在生成式AI的世界里,"创造全新内容"是永恒的主题------从生成逼真的艺术画作,到模拟罕见的医学影像,再到为AI游戏生成随机场景......而变分自编码器(Variational Auto-Encoder,VAE) 就是这样一种兼具"生成能力"与"概率可解释性"的经典模型。今天,我们就来深入拆解它的原理与价值。
一、为什么需要VAE?------ 从"数据压缩"到"数据创造"
传统自编码器(Auto-Encoder)的核心是"压缩-解压":把输入数据编码成一个固定的特征向量 ,再解码还原成原始数据。它能做数据压缩、去噪,但生成能力几乎为零------因为特征向量是"单点式"的,没有连续性和随机性,无法生成"新的、没见过的内容"。
而VAE的突破在于:它把"特征向量"升级成了**"概率分布"。换句话说,VAE不是用"一个点"表示数据特征,而是用"一个概率云"来描述------这让它既能重构已有数据,又能从"概率云"中采样生成全新的、多样化的内容**。
二、VAE的核心逻辑:用概率给数据"建模"
想象一下,每类数据(比如猫的图像)在"潜在空间"里都有一个"基因库":有的基因决定毛色,有的决定脸型......VAE要做的,就是用概率分布把这个"基因库"的规律找出来,再通过"采样基因组合"生成新猫。
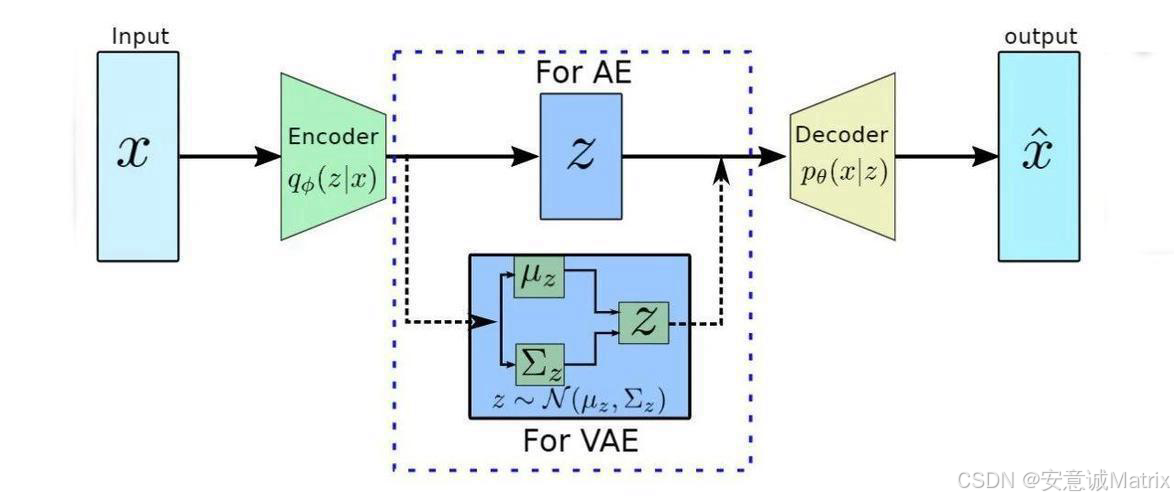
具体来说,VAE的流程可以拆成三个关键步骤:
1. 编码器(Encoder):给数据测"概率特征"
输入一张猫的图像 x\ x x,编码器会输出两个关键参数:
- 均值向量μ\muμ:相当于"这只猫的基因平均值"(比如平均毛色、平均脸型)。
- 标准差向量σ\sigmaσ :相当于"这只猫的基因波动范围"(毛色偏黑还是偏白的可能性,脸型偏圆还是偏尖的可能性)。
这两个参数共同定义了一个正态分布N(μ,σ2)\mathcal{N}(\mu, \sigma^2)N(μ,σ2),也就是这张猫图在"潜在空间"的概率分布。
2. 重参数化采样:从"概率云"中选"基因组合"
为了生成新内容,我们需要从这个正态分布中"采样"一个潜在向量 z\ z z (即一组"基因组合")。但直接采样会导致梯度无法回传(因为采样是随机的,和网络参数无关),所以VAE用了一个"技巧":
从标准正态分布N(0,I)\mathcal{N}(0, I)N(0,I) (可以理解为"通用基因库")中先采一个随机向量ϵ\epsilonϵ,再通过公式 z=μ+σ⊙ϵz = \mu + \sigma \odot \epsilonz=μ+σ⊙ϵ(⊙\odot⊙是逐元素相乘)生成 z\ z z。
这样既保证了 z\ z z服从mathcalN(μ,σ2)mathcal{N}(\mu, \sigma^2)mathcalN(μ,σ2),又让梯度能通过 μ\muμ 和 σ\sigmaσ回传给编码器,实现端到端训练。
3. 解码器(Decoder):用"基因组合"生成新内容
