目录
[🎯 开篇:小猫的视觉世界](#🎯 开篇:小猫的视觉世界)
[📚 核心概念:让计算机看懂图像](#📚 核心概念:让计算机看懂图像)
[2.1 什么是卷积神经网络?](#2.1 什么是卷积神经网络?)
[2.2 为什么需要CNN?](#2.2 为什么需要CNN?)
[2.3 CNN的基本结构](#2.3 CNN的基本结构)
[🎪 案例:数字识别小侦探](#🎪 案例:数字识别小侦探)
[3.1 问题背景](#3.1 问题背景)
[3.2 CNN设计思路](#3.2 CNN设计思路)
[3.3 特征提取过程](#3.3 特征提取过程)
[🔍 算法原理:CNN的三大核心组件](#🔍 算法原理:CNN的三大核心组件)
[4.1 卷积层:图像的特征提取器](#4.1 卷积层:图像的特征提取器)
[4.2 池化层:降维和特征压缩](#4.2 池化层:降维和特征压缩)
[4.3 全连接层:最终的分类器](#4.3 全连接层:最终的分类器)
[🔍 几何解释:CNN如何看世界](#🔍 几何解释:CNN如何看世界)
[5.1 感受野的概念](#5.1 感受野的概念)
[5.2 特征层次结构](#5.2 特征层次结构)
[5.3 参数共享的优势](#5.3 参数共享的优势)
[🌟 经典CNN模型:从LeNet到ResNet](#🌟 经典CNN模型:从LeNet到ResNet)
[6.1 LeNet-5:CNN的开山之作](#6.1 LeNet-5:CNN的开山之作)
[6.2 AlexNet:深度学习的里程碑](#6.2 AlexNet:深度学习的里程碑)
[6.3 VGGNet:更深的网络结构](#6.3 VGGNet:更深的网络结构)
[6.4 ResNet:解决深层网络的梯度消失问题](#6.4 ResNet:解决深层网络的梯度消失问题)
[🚀 CNN的应用场景:从图像识别到自动驾驶](#🚀 CNN的应用场景:从图像识别到自动驾驶)
[7.1 图像分类](#7.1 图像分类)
[7.2 物体检测](#7.2 物体检测)
[7.3 图像分割](#7.3 图像分割)
[7.4 人脸识别](#7.4 人脸识别)
[7.5 自动驾驶](#7.5 自动驾驶)
[💻 实战:从零实现简单CNN](#💻 实战:从零实现简单CNN)
[8.1 导入必要的库](#8.1 导入必要的库)
[8.2 数据加载与预处理](#8.2 数据加载与预处理)
[8.3 定义CNN模型](#8.3 定义CNN模型)
[8.4 模型训练](#8.4 模型训练)
[8.5 可视化卷积核和特征图](#8.5 可视化卷积核和特征图)
[🎓 哲学思考:CNN给我们的启示](#🎓 哲学思考:CNN给我们的启示)
[9.1 层次化的思维方式](#9.1 层次化的思维方式)
[9.2 特征的重要性](#9.2 特征的重要性)
[9.3 结构决定功能](#9.3 结构决定功能)
[9.4 从经验中学习](#9.4 从经验中学习)
[🎯 总结与展望](#🎯 总结与展望)
[10.1 CNN的核心价值](#10.1 CNN的核心价值)
[10.2 CNN的发展趋势](#10.2 CNN的发展趋势)
[10.3 未来应用前景](#10.3 未来应用前景)
🎯 开篇:小猫的视觉世界
从前,有一只好奇的小猫,它总是盯着窗外的世界看。主人发现,无论窗外的景色如何变化,小猫都能快速识别出移动的物体------一只飞鸟、一辆汽车,甚至是一片飘落的树叶。
科学家们对猫的视觉系统进行了研究,发现猫的大脑中有专门的神经元,这些神经元只对特定的视觉特征敏感:有些只对边缘线反应,有些只对特定方向的线条反应,还有些只对明暗对比敏感。更神奇的是,这些神经元是分层工作的:第一层识别简单的线条和边缘,第二层将这些简单特征组合成更复杂的形状,第三层则进一步组合成完整的物体。
这个发现启发了计算机科学家,他们想:如果我们能模仿猫的视觉系统设计一种神经网络,是不是就能让计算机也能看懂图像了?于是,卷积神经网络(CNN)应运而生。
📚 核心概念:让计算机看懂图像
2.1 什么是卷积神经网络?
