-
作者:Minwoo Kim, Geunsik Bae, Jinwoo Lee, Woojae Shin, Changseung Kim, Myong-Yol Choi, Heejung Shin, Hyondong Oh
-
单位:韩国蔚山科学技术院机械工程系
-
论文标题:RAPID: Robust and Agile Planner Using Inverse Reinforcement Learning for Vision-Based Drone Navigation
主要贡献
-
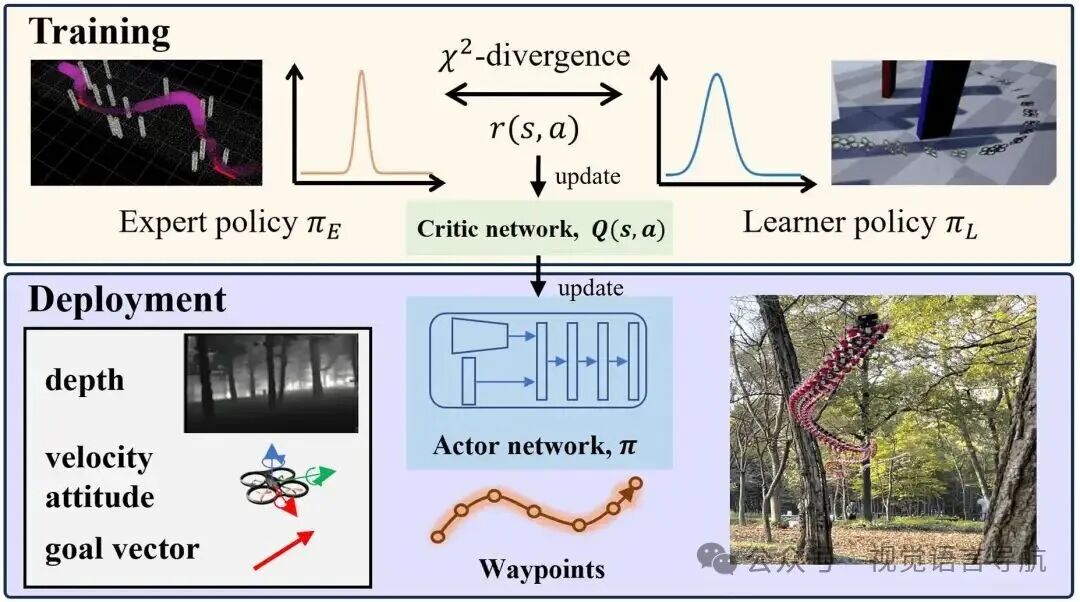
提出了基于逆强化学习的学习型视觉规划器RAPID,用于复杂环境中的敏捷无人机飞行,能够在毫秒级生成无碰撞的航点,无需单独的感知、建图和规划模块,可直接应用于现实场景,无需额外训练或调整。
-
开发了基于逆软Q学习的框架,用于高速视觉导航,无需手动设计奖励函数,通过针对高速场景的吸收态处理,实现鲁棒且样本高效的策略学习。
-
引入辅助自编码器损失函数,减轻高维视觉输入的复杂性,提高学习效率。
-
通过在训练中考虑控制器跟踪误差,减少仿真到现实(sim-to-real)的差距,验证了在自然和城市环境中以平均速度7 m/s进行高速飞行实验的可行性。
研究背景
-
无人机(UAV)因其敏捷性和紧凑性,在灾难救援、城市室内探索和目标跟踪等领域具有广泛应用前景,但在复杂环境中(如森林和工厂)利用其敏捷性仍面临感知、控制和实时运动规划的挑战。
-
传统的视觉导航方法依赖于模块化架构,将感知、建图和规划分开,虽然具有可解释性和易于与其他模块集成的优点,但计算成本高、延迟大,不适合敏捷无人机飞行。而端到端的神经网络学习方法将感知、建图和规划集成到一个过程中,减少了延迟,能够实现快速实时规划。
