HA高可用集群的架构,再啰嗦一遍:
Messaging Layer(消息层,也叫基础架构层)
heartbeat,corosync,cman,keepalived:这些软件都提供了消息层的功能,有些是专用于实现Messaging Layer功能的,如corosync,cman,有的是将Messaging Layer作为一个子功能模块,如heartbeat。
CRM(集群资源管理)
haresources,crm,pacemaker,rgmanager:这里分两类,haresources和crm是heartbeat的集群资源配置接口,也就是一个资源配置文件,我的理解是heartbeat实现程序上或是功能上的资源管理,但是定义资源,即资源的配置是通过配置文件来实现的,haresources是heartbeat v1版的资源配置文件,就是一个单纯的文本文件,在其中按照资源定义的语法定义各种资源以及约束等;而crm是heartbeat v2版的资源配置接口,这时的资源配置依然是通过一个配置文件来实现,只不过这个文件是xml格式的,如果直接编辑这个xml文件,相对比较困难,所以heartbeat v2提供了crm这个子模块,可以使用单独的工具,如hb_gui,连接crm从而达到间接配置xml文件的目的。所以haresources和crm只是集群资源的配置,具体集群资源管理的功能,还是由heartbeat实现的。而pacemaker和rgmanager是独立的软件,它们即实现程序功能上的资源管理,也实现资源配置的管理。
LRM(本地资源管理)
RA(资源代理)
heartbeat legacy,lsb,ocf,stonith
资源的类型:
primitive,group,clone,master/slave
约束:
location,order,colocation
heartbeat v2版本的资源管理,既可以使用v1版本的haresources,也可以使用crm,要使用crm,需要在heartbeat的配置文件ha.cf中增加:crm on 这个配置项,此时heartbeat会启动一个crmd子进程(进程名mgmtd子进程),监听在5560/tcp端口,接受如hb_gui等配置工具的连接,修改xml资源配置文件。
