一、绪论
1 、问题背景
国家优秀青年科学基金和国家杰出青年科学基金是中国科学技术部设立的两个重要科研项目,旨在发现和培养具有创新能力和发展潜力的优秀青年科学家。这些基金的设立和资助机制为优秀青年科学家提供了稳定的科研经费支持,激励他们在各自领域取得突破性的科学成果,推动中国科技事业的发展。
为了更好地了解这些优秀的科研人员的研究方向,本组成员共同完成了近五年国家杰青优青名单数据的搜集、分析与成果展示,以期为我国科研人才管理和培养提供有益的参考。
2 、问题提出
基于以上背景,需要建立模型解决以下问题:
①根据所提供的近五年国家杰青和优青名单,搜集整理对应科研人员的详细信息,并对数据进行初步处理,使之便于后续的分析;
②对处理后的数据进行特征提取,并对其进行相应的分析和解释;
③选择合适的机器学习算法对科研人员进行分类,并通过各项指标对模型性能进行评估;
④根据分析所得到的结果,对我国科研人才的管理和培养提出建议。
二、数据预处理
结合近五年国家杰青和优青名单,通过在网络上查找相关资料,本文对数据进行了二次补充。其中补充的个人属性包括:本科学校、硕士学校、博士学校、职称、论文H指数、成果数量、学校排名、出生年份等。在本文中,"成果数量"一项的数据以"科研之友"网站上的数据为准,"学校排名"以文件"university_new.xlsx"为准。由于有部分科研人员的出生年份无法在网络上查到准确的数据,因此本文以他们的"本科入学年份 - 18"代替他们的出生年份。同时,为了便于后续模型的建立,本文将科研人员的研究方向进行了类别划分,具体的划分规则如下:
A类:机械控制,包括机械、仪器仪表、自动化控制、工程、交通、建筑等
B类:信息技术,包括计算机、电信、通讯、电子等
C类:数理学科,包括数学、物理、地球与空间科学等
D类:生命科学,包括生物、农学、药学、医学、健康、卫生、食品等
E类:能源化工,包括能源、材料、石油、化学、化工、生态、环保等
F类:不属于以上任何一类的其他研究方向
经过上述处理,发现有部分科研学者的信息并不完整。对数据进行清洗、去重和格式化处理,得到预处理后的数据(详见附件"data_final.xlsx")。
三、特征工程
