目录
- 引言
- 一、模型简介
-
- 精准交互控制技术
- [3D 几何一致性保障机制](#3D 几何一致性保障机制)
- 高效世界模型强化学习方法
- 高效模型优化与蒸馏方案
- 实时流式推理方案
- 二、混元世界模型1.5架构解析
- 三、爱之初体验
引言
元旦好呀,新年的第一天祝大家新的一年顺顺利利,财源滚滚。
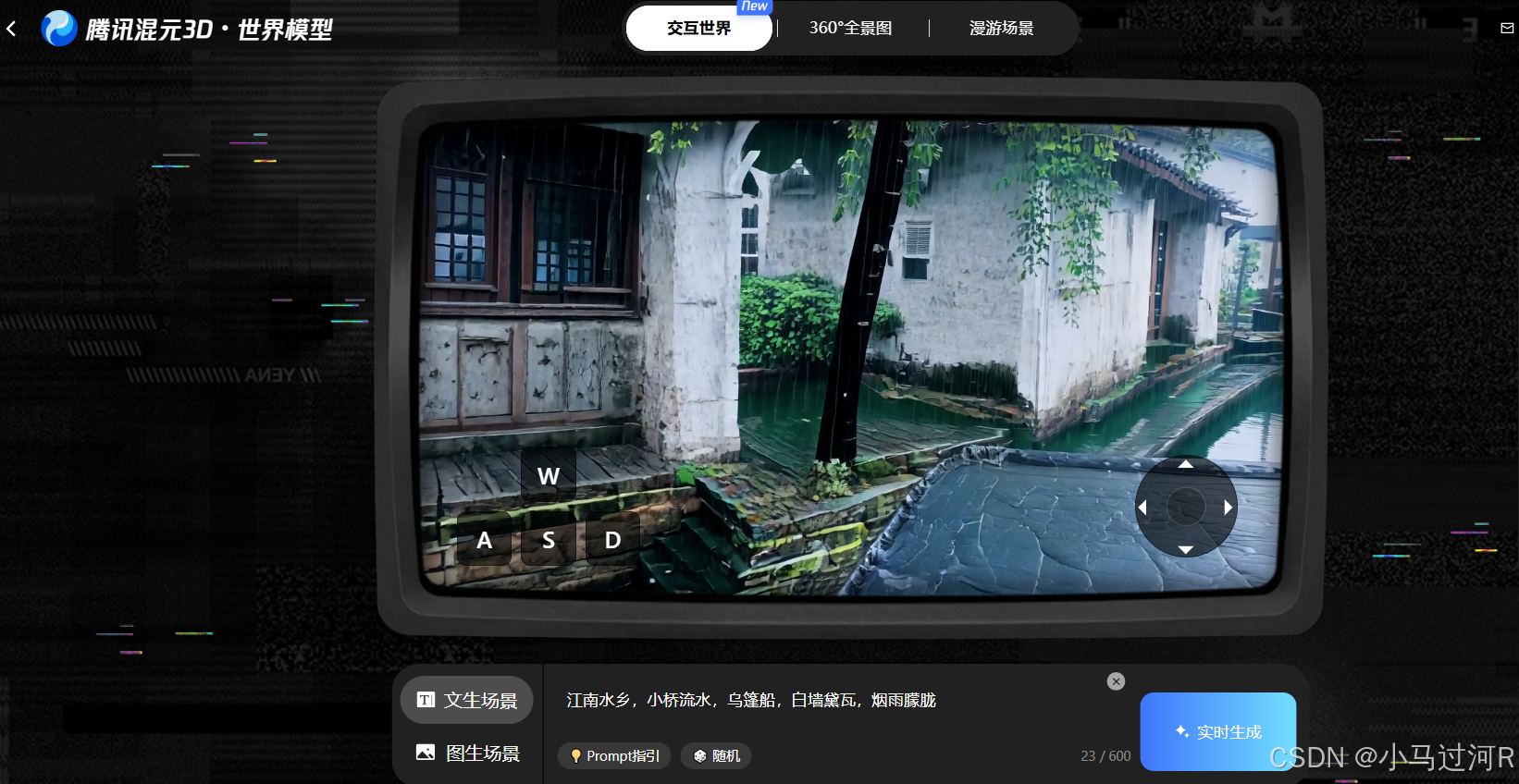
12月中旬,国内首个开放体验的实时世界模型 - 混元世界模型1.5(HY World 1.5)正式发布及开源!3D大模型乃至3D世界模型这块属于是小马的新草地,一发现这个消息小马就迫不及待地去体验了一番,不得不说效果真的很哇塞,交互世界和360度全景都好震撼。(漫游场景还没申请通过~~ 看起来也很挺)

一、模型简介
腾讯混元世界模型1.5(Tencent HY WorldPlay)是腾讯于2025年12月17日发布的最新版本,作为业界首个系统化开源的实时世界模型框架,它支持通过文字或图片输入生成可交互的三维场景,并具备空间记忆能力以维持长期一致性。
该模型的核心功能包括: 支持第一人称和第三人称视角的实时交互,用户可通过键盘、鼠标或手柄自由探索生成的世界;能根据指令(如"废弃游乐园,生锈的摩天轮")创建风格化场景,并触发动态效果(如爆炸或烟雾);同时支持3D点云导出,适用于游戏开发、影视预览和虚拟现实等领域。
技术上,混元世界模型1.5的核心是WorldPlay自回归扩散模型, 通过以下创新实现突破:
- 双重动作表示法:精准响应用户输入,实现流畅控制。
- 重构记忆机制:动态重建历史帧信息,缓解长视频生成中的记忆衰减问题。
- 情境强迫蒸馏法:通过记忆上下文对齐,在保持高速生成的同时抑制误差累积。
- WorldCompost强化学习框架:优化长序列视频生成的视觉质量和动作跟随能力。
性能方面, 模型在基准测试中视觉质量和几何一致性指标超越多数现有模型(如ViewCrafter和Gen3C),实时生成速度达24帧/秒,支持分钟级内容的一致性生成;其训练体系覆盖数据构建、预训练、持续训练和流式推理部署全流程,为AI游戏关卡生成、虚拟现实内容创作及具身智能研究提供了高效平台。
项目开源仓库:https://github.com/Tencent-Hunyuan/HY-WorldPlay