卷积神经网络(Convolutional Neural Network,简称CNN)是一种专门为处理图像和视频数据而设计的深度学习架构。与传统的全连接神经网络不同,CNN通过特殊的卷积操作,能够高效地提取图像中的局部特征,并自动学习这些特征之间的关系。
想象一下,如果你想让计算机识别一只猫,传统的全连接网络需要将整个图像的所有像素值作为输入,这会产生海量的参数。而CNN则聪明地采用了"局部感知"的策略------就像我们人类看东西时,先看到局部细节,再组合成整体。
2.2 为什么需要CNN?
在CNN出现之前,计算机处理图像面临着巨大挑战:
- 参数爆炸:一张512×512的彩色图像有超过78万个像素,如果直接连接到隐藏层,参数数量会极其庞大
- 特征工程复杂:需要人工设计特征提取器(如SIFT、HOG等)
- 位置不变性:传统方法难以处理同一物体在图像中不同位置的情况
CNN通过三个关键设计解决了这些问题:
- 局部连接:每个神经元只连接到输入的一小部分区域(感受野)
- 参数共享:同一卷积核在整个图像上共享权重
- 池化操作:降低特征图的维度,保持特征的同时减少计算量
2.3 CNN的基本结构
一个典型的CNN架构通常包含以下几种类型的层:
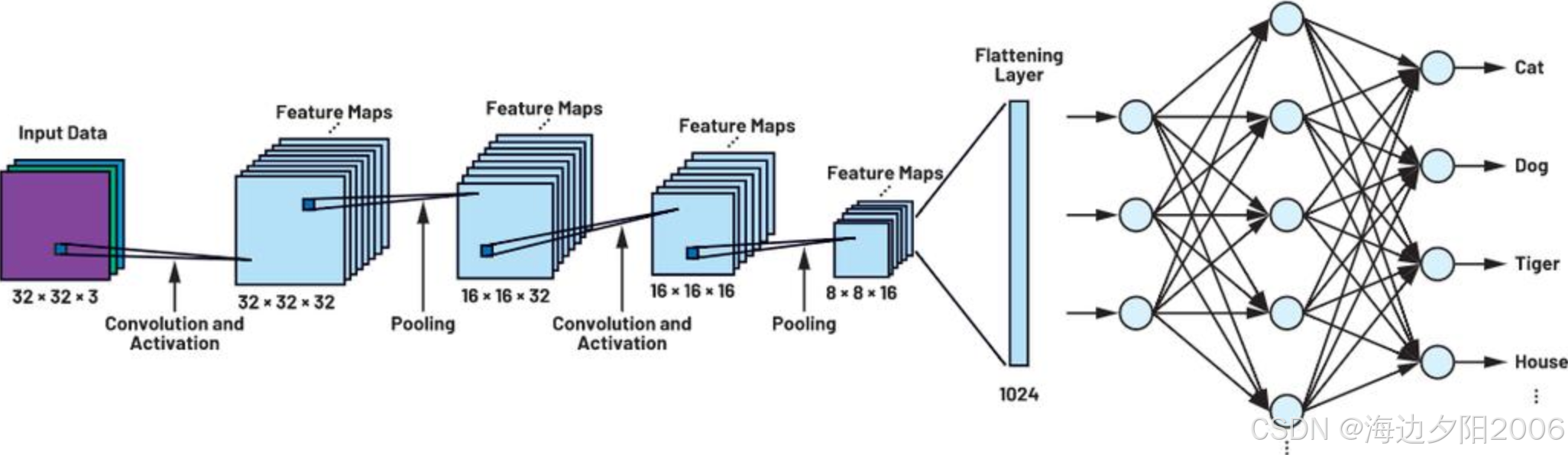
- 输入层:接收原始图像数据
- 卷积层:提取图像的局部特征
