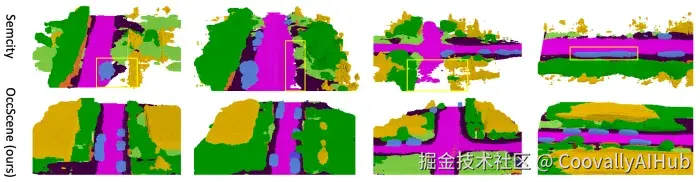
无需依赖真实标注,仅凭文字提示即可生成高质量3D场景
在自动驾驶、机器人导航等领域,3D场景的感知与生成一直是研究热点。然而,传统方法通常将这两个过程分离:生成模型仅仅作为数据增强工具,为下游感知任务提供合成数据。这种方法不仅灵活性有限,生成的场景也往往缺乏对感知任务有价值的细节。
近日,上海交通大学与宁波数字孪生研究院联合团队提出了一种名为OccScene 的创新范式,将细粒度3D感知与高质量场景生成统一在同一个框架中,实现了跨任务的互利共赢。
传统方法的三大挑战
现有3D场景生成方法面临三大核心问题:
- 灵活性有限: 依赖真实标注数据(如3D边界框、BEV地图)进行推理,标注成本高且难以生成多样化的边缘案例
- 约束不足: 使用区域级粗糙先验无法提供像素级细粒度语义和几何指导
- 目标不明确: 生成过程主观质量驱动,与感知任务需求脱节
OccScene的核心创新
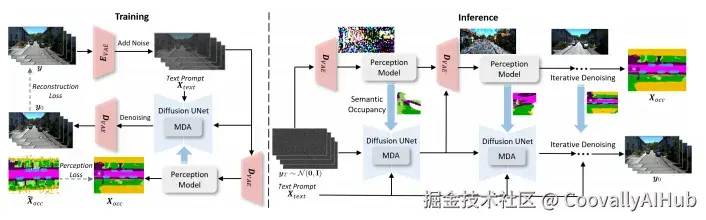
OccScene通过联合学习方案,将语义占据预测与文本驱动生成两个任务统一在单一扩散过程中,实现了真正的跨任务协作。
- 感知-生成联合扩散方案
OccScene框架同时训练生成扩散UNet和感知模型。输入图像经VAE编码器压缩后,分别送入扩散UNet去噪和VAE解码器生成噪声图像。感知模型以噪声图像为输入预测占据网格,作为额外条件约束扩散UNet。
训练过程采用两阶段策略:先冻结感知模型权重训练扩散UNet,再联合训练两者实现互利。损失函数结合了潜在扩散模型的重建损失和感知损失,通过√αₜ自适应调整不同噪声水平的监督强度。
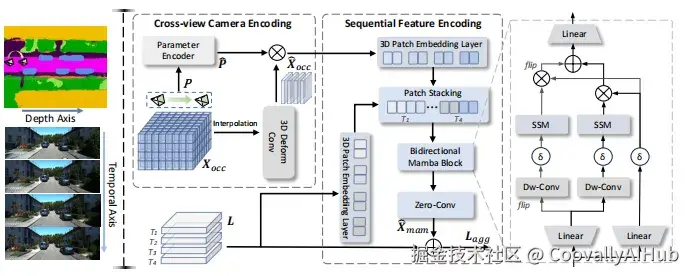
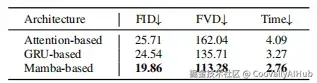
- Mamba-based双对齐模块
为将语义占据与扩散潜在特征对齐,团队提出了Mamba-based双对齐模块:
- 跨视角相机编码: 将相机参数与语义占据结合,实现相机轨迹感知
- 序列特征编码: 使用双向Mamba块沿深度维度处理语义占据特征,沿时间维度处理潜在特征
该模块通过线性复杂度操作符高效处理高维数据,确保跨视角生成一致性并提供细粒度几何语义指导。
- 跨任务互利学习机制
研究表明,深度学习网络在宽谷而非尖锐极小值处找到的解具有更好的泛化能力。OccScene的跨任务互利学习恰好促进了这类高质量解的发现。