那么,heartbeat v1和v2版的本质区别在哪里呢?对于v1版,配置好集群资源,即haresources后,需要手工同步,即配置文件要拷贝到集群中的每一个节点上;对于v2版,每个节点运行的crmd进程相互之间可以通信,配置信息实际上是先保存在DC中的cib(Cluster Information Base,集群信息库,/var/lib/heartbeat/cib/cib.xml)中,这个是主CIB,然后由DC同步到其他节点上。也就是说,虽然我们是某个节点上进行的配置操作,但是最终配置结果是保存在DC节点上的,然后由DC节点再分发给各个集群节点。
集群的层次结构,经历了如下二图的变化过程:先从三层变为四层后又退回三层,membership层实现成员管理,投票系统在此层实现。
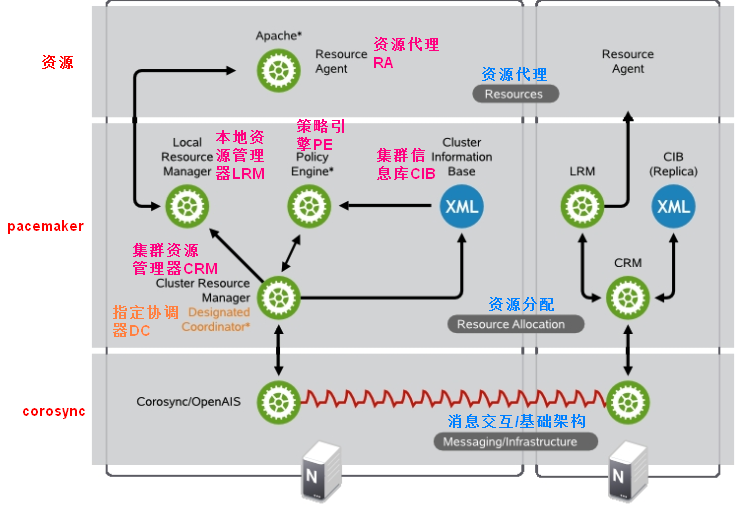
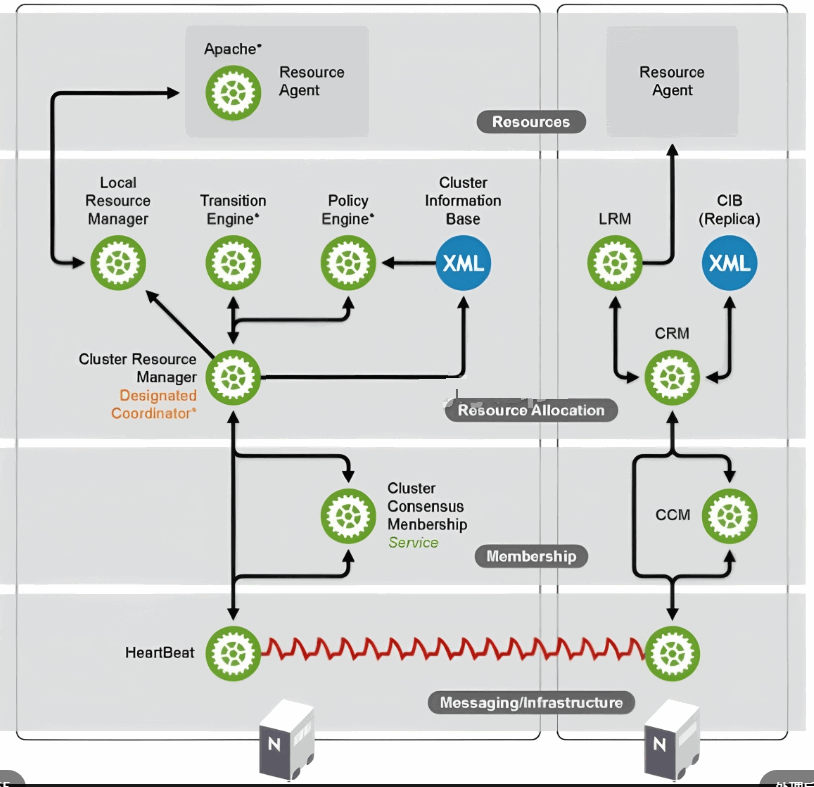
对于Corosync+Pacemaker组建HA集群,叫做Pacemaker Stack,其构建时的依赖关系如下:

需要先安装Corosync和cluster glue,然后安装resource agent,然后才能安装Pacemaker,即Pacemaker是依赖于Corosync、cluster glue、resource agent, 在此基础上,安装Distributed Lock Manager,分布式锁管理器,然后是cLVM2,GFS2,OCFS2,以实现集群文件系统功能。
集群文件系统:GFS2、OCFS2、cLVM2
共享存储是集群的一个重要的资源,像WEB服务、mysql服务实现HA集群时,都涉及共享存储。
存储类型 :
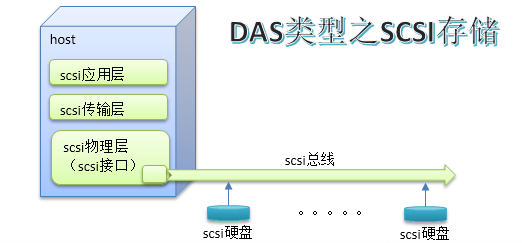
DAS:Direct Attached Storage,直接从主机主板上通过数据线(特定存储总线)连接的存储设备,如ide,usb,sata,scsi,sas,直接附加存储。(如主机的硬盘)
NAS:Network Attached Storage,网络附加存储,共享的是文件系统
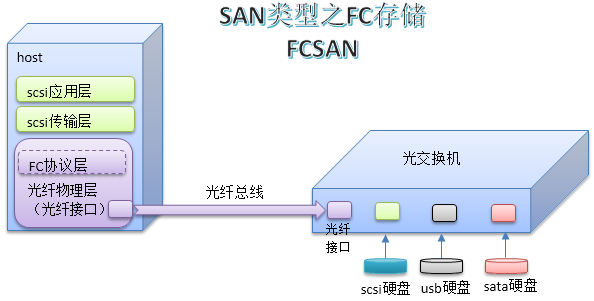
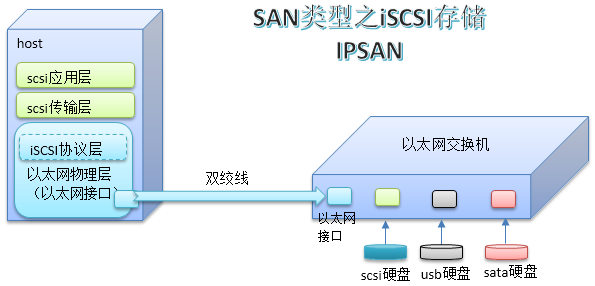
SAN:Storage Area Network。IPSAN,FCSAN,FCoESAN,存储区域网络,共享的是块设备
NAS与SAN的区别:

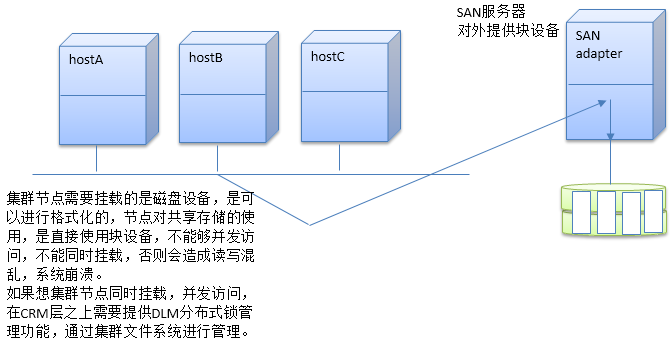
