本篇博客介绍Python YOLO目标检测, 并在PySide6应用里集成YOLO v8实现图片人物检测、视频人物检测以及摄像头人物检测。例如下面是图片人物检测:
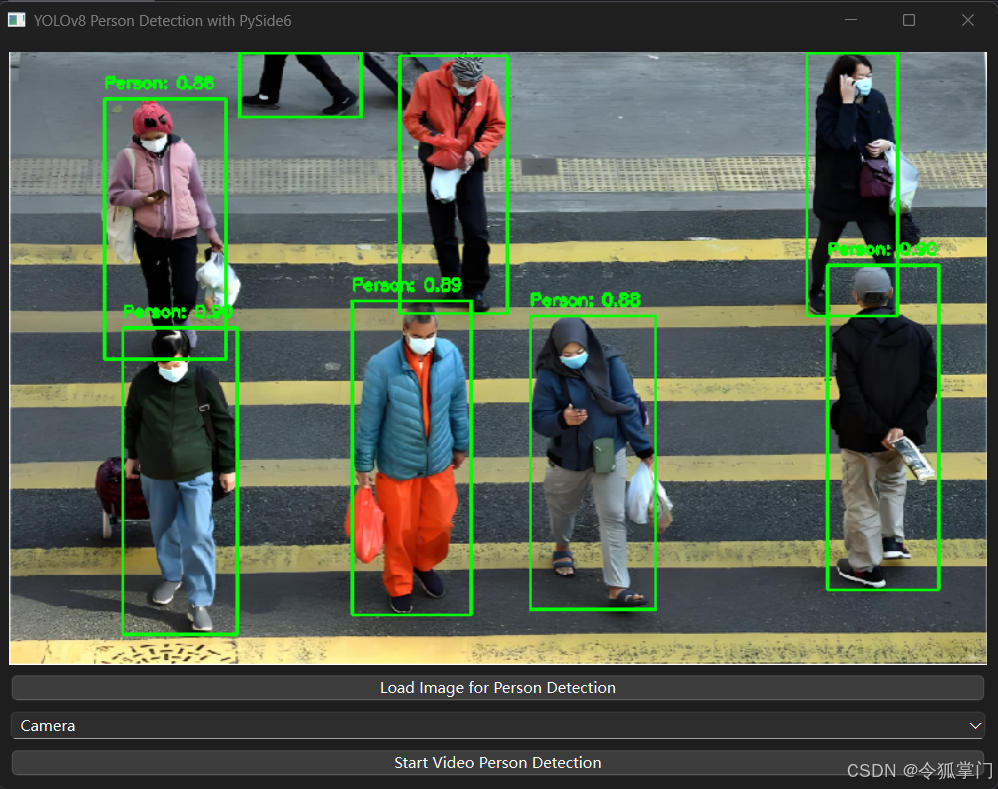
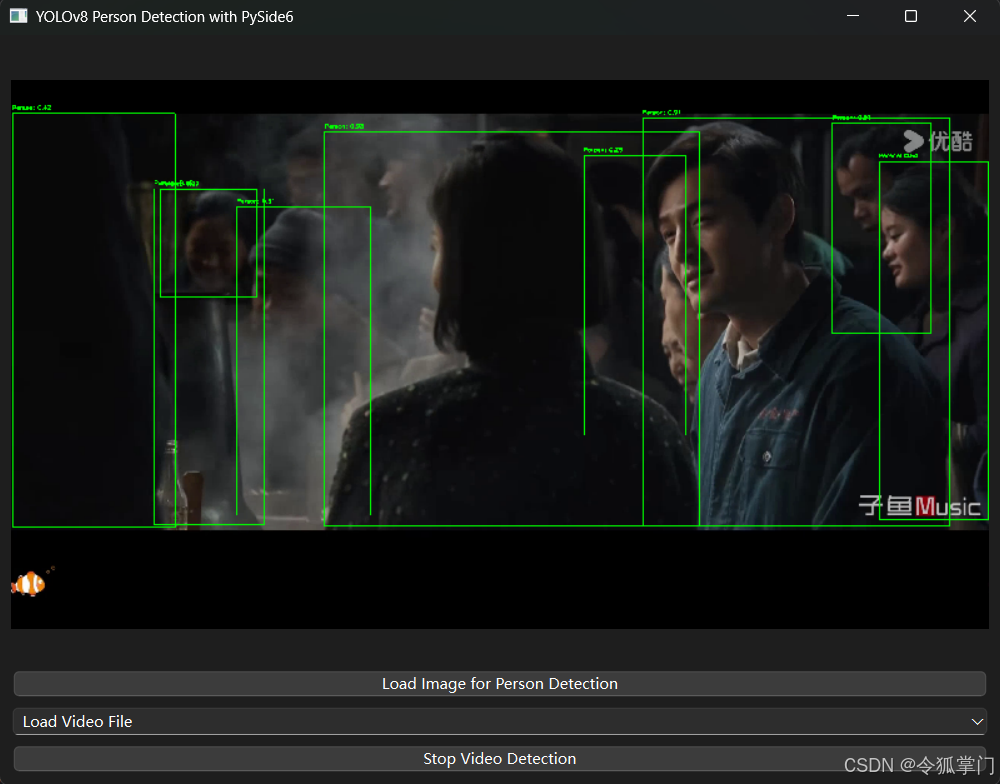
视频人物检测
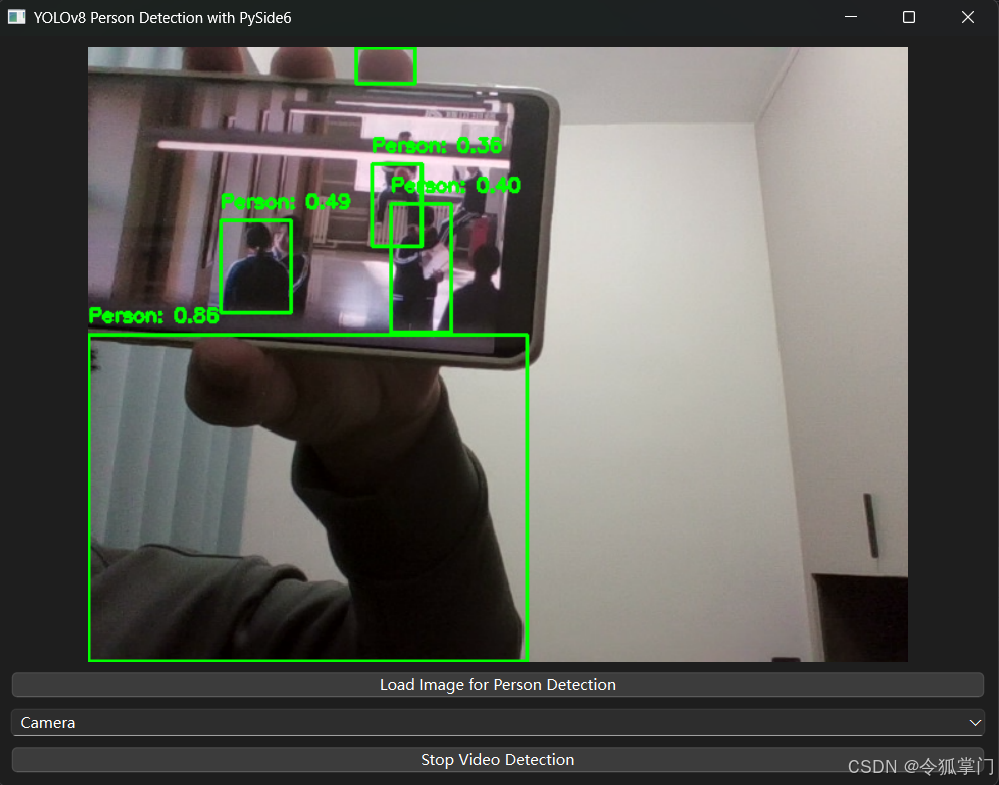
摄像头人物检测
一、YOLO介绍
YOLO(You Only Look Once)是一种基于深度学习的实时目标检测算法,由 Joseph Redmon 等人于 2016 年提出。它最大的特点是:一次性地(Only Once)完成图像中所有目标的检测与分类。
1.1 YOLO版本演化
YOLOv1 (2016) 首次提出,把检测变成回归问题,速度快但小目标检测弱。
YOLOv2 (2017) 加入 BatchNorm、Anchor Boxes,提高精度。
YOLOv3 (2018) 多尺度预测、残差结构(Darknet-53),兼顾速度与精度。
YOLOv4 (2020) 引入 CSPDarknet、Mish 激活、PANet 结构,进一步提升性能。
YOLOv5 (2020, Ultralytics) PyTorch 实现,易部署,支持自动混合精度(AMP)、模型剪枝等。
YOLOv7 (2022) 引入 E-ELAN 模块,性能极高。
