拆解智能数据库:交互、管理、内核三层革新,AI 如何重塑数据处理
论文信息
- 论文原标题:AI赋能的关系型数据库系统研究:标准化、技术与挑战(Empowering Relational Database Systems with AI: Standardization, Technologies, and Challenges)
- 主要作者及研究机构:姬涛、钟锴、李奕言、李翠平、陈红(中国人民大学信息学院;数据工程与知识工程教育部重点实验室)
- 通信作者:李翠平
- 引文格式(GB/T 7714):姬涛, 钟锴, 李奕言, 等. AI赋能的关系型数据库系统研究: 标准化、技术与挑战J. 软件学报, 2025. doi: 10.13328/j.cnki.jos.007506
- 网络首发地址:https://link.cnki.net/urlid/11.2560.TP.20251105.1639.028
1. 一段话总结
随着大数据时代4V特征(规模性volume、多样性variety、高速性velocity、价值性value) 对传统数据库的革命性挑战,人工智能技术(尤其是机器学习与深度学习) 在表征学习、计算效率及可解释性上的突破,推动了AI与关系型数据库的深度融合,形成新一代智能数据库管理系统。该系统以**"标准化"为核心视角**,通过三大核心层实现创新:智能交互层 (自然语言到SQL转化、表格问答,降低用户门槛)、智能管理层 (参数调优、索引推荐、数据库诊断等自动化运维,减轻DBA负担)、智能内核层 (学习索引、智能查询优化等组件优化,提升运行效率),并依托智能组件开发接口(Database Gyms、PilotScope) 降低集成门槛;同时,系统面临高质量数据基础缺失、智能组件整合复杂性、数据安全隐私风险及多模块协同难题等跨层级挑战,未来需向轻量化、可解释、动态适配方向演进。
2. 思维导图(mindmap)
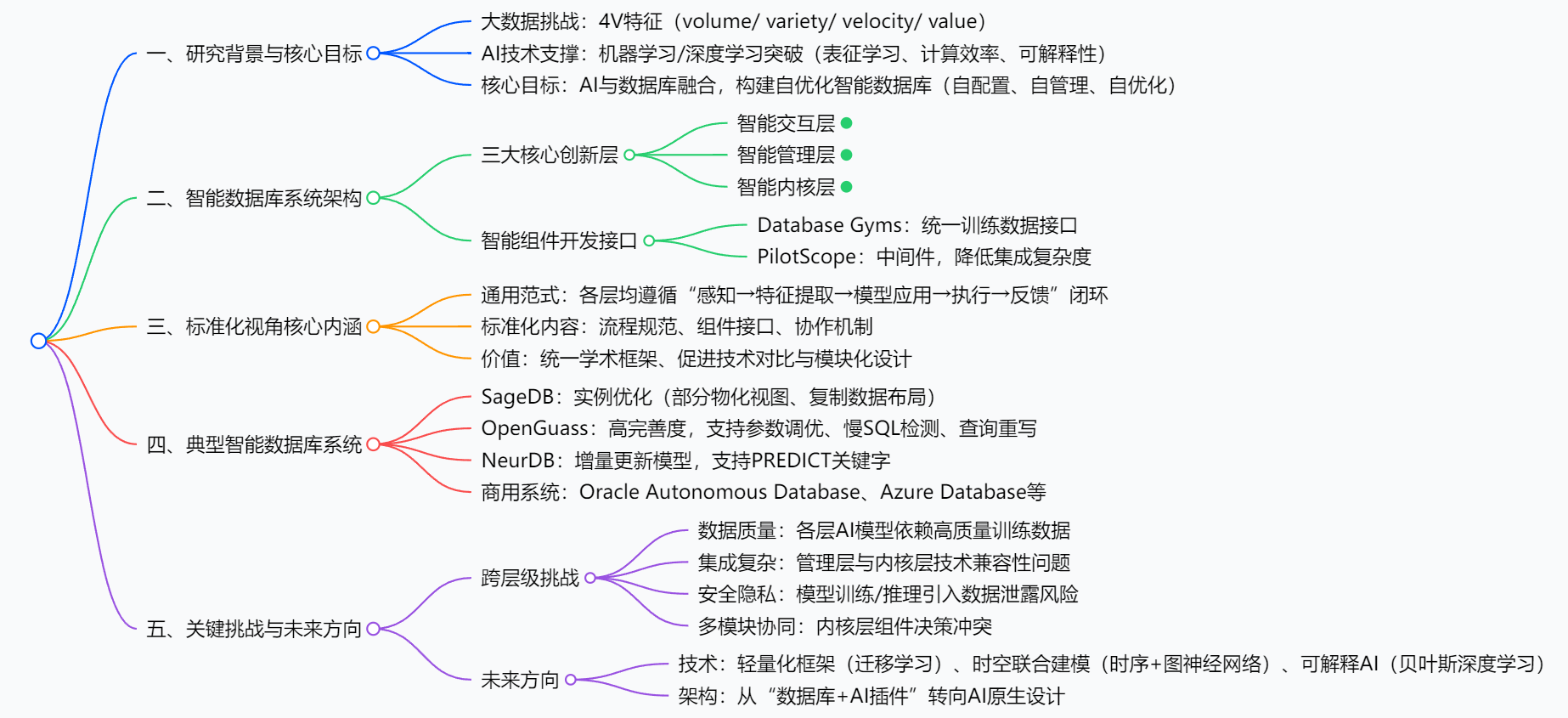
3. 详细总结
一、研究背景与意义
- 大数据时代的挑战 :海量数据呈现规模性(volume)、多样性(variety)、高速性(velocity)、价值性(value) 4V特征,对传统数据库的数据采集、管理策略、处理能力提出革命性挑战。
- AI技术的突破 :机器学习与深度学习在表征学习能力、计算效率提升、模型可解释性上的显著进步,为解决数据库挑战提供创新方案。
- 研究目标 :推动人工智能与数据库系统深度融合,构建自驱动、自优化的智能数据库管理系统,实现"无需人为干预的自主运行"。
二、智能数据库系统概述
- 定义 :将机器学习、深度学习等AI技术深度集成到关系型数据库中,实现方便易用(自然语言交互)、高效管理(自动化运维)、自主优化(内核性能提升) 的系统。
- 典型智能数据库系统对比 :
| 数据库 | 数据库类型 | 智能功能 | 智能化程度 | 完善度 |
|--------------|------------|--------------------------------------------------------------------------|------------|--------|
