目录
- 温故知新
-
- 强化学习分类
- 适用于求解问题的类型
- [在线策略 & 离线策略](#在线策略 & 离线策略)
- [TRPO 算法](#TRPO 算法)
- [PPO 算法](#PPO 算法)
温故知新
强化学习分类
- Model-based
- value-based
动态规划(DP)
- value-based
- Model-free
- value-based
蒙特卡洛(MC)、时序差分(TD) - policy-based
策略梯度算法(如REINFORCE) - 集大成者:Actor-Critic 算法/框架 【= Value-based(Critic) + Policy-based(Actor)】
- value-based
适用于求解问题的类型
- 状态、动作空间均离散且有限
动态规划、时序差分 - 连续状态,离散动作
DQN
在线策略 & 离线策略
在线策略(on-policy)算法:学习和采样的策略一样;
如:TD里的 Sarsa、策略梯度的算法 REINFORCE、Actor-Critic 以及两个改进算法------TRPO 和 PPO
离线策略(off-policy)算法:学习和采样的策略不同。
如:TD 里的 Q-learning
老样子,对之前的知识做个简单的分类不要混,其中的 TRPO 和 PPO 是本文的内容,其中 PPO 更是强化学习常用的基准算法。
TRPO 算法
像之前的策略梯度算法和 Actor-Critic 算法存在一个缺陷:当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果。TRPO(trust region policy optimization)就是在解决这种问题,使得训练更稳定。
先给个 TRPO 算法的宏观过程:
- 将策略参数化 ,然后设计相应的目标函数 如 J ( θ ) = E s 0 V π θ ( s 0 ) = E π θ ∑ t = 0 ∞ γ t r ( s t , a t ) J \left( \theta \right)=E_{s_{0}} \left V\^{ \\pi_{ \\theta}} \\left( s_{0} \\right) \\right=E_{ \pi_{ \theta}} \left \\sum_{t=0}\^{ \\infty} \\gamma\^{t}r \\left( s_{t},a_{t} \\right) \\right J(θ)=Es0Vπθ(s0)=Eπθ∑t=0∞γtr(st,at),同时引入 KL 散度 来衡量策略之间的距离,并规定其距离不能太大,也即定了约束条件(孙悟空给他师傅画圈),经过一系列近似、恒等变换操作,我们可将整体问题用下面公式进行刻画:
max θ E s ∼ ν π θ k E a ∼ π θ k ( ⋅ ∣ s ) π θ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) s . t . E s ∼ ν π θ k D KL ( π θ k ( ⋅ ∣ s ) , π θ ( ⋅ ∣ s ) ) ≤ δ \begin{split}\max_{\theta}&\quad\mathbb{E}{\bm{s} \sim\nu^{\pi{\theta_{\textit{k}}}}}\mathbb{E}{\bm{a}\sim\pi{\theta_{\textit {k}}}(\cdot|\bm{s})}\left\\frac{\\pi_{\\theta}(\\bm{a}\|\\bm{s})}{\\pi_{\\theta_{\\textit {k}}}(\\bm{a}\|\\bm{s})}\\bm{A}\^{\\pi_{\\theta_{\\textit{k}}}}(\\bm{s},\\bm{a})\\right \\ \mathrm{s.t.}&\quad\mathbb{E}{\bm{s}\sim\nu^{\pi{ \theta_{\textit{k}}}}}D_{\\textit{KL}}(\\pi_{\\theta_{\\textit{k}}}(\\cdot\|\\bm{s}),\\pi_{\\theta}(\\cdot\|\\bm{s}))\leq\delta\end{split} θmaxs.t.Es∼νπθkEa∼πθk(⋅∣s)πθk(a∣s)πθ(a∣s)Aπθk(s,a)Es∼νπθkDKL(πθk(⋅∣s),πθ(⋅∣s))≤δ
- 问题描述完就能求解了,TRPO 对上面两个公式用泰勒展开 式进行近似,又经过一系列操作,推出更进一步的优化目标,结合 KKT 条件 导出其解: θ k + 1 = θ k + 2 δ g T H − 1 g H − 1 g \theta_{k+1}= \theta_{k}+ \sqrt{ \frac{2 \delta}{g^{T}H^{-1}g}}H^{-1}g θk+1=θk+gTH−1g2δ H−1g,为了提高计算效率,令 x = H − 1 g \bm{x=H^{-1}g} x=H−1g,这个小问题是二次型优化问题,TRPO 采用共轭梯度法求解
- 为了抵消或者是平滑一下前面近似求解导致的误差,TRPO 采用了线性搜索,你可以理解为试探出合适的步长
- 至于广义优势估计 ,只是用来估计目标函数中的优势函数 A A A 的
上面只是草草说明下 TRPO 的做法流程,知道它大概做什么,详细的下面展开:
策略目标
当前策略是 π θ \pi_{\theta} πθ( θ \theta θ为参数),对优化目标 J ( θ ) J(\theta) J(θ) 做如下推导:
J ( θ ) = E s 0 V π θ ( s 0 ) = E π θ ′ ∑ t = 0 ∞ γ t V π θ ( s t ) − ∑ t = 1 ∞ γ t V π θ ( s t ) = − E π θ ′ ∑ t = 0 ∞ γ t ( γ V π θ ( s t + 1 ) − V π θ ( s t ) ) \begin{split} J(\theta)&=\mathbb{E}{s{0}}V\^{\\pi_ {\\theta}}(s_{0})\\ &=\mathbb{E}{\pi{\theta^{\prime}}}\left\\sum_{t=0}\^{\\infty} \\gamma\^{t}V\^{\\pi_{\\theta}}(s_{t})-\\sum_{t=1}\^{\\infty}\\gamma\^{t}V\^{\\pi_{\\theta} }(s_{t})\\right\\ &=-\mathbb{E}{\pi{\theta^{\prime}}}\left\\sum_{t=0}\^{\\infty} \\gamma\^{t}\\left(\\gamma V\^{\\pi_{\\theta}}(s_{t+1})-V\^{\\pi_{\\theta}}(s_{t}) \\right)\\right\end{split} J(θ)=Es0Vπθ(s0)=Eπθ′t=0∑∞γtVπθ(st)−t=1∑∞γtVπθ(st)=−Eπθ′t=0∑∞γt(γVπθ(st+1)−Vπθ(st))
(一)期望下标从 s 0 s_0 s0 ------> π θ ′ \pi_{\theta^{\prime}} πθ′
简单讲,其实换不换下标都是得对 s 0 s_0 s0求期望的,因为 V π θ ( s 0 ) V^{\pi_ {\theta}}(s_{0}) Vπθ(s0)定了 π θ \pi_ {\theta} πθ后,就只依赖于随机变量 s 0 s_0 s0了,而 s 0 s_0 s0又只服从初始状态分布,这个分布肯定不受策略影响的,所以换下标前后是等价的。展开讲:
E s 0 V π θ ( s 0 ) \mathbb{E}{s{0}}V\^{\\pi_ {\\theta}}(s_{0}) Es0Vπθ(s0):可理解为对于策略 π θ \pi_{\theta} πθ,在所有可能的起始状态上的平均性能;
