文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: F038
视频
https://www.bilibili.com/video/BV138BvY9E1P/
1 系统简介
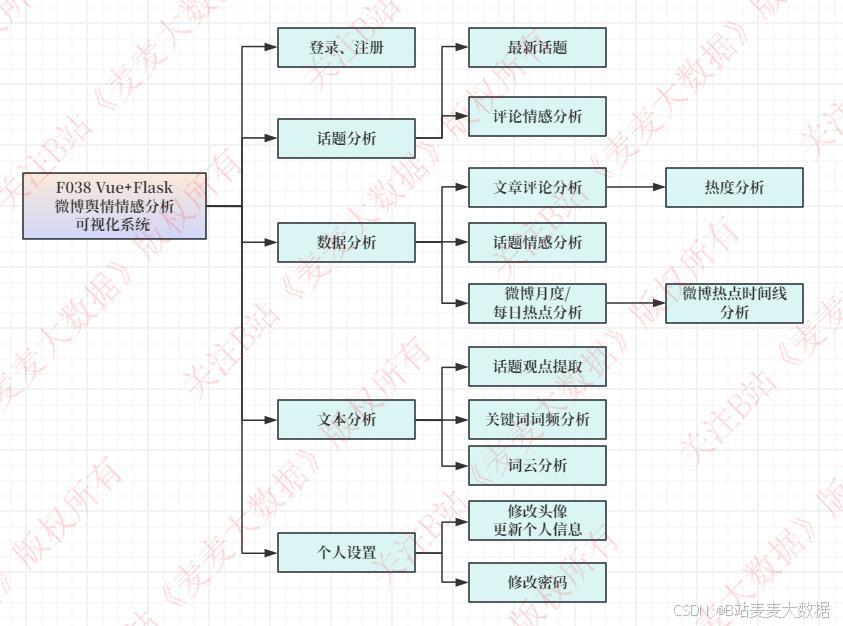
系统简介:本系统是一个基于Vue+Flask+MySQL的微博数据分析可视化平台,构建于典型的B/S架构之上。系统通过实时爬虫技术获取微博最新动态数据,实现对热门话题、评论信息的深度挖掘与多维分析。主要功能模块包括:首页动态展示实时热点话题与情感热度指数;数据看板呈现微博话题的词云图谱、情感分布雷达图及评论热力分析;可视化中心集成时间轴控件展示每日/每月热点