HY-World 1.5:一个具有实时延迟和几何一致性的交互世界建模系统框架。
支持实时交互生成、保持3D一致的世界模型。适用于风格多样的场景生成,支持3D重建、文本触发事件等多种应用。
精准交互控制技术
创新双分支动作表征,融合三维相机位姿与离散控制指令。相比单一离散指令,借助空间位置先验提升生成一致性。相较于纯连续位姿,缓解场景尺度不一致导致的收敛慢与控制漂移问题。
3D 几何一致性保障机制
构建短时序上下文记忆确保运动平滑,建立 FOV 与相机距离采样的长空间记忆防几何漂移。提出 "时间重构" 技术,动态重分配记忆帧 RoPE 编码,强化历史帧持续影响力。
高效世界模型强化学习方法
提出 World Compass 强化学习 (RL) 框架,旨在同步提升世界模型的动作控制准确性和视觉输出质量。设计渐进式 rollout 策略和细粒度奖励函数,显著提高采样效率,并通过与模型的自回归特性对齐,实现训练与推理过程的一致性。
高效模型优化与蒸馏方案
提出 Context Forcing 蒸馏策略,对齐师生模型记忆上下文。解决分布匹配蒸馏(DMD)模式崩溃问题,平衡实时性与记忆能力。减少长序列生成中的误差累积,兼顾速度与生成质量。
实时流式推理方案
开发流式推理服务,优化等待、传输与推理全链路延迟。采用 DiT 与 VAE 混合并行、流式解码传输及模型量化等优化。支持 720p 分辨率、24 帧 / 秒长时流式生成,适配多样化场景。
二、混元世界模型1.5架构解析
HY-World 1.5 是一个生成式世界模型,采用Next-Frames-Prediction 的视觉自回归任务进行训练,实现了长时几何一致性的实时世界交互,破解了当前方法同时满足实时性与几何一致性的难题。该模型依托四大核心创新:双分支动作表征 实现精准控制、上下文记忆重构机制 保持几何一致性、高效细粒度强化学习后训练框架 来进一步增强生成视频的视觉质量和控制准确性、上下文对齐蒸馏技术实现实时生成并保证几何一致性。除此之外,混元团队构建了自动化3D场景渲染流程,可以获得大量高质量的渲染数据,进一步激发核心算法的潜力。HY-World 1.5可支持24帧 / 秒的长时流式生成,一致性与泛化能力适用于多样化场景。
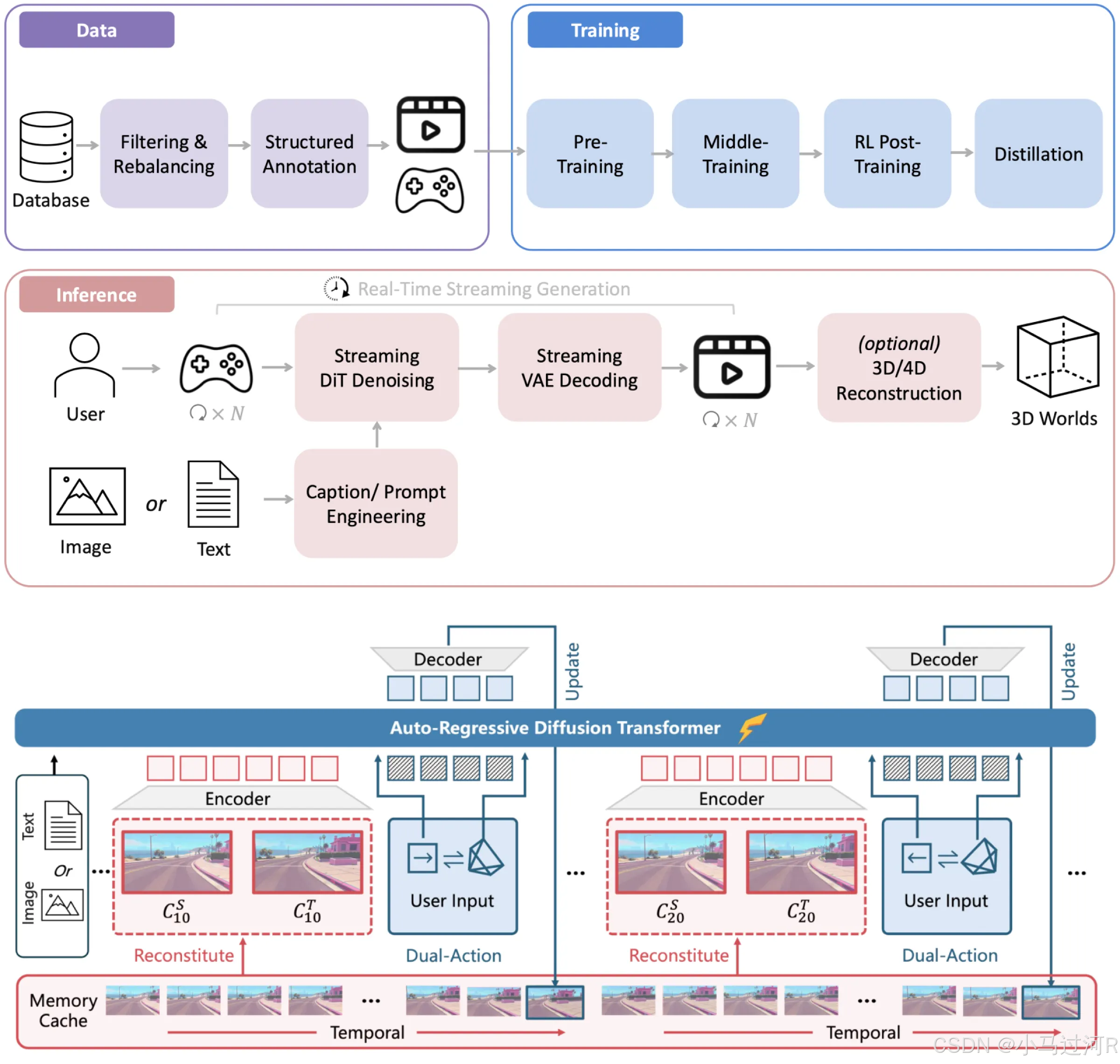
