一、引言:语音技术的新时代
随着人工智能的快速发展,语音识别
(ASR)和语音合成
(TTS)技术在多个领域得到了广泛应用。从智能助手到自动字幕生成,从有声读物到虚拟主播,语音技术正逐步改变人机交互的方式。
2025年,语音技术迎来了新的突破,特别是在大模型
(LLM)和扩散模型
的推动下,ASR和TTS的性能和应用场景得到了极大的扩展。
二、语音识别(ASR):从准确率到多样性
2.1 什么是ASR?
自动语音识别(ASR)是将语音信号转换为文本的技术,广泛应用于语音助手、会议记录、字幕生成等场景。
2.2 最新进展
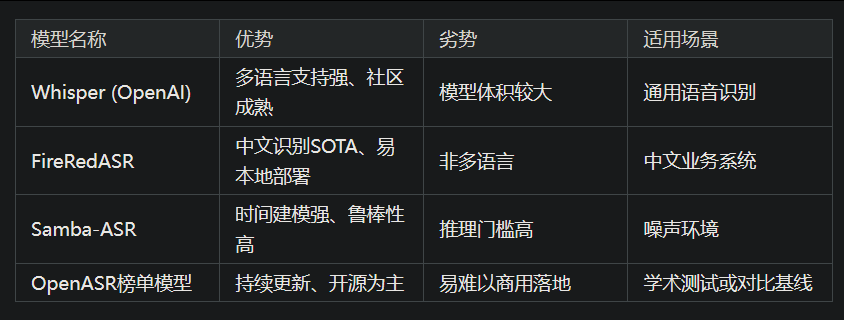
FireRedASR:小红书团队发布的开源ASR模型,在中文普通话测试集上取得了新的SOTA成绩,字错误率(CER)相对降低了8.4%。该模型包括FireRedASR-LLM和FireRedASR-AED两种结构,分别针对高精度和高效推理需求。
Samba-ASR
:基于Mamba架构的ASR模型,利用结构化状态空间模型(SSM)有效建模时间依赖关系,实现了在多个标准数据集上的SOTA性能。
Whisper
:OpenAI发布的多语言ASR模型,使用68万小时的多语言数据进行训练,支持多任务和多语言的语音识别。
三、语音合成(TTS):从文本到自然语音
3.1 什么是TTS?
文本转语音(TTS)技术将书面文本转换为自然流畅的语音,广泛应用于有声读物、语音助手、播客制作等领域。
3.2 最新进展
Kokoro TTS:基于StyleTTS
的开源模型,提供多种语音包和多语言支持,采用Apache 2.0许可证,适合商用部署。
NaturalSpeech 3:微软推出的TTS系统,采用因子化扩散模型,实现了零样本语音合成,语音质量接近人类水平。
T5-TTS
:NVIDIA发布的基于大型语言模型的TTS模型,解决了语音合成中的幻觉问题,提高了语音的准确性和自然度。四、语音识别(ASR)应用实践与模型选择建议
4.1 应用场景拆解
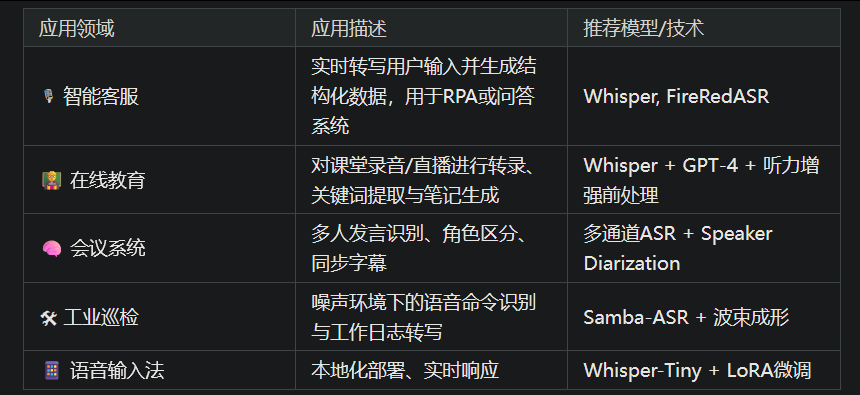
4.2 模型选择建议(表格对比)
五、语音合成(TTS)典型实践与产品化建议
5.1 应用场景与集成方式
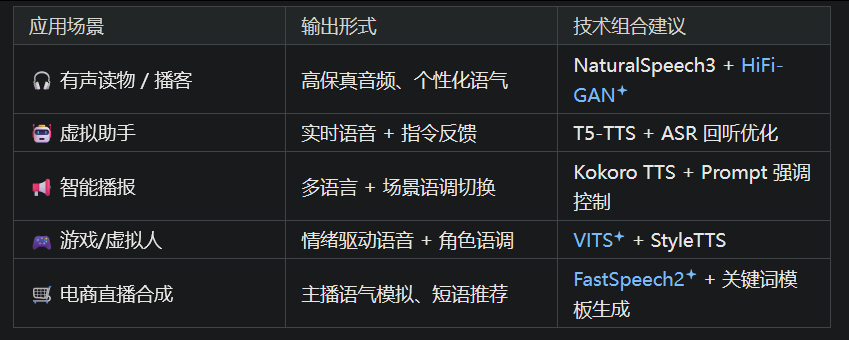
5.2 开发建议(从"可听"走向"可用")
强调 Prompt 可控性:使用 LLM 来生成带情绪描述的 Prompt,让合成更拟人。
后处理增强:应用 HiFi-GAN、MB-MelGAN 等声码器提升合成音质。
支持多说话人和多语言:尤其适用于虚拟数字人系统,支持"代码切换"(Code Switching)尤为关键。
边缘部署技巧:
可使用 ONNX 导出 TTS 模型
采用 VITS/Glow-TTS Tiny 模型在嵌入式设备中运行(如树莓派)文本预处理建议:
对数字、缩写、外语等内容提前规范化
