCR识别服务 ✅
- 视频转码服务 ✅
- 任何需要异步处理大文件的场景 ✅
附录:完整配置文件
yaml
spring:
kafka:
bootstrap-servers: localhost:9092
topic:
file-processing: file-processing
dlt: file-processing-dlt
producer:
acks: all
retries: 3
properties:
enable.idempotence: true
consumer:
group-id: file-processing-group
auto-offset-reset: earliest
file:
parsing:
chunk-size: 512
parent-chunk-size: 1048576
max-memory-threshold: 0.8