这张原理图展示了一个多模态生成与交互系统的完整架构,主要分为数据处理、模型训练、实时推理三大核心模块,结合自回归扩散Transformer和流式生成技术,实现从数据输入到3D/4D内容生成的端到端流程。以下是具体解析:
整体架构概述
系统以"数据-训练-推理"为主线,融合文本、图像等多模态输入,通过预训练、强化学习优化等步骤,最终生成实时流式内容或3D/4D虚拟世界,适用于游戏场景、实时交互等动态生成需求。
核心模块详解
- 数据处理模块(Data)
数据来源:以"Database"为起点,包含原始数据的采集与存储。
预处理流程:
Filtering & Rebalancing:数据过滤与重平衡,筛选有效数据并调整样本分布,避免训练偏差。
Structured Annotation:结构化标注,对数据添加语义标签(如图像区域标注、文本语义分类),为模型训练提供监督信号。
Game Data:明确标注"Game"场景,说明数据可能包含游戏相关的交互日志、场景数据等,用于适配游戏领域的生成需求。
- 模型训练模块(Training)
分阶段训练流程:
Pre-Training:基于大规模无标注数据进行自监督学习,初始化模型参数,掌握通用语义和生成能力。
Middle-Training:在预训练基础上,使用标注数据进行有监督微调,优化特定任务(如游戏场景生成)的性能。
RL Post-Training:通过强化学习(RL)进一步优化模型,可能针对生成内容的"真实性""交互性"等指标进行奖励信号调整。
Distillation:蒸馏过程,将大模型的知识压缩到轻量化模型中,降低推理时的计算成本,提升实时性。
- 实时推理模块(Inference)
核心目标:实现"User Input"到"3D Worlds"的实时生成,支持动态交互。
关键流程:
输入类型:支持"Image"(图像)和"Text"(文本)两种模态输入,用户可通过游戏手柄等设备实时输入指令。
生成过程:
Streaming DIT Denoising:流式去噪扩散模型(DIT),逐次生成图像细节,实现低延迟输出。
Streaming VAE Decoding:流式变分自编码器解码,将模型生成的潜在变量转换为可渲染的图像/视频流。
Real-Time Streaming Generation:实时流式生成,确保内容随用户输入动态更新,避免卡顿。