-
行为克隆(BC)和强化学习(RL)是常用的视觉导航学习方法,但BC容易因专家模仿有限而出现累积误差,RL则面临奖励函数设计困难和样本效率低下的问题。逆强化学习(IRL)通过从专家行为中学习潜在奖励来解决这些问题,但在视觉导航任务中应用IRL仍面临诸多挑战,如高维视觉信息处理、实时可行性检查和精确飞行姿态控制等。
方法
基础知识
RAPID 将视觉导航问题建模为无限时域马尔可夫决策过程(MDP),其组成部分包括状态 、动作 、初始状态分布 、转移概率 、奖励函数 和折扣因子 。策略 是一个随机策略,表示在给定状态 时采取动作 的概率分布。数据集分为专家策略数据 和学习者策略数据 。
状态和动作
-
状态:
-
状态空间 包括深度图像 、速度 、姿态四元数 和相对目标向量 。
-
为了缩小仿真与现实环境之间的差距,使用半全局匹配(SGM)算法生成类似真实深度图像的立体深度图像用于训练。
-
采用低分辨率图像(64×64)以减少过拟合并提高鲁棒性。
-

-
动作:
-
动作 包含 个航路点,每个航路点由相对距离 和相对角度 定义,使用柱坐标系表示以减少动作空间的复杂性。
-
将柱坐标系中的航路点转换为笛卡尔坐标系中的绝对位置,最终生成的动作 是 个航路点的集合。
-
设置 ,时间间隔 秒。
-
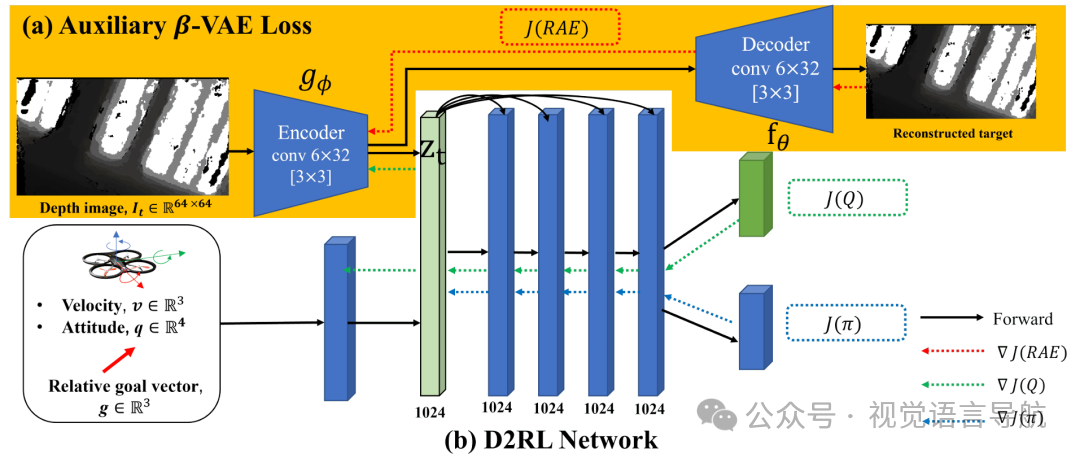
样本高效训练与图像重建
-
辅助自编码器损失函数:
-
使用 -VAE学习紧凑的状态表示,将高维输入嵌入到低维潜在向量 中,同时减轻噪声并提高视觉数据处理的鲁棒性。
-
自编码器由卷积编码器 和反卷积解码器 组成,目标函数 包括重建误差、潜在向量的 正则化和解码器参数的权重衰减。
-
为了避免策略网络的梯度更新影响编码器,只允许critic网络的梯度更新共享的编码器参数。