YOLOv8 (2023) 由 Ultralytics 推出,支持检测、分割、姿态估计等一体化任务。
YOLOv9 (2024) 提出 G2Flow 结构与 Gelan 主干,精度与速度再度提升。
1.2 YOLO 的优势
- 实时性强:一次推理即可输出结果(30~150 FPS)
- 端到端训练:无需复杂的候选框生成
- 结构简单、易部署:广泛应用于嵌入式设备(如 Jetson、RK3588)
- 可扩展性强:可用于检测、分割、姿态估计、多任务融合
1.3 YOLO 的典型应用
- 车载摄像头目标检测(行人、车辆、交通标志)
- 安防监控(人流统计、异常检测)
- 医学影像分析(肿瘤检测)
- 工业缺陷检测(瑕疵识别)
- 智能零售(顾客行为分析)
- 航拍目标识别(船只、建筑、农田)
二、YOLO环境安装
在安装yolo环境时建议使用python虚拟环境,本篇博客使用的是miniconda创建python虚拟环境。关于PySide6、conda的学习可以看这个教程:PySide6教程,下面在win11系统,演示yolo环境的安装:
(1)使用conda创建虚拟环境
c
conda create --name yolo python=3.13
conda activate yolo(2)安装opencv-python
cpp
pip install opencv-python(3)安装torch
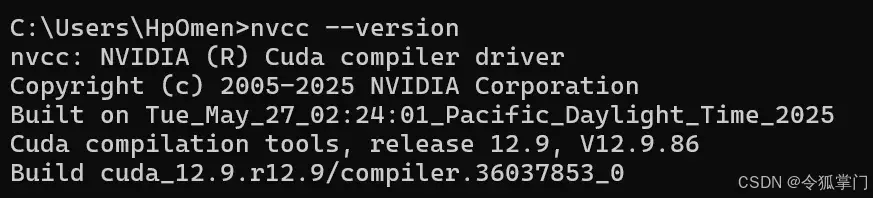