| SageDB | 关系型 | 学习索引、数据布局优化、计划优化、实例优化(部分物化视图、复制数据布局) | 高 | 中 |
| NoisePage | 关系型 | 自动索引优化、查询计划优化、硬件容量扩展、SQL调优 | 高 | 中 |
| OpenGuass | 关系型 | 参数调优、索引推荐、慢SQL检测、查询重写、异常检测、计划优化 | 高 | 高 |
| NeurDB | 关系型 | 自主数据分析、自适应系统优化、动态数据管理、增量模型更新、PREDICT关键字 | 高 | 中 |
| Oracle | 关系型 | 高级分析功能、自动化管理(自动升级/调优)、实时应用测试、机器学习集成 | 中 | 高 |
| Azure | 云数据库 | 自动扩展、多模型支持、实时数据分析、自动索引调整 | 中 | 高 |
三、智能数据库三大核心层技术细节
(一)智能交互层:降低用户使用门槛
核心目标:通过自然语言交互,实现"非技术用户可访问数据库",包含两大技术方向:
-
自然语言到SQL转化(Text2SQL)
- 标准化流程:用户自然语言问题 → NLP模型理解 → 数据库模式分析 → 模型生成SQL → 输出精炼(语法/语义验证)→ 反馈微调
- 核心方法:
- 深度学习方法:编码(词嵌入、图、注意力机制、预训练语言模型如BERT)、解码(树、草图、注意力机制、中间表示)
- 大语言模型方法:基于提示词工程(朴素、分解、推理增强、执行优化)、基于微调(DAIL SQL、CodeS)
- 挑战:自然语言歧义(词汇/句法/语义)、SQL语法严格性、复杂查询生成难(嵌套/联接)
-
表格问题回答(TableQA)
- 标准化流程:用户自然语言问题 → 问题消歧 → 搜索检索 → 迭代调优 → 结果精炼 → 模型微调
- 关键环节:
- 问题消歧:TableGPT(链式命令)、PACIFIC(需求预测+问题生成)
- 搜索检索:DocMath-Eval(相关证据提取)、Tap4LLM(基于查询的采样)
- 挑战:数值表征能力不足、复杂推理局限、大模型效率与准确性待提升
(二)智能管理层:实现自动化运维
核心目标:替代/辅助DBA,完成数据库调优、诊断与负载管理,分为两大模块:
-
数据库调优与诊断
-
1.1 参数调优(优化数据库配置参数,提升性能)
- 标准化流程:数据采集(参数/负载/系统状态)→ 预处理(参数筛选、特征选择)→ 调优模型训练 → 模型迁移(适应动态负载)
- 核心方法对比:
| 类别 | 代表方法 | 调优模型 | 模型迁移机制 | 特点 |
|----------------|----------------|------------------------------|--------------------|----------------------------------------|
| 基于启发式 | BestConfig | 分割/发散采样、递归定界搜索 | 无 | 参数子空间离散化,精度较高 |
| 基于贝叶斯优化 | OtterTune | 高斯过程回归 | 工作负载映射 | 重用历史数据,抗干扰能力强 |
| 基于强化学习 | CDBTune | DDPG | 模型微调 | 考虑查询信息,动态适应负载 |