E π θ ′ V π θ ( s 0 ) \mathbb{E}{\pi{\theta^{\prime}}}V\^{\\pi_ {\\theta}}(s_{0}) Eπθ′Vπθ(s0):是策略 π θ ′ \pi_{\theta^{\prime}} πθ′下的整个轨迹分布上求期望。其中 s 0 s_0 s0是从初始状态分布中采样而来,而不管是什么策略,肯定不影响初始状态分布的,并且我们是对 V π θ ( s 0 ) V^{\pi_ {\theta}}(s_{0}) Vπθ(s0)求期望,这里 π θ \pi_ {\theta} πθ在迭代结束前是给定死了,那么随机变量就是 s 0 s_0 s0,所以对 V ( . . . ) V(...) V(...)求期望其实本质就是基于随机变量 s 0 s_0 s0求的,那也就是说,我换了下标后其实计算的本质一样,并不影响,所以二者等价。至于为什么要换?①可以把 π θ \pi_ {\theta} πθ和 π θ ′ \pi_{\theta^{\prime}} πθ′联系起来;②便于展开成TD误差形式;③可能可以用上重要性采样
(二)等式第三行推导
∑ t = 0 ∞ γ t V ( s t ) − ∑ t = 1 ∞ γ t V ( s t ) = ∑ t = 0 ∞ γ t V ( s t ) − γ ∑ t = 0 ∞ γ t V ( s t + 1 ) = ∑ t = 0 ∞ γ t V ( s t ) − γ V ( s t + 1 ) = − ∑ t = 0 ∞ γ t γ V ( s t + 1 ) − V ( s t ) \sum_{t=0}^{\infty}\gamma^{t}V(\bm{s}{t})-\sum{t=1}^{\infty} \gamma^{t}V(\bm{s}{t}) =\sum{t=0}^{\infty}\gamma^{t}V(\bm{s}{t})-\gamma\sum{t=0}^{ \infty}\gamma^{t}V(\bm{s}{t+1})\newline =\sum{t=0}^{\infty}\gamma^{t}\leftV(\\bm{s}_{t})-\\gamma V(\\bm{s} _{t+1})\\right\newline =-\sum_{t=0}^{\infty}\gamma^{t}\left\\gamma V(\\bm{s}_{t+1})-V(\\bm {s}_{t})\\right t=0∑∞γtV(st)−t=1∑∞γtV(st)=t=0∑∞γtV(st)−γt=0∑∞γtV(st+1)=t=0∑∞γtV(st)−γV(st+1)=−t=0∑∞γtγV(st+1)−V(st)
作差,得出新旧策略的目标函数间差距:
J ( θ ′ ) − J ( θ ) = E s 0 V π θ ′ ( s 0 ) − E s 0 V π θ ( s 0 ) = E π θ ′ ∑ t = 0 ∞ γ t r ( s t , a t ) + E π θ ′ ∑ t = 0 ∞ γ t ( γ V π θ ( s t + 1 ) − V π θ ( s t ) ) = E π θ ′ ∑ t = 0 ∞ γ t \[ r ( s t , a t ) + γ V π θ ( s t + 1 ) − V π θ ( s t ) ] \begin{split} J(\theta^{\prime})-J(\theta)&=\mathbb{ E}{s{0}}\leftV\^{\\pi_{\\theta\^{\\prime}}}(s_{0})\\right-\mathbb{E}{s{0}} \leftV\^{\\pi_{\\theta}}(s_{0})\\right\\ &=\mathbb{E}{\pi{\theta^{\prime}}}\left\\sum_{t=0}\^{\\infty} \\gamma\^{t}r(s_{t},a_{t})\\right+\mathbb{E}{\pi{\theta^{\prime}}}\left\\sum_{ t=0}\^{\\infty}\\gamma\^{t}\\left(\\gamma V\^{\\pi_{\\theta}}(s_{t+1})-V\^{\\pi_{\\theta}}(s_{t}) \\right)\\right\\ &=\mathbb{E}{\pi{\theta^{\prime}}}\left\\sum_{t=0}\^{\\infty} \\gamma\^{t}\\left\[r(s_{t},a_{t})+\\gamma V\^{\\pi_{\\theta}}(s_{t+1})-V\^{\\pi_{ \\theta}}(s_{t})\\right\right]\end{split} J(θ′)−J(θ)=Es0Vπθ′(s0)−Es0Vπθ(s0)=Eπθ′t=0∑∞γtr(st,at)+Eπθ′t=0∑∞γt(γVπθ(st+1)−Vπθ(st))=Eπθ′t=0∑∞γt\[r(st,at)+γVπθ(st+1)−Vπθ(st)]
将时序差分残差定义为优势函数 A A A :
= E π θ ′ ∑ t = 0 ∞ γ t A π θ ( s t , a t ) = ∑ t = 0 ∞ γ t E s t ∼ P t π θ ′ E a t ∼ π θ ′ ( ⋅ ∣ s t ) A π θ ( s t , a t ) = 1 1 − γ E s ∼ ν π θ ′ E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) \begin{split}&=\mathbb{E}{\pi{\theta^{\prime}}}\left\\sum_{t=0}\^{ \\infty}\\gamma\^{t}A\^{\\pi_{\\theta}}(\\bm{s}_{t},\\bm{a}_{t})\\right\\ &=\sum_{t=0}^{\infty}\gamma^{t}\mathbb{E}{s{t} \sim P_{t}^{ \pi_{\theta^{\prime}}}}\mathbb{E}{a{t} \sim\pi_{\theta^{\prime}}(\cdot|\bm{ s}{t})}\leftA\^{\\pi_{\\theta}}(\\bm{s}_{t},\\bm{a}_{t})\\right\\ &=\frac{1}{1-\gamma}\mathbb{E}{\bm{s}\sim\nu^{\pi_{\theta^{ \prime}}}}\mathbb{E}{a\sim\pi{\theta^{\prime}}(\cdot|\bm{s})}\leftA\^{\\pi_{ \\theta}}(\\bm{s},\\bm{a})\\right\end{split} =Eπθ′t=0∑∞γtAπθ(st,at)=t=0∑∞γtEst∼Ptπθ′Eat∼πθ′(⋅∣st)Aπθ(st,at)=1−γ1Es∼νπθ′Ea∼πθ′(⋅∣s)Aπθ(s,a)
关于第三行的推导:
- 先定义下折扣状态访问分布: ν π θ ′ ( s ) = ( 1 − γ ) ∑ t = 0 ∞ γ t P t π θ ′ ( s ) \nu^{ \pi_{ \theta^{ \prime}}} \left( s \right)= \left( 1- \gamma \right) \sum_{t=0}^{ \infty} \gamma^{t}P_{t}^{ \pi_{ \theta^{ \prime}}} \left( s \right) νπθ′(s)=(1−γ)∑t=0∞γtPtπθ′(s),关于为什么前面加了折扣因子,其实主要是为了归一化 ,如下:
∑ s ∑ t = 0 ∞ γ t P t π E̸ ( s ) = ∑ t = 0 ∞ ∑ s γ t P t π E̸ ( s ) = ∑ t = 0 ∞ γ t ⋅ ( ∑ s P t π E̸ ( s ) ) = ∑ t = 0 ∞ γ t ⋅ 1 = 1 1 − γ \sum_{s}\sum_{t = 0}^{\infty}\gamma^{t}P_{t}^{\pi_{\not \mathscr{E}}}(s)= \sum_{t = 0}^{\infty}\sum_{s}\gamma^{t}P_{t}^{\pi_{\not \mathscr{E}}}(s)= \sum_{t = 0}^{\infty}\gamma^{t}\cdot\left(\sum_{s}P_{t}^{\pi_{\not \mathscr{ E}}}(s)\right)=\sum_{t = 0}^{\infty}\gamma^{t}\cdot 1 =\frac{1}{1-\gamma} s∑t=0∑∞γtPtπE(s)=t=0∑∞s∑γtPtπE(s)=t=0∑∞γt⋅(s∑PtπE(s))=t=0∑∞γt⋅1=1−γ1