-
采用更快的 Polyak 平均率更新目标 Q 函数的编码器参数,以解决梯度传播延迟的问题。
-
-
跳跃连接网络:
-
采用 D2RL 网络结构,通过跳跃连接保留重要输入信息,实现更快的收敛速度。
-
使用正交初始化和 delta-正交初始化分别初始化全连接层和卷积层的权重,以提高学习过程的稳定性。
-
隐式奖励的策略学习
-
学习隐式奖励:
-
使用最小二乘逆 Q 学习(LS-IQ)算法,通过逆软 Q 学习(IQ-learning)引入逆贝尔曼算子 ,将奖励函数表示为 Q 函数的形式,从而无需单独训练奖励网络。
-
通过引入正则化项 来稳定学习过程,该正则化项结合了专家数据和学习者数据的分布,以平衡两者的贡献。
-
对于吸收态(如目标或碰撞状态),采用引导式更新和分析计算相结合的方法来处理,提高稳定性。
-
设置吸收态奖励值 和 ,以避免在终端状态获得过高奖励,增强障碍物规避性能。
-
-
SAC更新:
-
使用soft actor-critic(SAC)方法更新策略,通过固定 Q 函数来近似最优策略。
-
策略更新公式为 ,其中 是温度参数,用于控制探索与利用的权衡。
-
轨迹生成与控制
-
轨迹生成:
-
将离散的航路点转换为连续可微的轨迹,轨迹 可以表示为沿每个轴的多项式函数。
-
为了确保轨迹的平滑性,多项式段的起点和终点必须与指定的航路点一致,并且在中间航路点处保持导数的连续性。
-
通过求解优化问题来最小化加速度平方的积分,生成轨迹,采用四阶多项式并确保在航路点处速度连续。
-
-
轨迹跟踪控制:
-
使用几何控制器进行轨迹跟踪,该控制器通过直接应用刚体动力学的几何原理来确保跟踪精度和稳定性,计算出必要的机体角速度和推力指令。
-
几何控制器的低延迟和易于实现的特点使其更适合于学习过程,与模型预测控制(MPC)相比,几何控制器的计算开销更低。
