一、前言:为什么企业需要分布式数据能力?
在传统架构中,企业多端数据同步往往依赖中心化服务器:App → API → 数据库。这种模型虽然稳定,但存在明显的瓶颈:
- 多设备间的数据同步延迟;
- 离线场景下的可用性低;
- 本地状态一致性难以保证;
- 服务端成本高、扩展性差。
鸿蒙操作系统(HarmonyOS)提供了分布式数据服务(Distributed Data Service,DDS),从操作系统层面实现了"数据即服务"的理念。无论设备是手机、车机、平板还是智能终端,都可以在同一账户或信任组内实现:
自动发现、数据共享、状态同步、离线回补。
这为企业级系统带来了新的数据协同模式------端侧自治 + 云端一致性。
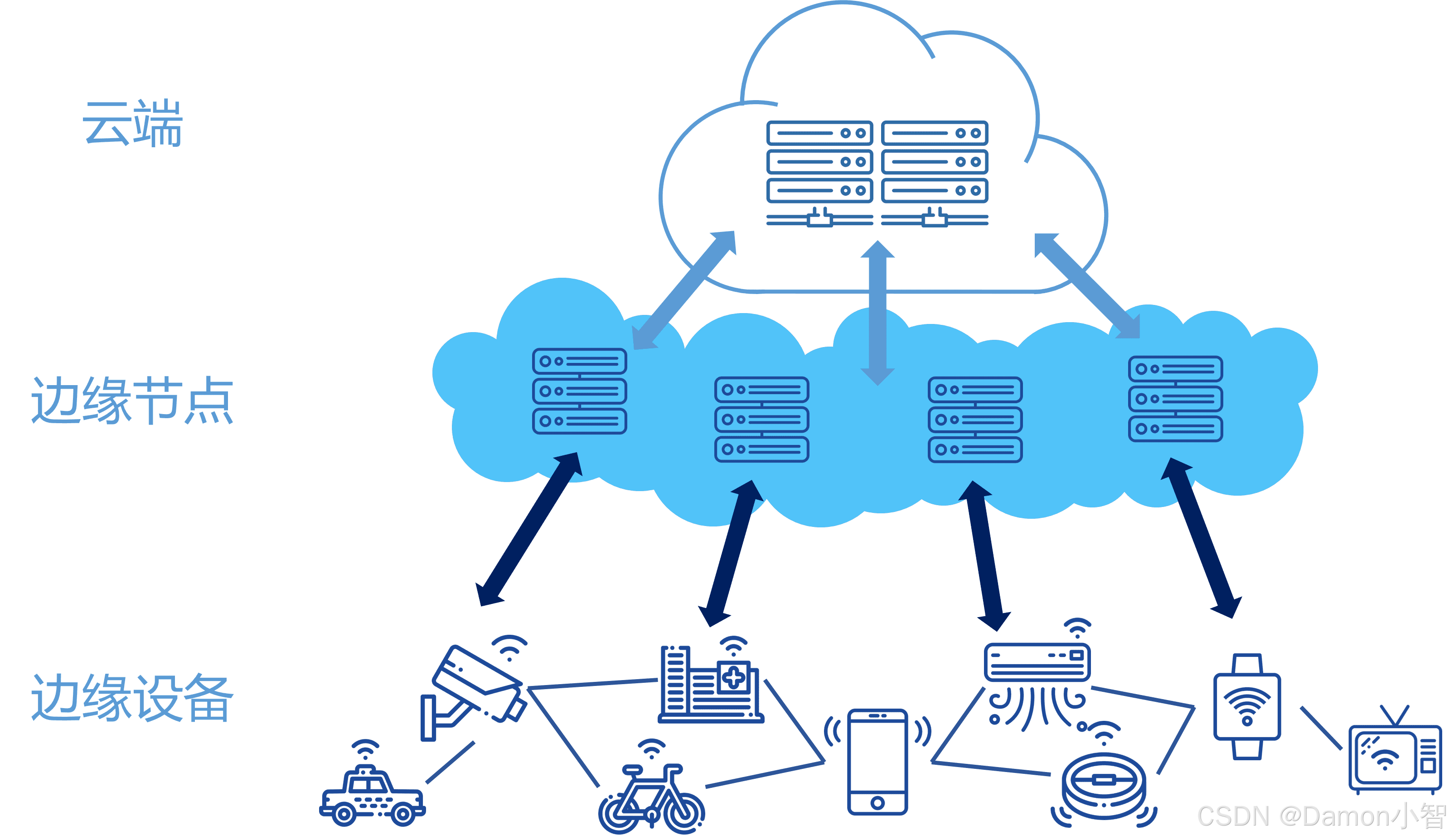
在企业应用场景中,例如汽车售后系统、仓储管理、零售电商,DDS 的落地能显著提升多终端协作效率。
二、架构总览:HarmonyOS DDS 的核心层次
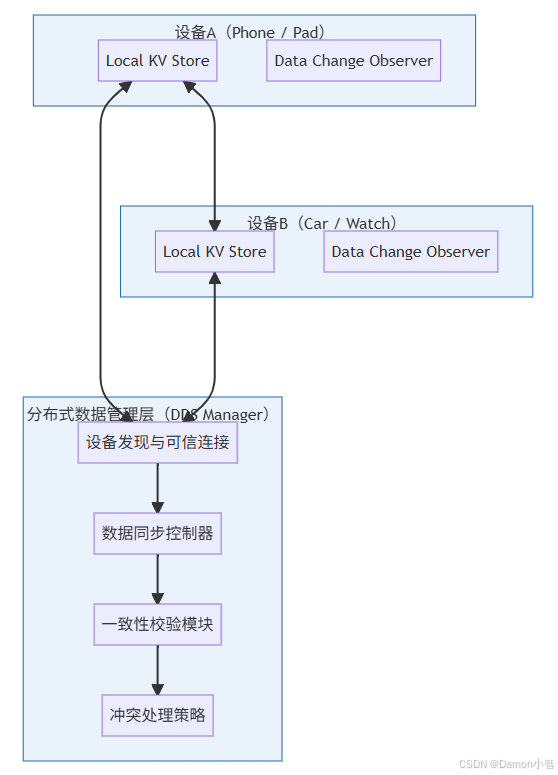
分层说明:
- Local KV Store(本地存储):基于轻量级分布式数据库(如 Preferences / KVStore),本地可独立运行;
- DDS Manager:负责多设备间的连接、同步策略、版本管理与冲突解决;
- Observer 层:监听数据变化并触发 UI 刷新或同步事件;
- 一致性层(Consistency):保证跨设备数据最终一致性,支持自定义冲突策略;
- 冲突处理策略(Conflict Resolution):支持 Last Write Wins、优先端、合并策略或开发者自定义逻辑。
三、核心原理:分布式同步机制
鸿蒙 DDS 在数据层采用了 "数据订阅 + 自动合并" 模式,核心机制包括:
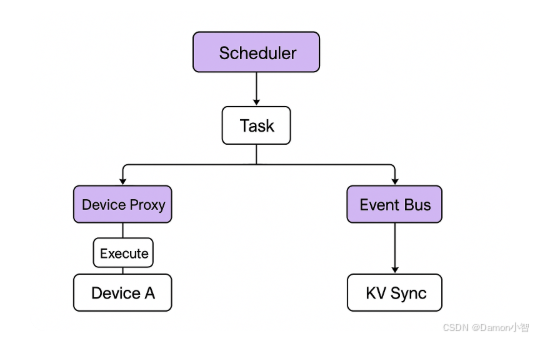
1️⃣ 数据存储模型:KV 架构
每个分布式存储单元可视为一个 Key-Value 表(Distributed KVStore),可在多设备间共享。
ts
import distributedData from '@ohos.data.distributedData';
const store = distributedData.createKVManager({ bundleName: 'com.example.demo' })