乘 ( 1 − γ ) (1-\gamma) (1−γ)后就有 ∑ s ν π θ ′ ( s ) = 1 \sum_{\bm{s}}\bm{\nu^{\pi_{\theta^{\prime}}}(s)=1} ∑sνπθ′(s)=1;- 其次对第三行推导补充如下:
∑ t = 0 ∞ γ t E s l ∼ P t π θ ′ E a l ∼ π θ ′ ( ⋅ ∣ s l ) A π θ ( s t , a t ) = ∑ t = 0 ∞ γ t ∑ s P t π θ ′ ( s ) E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) = ∑ s ∑ t = 0 ∞ γ t P t π θ ′ ( s ) E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) = ∑ s ν π θ ′ ( s ) 1 − γ E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) = 1 1 − γ ∑ s ν π θ ′ ( s ) E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) = 1 1 − γ E s ∼ ν π θ ′ E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) \begin{split}\sum_{t=0}^{\infty}\gamma^{t}\mathbb{E}{s{l}\sim P {t}^{\pi{\theta^{\prime}}}}\mathbb{E}{a{l}\sim\pi_{\theta^{\prime}}(\cdot |s_{l})}\leftA\^{\\pi_{\\theta}}(s_{t},a_{t})\\right&=\sum_{t=0}^{ \infty}\gamma^{t}\sum_{s}P_{t}^{\pi_{\theta^{\prime}}}(s)\mathbb{E}{a\sim\pi {\theta^{\prime}}(\cdot|s)}\leftA\^{\\pi_{\\theta}}(s,a)\\right\\ &=\sum_{s}\left\\sum_{t=0}\^{\\infty}\\gamma\^{t}P_{t}\^{\\pi_{\\theta\^{ \\prime}}}(s)\\right\mathbb{E}{a\sim\pi{\theta^{\prime}}(\cdot|s)}\leftA\^{ \\pi_{\\theta}}(s,a)\\right\\ &=\sum_{s}\frac{\nu^{\pi_{\theta^{\prime}}}(s)}{1-\gamma}\mathbb{ E}{a\sim\pi{\theta^{\prime}}(\cdot|s)}\leftA\^{\\pi_{\\theta}}(s,a)\\right\\ &=\frac{1}{1-\gamma}\sum_{s}\nu^{\pi_{\theta^{\prime}}}(s) \mathbb{E}{a\sim\pi{\theta^{\prime}}(\cdot|s)}\leftA\^{\\pi_{\\theta}}(s,a) \\right\\ &=\frac{1}{1-\gamma}\mathbb{E}{s\sim\nu^{\pi{\theta^{\prime}}}} \mathbb{E}{a\sim\pi{\theta^{\prime}}(\cdot|s)}\leftA\^{\\pi_{\\theta}}(s,a) \\right\end{split} t=0∑∞γtEsl∼Ptπθ′Eal∼πθ′(⋅∣sl)Aπθ(st,at)=t=0∑∞γts∑Ptπθ′(s)Ea∼πθ′(⋅∣s)Aπθ(s,a)=s∑t=0∑∞γtPtπθ′(s)Ea∼πθ′(⋅∣s)Aπθ(s,a)=s∑1−γνπθ′(s)Ea∼πθ′(⋅∣s)Aπθ(s,a)=1−γ1s∑νπθ′(s)Ea∼πθ′(⋅∣s)Aπθ(s,a)=1−γ1Es∼νπθ′Ea∼πθ′(⋅∣s)Aπθ(s,a)
好了,我们把目标函数简化成上式,在该式中,如果我们能保证等式右边非负,就能保证策略性能提升。但问题是直接求它很困难,因为 π θ ′ \pi_{\theta^{\prime}} πθ′ 是我们要求解的策略,但我们又要用它来收集样本,如果采取把所有可能的新策略都拿来收集数据,然后判断哪个策略满足上述条件的做法显然是不现实的。
所以 TRPO 采用如下替代优化目标:
L θ ( π θ ′ ) = J ( θ ) + 1 1 − γ E s ∼ ν π θ E a ∼ π θ ( ⋅ ∣ s ) π θ ′ ( a ∣ s ) π θ ( a ∣ s ) A π θ ( s , a ) L_{\theta}(\pi_{\theta^{\prime}})=J(\theta)+\frac{1}{1-\gamma}\mathbb{E}{s\sim\nu^{\pi\theta}}\mathbb{E}{a\sim\pi\theta(\cdot|s)}\left\\frac{\\pi_{\\theta\^{\\prime}}(a\|s)}{\\pi_\\theta(a\|s)}A\^{\\pi_\\theta}(s,a)\\right Lθ(πθ′)=J(θ)+1−γ1Es∼νπθEa∼πθ(⋅∣s)πθ(a∣s)πθ′(a∣s)Aπθ(s,a)
解释:
状态分布近似( π θ ′ ≈ π θ \pi_{ \theta^{ \prime}}\approx\pi_{ \theta} πθ′≈πθ)
前提是当新旧策略非常接近时,状态访问分布变化很小,故能做如下近似: J ( θ ′ ) − J ( θ ) ≈ 1 1 − γ E s ∼ ν π θ E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) J(\theta^{\prime})-J(\theta)\textcolor{red}\approx\frac{1}{1-\gamma}\mathbb{E}{s\sim\nu^{\textcolor{red}{\pi{ \theta}}}}\mathbb{E}{a\sim\pi{\theta^{ \prime}}(\cdot|s)}A\^{\\pi_{ \\theta}}(s,a) J(θ′)−J(θ)≈1−γ1Es∼νπθEa∼πθ′(⋅∣s)Aπθ(s,a)
重要性采样
重要性采样允许我们用一个容易采样的分布 q q q 来估计关于另一个分布 p p p 的期望,通过给每个样本加权重 p q \frac{p}{q} qp 来修正分布差异。值得说明的是,重要性采样是无偏估计,但若 q q q、 p p p 分布相差太大,则权重 p q \frac{p}{q} qp 不稳定,会导致方差大,所以上一步我们假设了新旧策略接近。故有如下式子: E a ∼ π θ ′ ( ⋅ ∣ s ) A π θ ( s , a ) = E a ∼ π θ ( ⋅ ∣ s ) π θ ′ ( a ∣ s ) π θ ( a ∣ s ) A π θ ( s , a ) \mathbb{E}{a\sim\textcolor{red}{\pi{\theta^{\prime}}}(\cdot|s)}A\^{\\pi_\\theta}(s,a)=\mathbb{E}{a\sim\textcolor{red}{\pi\theta}(\cdot|s)}\left\\textcolor{red}{\\frac{\\pi_{\\theta\^{\\prime}}(a\|s)}{\\pi_\\theta(a\|s)}}A\^{\\pi_\\theta}(s,a)\\right Ea∼πθ′(⋅∣s)Aπθ(s,a)=Ea∼πθ(⋅∣s)πθ(a∣s)πθ′(a∣s)Aπθ(s,a)
结合上述两步,最终就是上面替代后的优化目标了。
好了,聪明的你经过操作,问题变得可求解,但还有一个问题:前面我们说近似的前提是新旧策略非常接近,那怎么去衡量呢?