演化过程,支持关键词抽取、TF-IDF词频统计、TextRank算法分析等文本处理功能;情感分析模块采用机器学习模型实现评论级情感倾向判定(正面/中性/负面),并生成情感趋势折线图;用户中心包含登录注册体系及个人信息管理功能,支持头像上传、密码修改等个性化设置,为用户提供安全的数据分析服务。
2 功能设计
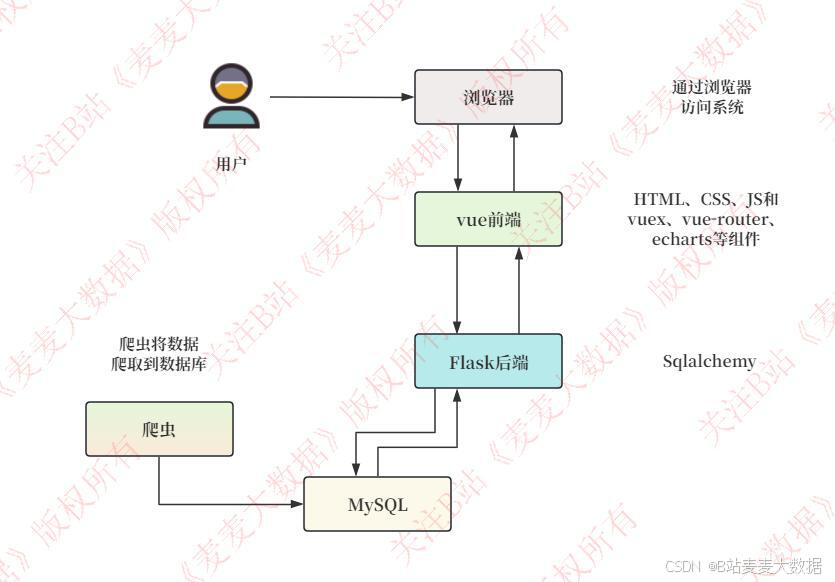
系统采用前后端分离架构模式,前端基于Vue.js构建响应式界面,整合ECharts可视化库实现动态图表渲染,通过Axios组件与后端Flask服务进行RESTful API通信。后端采用Flask框架开发微服务接口,集成SQLAlchemy ORM进行MySQL数据库操作,数据模型包含话题表、评论表、用户表等核心实体。