一、Tensor 与 Numpy 数组的互相转换
从Numpy 生成Tensor
data1 = np.array(0,1,2,3)
data2 = torch.from_numpy(my_data1)
从tensor 到 Numpy
data3 = torch.zeros(2,2)
data4 = data3.numpy()
注: 使用上述函数产生的tensor 和NumPy 数组共享内存,对其中的一个更改也会使另外一个随着改变,如需要不共享内存,则可以分别按照如下方式:
从Numpy 生成Tensor且不共享内存:
data1 = np.array(0,1,2,3)
data2 = torch.from_numpy(my_data1)
data2_non_shared = data2.clone()
从tensor 到 Numpy 且不共享内存:
data3 = torch.zeros(2,2)
data4 = data3.detach()
data5 = data4.numpy()
二、用于创建张量的常用操作
from_numpy 将Numpy数组转换为张量
zeros/ones 创建元素值全为0/1的张量
eye 创建对角元素为1,其余元素为0
cat/concat 连接多个张量
split 切分张量
stack 沿新维度连接多个张量
take 从输入张量中取出指定元素组成新张量
normal 返回由章台分布随机数组成的张量
rand 返回[0,1)区间均匀分布随机数组成的张量
randn 返回由标准正态分布随机数组成的张量
python
import torch
# 示例张量
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5, 6], [7, 8]])
# 沿 dim=0(行方向)拼接
cat_dim0 = torch.cat((x, y), dim=0) # shape: [4, 2]
print(cat_dim0)
# tensor([[1, 2],
# [3, 4],
# [5, 6],
# [7, 8]])
# 沿 dim=1(列方向)拼接
cat_dim1 = torch.cat((x, y), dim=1) # shape: [2, 4]
print(cat_dim1)
# tensor([[1, 2, 5, 6],
# [3, 4, 7, 8]])
python
# 示例张量
tensor = torch.arange(10).reshape(2, 5) # shape: [2, 5]
print(tensor)
# tensor([[0, 1, 2, 3, 4],
# [5, 6, 7, 8, 9]])
# 按 chunk_size 拆分
split_chunks = torch.split(tensor, 2, dim=1) # 每块 2 列
print(split_chunks)
# (tensor([[0, 1], [5, 6]]), tensor([[2, 3], [7, 8]]), tensor([[4], [9]]))
# 按 chunk_size 拆分 dim = 0 ,按行拆分
tensor1 = torch.arange(30).reshape(6, 5) # shape: [2, 5]
split_chunks = torch.split(tensor1, 2, dim=0) # 每块 2行
# (tensor([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]]),
tensor([[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]]),
tensor([[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]]))
# 按 split_size 列表拆分
split_sizes = [3, 2]
split_result = torch.split(tensor, split_sizes, dim=1) # 拆分 3 列 + 2 列
print(split_result)
# (tensor([[0, 1, 2], [5, 6, 7]]), tensor([[3, 4], [8, 9]]))
python
# 示例张量
x = torch.tensor([1, 2])
y = torch.tensor([3, 4])
# 沿新维度堆叠
stacked = torch.stack((x, y), dim=0) # shape: [2, 2] 按行堆叠
print(stacked)
# tensor([[1, 2],
# [3, 4]])
stacked_dim1 = torch.stack((x, y), dim=1) # shape: [2, 2] 按列堆叠
print(stacked_dim1)
# tensor([[1, 3],
# [2, 4]])
# 示例张量
tensor = torch.tensor([[1, 2], [3, 4]])
# 按索引提取(摆直再取值)
indices = torch.tensor([0, 3])
taken = torch.take(tensor, indices) # 取第0和第3个元素(展平后),提取元素后组成张量;
print(taken) # tensor([1, 4])
# 指定正态分布的均值和标准差
mean = torch.tensor([0.0, 1.0])
std = torch.tensor([1.0, 0.5])
normal_samples = torch.normal(mean, std) # 生成与 mean 形状相同的随机数
print(normal_samples) # 例如 tensor([-0.1234, 1.4567])
# 从单一均值和标准差生成
normal_single = torch.normal(mean=0.0, std=1.0, size=(2, 2)) # 指定形状
print(normal_single)
# tensor([[ 0.1234, -0.5678],
# [ 1.2345, -0.9876]])
# 生成 2x3 的随机矩阵
uniform_random = torch.rand(2, 3)