TRPO 使用了 KL散度 来衡量策略之间的距离(这里,对于KL散度你只需要知道能量化两个策略的差异就行),则整个问题可以变成一个带约束的优化函数了,我们描述如下:
max θ ′ L θ ( θ ′ ) s . t . E s ∼ ν π θ k D K L ( π θ k ( ⋅ ∣ s ) , π θ ′ ( ⋅ ∣ s ) ) ≤ δ \begin{aligned} & \max_{\theta^{\prime}}L_{\theta}(\theta^{\prime}) \\ & \mathrm{s.t.}\mathbb{E}{s\sim\nu^{\pi{\theta_{k}}}}D_{KL}(\\pi_{\\theta_{k}}(\\cdot\|s),\\pi_{\\theta\^{\\prime}}(\\cdot\|s))\leq\delta \end{aligned} θ′maxLθ(θ′)s.t.Es∼νπθkDKL(πθk(⋅∣s),πθ′(⋅∣s))≤δ
补充:
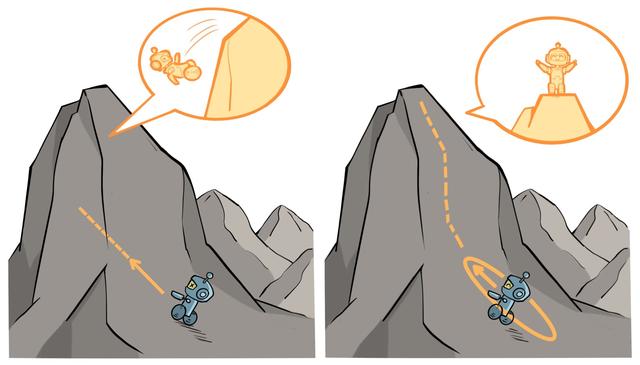
从上式易知,约束条件定义了策略空间中的一个 KL 球,被称为信任区域。(打个不太恰当的比喻:孙悟空给他师傅画的圈圈)在这个区域中,我们认为新旧策略的分布足够接近,可以认为当前学习策略和环境交互的状态分布与上一轮策略最后采样的状态分布一致,进而可以基于一步行动的重要性采样方法使当前学习策略稳定提升。
如上诠释了 TRPO 的原理,左图是当完全不设置信任区域,策略的梯度更新可能导致策略的性能骤降;右图设置了信任区域,可以保证每次策略的梯度更新时性能都有所提升。
近似求解
这里的近似求解也是类似的出发点,直接求解上式带约束的优化问题困难,所以 TRPO 分别对目标函数和约束条件在 θ k \theta_k θk (也即之前的 θ \theta θ,代表旧策略的参数)处采取泰勒展开进行近似,如下:
E s ∼ ν π θ k E a ∼ π θ k ( ⋅ ∣ s ) π θ ′ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) ≈ g T ( θ ′ − θ k ) \mathbb{E}{s\sim\nu^{\pi{\theta_{k}}}}\mathbb{E}{a\sim\pi{\theta_{k}}(\cdot|s)}\left\\frac{\\pi_{\\theta\^{\\prime}}(a\|s)}{\\pi_{\\theta_{k}}(a\|s)}A\^{\\pi_{\\theta_{k}}}(s,a)\\right\approx g^{T}(\theta^{\prime}-\theta_{k}) Es∼νπθkEa∼πθk(⋅∣s)πθk(a∣s)πθ′(a∣s)Aπθk(s,a)≈gT(θ′−θk)
E s ∼ ν π θ k D K L ( π θ k ( ⋅ ∣ s ) , π θ ′ ( ⋅ ∣ s ) ) ≈ 1 2 ( θ ′ − θ k ) T H ( θ ′ − θ k ) \mathbb{E}{s\sim\nu^{\pi{\theta_{k}}}}D_{KL}(\\pi_{\\theta_{k}}(\\cdot\|s),\\pi_{\\theta\^{\\prime}}(\\cdot\|s))\approx\frac{1}{2}(\theta^{\prime}-\theta_{k})^{T}H(\theta^{\prime}-\theta_{k}) Es∼νπθkDKL(πθk(⋅∣s),πθ′(⋅∣s))≈21(θ′−θk)TH(θ′−θk)
目标函数的泰勒展开:
- 我令 F = E s ∼ ν π θ k E a ∼ π θ k ( ⋅ ∣ s ) . . . F=\mathbb{E}{s\sim\nu^{\pi{\theta_{k}}}}\mathbb{E}{a\sim\pi{\theta_{k}}(\cdot|s)}... F=Es∼νπθkEa∼πθk(⋅∣s)...,则其泰勒展开大致如下: F ( θ ′ ) ≈ F ( θ k ) + ∇ θ ′ F ( θ k ) ⊤ ( θ ′ − θ k ) F(\theta^{\prime})\approx F(\theta_{k})+\nabla_{\theta^\prime} F(\theta_{k})^\top(\theta^{\prime}-\theta_{k}) F(θ′)≈F(θk)+∇θ′F(θk)⊤(θ′−θk)
- 其中,当 θ ′ = θ k \theta^{\prime} = \theta_{k} θ′=θk,重要性采样比值为1,此时有 F ( θ k ) = E s , a ∼ π k A π k ( s , a ) F(\theta_{k})=\mathbb{E}{s,a\sim\pi{k}}\leftA\^{\\pi_{k}}(s,a)\\right F(θk)=Es,a∼πkAπk(s,a),而对于任意策略,其优势函数关于动作的期望为0 ,即 E a ∼ π k A π k ( s , a ) = 0 \mathbb{E}{a\sim\pi{k}}\leftA\^{\\pi_{k}}(s,a)\\right=0 Ea∼πkAπk(s,a)=0,综上可得: F ( θ k ) = E s ∼ ν π θ k 0 = 0 F(\theta_{k})=\mathbb{E}{s\sim\nu^{\pi{\theta_{k}}}}0=0 F(θk)=Es∼νπθk0=0
- 令 g = ∇ θ ′ F ( θ k ) = ∇ θ ′ E s ∼ ν π θ k E a ∼ π θ k ( ⋅ ∣ s ) π θ ′ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) g=\nabla_{\theta^\prime}F(\theta_{k})=\nabla_{\theta^{\prime}}\mathbb{E}{s\sim\nu^{\pi{\theta_k}}}\mathbb{E}{a\sim\pi{\theta_k}(\cdot|s)}\left\\frac{\\pi_{\\theta\^{\\prime}}(a\|s)}{\\pi_{\\theta_k}(a\|s)}A\^{\\pi_{\\theta_k}}(s,a)\\right g=∇θ′F(θk)=∇θ′Es∼νπθkEa∼πθk(⋅∣s)πθk(a∣s)πθ′(a∣s)Aπθk(s,a)
约束条件的泰勒展开:
- KL 散度的定义如下: D K L ( π θ k ( ⋅ ∣ s ) , π θ ′ ( ⋅ ∣ s ) ) = E a ∼ π θ k ( ⋅ ∣ s ) log π θ k ( a ∣ s ) π θ ′ ( a ∣ s ) D_{KL}(\pi_{\theta_{k}}(\cdot|s),\pi_{\theta^{\prime}}(\cdot|s))=\mathbb{E}{a\sim\pi{\theta_{k}}(\cdot|s)}\left\\log\\frac{\\pi_{\\theta_{k}}(a\|s)}{\\pi_{\\theta\^{\\prime}}(a\|s)}\\right DKL(πθk(⋅∣s),πθ′(⋅∣s))=Ea∼πθk(⋅∣s)logπθ′(a∣s)πθk(a∣s),
通常考虑平均 KL 散度 : E s ∼ ν π θ k D K L ( π θ k , π θ ′ ) \mathbb{E}{s\sim\nu^{\pi{\theta_{k}}}}D_{KL}(\\pi_{\\theta_k},\\pi_{\\theta\^{\\prime}}) Es∼νπθkDKL(πθk,πθ′)。- 为方便说明,我们令 d ( θ ′ ) = D K L ( π θ k , π θ ′ ) d(\theta^{\prime})=D_{KL}(\pi_{\theta_k},\pi_{\theta^{\prime}}) d(θ′)=DKL(πθk,πθ′)。