.getKVStore('user_profile', { createIfMissing: true });
store.put('username', 'Guangzhi');
store.get('username', (err, value) => {
console.log('当前用户名:', value);
});2️⃣ 同步机制:主动与被动
- 主动同步(sync):代码中调用同步接口,将本地变更推送至其他设备;
- 被动同步(onChange):远端设备数据变化时,系统自动触发事件通知。
ts
store.on('dataChange', (changeInfo) => {
console.log('数据变更同步:', changeInfo);
});
store.sync('deviceB');3️⃣ 一致性策略
HarmonyOS DDS 采用 最终一致性模型(Eventual Consistency) 。
当设备间短时离线,数据会在恢复连接后进行 版本冲突检测 与 自动合并 。
冲突解决策略:
- 时间戳优先(Last Write Wins)
- 端优先策略:指定主端优先更新
- 自定义合并:开发者可注册回调处理复杂对象
4️⃣ 事务与批量操作
DDS 支持本地事务和批量操作:
ts
store.beginTransaction();
store.put('order1', { status: 'paid' });
store.put('order2', { status: 'pending' });
store.commit();事务提交后,DDS 会自动触发多端同步,确保原子性和一致性。
四、企业级实战:多终端订单同步系统
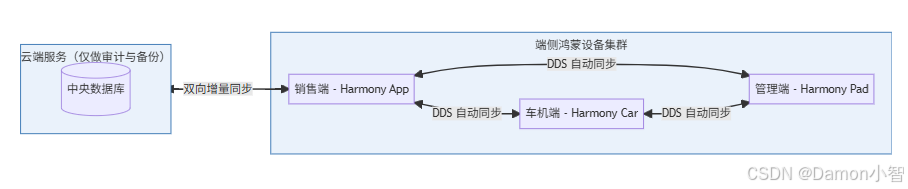
以汽车企业售后系统为例,存在以下终端:
- 销售端(手机)
- 服务端(车机)
- 管理端(平板)
目标是实现:
订单、客户信息在多端实时同步,离线更新后自动回补。
1️⃣ 架构设计
2️⃣ 实现要点
- 各端注册同一 bundleName 与同一 KVStore;
- 利用
deviceManager自动发现可信设备; - 统一数据模型(JSON Schema)并加版本号;
- 云端接口周期性备份与审计;
- 本地事务保证多数据项一致性。
ts
store.on('syncComplete', () => {
console.info('订单同步完成,触发云端上传任务');
