当业界还在为自回归与扩散这两种主流技术路线孰优孰劣而激辩时,答案可能已经显现。
今天,北京智源人工智能研究院(BAAI)重磅发布了其多模态系列模型的最新力作 ------ 悟界・Emu3.5。
这不仅仅是一次常规的模型迭代,Emu3.5 被定义为一个 "多模态世界大模型"(Multimodal World Foudation Model)。
通过在超过 10 万亿的多模态 Token(主要源自互联网视频,总时长约 790 年)上进行端到端预训练,Emu3.5 得以学习并内化了现实物理世界的动态规律。
这种原生的世界建模能力,是 Emu3.5 与其他生成模型的根本区别,并自然地外化为一系列高级功能:不仅能生成图文并茂的故事,更展现出在长时程视觉指导、复杂图像编辑、世界探索和具身操作等任务上的强大潜力。
不仅如此,Emu3.5 首次揭示了 "多模态 Scaling 范式" 的存在,这是继语言预训练、推理和后训练之后,人工智能的第三条 Scaling 范式。也是团队将其称为 "世界大模型"(World Foundation Model)的原因。
智源在悟道 1.0 发布会上率先提出 "大模型" 一词,他们相信本次悟界・Emu3.5 的发布,"世界大模型"(World Foundation Model)将开启一个全新的探索方向。
为了破解自回归模型在图像生成上的速度瓶颈,团队还提出了离散扩散自适应(DiDA)技术,将每张图像的推理速度提升了近 20 倍,且几乎没有性能损失。这使得 Emu3.5 成为首个在推理速度和生成质量上,能与顶级闭源扩散模型相媲美的自回归模型。
在多个基准测试中,Emu3.5 在图像编辑任务上达到了与谷歌 Gemini-2.5-Flash-Image(Nano Banana)相当的性能,并在文本渲染和一系列交错内容生成任务上显著超越对手。
智源研究院宣布后续将开源 Emu3.5,以支持社区的进一步研究。
-
悟界・Emu3.5 项目主页:zh.emu.world
-
悟界・Emu3.5 技术报告:zh.emu.world/Emu35_tech_...
Emu3.5:不止于生成
更在于对世界动态的理解和预测
现有的多模态大模型大多遵循一种 "多模块" 模式:以一个强大的 LLM 作为基础,这样做固然以很好地利用已有的强大的 LLM,但这也意味着图像、视频、语音等其他模态需要先转换到文本模态,再进行处理。各个模态之间仍是被区分开的。
智源去年发布的悟界・Emu3 提出了 "原生多模态" 的理念,只基于下一个 token 预测,实现了文本、图像、视频三种模态数据的理解和生成大一统。
Emu3.5 继承了 Emu3 的极简架构,基于一个 34B 的稠密 Transformer 模型。它的创新之处在于其模型的目标统一为 "下一状态预测"(Next-State Prediciton)。
这种 "原生" 特性赋予了 Emu3.5 一种独特的能力:生成交错的视觉 - 语言输出。当用户给出一个指令,Emu3.5 的回答可以是一段文字,紧接着一幅图像,然后是另一段解释性的文字和下一幅图像。这种能力使其天然胜任两类极具挑战性的新任务:
- 视觉叙事(Visual Narrative):Emu3.5 能生成一系列图文并茂的卡片,起点处从牛顿与索尼克在森林相遇、提出一场关于速度与引力的挑战开始,到两个交流和思考,再到最后在月光下共同仰望星空,整个过程逻辑连贯,画面风格统一。

- 视觉指导(Visual Guidance):模型可以生成分步的、带有视觉示例的教程。例如,当被问及 "如何画图中的猫?",Emu3.5 会生成几个步骤,每个步骤都配有一张清晰的图片,直观地展示从轮廓到最终完成猫图片的全过程。
这种能力标志着多模态模型从 "看图说话" 或 "按需作画" 的单一任务执行者,向着能够进行连续、多步、跨模态创造的 "世界学习器" 迈出了关键一步。
十万亿多模态 Tokens 的世界基座模型训练
悟界・Emu3.5 之所以能具备如此强大的原生多模态能力,其背后是一套极其庞大且精密的训练流程。与以往模型主要依赖静态的 "图像 - 文本对" 不同,Emu3.5 的训练数据主体,是包含超过 10 万亿 Tokens 的视觉 - 语言交错数据,主要来源于互联网视频及其对应的语音转录文本,视频时长总计约 790 年。
为什么视频数据如此重要?因为静态图文对只能教会模型 "这是什么",而连续的视频帧和同步的解说,则能教会模型现实世界的物理动态、时空连续性和因果等规律。
整个流程分为四个核心阶段:
- 大规模预训练
这是奠定模型基础的阶段。Emu3.5 在超过 10 万亿 Tokens 的数据上,采用统一的 "下一状态预测"(Next-State Predicttion)目标进行端到端训练。这一阶段分为两步,第一步在 10 万亿 Tokens 上进行大规模基础学习,第二步则在 3 万亿更高质量、更高分辨率和更丰富标注的数据上进行能力增强。
值得注意的是,模型在训练过程中,验证集上多个分布外(Out-of-Distribution)任务的损失持续下降,这表明模型涌现出了强大的泛化能力,而不仅仅是记忆训练数据。
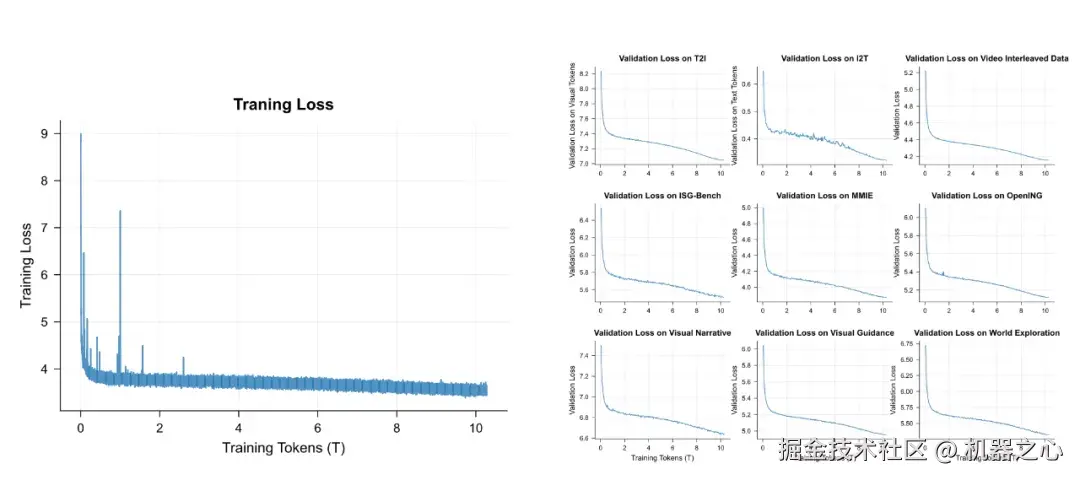
曲线表明 Emu3.5 实现了平滑且稳定的优化过程,并在多组验证集上保持了一致的泛化能力
- 监督微调
在预训练之后,模型在一个包含 1500 亿样本的高质量数据集上进行微调。这些数据覆盖了从通用图文生成、视觉问答,到前文提到的视觉叙事、视觉指导、世界探索和具身操作等多种复杂任务。SFT 阶段的目标是建立一个统一的多模态交互接口,让模型学会如何 "听懂" 并完成各种具体指令,并促进不同任务之间的知识迁移。
- 大规模多模态强化学习
为了进一步提升多模态推理和生成质量,Emu3.5 首次在多模态领域进行大规模强化学习。团队构建了一个复杂的多维度奖励系统,能够同时评估生成内容的美学质量、图文对齐度、叙事连贯性、文本渲染准确度等多个指标。
通过在统一的奖励空间中进行优化,模型学会在多个目标之间取得平衡,避免了 "奖励欺骗"(Reward Hacking)现象,实现了跨任务的持续改进。
- 高效自回归推理加速