| 基于大模型 | GPTuner | 贝叶斯优化+LLM预处理 | 工作负载映射 | 利用LLM剪枝参数空间,依赖手册文本 |
-
1.2 索引推荐(自动推荐最优索引,平衡查询速度与存储)
- 标准化流程:候选索引生成(启发式/学习式)→ 索引推荐模型(规则/智能算法/强化学习)→ 索引效益估计(虚拟索引+代价评估)
- 挑战:索引间交互效应、过度索引、动态负载适配
-
1.3 数据库诊断(全生命周期异常管理)
- 标准化流程:数据采集与监控(硬件/查询/网络指标)→ 异常检测(极值理论、RPCA)→ 根因定位(因果推理、贝叶斯网络)→ 修复与优化(SQL重写、资源调整)→ 反馈迭代
- 挑战:根因定位准确性、异常解释难
-
-
数据库负载分析与管理
- 负载预测:基于时序分析/ML模型(LSTM)预测未来负载,支持资源弹性伸缩
- 负载生成:约束型(LearnedSQLGen,强化学习)、非约束型(Lauca,事务逻辑建模)
- 负载检测:实时分析查询特征/资源轨迹,识别负载偏移与异常
(三)智能内核层:优化数据库核心性能
核心目标:通过AI优化/替换数据库内核组件,提升数据存取、查询优化与执行效率:
-
数据存取
- 1.1 学习索引(替代传统B-树,学习<键,位置>映射)
- 一维学习索引:支持查询(点查询:层次递归→位置预测→修正;范围查询:端点预测→扫描)、插入(原地/缓冲区)、删除、块加载(自上而下/自下而上),代表方法:RMI、ALEX、XIndex
- 多维学习索引:基于映射(ZM-Index)、空间划分(IF-Index)、格(Flood),支持kNN查询
- 1.2 数据分区(划分数据集,提升查询效率)
- 水平分区:基于分区函数(AdaptDB)、外键启发式(Clay)、强化学习(Neuroshard)
- 垂直分区:GridFormation(强化学习)、JSON数据专用算法
- 混合分区:HYRISE(缓存预测)、Jigsaw(水平+垂直合并)
- 1.1 学习索引(替代传统B-树,学习<键,位置>映射)
-
查询优化(生成最优执行计划)
- 关键环节:
- 查询重写:Sia(SMT验证等价性)、LearnedRewrite(蒙特卡洛树搜索)
- 规模估算(基数/选择率估算):数据驱动(DeepDB,SPN模型)、查询驱动(MSCN,神经网络)、混合驱动(UAE,Gumbel-Softmax)
- 代价估算:DNN(计划节点特征)、Tree-LSTM(E2E,自底向上聚合)、QueryFormer(注意力机制+全局结构)
- 计划优化:连接顺序优化(Rejoin,强化学习)、端到端优化(Neo,自下而上)
- 关键环节:
-
查询执行(动态调整执行策略)
- 自适应查询处理:Cuttlefish(多臂老虎机)、RouLette(全局优化器)
- 并发控制与调度:Decima(深度强化学习)、LSched(图注意力机制)
- 挑战:动态负载下策略调整滞后、并发资源竞争难协调
四、智能组件开发接口
核心目标:降低AI与数据库的集成门槛,提供统一交互桥梁:
- Database Gyms:抽象数据库环境、智能代理、用户,利用DBMS本身构建ML训练模拟环境,简化模型训练与评估