-
仿真
数据获取与训练

-
数据获取:
-
环境设置:使用 AirSim 模拟器生成多样化的训练环境,包括树木、圆锥体、立方体、球体等障碍物,以增强模型的泛化能力。图 6 展示了不同训练环境的示例。
-
专家数据生成:采用基于运动原语的专家规划器生成全局轨迹。首先收集环境的点云数据,构建全局轨迹,然后根据障碍物成本采样局部轨迹。全局轨迹是从起点到终点的完整路径,局部轨迹是全局轨迹的细化片段。
-
参数设置:全局轨迹的平均速度设置为 7m/s,最大速度和加速度分别限制为 8m/s 和 10m/s²。为了增加轨迹多样性,对滚转角和偏航角施加随机扰动(最大 0.3 弧度)。共生成 1,800 条全局轨迹,覆盖 600 个训练地图,最终收集到约 10 万个局部轨迹及其对应的状态-动作数据。
-
-
训练:
-
领域随机化:为了增强模型的泛化能力,训练过程中应用了多种随机化技术。例如,每次训练时随机选择起始位置,并在控制器增益中加入约 10% 的噪声。此外,还使用了图像随机打乱技术以增强编码器的鲁棒性。
-
地图更新:每 5 个训练周期更换一次地图,以增加环境的多样性。
-
训练终止条件:如果无人机与障碍物碰撞或到达目标点,则终止当前训练周期。
-
仿真结果
-
基线方法:将 RAPID 与以下基线方法进行比较:
-
行为克隆(BC):使用预训练的 MobileNetV3 模型,具有相同的网络结构。
-
最小二乘逆 Q 学习(LS-IQ):与 RAPID 具有相同的网络结构,但吸收态奖励更新规则不同。
-
AGILE:基于 DAgger 的规划器,使用松弛的赢者通吃(R-WTA)损失函数。
-
-
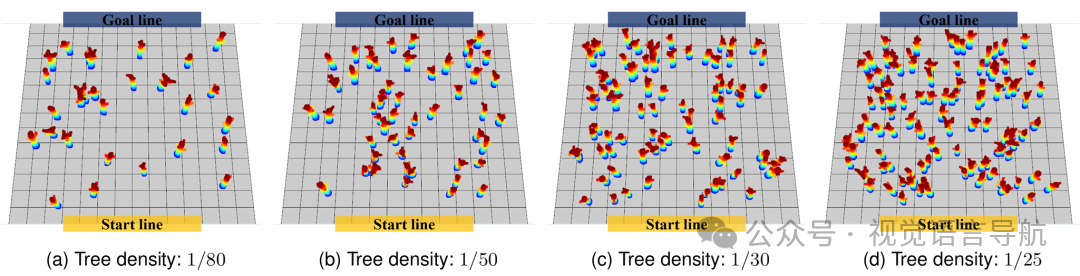