- 激活层:引入非线性变换
- 池化层:降低特征图维度,提高计算效率
- 全连接层:将提取的特征映射到最终输出
- 输出层:产生分类或回归结果
🎪 案例:数字识别小侦探
让我们通过一个简单的手写数字识别案例来理解CNN的工作原理:
3.1 问题背景
我们想要让计算机自动识别手写的数字(0-9)。这是一个经典的图像分类问题,输入是一张28×28的灰度图像,输出是0-9中的一个数字。
3.2 CNN设计思路
我们可以设计一个简单的CNN模型:
- 输入层:28×28×1的灰度图像
- 卷积层1:使用6个5×5的卷积核
- 池化层1:2×2最大池化
- 卷积层2:使用16个5×5的卷积核
- 池化层2:2×2最大池化
- 全连接层1:120个神经元
- 全连接层2:84个神经元
- 输出层:10个神经元(对应0-9)
3.3 特征提取过程
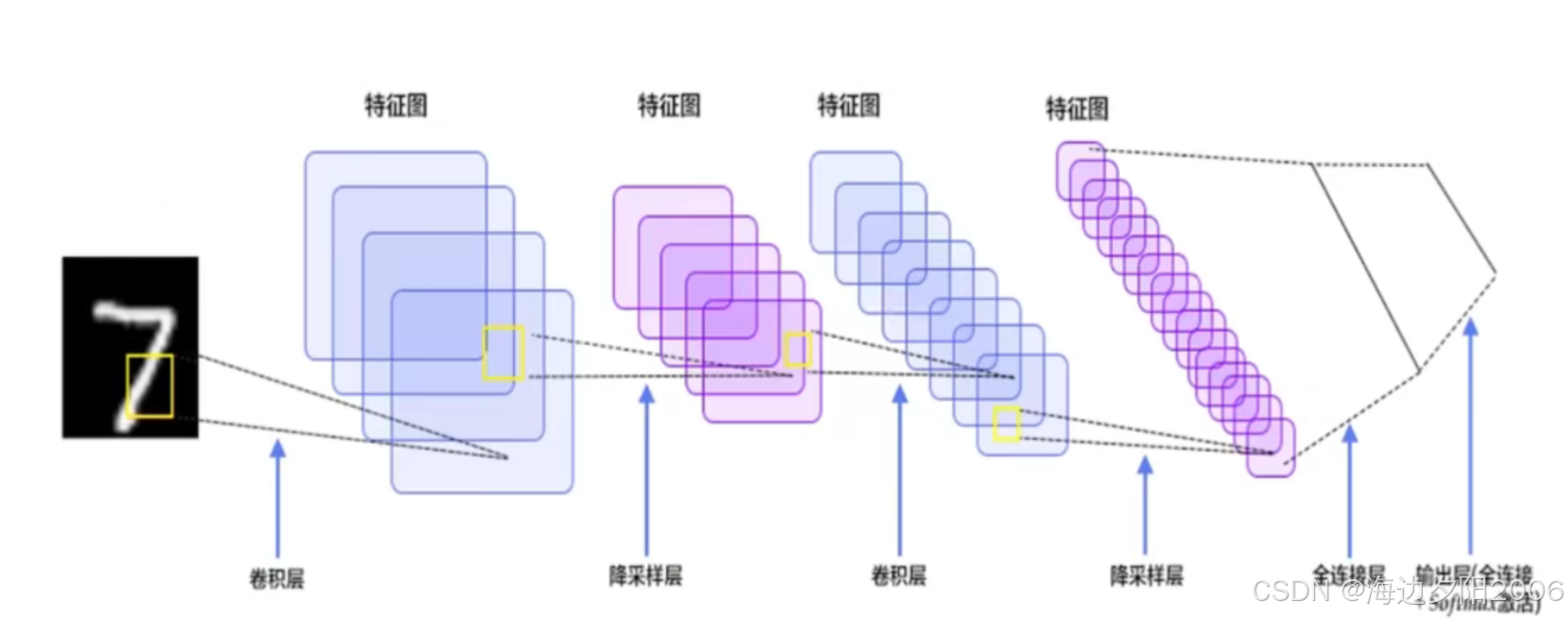
当输入一张手写数字"7"的图像时:
- 第一层卷积会检测出图像中的边缘和线条
- 池化层会保留重要特征并降低维度
- 第二层卷积会将这些边缘组合成更复杂的形状(如拐角、交叉点)
- 最后通过全连接层将提取的特征映射到最终的数字类别
🔍 算法原理:CNN的三大核心组件
4.1 卷积层:图像的特征提取器
卷积层是CNN的核心,它通过卷积操作提取图像中的局部特征。
🎯 什么是卷积操作?