独立部署的微博爬虫模块采用Scrapy框架实现分布式数据采集,通过模拟登录和API调用获取实时话题数据(包括话题内容、评论文本、发布时间、互动数据等),数据经预处理后存储至MySQL数据库。文本分析引擎集成Jieba分词、SnowNLP情感分析、Gensim主题模型等NLP技术,支持关键词提取(TF-IDF/TextRank算法)、观点抽取、情感极性分析等处理流程。可视化模块通过D3.js与ECharts构建动态热力图、词云图谱、时间序列分析等交互式图表,热点分析功能结合时间衰减算法实现历史趋势追踪与预测。用户认证模块采用JWT令牌机制保障接口安全,个人中心支持头像上传、密码修改等基础功能,完成完整的用户生命周期管理。
2.1系统架构图
2.2 功能模块图
3 功能展示
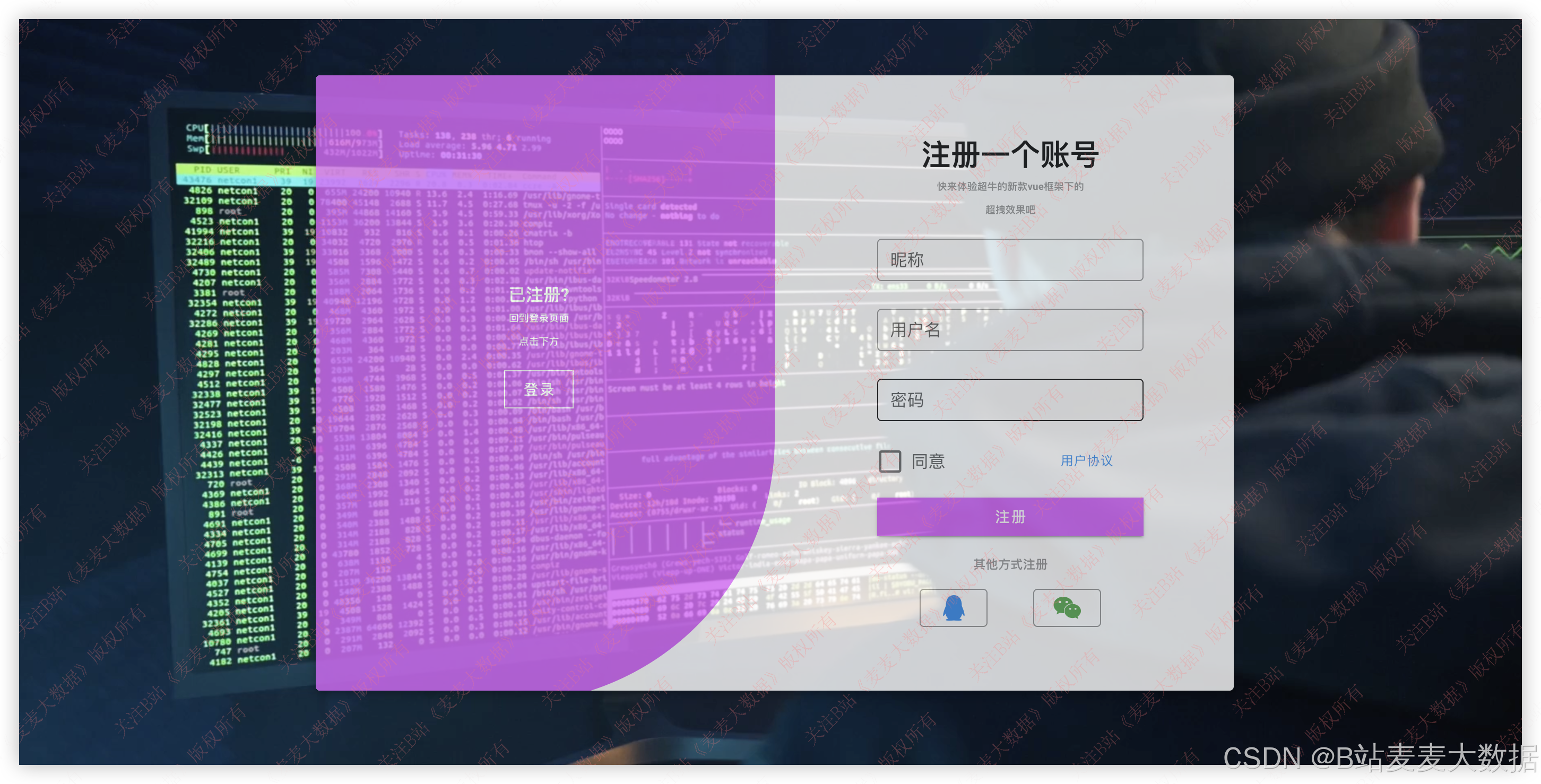
3.1 登录 & 注册
登录注册做的是一个可以切换的登录注册界面,点击去登录后者去注册可以切换,背景是一个视频,循环播放。
登录需要验证用户名和密码是否正确,如果不正确会有错误提示 。

注册需要验证用户名是否存在 ,如果错误会有提示。
3.2 主页
主页的布局采用了左侧是菜单,右侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。
主页是一个轮播图:

下方是爬取的微博话题最新信息:
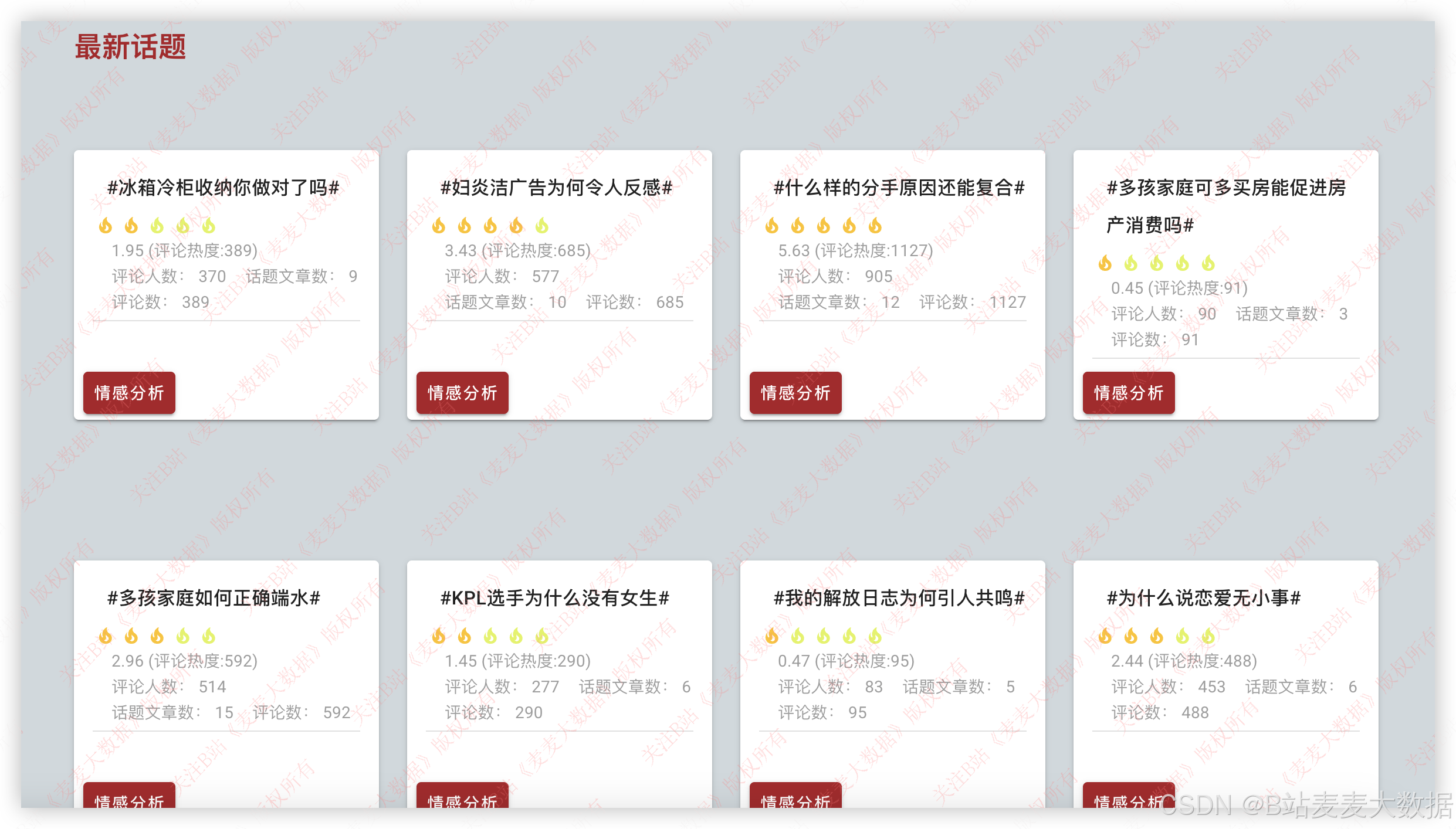
