当前,主流大模型在处理长文本时存在两大根本性效率问题。
其一是二次方时间复杂度,注意力分数的计算与序列长度的平方成正比,当文本长度大幅增加时,计算量将呈指数级增长。
其二是线性增长的KV缓存,在自回归生成过程中,模型需要缓存过去所有token的键和值,对于百万级别的长文本,KV缓存会消耗大量显存,限制了模型的吞吐量和并发处理能力。
线性注意力通过数学变换将计算复杂度从二次方降低到线性,但这种效率提升往往伴随着模型表达能力的牺牲。
尽管近年来线性注意力研究取得进展,但纯粹的线性结构由于有限的状态容量,在需要精确检索长序列中特定信息的任务上仍然面临理论挑战。
因此,当前LLMs在处理长序列任务时常常面临计算效率和性能瓶颈。
而今天,Kimi最新开源的注意力架构------Kimi Linear则有望解决这一难题。

Kimi Linear的架构创新
Kimi Linear采用了一种精巧的3:1混合层级结构,每三个Kimi Delta Attention线性注意力层之后,插入一个全注意力层。
KDA层作为模型的主体,负责处理大部分的token间交互,保证模型在处理长文本时的高效率。MLA层则作为周期性的全局信息枢纽,捕捉序列中任意两个token之间的依赖关系,弥补线性注意力在长距离、精细化信息检索上的不足。
这种混合设计使得Kimi Linear在长序列生成过程中,能将内存和KV缓存使用量减少高达75%。在处理百万级别上下文长度时,实现高达6.3倍的解码吞吐量提升。
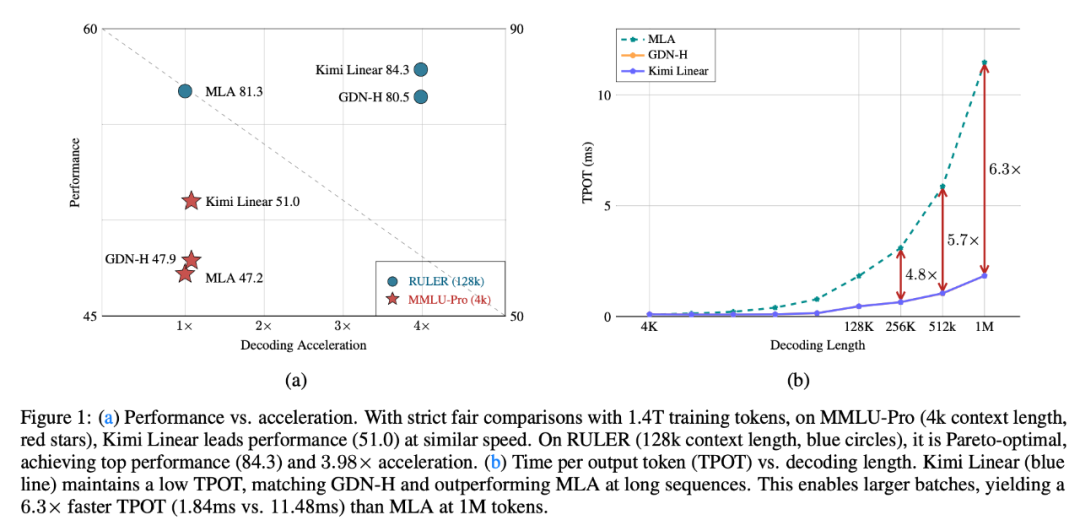
核心技术创新与性能突破
Kimi Delta Attention是架构的核心创新,这是一种新型的门控线性注意力变体。
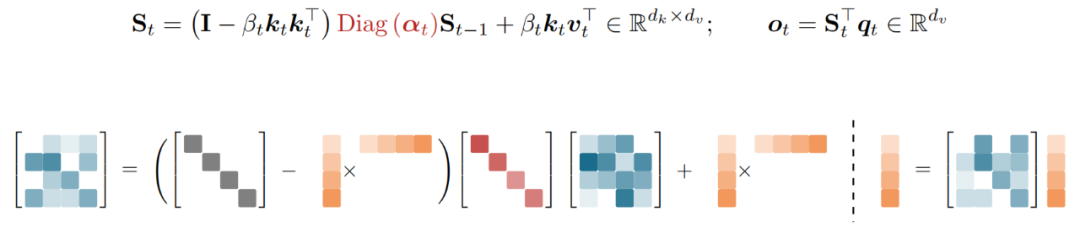
它基于Gated DeltaNet进行关键改进,通过更精细的门控机制实现对循环神经网络有限状态记忆的有效利用。KDA采用增量法则,将注意力状态更新过程重新解释为重构损失上的在线梯度下降,稳定了学习过程并提升性能。
另一个引人注目的设计是所有全注意力层都不使用任何显式的位置编码。模型将编码位置信息和时序偏见的全部责任交给KDA层,这种策略在长文本任务上表现出更强的鲁棒性和外推能力。
这一技术突破对AI应用开发具有深远意义。大幅降低的KV缓存意味着在相同硬件条件下,可以处理更长的上下文内容,支持更复杂的长文档分析和多轮对话场景。 解码速度的显著提升直接转化为更低的推理成本和更高的系统吞吐量,为AI应用的大规模商业化部署创造条件。
月之暗面已经开源了核心代码,并提供了vLLM集成支持,这将加速技术在开发者社区的普及和应用验证。
随着线性注意力技术的成熟,它有望成为下一代Agent LLM的基石技术,在长上下文推理、智能助手和多模态生成等应用中发挥关键作用。
当前,人工智能技术正处在快速演进阶段,计算效率的突破将直接决定应用落地的广度和深度。
Kimi Linear的出现,为行业提供了处理长文本任务的新选择,也预示着大模型架构创新远未到达终点。