实验设置:在不同树密度的测试环境中进行实验,树密度表示单位面积内的树木数量。树木被随机倾斜并赋予随机方向,以增加测试环境的复杂性。树木的尺寸根据连续均匀随机分布进行随机化,范围为 ,测试地图大小为 50m×50m。
-
测试环境:测试环境的树密度分别为 1/80、1/50、1/30 和 1/25(单位:树木/平方米)。图 7 展示了不同树密度的测试环境。
-
评估指标:包括任务进度(MP,从起点到目标点的进度)、速度和飞行距离。
-
实验结果:
-
BC:由于过拟合和累积误差,性能最低。在复杂环境中,其泛化能力受限。
-
LS-IQ:性能优于 BC,但在高树密度环境中,优先考虑高速飞行而牺牲了碰撞规避能力。
-
AGILE:在低树密度环境中表现良好,但在高树密度环境中,其性能显著下降,且对控制器跟踪误差的适应性较差。
-
RAPID:在所有测试条件下均表现出最佳的碰撞规避性能,任务进度和速度均优于其他方法。表 I 和图 8 展示了详细的定量结果。
-

实验
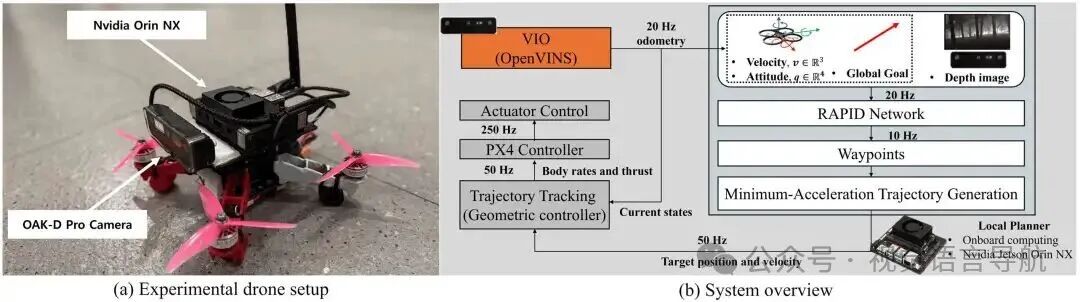
硬件设置
-
无人机设计:
-
为了实现高速飞行,设计了一款类似竞速无人机的轻量化无人机,配备 Velox 2550kV 电机和 Gemfan Hurricane 51466 螺旋桨,整体重量为 1.1kg,推重比达到 3.57,能够进行高速和敏捷机动。
-
机载计算单元采用 NVIDIA Jetson Orin NX,该计算板轻巧且紧凑,能够快速执行神经网络部署。
-
使用 Oak-D Pro 深度相机进行深度测量和视觉惯性里程计(VIO),相机配备全局快门镜头,提供 80°×55° 的立体图像视野和 72°×50° 的立体深度图像视野,图像和深度图像的采集频率均为 20Hz。
-

-
处理延迟测试:
- 上表显示了 RAPID 模型与 AGILE 模型的处理延迟对比。尽管 RAPID 的参数数量更多,但由于其浮点运算次数(FLOPS)更低,因此在 CPU 和 GPU 推理速度上均优于 AGILE,推理时间比 AGILE 快 6 倍以上。
系统概述
-
系统模块:
-
VIO 模块:使用 OpenVINS 进行稳定高速飞行,该模块结合图像状态信息和惯性测量单元(IMU)数据,深度相机以 20Hz 的频率运行,IMU 测量数据以 200Hz 的频率收集,最终将局部里程计信息以 20Hz 的频率发布到 PX4 自动飞行控制系统。
-
局部规划器模块:RAPID 方法以 10Hz 的频率接收深度图像、速度、姿态和目标方向向量,并生成无碰撞航路点。生成的航路点通过最小加速度轨迹生成方法转换为连续轨迹,然后以 50Hz 的频率对轨迹进行采样,以获得目标位置和速度指令。
-
控制器模块:几何控制器根据目标位置和速度指令计算必要的机体角速度和推力指令,以跟踪目标轨迹。这些指令以 250Hz 的频率发送到 PX4 控制器,控制无人机的执行器。
-
-
系统集成:
- 整个系统包括 VIO、局部规划器和控制器三个模块,如图 9(b) 所示。系统能够实现从视觉输入到轨迹生成和跟踪的完整流程,确保无人机在复杂环境中进行高速飞行。
实验结果
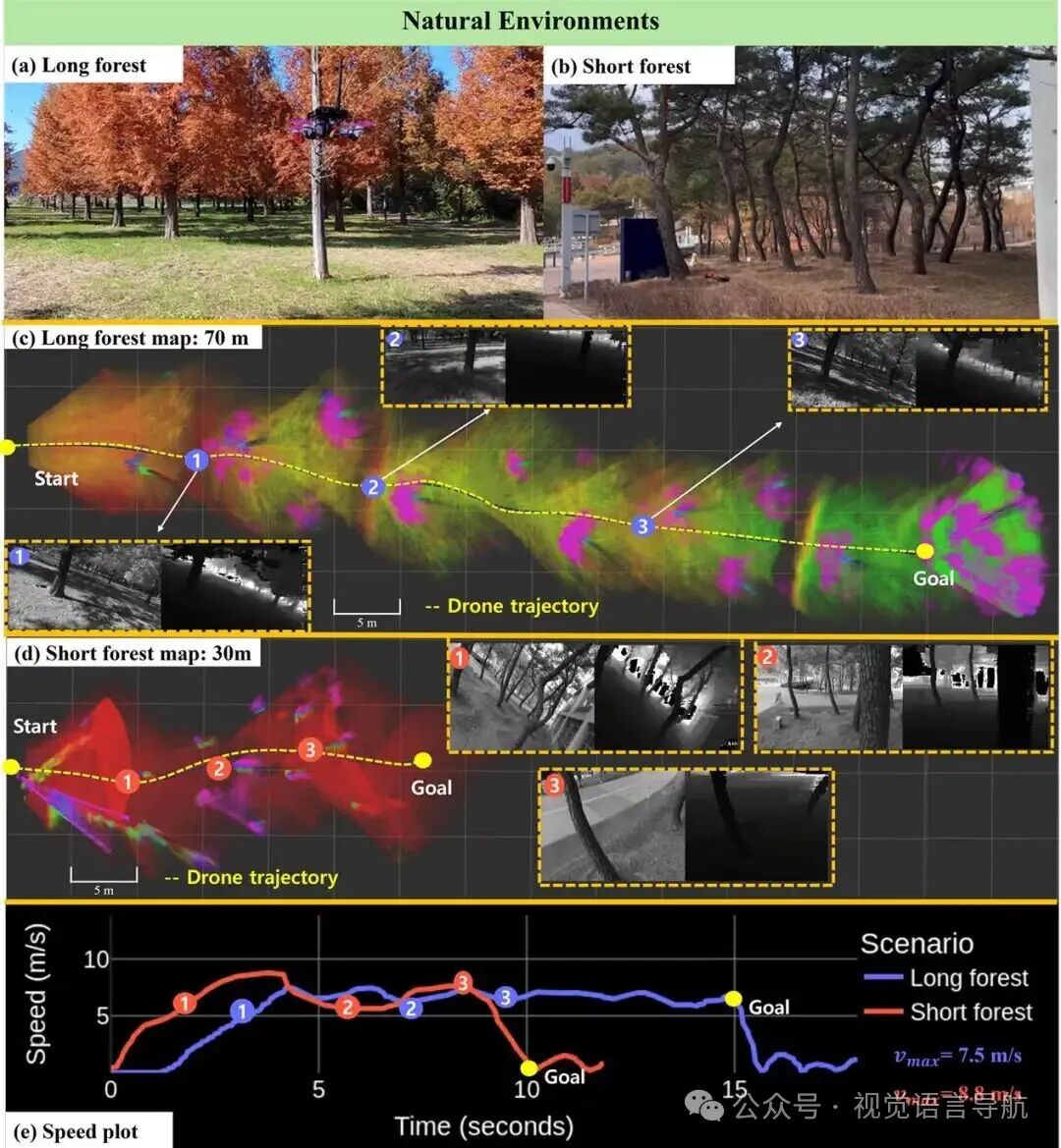
-
自然环境实验:
-
长森林场景:树木间距为 5 米,目标点距离 60 米。实验中,无人机从悬停状态开始,沿着轨迹飞行,成功避开沿途障碍物,最大速度达到 7.5m/s。
-
短森林场景:树木密集排列,间距为 2 米,目标点距离 30 米。为了测试无人机在更复杂环境中的飞行能力,将航路点生成时间缩短至 0.9 秒,无人机成功到达目标点,最大速度达到 8.8m/s。
-