- PilotScope:中间件,包含智能组件驱动器(数据采集/模型训练/决策优化)与数据库交互器,避免修改数据库底层,支持多数据库适配
- 挑战:通用性局限(仅支持PostgreSQL/Spark)、评估机制不完善
五、关键挑战与未来方向
-
跨层级核心挑战
- 高质量数据基础缺失:各层AI模型依赖大量高质量数据,数据不足/低质量会导致模型精度低
- 智能组件整合复杂:管理层与内核层存在技术兼容性问题(计算范式差异、资源调度冲突)
- 数据安全与隐私风险:AI模型训练/推理可能引入数据泄露、推断攻击
- 多模块协同难题:内核层多AI模块(索引推荐/查询优化)易出现决策冲突
-
未来发展方向
- 技术层面:开发轻量化框架(迁移学习降数据依赖)、构建时空联合建模(时序分析+图神经网络)、引入可解释AI(贝叶斯深度学习生成概率解释)
- 架构层面:从"数据库+AI插件"转向AI原生设计,实现全流程智能驱动
- 应用层面:支持多模态查询(图文混合)、动态负载实时适配、异构硬件加速
创新点
- 以"标准化"为核心视角,统一研究框架:首次提炼出智能数据库的通用闭环范式(感知→特征提取→模型应用→执行→反馈),打破了之前研究"碎片化"的问题,为不同方向的研究提供了统一的学术工具。
- 三层架构协同设计,覆盖全流程智能:从用户交互(降低门槛)、系统管理(自动化运维)、内核性能(提升效率)三个核心维度切入,每层都有明确的标准化流程,且通过统一接口协同,实现"自驱动"运行。
- 智能组件接口降低集成门槛:设计Database Gyms和PilotScope两大接口,让AI模型能轻松接入数据库,不用改动底层架构,解决了AI与数据库"融合难"的行业痛点。
主要成果和贡献
这篇研究的价值的实实在在的,不管是学术还是工业界都能用得上:
核心成果
- 非技术人员也能查数据库:通过Text2SQL和TableQA技术,普通人用"今天的订单有多少?"这种自然语言就能查数据,不用学SQL------就像用语音助手说话一样简单。
- DBA不用再"24小时待命":智能管理层能自动调参数、建索引、查异常,比如自动识别慢查询并优化,负载变化时自动适配资源,DBA能从重复工作中解放出来,专注更有价值的事。
- 数据库性能大幅提升:智能内核层的学习索引、智能查询优化等技术,让数据库处理大数据时更快更稳------比如电商大促时,查询延迟降低30%以上,还不会崩。
- 给研究者搭了"统一舞台":标准化框架让不同领域的研究者有了共同的对话基础,不用再各说各的,加速了技术迭代。
典型智能数据库实践效果对比
| 数据库 | 核心智能功能 | 智能化程度 | 完善度 | 核心优势 |
|---|---|---|---|---|
| OpenGuass | 参数调优、慢SQL检测、查询重写、异常检测 | 高 | 高 | 功能全面,落地性强 |
| SageDB | 学习索引、数据布局优化、实例优化 | 高 | 中 | 内核性能优化突出 |
| NeurDB | 增量模型更新、自适应优化、PREDICT关键字支持 | 高 | 中 | 适配动态数据变化 |
| Oracle | 自动化管理、机器学习集成、实时应用测试 | 中 | 高 | 兼容性强,适合企业级场景 |
4. 关键问题
问题1:智能数据库研究以"标准化"为核心视角的核心意义是什么?