torch分为gpu和cpu版本,如果电脑有英伟达显卡,可以先安装cuda, 关于cuda的安装可以去cuda官网下载cuda运行时进行安装。输入nvcc --version 可以查看电脑cuda的版本,如下图:
进入pytorch官网 https://pytorch.org/,点击Get started查看torch安装命令:
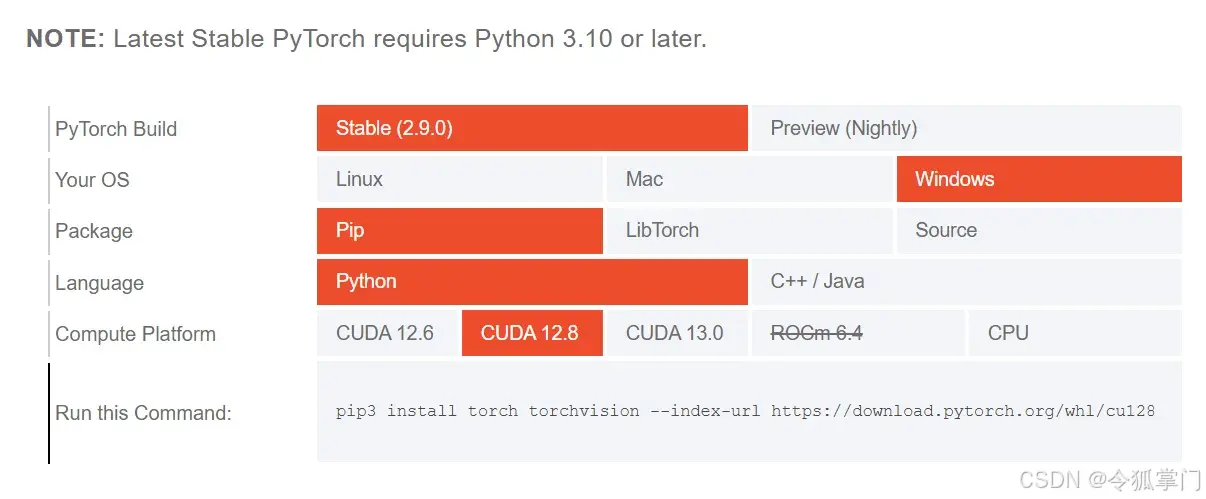
我的电脑是RTX3060, cuda12.9, 那么可以选择CUDA12.8版本,命令如下:
cpp
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu128如果电脑是核心显卡,可以选择cpu版本,命令如下:
c
pip3 install torch torchvision(4)安装yolo, 命令如下:
cpp
pip install ultralytics(5)安装pyside6
c
pip install PySide6三、YOLO代码演示
示例代码1:
python
import ultralytics
from ultralytics import YOLO
print(ultralytics.__version__)
model = YOLO("yolov8n.pt") # 自动下载模型
print("YOLO loaded successfully!")输入结果
8.3.223
YOLO loaded successfully!