对预处理后的数据进行分析。为了便于后续模型的构建,本文将"主任医师"等价为"教授","教授级高级工程师"等价为"教授", "副主任医师"等价为"副教授","副主任"等价为"教授", "主任"等价为"教授";对于年龄未知的科研人员,统一将其年龄设置为40岁;用学校排名代替学校名称,若排名未知,则设置为"-1"。
通过上述处理,可以提取出以下特征:姓名、年份、类型、职称、论文H指数、成果数量、学校排名、年龄、研究方向(A、B、C、D、E、F)、博士学校排名、硕士学校排名、本科学校排名、学校层次(985、211、双非)。
四、模型构建
通过查阅资料可知,聚类算法有:原型聚类(K-means,学习向量化,高斯混合聚类等)、密度聚类、层次聚类等方法。本文采用了pycaret库中自带的聚类算法进行比较,以得到最佳的模型。
Pycaret库提供了以下聚类方法,其代号和各自的特点分别如表1所示:
| 名称 | 简写 | 特点 |
|---|---|---|
| K-Means 聚类 | kmeans | 是一种基于距离的聚类算法,它试图将数据划分为预定义的聚类数量,并最小化每个聚类内部的平方误差 |
| Affinity Propagation 聚类 | ap | 是一种基于数据点之间的"亲和力"的聚类算法,不需要预先设定聚类的数量 |
| Mean Shift 聚类 | meanshift | 是一种基于密度的聚类算法,它试图找到数据的密度峰值作为聚类中心 |
| Spectral Clustering 聚类 | sc | 是一种基于图论的聚类算法,它试图找到数据的最优划分,使得划分后的子集之间的相似度最小 |
| Hierarchical Clustering 聚类 | hclust | 是一种基于层次的聚类算法,它可以生成一个聚类树,用户可以在任何层次上划分聚类 |
| DBSCAN 聚类 | dbscan | 是一种基于密度的聚类算法,它可以发现任意形状的聚类,并能够处理噪声数据点 |
| OPTICS 聚类 | optics | 是一种基于密度的聚类算法,它是 DBSCAN 的一种改进,可以处理不同密度的聚类 |
| BIRCH 聚类 | birch | 是一种基于层次和密度的聚类算法,它特别适合处理大数据集 |
表1
首先,需要从这些模型中选出几种较为可靠的方法。在不设置分类类别数的前提下,对所有数据进行聚类,观察各种模型的聚类效果,结果如表2所示:
| 模型 | 丢弃原因 |
|---|---|
| kmeans | 4个分类,不集中在某一类 |
| hclust | 4个分类,不集中在某一类 |
| birch | 4个分类,不集中在某一类 |
| ap | 分类过多 |
| meanshift | 分类过多,而且高度集中在其中一类 |
| sc | 只有两类,而且高度集中在一类 |
| dbscan | 没有进行聚类,只有一类 |
| optics | 分类过多,高度集中在一类 |
表2
因此,本文采用kmeans、hclust和birch三种聚类方法进行聚类。
由于本次聚类为非监督学习,并不知道各科研人员的实际类别,因此本文选用Silhouette、Calinski-Harabasz和Davies-Bouldin这三个指标来衡量聚类的紧密性和分离性。对kmeans、hclust、birch的分类效果进行评估,结果如表3所示:
| Silhouette | Calinski-Harabasz | Davies-Bouldin | |
|---|---|---|---|
| kmeans | 0.0703 | 5.2811 | 3.4326 |
| hclust | 0.0580 | 5.4526 | 3.6743 |
| birch | 0.0596 | 5.4919 | 3.6955 |
表3
经过上述分析,本文采用kmeans、hclust和birch三种聚类方法对科研人员进行分类,其中每一种聚类都将所有人员分为四类:王者、星耀、钻石、铂金。对每位科研人员,取出现次数最多的段位作为其最终段位;若其三次分类的结果互不相同,则取kmeans聚类的段位作为其最终段位。
将该模型进行保存,以便进行后续的预测
五、模型评估与优化
我们得到了两种参数很优秀的模型,Naïve Bayes (NB)和Extra Trees Classifier (ET)。下面对这两种模型进行评估。
1.Naive Bayes
(1)AUC
AUC曲线下的面积是一个用于评估分类模型性能的指标,值介于0和1之间。AUC接近1意味着模型在区分正负样本上做得非常好,即真正例率(TPR)高,假正例率(FPR)低,表明这个模型在这四个类别的预测上都表现出了很高的准确性。该模型的AUC曲线如图1所示。