为了解决自回归模型在生成速度方面的挑战,Emu3.5 团队提出了一种叫做 "离散扩散自适应"(Discrete Diffusion Adaptation,DiDA)的方法。在不牺牲生成质量的前提下,Emu3.5 的单图生成速度提升了约 20 倍。这意味着,Emu3.5 在保持自回归模型强大可控性的同时,获得了接近主流扩散模型的推理效率,成功弥合了两种技术路线之间的鸿沟。
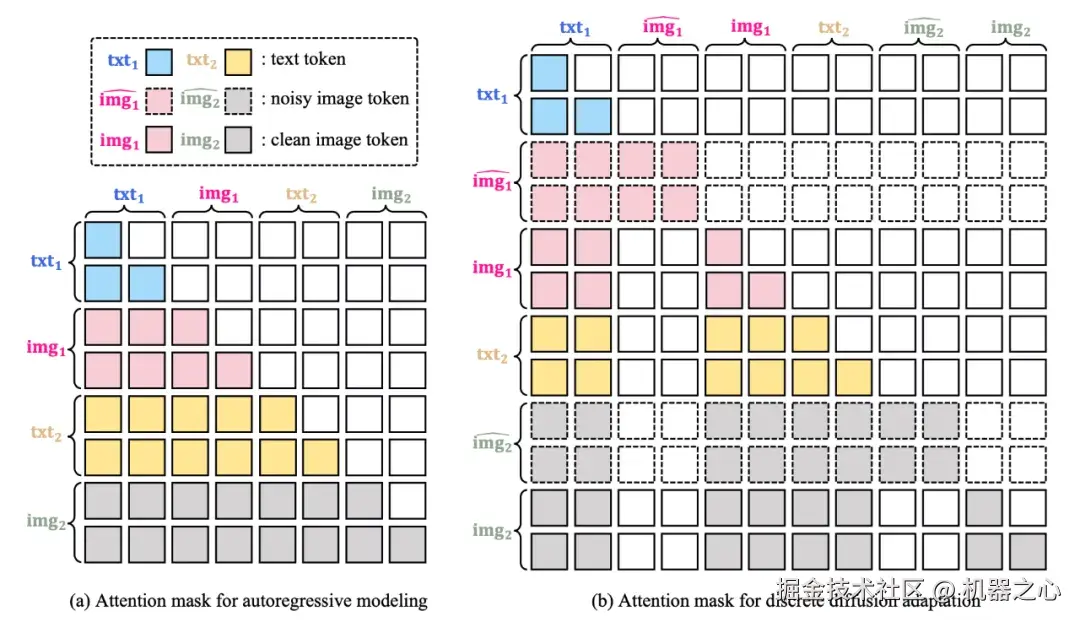
DiDA 的核心思想借鉴了扩散模型,但将其应用于离散的 Token 空间。它将自回归模型的单向、顺序预测,转化为一种并行的、双向的去噪过程。
从视觉叙事到世界探索:Emu3.5 的惊人能力
得益于其原生多模态架构、海量视频数据训练和 DiDA 加速,Emu3.5 在一系列任务中展现了 SOTA 或极具竞争力的表现。
通用图像编辑与生成:在需要精确控制和多模态指令遵循的图像编辑任务上,Emu3.5 表现出色,能够实现开放世界的编辑和时空操作。在文字渲染方面,其准确性和自然度超越了包括 Gemini-2.5-Flash-Image(Nano Banana)在内的领先模型。




世界建模与探索:项目主页中展示的 "世界探索" 和 "具身操作" 能力,使其与谷歌的 Genie 等前沿世界模型处于同一水平。Emu3.5 能够根据指令,生成在虚拟环境中连续移动的视觉序列,并保持场景的几何、语义和外观一致性。
具身操作任务:它能将一个复杂的、长期的机器人操作任务(如倒水、折叠衣物)分解为一系列带有语言指令和关键帧图像的子任务,为训练更通用的具身智能体提供了基础。
这些能力的涌现,验证了 Emu3.5 技术报告的核心观点:通过在海量视频数据上进行大规模训练,模型能够内化现实世界的运行规律,从而进行更深层次的模拟和推理。
无限生成,赋能具身智能的新引擎

Emu3.5 的突破,也为具身智能的发展补全了一块关键的拼图。
一直以来,具身智能领域都苦于缺乏高质量的数据,Emu3.5 可以作为一个无限数据生成器:它不仅能够生成丰富多样的虚拟环境和任务,大幅拓展 AI 学习和测试的空间,还能生成从高层目标到具体操作的分步规划数据,帮助具身智能系统理解和实践复杂任务的全过程。
智源研究院在很早就预判大模型正从数字世界加速迈入物理世界。"悟界" 系列模型,正是这一预判的集中体现。
Emu3.5 通过 "下一状态预测" 和原生多模态融合,自然涌现出对时空、物理规律、因果等世界动态的内在理解,这正是机器人进行自主导航、精细操作、复杂决策等任务的基础。
通往下一代多模态智能
智源悟界・Emu3.5 展示出了作为 "世界模型的基础模型" 的巨大潜力。
通过原生多模态架构、以视频为主的训练数据和创新的 DiDA 加速技术,也向我们展示了如何构建一个更强大、更高效、更接近人类自然学习方式的世界模型。
当然,Emu3.5 也存在局限。技术报告中表示,其视觉分词器(Tokenizer)的压缩率仍有提升空间,DiDA 的加速潜力也未完全挖掘。同时,对于视觉叙事、世界探索等新能力的评估,也需要建立更系统化的基准。
它的开源,无疑将为全球 AI 研究社区提供一个强大的新基座。感兴趣的读者可以填写报名表,申请获取 Emu3.5 的内测资格。