想象一下,你有一个小放大镜(卷积核),它在图像上从左到右、从上到下滑动。在每个位置,放大镜会计算它所覆盖区域的加权和,这个过程就叫做卷积。
输入图像区域: 卷积核:
1 2 3 1 0
4 5 6 0 1
7 8 9
卷积计算: 1×1 + 2×0 + 4×0 + 5×1 = 1 + 5 = 61️⃣ 卷积的数学表达:
对于二维卷积,输出特征图上每个位置的值可以表示为:
其中:
- f(i,j)f(i,j) 是输出特征图在位置 (i,j)(i,j) 的值
- II 是输入图像
- KK 是卷积核(大小为 k×kk×k)
2️⃣ 多通道卷积:
对于彩色图像(RGB),输入有3个通道。卷积核也需要有3个通道,每个通道对应输入的一个通道。输出特征图是3个通道卷积结果的总和。
3️⃣ 卷积核的意义:
不同的卷积核可以提取不同的特征:
- 垂直边缘检测核:
[[1,0,-1],[1,0,-1],[1,0,-1]] - 水平边缘检测核:
[[1,1,1],[0,0,0],[-1,-1,-1]] - 模糊核:
[[1,1,1],[1,1,1],[1,1,1]]/9
4.2 池化层:降维和特征压缩
池化层(Pooling Layer)位于卷积层之后,主要有两个作用:
- 降低特征图的维度,减少计算量
- 提高模型的鲁棒性,使特征对位置变化不那么敏感
常见的池化操作:
-
最大池化(Max Pooling):取区域内的最大值
输入区域: 最大池化后: 1 2 3 4 6 8 5 6 7 8 3 5 2 3 4 5 -
平均池化(Average Pooling):取区域内的平均值
输入区域: 平均池化后: 1 2 3 4 3.5 6.5 5 6 7 8 2.5 4.5 2 3 4 5
池化层的超参数包括:
- 池化大小:通常为2×2或3×3
- 步长:池化窗口滑动的步长,通常与池化大小相同
4.3 全连接层:最终的分类器
在CNN的最后部分,通常会有一到两个全连接层,它们将前面卷积和池化层提取的特征映射到最终的输出类别。
全连接层的工作原理是将特征图展平成一维向量,然后通过权重矩阵连接到输出层。对于分类任务,输出层通常使用softmax激活函数,将输出转换为概率分布。
🔍 几何解释:CNN如何看世界
5.1 感受野的概念
在CNN中,每个神经元只对输入图像的一小部分区域敏感,这个区域称为感受野(Receptive Field)。随着网络深度的增加,感受野会逐渐扩大,高层神经元的感受野可以覆盖整个输入图像。
这就像人类视觉系统一样:视网膜上的每个感光细胞只对很小的视野区域敏感,但当信号传递到大脑视觉皮层时,神经元可以感知更大的区域。
5.2 特征层次结构
CNN中的特征提取是分层进行的,形成了一个层次结构:
- 浅层特征:边缘、线条、纹理等简单特征
- 中层特征:形状、部件等复杂特征
- 高层特征:完整的物体、场景等抽象特征
这种层次结构使得CNN能够从原始像素逐步构建出越来越抽象的语义表示。
5.3 参数共享的优势
参数共享是CNN的一个重要特性,它意味着同一个卷积核在整个图像上使用相同的权重。这带来了几个关键优势:
- 参数数量大幅减少:不再需要为每个像素位置学习不同的权重
- 平移不变性:无论物体在图像的哪个位置,都能被同样的特征检测器识别
- 提高泛化能力:减少了过拟合的风险
🌟 经典CNN模型:从LeNet到ResNet
6.1 LeNet-5:CNN的开山之作
LeNet-5是由Yann LeCun于1998年提出的第一个成功的卷积神经网络模型,用于手写数字识别。
1️⃣ 结构特点:
- 5层结构(不包括输入层)
- 2个卷积层 + 2个池化层 + 1个全连接层
- 使用Sigmoid或Tanh作为激活函数
- 使用softmax作为输出层激活函数
2️⃣ 历史意义:
LeNet-5成功应用于银行支票的手写数字识别,证明了CNN在实际应用中的有效性,为后续的CNN发展奠定了基础。
6.2 AlexNet:深度学习的里程碑
AlexNet由Alex Krizhevsky等人于2012年提出,在ImageNet竞赛中取得了突破性的成绩,错误率比第二名低了10个百分点以上。
1️⃣ 结构特点:
- 8层结构(5个卷积层 + 3个全连接层)
- 使用ReLU激活函数,解决了梯度消失问题
- 首次使用Dropout技术减少过拟合
- 使用数据增强技术提高泛化能力
- 首次使用GPU加速训练
2️⃣ 历史意义:
AlexNet的成功标志着深度学习时代的正式开始,引发了计算机视觉领域的革命。
6.3 VGGNet:更深的网络结构
VGGNet由牛津大学的Visual Geometry Group于2014年提出,以其简洁统一的结构而闻名。
1️⃣ 结构特点:
- 16或19层结构
- 只使用3×3的小卷积核
- 使用2×2的最大池化
- 卷积层通道数从64开始,每次池化后翻倍
2️⃣ 设计理念:
VGGNet证明了网络深度对性能的重要性,多个小卷积核的堆叠比单个大卷积核效果更好。
6.4 ResNet:解决深层网络的梯度消失问题
ResNet(Residual Network)由何凯明等人于2015年提出,通过引入残差连接解决了深层网络训练困难的问题。