则有: d ( θ ′ ) ≈ d ( θ k ) + ∇ θ ′ d ( θ k ) ⊤ ( θ ′ − θ k ) + 1 2 ( θ ′ − θ k ) ⊤ ∇ θ ′ 2 d ( θ k ) ( θ ′ − θ k ) d(\theta^{\prime})\approx d(\theta_{k})+\nabla_{\theta^{\prime}} d(\theta_{k})^\top(\theta^{\prime}-\theta_{k})+\frac{1}{2}(\theta^{\prime}-\theta_{k})^\top\nabla_{\theta^{\prime}}^2d(\theta_{k})(\theta^{\prime}-\theta_{k}) d(θ′)≈d(θk)+∇θ′d(θk)⊤(θ′−θk)+21(θ′−θk)⊤∇θ′2d(θk)(θ′−θk)。
可能你会有疑惑,约束条件不是期望的形式吗,不应该是对整个期望展开吗,为什么这里直接先对期望内部的 D K L D_{KL} DKL 展开了?因为期望是线性算子,使得我们可以先对内部进行近似展开,再求期望。- 其中,当 θ ′ = θ k \theta^{\prime} = \theta_{k} θ′=θk,新旧策略相同,则两个分布相同,故有 d ( θ k ) = 0 d(\theta_{k})=0 d(θk)=0;
- 计算一阶导:
变换一下 d ( θ ′ ) = ∑ a π θ k ( a ∣ s ) log π θ k ( a ∣ s ) − log π θ ′ ( a ∣ s ; θ ′ ) d(\theta^{\prime})=\sum_a\pi_{\theta_{k}}(a|s)\left\\log\\pi_{\\theta_{k}}(a\|s)-\\log\\pi_{\\theta\^{\\prime}}(a\|s;\\theta\^{\\prime})\\right d(θ′)=∑aπθk(a∣s)logπθk(a∣s)−logπθ′(a∣s;θ′),
上式对 θ ′ \theta^{\prime} θ′ 求导并代入 θ k \theta_{k} θk: ∇ θ ′ d ( θ k ) = − ∑ a π θ k ( a ∣ s ) ∇ θ ′ log π ( a ∣ s ; θ k ) \nabla_\theta^{\prime} d(\textcolor{blue}{\theta_{k}})=-\sum_a\pi_{\theta_{k}}(a|s)\nabla_{\theta^\prime}\log\pi(a|s;\textcolor{blue}{\theta_{k}}) ∇θ′d(θk)=−∑aπθk(a∣s)∇θ′logπ(a∣s;θk),则有 :
∑ a π θ k ( a ∣ s ) ∇ θ ′ log π ( a ∣ s ; θ k ) = ∑ a π θ k ( a ∣ s ) ∇ θ ′ π ( a ∣ s ; θ k ) π ( a ∣ s ; θ k ) = ∑ a π θ k ( a ∣ s ) ∇ θ ′ π ( a ∣ s ; θ k ) π θ k ( a ∣ s ) = ∑ a ∇ θ ′ π ( a ∣ s ; θ k ) \begin{aligned} \sum_a\pi_{\theta_{k}}(a|s)\nabla_{\theta^\prime}\log\pi(a|s;\theta_{k}) & =\sum_a\pi_{\theta_{k}}(a|s)\frac{\nabla_{\theta^{\prime}}\pi(a|s;\theta_{k})} {\pi(a|s;\theta_{k})} \\ & = \sum_a\pi_{\theta_{k}}(a|s)\frac{\nabla_{\theta^{\prime}}\pi(a|s;\theta_{k})} {\pi_{\theta_{k}}(a|s)} \\ & =\sum_a\nabla_{\theta^{\prime}}\pi(a|s;\theta_{k}) \end{aligned} a∑πθk(a∣s)∇θ′logπ(a∣s;θk)=a∑πθk(a∣s)π(a∣s;θk)∇θ′π(a∣s;θk)=a∑πθk(a∣s)πθk(a∣s)∇θ′π(a∣s;θk)=a∑∇θ′π(a∣s;θk)
而 ∑ a π ( a ∣ s ; θ ) = 1 \sum_a\pi(a|s;\theta)=1 ∑aπ(a∣s;θ)=1,对 θ \theta θ 求导就得 ∑ a ∇ θ π ( a ∣ s ; θ ) = 0 \sum_a\nabla_\theta\pi(a|s;\theta)=0 ∑a∇θπ(a∣s;θ)=0,故上式的一阶导 ∇ θ ′ d ( θ k ) = 0 \nabla_\theta^{\prime} d(\theta_{k})=0 ∇θ′d(θk)=0。- 计算二阶导:
这里用黑塞矩阵 (Hessian matrix)H 代表二阶梯度,也即 H = ∇ θ 2 D ˉ K L ( θ o l d , θ ) ∣ θ = θ o l d H=\nabla_{\theta}^{2}\bar{D}{\mathrm{KL}}(\theta{\mathrm{old}},\theta)|{\theta=\theta{\mathrm{old}}} H=∇θ2DˉKL(θold,θ)∣θ=θold
综上就是所示的约束条件的泰勒展开形式。
自此,我们讲问题的优化目标又转化为:
θ k + 1 = arg max θ ′ g T ( θ ′ − θ k ) s . t . 1 2 ( θ ′ − θ k ) T H ( θ ′ − θ k ) ≤ δ \begin{aligned} & \theta_{k+1}=\arg\max_{\theta^{\prime}}g^T(\theta^{\prime}-\theta_k) \\ & \mathrm{s.t.}\quad\frac{1}{2}(\theta^{\prime}-\theta_k)^TH(\theta^{\prime}-\theta_k)\leq\delta \end{aligned} θk+1=argθ′maxgT(θ′−θk)s.t.21(θ′−θk)TH(θ′−θk)≤δ
根据KKT条件 直接导出上述问题的解:
θ k + 1 = θ k + 2 δ g T H − 1 g H − 1 g \theta_{k+1}=\theta_k+\sqrt{\frac{2\delta}{g^TH^{-1}g}}H^{-1}g θk+1=θk+gTH−1g2δ H−1g
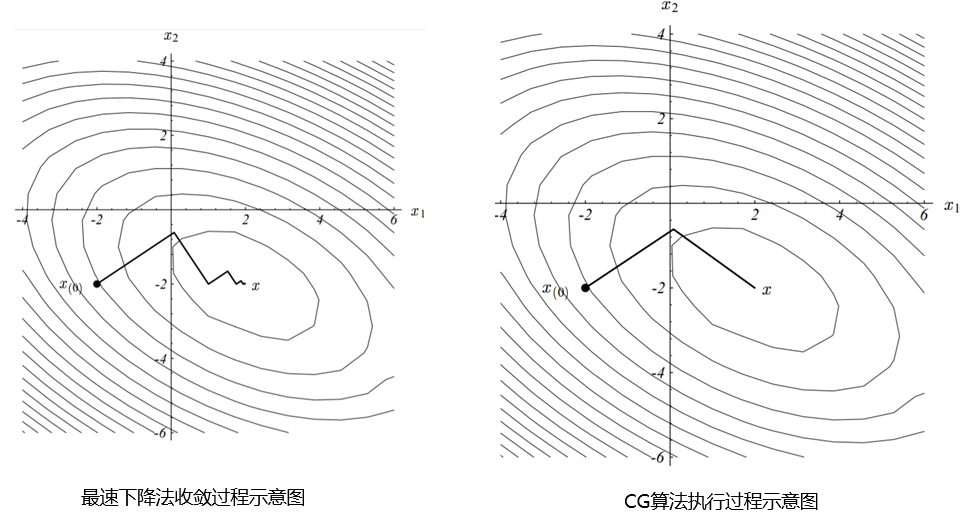
共轭梯度
共轭梯度法(Conjugate Gradients)是稀疏线性方程组迭代求解法里面最优秀的方法,是解决大型线性方程组问题最流行的迭代算法,如: A x ⃗ = b ⃗ \mathbf{A}\vec{x}=\vec{b} Ax =b 。
回到我们的问题,前面我们推导出问题的解,但存在不足:计算和存储黑塞矩阵的逆非常耗时耗内存,所以 TRPO 采取直接计算 x = H − 1 g x=H^{-1}g x=H−1g( x x x 为参数更新方向)。
假设满足 KL 距离约束的参数更新时的最大步长为 β \beta β,则根据 KL 距离约束条件,有 1 2 ( β x ) T H ( β x ) = δ \frac{1}{2}(\beta x)^{T}H(\beta x)=\delta 21(βx)TH(βx)=δ,解得 β = 2 δ x T H x \beta=\sqrt{\frac{2\delta}{x^{T}Hx}} β=xTHx2δ ,此时参数更新方式为:
θ k + 1 = θ k + 2 δ x T H x x \theta_{k+1}=\theta_k+\sqrt{\frac{2\delta}{x^THx}}x θk+1=θk+xTHx2δ x
那么,现在问题就是求这个 x x x,根据上文 TRPO 的设想,问题转化为解线性方程组: H x = g Hx=g Hx=g,实际 H 是对称正定矩阵,这么一转化就很适合用共轭梯度法求:

对于二次型优化问题,我们熟悉的梯度下降法是通过沿着当前点 x 0 x_0 x0 的梯度方向寻找一个新点 x 1 x_1 x1,在点 x 1 x_1 x1 处的梯度跟点 x 0 x_0 x0 处的梯度刚好正交 ,从而确定当前点 x 0 x_0 x0 的前进步长 的;而共轭梯度法是构建一组线性无关向量(空间维度决定这组向量有多少个,如2维就2个无关向量)作为搜索方向 (前进方向),显见,这组无关向量肯定能表示出当前点 x 0 x_0 x0 与目标值点 x x x 间的误差向量(也即误差向量是这些无关向量的线性组合,每个搜索向量都是误差向量的分量),而 CG 就是通过每次迭代时消除搜索向量(也即消除误差向量的分量 )达到目标,从而最优化问题。
上述伪代码流程中,for 循环里前三个迭代式就是类似梯度下降法的思想,而不同于梯度下降的是其利用的是搜索向量 p k p_k pk 而不完全是梯度,后两个迭代式就是在对搜索向量 p k p_k pk 进行迭代更新的。
其实,粗糙得说,CG 跟梯度下降都是在求梯度,只是二者对步长的确定不同,因为二者的迭代路径其实通过平移后一致:
线性搜索
其实就是对抗之前近似操作的误差,让更新的步长更可靠
问题不足:前面对求解问题用到泰勒展开近似,而非精确解,因此,按理论的 2 δ x T H x \sqrt{\frac{2\delta}{x^THx}} xTHx2δ 步长去更新参数,可能导致 θ ′ \theta^{\prime} θ′ 未必优于 θ \theta θ,或未必满足 KL散度约束。
改进:TRPO 在每次迭代的最后进行一次线性搜索(Line Search),以确保找到满足条件。
具体讲,更新方式修改为 θ k + 1 = θ k + α i 2 δ x T H x x \theta_{k+1}=\theta_k+\alpha^i\sqrt{\frac{2\delta}{x^THx}}x θk+1=θk+αixTHx2δ x,我们目标是找到一个最小的非负正数 i i i,使得 θ k + 1 \theta_{k+1} θk+1 既能满足 KL散度约束,又能提升目标函数,即 L θ ( θ ′ ) ≥ L θ ( θ k ) L_\theta(\theta^{\prime})\geq L_\theta(\theta_k) Lθ(θ′)≥Lθ(θk)。
体现在代码就是计算出来然后作比较:
python
if new_obj > old_obj and kl_div < self.kl_constraint:
return new_para广义优势估计
填一下优势函数 A A A 的坑的...
之前推导那么多,还有一个漏了,就是优势函数,求梯度 g g g 需要到的。那就是如何去估计 A A A 的问题,目前常用的一种方法为广义优势估计(Generalized Advantage Estimation,GAE)。
用 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t=r_t+\gamma V(s_{t+1})-V(s_t) δt=rt+γV(st+1)−V(st) 表示时序差分误差,根据多步时序差分的思想,有:
A t ( 1 ) = δ t = − V ( s t ) + r t + γ V ( s t + 1 ) A t ( 2 ) = δ t + γ δ t + 1 = − V ( s t ) + r t + γ r t + 1 + γ 2 V ( s t + 2 ) A t ( 3 ) = δ t + γ δ t + 1 + γ 2 δ t + 2 = − V ( s t ) + r t + γ r t + 1 + γ 2 r t + 2 + γ 3 V ( s t + 3 ) : A t ( k ) = ∑ l = 0 k − 1 γ l δ t + l = − V ( s t ) + r t + γ r t + 1 + ... + γ k − 1 r t + k − 1 + γ k V ( s t + k ) \begin{aligned} & A_{t}^{(1)}=\delta_{t} & & =-V(s_t)+r_t+\gamma V(s_{t+1}) \\ & A_{t}^{(2)}=\delta_t+\gamma\delta_{t+1} & & =-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2V(s_{t+2}) \\ & A_{t}^{(3)}=\delta_t+\gamma\delta_{t+1}+\gamma^2\delta_{t+2} & & =-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2r_{t+2}+\gamma^3V(s_{t+3}) \\ & : & & \\ & A_t^{(k)}=\sum_{l=0}^{k-1}\gamma^l\delta_{t+l} & & =-V(s_t)+r_t+\gamma r_{t+1}+\ldots+\gamma^{k-1}r_{t+k-1}+\gamma^kV(s_{t+k}) \end{aligned} At(1)=δtAt(2)=δt+γδt+1At(3)=δt+γδt+1+γ2δt+2:At(k)=l=0∑k−1γlδt+l=−V(st)+rt+γV(st+1)=−V(st)+rt+γrt+1+γ2V(st+2)=−V(st)+rt+γrt+1+γ2rt+2+γ3V(st+3)=−V(st)+rt+γrt+1+...+γk−1rt+k−1+γkV(st+k)
k k k:理解为步数
GAE 将这些不同步数的优势估计进行指数加权平均:
A t G A E = ( 1 − λ ) ( A t ( 1 ) + λ A t ( 2 ) + λ 2 A t ( 3 ) + ⋯ ) = ( 1 − λ ) ( δ t + λ ( δ t + γ δ t + 1 ) + λ 2 ( δ t + γ δ t + 1 + γ 2 δ t + 2 ) + ⋯ ) = ( 1 − λ ) ( δ ( 1 + λ + λ 2 + ⋯ ) + γ δ t + 1 ( λ + λ 2 + λ 3 + ⋯ ) + γ 2 = ( 1 − λ ) ( δ t 1 1 − λ + γ δ t + 1 λ 1 − λ + γ 2 δ t + 2 λ 2 1 − λ + ⋯ ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l \begin{aligned} A_{t}^{GAE} & =(1-\lambda)(A_t^{(1)}+\lambda A_t^{(2)}+\lambda^2A_t^{(3)}+\cdots) \\ & =(1-\lambda)(\delta_t+\lambda(\delta_t+\gamma\delta_{t+1})+\lambda^2(\delta_t+\gamma\delta_{t+1}+\gamma^2\delta_{t+2})+\cdots) \\ & =(1-\lambda)(\delta(1+\lambda+\lambda^2+\cdots)+\gamma\delta_{t+1}(\lambda+\lambda^2+\lambda^3+\cdots)+\gamma^2 \\ & =(1-\lambda)\left(\delta_t\frac{1}{1-\lambda}+\gamma\delta_{t+1}\frac{\lambda}{1-\lambda}+\gamma^2\delta_{t+2}\frac{\lambda^2}{1-\lambda}+\cdots\right) \\ & =\sum_{l=0}^\infty(\gamma\lambda)^l\delta_{t+l} \end{aligned} AtGAE=(1−λ)(At(1)+λAt(2)+λ2At(3)+⋯)=(1−λ)(δt+λ(δt+γδt+1)+λ2(δt+γδt+1+γ2δt+2)+⋯)=(1−λ)(δ(1+λ+λ2+⋯)+γδt+1(λ+λ2+λ3+⋯)+γ2=(1−λ)(δt1−λ1+γδt+11−λλ+γ2δt+21−λλ2+⋯)=l=0∑∞(γλ)lδt+l