集群文件系统有性能上的瓶颈,集群节点数不多时可以使用。
SAN可以说是由DAS中的scsi扩展形成的。scsi是在主机主板中提供一个scsi控制接口,连接上scsi类型总线,这个总线上可以连接7或15块scsi类型的硬盘。scsi的性能非常好,读写速度快。为了增加连接的硬盘数量,这些接口又可以扩展,每个接口下经过扩展可以接32块scsi硬盘,这其实就是一个网络了,只不过终端是硬盘而已。scsi本身也是一种协议,分层协议,可以类似的理解为应用层、传输层、物理层等。但是scsi总线长度有限,仅限于机箱或机架范围,于是就对其进行了扩展,方法是将物理层由scsi物理线路改成光纤,光纤的传输距离很远。相应的,终端也需要适配光纤传输,于是使用一种光纤交换机,光接口用于接收光数据,其他接口适配不同的存储设备,形成一个存储区域网络。因为光纤技术成本高,于是底层传输又被扩展出使用以太网进行传输。这就是fc协议和iscsi协议,对应的存储区域网络叫做FCSAN和IPSAN,还有一种是scsi传输层再往下包装成光纤协议后又再次包装为以太网物理层,通过以太网传输,这就是FCoESAN
iscsi协议、fc协议
iscsi协议用于将scsi报文转换为经网线传输的以太网报文(tcp/ip报文),而fc协议是将scsi报文转换为光纤传输格式报文的协议。
SAN存储网络提供的是块级别的存储设备共享。
在没有财力能力构建SAN存储网络,而又想使用块级别共享存储时,可以使用另一种技术:DRBD
DRBD ------ Distributed Replicated Block Device,分布式复制块设备。
drbd:跨主机的块设备镜像系统,基于网络实现数据镜像,工作于内核中,是软件;其用户空间的配置管理工具:drbdadm,drbdsetup,drbdmeta;
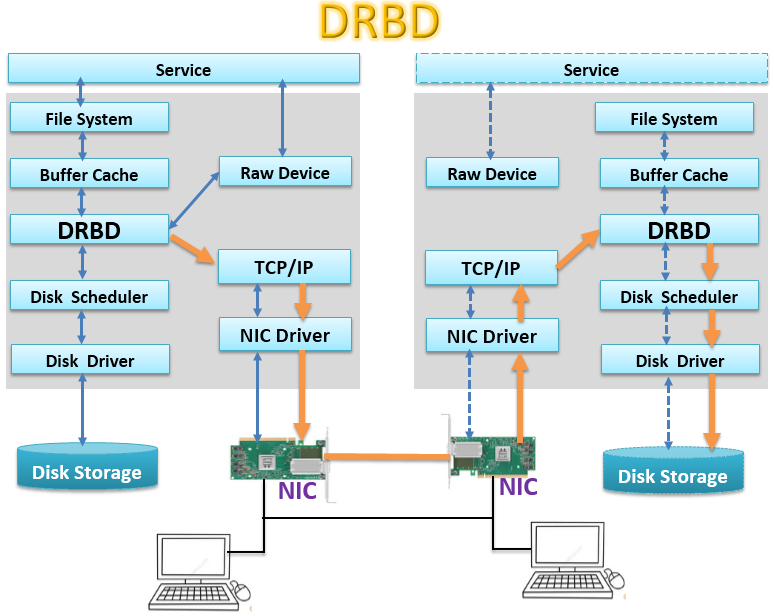
上图中灰色背景块代表内核空间,服务Service发起存储读写调用,通过内核的FileSystem进行操作,内核文件操作先是在一个Buffer Cache,即一个缓存中完成,这是加快读写速度,正常的在非DRBD模式下,Buffer Cache的数据流会接着由Disk Scheduler,即磁盘调度器,调用相应的Disk Driver ,即磁盘驱动,与物理磁盘交互,完成数据实际的存储。