点击话题卡片还可以看到最新的微博话题评论,以及对评论的情感分析结果(大拇指):

3.3 话题搜索
输入关键词进行微博话题的索索:
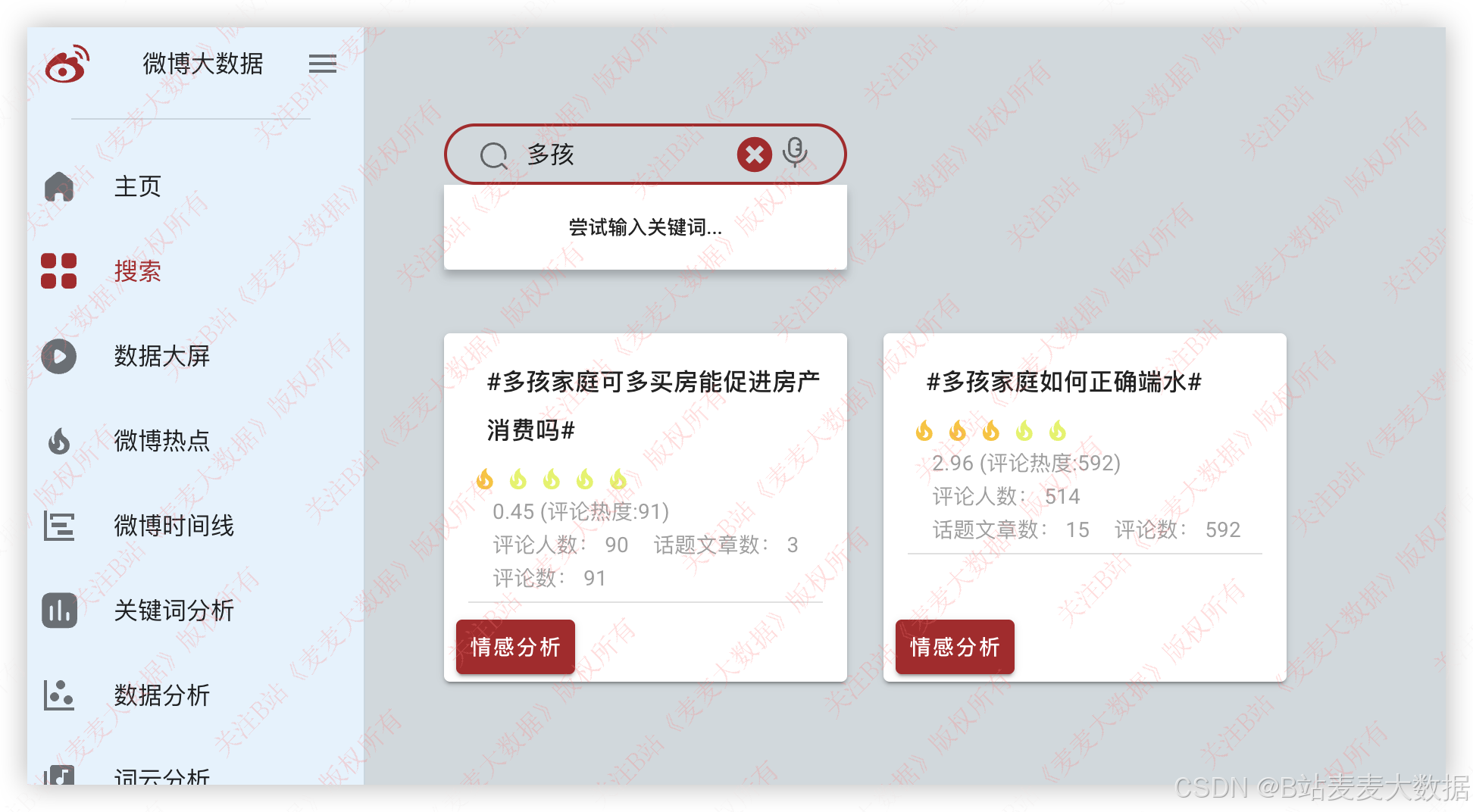
3.4 微博热搜可视化
每日热点话题:
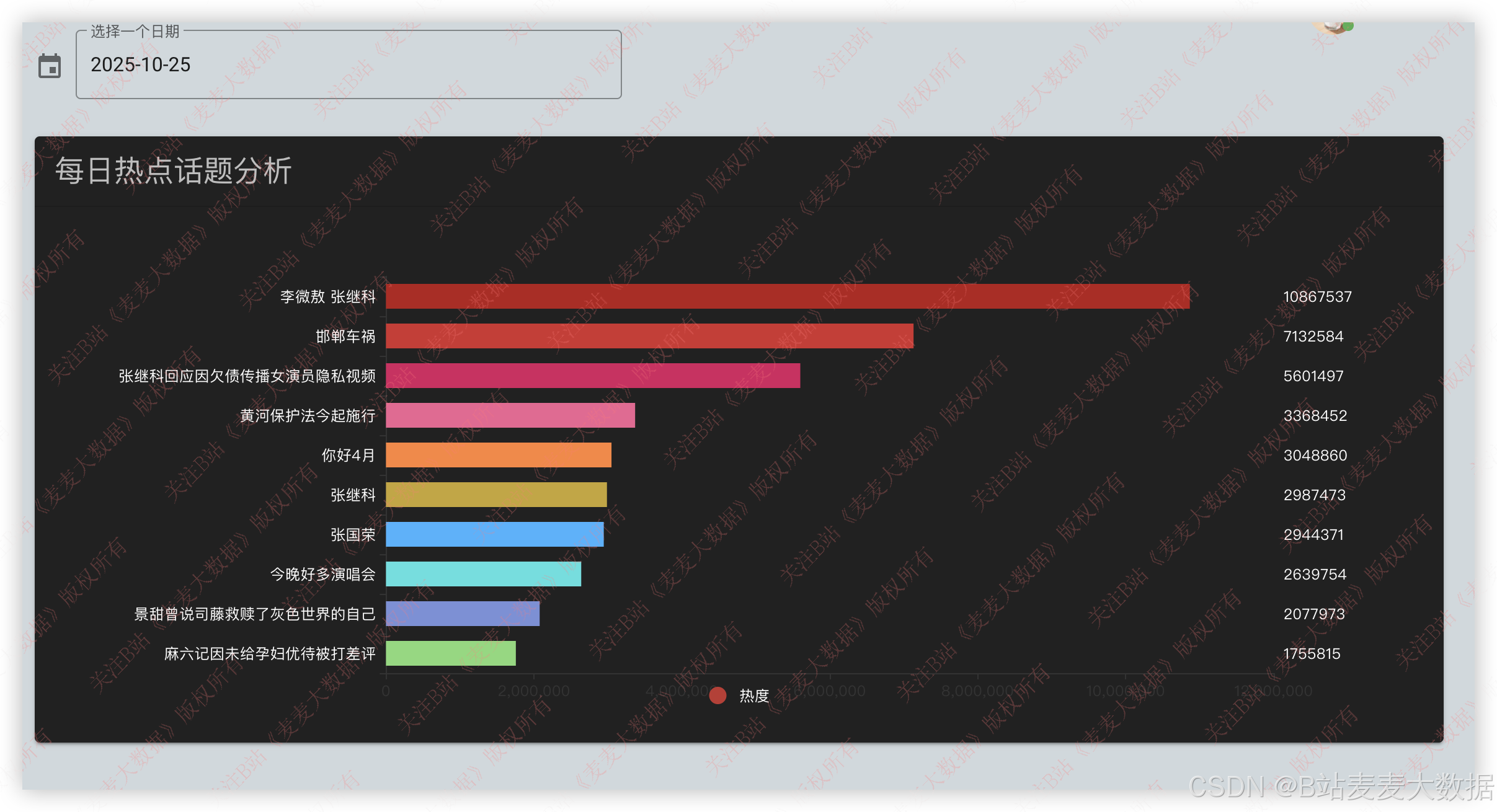
月度热点话题:
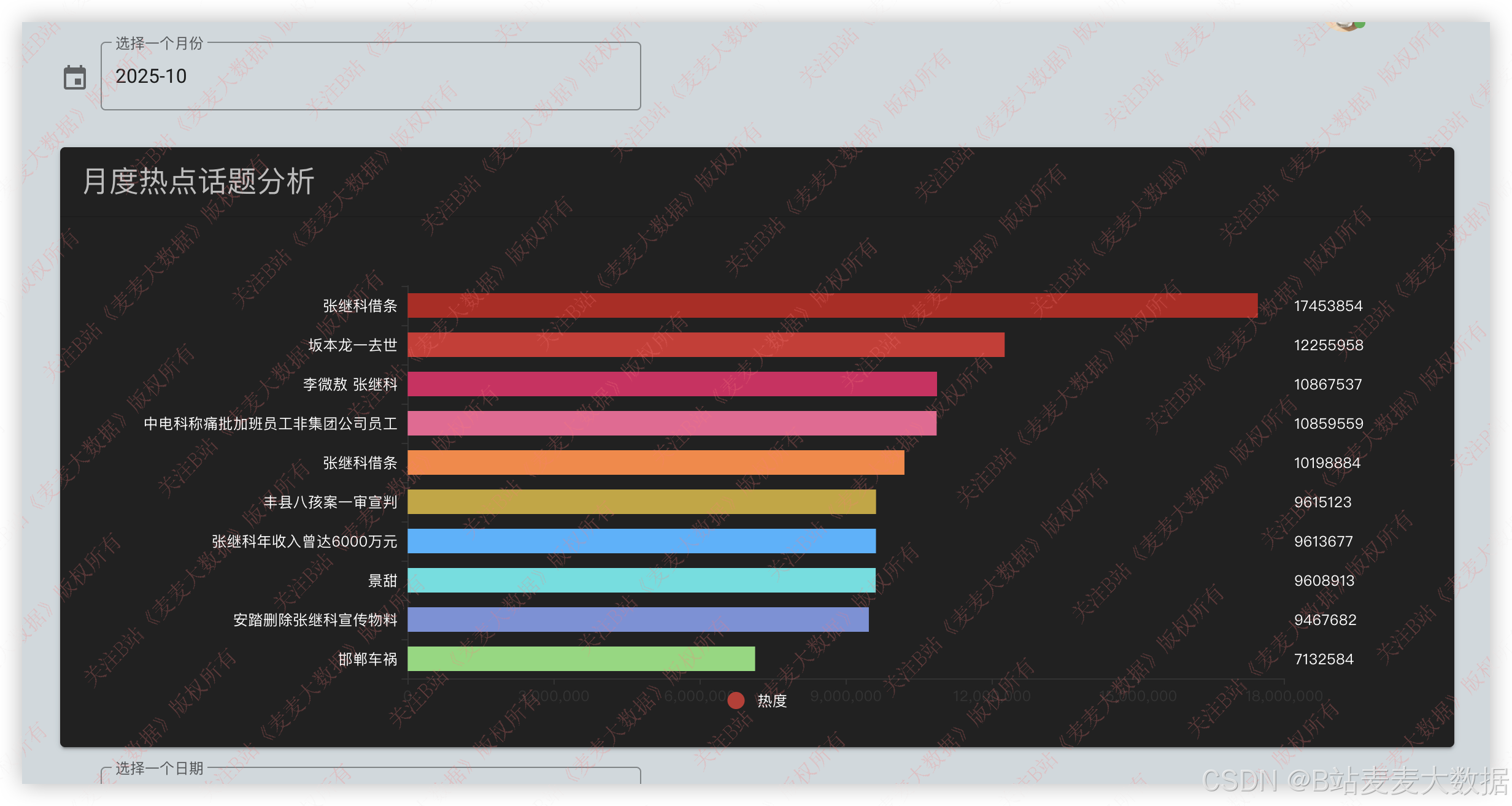
微博热点时间线:

3.5 微博热度可视化
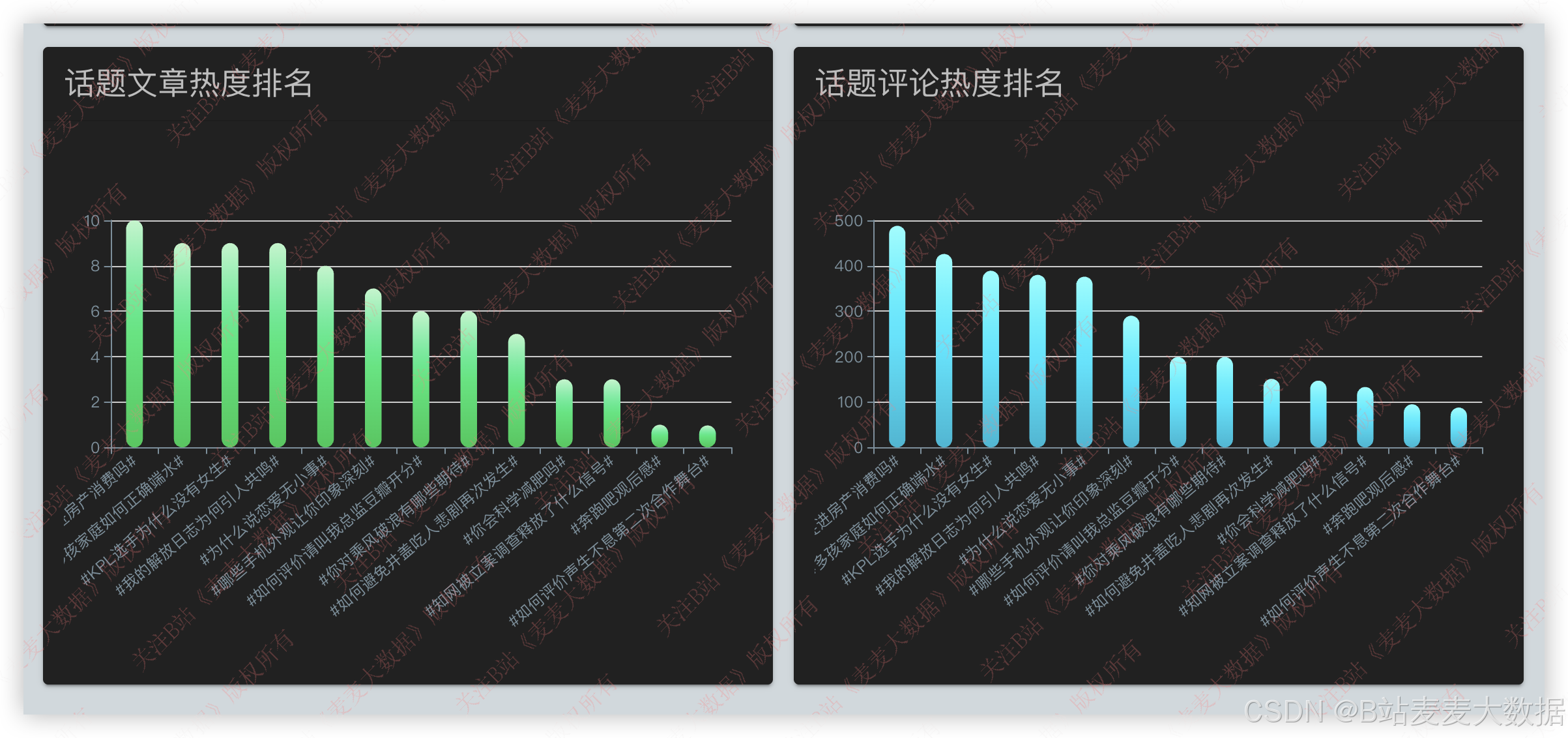
评论文章分析:
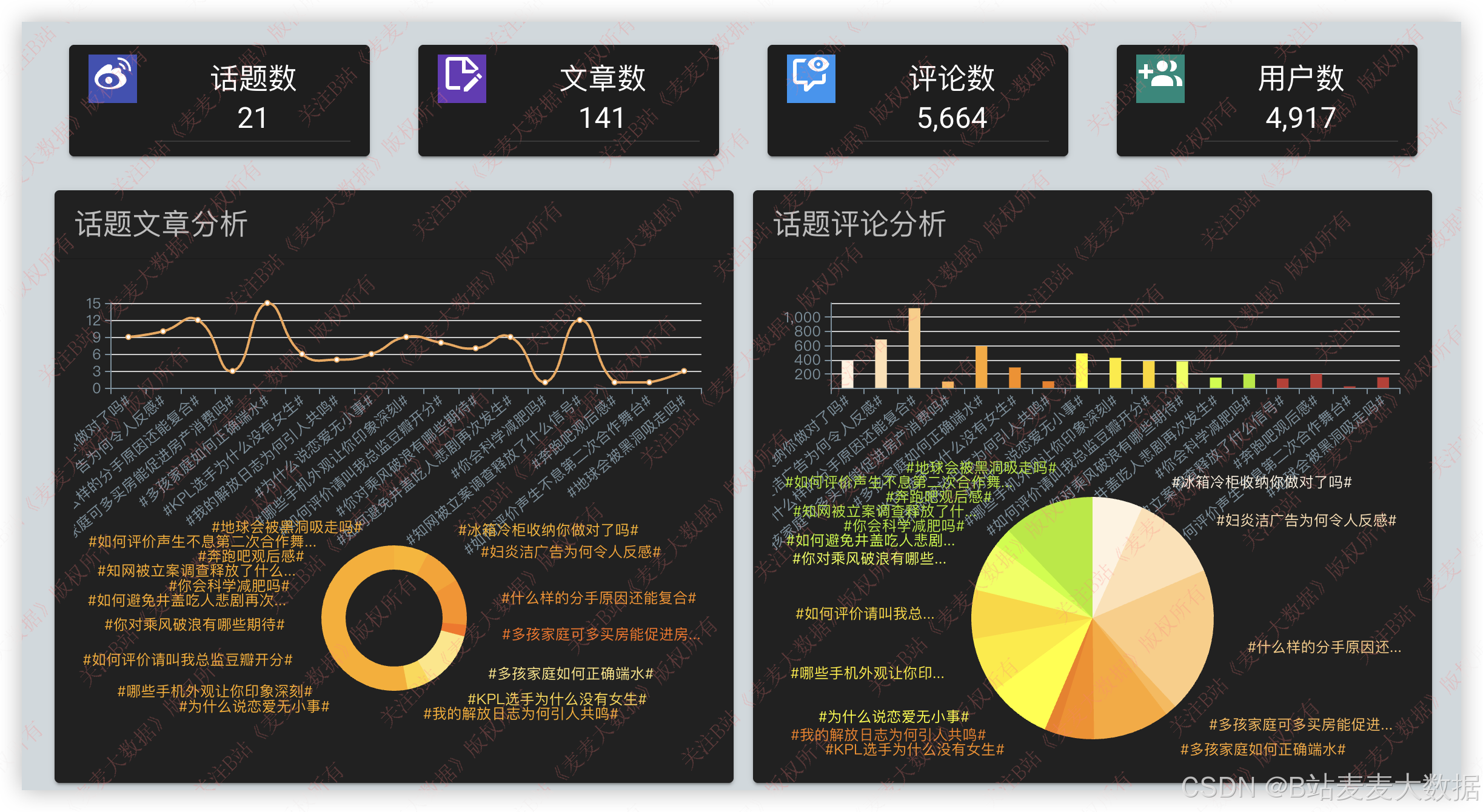
评论热度分析:
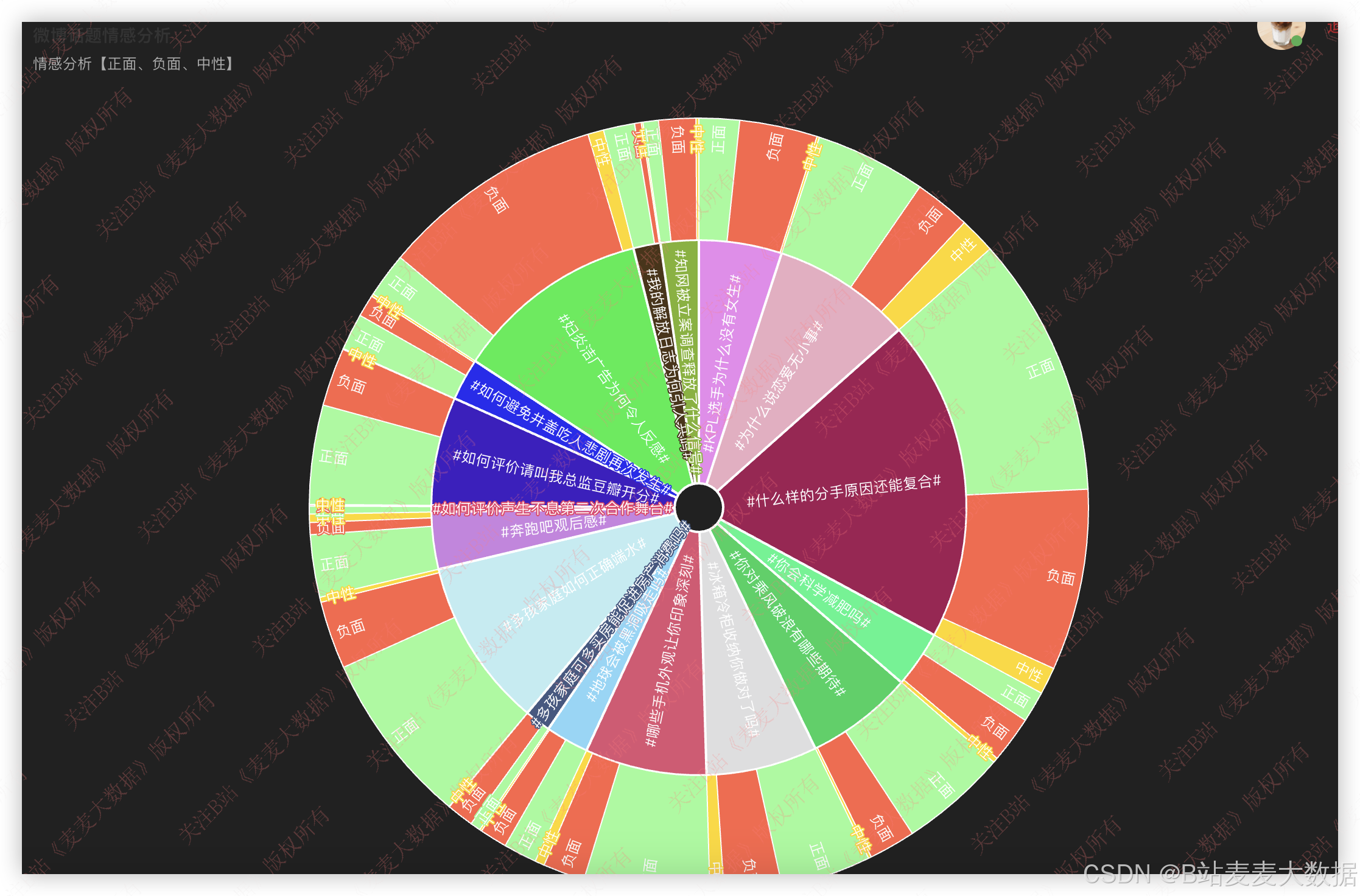
可视化情感分析:

3.6 微博文本分析
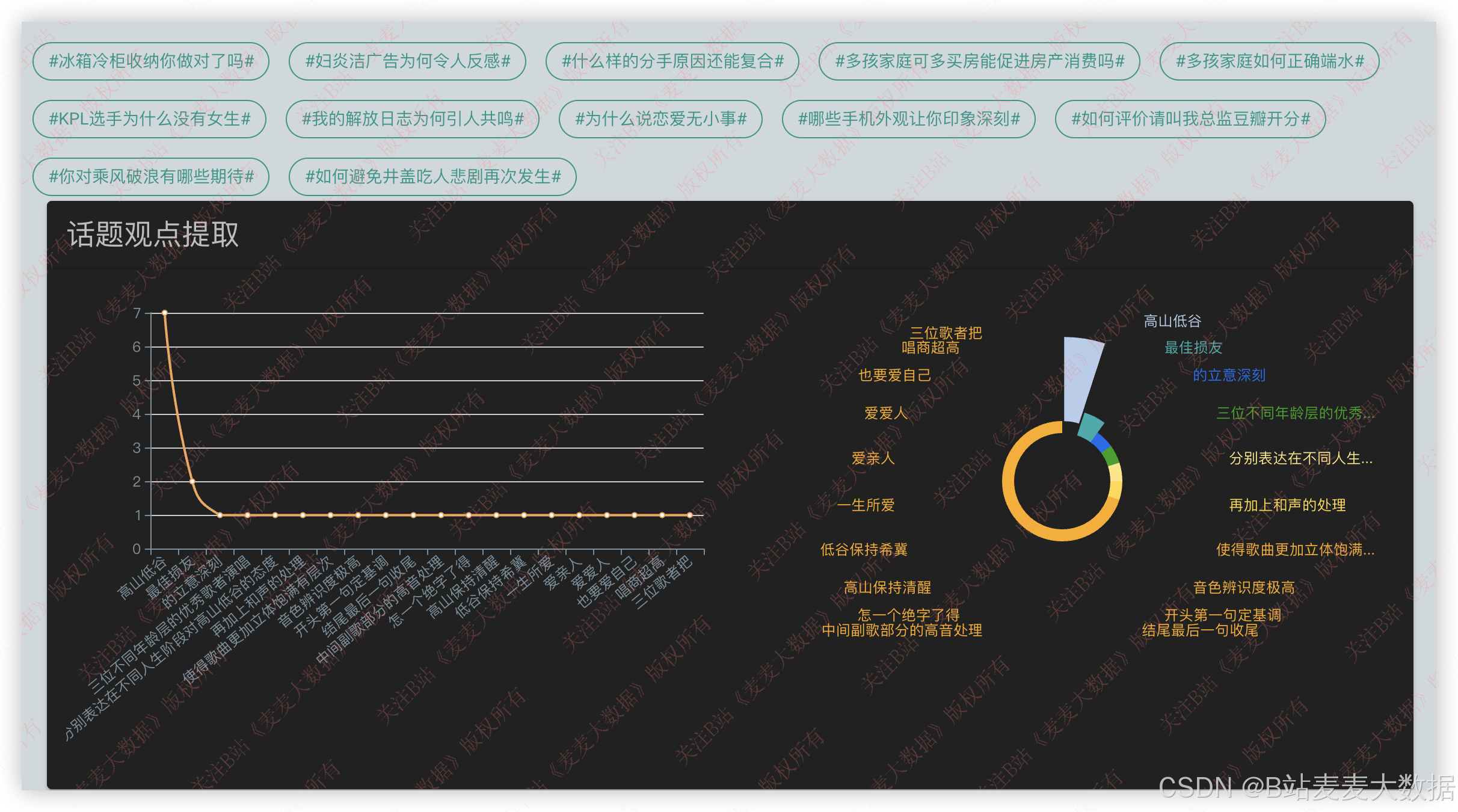
话题观点提取:
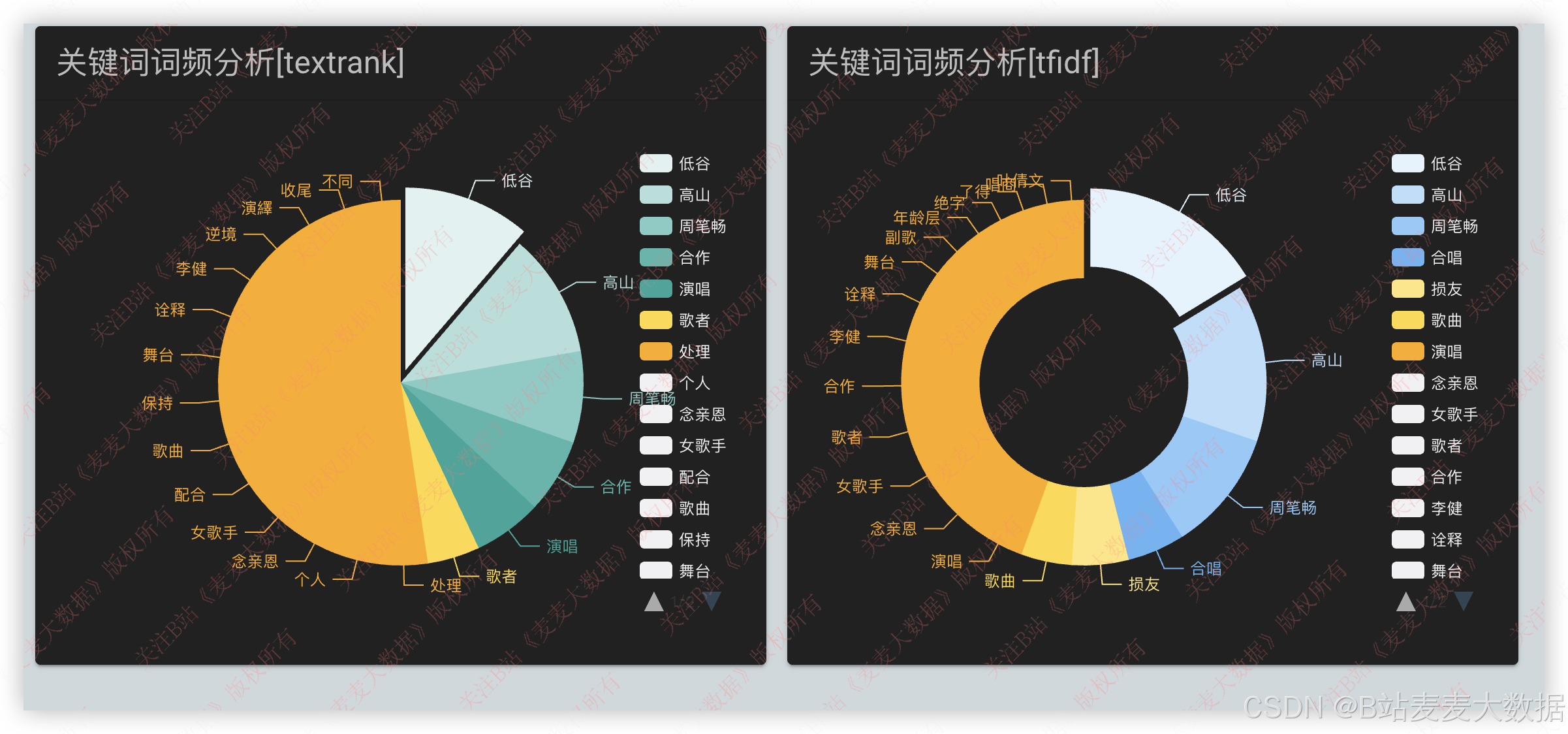
关键词词频分析:
词云分析:

3.7 微博信息表格搜索
可以查看当前话题的负面舆情指数:

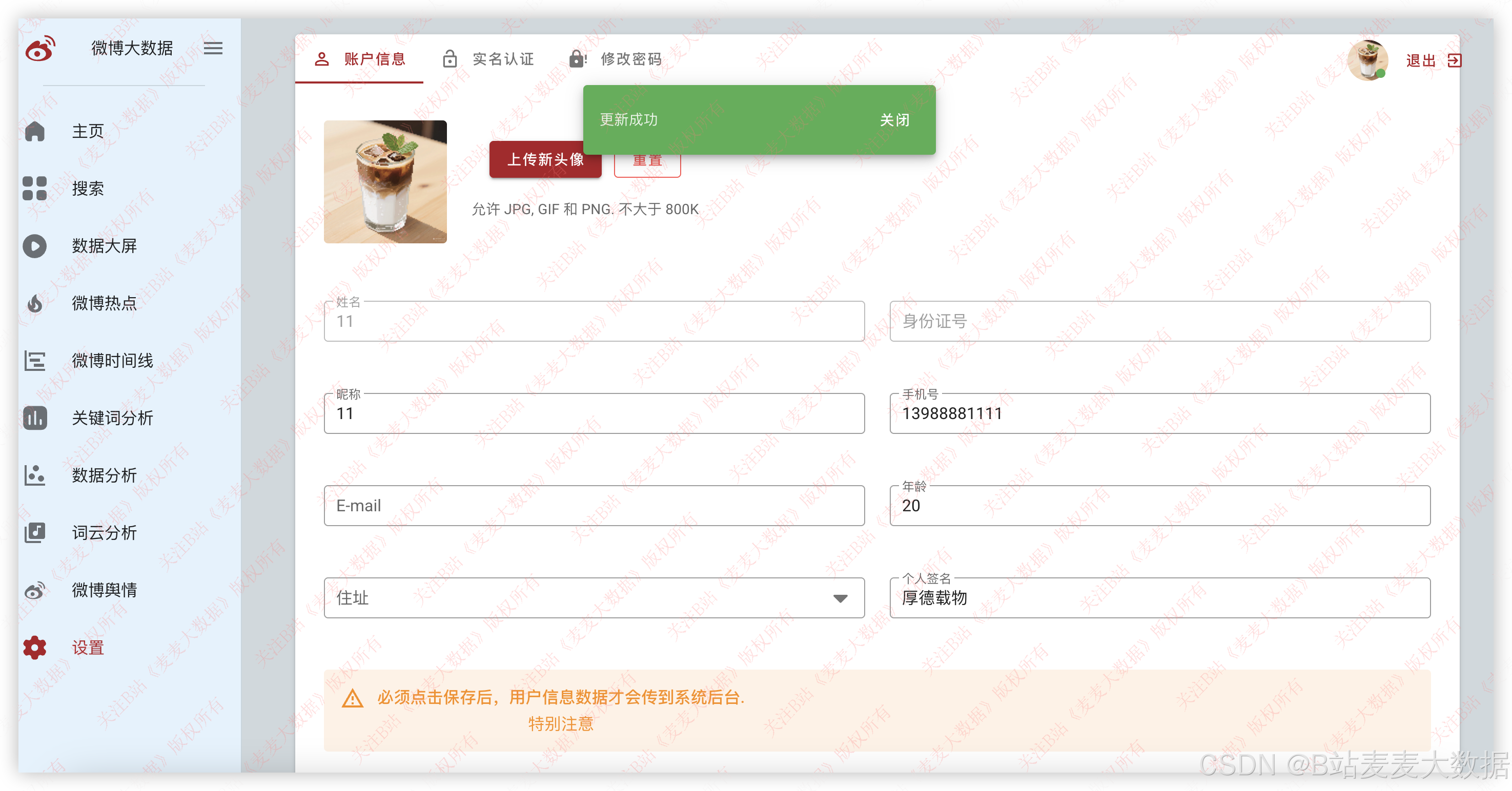
3.8 个人设置
个人设置方面包含了用户信息修改、密码修改功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息。
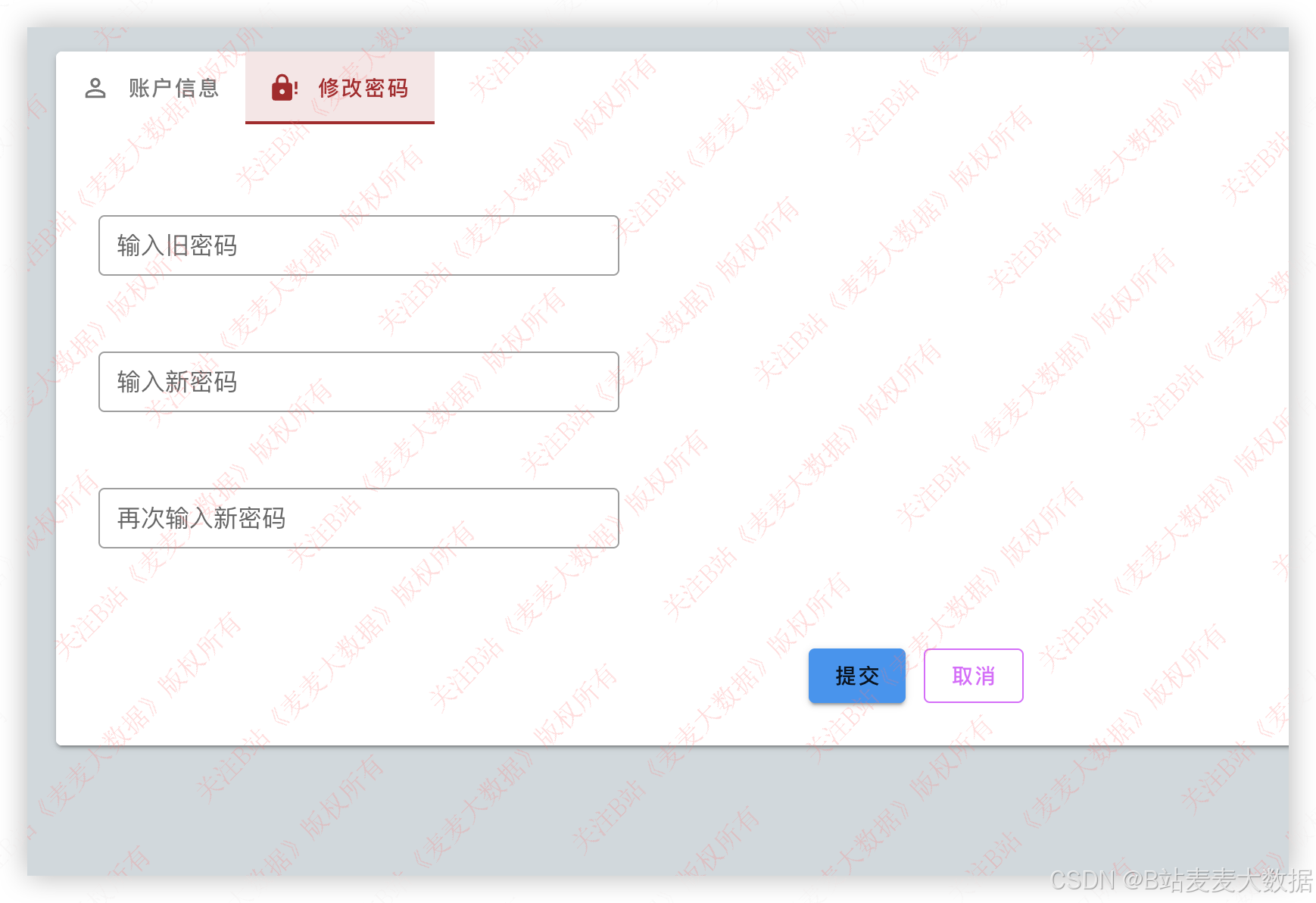