1️⃣ 核心创新:
残差块(Residual Block)使用了快捷连接(Shortcut Connection),允许梯度直接从后层流向浅层:
其中,F(x, {Wi})是残差映射,x是输入,y是输出。
2️⃣ 历史意义:
ResNet使训练超过100层的网络成为可能,在ImageNet竞赛中取得了当时最好的成绩,并启发了后续一系列网络的设计。
🚀 CNN的应用场景:从图像识别到自动驾驶
7.1 图像分类
图像分类是CNN最基本的应用,它的任务是将输入图像分配到预定义的类别中。
应用案例:
- ImageNet大规模图像分类
- 物体识别(猫狗分类、人脸识别等)
- 医疗图像分类(癌症检测、疾病诊断)
技术要点:
- 通常使用预训练模型作为特征提取器
- 对于小数据集,可以采用迁移学习的方法
- 常用评估指标:准确率、精确率、召回率、F1分数
7.2 物体检测
物体检测不仅要识别图像中的物体类别,还要确定它们在图像中的位置。
主流方法:
- 两阶段检测器:Faster R-CNN(先生成候选区域,再进行分类和定位)
- 单阶段检测器:YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)
应用案例:
- 安防监控中的行人检测
- 自动驾驶中的车辆和行人检测
- 零售场景中的商品识别
7.3 图像分割
图像分割将图像像素级地分类,生成像素级的标注。
类型:
- 语义分割:将像素分为不同的语义类别
- 实例分割:区分同一类别的不同实例
应用案例:
- 医学图像分割(器官分割、肿瘤分割)
- 自动驾驶中的场景理解
- 卫星图像分析
7.4 人脸识别
人脸识别是一种特殊的图像识别任务,专注于识别人脸。
关键技术:
- 人脸检测:定位图像中的人脸
- 特征提取:提取人脸的关键特征
- 特征比对:与数据库中的人脸进行比对
应用案例:
- 手机解锁和支付验证
- 安防监控和罪犯追踪
- 考勤系统和身份认证
7.5 自动驾驶
CNN在自动驾驶中发挥着至关重要的作用,负责感知和理解周围环境。
核心任务:
- 车道线检测
- 交通标志识别
- 车辆和行人检测
- 场景理解和路径规划
挑战与突破:
- 实时性能要求高,需要优化推理速度
- 需要处理各种天气和光照条件
- 安全性要求极高,模型必须具有高可靠性
💻 实战:从零实现简单CNN
让我们使用PyTorch实现一个简单的CNN来识别MNIST手写数字:
8.1 导入必要的库
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt8.2 数据加载与预处理
python
# 定义数据变换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)8.3 定义CNN模型
python
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一个卷积层:输入1通道,输出10通道,卷积核5x5
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
# 第二个卷积层:输入10通道,输出20通道,卷积核5x5
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
# 卷积层后接一个Dropout层
self.conv2_drop = nn.Dropout2d()
# 全连接层1:输入是20*4*4=320,输出50
self.fc1 = nn.Linear(320, 50)
# 全连接层2:输入50,输出10(对应0-9)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
# 第一层卷积+池化:ReLU激活+2x2最大池化
x = F.relu(F.max_pool2d(self.conv1(x), 2))
# 第二层卷积+池化:ReLU激活+2x2最大池化+Dropout
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# 展平特征图
x = x.view(-1, 320)
# 第一个全连接层+ReLU
x = F.relu(self.fc1(x))
# Dropout
x = F.dropout(x, training=self.training)
# 第二个全连接层
x = self.fc2(x)
# 输出层使用log_softmax
return F.log_softmax(x, dim=1)8.4 模型训练
python
# 初始化模型、优化器和损失函数
model = SimpleCNN()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.1f}%)\n')
return accuracy
# 训练模型
accuracies = []
for epoch in range(1, 11):
train(epoch)
acc = test()