特别注意对"段落停顿、标点语调"的映射策略六、TTS 和 ASR 的协同创新实践(Closed-Loop)
一个完整的语音系统往往既需要听得懂(ASR),也需要说得像人(TTS)。越来越多的系统正在构建如下闭环:

这样的闭环被广泛用于:
AI客服 / Copilot
智能车载语音系统
无障碍读屏设备
智能会议纪要系统七、语音系统的部署策略分析
开发者在设计语音应用系统时,不仅要关注模型的准确率和速度,还必须考虑"部署环境"的限制与优势。以下是三种典型部署架构:
7.1 云端部署:高性能、资源灵活
适用场景:
海量请求接入(如AI客服中心)
多语言识别与高并发TTS生成
快速迭代(模型频繁更新)优势:
可部署大模型(Whisper large、NaturalSpeech3)
动态扩容(如使用 Hugging Face Spaces / AWS Lambda + GPU 实例)
易于做模型 A/B 测试挑战:
网络延迟(影响实时体验)
隐私合规风险(语音上传云端)
高频调用成本高(按 Token 或秒计费)推荐实践:
TTS 采用离线合成 + CDN 缓存
ASR 结合 WebSocket 实现流式推理
用 NVIDIA NeMo 或 OpenVINO 进行多模型并发部署7.2 边缘端部署:实时性好,成本受控
适用场景:
车载语音、语音家居、手持设备(POS机等)
对网络要求敏感(无法依赖云)优势:
响应时间快(本地执行,不依赖网络)
隐私保护强(本地数据不上传)
可搭配 GPU/TPU 加速(Jetson、NPU)挑战:
模型压缩复杂(需剪枝、量化)
功耗与存储受限(部署模型需 <300MB)
一般不支持复杂多语种模型推荐工具链:
使用 ONNX Runtime
边缘模型选择 Whisper-Tiny, VITS-Tiny, DeepSpeech-lite
推理加速用 TensorRT + INT8/FP16 编译7.3 超轻量嵌入式部署:能识别能说话的小设备
适用场景:
智能门铃、玩具语音模块、麦克风芯片模组
单芯片语音交互设备(ESP32、AP6256)优势:
超低功耗运行
极小模型(<30MB)
本地语音识别+合成,一体化封装挑战:
只能识别命令词/短句,TTS效果有限
不支持流式对话或大语言模型推荐方案:
ASR:Picovoice Rhino、Google WakeWord Engine
TTS:EdgeImpulse + Coqui TTS 模型剪裁
结合 RTOS 或嵌入式 Linux 驱动声卡模块
八、总结:构建"听说自如"的智能语音系统
云端部署适合"大而强":追求高质量、可扩展与多语种处理
边缘部署偏向"实时可靠":适合响应敏感型场景与隐私敏感业务
嵌入式部署强调"极致压缩":适合体积小、硬件弱的轻设备语音交互
虚线表示部署选项可替换(即该节点可在云端、边缘或芯片中运行)。
所有路径都回归语音交互闭环(输入 → 识别 → 解析 → 合成 → 输出)。📌 推荐策略:
在复杂项目中,将 ASR 放在边缘,TTS 放在云端(生成后缓存播放),形成混合架构,效果最佳、体验最优。