其中, λ ∈ 0 , 1 \lambda\in0,1 λ∈0,1 即权重,因为 1 + λ + λ 2 + λ 3 + ⋯ = 1 1 − λ 1+\lambda+\lambda^2+\lambda^3+\cdots=\frac{1}{1-\lambda} 1+λ+λ2+λ3+⋯=1−λ1,所以整体需要除以总权重之和,也即乘 ( 1 − λ ) (1-\lambda) (1−λ)。
- 代入 0 时:
A t ( G A E ) = ∑ i = 0 ∞ ( 0 ) i δ t + i = ( 1 ) ∗ δ t + 0 + 0 + 0 + . . . = δ t = r t + γ V ( s t + 1 ) − V ( s t ) A_t^{(GAE)}=\sum_{i=0}^\infty(0)^i\delta_{t+i}=(1)*\delta_{t+0}+0+0+...=\delta_t=r_t+\gamma V(s_{t+1})-V(s_t) At(GAE)=∑i=0∞(0)iδt+i=(1)∗δt+0+0+0+...=δt=rt+γV(st+1)−V(st)
此时,优势函数的估计完全依赖于当前的单步奖励 r t r_t rt 和下一个状态的价值估计 V ( s t + 1 ) V(s_{t+1}) V(st+1)。其估计严重依赖 V V V 的准确性,但只涉及一次奖励采样和一个价值函数估计,引入的随机性较少,总结就是高偏差,低方差。- 代入 1 时:
A t ( G A E ) = ∑ i = 0 ∞ γ i δ t + i = − V ( s t ) + ∑ i = 0 ∞ γ i r t + i A_t^{(GAE)}=\sum_{i=0}^\infty\gamma^i\delta_{t+i}=-V(s_t)+\sum_{i=0}^\infty\gamma^ir_{t+i} At(GAE)=∑i=0∞γiδt+i=−V(st)+∑i=0∞γirt+i(中间推导利用上文 A t ( k ) = ∑ l = 0 k − 1 γ l δ t + l A_t^{(k)}=\sum_{l=0}^{k-1}\gamma^l\delta_{t+l} At(k)=∑l=0k−1γlδt+l)
此时,优势函数的估计依赖于从当前时刻到回合结束的所有实际奖励。其估计基于大量真实的奖励信号,而不是仅仅依赖价值函数的预测,因此它更接近真实的优势值,但由于累计了未来很多步的随机奖励,而这些奖励本身是采样的、有随机性的,所以最终估计值的方差会很高,总结就是低偏差,高方差。GAE 的巧妙之处就在于,通过设置 λ ∈ 0 , 1 \lambda\in0,1 λ∈0,1(例如 0.95),我们可以在两种极端之间找到一个理想的折中点,既获得了蒙特卡洛方法低偏差、更准确的优势,又利用了时序差分方法低方差、更稳定的优点。
TRPO 算法流程(伪代码)
最后,给出 TRPO 的全部过程:

可见,TRPO 算法属于在线策略学习方法,每次策略训练仅使用上一轮策略采样的数据,是基于策略的深度强化学习算法中十分有代表性的工作之一。
PPO 算法
TRPO 很强,但计算好复杂,简单点才是美,PPO(Proximal Policy Optimization,近端策略优化) 就是简化了 TRPO 的计算,同样的,TRPO 的优化目标:
max θ E s ∼ ν π θ k E a ∼ π θ k ( ⋅ ∣ s ) π θ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) s . t . E s ∼ ν π θ k D KL ( π θ k ( ⋅ ∣ s ) , π θ ( ⋅ ∣ s ) ) ≤ δ \begin{split}\max_{\theta}&\quad\mathbb{E}{\bm{s} \sim\nu^{\pi{\theta_{\textit{k}}}}}\mathbb{E}{\bm{a}\sim\pi{\theta_{\textit {k}}}(\cdot|\bm{s})}\left\\frac{\\pi_{\\theta}(\\bm{a}\|\\bm{s})}{\\pi_{\\theta_{\\textit {k}}}(\\bm{a}\|\\bm{s})}\\bm{A}\^{\\pi_{\\theta_{\\textit{k}}}}(\\bm{s},\\bm{a})\\right \\ \mathrm{s.t.}&\quad\mathbb{E}{\bm{s}\sim\nu^{\pi{ \theta_{\textit{k}}}}}D_{\\textit{KL}}(\\pi_{\\theta_{\\textit{k}}}(\\cdot\|\\bm{s}),\\pi_{\\theta}(\\cdot\|\\bm{s}))\leq\delta\end{split} θmaxs.t.Es∼νπθkEa∼πθk(⋅∣s)πθk(a∣s)πθ(a∣s)Aπθk(s,a)Es∼νπθkDKL(πθk(⋅∣s),πθ(⋅∣s))≤δ
PPO 使用更为简单的解法,具体而言,PPO 有两种形式:① PPO-惩罚,② PPO-截断
PPO-惩罚(PPO-Penalty)
PPO-Penalty 使用拉格朗日乘数法 直接将 KL 散度的限制放到目标函数中,使得成为一个无约束的优化问题,然后迭代更新 β \beta β,所以惩罚其实就是指减去了 β D K L \beta D_{KL} βDKL,优化目标转化为:
arg max θ E s ∼ ν ∗ θ k E a ∼ π θ k ( ⋅ ∣ s ) π θ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) − β D K L \[ π θ k ( ⋅ ∣ s ) , π θ ( ⋅ ∣ s ) ] \arg\max_{\theta}\mathbb{E}{s\sim\nu}*{\theta_{k}}\mathbb{E}{a\sim\pi{\theta_{k}}(\cdot|s)}\left\\frac{\\pi_{\\theta}(a\|s)}{\\pi_{\\theta_{k}}(a\|s)}A\^{\\pi_{\\theta_{k}}}(s,a)-\\beta D_{KL}\[\\pi_{\\theta_{k}}(\\cdot\|s),\\pi_{\\theta}(\\cdot\|s)\right] argθmaxEs∼ν∗θkEa∼πθk(⋅∣s)πθk(a∣s)πθ(a∣s)Aπθk(s,a)−βDKL\[πθk(⋅∣s),πθ(⋅∣s)]
令 d k = D K L ν π θ k ( π θ k , π θ ) d_{k}=D_{KL}^{\nu^{\pi_{\theta_{k}}}}(\pi_{\theta_{k}},\pi_{\theta}) dk=DKLνπθk(πθk,πθ)(旧策略访问状态分布下,新旧策略的 KL 散度),预设超参数 δ \delta δ(用于限制学习策略和之前一轮策略的差距),规定参数 β \beta β 更新规则:
- 如果 d k < δ / 1.5 d_{k}<\delta/1.5 dk<δ/1.5,那么 β k + 1 = β k / 2 \beta_{k+1}=\beta_{k}/2 βk+1=βk/2
- 如果 d k > δ × 1.5 d_{k}>\delta\times1.5 dk>δ×1.5,那么 β k + 1 = β k × 2 \beta_{k+1}=\beta_{k}\times2 βk+1=βk×2
- 否则 β k + 1 = β k \beta_{k+1}=\beta_{k} βk+1=βk
可知,PPO-Penalty 采用自适应调整 β \beta β 的方法,使得 KL 散度 d k d_{k} dk 维持在某个目标值 δ \delta δ 附近。
设想如果固定 β \beta β 为某个值会有什么问题?
