当大促的时候,flink 任务在处理数据时由于数据倾斜或者数据量突然增大导致的checkpoint迟迟过不去,在这时候我们临时去改代码可能来不及,或者不允许,因为改代码可能会导致状态丢失。
这时候去配置【Tolerable Failed Checkpoints】,宽松配置,提高作业稳定性,配置成一个比较大的值比如:1百万。如下:
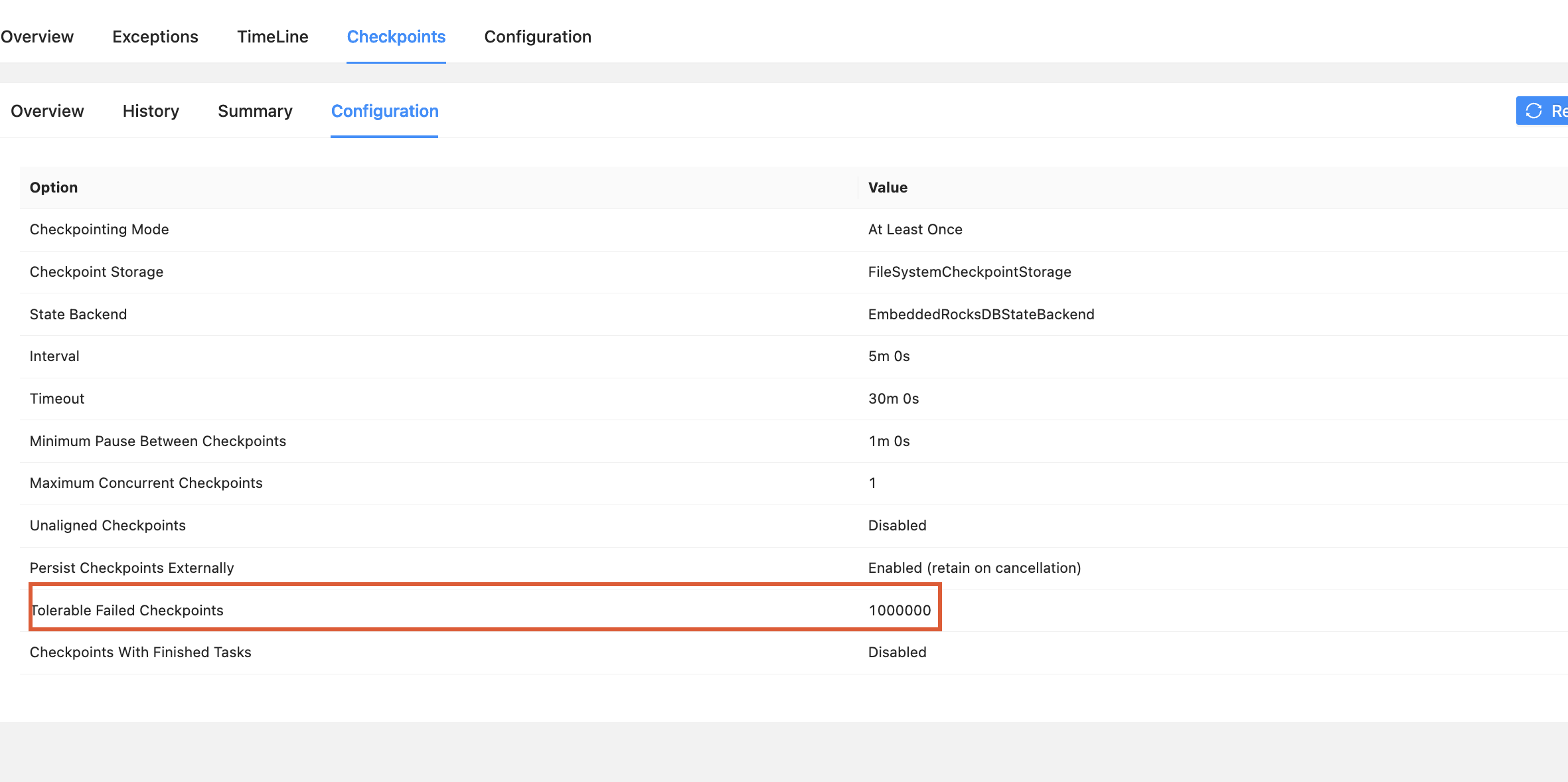
execution.checkpointing.tolerable-failed-checkpoints: 100000
改完该参数以后,前几个checkpoint任然可能过不去,但等失败几个批次以后慢慢会过去。因为如果改参数配置成0,每次checkpoint失败flink都会重新从上一个成功的checkpoint 的offset重新消费,进而导致恶性循环,迟迟过不去;如果配置比较大,虽然当前checkpoint失败,但是截止当前的offset继续消费,而不会重新从上一个成功的checkpoint 的offset重新消费。这样就可以慢慢缓冲过去。
该参数是Flink容错机制中的一个关键配置参数,它定义了允许连续失败的检查点的最大数量。当连续失败的检查点数量超过此阈值时,Flink作业将自动失败并停止运行。是Flink容错机制的"安全阀",它平衡了作业稳定性与数据一致性之间的权衡。该参数不是用来解决检查点失败问题的工具,而是用来防止问题恶化的防护机制。
切记这只能作为临时的解决方案,然后再去排查导致检查点失败的根本原因,当大促过去以后,上线新的方案,备任务起来并行运行一段时间,然后平滑的迁移到新的方案。然后重新配置改参数,一般我们生产改参数配置比较小(0或小于5的数字),严格配置,快速失败以保护数据一致性。
execution.checkpointing.tolerable-failed-checkpoints: 0