print(uniform_random)
# tensor([[0.1234, 0.5678, 0.9012],
# [0.3456, 0.7890, 0.2345]])
# 生成 2x3 的标准正态分布随机数
normal_random = torch.randn(2, 3)
print(normal_random)
# tensor([[ 0.1234, -1.5678, 0.9012],
# [-0.3456, 0.7890, -1.2345]])三、张量的常用属性
dtype tensor 存储的数据类型 ,常用的数据类型有:
torch.float16/torch.half 16位浮点 torch.float32/torch.float 32位浮点 torch.float64/torch.double 64位浮点
torch.uint8 8 位无符号整型
torch.int8 8位整型
torch.int16/torch.short
torch.int32/torch.int
torch.int64/torch.long
torch.bool
torch.bfloat16 # PyTorch 提供的一种 16 位浮点数数据类型,全称为 Brain Floating Point 16
位数分配 由1 位符号位 + 8 位指数位 + 7 位尾数位 (与标准的 float32 指数位相同,但尾数位更少)具有动态范围大,能覆盖与 float32 相近的数值范围(,尾数位较少导致精度下降(约 2^-7 ≈ 0.0078 的最小间隔),但对许多深度学习任务影响有限,因为神经网络通常对数值精度不敏感。
四、数据位宽与算法精度的关系
由于深度学习多层神经网络特性深度学习不需要全部的高精度,例如t-SNE可视化MNIST手写数据集,各个数字在两成分的展示图上间距较大,因此可以用低位宽的非精确类型进行训练。
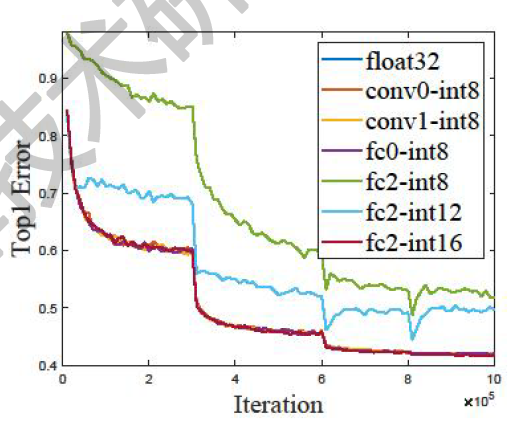
在同一种类型的深度学习模型中,例如AlexNet,不同层的数据都有其保持网络收敛的最低位宽需求,即为了使某层的数据正常收敛而需要的匹配这层收敛域的最低位宽。
如图 fc2 在 int8、int12 上训练迭代后期收敛效果不明显,而在int16上收敛较好,因此int16 是这层的收敛最低位宽。
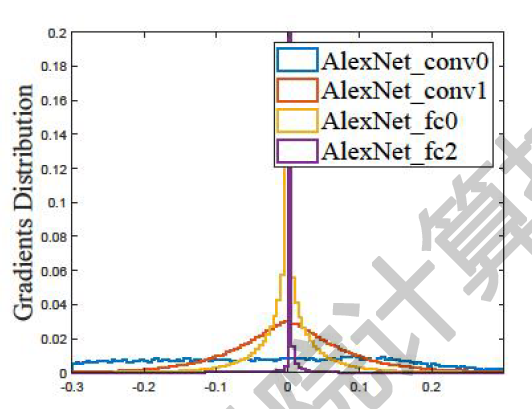
在数据分布角度看,在完整的迭代训练期内,每层梯度的数值分布特性决定了这层的梯度值的收敛域,因此相应的最低位宽不同。紫色部分的分布曲线,显示fc2梯度值分布在0值附近密集,因此梯度值在收敛时梯度值较小,且波动小,因而收敛域更窄,需更高的数值位宽。(如果只用低位宽则低位宽上相应的数值还没有够到收敛的数位,因而波动更大,收敛不明显。)
五、张量的device属性 和属性转换
torch.device指定tensor所在的设备,设备序号。
用'cuda:n'表示第n个GPU设备,用'dlp:n'表示第n个深度学习处理器。
python
#在GPU上创建一个张量
my_data1 = torch.tensor([0,1,2,3],device=torch.device('cuda:1'))
my_data2 = torch.tensor([0,1,2,3],device=torch.device('cuda',1))
my_data3 = torch.tensor([0,1,2,3],device='cuda:1')
#设置默认的device类型
my_device = 'cuda' if torch.cuda.is_available() else 'cpu'
my_data4 = torch.tensor([0,1,2,3],device=my_device)tensor.to():进行张量的数据类型或设备类型转换:
python
#张量设备类型转换
my_data1 = torch.tensor([0,1,2,3])
my_data1 = my_data1.to('cuda')
#张量数据类型转换
my_data1 = my_data1.to(torch.double)将GPU上的张量转换成NumPy数组,需要先将张量转换到CPU上,再转换成NumPy。
python
my_data2 = torch.tensor([0,1,2,3],device = 'cuda:1')
my_data3 = my_data2.cpu().numpy()tensor.reshape(*shape):进行张量的形状属性转换。
python
my_data1 = torch.tensor([0,1,2,3])
my_data2 = my_data1.reshape(2,2)单个维度上的shape值可以为-1,表示该维度上的shape值根据其他维度的值推算。
python
my_data3 = torch.arange(6)
my_data4 = my_data3.reshape(-1,2) #形状转换为(3,2)张量的复制:tensor.clone(),不共享内存,如第一节所示例。
六、张量的数据格式
PyTorch、GPU中采用NCHW格式,TensorFlow、CPU中采用NHWC格式。
N:表示一批次的数据个数(batch size) ,如RGB图像的数量,有多少N,就有多少CHW。
C: 通道数,对应R 、G、B。
H: 高度 单通道的尺寸。
W: 宽度 单通道的尺寸。
存储格式:
对于 N=2,C=3, H=2,W=2 的张量:
\[\[\[0,1\],\[2,3\]\] ,\[\[4,5\],\[6,7\]\],\[\[8,9\],\[10,11\]\] \], \[\[\[12,13\],\[14,15\]\] ,\[\[16,17\],\[18,19\]\],\[\[20,21\],\[22,23\]\] \],
存储的格式按照1维来存储,且对于NCHW格式按照 W->H->C->N的述序存储:
1,2,3,4,5,6,7,8,9,10,11 || 12,13,14,15,16,17,18,19,20,21,22,23
且对于NHWC格式按照 C->W->H->N的述序存储:
0,4,8,0,5,9,2,6,10,3,7,11 || 12,16,20,13,17,21,14,18,22,15,19,23
'||' 表示 N值不同的分割符。