- Kafka文件的存储机制
主题 topic - 分区 partition - 分段 segment
每一段有三个文件:
① .index 索引文件
② .log 数据文件
③ .timeindex 时间索引文件
- 分段的意义
① 删除无用文件更加方便,提高磁盘的利用率
② 查找数据便捷
- 数据清理机制
3.1 根据消息的保留时间,当Kafka中保存的时间超过了指定的时间,就会触发清理过程。

3.2 根据topic存储数据的大小,当topic所占的日志文件大小大于一定的阈值(默认 1 GB),则开始删除最久的消息,需要手动开启。

- Kafka 高性能设计
4.1 消息分区: 不受单台服务器的限制,可以不受限的处理更多的数据
4.2 顺序读写: 磁盘顺序读写,提升读写效率(相对于数据随机存放、随机读写而言)
4.3 页缓存(Linux系统): 把磁盘中的数据缓存到内存中,把对磁盘的访问改变为对内存的访问
4.4 零拷贝: 减少上下文切换机数据copy
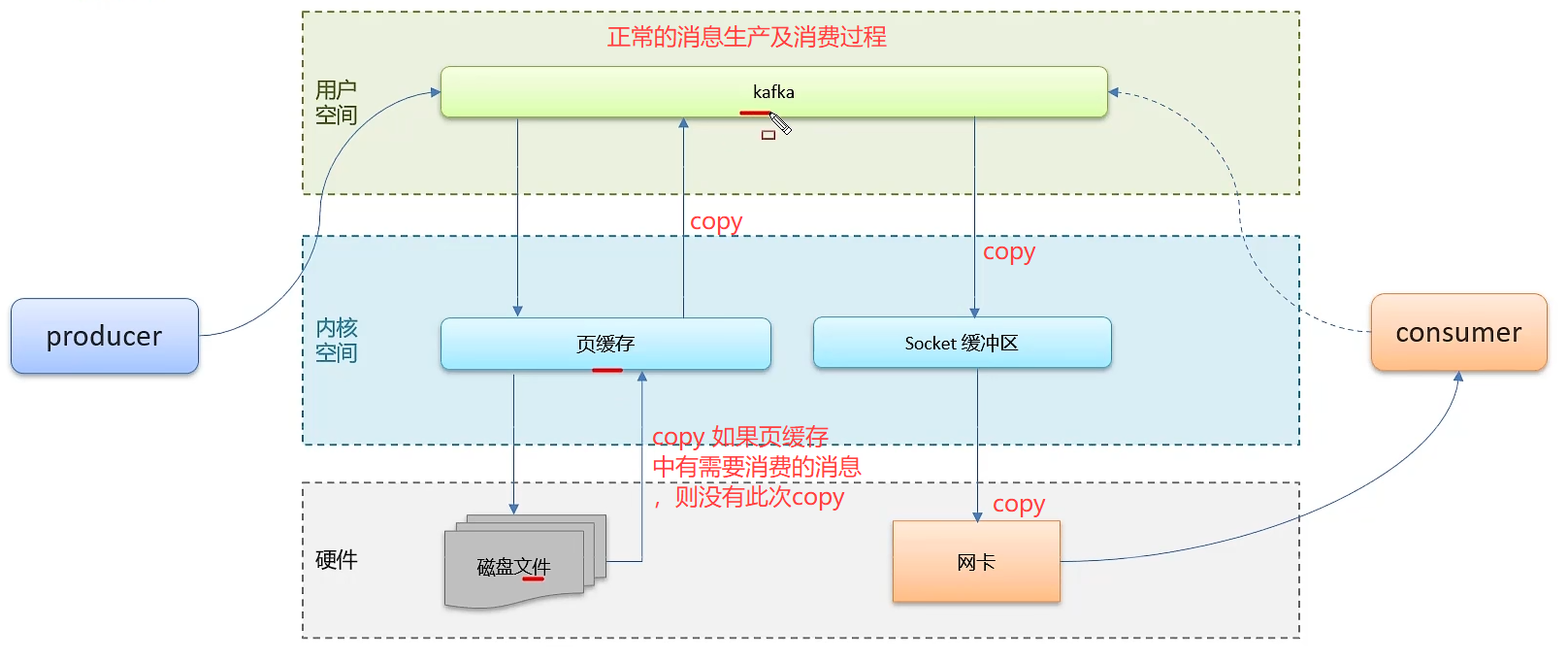
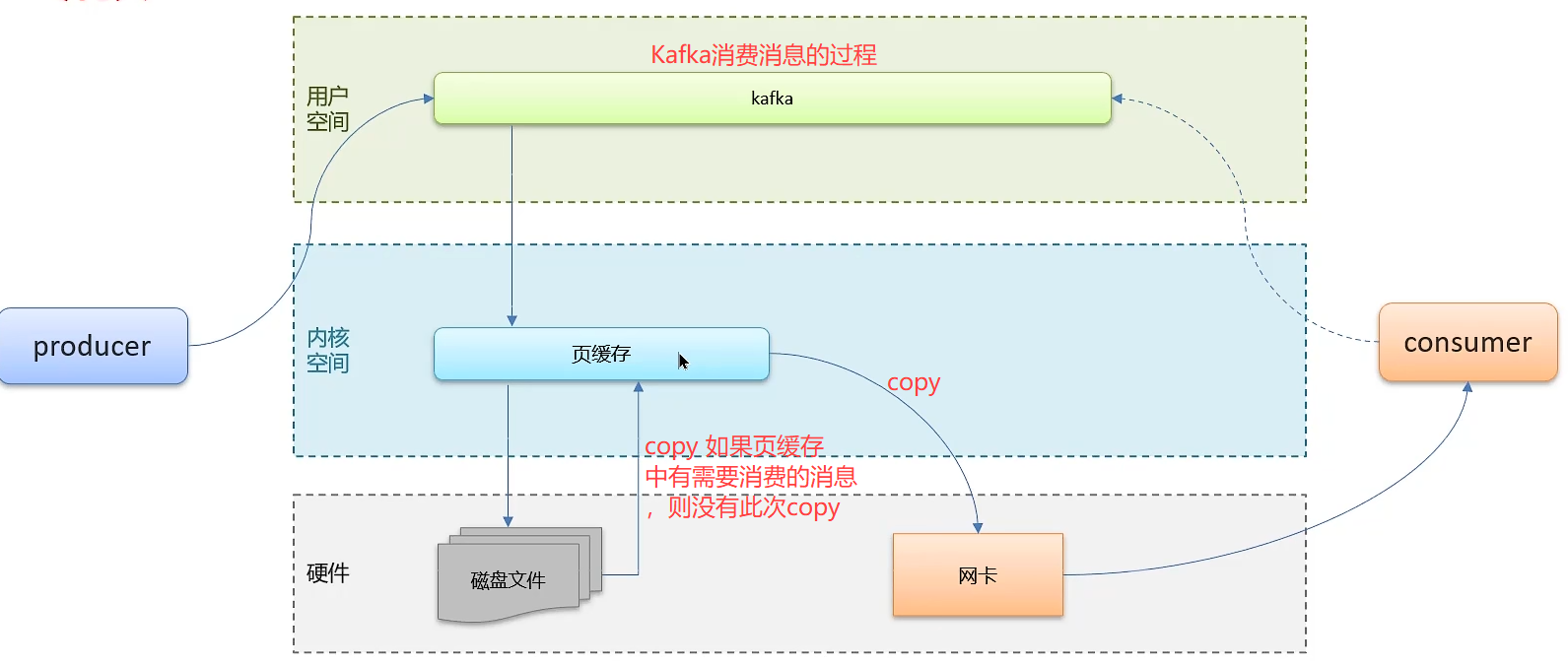
4.5 消息压缩: 减少磁盘IO和网络IO,但是压缩过程耗费CPU
4.6 分批法送: 将消息打包批量发送,减少网络开销