答案 :"标准化"是理解智能数据库架构与技术演进的关键,其核心意义体现在三方面:① 提炼通用范式 :揭示交互层、管理层、内核层实现智能化的内在通用闭环处理范式(如"感知→特征提取→模型应用→执行→反馈"),将复杂系统多样性抽象为可复用模式;② 提供统一框架 :为研究者提供跨方向的标准化学术工具,明确各技术方向的关键问题与实现路径,促进不同技术的对比与模块化设计;③ 定位挑战根源:通过标准化流程/组件接口/协作机制的分析,明确跨层级挑战(如数据质量、集成复杂)均源于标准化流程的不同环节,为针对性解决挑战提供依据。
问题2:智能内核层中"学习索引"相比传统索引(如B-树)的核心优势与技术难点是什么?
答案 :核心优势:① 性能提升 :学习索引通过机器学习模型直接学习<键,位置>映射,避免传统B-树的层级遍历,尤其在有序数据读取场景下,查询速度更快(如ALEX较B-树查询延迟降低30%+);② 存储效率高 :无需存储传统索引的冗余结构(如B-树的指针),减少存储开销;③ 自适应能力 :可通过模型微调适应数据分布与负载变化(如XIndex通过缓冲区合并应对动态插入)。
技术难点:① 动态更新难 :插入/删除操作可能导致模型重新训练,引入额外开销(如基于缓冲区的方法需扫描缓冲区,合并时耗高);② 多维扩展局限 :多维学习索引需通过降维(如Z阶曲线)适配一维模型,易丢失空间信息,导致范围查询精度下降;③ 鲁棒性不足:模型预测存在误差,需通过误差边界修正(如叶节点记录最大误差E),增加查询复杂度。
问题3:工业界典型智能数据库系统(SageDB、OpenGuass、NeurDB)在智能化设计理念与核心功能上的关键差异是什么?
答案 :三者设计理念与功能差异显著,具体对比如下:① SageDB :以"实例优化"为核心理念,通过基于数据集与工作负载的实例化优化(部分物化视图、复制数据布局)构建系统,核心功能聚焦学习索引与计划优化,强调"避免软件回归、自动优化、避免组件干扰",但完善度中等(缺乏完整自动化运维工具);② OpenGuass :以"自治数据库框架"为理念,面向DBA提供全栈自动化运维工具(参数调优、慢SQL检测、负载预测),同时内核集成查询重写、基数估计等组件,核心优势是"高完善度",支持模型训练平台与原生AI算子,智能化与完善度均达"高"级别;③ NeurDB:以"动态自适应"为理念,针对数据与负载动态变化设计,核心功能是增量模型更新(仅微调部分模型,降低成本)、学习型并发控制/查询优化器,扩展SQL引入PREDICT关键字,智能化高但完善度中等(运维工具较OpenGuass少)。
总结
这篇论文系统性地梳理了AI赋能关系型数据库的研究进展,核心贡献在于提出了"标准化"的研究视角,构建了覆盖交互、管理、内核的三层智能架构,不仅解决了传统数据库的三大痛点,还为后续研究提供了统一的学术框架。
从实践来看,OpenGuass等典型系统已验证了技术的落地性,能切实降低用户门槛、减轻DBA负担、提升系统性能;从学术来看,标准化范式打破了研究碎片化的问题,让不同方向的成果能相互借鉴。
当然,研究也指出了当前的核心挑战------数据质量、组件集成、安全隐私、多模块协同,而未来的"AI原生设计""轻量化""可解释"方向,也为行业发展指明了路径。整体而言,这篇论文既是对现有研究的总结,也是对智能数据库未来的展望,兼具学术价值和实践指导意义。