卓越的实验表现
- 生成质量评估
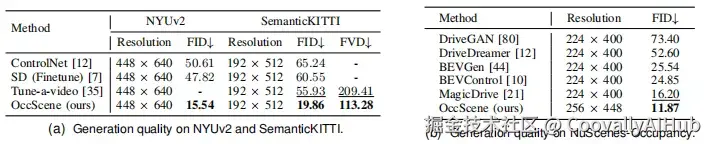
在NYUv2、SemanticKITTI和NuScenes-Occupancy等多个数据集上的实验表明,OccScene在生成质量上显著优于现有方法:
在NuScenes-Occupancy上达到11.87 FID,超越MagicDrive的16.20
在SemanticKITTI上实现113.28 FVD,优于Tune-a-video的209.41
3D语义场景生成的FID相比SemCity提升30.66%
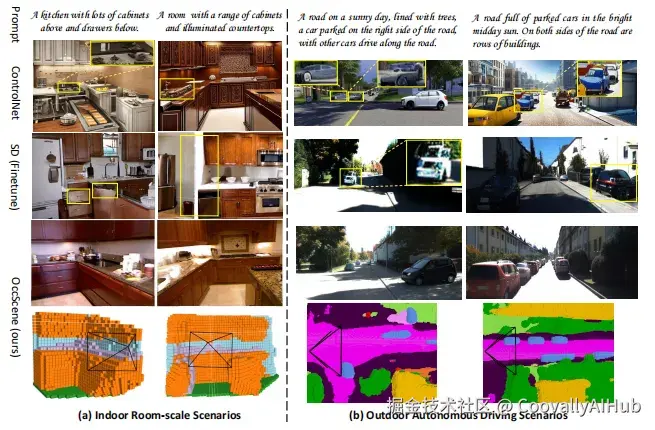

- 感知性能提升
OccScene作为即插即用框架,显著提升了多种语义占据预测模型的性能:
在NYUv2上,将MonoScene的mIoU提升2.84,NDC-Scene提升3.09
在SemanticKITTI上,将MonoScene的mIoU提升3.90,TPVFormer提升4.38
在NuScenes-Occupancy上,将MonoScene的mIoU提升4.10
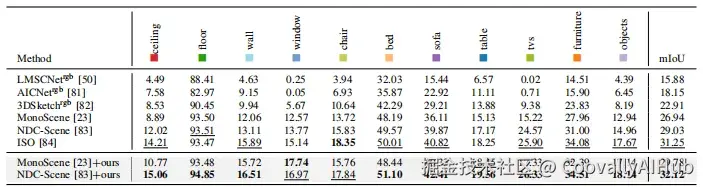
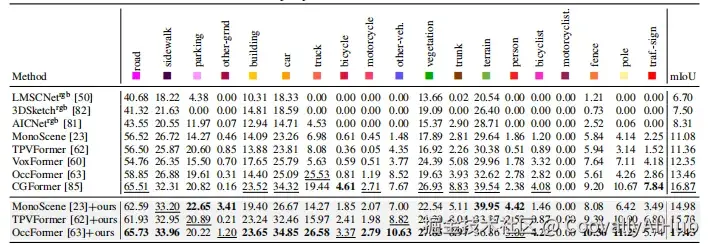
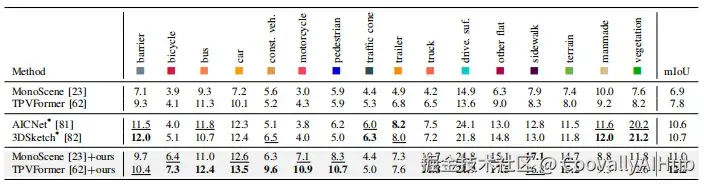
- 消融实验验证
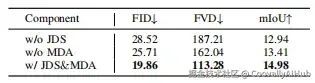
团队通过系统消融研究验证了各组件贡献:
联合扩散方案(JDS)提升生成保真度并增强感知性能2.04 mIoU
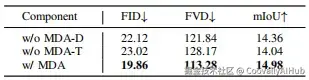
Mamba-based双对齐(MDA)在线性复杂度和生成质量上均优于基于注意力或GRU的设计
沿深度和时间维度同时应用MDA模块带来最大性能增益
实际应用价值
OccScene仅凭文本提示就能同步生成逼真的场景图像/视频及其对应语义占据,为自动驾驶和机器人领域带来了实际价值:
- 无需标注数据即可生成多样化训练样本
- 增强感知模型在复杂场景下的理解能力
- 支持一致性视频生成 与编辑,适应动态环境

未来展望
OccScene为3D场景理解与生成开辟了新路径。其核心思想------通过跨任务互利学习实现共赢------可望扩展到更多视觉任务中。随着扩散模型和状态空间模型的不断发展,感知与生成的融合将成为未来三维视觉领域的重要方向。
该研究已在TPAMI提交,相关代码和模型即将开源,值得学术界和工业界共同关注。