修改密码需要输入用户旧密码和新密码,验证旧密码成功后,就可以完成密码修改。
4程序代码
4.1 代码说明
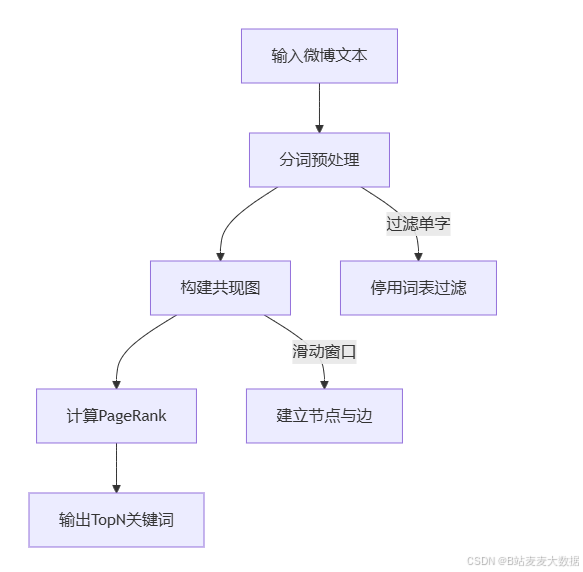
代码介绍:以下是一个基于TextRank算法的微博舆情关键词提取方案,包含代码说明、流程图和示例代码:
4.2 流程图
4.3 代码实例
python
import jieba
import networkx as nx
from collections import defaultdict
def weibo_text_rank(text, window=2, top_k=10):
# 预处理:分词和过滤
words = [w for w in jieba.cut(text) if len(w.strip()) > 1]
# 构建共现图
graph = nx.Graph()
for i in range(len(words)-window+1):
for j in range(i+1, min(i+window, len(words))):
w1, w2 = words[i], words[j]
graph.add_edge(w1, w2, weight=1)
# 计算PageRank值
scores = nx.pagerank(graph, alpha=0.85)
# 返回Top-N关键词
return sorted(scores.items(), key=lambda x: -x[1])[:top_k]