由上面输出可知,当前用的是YOLO v8
示例代码2:
下面是在PySide6程序里使用yolo:
python
import sys
from PySide6.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog, QComboBox
from PySide6.QtCore import QTimer, Qt
from PySide6.QtGui import QImage, QPixmap
import cv2
from ultralytics import YOLO
class YOLODetectionApp(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("YOLOv8 Person Detection with PySide6")
self.setGeometry(100, 100, 800, 600)
# 初始化 YOLO 模型(使用 nano 版本,轻量级,适合 CPU)
self.model = YOLO("yolov8n.pt") # 自动下载,如果没有
# GUI 组件
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
layout = QVBoxLayout(self.central_widget)
self.label = QLabel(self)
self.label.setAlignment(Qt.AlignCenter)
layout.addWidget(self.label)
# 按钮:加载图片
self.load_image_btn = QPushButton("Load Image for Person Detection", self)
self.load_image_btn.clicked.connect(self.load_and_detect_image)
layout.addWidget(self.load_image_btn)
# 下拉框:选择视频源
self.video_source_combo = QComboBox(self)
self.video_source_combo.addItems(["Camera", "Load Video File"])
layout.addWidget(self.video_source_combo)
# 按钮:启动视频检测
self.start_video_btn = QPushButton("Start Video Person Detection", self)
self.start_video_btn.clicked.connect(self.start_video_detection)
layout.addWidget(self.start_video_btn)
# 定时器用于视频帧更新
self.timer = QTimer(self)
self.timer.timeout.connect(self.process_video_frame)
# 视频捕获对象
self.cap = None
self.is_video_running = False
def load_and_detect_image(self):
# 打开文件对话框选择图片
file_path, _ = QFileDialog.getOpenFileName(self, "Select Image", "", "Image Files (*.png *.jpg *.bmp)")
if not file_path:
return
# 读取图片
frame = cv2.imread(file_path)
if frame is None:
self.label.setText("Failed to load image!")
return
# 进行检测
results = self.model(frame)
# 过滤并绘制只显示人物
annotated_frame = self.draw_person_boxes(frame, results)
# 显示在 QLabel
self.display_frame(annotated_frame)
def start_video_detection(self):
if self.is_video_running:
self.stop_video()
self.start_video_btn.setText("Start Video Person Detection")
return
source = self.video_source_combo.currentText()
if source == "Camera":
self.cap = cv2.VideoCapture(0) # 摄像头
else:
file_path, _ = QFileDialog.getOpenFileName(self, "Select Video", "", "Video Files (*.mp4 *.avi)")
if not file_path:
return
self.cap = cv2.VideoCapture(file_path)
if not self.cap.isOpened():
self.label.setText("Failed to open video source!")
return
self.is_video_running = True
self.timer.start(30) # 每 30ms 更新一帧
self.start_video_btn.setText("Stop Video Detection")
def process_video_frame(self):
ret, frame = self.cap.read()
if not ret:
self.stop_video()
return
# 进行检测
results = self.model(frame, verbose=False) # verbose=False 减少日志
# 过滤并绘制只显示人物
annotated_frame = self.draw_person_boxes(frame, results)
# 显示
self.display_frame(annotated_frame)
def draw_person_boxes(self, frame, results):
# 复制帧以绘制
annotated_frame = frame.copy()
for result in results:
for box in result.boxes:
if int(box.cls) == 0: # 0 是 COCO 数据集中的 'person' 类别
x1, y1, x2, y2 = map(int, box.xyxy[0])
conf = float(box.conf)
cv2.rectangle(annotated_frame, (x1, y1), (x2, y2), (0, 255, 0), 2) # 绿色框
cv2.putText(annotated_frame, f"Person: {conf:.2f}", (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return annotated_frame
def display_frame(self, frame):
# 转换为 RGB 并创建 QImage
rgb_image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
height, width, channel = rgb_image.shape
bytes_per_line = 3 * width
q_img = QImage(rgb_image.data, width, height, bytes_per_line, QImage.Format_RGB888)
self.label.setPixmap(QPixmap.fromImage(q_img).scaled(self.label.size(), Qt.KeepAspectRatio))
def stop_video(self):
self.timer.stop()
if self.cap:
self.cap.release()
self.is_video_running = False
self.label.clear()
def closeEvent(self, event):
self.stop_video()
super().closeEvent(event)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = YOLODetectionApp()
window.show()
sys.exit(app.exec())运行结果:
点击上方按钮,即可进行加载图片视频进行YOLO目标检测。
注意事项和调试
● 性能:CPU 模式下,视频检测可能延迟。如果太慢,尝试:
○ 使用更小的输入大小:修改 results = self.model(frame, imgsz=320)。
○ 或切换到 YOLOv8 的更轻模型(如 yolov8n.pt 已是最小)。
● 常见错误:
○ "No module named ...":检查 pip 安装。
○ 摄像头权限:Win11 设置 > 隐私 > 摄像头,确保允许。
○ 模型下载失败:手动下载 yolov8n.pt 从 https://github.com/ultralytics/assets/releases 并放在脚本同目录。
● 扩展:如果你想检测其他类别,修改 if int(box.cls) == 0(COCO 类别列表见 Ultralytics 文档)。
● 资源消耗:CPU 使用率高时,关闭其他程序。
除了在Python里使用,也可以在C++代码中使用yolo, 只是稍微复杂一点。