观察现象:尽管训练数据集中的速度为 7m/s,但 IRL 训练使策略能够表现出加速和减速行为,甚至在接近障碍物时显著降低速度以执行避障动作,这表明 IRL 方法能够超越简单模仿专家行为,有效捕捉避障意图。
-
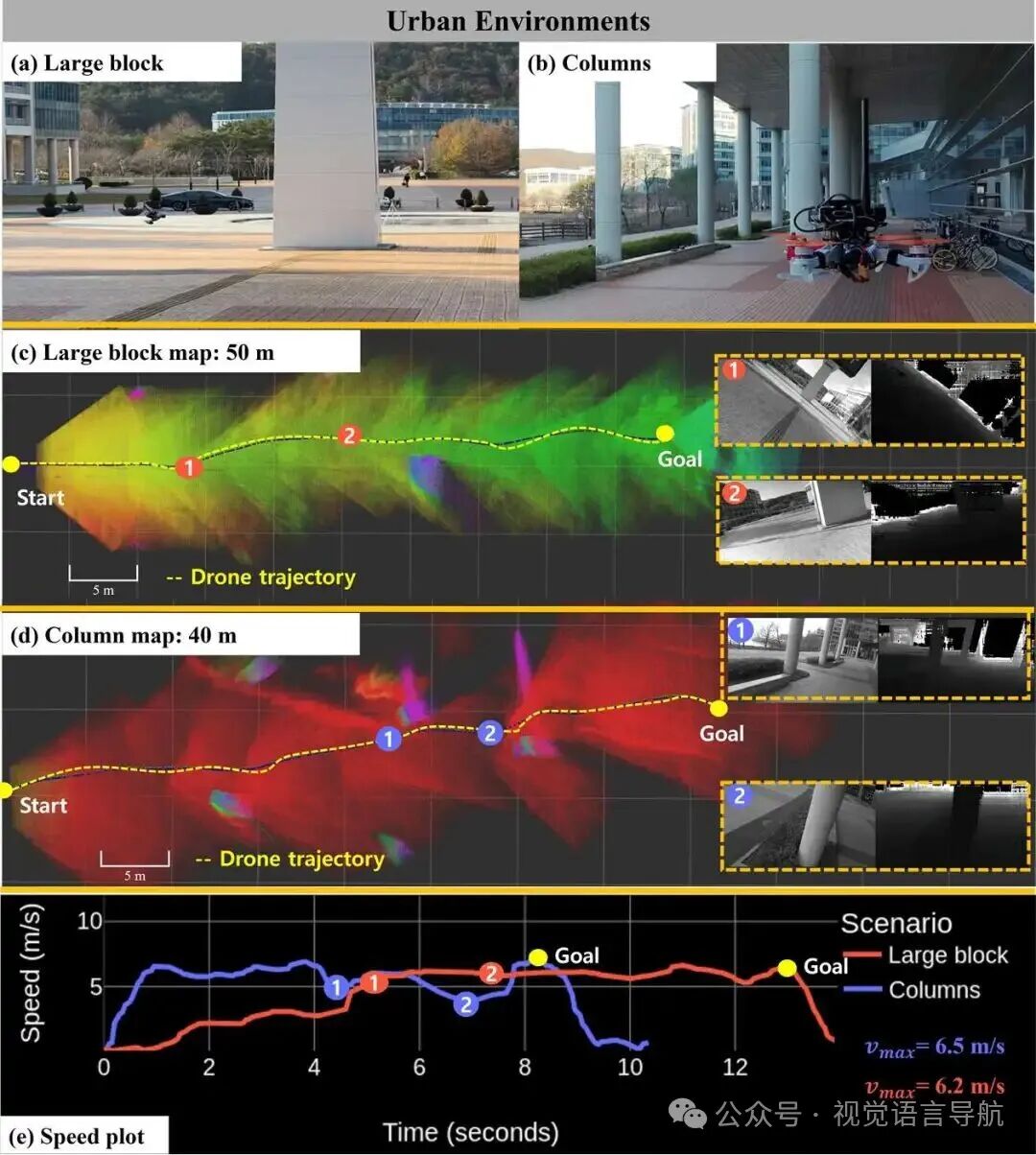
-
城市环境实验:
-
大块障碍物场景:障碍物几何形状简单但体积较大。为了降低安全风险,将无人机速度降低至平均 6m/s。无人机成功从起点生成避障路径并到达目的地,最大速度达到 6.5m/s。
-
柱状障碍物场景:包含六个大型柱状障碍物。无人机在飞行过程中减速以避开障碍物,然后再次加速,最终成功到达目的地,最大速度达到 6.2m/s。
-
实验结论:尽管模型仅在仿真环境中训练,但在真实世界场景中表现出良好的性能,与仿真环境相比几乎没有性能下降。实验结果表明,模型在类似仿真设置的树环境中部分弥合了仿真到现实的差距,并且在城市环境中能够泛化到新的障碍物形状,展现出对多样化真实世界环境的适应能力。
-
结论与未来工作
-
结论:
-
RAPID作为一种基于IRL的无人机视觉规划器,在复杂环境中的高速视觉导航方面表现出色,通过整合视觉输入和规划,能够实时生成无碰撞的航点,并在仿真和现实世界场景中均展现出优越的性能。
-
尽管RAPID取得了良好的效果,但仍存在一些局限性,如缺乏时间感知能力导致在面对大型障碍物时容易陷入局部最小值;在探索过程中可能会生成不可行的轨迹,影响Q函数的收敛;专家数据集的不完整性可能导致模型在遇到远离专家轨迹的状态时无法找到解决方案;sim-to-real差距尚未完全弥合。
-
-
未来工作:
- 将致力于解决这些限制,通过探索基于记忆的架构、采用基于约束的强化学习方法以及改进数据获取策略,以实现更稳健、可扩展和高效的高速无人机导航学习。