拿到潜在向量 z\ z z(一组"基因组合")后,解码器会把它映射回原始数据空间,输出重构图像x^\hat{x}x^(比如一只根据这组基因生成的新猫)。
三、训练VAE:既要"像原图",又要"基因库规整"
VAE的训练目标是两个"损失"的平衡,缺一不可:
1. 重构损失:保证"生成的像原图"
我们需要让解码器输出的x^\hat{x}x^尽可能接近输入 x\ x x。对于图像这类数据,通常用均方误差(MSE)或交叉熵来衡量两者的差异,强制模型"记住"数据的外观特征。
2. KL散度损失:保证"基因库规整"
为了让潜在空间的"概率云"有良好的连续性和可采样性 ,VAE要求编码器输出的分布N(μ,σ2)\mathcal{N}(\mu, \sigma^2)N(μ,σ2)尽可能接近标准正态分布N(0,I)\mathcal{N}(0, I)N(0,I) 。
这里用KL散度 (Kullback-Leibler Divergence)来量化两个分布的差异并最小化它。这一约束的意义是:让潜在空间"充满规律",后续可以在标准正态分布中随便采样 z\ z z,解码器都能生成合理的新内容。
四、VAE vs GAN:生成模型的"双雄对决"
经常有人把VAE和生成对抗网络(GAN)放在一起比较,它们的区别很有意思:
| 维度 | 变分自编码器(VAE) | 生成对抗网络(GAN) |
|---|---|---|
| 训练稳定性 | 高(基于概率分布优化,收敛更可控) | 低(对抗式训练易出现"模式崩溃") |
| 概率可解释性 | 强(潜在空间是明确的正态分布) | 弱(生成过程缺乏概率解释) |
| 生成画质 | 偏模糊(早期模型) | 高(可生成照片级逼真图像) |
| 应用场景 | 数据生成、数据增强、异常检测 | 艺术创作、超分辨率、风格迁移 |
简单来说,VAE胜在**"稳"和"可解释",适合需要概率支撑的场景(比如医学影像生成,要保证每类病变的分布合理);GAN胜在"画质"**,适合追求视觉冲击的创意场景(比如AI绘画)。
五、VAE的应用:从实验室到产业落地
VAE的能力已经在很多领域开花结果:
- 图像生成与编辑:可以生成全新的人脸、动物、风景,也能通过潜在空间的插值实现"变脸""换风格"。
- 数据增强:在医疗、工业等数据稀缺的领域,生成海量仿真数据扩充训练集,提升模型鲁棒性。
- 异常检测:正常数据在潜在空间的分布是"规整的概率云",如果输入是异常数据,重构损失会显著升高,以此识别异常。
结语:VAE的"概率思维"为何重要?
VAE的核心价值,在于它把"生成式AI"从"黑箱式创造"推向了"可解释的概率化创造"。它证明了:通过对"潜在空间概率分布"的建模,AI不仅能"复刻"数据,更能"理解"数据的分布规律,进而创造出无限可能的新内容。
从VAE出发,后续的生成模型(如VQ-VAE、扩散模型)也都在"概率建模"的思路上不断进化。可以说,VAE是打开"生成式AI概率之门"的一把关键钥匙。