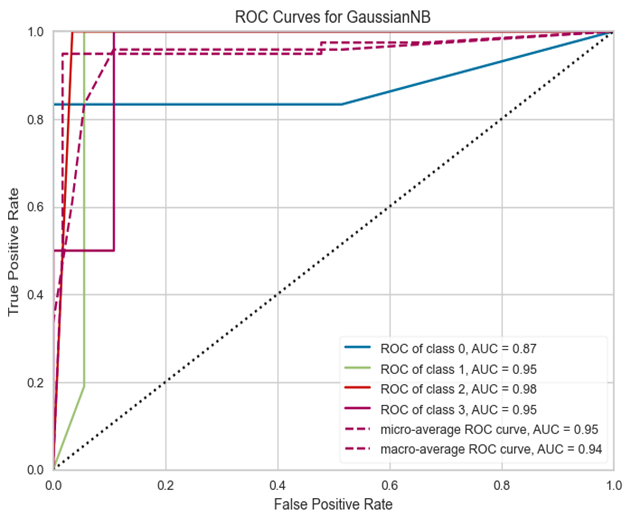
图1
可以看到,四个类的AUC曲线的面积都接近1,意味着该模型在四个类别上的表现都非常好。
(2)混淆矩阵
该模型的混淆矩阵如图2所示:
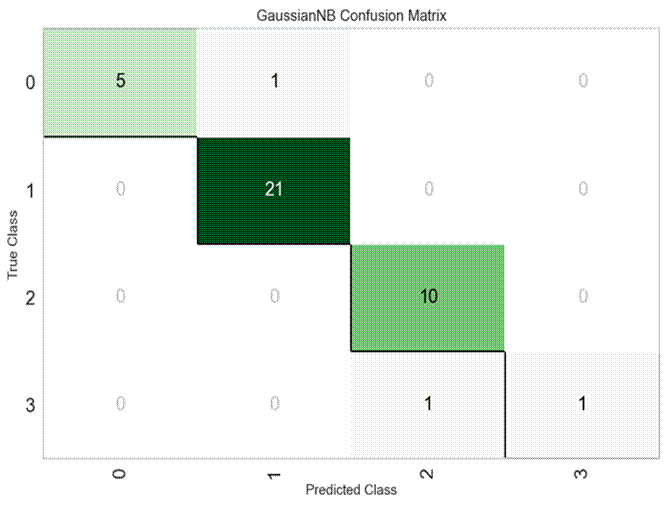
图2
在这个4x4的混淆矩阵中:
第一行表示所有实际为第一类的样本,其中,5个被正确地预测为第一类,1个被错误地预测为第二类,没有被错误地预测为第三类和第四类;
第二行表示所有实际为第二类的样本,其中,21个被正确地预测为第二类,没有被错误地预测为其他类别;
第三行表示所有实际为第三类的样本,其中,10个被正确地预测为第三类,没有被错误地预测为其他类别;
第四行表示所有实际为第四类的样本,其中,1个被正确地预测为第四类,1个被错误地预测为第三类,没有被错误地预测为第一类和第二类。
从混淆矩阵可以看出,绝大部分的预测都是正确的(主对角线上的值较大),只有极少数的预测是错误的(非对角线上的值较小),说明该模型的性能很好。
(3)学习曲线
该模型的学习曲线如图3所示:
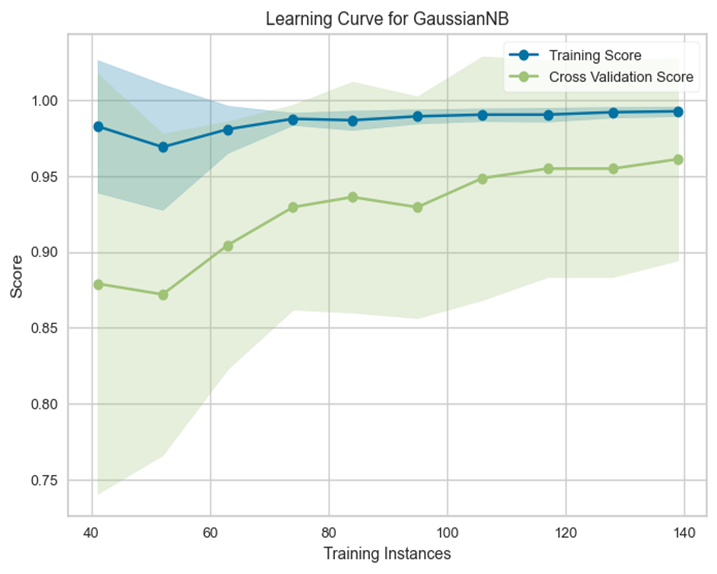
图3
从该模型的学习曲线中可以看出,训练分数和交叉验证分数都接近1,表明模型在训练集和验证集上的表现都很好。该模型的训练分数比交叉验证分数高,意味着模型对训练数据可能有过拟合,但是这种情况下的过拟合程度不高,因为交叉验证分数也很高。由此可以推测,这种情况的出现可能是因为训练数据较少。
(4)性能评估
图4为该模型的性能评估结果,其中precision是模型对每个类别的精确度,即预测为该类别的样本中真正为该类别的比例;recall是模型对每个类别的召回率,即真正的该类别的样本中被预测为该类别的比例;f1-score是精确度和召回率的调和平均值,可以被视为模型的综合性能指标;support是每个类别的真实样本数量。
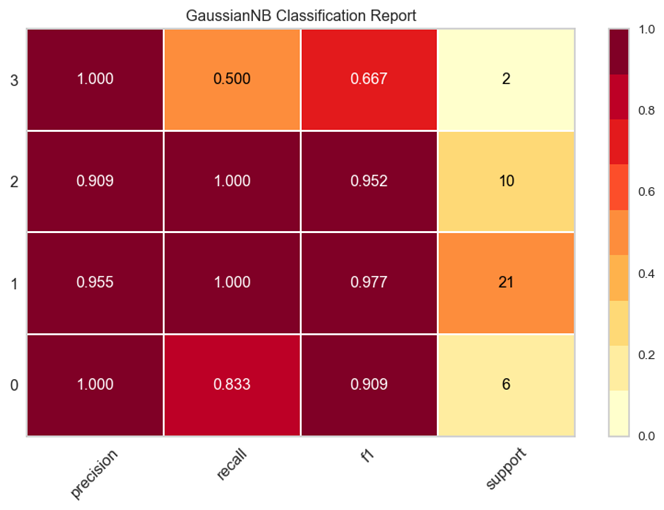
图4
由此可见,该模型所划分的cluster0、cluster1和cluster2性能好,cluster3的性能较差。
2.Extra Trees Classifier
(1)AUC
该模型的AUC曲线如图5所示。