accuracies.append(acc)
# 绘制准确率变化曲线
plt.plot(range(1, 11), accuracies)
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('MNIST Classification Accuracy')
plt.grid(True)
plt.show()8.5 可视化卷积核和特征图
python
# 可视化第一个卷积层的卷积核
def visualize_kernels():
kernels = model.conv1.weight.detach().cpu().numpy()
fig, axes = plt.subplots(2, 5, figsize=(12, 6))
for i, ax in enumerate(axes.flatten()):
ax.imshow(kernels[i, 0], cmap='gray')
ax.set_title(f'Kernel {i+1}')
ax.axis('off')
plt.tight_layout()
plt.show()
# 可视化特征图
def visualize_feature_maps():
# 获取一个测试图像
dataiter = iter(test_loader)
images, labels = next(dataiter)
img = images[0:1]
# 注册钩子来获取特征图
activation = {}
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
model.conv1.register_forward_hook(get_activation('conv1'))
model(img)
# 可视化第一个卷积层的输出特征图
feature_maps = activation['conv1'].squeeze()
fig, axes = plt.subplots(2, 5, figsize=(12, 6))
for i, ax in enumerate(axes.flatten()):
ax.imshow(feature_maps[i], cmap='viridis')
ax.set_title(f'Feature Map {i+1}')
ax.axis('off')
plt.tight_layout()
plt.show()
visualize_kernels()
visualize_feature_maps()🎓 哲学思考:CNN给我们的启示
9.1 层次化的思维方式
CNN采用分层处理的思想,从简单到复杂,从局部到整体,逐步构建对世界的理解。这启示我们在面对复杂问题时,也可以采用层次化的思维方式:
- 分解问题:将复杂问题分解为简单的子问题
- 逐步抽象:从具体到抽象,从现象到本质
- 综合理解:将各个层次的信息综合起来,形成完整的认识
9.2 特征的重要性
CNN的成功关键在于能够自动学习到最有价值的特征。这告诉我们:
- 关注本质:在解决问题时,要抓住最本质的特征和规律
- 避免表象:不要被表面现象所迷惑,要看到问题的深层结构
- 动态学习:特征不是固定不变的,需要根据具体情况动态调整
9.3 结构决定功能
CNN的结构设计(卷积、池化、全连接的组合)直接决定了它的功能和性能。这提醒我们:
- 合理设计:好的结构设计能够事半功倍
- 模块化思想:将复杂系统分解为功能明确的模块
- 整体优化:各个模块之间需要协调配合,实现整体最优
9.4 从经验中学习
CNN通过大量数据的训练不断改进自己的性能,这与人类的学习过程非常相似:
- 实践出真知:通过实践积累经验,不断提高自己的能力
- 从错误中学习:通过反馈机制,纠正错误,不断进步
- 循序渐进:学习是一个渐进的过程,需要持续努力
🎯 总结与展望
10.1 CNN的核心价值
卷积神经网络通过模仿人类视觉系统,成功解决了计算机视觉领域的众多难题。它的核心价值在于:
- 自动特征学习:无需手动设计特征提取器
- 参数效率高:通过参数共享大幅减少参数量
- 强大的表达能力:能够学习到复杂的非线性关系
- 良好的泛化能力:在各种视觉任务上都表现出色
10.2 CNN的发展趋势
随着深度学习技术的不断发展,CNN也在不断演进:
- 轻量化设计:MobileNet、EfficientNet等模型通过特殊的设计降低参数量和计算量
- 多模态融合:结合图像、文本、音频等多种模态的信息
- 自监督学习:减少对标注数据的依赖
- 可解释性研究:提高模型的透明度和可解释性
10.3 未来应用前景
CNN的应用已经从最初的图像识别扩展到了众多领域:
- 增强现实:实时识别和跟踪环境中的物体
- 机器人视觉:帮助机器人理解周围环境并进行交互
- 智能医疗:辅助医生进行疾病诊断和治疗
- 智慧城市:交通监控、安防管理、环境监测等
- 元宇宙:虚拟世界中的物体识别和交互
卷积神经网络的发展历程告诉我们,模仿自然(如人类视觉系统)是人工智能进步的重要途径。随着技术的不断发展,我们有理由相信,CNN将在更多领域发挥重要作用,为人类社会带来更多福祉。