Kafka 是一款由 Apache 软件基金会开发的分布式流处理平台,主要用于高吞吐量的实时数据管道构建、流式数据分析及跨系统集成。其核心特性包括持久化存储、水平扩展和容错机制。
核心概念
-
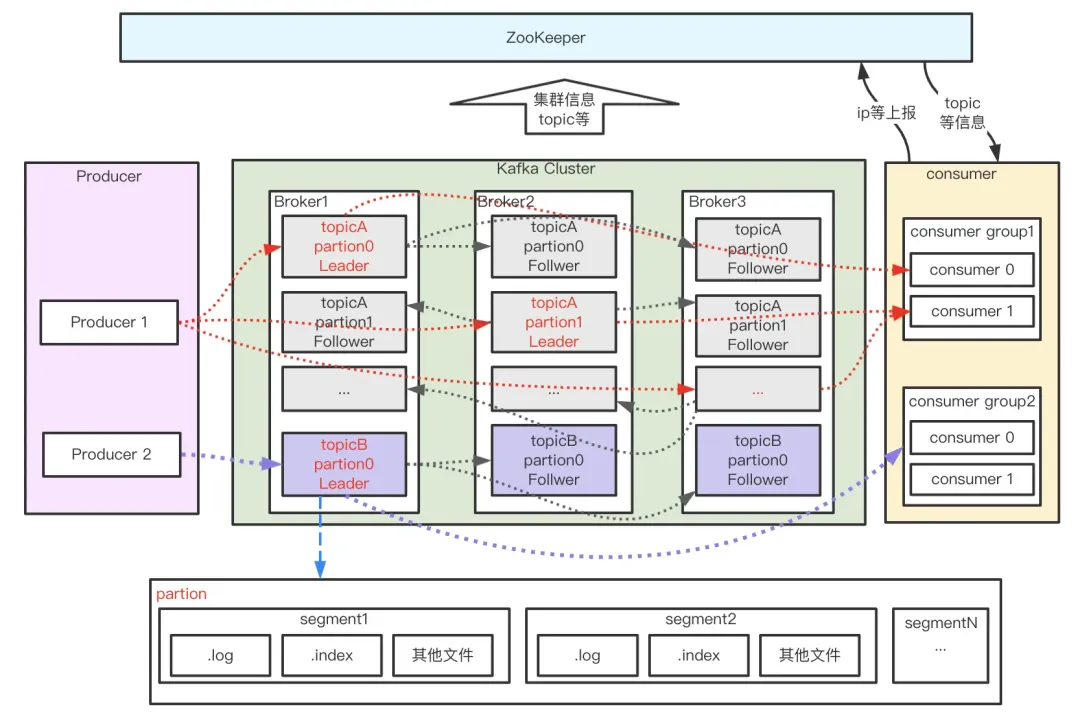
主题(Topic)
消息的分类单元,生产者将消息发送到特定主题,消费者订阅主题进行消费。
-
分区(Partition)
每个主题分为多个分区,分区是消息的有序队列,物理上对应一个文件夹,支持水平扩展。
-
副本(Replica)
分区的副本分布在集群不同节点,通过冗余提升可用性。
-
分段(segment)
宏观上看,(一个partition对应一个日志)。由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据检索效率低下,kafka采取分段和索引机制,将每个partition分为多个segment,同时也便于消息的维护和清理。
核心组件
- 生产者(Producer):发布消息到主题。
- 消费者(Consumer):订阅主题并处理数据流。
- 代理(Broker):Kafka 集群中的服务器节点,负责消息存储和转发。
应用场景
- 实时数据管道:如日志收集、大数据传输。
- 流式处理:电商订单处理、金融交易监控。
与其他消息队列对比
- Kafka:高吞吐、持久化存储,适合海量数据场景。
- RabbitMQ:低延迟、复杂路由,适合中小规模系统。
- RocketMQ:金融级事务支持,如订单一致性。
参考:Kafka 官方文档 或入门教程。