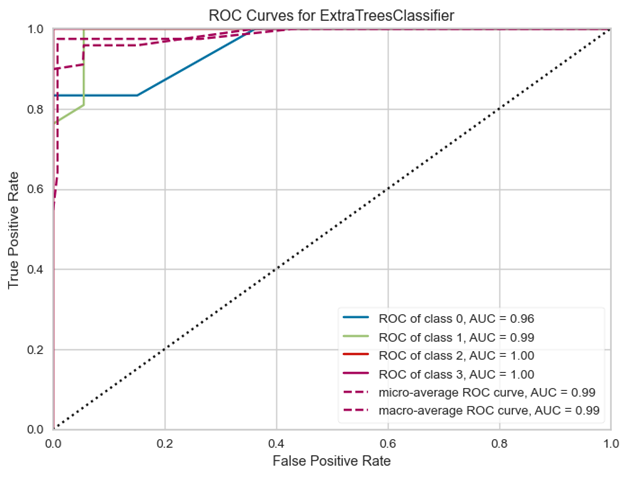
图5
可以看到,四个类的AUC曲线的面积都接近1,意味着该模型在四个类别上的表现都非常好。
(2)混淆矩阵
该模型的混淆矩阵如图6所示:
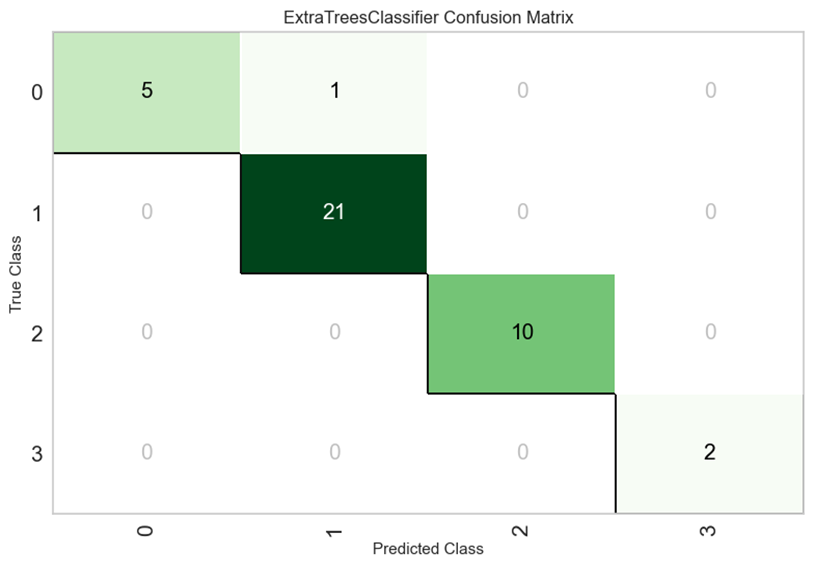
图6
从混淆矩阵可以看出,绝大部分的预测都是正确的(主对角线上的值较大),只有极少数的预测是错误的(非对角线上的值较小),说明该模型的性能很好。
(3)学习曲线
该模型的学习曲线如图7所示:
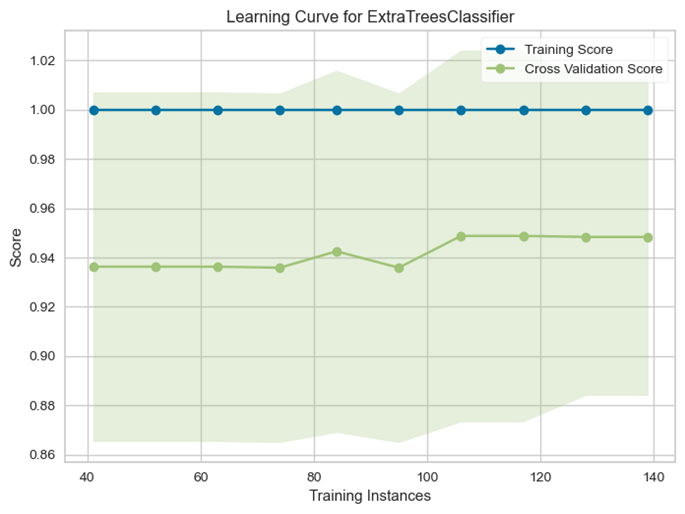
图7
该模型的学习曲线与Naïve Bayes的学习曲线类似,均有部分过拟合的现象出现,可能是因为训练数据较少。
(4)性能评估
图8为该模型的性能评估结果:
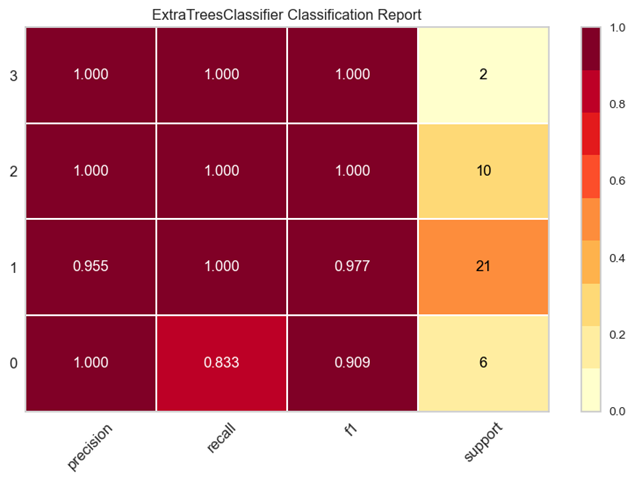
图8
由此可见,该模型的整体性能较好。
六、结果分析与应用
通过上述模型的建立与评估,可以得出,Naïve Bayes是更适合此数据的模型。同时,我们提供了对科研人员的类型进行预测的功能,也建立了UI以实现科研人员信息查找的功能。下面,本文将对这两种应用方式进行简要介绍。
①关于UI的使用说明
运行文件"UI.py"(界面如图9所示),选择相应的功能后,按提示输入所要查询的内容,点击查找便可得到符合条件的科研人员的信息,包括姓名、出生年份、教育经历、杰青/优青、职称、研究方向等。
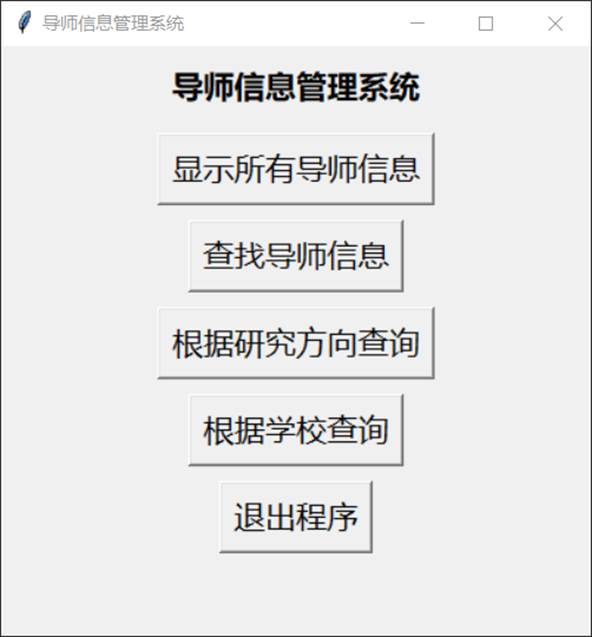
图9
②关于预测功能文件"prediction.ipynb"的说明
该文件在运行时会加载"ML.ipynb"中得到的最优模型,并利用该模型对已预处理好的需要预测类别的数据进行分类,并将输出的结果作为预测结果。随后,该程序会将预测结果添加到原始数据中,并将预测结果保存为新文件。
上述所提到的程序均会在附件中给出。
七、总结与展望