- 若 β \beta β 过大,惩罚就过强,策略更新会十分保守,学习训练缓慢
- 若 β \beta β 过小,惩罚就太弱,策略更新幅度可能过大,训练不稳定
分析一下更新条件:
- 如果 d k < δ / 1.5 d_{k}<\delta/1.5 dk<δ/1.5,说明 KL 散度偏小,策略差距小,可以允许更大的更新幅度,所以可以减弱惩罚,即 β k + 1 = β k / 2 \beta_{k+1}=\beta_{k}/2 βk+1=βk/2;
- 如果 d k > δ × 1.5 d_{k}>\delta\times1.5 dk>δ×1.5,说明 KL 散度偏大,策略差距大,需要限制较小的更新幅度以防止不稳定,所以应该加强惩罚,即 β k + 1 = β k × 2 \beta_{k+1}=\beta_{k}\times2 βk+1=βk×2;
- 否则 δ / 1.5 ≤ d k ≤ δ × 1.5 \delta/1.5\leq d_k\leq\delta\times1.5 δ/1.5≤dk≤δ×1.5,KL 散度在可接受范围内, β \beta β 不变。
可见,PPO-Penalty 的设计原理是同样是限制新旧策略的差距在合理的范围内 ,体现在让 d k d_k dk 靠近 δ \delta δ,利用比例控制思想,本质还是反馈控制:
- KL 太小 → 惩罚减弱 → L θ ( θ ′ ) L_\theta(\theta^{\prime}) Lθ(θ′) 下次的更新步长可能变大 → KL 增加;
- KL 太大 → 惩罚增强 → L θ ( θ ′ ) L_\theta(\theta^{\prime}) Lθ(θ′) 下次的更新步长可能变小 → KL 减小。
PPO-截断(PPO-Clip)
PPO-Clip 是 PPO 更常用的形式,它直接用裁剪比率来限制更新幅度:
arg max E s ∼ ν E a ∼ π s k ( ⋅ ∣ s ) min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A π θ k ( s , a ) , c l i p ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A π θ k ( s , a ) ) \arg\max\mathbb{E}{s\sim\nu}\mathbb{E}{a\sim\pi_{s_k}(\cdot|s)}\left\\min\\left(\\frac{\\pi_\\theta(a\|s)}{\\pi_{\\theta_k}(a\|s)}A\^{\\pi_{\\theta_k}}(s,a),\\mathrm{clip}\\left(\\frac{\\pi_\\theta(a\|s)}{\\pi_{\\theta_k}(a\|s)},1-\\epsilon,1+\\epsilon\\right)A\^{\\pi_{\\theta_k}}(s,a)\\right)\\right argmaxEs∼νEa∼πsk(⋅∣s)min(πθk(a∣s)πθ(a∣s)Aπθk(s,a),clip(πθk(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aπθk(s,a))
其中, c l i p ( x , l , r ) : = max ( min ( x , r ) , l ) \mathrm{clip}(x,l,r):=\max(\min(x,r),l) clip(x,l,r):=max(min(x,r),l),即把 x x x 限制在 l , r l,r l,r 内,而 ϵ \epsilon ϵ 是一个超参数,由式子可知:
- 当 A π θ k ( s , a ) > 0 A^{\pi_{\theta_{k}}}(s,a)>0 Aπθk(s,a)>0,代表好动作,鼓励更新,但别太过头,最多更新 1 + ϵ 1+\epsilon 1+ϵ 即可;
- 当 A π θ k ( s , a ) < 0 A^{\pi_{\theta_{k}}}(s,a)<0 Aπθk(s,a)<0,代表坏动作,抑制更新,但也别一棍子打死,最低抑制到 1 − ϵ 1-\epsilon 1−ϵ 即可。
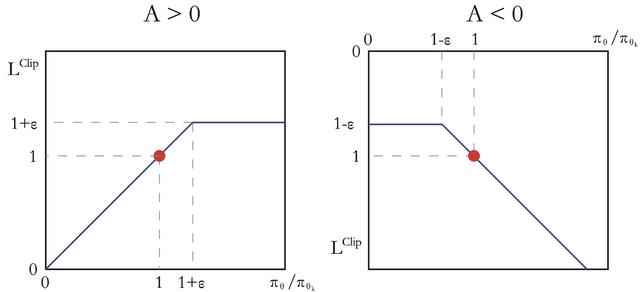
上图是 PPO-Clip 的示意图,很形象的说明了截断操作。
可见,PPO-Clip 的设计原理是同样也是限制新旧策略的差距在合理的范围内 ,而它体现在使用超参数 ϵ \epsilon ϵ 配合截断比率,实现更简单,效果更稳定,相比之前的复杂计算、麻烦的迭代,PPO-Clip 更加巧妙和简洁高效!
小结
小结一下:
| PPO-Penalty | PPO-Clip | |
|---|---|---|
| 约束方式 | 在目标函数中添加自适应KL惩罚项 | 在目标函数中直接采用截断比率 |
| 超参数 | 初始惩罚系数 β \beta β,KL限制 δ \delta δ | 截断范围 ϵ \epsilon ϵ |
| 调节机制 | 根据KL散度动态调整 β \beta β | 固定的 ϵ \epsilon ϵ,通过目标函数设计内在约束 |
| 优点 | 理论上能更精确地控制KL散度 | 实现更简单,效果更稳定,是更常用的版本 |
最后,值得说明的是,TRPO 和 PPO 都属于在线策略学习算法,即使优化目标中包含重要性采样的过程,但其实只用到了上一轮策略的数据,而非过去所有策略的数据。
参考资料