可选输出:通过"3D/4D Reconstruction"模块,将生成的2D内容扩展为三维或四维空间(如加入时间维度的动态场景),最终构建虚拟世界。
- 核心模型:Auto-Regressive Diffusion Transformer
架构组成:
Encoder-Decoder结构:编码器(Encoder)处理输入文本/图像,解码器(Decoder)生成输出序列,支持自回归生成(逐token预测)。
Dual-Action与Memory Cache:通过"Dual-Action"模块实现输入与记忆的融合,"Memory Cache"存储历史生成状态,结合"Temporal"(时间维度)信息,确保生成内容的连贯性(如游戏场景的前后帧一致性)。
Update机制:解码器通过"Update"持续优化生成结果,结合"Reconstitute"模块动态重构内容,提升实时性。
应用场景与技术特点
典型场景:游戏场景生成(如动态地图、角色动作)、实时交互式虚拟世界(如元宇宙中的场景构建)、多模态内容创作(如文本生成图像、图像生成视频)。
技术优势:
实时性:流式生成(Streaming)技术确保低延迟响应,满足游戏等实时交互需求。
多模态融合:同时处理文本、图像输入,生成内容更贴近真实场景。
可扩展性:支持从2D图像到3D/4D空间的扩展,适配不同维度的生成需求。
关键技术术语补充
Auto-Regressive:自回归模型,通过已生成的部分内容预测下一个元素,适用于序列生成任务(如文本、图像像素)。
Diffusion Transformer:结合扩散模型(逐步生成)和Transformer(注意力机制),平衡生成质量与效率。
VAE(变分自编码器):通过编码-解码学习数据的潜在分布,用于生成高保真图像或视频。
通过以上模块的协同,该系统实现了从数据到实时3D/4D内容的端到端生成,核心在于"训练-推理"闭环与流式生成技术的结合,尤其适用于需要动态交互的场景。
三、爱之初体验
目前体验是需要申请的,不过通过很快,官方传送门。小马试了一下360度全景功能,文生全景图。
提示词:
bash
太空站观景台,巨大的地球悬浮窗外,星空璀璨,科幻感十足。效果如下,挺有感觉的:

https://3d.hunyuan.tencent.com/share?shareId=9119adf3-df13-4e46-882c-f58b88e0ea7c&shareType=panorama
- 彩蛋的位置