现如今,伴随着新一轮科技革命与产业变革持续深入,各学科研究领域日益扩大,朝着精细化、多元化的方向发展,此外,社会对学科交叉型人才的需求日趋明显,这使得大学本科生在申请导师时面临更多选择。我们不难在各大社会媒体中发现,高校中由于选择不适合自己的专业、导师而丧失学习兴趣的事例屡见不鲜,这足以引起社会的关注。当然,我们能够看到,众多互联网厂商和教育平台已经开始打造为大学生选择研究生导师、专业的平台,但普遍实用性不大,缺少系统性。作为一名大学生,我们更能了解同学们的需求,希望能打造一款数据全面,能同时满足同学们对导师专业、导师性格、导师能力、导师职称等全方面多维度的考量,真正做到操作简单,数据可信,实用价值高。当然,我们的模型仍然存在着许多问题。未来,我们将着手解决上述问题,使我们的模型能够真正运用到实际生活中去。
科研人才的管理和培养对于国家科研事业的发展至关重要,我们也结合分析的结果,提出了一些建议:
①加强基础科研人才培养:加大对基础科学研究的支持力度,提供更多的资金和资源,鼓励年轻人从事基础科研工作;建立并完善科研人员评价制度,注重对基础科学研究的认可和奖励,培养更多的杰出科学家。
②推进跨学科交叉培养:鼓励和支持不同学科领域之间的合作和交流,培养具有跨学科背景的科研人才;设立跨学科研究项目,并提供相应的奖励和支持,以激励科研人员积极参与跨学科研究。
③加强科研团队建设:提供更多对科研项目支持和优惠政策,吸引高水平的科研团队和人才加入,营造积极向上的科研氛围。
④建立科学合理的科研评价体系:注重绩效评估和成果转化,不仅要考虑科研成果的数量,还要关注科研质量、影响力和创新能力等方面的表现。
⑤加强国际交流与合作:鼓励科研人员参与国际学术交流和合作项目,提供更多的留学和出国交流机会;引进国际先进科研人才和管理经验,促进国内外科研人才的互动和合作,提升我国科研水平。
⑥加大科研人才培养投入:增加对科研人才培养的投入,提供更多的奖学金、科研项目资助和实习机会;建立科研人才培养基地和科研实践基地,提供科研人才培养的平台和机会。
八、参考文献
1 周志华.机器学习M.清华大学出版社,2016.
2 王凯, 王益华, & 李辉. (2012). 基于多项式朴素贝叶斯的中文情感分类研究.《计算机应用研究》,29(8),2932-2934.
3 Jain, A. K. , and R. C. Dubes . "Algorithms for clustering data." Technometrics32.2(1988):227-229.
4 司守奎,孙玺菁.数学建模算法与应用M.国防工业出版社,2022.