uploadToCloud(store.snapshot());
});3️⃣ 优化技巧
- 使用 增量同步 代替全量同步,降低网络压力;
- 对频繁变更的数据分表或分片存储,避免冲突;
- 利用
onSyncStateChange监控同步状态,实现可视化运维; - 结合 DDS 安全机制,控制设备权限、限制同步范围。
4️⃣ 扩展场景
- 库存管理:多仓库实时同步库存状态
- 工单调度:现场设备离线生成数据,回联后自动同步
- 企业配置中心:多终端统一配置信息管理
五、性能优化与安全保障
| 优化点 | 方案 |
|---|---|
| 同步延迟 | 设置 setSyncPolicy(POLICY_REALTIME),降低触发延迟 |
| 冲突概率 | 数据结构加入版本号与编辑人信息,使用事务和批量操作 |
| 离线场景支持 | 本地缓存 + 自动回补机制 |
| 大数据场景 | 分片存储 + 增量同步,避免整表传输 |
| 安全性 | 利用 authInfo 校验设备信任关系,限制同步范围 |
| 监控体系 | 使用 onSyncStateChange 实时记录同步状态,实现日志与报警 |
示例:实时同步策略
ts
store.setSyncPolicy({
policy: 'POLICY_REALTIME',
interval: 5000, // 5秒批量同步
conflictResolver: (local, remote) => remote // 简单 LWW 策略
});六、企业落地经验与注意事项
-
KVStore 命名规范
- 使用
模块名_业务名,防止冲突; - 对跨模块共享数据,提前定义 schema 与版本号。
- 使用
-
设备信任组管理
- 利用 HarmonyOS 账户或可信设备组管理权限;
- 控制 DDS 数据同步范围,避免泄露。
-
离线场景测试
- 必须模拟短时断网、异常中断;
- 验证自动回补和冲突解决策略是否可靠。
-
性能监控
- 增量同步的耗时、冲突率、内存占用必须监控;
- 提前规划关键业务数据的同步策略。
七、总结与展望
鸿蒙 DDS 的核心价值在于:
让数据同步不再依赖"中心",而依赖"信任边界"。
企业级落地优势:
- 云端轻量化:只做备份与审计;
- 端侧自治:低延迟、高可靠;
- 分布式协同:多端状态一致。
未来,随着 HarmonyOS NEXT 全面去安卓化 、分布式数据库 API 标准化,企业可以构建真正的:
全端互通 · 数据自治 · 智能协同的数字生态体系。