在使用DRBD时,在Buffer Cache与Disk Scheduler之间插入了一个DRBD层,这个DRBD层截取Buffer Cache流向Disk Scheduler的数据流,将其复制一份,其中一份传递到Disk Scheduler,保存到本地磁盘中,一份通过网络(即TCP/IP协议),经由网卡传输到另一台设备上,在另一台设备上,网卡接收数据报文,经由TCP/IP协议将报文解封为DRBD报文,由DRBD调用DIsk Scheduler,最终保存到这一台设备的磁盘中,实现数据的镜像保存。Raw Device叫做裸设备,有些应用读写数据不需要通过文件系统,而是直接读写磁盘块,如oracle等软件就具有这种功能,跳过了文件系统,读写性能会提高。
drbd工作特性:实时、透明、同步或异步;
数据同步模型:三种协议
protocol A,B,C
A:Asynchronous,异步
B:半同步
C:同步
在没有引入DRBD前,数据在Buffer Cache中写完毕,内核系统就可以返回读写完成状态,所以在Service看来性能很好,然后由Disk Scheduler在适当时机将数据写入磁盘中,在引入了DRBD后,就要考虑镜像到其他设备上数据的读写完成状态了。如果返回读写完成状态需要等到镜像设备写完成,即数据要通过主设备的网络传到镜像机器,由镜像机器网络接收,再通过镜像机器的DRBD写入镜像设备磁盘,然后在将状态原路返回给主设备,此时主设备才能给Service发读写完成状态,性能明显会降低很多,这种模型就是上面说的数据同步模型的C模型,即同步模型,性能最差,但是数据可靠性最高;第二种处理方式是当数据在镜像设备的网卡接收完毕后,就发送写操作完成状态,不必等到镜像设备写磁盘完成,性能将有所提升,数据可靠性降低,这是数据同步模型B,半同步模型;第三种是在主设备上,当DRBD将数据传递给本设备上的TCP/IP协议栈时,就认为写操作完成,性能进一步提升,数据可靠性进一步下降,这是数据同步模型A,异步模型。
DRBD使用:
每组drbd设备都由"drbd resource"进行定义:
名 字 :只能由空白字符之外的ASCII字符组成;
drbd设备:/dev/drbd#
主设备号:147,
次设备号:从0开始编号
磁盘配置:各主机上用于组成此drbd设备的磁盘或分区,编号可以不同,大小需要一致;
网络配置:数据同步时网络通信属性;
工作模型:
master/slave:主从模型
dual master :双主模型,要求必须在HA集群使用集群文件系统;