"点积"(Dot Product)是大模型,尤其是 Transformer 架构 中一个非常核心的数学操作。它在 注意力机制(Attention) 中起着关键作用。
【【Transformer】最强动画讲解!目前B站最全最详细的Transformer教程,2025最新版!从理论到实战,通俗易懂解释原理,草履虫都学的会!】https://www.bilibili.com/video/BV1fGeAz6Eie?p=6&vd_source=e14fbfa32a7c9167af15da4f1666253a
下面我们从基础概念到实际应用,一步步帮你深入理解"点积"在大模型中的意义。
一、什么是点积?(数学基础)
1. 定义
两个向量的点积(也叫内积)定义为:
2. 几何意义
- 点积衡量两个向量的相似度。
- 公式:a⋅b=∣a∣∣b∣cosθ
- θ 是两向量夹角。
- 当方向越接近(夹角小),点积越大;
- 方向相反时,点积为负。
✅ 所以:点积越大 → 两个向量越相似
二、点积在大模型中的作用:注意力机制的核心
在 Transformer 的 Self-Attention 中,点积用于计算一个词对其他词的"关注度"。
1. Attention 中的 Q, K, V
- Query (Q):当前词"想查询什么信息"
- Key (K):其他词"能提供什么信息"
- Value (V):其他词的"实际内容"
注意力得分 = Query 和 Key 的相似度 → 用点积计算!
2. 点积注意力公式
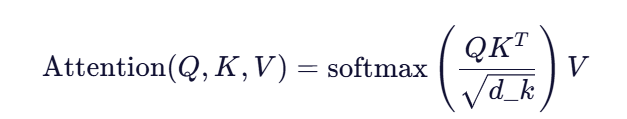
其中:
就是批量点积:每个 Query 向量与所有 Key 向量做点积。
- d_k 是 Key 向量的维度,用于缩放(防止 softmax 梯度消失)。
- softmax 将点积结果归一化为概率分布(即"注意力权重")。
- 最后用权重加权 Value 得到输出。
三、举个例子:理解"点积如何决定注意力"
假设我们有句子:"I love AI and I love NLP"
我们想计算第一个 "love" 对其他词的关注度。
| 词 | Key 向量(简化) |
|---|---|
| I | 1, 0 |
| love | 0, 1 |
| AI | 0.8, 0.2 |
| ... | ... |
当前词 "love" 的 Query 向量:0, 1
计算点积:
- love⋅I=\0,1⋅\1,0=0love⋅I=\0,1⋅\1,0=0
- love⋅love=\0,1⋅\0,1=1love⋅love=\0,1⋅\0,1=1
- love⋅AI=\0,1⋅\0.8,0.2=0.2love⋅AI=\0,1⋅\0.8,0.2=0.2
→ 模型发现 "love" 和自己最相似,其次是 "AI",几乎不关注 "I"。
经过 softmax 后,会把"love"和"AI"分配较高的注意力权重。
四、为什么用点积而不是其他相似度?
| 方法 | 优缺点 |
|---|---|
| 点积 | 快速、可并行、适合 GPU 计算;但数值随维度增大而变大 → 需要缩放 d_kd_k |
| 余弦相似度 | 已归一化,只看方向;但计算更复杂 |
| 加性注意力 | 更灵活,但参数多、慢 |
Transformer 选择缩放点积注意力 (Scaled Dot-Product Attention)是因为:高效 + 可扩展